
uzu
A high-performance inference engine for AI models
Stars: 1425

uzu is a high-performance inference engine for AI models on Apple Silicon. It features a simple, high-level API, hybrid architecture for GPU kernel computation, unified model configurations, traceable computations, and utilizes unified memory on Apple devices. The tool provides a CLI mode for running models, supports its own model format, and offers prebuilt Swift and TypeScript frameworks for bindings. Users can quickly start by adding the uzu dependency to their Cargo.toml and creating an inference Session with a specific model and configuration. Performance benchmarks show metrics for various models on Apple M2, highlighting the tokens/s speed for each model compared to llama.cpp with bf16/f16 precision.
README:


A high-performance inference engine for AI models on Apple Silicon. Key features:
- Simple, high-level API
- Hybrid architecture, where layers can be computed as GPU kernels or via MPSGraph (a low-level API beneath CoreML)
- Unified model configurations, making it easy to add support for new models
- Traceable computations to ensure correctness against the source-of-truth implementation
- Utilizes unified memory on Apple devices
For a detailed explanation of the architecture, please refer to the documentation.
uzu uses its own model format. To export a specific model, use lalamo:
git clone https://github.com/trymirai/lalamo.git
cd lalamo
git checkout v0.6.0After that, you can retrieve the list of supported models:
uv run lalamo list-modelsThen, export the specific one:
uv run lalamo convert meta-llama/Llama-3.2-1B-InstructAlternatively, you can download a test model using the sample script:
./scripts/download_test_model.shOr you can download any supported model that has already been converted using:
cd ./tools/helpers/
uv sync # install dependencies
uv run main.py list-models # show the list of supported models
uv run main.py download-model {REPO_ID} # download a specific model using repo_idAfter that, you can find the downloaded model at ./models/{VERSION}/.
- uzu-swift - a prebuilt Swift framework, ready to use with SPM
- uzu-ts - a prebuilt TypeScript framework made for Node.js ecosystem
You can run uzu in a CLI mode:
cargo run --release -p cli -- helpUsage: cli [COMMAND]
Commands:
run Run a model with the specified path
serve Start a server with the specified model path
bench Run benchmarks for the specified model
help Print this message or the help of the given subcommand(s)For now, we only support the Metal backend, so to compile corresponding kernels you’ll need to install Xcode and run the following commands:
xcodebuild -runFirstLaunch
xcodebuild -downloadComponent MetalToolchainFirst, add the uzu dependency to your Cargo.toml:
[dependencies]
uzu = { git = "https://github.com/trymirai/uzu", branch = "main", package = "uzu" }Then, create an inference Session with a specific model and configuration:
use std::path::PathBuf;
use uzu::session::{
Session,
config::{DecodingConfig, RunConfig},
types::{Input, Output},
};
fn main() -> Result<(), Box<dyn std::error::Error>> {
let model_path = PathBuf::from("MODEL_PATH");
let mut session = Session::new(model_path, DecodingConfig::default())?;
let input = Input::Text(String::from("Tell about London"));
let output = session.run(
input,
RunConfig::default().tokens_limit(128),
Some(|_: Output| {
return true;
}),
)?;
println!("{}", output.text.original);
Ok(())
}To run benchmarks, you can use the following command:
cargo run --release -p cli -- bench ./models/{ENGINE_VERSION}/{MODEL_NAME} ./models/{ENGINE_VERSION}/{MODEL_NAME}/benchmark_task.json ./models/{ENGINE_VERSION}/{MODEL_NAME}/benchmark_result.jsonbenchmark_task.json will be automatically generated after the model is downloaded via ./tools/helpers/, as described earlier.
This project is licensed under the MIT License. See the LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for uzu
Similar Open Source Tools
uzu
uzu is a high-performance inference engine for AI models on Apple Silicon. It features a simple, high-level API, hybrid architecture for GPU kernel computation, unified model configurations, traceable computations, and utilizes unified memory on Apple devices. The tool provides a CLI mode for running models, supports its own model format, and offers prebuilt Swift and TypeScript frameworks for bindings. Users can quickly start by adding the uzu dependency to their Cargo.toml and creating an inference Session with a specific model and configuration. Performance benchmarks show metrics for various models on Apple M2, highlighting the tokens/s speed for each model compared to llama.cpp with bf16/f16 precision.

web-llm
WebLLM is a modular and customizable javascript package that directly brings language model chats directly onto web browsers with hardware acceleration. Everything runs inside the browser with no server support and is accelerated with WebGPU. WebLLM is fully compatible with OpenAI API. That is, you can use the same OpenAI API on any open source models locally, with functionalities including json-mode, function-calling, streaming, etc. We can bring a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

labo
LABO is a time series forecasting and analysis framework that integrates pre-trained and fine-tuned LLMs with multi-domain agent-based systems. It allows users to create and tune agents easily for various scenarios, such as stock market trend prediction and web public opinion analysis. LABO requires a specific runtime environment setup, including system requirements, Python environment, dependency installations, and configurations. Users can fine-tune their own models using LABO's Low-Rank Adaptation (LoRA) for computational efficiency and continuous model updates. Additionally, LABO provides a Python library for building model training pipelines and customizing agents for specific tasks.

vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.

paxml
Pax is a framework to configure and run machine learning experiments on top of Jax.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.
torchtitan
Torchtitan is a PyTorch native platform designed for rapid experimentation and large-scale training of generative AI models. It provides a flexible foundation for developers to build upon with extension points for creating custom extensions. The tool showcases PyTorch's latest distributed training features and supports pretraining Llama 3.1 LLMs of various sizes. It offers key features like multi-dimensional parallelisms, FSDP2 with per-parameter sharding, Tensor Parallel, Pipeline Parallel, and more. Users can contribute to the tool through the experiments folder and core contributions guidelines. Installation can be done from source, nightly builds, or stable releases. The tool also supports training Llama 3.1 models and provides guidance on starting a training run and multi-node training. Citation information is available for referencing the tool in academic work, and the source code is under a BSD 3 license.
llm-term
LLM-Term is a Rust-based CLI tool that generates and executes terminal commands using OpenAI's language models or local Ollama models. It offers configurable model and token limits, works on both PowerShell and Unix-like shells, and provides a seamless user experience for generating commands based on prompts. Users can easily set up the tool, customize configurations, and leverage different models for command generation.

kaito
KAITO is an operator that automates the AI/ML model inference or tuning workload in a Kubernetes cluster. It manages large model files using container images, provides preset configurations to avoid adjusting workload parameters based on GPU hardware, supports popular open-sourced inference runtimes, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry. Using KAITO simplifies the workflow of onboarding large AI inference models in Kubernetes.
lorax
LoRAX is a framework that allows users to serve thousands of fine-tuned models on a single GPU, dramatically reducing the cost of serving without compromising on throughput or latency. It features dynamic adapter loading, heterogeneous continuous batching, adapter exchange scheduling, optimized inference, and is ready for production with prebuilt Docker images, Helm charts for Kubernetes, Prometheus metrics, and distributed tracing with Open Telemetry. LoRAX supports a number of Large Language Models as the base model including Llama, Mistral, and Qwen, and any of the linear layers in the model can be adapted via LoRA and loaded in LoRAX.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.

generative-models
Generative Models by Stability AI is a repository that provides various generative models for research purposes. It includes models like Stable Video 4D (SV4D) for video synthesis, Stable Video 3D (SV3D) for multi-view synthesis, SDXL-Turbo for text-to-image generation, and more. The repository focuses on modularity and implements a config-driven approach for building and combining submodules. It supports training with PyTorch Lightning and offers inference demos for different models. Users can access pre-trained models like SDXL-base-1.0 and SDXL-refiner-1.0 under a CreativeML Open RAIL++-M license. The codebase also includes tools for invisible watermark detection in generated images.
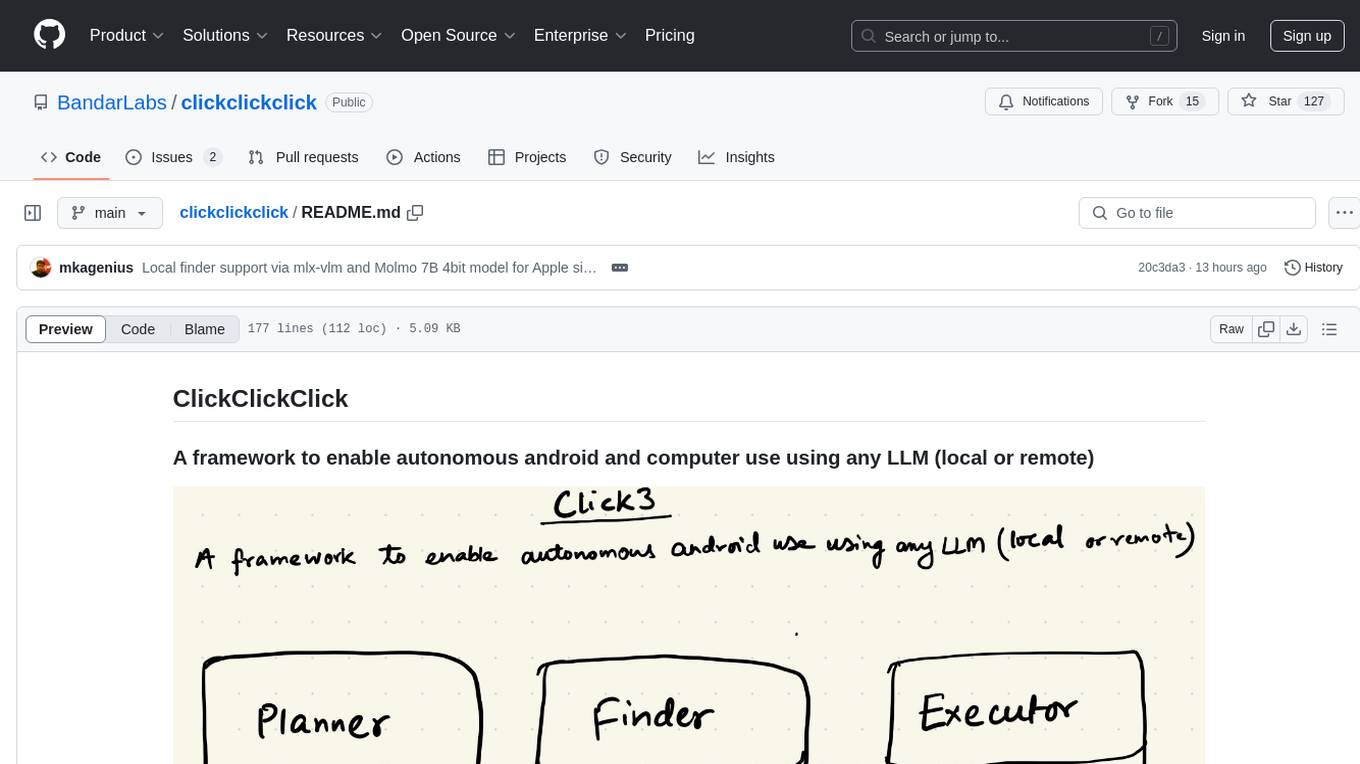
clickclickclick
ClickClickClick is a framework designed to enable autonomous Android and computer use using various LLM models, both locally and remotely. It supports tasks such as drafting emails, opening browsers, and starting games, with current support for local models via Ollama, Gemini, and GPT 4o. The tool is highly experimental and evolving, with the best results achieved using specific model combinations. Users need prerequisites like `adb` installation and USB debugging enabled on Android phones. The tool can be installed via cloning the repository, setting up a virtual environment, and installing dependencies. It can be used as a CLI tool or script, allowing users to configure planner and finder models for different tasks. Additionally, it can be used as an API to execute tasks based on provided prompts, platform, and models.

sieves
sieves is a library for zero- and few-shot NLP tasks with structured generation, enabling rapid prototyping of NLP applications without the need for training. It simplifies NLP prototyping by bundling capabilities into a single library, providing zero- and few-shot model support, a unified interface for structured generation, built-in tasks for common NLP operations, easy extendability, document-based pipeline architecture, caching to prevent redundant model calls, and more. The tool draws inspiration from spaCy and spacy-llm, offering features like immediate inference, observable pipelines, integrated tools for document parsing and text chunking, ready-to-use tasks such as classification, summarization, translation, and more, persistence for saving and loading pipelines, distillation for specialized model creation, and caching to optimize performance.

Biomni
Biomni is a general-purpose biomedical AI agent designed to autonomously execute a wide range of research tasks across diverse biomedical subfields. By integrating cutting-edge large language model (LLM) reasoning with retrieval-augmented planning and code-based execution, Biomni helps scientists dramatically enhance research productivity and generate testable hypotheses.
For similar tasks

arena-hard-auto
Arena-Hard-Auto-v0.1 is an automatic evaluation tool for instruction-tuned LLMs. It contains 500 challenging user queries. The tool prompts GPT-4-Turbo as a judge to compare models' responses against a baseline model (default: GPT-4-0314). Arena-Hard-Auto employs an automatic judge as a cheaper and faster approximator to human preference. It has the highest correlation and separability to Chatbot Arena among popular open-ended LLM benchmarks. Users can evaluate their models' performance on Chatbot Arena by using Arena-Hard-Auto.

max
The Modular Accelerated Xecution (MAX) platform is an integrated suite of AI libraries, tools, and technologies that unifies commonly fragmented AI deployment workflows. MAX accelerates time to market for the latest innovations by giving AI developers a single toolchain that unlocks full programmability, unparalleled performance, and seamless hardware portability.

ai-hub
AI Hub Project aims to continuously test and evaluate mainstream large language models, while accumulating and managing various effective model invocation prompts. It has integrated all mainstream large language models in China, including OpenAI GPT-4 Turbo, Baidu ERNIE-Bot-4, Tencent ChatPro, MiniMax abab5.5-chat, and more. The project plans to continuously track, integrate, and evaluate new models. Users can access the models through REST services or Java code integration. The project also provides a testing suite for translation, coding, and benchmark testing.

long-context-attention
Long-Context-Attention (YunChang) is a unified sequence parallel approach that combines the strengths of DeepSpeed-Ulysses-Attention and Ring-Attention to provide a versatile and high-performance solution for long context LLM model training and inference. It addresses the limitations of both methods by offering no limitation on the number of heads, compatibility with advanced parallel strategies, and enhanced performance benchmarks. The tool is verified in Megatron-LM and offers best practices for 4D parallelism, making it suitable for various attention mechanisms and parallel computing advancements.

marlin
Marlin is a highly optimized FP16xINT4 matmul kernel designed for large language model (LLM) inference, offering close to ideal speedups up to batchsizes of 16-32 tokens. It is suitable for larger-scale serving, speculative decoding, and advanced multi-inference schemes like CoT-Majority. Marlin achieves optimal performance by utilizing various techniques and optimizations to fully leverage GPU resources, ensuring efficient computation and memory management.

MMC
This repository, MMC, focuses on advancing multimodal chart understanding through large-scale instruction tuning. It introduces a dataset supporting various tasks and chart types, a benchmark for evaluating reasoning capabilities over charts, and an assistant achieving state-of-the-art performance on chart QA benchmarks. The repository provides data for chart-text alignment, benchmarking, and instruction tuning, along with existing datasets used in experiments. Additionally, it offers a Gradio demo for the MMCA model.

Tiktoken
Tiktoken is a high-performance implementation focused on token count operations. It provides various encodings like o200k_base, cl100k_base, r50k_base, p50k_base, and p50k_edit. Users can easily encode and decode text using the provided API. The repository also includes a benchmark console app for performance tracking. Contributions in the form of PRs are welcome.

ppl.llm.serving
ppl.llm.serving is a serving component for Large Language Models (LLMs) within the PPL.LLM system. It provides a server based on gRPC and supports inference for LLaMA. The repository includes instructions for prerequisites, quick start guide, model exporting, server setup, client usage, benchmarking, and offline inference. Users can refer to the LLaMA Guide for more details on using this serving component.
For similar jobs

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.
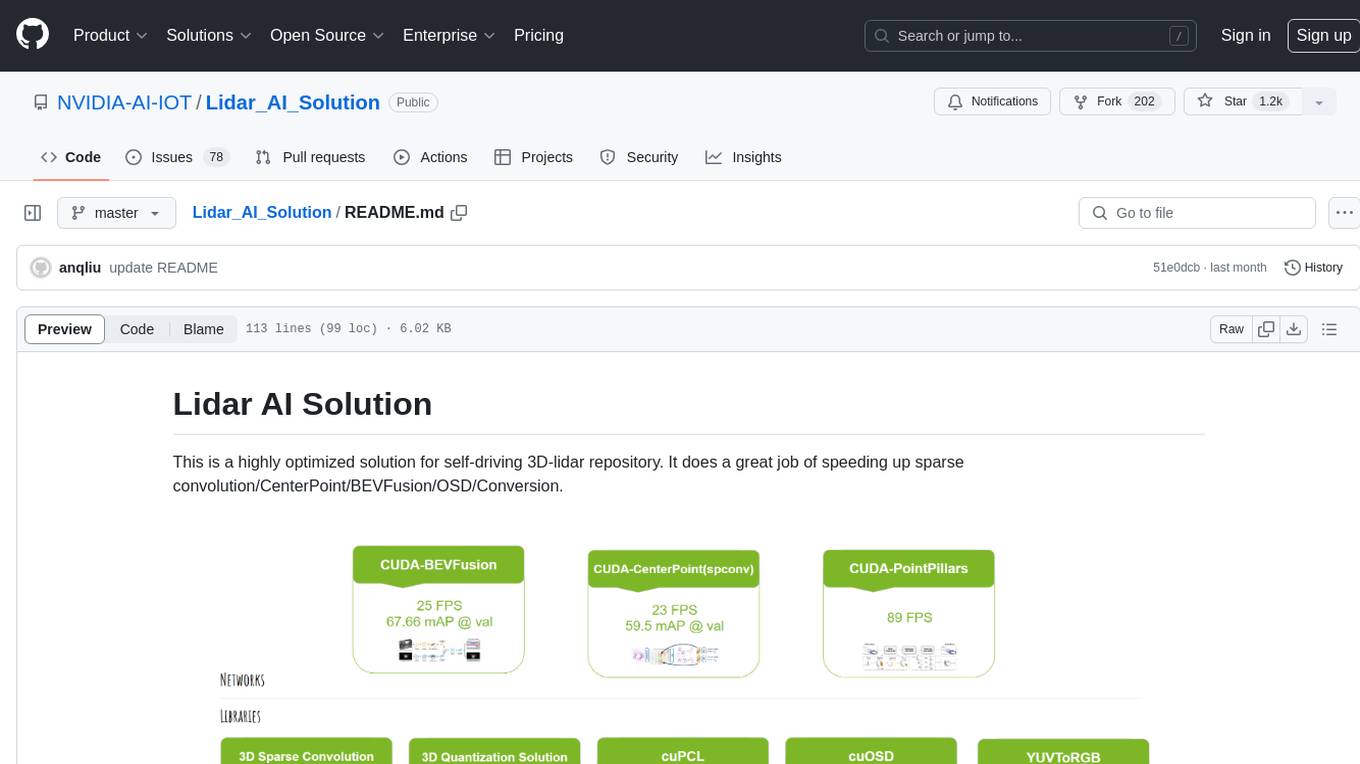
Lidar_AI_Solution
Lidar AI Solution is a highly optimized repository for self-driving 3D lidar, providing solutions for sparse convolution, BEVFusion, CenterPoint, OSD, and Conversion. It includes CUDA and TensorRT implementations for various tasks such as 3D sparse convolution, BEVFusion, CenterPoint, PointPillars, V2XFusion, cuOSD, cuPCL, and YUV to RGB conversion. The repository offers easy-to-use solutions, high accuracy, low memory usage, and quantization options for different tasks related to self-driving technology.

generative-ai-sagemaker-cdk-demo
This repository showcases how to deploy generative AI models from Amazon SageMaker JumpStart using the AWS CDK. Generative AI is a type of AI that can create new content and ideas, such as conversations, stories, images, videos, and music. The repository provides a detailed guide on deploying image and text generative AI models, utilizing pre-trained models from SageMaker JumpStart. The web application is built on Streamlit and hosted on Amazon ECS with Fargate. It interacts with the SageMaker model endpoints through Lambda functions and Amazon API Gateway. The repository also includes instructions on setting up the AWS CDK application, deploying the stacks, using the models, and viewing the deployed resources on the AWS Management Console.

cake
cake is a pure Rust implementation of the llama3 LLM distributed inference based on Candle. The project aims to enable running large models on consumer hardware clusters of iOS, macOS, Linux, and Windows devices by sharding transformer blocks. It allows running inferences on models that wouldn't fit in a single device's GPU memory by batching contiguous transformer blocks on the same worker to minimize latency. The tool provides a way to optimize memory and disk space by splitting the model into smaller bundles for workers, ensuring they only have the necessary data. cake supports various OS, architectures, and accelerations, with different statuses for each configuration.

Awesome-Robotics-3D
Awesome-Robotics-3D is a curated list of 3D Vision papers related to Robotics domain, focusing on large models like LLMs/VLMs. It includes papers on Policy Learning, Pretraining, VLM and LLM, Representations, and Simulations, Datasets, and Benchmarks. The repository is maintained by Zubair Irshad and welcomes contributions and suggestions for adding papers. It serves as a valuable resource for researchers and practitioners in the field of Robotics and Computer Vision.

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.
vector-inference
This repository provides an easy-to-use solution for running inference servers on Slurm-managed computing clusters using vLLM. All scripts in this repository run natively on the Vector Institute cluster environment. Users can deploy models as Slurm jobs, check server status and performance metrics, and shut down models. The repository also supports launching custom models with specific configurations. Additionally, users can send inference requests and set up an SSH tunnel to run inference from a local device.

rhesis
Rhesis is a comprehensive test management platform designed for Gen AI teams, offering tools to create, manage, and execute test cases for generative AI applications. It ensures the robustness, reliability, and compliance of AI systems through features like test set management, automated test generation, edge case discovery, compliance validation, integration capabilities, and performance tracking. The platform is open source, emphasizing community-driven development, transparency, extensible architecture, and democratizing AI safety. It includes components such as backend services, frontend applications, SDK for developers, worker services, chatbot applications, and Polyphemus for uncensored LLM service. Rhesis enables users to address challenges unique to testing generative AI applications, such as non-deterministic outputs, hallucinations, edge cases, ethical concerns, and compliance requirements.