
sdk-examples
Spectacular AI SDK examples
Stars: 223
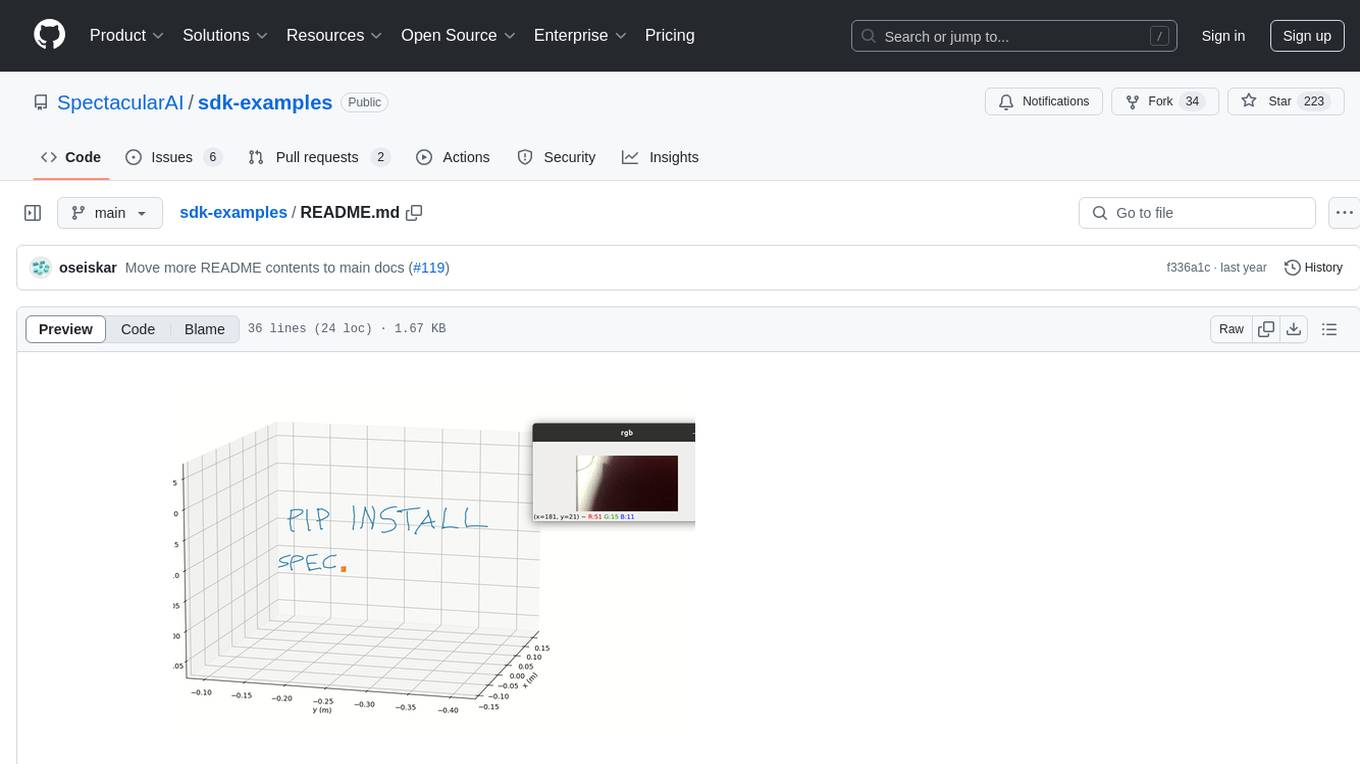
Spectacular AI SDK fuses data from cameras and IMU sensors to output an accurate 6-degree-of-freedom pose of a device, enabling Visual-Inertial SLAM for tracking robots and vehicles, as well as Augmented, Mixed, and Virtual Reality. The SDK includes a Mapping API for real-time and offline 3D reconstruction use cases.
README:
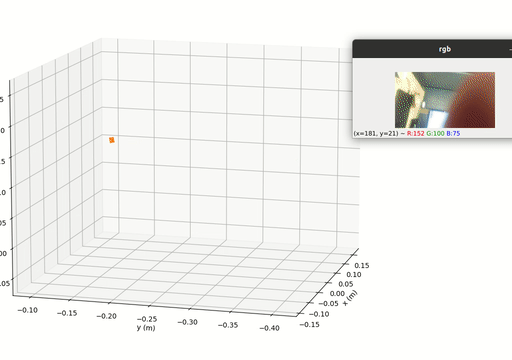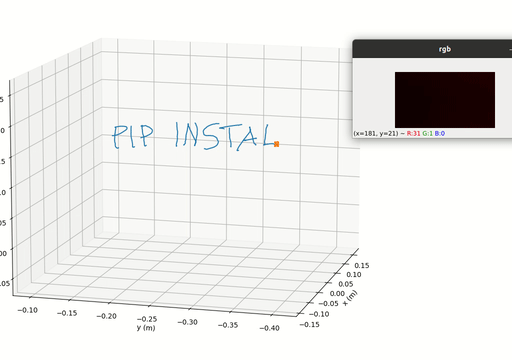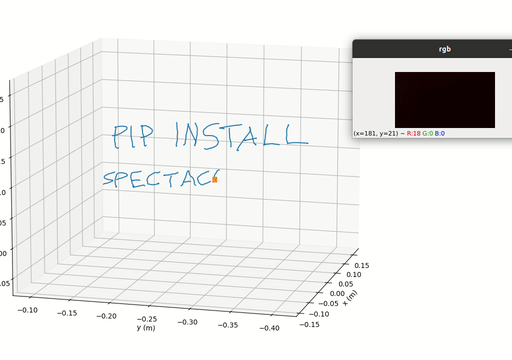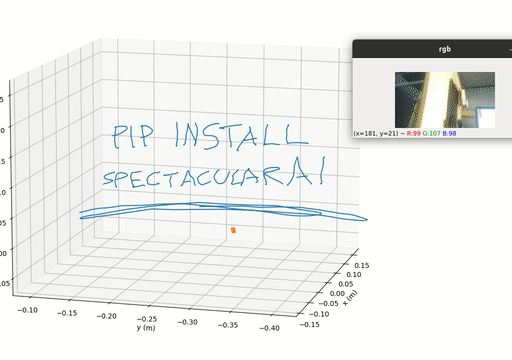
Spectacular AI SDK fuses data from cameras and IMU sensors (accelerometer and gyroscope) and outputs an accurate 6-degree-of-freedom pose of a device. This is called Visual-Inertial SLAM (VISLAM) and it can be used in, among other cases, tracking (autonomous) robots and vehicles, as well as Augmented, Mixed and Virtual Reality.
The SDK also includes a Mapping API that can be used to access the full SLAM map for both real-time and offline 3D reconstruction use cases.
See also the parts of the SDK with public source code:
The examples in this repository are licensed under Apache 2.0 (see LICENSE).
The SDK itself (not included in this repository) is proprietary to Spectacular AI. The OAK / Depth AI wrapper available in PyPI is free for non-commercial use on x86_64 Windows and Linux platforms. For commerical licensing options and more SDK variants (ARM binaries & C++ API), contact us at https://www.spectacularai.com/#contact .
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for sdk-examples
Similar Open Source Tools
sdk-examples
Spectacular AI SDK fuses data from cameras and IMU sensors to output an accurate 6-degree-of-freedom pose of a device, enabling Visual-Inertial SLAM for tracking robots and vehicles, as well as Augmented, Mixed, and Virtual Reality. The SDK includes a Mapping API for real-time and offline 3D reconstruction use cases.

Genkit
Genkit is an open-source framework for building full-stack AI-powered applications, used in production by Google's Firebase. It provides SDKs for JavaScript/TypeScript (Stable), Go (Beta), and Python (Alpha) with unified interface for integrating AI models from providers like Google, OpenAI, Anthropic, Ollama. Rapidly build chatbots, automations, and recommendation systems using streamlined APIs for multimodal content, structured outputs, tool calling, and agentic workflows. Genkit simplifies AI integration with open-source SDK, unified APIs, and offers text and image generation, structured data generation, tool calling, prompt templating, persisted chat interfaces, AI workflows, and AI-powered data retrieval (RAG).

Protofy
Protofy is a full-stack, batteries-included low-code enabled web/app and IoT system with an API system and real-time messaging. It is based on Protofy (protoflow + visualui + protolib + protodevices) + Expo + Next.js + Tamagui + Solito + Express + Aedes + Redbird + Many other amazing packages. Protofy can be used to fast prototype Apps, webs, IoT systems, automations, or APIs. It is a ultra-extensible CMS with supercharged capabilities, mobile support, and IoT support (esp32 thanks to esphome).

genkit
Firebase Genkit (beta) is a framework with powerful tooling to help app developers build, test, deploy, and monitor AI-powered features with confidence. Genkit is cloud optimized and code-centric, integrating with many services that have free tiers to get started. It provides unified API for generation, context-aware AI features, evaluation of AI workflow, extensibility with plugins, easy deployment to Firebase or Google Cloud, observability and monitoring with OpenTelemetry, and a developer UI for prototyping and testing AI features locally. Genkit works seamlessly with Firebase or Google Cloud projects through official plugins and templates.

openvino
OpenVINO™ is an open-source toolkit for optimizing and deploying AI inference. It provides a common API to deliver inference solutions on various platforms, including CPU, GPU, NPU, and heterogeneous devices. OpenVINO™ supports pre-trained models from Open Model Zoo and popular frameworks like TensorFlow, PyTorch, and ONNX. Key components of OpenVINO™ include the OpenVINO™ Runtime, plugins for different hardware devices, frontends for reading models from native framework formats, and the OpenVINO Model Converter (OVC) for adjusting models for optimal execution on target devices.
adk-java
Agent Development Kit (ADK) for Java is an open-source toolkit designed for developers to build, evaluate, and deploy sophisticated AI agents with flexibility and control. It allows defining agent behavior, orchestration, and tool use directly in code, enabling robust debugging, versioning, and deployment anywhere. The toolkit offers a rich tool ecosystem, code-first development approach, and support for modular multi-agent systems, making it ideal for creating advanced AI agents integrated with Google Cloud services.
positronic
Positronic is an end-to-end toolkit for building ML-driven robotics systems, aiming to simplify data collection, messy data handling, and complex deployment in the field of robotics. It provides a Python-native stack for real-life ML robotics, covering hardware integration, dataset curation, policy training, deployment, and monitoring. The toolkit is designed to make professional-grade ML robotics approachable, without the need for ROS. Positronic offers solutions for data ops, hardware drivers, unified inference API, and iteration workflows, enabling teams to focus on developing manipulation systems for robots.
MaixCDK
MaixCDK (Maix C/CPP Development Kit) is a C/C++ development kit that integrates practical functions such as AI, machine vision, and IoT. It provides easy-to-use encapsulation for quickly building projects in vision, artificial intelligence, IoT, robotics, industrial cameras, and more. It supports hardware-accelerated execution of AI models, common vision algorithms, OpenCV, and interfaces for peripheral operations. MaixCDK offers cross-platform support, easy-to-use API, simple environment setup, online debugging, and a complete ecosystem including MaixPy and MaixVision. Supported devices include Sipeed MaixCAM, Sipeed MaixCAM-Pro, and partial support for Common Linux.
llm-rag-vectordb-python
This repository provides sample applications and tutorials to showcase the power of Amazon Bedrock with Python. It helps Python developers understand how to harness Amazon Bedrock in building generative AI-enabled applications. The resources also demonstrate integration with vector databases using RAG (Retrieval-augmented generation) and services like Amazon Aurora, RDS, and OpenSearch. Additionally, it explores using langchain and streamlit to create effective experimental applications.

qdrant
Qdrant is a vector similarity search engine and vector database. It is written in Rust, which makes it fast and reliable even under high load. Qdrant can be used for a variety of applications, including: * Semantic search * Image search * Product recommendations * Chatbots * Anomaly detection Qdrant offers a variety of features, including: * Payload storage and filtering * Hybrid search with sparse vectors * Vector quantization and on-disk storage * Distributed deployment * Highlighted features such as query planning, payload indexes, SIMD hardware acceleration, async I/O, and write-ahead logging Qdrant is available as a fully managed cloud service or as an open-source software that can be deployed on-premises.

awesome-RK3588
RK3588 is a flagship 8K SoC chip by Rockchip, integrating Cortex-A76 and Cortex-A55 cores with NEON coprocessor for 8K video codec. This repository curates resources for developing with RK3588, including official resources, RKNN models, projects, development boards, documentation, tools, and sample code.
AIQC
AIQC is an open source Python package that provides a declarative API for end-to-end MLOps in order to make deep learning more accessible to researchers. It utilizes a SQLite object-relational model for machine learning objects and stacks standardized workflows for various analyses, data types, and libraries. The benefits include a 90% reduction in data wrangling, reproducibility, and no need to install and maintain application and database servers for experiment tracking. AIQC is pip-installable and provides a Dash-Plotly UI for real-time experiment tracking.
geoai
geoai is a Python package designed for utilizing Artificial Intelligence (AI) in the context of geospatial data. It allows users to visualize various types of geospatial data such as vector, raster, and LiDAR data. Additionally, the package offers functionalities for segmenting remote sensing imagery using the Segment Anything Model and classifying remote sensing imagery with deep learning models. With a focus on geospatial AI applications, geoai provides a versatile tool for processing and analyzing spatial data with the power of AI.

Geoweaver
Geoweaver is an in-browser software that enables users to easily compose and execute full-stack data processing workflows using online spatial data facilities, high-performance computation platforms, and open-source deep learning libraries. It provides server management, code repository, workflow orchestration software, and history recording capabilities. Users can run it from both local and remote machines. Geoweaver aims to make data processing workflows manageable for non-coder scientists and preserve model run history. It offers features like progress storage, organization, SSH connection to external servers, and a web UI with Python support.

macai
Macai is a native macOS client for interacting with modern AI tools, such as ChatGPT and Ollama. It features organized chats with custom system messages, system-defined light/dark themes, backup and restore functionality, customizable context size, support for any model with a compatible API, formatted code blocks and tables, multiple chat tabs, CoreData data storage, streamed responses, and automatic chat name generation. Macai is in active development, with contributions welcome.

Vento
Vento is an AI-driven machine automation platform that utilizes a Large Language Model (LLM) to automate the control of physical devices and machines. It features a natural language autopilot system for smart and industrial devices, providing a continuous decision loop for sensor states evaluation and actuator triggering. The platform offers a user-friendly UI for device onboarding, rule configuration, and real-time monitoring. Vento supports connected devices (IoT) based on ESP32 with ESPHome, allowing users to program, deploy, and manage IoT networks visually. Additionally, it provides AI assistance for creating rules and system management through automatic context transfer and prompt cascading.
For similar tasks
sdk-examples
Spectacular AI SDK fuses data from cameras and IMU sensors to output an accurate 6-degree-of-freedom pose of a device, enabling Visual-Inertial SLAM for tracking robots and vehicles, as well as Augmented, Mixed, and Virtual Reality. The SDK includes a Mapping API for real-time and offline 3D reconstruction use cases.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024
Vitron
Vitron is a unified pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing static images and dynamic videos. It addresses challenges in existing vision LLMs such as superficial instance-level understanding, lack of unified support for images and videos, and insufficient coverage across various vision tasks. The tool requires Python >= 3.8, Pytorch == 2.1.0, and CUDA Version >= 11.8 for installation. Users can deploy Gradio demo locally and fine-tune their models for specific tasks.
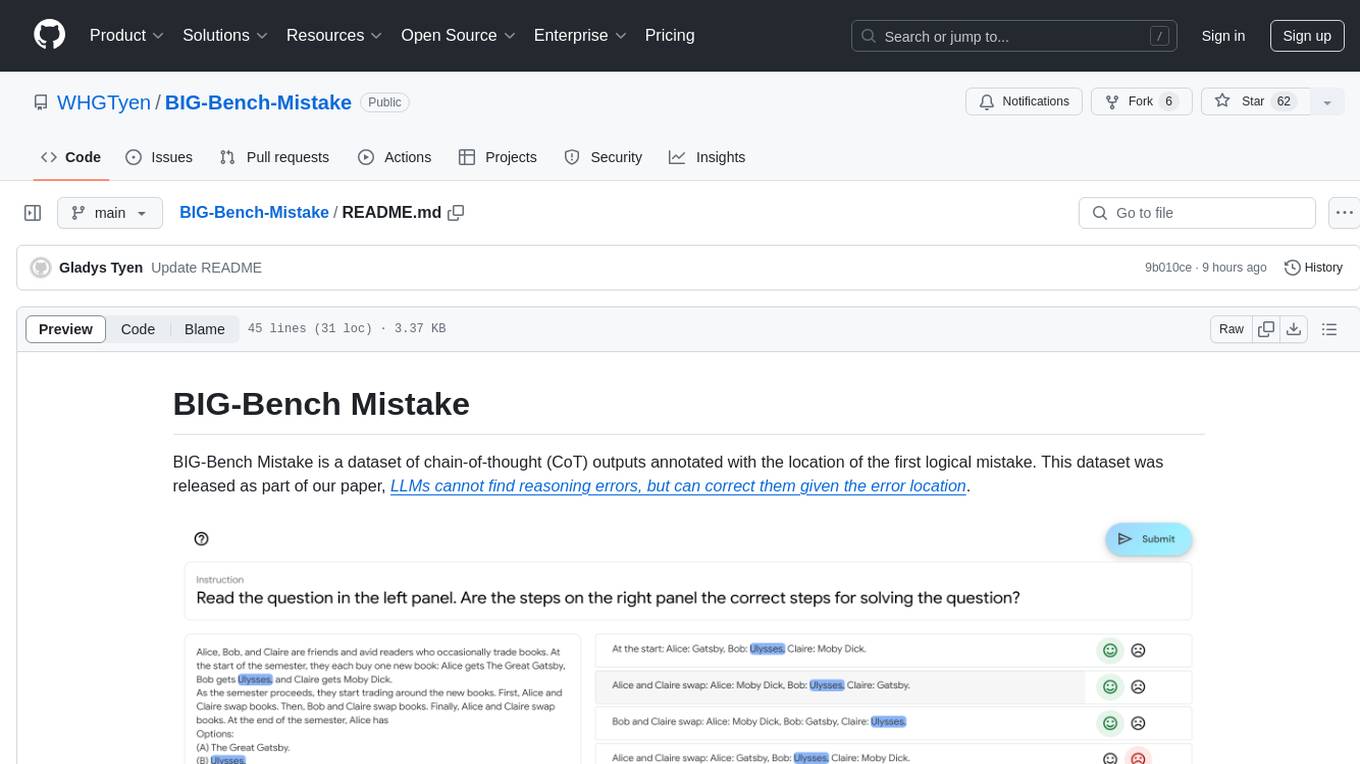
BIG-Bench-Mistake
BIG-Bench Mistake is a dataset of chain-of-thought (CoT) outputs annotated with the location of the first logical mistake. It was released as part of a research paper focusing on benchmarking LLMs in terms of their mistake-finding ability. The dataset includes CoT traces for tasks like Word Sorting, Tracking Shuffled Objects, Logical Deduction, Multistep Arithmetic, and Dyck Languages. Human annotators were recruited to identify mistake steps in these tasks, with automated annotation for Dyck Languages. Each JSONL file contains input questions, steps in the chain of thoughts, model's answer, correct answer, and the index of the first logical mistake.
For similar jobs
sdk-examples
Spectacular AI SDK fuses data from cameras and IMU sensors to output an accurate 6-degree-of-freedom pose of a device, enabling Visual-Inertial SLAM for tracking robots and vehicles, as well as Augmented, Mixed, and Virtual Reality. The SDK includes a Mapping API for real-time and offline 3D reconstruction use cases.
QuestCameraKit
QuestCameraKit is a collection of template and reference projects demonstrating how to use Meta Quest’s new Passthrough Camera API (PCA) for advanced AR/VR vision, tracking, and shader effects. It includes samples like Color Picker, Object Detection with Unity Sentis, QR Code Tracking with ZXing, Frosted Glass Shader, OpenAI vision model, and WebRTC video streaming. The repository provides detailed instructions on how to run each sample and troubleshoot known issues. Users can explore various functionalities such as converting 3D points to 2D image pixels, detecting objects, tracking QR codes, applying custom shader effects, interacting with OpenAI's vision model, and streaming camera feed over WebRTC.
DriveLM
DriveLM is a multimodal AI model that enables autonomous driving by combining computer vision and natural language processing. It is designed to understand and respond to complex driving scenarios using visual and textual information. DriveLM can perform various tasks related to driving, such as object detection, lane keeping, and decision-making. It is trained on a massive dataset of images and text, which allows it to learn the relationships between visual cues and driving actions. DriveLM is a powerful tool that can help to improve the safety and efficiency of autonomous vehicles.
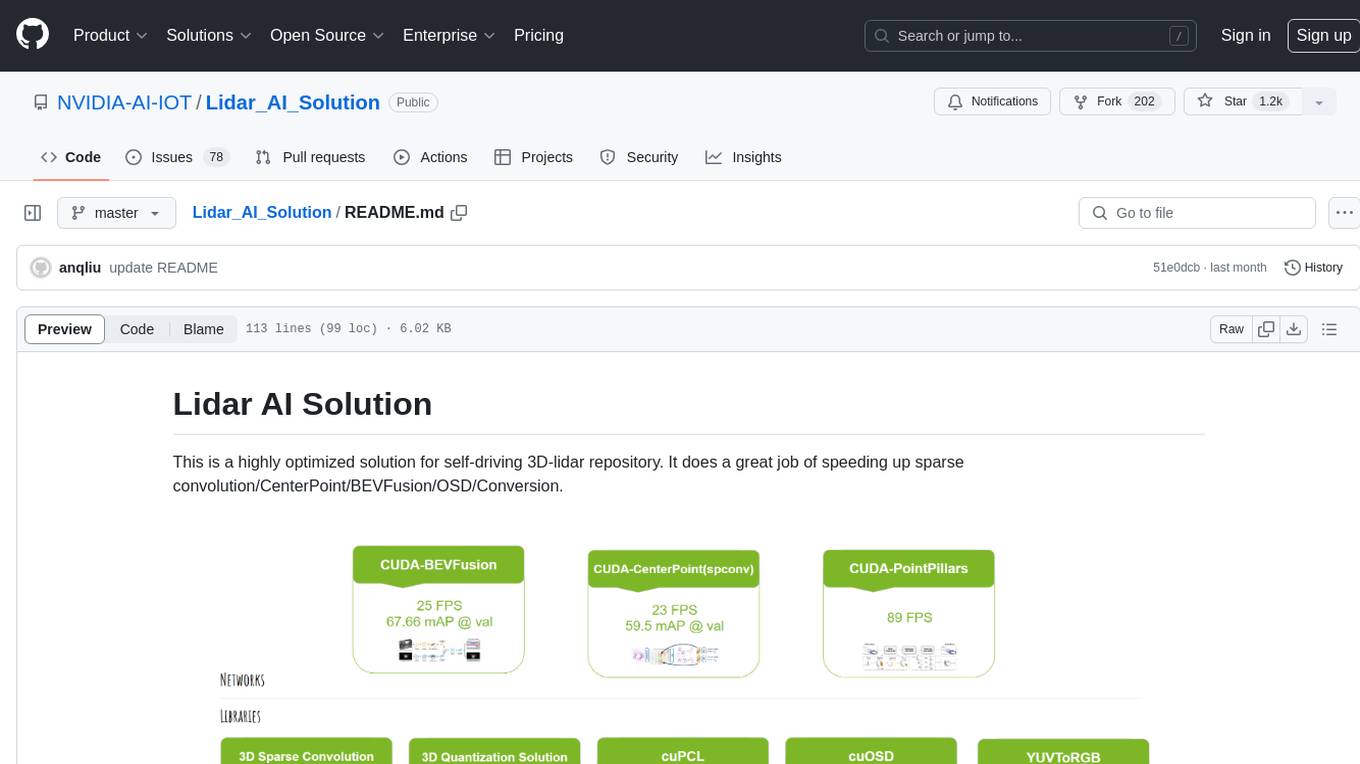
Lidar_AI_Solution
Lidar AI Solution is a highly optimized repository for self-driving 3D lidar, providing solutions for sparse convolution, BEVFusion, CenterPoint, OSD, and Conversion. It includes CUDA and TensorRT implementations for various tasks such as 3D sparse convolution, BEVFusion, CenterPoint, PointPillars, V2XFusion, cuOSD, cuPCL, and YUV to RGB conversion. The repository offers easy-to-use solutions, high accuracy, low memory usage, and quantization options for different tasks related to self-driving technology.
AirSLAM
AirSLAM is an efficient visual SLAM system designed to tackle short-term and long-term illumination challenges. It combines deep learning techniques with traditional optimization methods, featuring a unified CNN for keypoint and structural line extraction. The system includes a relocalization pipeline for map reuse, accelerated using C++ and NVIDIA TensorRT. Outperforming other SLAM systems in challenging environments, it runs at 73Hz on PC and 40Hz on embedded platforms.

awesome-and-novel-works-in-slam
This repository contains a curated list of cutting-edge works in Simultaneous Localization and Mapping (SLAM). It includes research papers, projects, and tools related to various aspects of SLAM, such as 3D reconstruction, semantic mapping, novel algorithms, large-scale mapping, and more. The repository aims to showcase the latest advancements in SLAM technology and provide resources for researchers and practitioners in the field.
retinify
Retinify is an advanced AI-powered stereo vision library designed for robotics, enabling real-time, high-precision 3D perception by leveraging GPU and NPU acceleration. It is open source under Apache-2.0 license, offers high precision 3D mapping and object recognition, runs computations on GPU for fast performance, accepts stereo images from any rectified camera setup, is cost-efficient using minimal hardware, and has minimal dependencies on CUDA Toolkit, cuDNN, and TensorRT. The tool provides a pipeline for stereo matching and supports various image data types independently of OpenCV.
Autopilot-Notes
Autopilot Notes is an open-source knowledge base for systematically learning autonomous driving technology. It covers basic theory, hardware, algorithms, tools, and practical engineering practices across 10+ chapters. The repository provides daily updates on industry trends, in-depth analysis of mainstream solutions like Tesla, Baidu Apollo, and Openpilot, and hands-on content including simulation, deployment, and optimization. Contributors are welcome to submit pull requests to improve the documentation.