
Open-Reasoning-Tasks
A comprehensive repository of reasoning tasks for LLMs (and beyond)
Stars: 205
The Open-Reasoning-Tasks repository is a collaborative project aimed at creating a comprehensive list of reasoning tasks for training large language models (LLMs). Contributors can submit tasks with descriptions, examples, and optional diagrams to enhance LLMs' reasoning capabilities.
README:
Welcome to the LLM Reasoning Task Collection repository! This project is an open collaboration to create a comprehensive master list of reasoning tasks that can teach, elicit, or show reasoning samples to large language models (LLMs) for training purposes.
The goal of this repository is to gather a diverse set of reasoning tasks designed to improve the reasoning capabilities of LLMs. Contributors are encouraged to submit tasks, provide examples, and optionally include diagrams or workflows to illustrate how the tasks function.
You can access the main tasks list table by clicking here (or open tasks.md file in the top level directory)
You can access the full table of reasoning tasks from our quarto based website by clicking here.
Coming Soon
Coming Soon
Coming Soon
We welcome contributions from everyone! To contribute, please see our Contribution Guide.
This project is licensed under the Apache 2.0 License. See the LICENSE file for details.
@misc{nousresearch2024,
title = {Open Reasoning Tasks: LLM Reasoning Tasks Collection},
author = {Nous Research},
url = {https://github.com/NousResearch/Open-Reasoning-Tasks},
year = {2024},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Open-Reasoning-Tasks
Similar Open Source Tools
Open-Reasoning-Tasks
The Open-Reasoning-Tasks repository is a collaborative project aimed at creating a comprehensive list of reasoning tasks for training large language models (LLMs). Contributors can submit tasks with descriptions, examples, and optional diagrams to enhance LLMs' reasoning capabilities.
reasoning-from-scratch
This repository contains the code for developing a large language model (LLM) reasoning model. The book 'Build a Reasoning Model (From Scratch)' provides a hands-on approach to understanding and implementing reasoning capabilities in LLMs. It guides users through creating a small but functional reasoning model, mirroring approaches used in large-scale models like DeepSeek R1 and GPT-5 Thinking. The code includes methods for loading weights of pretrained models.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.

fenic
fenic is an opinionated DataFrame framework from typedef.ai for building AI and agentic applications. It transforms unstructured and structured data into insights using familiar DataFrame operations enhanced with semantic intelligence. With support for markdown, transcripts, and semantic operators, plus efficient batch inference across various model providers. fenic is purpose-built for LLM inference, providing a query engine designed for AI workloads, semantic operators as first-class citizens, native unstructured data support, production-ready infrastructure, and a familiar DataFrame API.

LightLLM
LightLLM is a lightweight library for linear and logistic regression models. It provides a simple and efficient way to train and deploy machine learning models for regression tasks. The library is designed to be easy to use and integrate into existing projects, making it suitable for both beginners and experienced data scientists. With LightLLM, users can quickly build and evaluate regression models using a variety of algorithms and hyperparameters. The library also supports feature engineering and model interpretation, allowing users to gain insights from their data and make informed decisions based on the model predictions.
RAGxplorer
RAGxplorer is a tool designed to build visualisations for Retrieval Augmented Generation (RAG). It provides functionalities to interact with RAG models, visualize queries, and explore information retrieval tasks. The tool aims to simplify the process of working with RAG models and enhance the understanding of retrieval and generation processes.
langchain-benchmarks
A package to help benchmark various LLM related tasks. The benchmarks are organized by end-to-end use cases, and utilize LangSmith heavily. We have several goals in open sourcing this: * Showing how we collect our benchmark datasets for each task * Showing what the benchmark datasets we use for each task is * Showing how we evaluate each task * Encouraging others to benchmark their solutions on these tasks (we are always looking for better ways of doing things!)
miyagi
Project Miyagi showcases Microsoft's Copilot Stack in an envisioning workshop aimed at designing, developing, and deploying enterprise-grade intelligent apps. By exploring both generative and traditional ML use cases, Miyagi offers an experiential approach to developing AI-infused product experiences that enhance productivity and enable hyper-personalization. Additionally, the workshop introduces traditional software engineers to emerging design patterns in prompt engineering, such as chain-of-thought and retrieval-augmentation, as well as to techniques like vectorization for long-term memory, fine-tuning of OSS models, agent-like orchestration, and plugins or tools for augmenting and grounding LLMs.
ScholarCopilot
Scholar Copilot is an intelligent academic writing assistant that enhances the research writing process through AI-powered text completion and citation suggestions. It aims to streamline academic writing while maintaining high scholarly standards. The tool provides features such as smart text generation with next-3-sentence suggestions, full section auto-completion, and context-aware writing. It also offers intelligent citation management with real-time citation suggestions, one-click citation insertion, and citation Bibtex generation. Scholar Copilot employs a unified model architecture that integrates retrieval and generation through a dynamic switching mechanism, ensuring coherent text generation with appropriate citation points.

babilong
BABILong is a generative benchmark designed to evaluate the performance of NLP models in processing long documents with distributed facts. It consists of 20 tasks that simulate interactions between characters and objects in various locations, requiring models to distinguish important information from irrelevant details. The tasks vary in complexity and reasoning aspects, with test samples potentially containing millions of tokens. The benchmark aims to challenge and assess the capabilities of Large Language Models (LLMs) in handling complex, long-context information.
robot-3dlotus
Towards Generalizable Vision-Language Robotic Manipulation: A Benchmark and LLM-guided 3D Policy is a research project focusing on addressing the challenge of generalizing language-conditioned robotic policies to new tasks. The project introduces GemBench, a benchmark to evaluate the generalization capabilities of vision-language robotic manipulation policies. It also presents the 3D-LOTUS approach, which leverages rich 3D information for action prediction conditioned on language. Additionally, the project introduces 3D-LOTUS++, a framework that integrates 3D-LOTUS's motion planning capabilities with the task planning capabilities of LLMs and the object grounding accuracy of VLMs to achieve state-of-the-art performance on novel tasks in robotic manipulation.
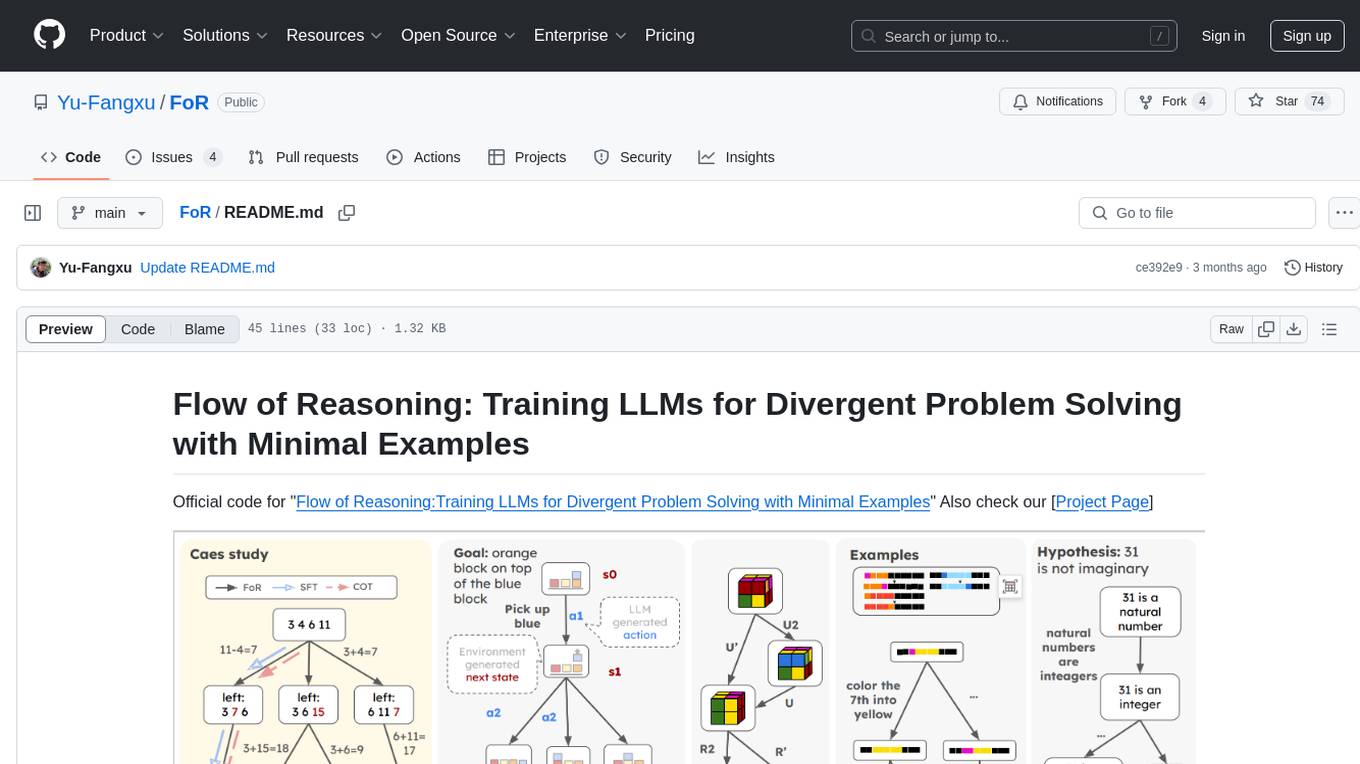
FoR
FoR is the official code repository for the 'Flow of Reasoning: Training LLMs for Divergent Problem Solving with Minimal Examples' project. It formulates multi-step reasoning tasks as a flow, involving designing reward functions, collecting trajectories, and training LLM policies with trajectory balance loss. The code provides tools for training and inference in a reproducible experiment environment using conda. Users can choose from 5 tasks to run, each with detailed instructions in the respective branches.
incubator-hugegraph-ai
hugegraph-ai aims to explore the integration of HugeGraph with artificial intelligence (AI) and provide comprehensive support for developers to leverage HugeGraph's AI capabilities in their projects. It includes modules for large language models, graph machine learning, and a Python client for HugeGraph. The project aims to address challenges like timeliness, hallucination, and cost-related issues by integrating graph systems with AI technologies.
refly
Refly.AI is an open-source AI-native creation engine that empowers users to transform ideas into production-ready content. It features a free-form canvas interface with multi-threaded conversations, knowledge base integration, contextual memory, intelligent search, WYSIWYG AI editor, and more. Users can leverage AI-powered capabilities, context memory, knowledge base integration, quotes, and AI document editing to enhance their content creation process. Refly offers both cloud and self-hosting options, making it suitable for individuals, enterprises, and organizations. The tool is designed to facilitate human-AI collaboration and streamline content creation workflows.

Macaw-LLM
Macaw-LLM is a pioneering multi-modal language modeling tool that seamlessly integrates image, audio, video, and text data. It builds upon CLIP, Whisper, and LLaMA models to process and analyze multi-modal information effectively. The tool boasts features like simple and fast alignment, one-stage instruction fine-tuning, and a new multi-modal instruction dataset. It enables users to align multi-modal features efficiently, encode instructions, and generate responses across different data types.
For similar tasks
Open-Reasoning-Tasks
The Open-Reasoning-Tasks repository is a collaborative project aimed at creating a comprehensive list of reasoning tasks for training large language models (LLMs). Contributors can submit tasks with descriptions, examples, and optional diagrams to enhance LLMs' reasoning capabilities.
Awesome-System2-Reasoning-LLM
The Awesome-System2-Reasoning-LLM repository is dedicated to a survey paper titled 'From System 1 to System 2: A Survey of Reasoning Large Language Models'. It explores the development of reasoning Large Language Models (LLMs), their foundational technologies, benchmarks, and future directions. The repository provides resources and updates related to the research, tracking the latest developments in the field of reasoning LLMs.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.