
TurtleBench
Benchmark for LLM Reasoning & Understanding with Challenging Tasks from Real Users.
Stars: 106
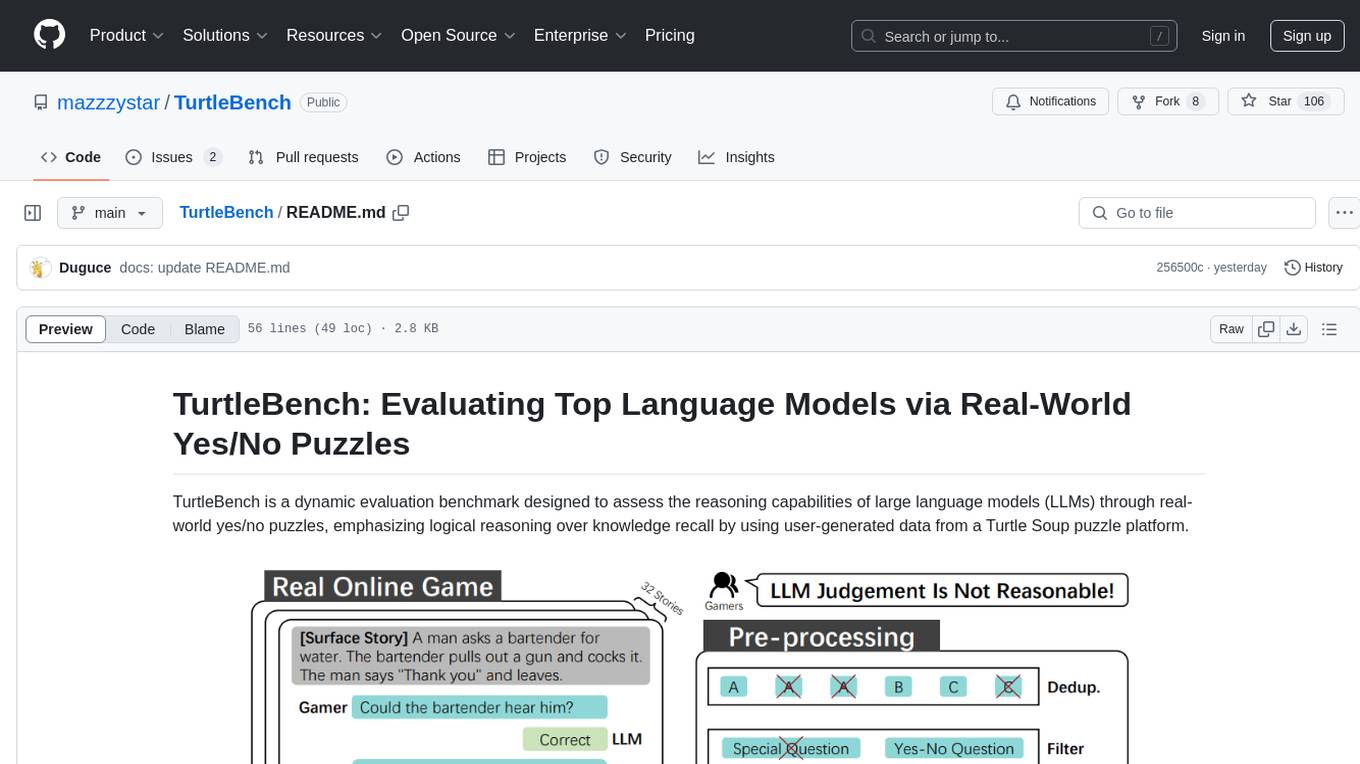
TurtleBench is a dynamic evaluation benchmark that assesses the reasoning capabilities of large language models through real-world yes/no puzzles. It emphasizes logical reasoning over knowledge recall by using user-generated data from a Turtle Soup puzzle platform. The benchmark is objective and unbiased, focusing purely on reasoning abilities and providing clear, measurable outcomes for easy comparison. TurtleBench constantly evolves with real user-generated questions, making it impossible to 'game' the system. It tests the model's ability to comprehend context and make logical inferences.
README:
TurtleBench is a dynamic evaluation benchmark designed to assess the reasoning capabilities of large language models (LLMs) through real-world yes/no puzzles, emphasizing logical reasoning over knowledge recall by using user-generated data from a Turtle Soup puzzle platform.

- Objective and Unbiased: Eliminates the need for background knowledge, focusing purely on reasoning abilities.
- Quantifiable Results: Clear, measurable outcomes (correct/incorrect/unknown) for easy comparison.
- Constantly Evolving: Uses real user-generated questions, making it impossible to "game" the system.
- Language Understanding: Tests the model's ability to comprehend context and make logical inferences.
# Install dependencies
conda create -n turtle python=3.10
conda activate turtle
pip install -r requirements.txt
# Set up configuration
mv config_example.ini config.ini
# Edit config.ini to add your API key
# Run evaluations
python eval.py --shot 0 --models Claude_3_5_Sonnet --language zh --save_interval 10 --time_delay 2
# Analyze results
python analyst.py
.
├── README.md # Project description and documentation
├── analyst.py # Data analysis script
├── archived # Archived result files
├── config.ini # Configuration file (for actual run)
├── config_example.ini # Example configuration file
├── data # Directory containing project data
│ ├── en # Subdirectory for English data
│ └── zh # Subdirectory for Chinese data
├── eval.py # Evaluation script
├── insights # Analysis and visualization-related scripts
│ ├── case_handler.py # OpenAI o1 Error case handling script
│ ├── plots.ipynb # Data visualization and plot generation
│ ├── token_boxplot.py # Box plot for token usage
│ └── token_cal.py # Token calculation script
├── logs # Directory for storing logs
├── models.py # Model definition script
├── outputs # Directory for storing output results
├── prompts # Files related to prompt generation
├── requirements.txt # Project dependencies list
└── stats # Statistics and result-related files
Note: You can find detailed experiment results in the archived directory.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for TurtleBench
Similar Open Source Tools
TurtleBench
TurtleBench is a dynamic evaluation benchmark that assesses the reasoning capabilities of large language models through real-world yes/no puzzles. It emphasizes logical reasoning over knowledge recall by using user-generated data from a Turtle Soup puzzle platform. The benchmark is objective and unbiased, focusing purely on reasoning abilities and providing clear, measurable outcomes for easy comparison. TurtleBench constantly evolves with real user-generated questions, making it impossible to 'game' the system. It tests the model's ability to comprehend context and make logical inferences.

NeMo-Curator
NeMo Curator is a GPU-accelerated open-source framework designed for efficient large language model data curation. It provides scalable dataset preparation for tasks like foundation model pretraining, domain-adaptive pretraining, supervised fine-tuning, and parameter-efficient fine-tuning. The library leverages GPUs with Dask and RAPIDS to accelerate data curation, offering customizable and modular interfaces for pipeline expansion and model convergence. Key features include data download, text extraction, quality filtering, deduplication, downstream-task decontamination, distributed data classification, and PII redaction. NeMo Curator is suitable for curating high-quality datasets for large language model training.

raga-llm-hub
Raga LLM Hub is a comprehensive evaluation toolkit for Language and Learning Models (LLMs) with over 100 meticulously designed metrics. It allows developers and organizations to evaluate and compare LLMs effectively, establishing guardrails for LLMs and Retrieval Augmented Generation (RAG) applications. The platform assesses aspects like Relevance & Understanding, Content Quality, Hallucination, Safety & Bias, Context Relevance, Guardrails, and Vulnerability scanning, along with Metric-Based Tests for quantitative analysis. It helps teams identify and fix issues throughout the LLM lifecycle, revolutionizing reliability and trustworthiness.
samples
Strands Agents Samples is a repository showcasing easy-to-use examples for building AI agents using a model-driven approach. The examples provided are for demonstration and educational purposes only, not intended for direct production use. Users can explore various samples to understand concepts and techniques, ensuring proper security and testing procedures before implementation.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.
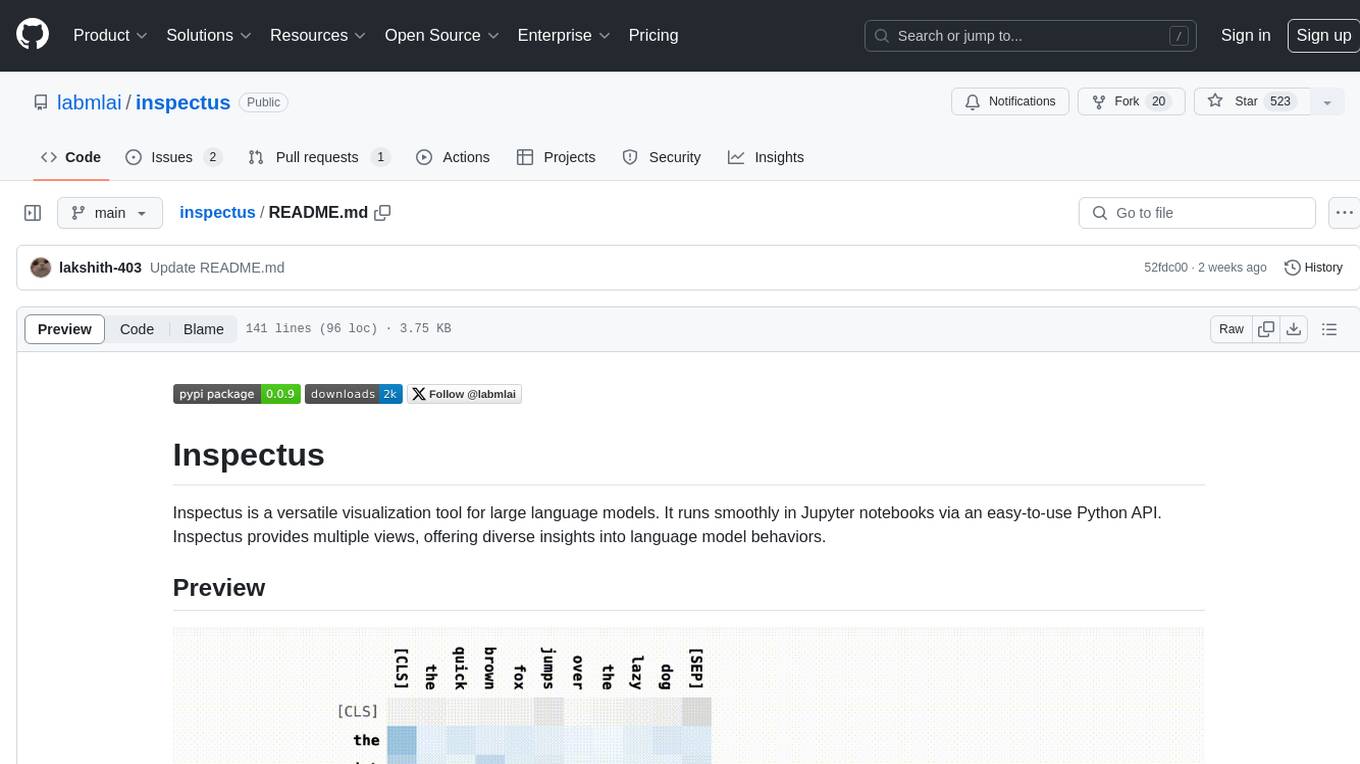
inspectus
Inspectus is a versatile visualization tool for large language models. It provides multiple views, including Attention Matrix, Query Token Heatmap, Key Token Heatmap, and Dimension Heatmap, to offer insights into language model behaviors. Users can interact with the tool in Jupyter notebooks through an easy-to-use Python API. Inspectus allows users to visualize attention scores between tokens, analyze how tokens focus on each other during processing, and explore the relationships between query and key tokens. The tool supports the visualization of attention maps from Huggingface transformers and custom attention maps, making it a valuable resource for researchers and developers working with language models.
SiLLM
SiLLM is a toolkit that simplifies the process of training and running Large Language Models (LLMs) on Apple Silicon by leveraging the MLX framework. It provides features such as LLM loading, LoRA training, DPO training, a web app for a seamless chat experience, an API server with OpenAI compatible chat endpoints, and command-line interface (CLI) scripts for chat, server, LoRA fine-tuning, DPO fine-tuning, conversion, and quantization.

TokenFormer
TokenFormer is a fully attention-based neural network architecture that leverages tokenized model parameters to enhance architectural flexibility. It aims to maximize the flexibility of neural networks by unifying token-token and token-parameter interactions through the attention mechanism. The architecture allows for incremental model scaling and has shown promising results in language modeling and visual modeling tasks. The codebase is clean, concise, easily readable, state-of-the-art, and relies on minimal dependencies.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.

OpenAdapt
OpenAdapt is an open-source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs). It aims to automate repetitive GUI workflows by leveraging the power of LMMs. OpenAdapt records user input and screenshots, converts them into tokenized format, and generates synthetic input via transformer model completions. It also analyzes recordings to generate task trees and replay synthetic input to complete tasks. OpenAdapt is model agnostic and generates prompts automatically by learning from human demonstration, ensuring that agents are grounded in existing processes and mitigating hallucinations. It works with all types of desktop GUIs, including virtualized and web, and is open source under the MIT license.
vts
VTS (Vector Transport Service) is an open-source tool developed by Zilliz based on Apache Seatunnel for moving vectors and unstructured data. It addresses data migration needs, supports real-time data streaming and offline import, simplifies unstructured data transformation, and ensures end-to-end data quality. Core capabilities include rich connectors, stream and batch processing, distributed snapshot support, high performance, and real-time monitoring. Future developments include incremental synchronization, advanced data transformation, and enhanced monitoring. VTS supports various connectors for data migration and offers advanced features like Transformers, cluster mode deployment, RESTful API, Docker deployment, and more.
gemma
Gemma is a family of open-weights Large Language Model (LLM) by Google DeepMind, based on Gemini research and technology. This repository contains an inference implementation and examples, based on the Flax and JAX frameworks. Gemma can run on CPU, GPU, and TPU, with model checkpoints available for download. It provides tutorials, reference implementations, and Colab notebooks for tasks like sampling and fine-tuning. Users can contribute to Gemma through bug reports and pull requests. The code is licensed under the Apache License, Version 2.0.
adk-java
Agent Development Kit (ADK) for Java is an open-source toolkit designed for developers to build, evaluate, and deploy sophisticated AI agents with flexibility and control. It allows defining agent behavior, orchestration, and tool use directly in code, enabling robust debugging, versioning, and deployment anywhere. The toolkit offers a rich tool ecosystem, code-first development approach, and support for modular multi-agent systems, making it ideal for creating advanced AI agents integrated with Google Cloud services.
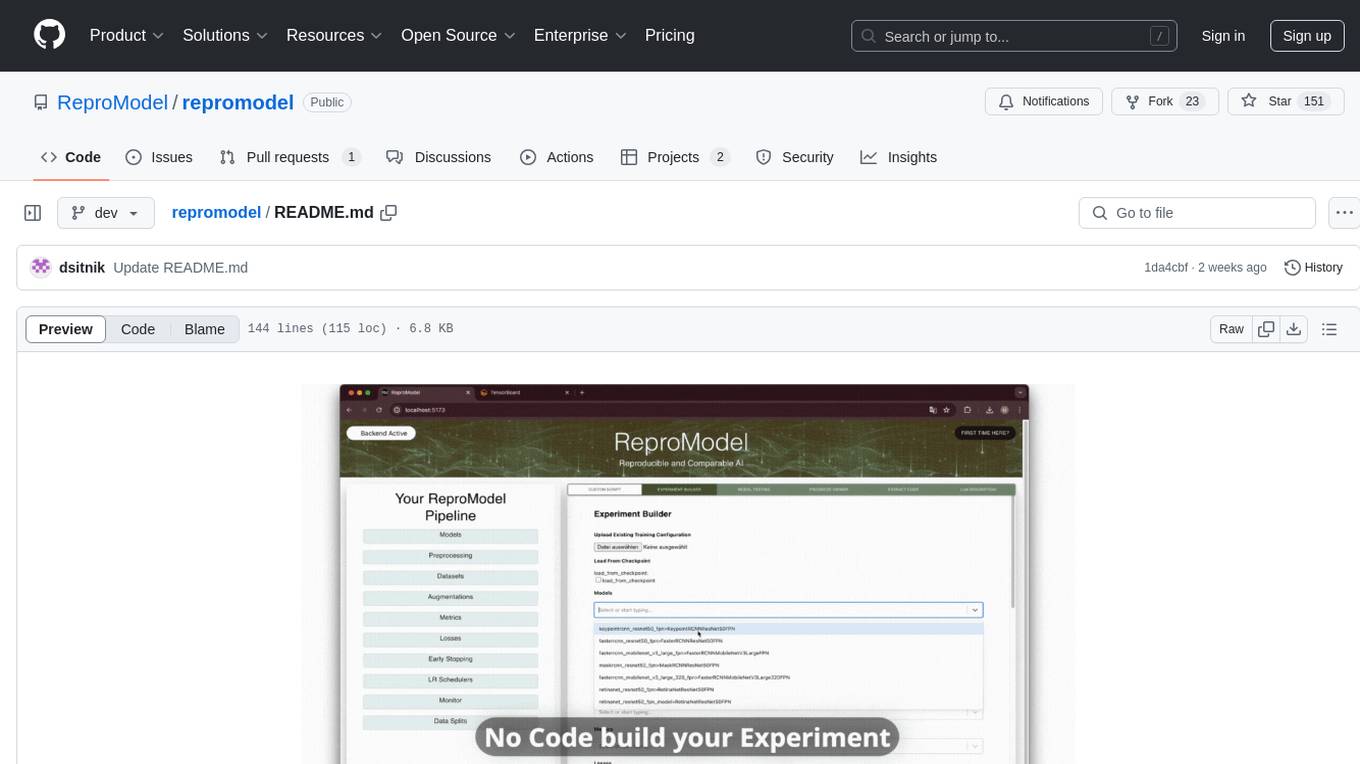
repromodel
ReproModel is an open-source toolbox designed to boost AI research efficiency by enabling researchers to reproduce, compare, train, and test AI models faster. It provides standardized models, dataloaders, and processing procedures, allowing researchers to focus on new datasets and model development. With a no-code solution, users can access benchmark and SOTA models and datasets, utilize training visualizations, extract code for publication, and leverage an LLM-powered automated methodology description writer. The toolbox helps researchers modularize development, compare pipeline performance reproducibly, and reduce time for model development, computation, and writing. Future versions aim to facilitate building upon state-of-the-art research by loading previously published study IDs with verified code, experiments, and results stored in the system.

labo
LABO is a time series forecasting and analysis framework that integrates pre-trained and fine-tuned LLMs with multi-domain agent-based systems. It allows users to create and tune agents easily for various scenarios, such as stock market trend prediction and web public opinion analysis. LABO requires a specific runtime environment setup, including system requirements, Python environment, dependency installations, and configurations. Users can fine-tune their own models using LABO's Low-Rank Adaptation (LoRA) for computational efficiency and continuous model updates. Additionally, LABO provides a Python library for building model training pipelines and customizing agents for specific tasks.
Linly-Talker
Linly-Talker is an innovative digital human conversation system that integrates the latest artificial intelligence technologies, including Large Language Models (LLM) 🤖, Automatic Speech Recognition (ASR) 🎙️, Text-to-Speech (TTS) 🗣️, and voice cloning technology 🎤. This system offers an interactive web interface through the Gradio platform 🌐, allowing users to upload images 📷 and engage in personalized dialogues with AI 💬.
For similar tasks
TurtleBench
TurtleBench is a dynamic evaluation benchmark that assesses the reasoning capabilities of large language models through real-world yes/no puzzles. It emphasizes logical reasoning over knowledge recall by using user-generated data from a Turtle Soup puzzle platform. The benchmark is objective and unbiased, focusing purely on reasoning abilities and providing clear, measurable outcomes for easy comparison. TurtleBench constantly evolves with real user-generated questions, making it impossible to 'game' the system. It tests the model's ability to comprehend context and make logical inferences.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.

promptfoo
Promptfoo is a tool for testing and evaluating LLM output quality. With promptfoo, you can build reliable prompts, models, and RAGs with benchmarks specific to your use-case, speed up evaluations with caching, concurrency, and live reloading, score outputs automatically by defining metrics, use as a CLI, library, or in CI/CD, and use OpenAI, Anthropic, Azure, Google, HuggingFace, open-source models like Llama, or integrate custom API providers for any LLM API.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

flower
Flower is a framework for building federated learning systems. It is designed to be customizable, extensible, framework-agnostic, and understandable. Flower can be used with any machine learning framework, for example, PyTorch, TensorFlow, Hugging Face Transformers, PyTorch Lightning, scikit-learn, JAX, TFLite, MONAI, fastai, MLX, XGBoost, Pandas for federated analytics, or even raw NumPy for users who enjoy computing gradients by hand.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.