
LinguaHaru
Next-Gen AI Translation Tool Powered by LLM. Support Office documents, PDF, TXT, and more format with just one click.
Stars: 93

Next-generation AI translation tool that provides high-quality, precise translations for various common file formats with a single click. It is based on cutting-edge large language models, offering exceptional translation quality with minimal operation, supporting multiple document formats and languages. Features include multi-format compatibility, global language translation, one-click rapid translation, flexible translation engines, and LAN sharing for efficient collaborative work.
README:



Next-generation AI translation tool that provides high-quality, precise translations for various common file formats with a single click
📄 DOCX • 📊 XLSX • 📑 PPTX • 📰 PDF • 📝 TXT • 🎬 SRT
It provides the following features:
- Multi-format compatibility: Perfect support for common file formats including .docx, .pptx, .xlsx, .pdf, .txt, .srt, with more document types to be expanded in the future.
- Global language translation: Covers 10+ languages including Chinese/English/Japanese/Korean/Russian, continuously expanding to meet globalization needs.
- One-click rapid translation: No complicated operations needed, just upload a file and click translate to instantly generate accurate translations.
- Flexible translation engines: Freely switch between local models (Ollama) and online APIs (Deepseek/OpenAI, etc.), adapting to different usage environments at any time.
- LAN sharing: One host computer can easily be used by all devices on the local network, enabling efficient collaborative work.
-
CUDA
You need to install CUDA (currently 11.7 and 12.1 have been tested without issues) -
Python (python==3.10)
It is recommended to use Conda to create a virtual environmentconda create -n lingua-haru python=3.10 conda activate lingua-haru
-
Install dependencies
- Dependency packages
pip install -r requirements.txt
- Model download After downloading, please save in the "models" folder
- Dependency packages
-
Run the tool
python app.py
Default access address is
http://127.0.0.1:9980
-
Local large language model support
Currently only supports Ollama
You need to download Ollama dependencies and models for translation- Download model (QWen series models recommended)
ollama pull qwen2.5
- Download model (QWen series models recommended)



- Add continue translation functionality.
- 2025/04/02
Updated to v2.3, adding custom icons/Title and supporting multi-task queues. Optimized translation result detection logic. Added a feature to show the translation result with the original text. - 2025/03/14 Updated to V2.0, added support for Txt files. Optimized Word/Excel/long text translation. Added customizable retry count functionality. Improved display of translation results.
- 2025/02/01
Updated the processing logic for failed translations. - 2025/01/15
Fixed a bug in PDF translation, added multilingual support, and petted the kitty. - 2025/01/11
Added support for PDF. Reference project: PDFMathTranslate - 2025/01/10
Added support for deepseek-v3. Now you can use API for translation (more stable).
Get API: https://www.deepseek.com/ - 2025/01/03
Happy New Year! Revised logic, added review functionality, and enhanced logging.
The software code is completely open source and can be freely used under the GPL-3.0 license.
This software only provides AI translation services, and any content translated using this software is not related to its creator.
Users should comply with the law and engage in legal translation activities.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LinguaHaru
Similar Open Source Tools
LinguaHaru
Next-generation AI translation tool that provides high-quality, precise translations for various common file formats with a single click. It is based on cutting-edge large language models, offering exceptional translation quality with minimal operation, supporting multiple document formats and languages. Features include multi-format compatibility, global language translation, one-click rapid translation, flexible translation engines, and LAN sharing for efficient collaborative work.

TeroSubtitler
Tero Subtitler is an open source, cross-platform, and free subtitle editing software with a user-friendly interface. It offers fully fledged editing with SMPTE and MEDIA modes, support for various subtitle formats, multi-level undo/redo, search and replace, auto-backup, source and transcription modes, translation memory, audiovisual preview, timeline with waveform visualizer, manipulation tools, formatting options, quality control features, translation and transcription capabilities, validation tools, automation for correcting errors, and more. It also includes features like exporting subtitles to MP3, importing/exporting Blu-ray SUP format, generating blank video, generating video with hardcoded subtitles, video dubbing, and more. The tool utilizes powerful multimedia playback engines like mpv, advanced audio/video manipulation tools like FFmpeg, tools for automatic transcription like whisper.cpp/Faster-Whisper, auto-translation API like Google Translate, and ElevenLabs TTS for video dubbing.
extractous
Extractous offers a fast and efficient solution for extracting content and metadata from various document types such as PDF, Word, HTML, and many other formats. It is built with Rust, providing high performance, memory safety, and multi-threading capabilities. The tool eliminates the need for external services or APIs, making data processing pipelines faster and more efficient. It supports multiple file formats, including Microsoft Office, OpenOffice, PDF, spreadsheets, web documents, e-books, text files, images, and email formats. Extractous provides a clear and simple API for extracting text and metadata content, with upcoming support for JavaScript/TypeScript. It is free for commercial use under the Apache 2.0 License.
SLAM-LLM
SLAM-LLM is a deep learning toolkit designed for researchers and developers to train custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). SLAM-LLM features easy extension to new models and tasks, mixed precision training for faster training with less GPU memory, multi-GPU training with data and model parallelism, and flexible configuration based on Hydra and dataclass.
Srt-AI-Voice-Assistant
Srt-AI-Voice-Assistant is a convenient tool that generates audio from uploaded .srt subtitle files by calling APIs such as Bert-VITS2 (HiyoriUI), GPT-SoVITS, and Microsoft TTS (online). The code is currently not perfect, and feedback on bugs or suggestions can be provided at https://github.com/YYuX-1145/Srt-AI-Voice-Assistant/issues. Recent updates include adding custom API functionality with a focus on security, support for Microsoft online TTS (requires key configuration), error handling improvements, automatic project path detection, compatibility with API-v1 for limited functionality, and significant feature updates supporting card synthesis.

qrbtf
QRBTF is the world's first and best AI & parametric QR code generator developed by Latent Cat. It features original AI models trained on a large number of images for fast and high-quality inference. The parametric part is open source, offering various styles without requiring a backend. Users can create beautiful QR codes by entering a URL or text, selecting a style, adjusting parameters, and downloading in SVG or JPG format. The website supports English and Chinese, with contributions for i18n in other languages welcome. QRBTF also provides a React component for integration into projects.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.
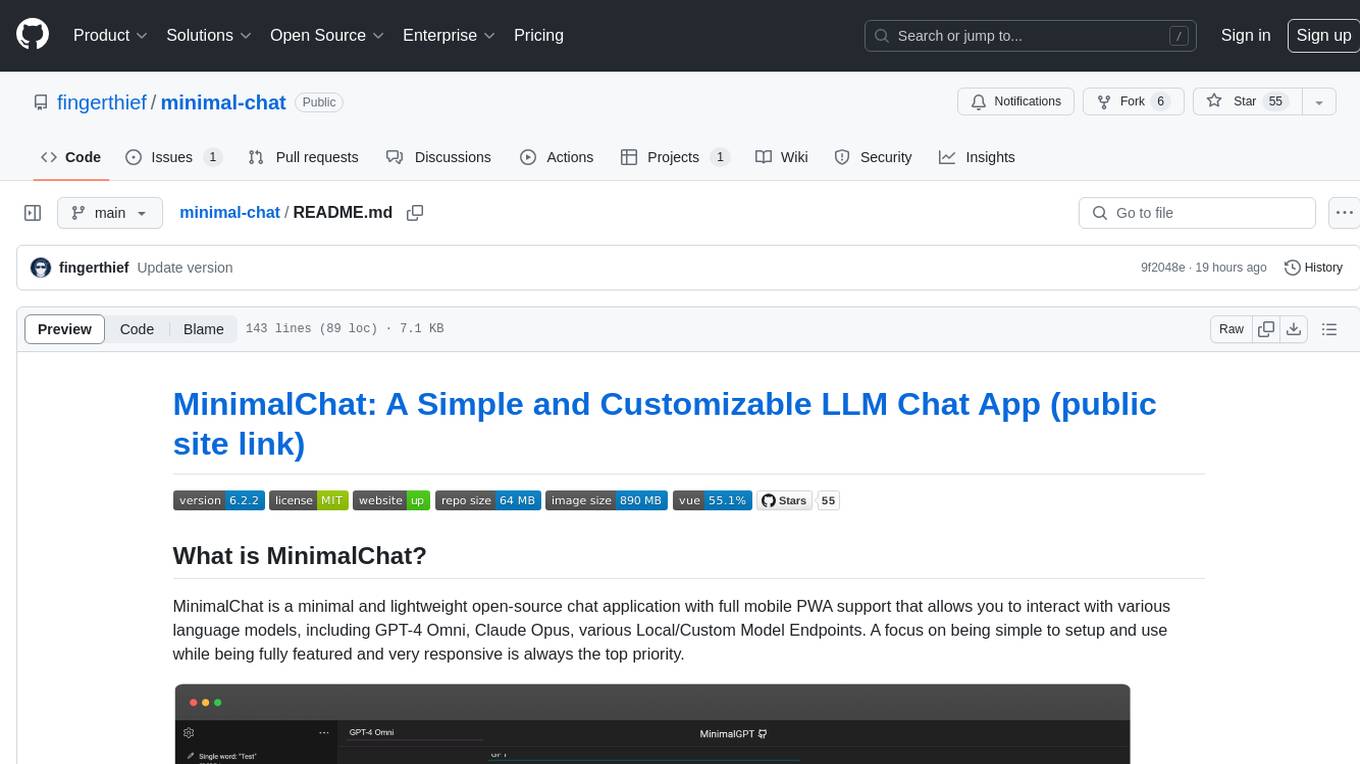
minimal-chat
MinimalChat is a minimal and lightweight open-source chat application with full mobile PWA support that allows users to interact with various language models, including GPT-4 Omni, Claude Opus, and various Local/Custom Model Endpoints. It focuses on simplicity in setup and usage while being fully featured and highly responsive. The application supports features like fully voiced conversational interactions, multiple language models, markdown support, code syntax highlighting, DALL-E 3 integration, conversation importing/exporting, and responsive layout for mobile use.

swark
Swark is a VS Code extension that automatically generates architecture diagrams from code using large language models (LLMs). It is directly integrated with GitHub Copilot, requires no authentication or API key, and supports all languages. Swark helps users learn new codebases, review AI-generated code, improve documentation, understand legacy code, spot design flaws, and gain test coverage insights. It saves output in a 'swark-output' folder with diagram and log files. Source code is only shared with GitHub Copilot for privacy. The extension settings allow customization for file reading, file extensions, exclusion patterns, and language model selection. Swark is open source under the GNU Affero General Public License v3.0.

gptme
Personal AI assistant/agent in your terminal, with tools for using the terminal, running code, editing files, browsing the web, using vision, and more. A great coding agent that is general-purpose to assist in all kinds of knowledge work, from a simple but powerful CLI. An unconstrained local alternative to ChatGPT with 'Code Interpreter', Cursor Agent, etc. Not limited by lack of software, internet access, timeouts, or privacy concerns if using local models.
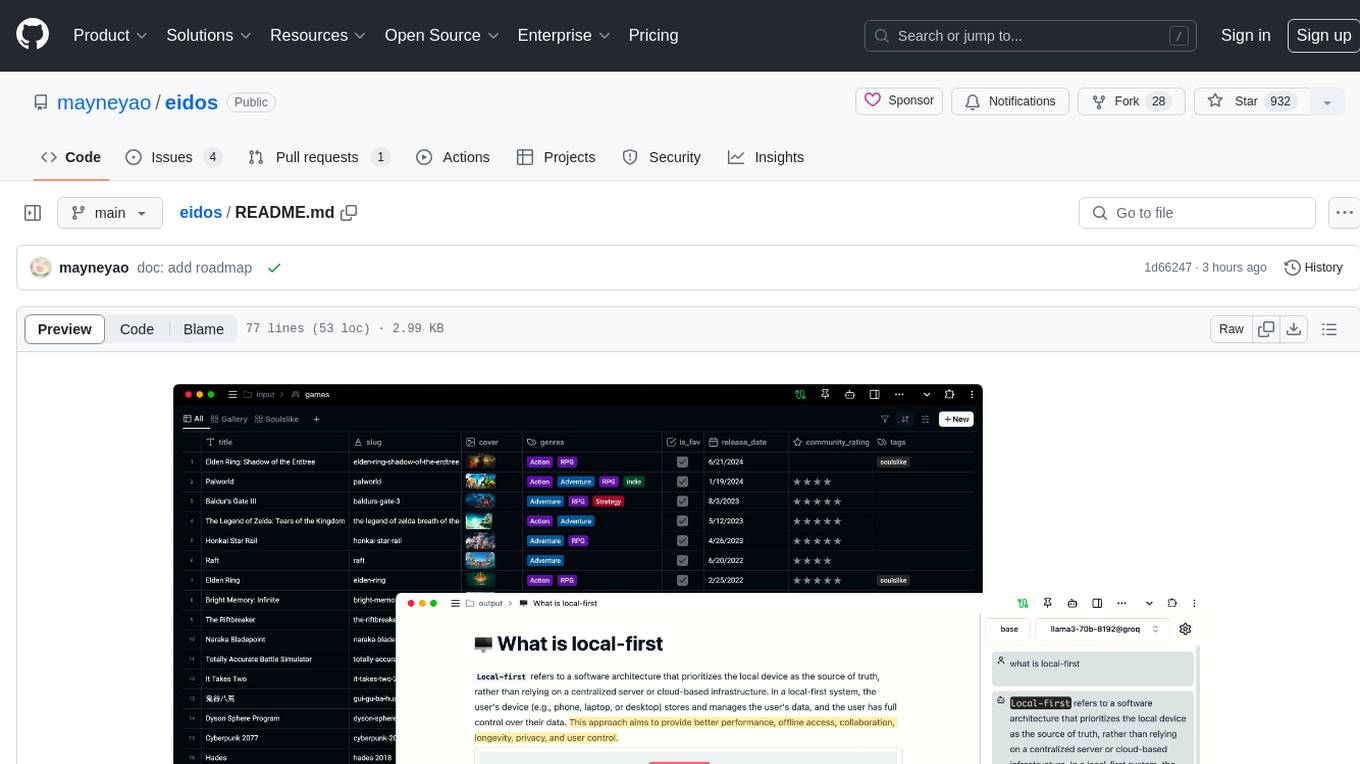
eidos
Eidos is an extensible framework for managing personal data in one place. It runs inside the browser as a PWA with offline support. It integrates AI features for translation, summarization, and data interaction. Users can customize Eidos with Prompt extension, JavaScript for Formula functions, TypeScript/JavaScript for data processing logic, and build apps using any framework. Eidos is developer-friendly with API & SDK, and uses SQLite standardization for data tables.

Revornix
Revornix is an information management tool designed for the AI era. It allows users to conveniently integrate all visible information and generates comprehensive reports at specific times. The tool offers cross-platform availability, all-in-one content aggregation, document transformation & vectorized storage, native multi-tenancy, localization & open-source features, smart assistant & built-in MCP, seamless LLM integration, and multilingual & responsive experience for users.
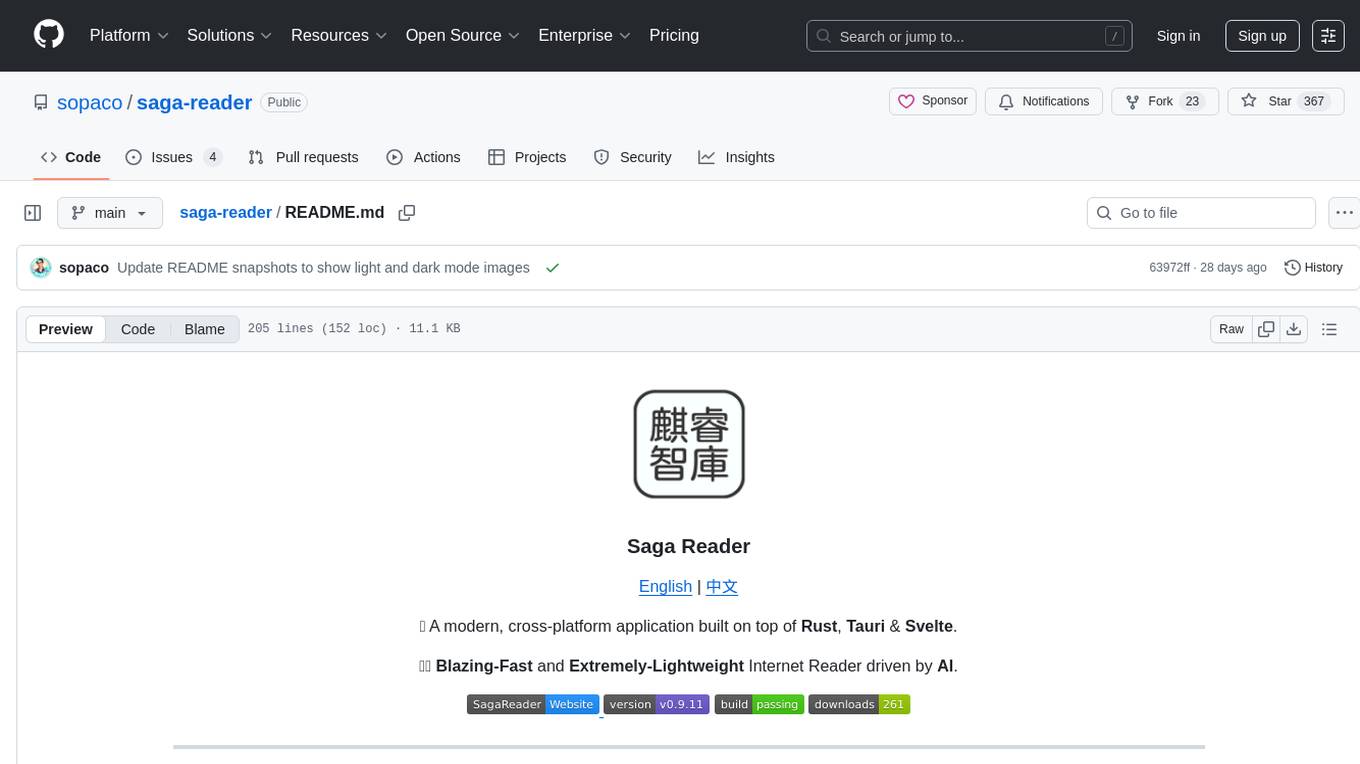
saga-reader
Saga Reader is an AI-driven think tank-style reader that automatically retrieves information from the internet based on user-specified topics and preferences. It uses cloud or local large models to summarize and provide guidance, and it includes an AI-driven interactive companion reading function, allowing you to discuss and exchange ideas with AI about the content you've read. Saga Reader is completely free and open-source, meaning all data is securely stored on your own computer and is not controlled by third-party service providers. Additionally, you can manage your subscription keywords based on your interests and preferences without being disturbed by advertisements and commercialized content.
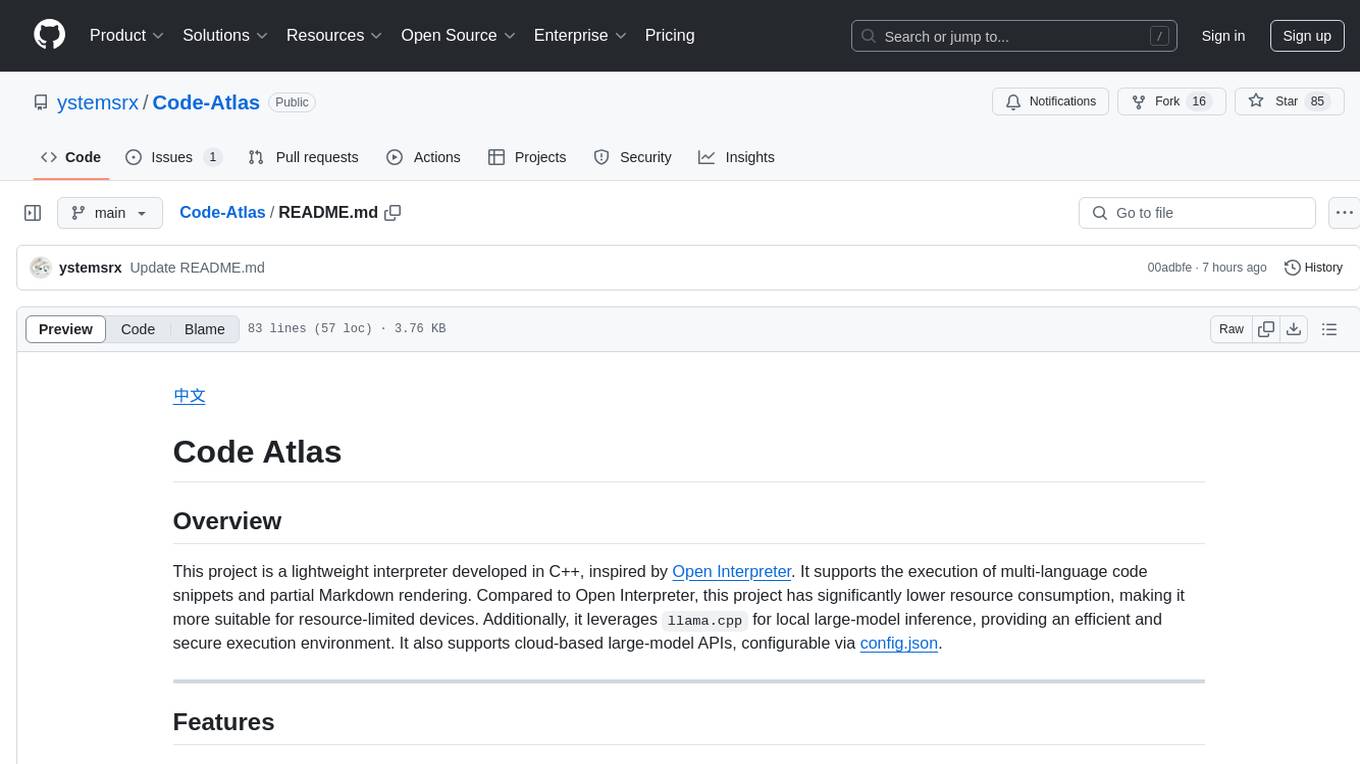
Code-Atlas
Code Atlas is a lightweight interpreter developed in C++ that supports the execution of multi-language code snippets and partial Markdown rendering. It consumes significantly lower resources compared to similar tools, making it suitable for resource-limited devices. It leverages llama.cpp for local large-model inference and supports cloud-based large-model APIs. The tool provides features for code execution, Markdown rendering, local AI inference, and resource efficiency.
LLM-Zero-to-Hundred
LLM-Zero-to-Hundred is a repository showcasing various applications of LLM chatbots and providing insights into training and fine-tuning Language Models. It includes projects like WebGPT, RAG-GPT, WebRAGQuery, LLM Full Finetuning, RAG-Master LLamaindex vs Langchain, open-source-RAG-GEMMA, and HUMAIN: Advanced Multimodal, Multitask Chatbot. The projects cover features like ChatGPT-like interaction, RAG capabilities, image generation and understanding, DuckDuckGo integration, summarization, text and voice interaction, and memory access. Tutorials include LLM Function Calling and Visualizing Text Vectorization. The projects have a general structure with folders for README, HELPER, .env, configs, data, src, images, and utils.
yn
Yank Note is a highly extensible Markdown editor designed for productivity. It offers features like easy-to-use interface, powerful support for version control and various embedded content, high compatibility with local Markdown files, plug-in extension support, and encryption for saving private files. Users can write their own plug-ins to expand the editor's functionality. However, for more extendability, security protection is sacrificed. The tool supports sync scrolling, outline navigation, version control, encryption, auto-save, editing assistance, image pasting, attachment embedding, code running, to-do list management, quick file opening, integrated terminal, Katex expression, GitHub-style Markdown, multiple data locations, external link conversion, HTML resolving, multiple formats export, TOC generation, table cell editing, title link copying, embedded applets, various graphics embedding, mind map display, custom container support, macro replacement, image hosting service, OpenAI auto completion, and custom plug-ins development.
For similar tasks
LinguaHaru
Next-generation AI translation tool that provides high-quality, precise translations for various common file formats with a single click. It is based on cutting-edge large language models, offering exceptional translation quality with minimal operation, supporting multiple document formats and languages. Features include multi-format compatibility, global language translation, one-click rapid translation, flexible translation engines, and LAN sharing for efficient collaborative work.

lingo.dev
Replexica AI automates software localization end-to-end, producing authentic translations instantly across 60+ languages. Teams can do localization 100x faster with state-of-the-art quality, reaching more paying customers worldwide. The tool offers a GitHub Action for CI/CD automation and supports various formats like JSON, YAML, CSV, and Markdown. With lightning-fast AI localization, auto-updates, native quality translations, developer-friendly CLI, and scalability for startups and enterprise teams, Replexica is a top choice for efficient and effective software localization.

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.
dodari
Dodari is a local web service that makes NHNDQ AI Korean-English/English-Korean translation easy for everyday people to use (based on Gradio).

vector-vein
VectorVein is a no-code AI workflow software inspired by LangChain and langflow, aiming to combine the powerful capabilities of large language models and enable users to achieve intelligent and automated daily workflows through simple drag-and-drop actions. Users can create powerful workflows without the need for programming, automating all tasks with ease. The software allows users to define inputs, outputs, and processing methods to create customized workflow processes for various tasks such as translation, mind mapping, summarizing web articles, and automatic categorization of customer reviews.
project-lakechain
Project Lakechain is a cloud-native, AI-powered framework for building document processing pipelines on AWS. It provides a composable API with built-in middlewares for common tasks, scalable architecture, cost efficiency, GPU and CPU support, and the ability to create custom transform middlewares. With ready-made examples and emphasis on modularity, Lakechain simplifies the deployment of scalable document pipelines for tasks like metadata extraction, NLP analysis, text summarization, translations, audio transcriptions, computer vision, and more.
ezwork-ai-doc-translation
EZ-Work AI Document Translation is an AI document translation assistant accessible to everyone. It enables quick and cost-effective utilization of major language model APIs like OpenAI to translate documents in formats such as txt, word, csv, excel, pdf, and ppt. The tool supports AI translation for various document types, including pdf scanning, compatibility with OpenAI format endpoints via intermediary API, batch operations, multi-threading, and Docker deployment.
AI-Office-Translator
AI-Office-Translator is a free, fully localized, user-friendly translation tool that helps you translate Office files (Word, PowerPoint, and Excel) between different languages. It supports .docx, .pptx, and .xlsx files and allows translation between English, Chinese, and Japanese. Users can run the tool after installing CUDA, downloading Ollama dependencies and models, setting up a virtual environment (optional), and installing requirements. The tool provides a UI where users can select languages, models, upload files for translation, start translation, and download translated files. It also supports an online mode with API key integration. The software is open-source under GPL-3.0 license and only provides AI translation services, with users expected to engage in legal translation activities.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.