
dodari
AI 영한-한영 번역기, 도다리 en-ko/ ko-en AI translator
Stars: 168
Dodari is a local web service that makes NHNDQ AI Korean-English/English-Korean translation easy for everyday people to use (based on Gradio).
README:
NHNDQ
AI 한영/영한 번역기를
일반 사람들도 쉽게 쓸수 있게 만든 로컬 웹서비스 입니다. (based on Gradio)
자신의 컴퓨터에서 제한없이 한영-영한 AI 번역이 가능합니다.
-
일반 기계번역에 비해 품질이 우수합니다.
-
txt와 epub파일 번역이 가능합니다. epub은 제목이나 목차등을 제외한 본문의 내용만 번역하였습니다.
-
번역문(원문)파일과번역문파일, 이렇게 두가지 파일로 출력됩니다. 번역이 이상할 경우 원문과 바로 비교할수 있습니다. -
사용이 아주 쉽습니다. 번역이 필요한 파일들을 드래그한 후
번역 실행하기버튼만 클릭하면 됩니다. 알아서한↔영으로 번역해 줍니다. -
번역 성능이 뛰어난 모델로 최신 업데이트가 가능합니다 - 현재는 가성비가 가장 좋은 NHNDQ만 사용합니다.
아래와 같이 두개의 파일이 만들어집니다.
도다리 번역 - 번역문(원문)파일
도다리 번역 - 번역문파일
(참고) DeepL 번역
"토끼굴 아래로 앨리스는 언니 옆에 앉아서 할 일이 없는 것에 매우 지치기 시작했고, 언니가 읽고 있는 책을 한두 번 들여다봤지만, 그 책에는 그림이나 대화가 없었습니다."그림이나 대화가 없는 책이 무슨 소용이 있을까?"앨리스는 생각했습니다. "그래서 그녀는 데이지 사슬을 만드는 즐거움이 일어나서 데이지를 따는 수고로움의 가치가 있는지, (더운 날이 그녀를 매우 졸리고 멍청하게 만들었 기 때문에 가능한 한 잘 생각했습니다) 마음 속으로 생각하고 있었는데 갑자기 분홍색 눈을 가진 하얀 토끼가 그녀 곁으로 달려갔습니다."거기에는 그렇게 놀라운 것도 없었고 앨리스도 토끼가 스스로 말하는 것을 듣는 것이 그렇게 매우 이상하게 생각하지 않았습니다."오 맙소사! 오, 이런! 너무 늦겠어!" (나중에 곰곰이 생각해보니 앨리스가 이걸 궁금해했어야 했다는 생각이 들었지만, 그 당시에는 모든 것이 아주 자연스러워 보였습니다); "그러나 토끼가 실제로 양복 조끼 주머니에서 시계를 꺼내어 그것을 보고는 서둘러 가자 앨리스는 발걸음을 재촉했습니다. 왜냐하면 양복 조끼 주머니를 가진 토끼나 시계를 꺼내는 토끼를 본 적이 없다는 생각이 스쳐 지나갔고, 호기심에 불타서 그 토끼를 따라 들판을 가로질러 뛰어갔을 때 마침 울타리 아래 커다란 토끼 구멍으로 토끼가 튀어 나오는 것을 보았기 때문입니다." "앨리스는 도대체 어떻게 다시 빠져나올 수 있을지 한 번도 생각하지 않은 채 토끼굴을 따라 내려갔고, 토끼굴은 터널처럼 곧장 이어지다가 갑자기 아래로 가라앉아 앨리스는 멈출 생각을 할 틈도 없이 아주 깊은 우물 속으로 떨어지는 자신을 발견했다."
(참고) 구글 번역
“앨리스는 은행에서 여동생 옆에 앉아 있고 할 일이 없는 것에 매우 지치기 시작했습니다. 한두 번 그녀는 여동생이 읽고 있는 책을 들여다 보았지만 그 안에 그림이나 대화가 전혀 없었습니다. "그림이나 대화가 없는 책이 무슨 소용이 있겠는가?"라고 앨리스는 생각했습니다. 데이지 체인을 만드는 즐거움이 일어나서 데이지를 따는 수고를 할 만큼 가치가 있을지에 대해 그녀 자신의 마음 속에서 (그리고 그녀는 할 수 있는 한, 더운 날 때문에 그녀는 매우 졸리고 멍청하다고 느꼈다) 갑자기 백인이 분홍색 눈을 가진 토끼가 그녀 옆으로 달려왔습니다. 그다지 주목할만한 점은 없었습니다. 앨리스는 토끼가 혼잣말하는 것을 듣고도 별로 이상하다고 생각하지 않았습니다. “오 이런! 이런! 너무 늦을 것 같아요!” (나중에 그녀가 곰곰이 생각해보니, 그녀는 이것에 대해 궁금해했어야 했다는 생각이 들었지만, 당시에는 모든 것이 아주 자연스러워 보였습니다.) “그러나 토끼가 실제로 양복 조끼 주머니에서 시계를 꺼내서 살펴보더니 서둘러 갔을 때, 앨리스는 일어서기 시작했습니다. 그녀는 양복 조끼 주머니나 시계를 꺼내려고 호기심에 불타서 그것을 쫓아 들판을 가로질러 달려갔고, 때맞춰 그것이 울타리 아래 커다란 토끼 굴로 떨어지는 것을 보았습니다.” "또 다른 순간에 앨리스는 그 뒤를 따라 내려갔습니다. 도대체 그녀가 다시 나갈 수 있다는 생각은 단 한 번도 하지 않았습니다. 토끼굴은 어떤 식으로든 터널처럼 곧게 이어지다가 갑자기 아래로 내려갔습니다. 너무 갑자기 내려가서 앨리스는 더 이상 빠져나갈 수 없었습니다. 그녀가 아주 깊은 우물처럼 보이는 곳으로 떨어지기 전에 자신을 멈추는 것에 대해 생각할 순간이었습니다.”
공통,
- 먼저 파이썬이 설치되어 있어야 합니다. 윈도우에는 파이썬이 기본으로 설치되어 있지 않습니다.
- https://wikidocs.net/8 를 참고하여 쉽게 설치하실수 있습니다.
초보자라면,
- 압축 파일 다운로드 클릭
- 압축해제 후
- 윈도우 사용자는 start_windows.bat 더블 클릭
- 맥이나 우분투 사용자는 터미널 창에서 sh start_mac.sh 실행
- 처음 실행이라면 프로그램을 자동으로 설치한 후 실행합니다. 이미 설치가 되었다면 바로 실행합니다.
고급 사용자라면,
- git clone https://github.com/vEduardovich/dodari.git
- cd dodari
- 아래 방법으로 실행하기
- 윈도우는 start_windows.bat 실행
- 맥, 우분투는 sh start_mac.sh 실행
첫 실행시 관련 프로그램 설치와 AI 모델을 다운로드 하는데 아주 오랜 시간이 걸립니다!
헤르만 헤세의 싯다르타 text과 이상한 나라의 앨리스(영문판).epub을 번역해봤습니다.
| 사양 | 운영체제 | CPU | GPU | 문장수 | 싯다르타.txt | 이상한나라의 앨리스.epub |
|---|---|---|---|---|---|---|
| LG전자 2020 그램 17 | 윈도우10 | i7 (1.3GHz) | 내장그래픽 | 378KB 2577개 |
2시간 55분 24초 | 3시간 45분 6초 |
| Mac Pro M1 | iOS | 10코어 | 16코어 | 54분 23초 | 1시간 13분 5초 | |
| 데스크탑 | Ubuntu22.04 | i9-13900k | RTX4090 24GB | 5분 25초 | 7분 20초 | |
| 데스크탑 | 윈도우11 | i9-13900k | RTX4090 24GB | 11분 49초 | 14분 36초 |
이상한나라의 앨리스.epub, RTX 4090으로 테스트
| 상태 | 걸린시간 |
|---|---|
| vllm 미적용시 | 4시간 7분 26초 |
| vllm 적용시 | 40분 5초 |
dodari
├⎯ models : AI가 다운로드되는 폴더
├⎯ venv : 도다리 실행을 위한 관련 파일들이 설치되는 폴더
├⎯ imgs : 도다리 이미지
초보자라면,
- 위 압축파일을 다시 다운로드하고 압축을 푼후
- 기존 도다리 폴더안에 덮어쓰면 됩니다.
고급 사용자라면,
- git pull
- 폴더 전체를 지우면 깨끗하게 지워집니다.
- ext dot 중복제거
- 주요 라이브러리 버전 fix
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for dodari
Similar Open Source Tools
dodari
Dodari is a local web service that makes NHNDQ AI Korean-English/English-Korean translation easy for everyday people to use (based on Gradio).
Wechat-AI-Assistant
Wechat AI Assistant is a project that enables multi-modal interaction with ChatGPT AI assistant within WeChat. It allows users to engage in conversations, role-playing, respond to voice messages, analyze images and videos, summarize articles and web links, and search the internet. The project utilizes the WeChatFerry library to control the Windows PC desktop WeChat client and leverages the OpenAI Assistant API for intelligent multi-modal message processing. Users can interact with ChatGPT AI in WeChat through text or voice, access various tools like bing_search, browse_link, image_to_text, text_to_image, text_to_speech, video_analysis, and more. The AI autonomously determines which code interpreter and external tools to use to complete tasks. Future developments include file uploads for AI to reference content, integration with other APIs, and login support for enterprise WeChat and WeChat official accounts.
chat-master
ChatMASTER is a self-built backend conversation service based on AI large model APIs, supporting synchronous and streaming responses with perfect printer effects. It supports switching between mainstream models such as DeepSeek, Kimi, Doubao, OpenAI, Claude3, Yiyan, Tongyi, Xinghuo, ChatGLM, Shusheng, and more. It also supports loading local models and knowledge bases using Ollama and Langchain, as well as online API interfaces like Coze and Gitee AI. The project includes Java server-side, web-side, mobile-side, and management background configuration. It provides various assistant types for prompt output and allows creating custom assistant templates in the management background. The project uses technologies like Spring Boot, Spring Security + JWT, Mybatis-Plus, Lombok, Mysql & Redis, with easy-to-understand code and comprehensive permission control using JWT authentication system for multi-terminal support.
Gensokyo-llm
Gensokyo-llm is a tool designed for Gensokyo and Onebotv11, providing a one-click solution for large models. It supports various Onebotv11 standard frameworks, HTTP-API, and reverse WS. The tool is lightweight, with built-in SQLite for context maintenance and proxy support. It allows easy integration with the Gensokyo framework by configuring reverse HTTP and forward HTTP addresses. Users can set system settings, role cards, and context length. Additionally, it offers an openai original flavor API with automatic context. The tool can be used as an API or integrated with QQ channel robots. It supports converting GPT's SSE type and ensures memory safety in concurrent SSE environments. The tool also supports multiple users simultaneously transmitting SSE bidirectionally.
ChatGLM3
ChatGLM3 is a conversational pretrained model jointly released by Zhipu AI and THU's KEG Lab. ChatGLM3-6B is the open-sourced model in the ChatGLM3 series. It inherits the advantages of its predecessors, such as fluent conversation and low deployment threshold. In addition, ChatGLM3-6B introduces the following features: 1. A stronger foundation model: ChatGLM3-6B's foundation model ChatGLM3-6B-Base employs more diverse training data, more sufficient training steps, and more reasonable training strategies. Evaluation on datasets from different perspectives, such as semantics, mathematics, reasoning, code, and knowledge, shows that ChatGLM3-6B-Base has the strongest performance among foundation models below 10B parameters. 2. More complete functional support: ChatGLM3-6B adopts a newly designed prompt format, which supports not only normal multi-turn dialogue, but also complex scenarios such as tool invocation (Function Call), code execution (Code Interpreter), and Agent tasks. 3. A more comprehensive open-source sequence: In addition to the dialogue model ChatGLM3-6B, the foundation model ChatGLM3-6B-Base, the long-text dialogue model ChatGLM3-6B-32K, and ChatGLM3-6B-128K, which further enhances the long-text comprehension ability, are also open-sourced. All the above weights are completely open to academic research and are also allowed for free commercial use after filling out a questionnaire.
grps_trtllm
The grps-trtllm repository is a C++ implementation of a high-performance OpenAI LLM service, combining GRPS and TensorRT-LLM. It supports functionalities like Chat, Ai-agent, and Multi-modal. The repository offers advantages over triton-trtllm, including a complete LLM service implemented in pure C++, integrated tokenizer supporting huggingface and sentencepiece, custom HTTP functionality for OpenAI interface, support for different LLM prompt styles and result parsing styles, integration with tensorrt backend and opencv library for multi-modal LLM, and stable performance improvement compared to triton-trtllm.

tiny-llm-zh
Tiny LLM zh is a project aimed at building a small-parameter Chinese language large model for quick entry into learning large model-related knowledge. The project implements a two-stage training process for large models and subsequent human alignment, including tokenization, pre-training, instruction fine-tuning, human alignment, evaluation, and deployment. It is deployed on ModeScope Tiny LLM website and features open access to all data and code, including pre-training data and tokenizer. The project trains a tokenizer using 10GB of Chinese encyclopedia text to build a Tiny LLM vocabulary. It supports training with Transformers deepspeed, multiple machine and card support, and Zero optimization techniques. The project has three main branches: llama2_torch, main tiny_llm, and tiny_llm_moe, each with specific modifications and features.

LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
job-hunting
Job Hunting is a browser extension designed to enhance the job searching experience on popular recruitment platforms in China. It aims to improve job listing visibility, provide personalized job search capabilities, analyze job data, facilitate job discussions, and offer company insights. The extension offers features such as job card display, company reputation checks, quick company information lookup, job and company data storage, job and company tagging, data analysis, data sharing, personal job preferences, automation tasks, discussion forums, data backup and recovery, and data sharing plans. It supports platforms like BOSS 直聘, 前程无忧, 智联招聘, 拉钩网, and 猎聘网, and provides visualizations for job posting trends and company data.
k8m
k8m is an AI-driven Mini Kubernetes AI Dashboard lightweight console tool designed to simplify cluster management. It is built on AMIS and uses 'kom' as the Kubernetes API client. k8m has built-in Qwen2.5-Coder-7B model interaction capabilities and supports integration with your own private large models. Its key features include miniaturized design for easy deployment, user-friendly interface for intuitive operation, efficient performance with backend in Golang and frontend based on Baidu AMIS, pod file management for browsing, editing, uploading, downloading, and deleting files, pod runtime management for real-time log viewing, log downloading, and executing shell commands within pods, CRD management for automatic discovery and management of CRD resources, and intelligent translation and diagnosis based on ChatGPT for YAML property translation, Describe information interpretation, AI log diagnosis, and command recommendations, providing intelligent support for managing k8s. It is cross-platform compatible with Linux, macOS, and Windows, supporting multiple architectures like x86 and ARM for seamless operation. k8m's design philosophy is 'AI-driven, lightweight and efficient, simplifying complexity,' helping developers and operators quickly get started and easily manage Kubernetes clusters.
Awesome-ChatTTS
Awesome-ChatTTS is an official recommended guide for ChatTTS beginners, compiling common questions and related resources. It provides a comprehensive overview of the project, including official introduction, quick experience options, popular branches, parameter explanations, voice seed details, installation guides, FAQs, and error troubleshooting. The repository also includes video tutorials, discussion community links, and project trends analysis. Users can explore various branches for different functionalities and enhancements related to ChatTTS.
AI0x0.com
AI 0x0 is a versatile AI query generation desktop floating assistant application that supports MacOS and Windows. It allows users to utilize AI capabilities in any desktop software to query and generate text, images, audio, and video data, helping them work more efficiently. The application features a dynamic desktop floating ball, floating dialogue bubbles, customizable presets, conversation bookmarking, preset packages, network acceleration, query mode, input mode, mouse navigation, deep customization of ChatGPT Next Web, support for full-format libraries, online search, voice broadcasting, voice recognition, voice assistant, application plugins, multi-model support, online text and image generation, image recognition, frosted glass interface, light and dark theme adaptation for each language model, and free access to all language models except Chat0x0 with a key.
api-for-open-llm
This project provides a unified backend interface for open large language models (LLMs), offering a consistent experience with OpenAI's ChatGPT API. It supports various open-source LLMs, enabling developers to seamlessly integrate them into their applications. The interface features streaming responses, text embedding capabilities, and support for LangChain, a tool for developing LLM-based applications. By modifying environment variables, developers can easily use open-source models as alternatives to ChatGPT, providing a cost-effective and customizable solution for various use cases.

Steel-LLM
Steel-LLM is a project to pre-train a large Chinese language model from scratch using over 1T of data to achieve a parameter size of around 1B, similar to TinyLlama. The project aims to share the entire process including data collection, data processing, pre-training framework selection, model design, and open-source all the code. The goal is to enable reproducibility of the work even with limited resources. The name 'Steel' is inspired by a band '万能青年旅店' and signifies the desire to create a strong model despite limited conditions. The project involves continuous data collection of various cultural elements, trivia, lyrics, niche literature, and personal secrets to train the LLM. The ultimate aim is to fill the model with diverse data and leave room for individual input, fostering collaboration among users.
ComfyUI-OllamaGemini
ComfyUI GeminiOllama Extension integrates Google's Gemini API, OpenAI (ChatGPT), Anthropic's Claude, Ollama, Qwen, and image processing tools into ComfyUI for leveraging powerful models and features directly within workflows. Features include multiple AI API integrations, advanced prompt engineering, Gemini image generation, background removal, SVG conversion, FLUX resolutions, ComfyUI Styler, smart prompt generator, and more. The extension offers comprehensive API integration, advanced prompt engineering with researched templates, high-quality tools like Smart Prompt Generator and BRIA RMBG, and supports video & audio processing. It provides a single interface to access powerful AI models, transform prompts into detailed instructions, and use various tools for image processing, styling, and content generation.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
For similar tasks

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.
dodari
Dodari is a local web service that makes NHNDQ AI Korean-English/English-Korean translation easy for everyday people to use (based on Gradio).

vector-vein
VectorVein is a no-code AI workflow software inspired by LangChain and langflow, aiming to combine the powerful capabilities of large language models and enable users to achieve intelligent and automated daily workflows through simple drag-and-drop actions. Users can create powerful workflows without the need for programming, automating all tasks with ease. The software allows users to define inputs, outputs, and processing methods to create customized workflow processes for various tasks such as translation, mind mapping, summarizing web articles, and automatic categorization of customer reviews.
project-lakechain
Project Lakechain is a cloud-native, AI-powered framework for building document processing pipelines on AWS. It provides a composable API with built-in middlewares for common tasks, scalable architecture, cost efficiency, GPU and CPU support, and the ability to create custom transform middlewares. With ready-made examples and emphasis on modularity, Lakechain simplifies the deployment of scalable document pipelines for tasks like metadata extraction, NLP analysis, text summarization, translations, audio transcriptions, computer vision, and more.
ezwork-ai-doc-translation
EZ-Work AI Document Translation is an AI document translation assistant accessible to everyone. It enables quick and cost-effective utilization of major language model APIs like OpenAI to translate documents in formats such as txt, word, csv, excel, pdf, and ppt. The tool supports AI translation for various document types, including pdf scanning, compatibility with OpenAI format endpoints via intermediary API, batch operations, multi-threading, and Docker deployment.
AI-Office-Translator
AI-Office-Translator is a free, fully localized, user-friendly translation tool that helps you translate Office files (Word, PowerPoint, and Excel) between different languages. It supports .docx, .pptx, and .xlsx files and allows translation between English, Chinese, and Japanese. Users can run the tool after installing CUDA, downloading Ollama dependencies and models, setting up a virtual environment (optional), and installing requirements. The tool provides a UI where users can select languages, models, upload files for translation, start translation, and download translated files. It also supports an online mode with API key integration. The software is open-source under GPL-3.0 license and only provides AI translation services, with users expected to engage in legal translation activities.

LinguaHaru
Next-generation AI translation tool that provides high-quality, precise translations for various common file formats with a single click. It is based on cutting-edge large language models, offering exceptional translation quality with minimal operation, supporting multiple document formats and languages. Features include multi-format compatibility, global language translation, one-click rapid translation, flexible translation engines, and LAN sharing for efficient collaborative work.
DocTranslator
DocTranslator is a document translation tool that supports various file formats, compatible with OpenAI format API, and offers batch operations and multi-threading support. Whether for individual users or enterprise teams, DocTranslator helps efficiently complete document translation tasks. It supports formats like txt, markdown, word, csv, excel, pdf (non-scanned), and ppt for AI translation. The tool is deployed using Docker for easy setup and usage.
For similar jobs

mikupad
mikupad is a lightweight and efficient language model front-end powered by ReactJS, all packed into a single HTML file. Inspired by the likes of NovelAI, it provides a simple yet powerful interface for generating text with the help of various backends.
blog
这是一个程序员关于 ChatGPT 学习过程的记录,其中包括了 ChatGPT 的使用技巧、相关工具和资源的整理,以及一些个人见解和思考。 **使用技巧** * **充值 OpenAI API**:可以通过 https://beta.openai.com/account/api-keys 进行充值,支持信用卡和 PayPal。 * **使用专梯**:推荐使用稳定的专梯,可以有效提高 ChatGPT 的访问速度和稳定性。 * **使用魔法**:可以通过 https://my.x-air.app:666/#/register?aff=32853 访问 ChatGPT,无需魔法即可访问。 * **下载各种 apk**:可以通过 https://apkcombo.com 下载各种安卓应用的 apk 文件。 * **ChatGPT 官网**:ChatGPT 的官方网站是 https://ai.com。 * **Midjourney**:Midjourney 是一个生成式 AI 图像平台,可以通过 https://midjourney.com 访问。 * **文本转视频**:可以通过 https://www.d-id.com 将文本转换为视频。 * **国内大模型**:国内也有很多大模型,如阿里巴巴的通义千问、百度文心一言、讯飞星火、阿里巴巴通义听悟等。 * **查看 OpenAI 状态**:可以通过 https://status.openai.com/ 查看 OpenAI 的服务状态。 * **Canva 画图**:Canva 是一个在线平面设计平台,可以通过 https://www.canva.cn 进行画图。 **相关工具和资源** * **文字转语音**:可以通过 https://modelscope.cn/models?page=1&tasks=text-to-speech&type=audio 找到文字转语音的模型。 * **可好好玩玩的项目**: * https://github.com/sunner/ChatALL * https://github.com/labring/FastGPT * https://github.com/songquanpeng/one-api * **个人博客**: * https://baoyu.io/ * https://gorden-sun.notion.site/527689cd2b294e60912f040095e803c5?v=4f6cc12006c94f47aee4dc909511aeb5 * **srt 2 lrc 歌词**:可以通过 https://gotranscript.com/subtitle-converter 将 srt 格式的字幕转换为 lrc 格式的歌词。 * **5 种速率限制**:OpenAI API 有 5 种速率限制:RPM(每分钟请求数)、RPD(每天请求数)、TPM(每分钟 tokens 数量)、TPD(每天 tokens 数量)、IPM(每分钟图像数量)。 * **扣子平台**:coze.cn 是一个扣子平台,可以提供各种扣子。 * **通过云函数免费使用 GPT-3.5**:可以通过 https://juejin.cn/post/7353849549540589587 免费使用 GPT-3.5。 * **不蒜子 统计网页基数**:可以通过 https://busuanzi.ibruce.info/ 统计网页的基数。 * **视频总结和翻译网页**:可以通过 https://glarity.app/zh-CN 总结和翻译视频。 * **视频翻译和配音工具**:可以通过 https://github.com/jianchang512/pyvideotrans 翻译和配音视频。 * **文字生成音频**:可以通过 https://www.cnblogs.com/jijunjian/p/18118366 将文字生成音频。 * **memo ai**:memo.ac 是一个多模态 AI 平台,可以将视频链接、播客链接、本地音视频转换为文字,支持多语言转录后翻译,还可以将文字转换为新的音频。 * **视频总结工具**:可以通过 https://summarize.ing/ 总结视频。 * **可每天免费玩玩**:可以通过 https://www.perplexity.ai/ 每天免费玩玩。 * **Suno.ai**:Suno.ai 是一个 AI 语言模型,可以通过 https://bibigpt.co/ 访问。 * **CapCut**:CapCut 是一个视频编辑软件,可以通过 https://www.capcut.cn/ 下载。 * **Valla.ai**:Valla.ai 是一个多模态 AI 模型,可以通过 https://www.valla.ai/ 访问。 * **Viggle.ai**:Viggle.ai 是一个 AI 视频生成平台,可以通过 https://viggle.ai 访问。 * **使用免费的 GPU 部署文生图大模型**:可以通过 https://www.cnblogs.com/xuxiaona/p/18088404 部署文生图大模型。 * **语音转文字**:可以通过 https://speech.microsoft.com/portal 将语音转换为文字。 * **投资界的 ai**:可以通过 https://reportify.cc/ 了解投资界的 ai。 * **抓取小视频 app 的各种信息**:可以通过 https://github.com/NanmiCoder/MediaCrawler 抓取小视频 app 的各种信息。 * **马斯克 Grok1 开源**:马斯克的 Grok1 模型已经开源,可以通过 https://github.com/xai-org/grok-1 访问。 * **ChatALL**:ChatALL 是一个跨端支持的聊天机器人,可以通过 https://github.com/sunner/ChatALL 访问。 * **零一万物**:零一万物是一个 AI 平台,可以通过 https://www.01.ai/cn 访问。 * **智普**:智普是一个 AI 语言模型,可以通过 https://chatglm.cn/ 访问。 * **memo ai 下载**:可以通过 https://memo.ac/ 下载 memo ai。 * **ffmpeg 学习**:可以通过 https://www.ruanyifeng.com/blog/2020/01/ffmpeg.html 学习 ffmpeg。 * **自动生成文章小工具**:可以通过 https://www.cognition-labs.com/blog 生成文章。 * **简易商城**:可以通过 https://www.cnblogs.com/whuanle/p/18086537 搭建简易商城。 * **物联网**:可以通过 https://www.cnblogs.com/xuxiaona/p/18088404 学习物联网。 * **自定义表单、自定义列表、自定义上传和下载、自定义流程、自定义报表**:可以通过 https://www.cnblogs.com/whuanle/p/18086537 实现自定义表单、自定义列表、自定义上传和下载、自定义流程、自定义报表。 **个人见解和思考** * ChatGPT 是一个强大的工具,可以用来提高工作效率和创造力。 * ChatGPT 的使用门槛较低,即使是非技术人员也可以轻松上手。 * ChatGPT 的发展速度非常快,未来可能会对各个行业产生深远的影响。 * 我们应该理性看待 ChatGPT,既要看到它的优点,也要意识到它的局限性。 * 我们应该积极探索 ChatGPT 的应用场景,为社会创造价值。
Tiny-Predictive-Text
Tiny-Predictive-Text is a demonstration of predictive text without an LLM, using permy.link. It provides a detailed description of the tool, including its features, benefits, and how to use it. The tool is suitable for a variety of jobs, including content writers, editors, and researchers. It can be used to perform a variety of tasks, such as generating text, completing sentences, and correcting errors.
ClipboardConqueror
Clipboard Conqueror is a multi-platform omnipresent copilot alternative. Currently requiring a kobold united or openAI compatible back end, this software brings powerful LLM based tools to any text field, the universal copilot you deserve. It simply works anywhere. No need to sign in, no required key. Provided you are using local AI, CC is a data secure alternative integration provided you trust whatever backend you use. *Special thank you to the creators of KoboldAi, KoboldCPP, llamma, openAi, and the communities that made all this possible to figure out.
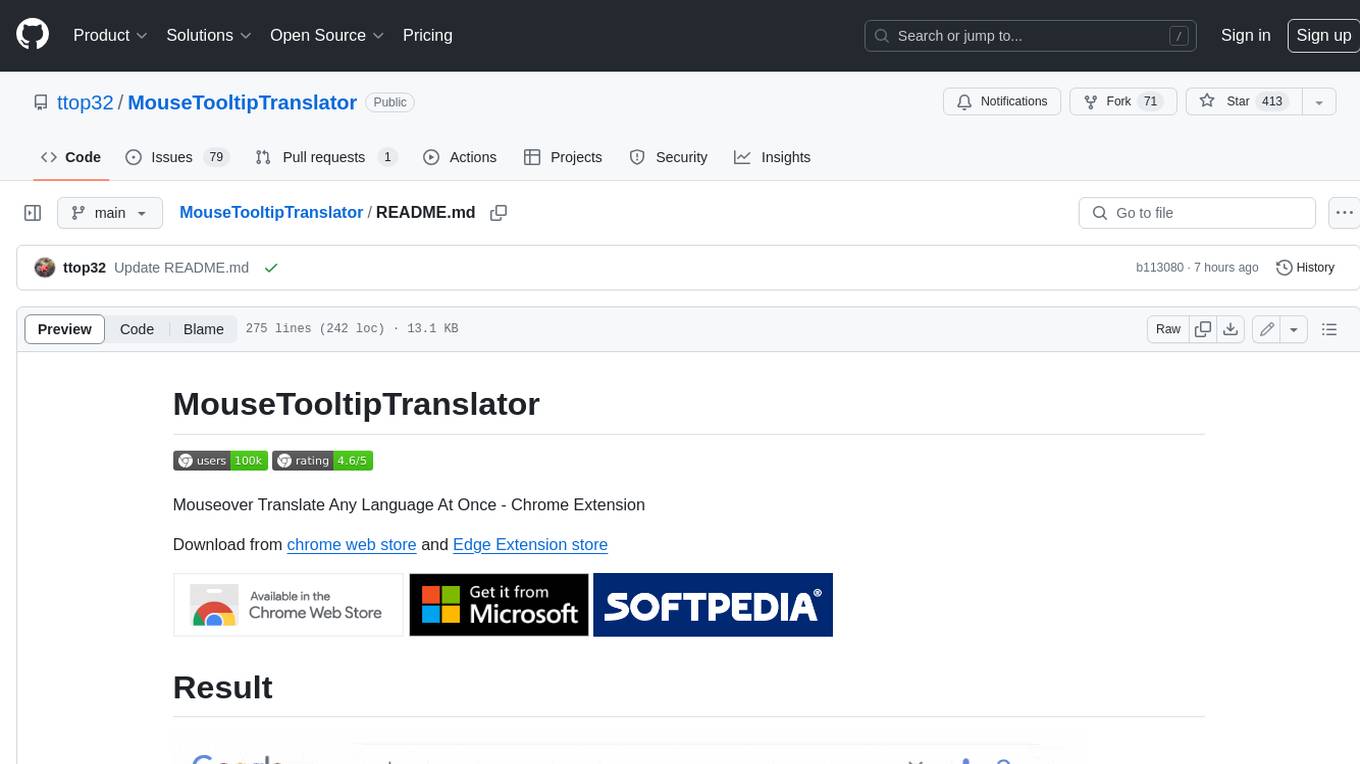
MouseTooltipTranslator
MouseTooltipTranslator is a Chrome extension that allows users to translate any text on a webpage by simply hovering over it. It supports both Google Translate and Bing Translate, and can also be used to listen to the pronunciation of words and phrases. Additionally, the extension can be used to translate text in input boxes and highlighted text, and to display translated tooltips for PDFs and YouTube videos. It also supports OCR, allowing users to translate text in images by holding down the left shift key and hovering over the image.
dodari
Dodari is a local web service that makes NHNDQ AI Korean-English/English-Korean translation easy for everyday people to use (based on Gradio).
gpt_academic
GPT Academic is a powerful tool that leverages the capabilities of large language models (LLMs) to enhance academic research and writing. It provides a user-friendly interface that allows researchers, students, and professionals to interact with LLMs and utilize their abilities for various academic tasks. With GPT Academic, users can access a wide range of features and functionalities, including: * **Summarization and Paraphrasing:** GPT Academic can summarize complex texts, articles, and research papers into concise and informative summaries. It can also paraphrase text to improve clarity and readability. * **Question Answering:** Users can ask GPT Academic questions related to their research or studies, and the tool will provide comprehensive and well-informed answers based on its knowledge and understanding of the relevant literature. * **Code Generation and Explanation:** GPT Academic can generate code snippets and provide explanations for complex coding concepts. It can also help debug code and suggest improvements. * **Translation:** GPT Academic supports translation of text between multiple languages, making it a valuable tool for researchers working with international collaborations or accessing resources in different languages. * **Citation and Reference Management:** GPT Academic can help users manage their citations and references by automatically generating citations in various formats and providing suggestions for relevant references based on the user's research topic. * **Collaboration and Note-Taking:** GPT Academic allows users to collaborate on projects and take notes within the tool. They can share their work with others and access a shared workspace for real-time collaboration. * **Customizable Interface:** GPT Academic offers a customizable interface that allows users to tailor the tool to their specific needs and preferences. They can choose from a variety of themes, adjust the layout, and add or remove features to create a personalized workspace. Overall, GPT Academic is a versatile and powerful tool that can significantly enhance the productivity and efficiency of academic research and writing. It empowers users to leverage the capabilities of LLMs and unlock new possibilities for academic exploration and knowledge creation.

Chinese-LLaMA-Alpaca-2
Chinese-LLaMA-Alpaca-2 is a large Chinese language model developed by Meta AI. It is based on the Llama-2 model and has been further trained on a large dataset of Chinese text. Chinese-LLaMA-Alpaca-2 can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. Here are some of the key features of Chinese-LLaMA-Alpaca-2: * It is the largest Chinese language model ever trained, with 13 billion parameters. * It is trained on a massive dataset of Chinese text, including books, news articles, and social media posts. * It can be used for a variety of natural language processing tasks, including text generation, question answering, and machine translation. * It is open-source and available for anyone to use. Chinese-LLaMA-Alpaca-2 is a powerful tool that can be used to improve the performance of a wide range of natural language processing tasks. It is a valuable resource for researchers and developers working in the field of artificial intelligence.