
Wechat-AI-Assistant
微信AI助理 (Wechat AI Assistant): 在微信中与 AI 助理进行多模态交互, 处理问答、扮演角色、响应语音消息、分析图片和视频、总结文章和网页链接、搜索互联网等等。现支持 OpenAI Assistant API 和 GPT-4o模型。
Stars: 106
Wechat AI Assistant is a project that enables multi-modal interaction with ChatGPT AI assistant within WeChat. It allows users to engage in conversations, role-playing, respond to voice messages, analyze images and videos, summarize articles and web links, and search the internet. The project utilizes the WeChatFerry library to control the Windows PC desktop WeChat client and leverages the OpenAI Assistant API for intelligent multi-modal message processing. Users can interact with ChatGPT AI in WeChat through text or voice, access various tools like bing_search, browse_link, image_to_text, text_to_image, text_to_speech, video_analysis, and more. The AI autonomously determines which code interpreter and external tools to use to complete tasks. Future developments include file uploads for AI to reference content, integration with other APIs, and login support for enterprise WeChat and WeChat official accounts.
README:
在微信中与 ChatGPT AI 助理进行多模态交互, 处理问答、扮演角色、响应语音、图片和视频消息、总结文章和网页、搜索互联网等等。把个人微信变成你的 AI 助理。
本项目使用 WeChatFerry 库控制 Windows PC 桌面微信客户端, 调用 OpenAI Assistant API 进行智能多模态消息处理。
- 在微信中与 ChatGPT AI 对话(文字或语音),进行多模态交互。
- 使用 WeChatFerry 接入 Windows 桌面版微信, 对微信的兼容性高(无需实名认证), 风险低。
- 使用 OpenAI Assistant API 自动管理群聊对话上下文。
- 使用 gpt-4o 等视觉支持模型,可进行图片/视频内容读取分析。
- 文档上传,文档内容检索,根据文档内容回答问题(使用 OpenAI 内置 file_search 工具)。
- AI 自行判断调用代码解释器和外部工具完成任务。现有工具: bing_search (必应搜索), browse_link (浏览网页链接), text_to_image (文字描述作图), text_to_speech (文本转语音), mahjong_agari(立直麻将和牌计算:番数,符数,役种,点数等)
- 后续计划开发: 其他 API 和工具调用 / 企业微信和微信公众号登录
- QQ群: 812016253 点击加入
- 支持微信桌面客户端版本:3.9.10.27
- "画一张猫和水豚一起滑雪的照片"
- "(引用图片) 根据图片内容作一首诗,并读给我听"
- "(引用公众号文章或网页链接) 总结一下文章的要点"
- "搜索关于OPENAI的新闻, 把结果读给我听"
- "立直麻将手牌 1112345678999m 自摸0m,和什么役种和点数?"






- OpenAI API Key 注: 本项目依赖于 Assistant API,非官方的 API 入口请确认是否支持 Assistant API。
- Windows 电脑或服务器。
- (可选, 中国国内) 访问 OpenAI 的代理服务器 (例如 openai-proxy), 或者使用 API 代理。
- (可选,手动部署需要) 安装好 Python 环境和 Git
- (可选, 供联网搜索插件使用) Bing Search API Key. 获取地址
- 到 Releases 中下载打包好的可执行文件和微信安装文件
- 安装微信 Windows 桌面指定版本 (安装包已提供)。
- 将压缩包解压到本地。
- 编辑 config.yaml 文件(必填项目为openai api_key,配置项说明见文档。)
- 运行"main.exe", 程序将唤起微信客户端, 登录后程序开始运行。
- 安装微信Windows指定版本版本。请到 Release 中下载。
- 克隆项目代码到本地
git clone https://github.com/latorc/Wechat-AI-Assistant.git- (可选) 创建 Python 虚拟环境并激活
python -m venv .venv
call .venv\Scripts\activate.bat- 安装依赖的库; 这里使用清华的来源, 方便中国国内用户快速下载
cd Wechat-AI-Assistant
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple- 编辑配置文件: 重命名配置文件 config_template.yaml 为 config.yaml, 并编辑配置项。配置项说明见文档。
- 运行 main.py
python main.py程序会自动唤起微信客户端, 之后扫码登录微信桌面客户端, 即可开始使用。
| 配置项 | 说明 | 举例 |
|---|---|---|
| api_key | 你的 OpenAI API Key | sk-abcdefg12345678.... |
| base_url | API 的网址, 使用默认 API 无需改动, 使用代理或第三方 API 时填写 | https://api.openai.com/v1 |
| proxy | 用于访问 OpenAI 的代理服务器地址, 格式为"http://地址:端口号" | http://10.0.0.10:8002 |
| chat_model | 默认使用的聊天模型 | gpt-4o |
| admins | 管理员微信号列表, 只有管理员可以使用管理员命令 | [wx1234, wx2345] |
其他配置选项请参见 config.yaml 中的注释。
- 添加微信AI助理的微信好友, 或将其加入群聊中并@它, 与它进行对话。
- 直接与其对话将调用 ChatGPT 进行回答。可以发送图片和文件后, 引用图片和文件并@AI助理, 指示其进行处理。
- 微信AI助理会根据用户的文本, 自主选择调用工具完成任务。现阶段工具包括绘图(OpenAI dall-e-3), 代码解释器, 合成语音(OpenAI API), 访问网页, 搜索等。
- 绘图质量暂时由 AI 控制
- 只支持指定版本微信,请在设置中关闭微信自动更新。运行前请关闭打开的微信桌面客户端。
定义了管理员后 (config.yaml 文件中的 admins 项目), 管理员可以使用管理员命令。默认的命令如下:
| 命令 | 说明 |
|---|---|
| $帮助 | 显示帮助信息 |
| $刷新配置 | 重新载入程序配置 |
| $清除 | 清除当前对话记忆 |
| $加载<预设名> | 为当前对话加载预设 |
| $重置预设 | 为当前对话重置预设到默认预设 |
| $预设列表 | 显示可用的预设 |
| $id | 显示当前对话的id |
这些命令可以在 config.yaml 中修改
- 对话预设是对当前对话(群聊或单聊)生效的系统提示词和消息包装方式。
- 对AI助理使用默认命令"$加载 <预设名>"可以为当前对话加载预设。"$预设列表"命令显示当前可用的预设及其描述。
- <预设名>为定义在 presets 目录下的同名 yaml 配置文件。
- default.yaml 是默认预设, 对话默认使用。
- 可以用配置文件中的 group_presets 字段,为对话设置预设,程序启动时自动加载。
- 要创建自己的预设, 请参考 presets 目录下的 default.yaml, 即默认的预设。复制该文件,改名成你的预设名称,并修改其中信息。
- desc: 预设的简单描述
- sys_prompt: 预设的系统提示词
- msg_format: 包装用户消息的格式字符串, 可用替换变量 {message}=原消息, {wxcode}=发送者微信号, {nickname}=发送者微信昵称。如不设置则直接发送源消息。
- 工具代表外部函数和 API, 可以供 AI 模型自主选择调用, 来完成额外任务, 如画图, 联网搜索等功能。
- 使用 "$帮助" 命令显示启用的工具插件。
- 工具配置: 在 config.yaml 中的 tools 字段, 定义了工具是否启用, 以及工具的配置选项。要禁用工具, 只需删除或者注释掉插件名。某些插件需要额外配置选项才能工作, 比如 bing_search (必应搜索) 需要 api_key 才能工作。
- 每个工具在 Assistant 中对应一个 Function Tool, 可以在 OpenAI Playground 查看。
- 工具代码位于 tools 目录下, 继承 ToolBase 类并实现接口。
工具介绍:
- bing_search (必应搜索): 使用微软 Bing Search API 搜索互联网上的内容。
- 注册获取 Bing search API 见: https://www.microsoft.com/bing/apis/bing-web-search-api
- browse_link: 浏览网页链接。使用 Selenium 获取网页文字内容供 AI 使用。
- text_to_image: 文本作图。 使用 dall-e 模型根据文字生成图片。
- text_to_speech: 文本转语音。使用 OpenAI API 从文本生成语音音频。
- audio_transcript: 语音转文本。使用 OpenAI Whipser 将语音转录成文本。
- mahjong_agari: 日麻点和牌点数计算。计算役种,番数符数,点数等信息。使用库: https://github.com/MahjongRepository/mahjong
- 在国内无法连接官方 API 时, 可以尝试使用 API 代理, 或者使用科学上网代理。一个免费的 API 代理是openai-proxy.com, 将 base_url 替换成 https://api.openai-proxy.com/v1
- 可以使用手机模拟器 (如逍遥模拟器) 登录微信, 并登录 Windows 微信客户端, 即可保持微信持续在线。不要打断模拟器的扫码过程,可能会触发微信检测封号。
- 程序调用了 OpenAI 的 Assistant API. 运行时,程序将创建并修改一个名为 "Wechat_AI_Assistant" 的 assistant 用于对话。你可以在 OpenAI Playground 测试这个助理。
- 程序会上传照片和文件到 OpenAI 进行处理。你可以在 OpenAI管理后台查看和删除你的文件。OpenAI 不对文件本身进行收费,但是对文件的总占用空间有限制。
- 程序把所有工具的定义描述, 搜索结果和网页全文都发给 OpenAI。需要节省 token 可以关闭部分工具(插件)。
- QQ群: 812016253 点击加入
- 鸣谢: 本项目基于 WeChatFerry. 感谢 lich0821 大佬的 WeChatFerry 项目
- 推荐: 一键部署自己的ChatGPT网站 ChatGPT-Next-Web 项目
- 参考: 使用网页版微信登录的微信机器人 ChatGPT-on-Wechat 项目
- 参考: OpenAI Cookbook 博客教程 Assistant API Overview
- 参考: OpenAI API Reference
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Wechat-AI-Assistant
Similar Open Source Tools
Wechat-AI-Assistant
Wechat AI Assistant is a project that enables multi-modal interaction with ChatGPT AI assistant within WeChat. It allows users to engage in conversations, role-playing, respond to voice messages, analyze images and videos, summarize articles and web links, and search the internet. The project utilizes the WeChatFerry library to control the Windows PC desktop WeChat client and leverages the OpenAI Assistant API for intelligent multi-modal message processing. Users can interact with ChatGPT AI in WeChat through text or voice, access various tools like bing_search, browse_link, image_to_text, text_to_image, text_to_speech, video_analysis, and more. The AI autonomously determines which code interpreter and external tools to use to complete tasks. Future developments include file uploads for AI to reference content, integration with other APIs, and login support for enterprise WeChat and WeChat official accounts.
BreezeApp
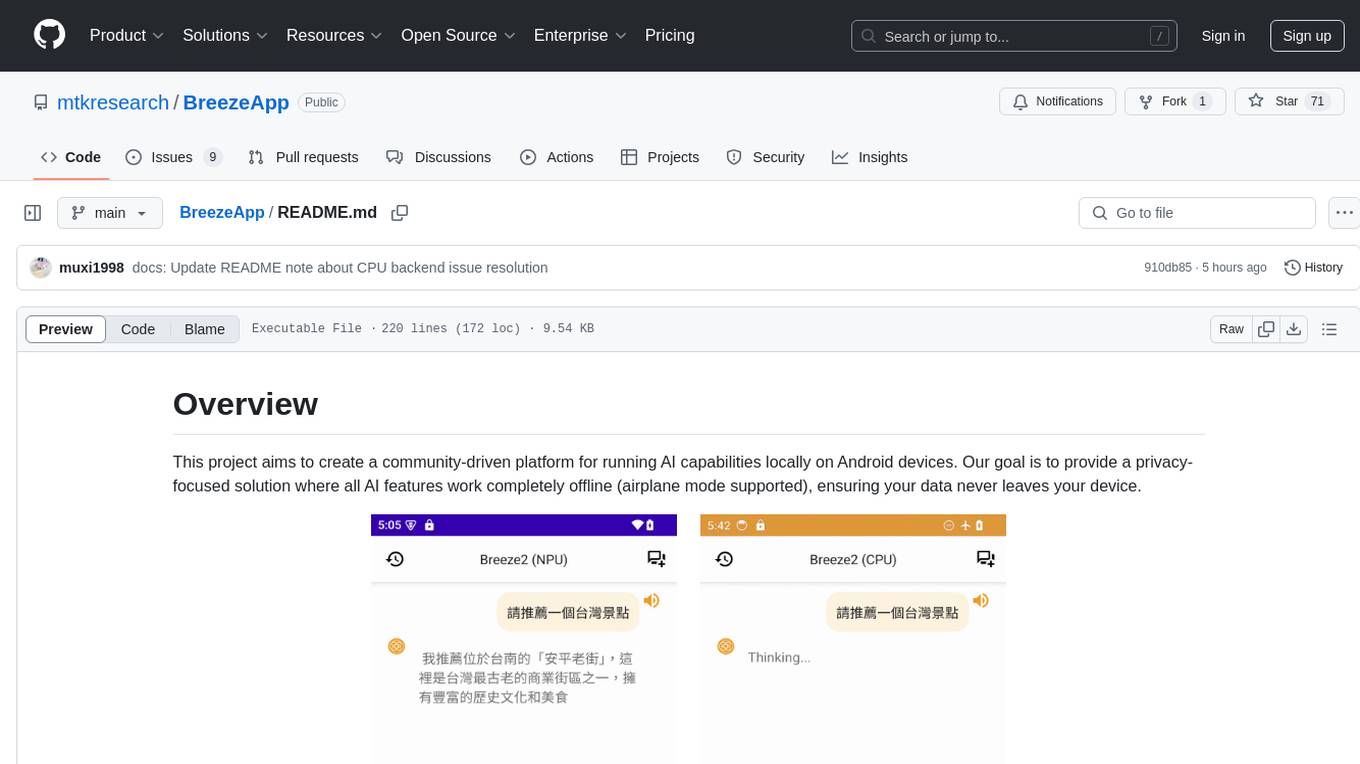
BreezeApp is a community-driven platform for running AI capabilities locally on Android devices. It offers a privacy-focused solution where all AI features work offline, showcasing text-based chat interface, voice input/output support, and image understanding capabilities. The app supports multiple backends for different components and aims to make powerful AI models accessible to users. Users can contribute to the project by reporting issues, suggesting features, submitting pull requests, and sharing feedback. The architecture follows a service-based approach with service implementations for each AI capability. BreezeApp is a research project that may require specific hardware support or proprietary components, providing open-source alternatives where possible.
PureChat
PureChat is a chat application integrated with ChatGPT, featuring efficient application building with Vite5, screenshot generation and copy support for chat records, IM instant messaging SDK for sessions, automatic light and dark mode switching based on system theme, Markdown rendering, code highlighting, and link recognition support, seamless social experience with GitHub quick login, integration of large language models like ChatGPT Ollama for streaming output, preset prompts, and context, Electron desktop app versions for macOS and Windows, ongoing development of more features. Environment setup requires Node.js 18.20+. Clone code with 'git clone https://github.com/Hyk260/PureChat.git', install dependencies with 'pnpm install', start project with 'pnpm dev', and build with 'pnpm build'.
fastapi
智元 Fast API is a one-stop API management system that unifies various LLM APIs in terms of format, standards, and management, achieving the ultimate in functionality, performance, and user experience. It supports various models from companies like OpenAI, Azure, Baidu, Keda Xunfei, Alibaba Cloud, Zhifu AI, Google, DeepSeek, 360 Brain, and Midjourney. The project provides user and admin portals for preview, supports cluster deployment, multi-site deployment, and cross-zone deployment. It also offers Docker deployment, a public API site for registration, and screenshots of the admin and user portals. The API interface is similar to OpenAI's interface, and the project is open source with repositories for API, web, admin, and SDK on GitHub and Gitee.
ChatGLM3
ChatGLM3 is a conversational pretrained model jointly released by Zhipu AI and THU's KEG Lab. ChatGLM3-6B is the open-sourced model in the ChatGLM3 series. It inherits the advantages of its predecessors, such as fluent conversation and low deployment threshold. In addition, ChatGLM3-6B introduces the following features: 1. A stronger foundation model: ChatGLM3-6B's foundation model ChatGLM3-6B-Base employs more diverse training data, more sufficient training steps, and more reasonable training strategies. Evaluation on datasets from different perspectives, such as semantics, mathematics, reasoning, code, and knowledge, shows that ChatGLM3-6B-Base has the strongest performance among foundation models below 10B parameters. 2. More complete functional support: ChatGLM3-6B adopts a newly designed prompt format, which supports not only normal multi-turn dialogue, but also complex scenarios such as tool invocation (Function Call), code execution (Code Interpreter), and Agent tasks. 3. A more comprehensive open-source sequence: In addition to the dialogue model ChatGLM3-6B, the foundation model ChatGLM3-6B-Base, the long-text dialogue model ChatGLM3-6B-32K, and ChatGLM3-6B-128K, which further enhances the long-text comprehension ability, are also open-sourced. All the above weights are completely open to academic research and are also allowed for free commercial use after filling out a questionnaire.
ai-paint-today-BE
AI Paint Today is an API server repository that allows users to record their emotions and daily experiences, and based on that, AI generates a beautiful picture diary of their day. The project includes features such as generating picture diaries from written entries, utilizing DALL-E 2 model for image generation, and deploying on AWS and Cloudflare. The project also follows specific conventions and collaboration strategies for development.

cactus
Cactus is an energy-efficient and fast AI inference framework designed for phones, wearables, and resource-constrained arm-based devices. It provides a bottom-up approach with no dependencies, optimizing for budget and mid-range phones. The framework includes Cactus FFI for integration, Cactus Engine for high-level transformer inference, Cactus Graph for unified computation graph, and Cactus Kernels for low-level ARM-specific operations. It is suitable for implementing custom models and scientific computing on mobile devices.
LLMBook-zh.github.io
This book aims to provide readers with a comprehensive understanding of large language model technology, including its basic principles, key technologies, and application prospects. Through in-depth research and practice, we can continuously explore and improve large language model technology, and contribute to the development of the field of artificial intelligence.
MING
MING is an open-sourced Chinese medical consultation model fine-tuned based on medical instructions. The main functions of the model are as follows: Medical Q&A: answering medical questions and analyzing cases. Intelligent consultation: giving diagnosis results and suggestions after multiple rounds of consultation.
Gensokyo-llm
Gensokyo-llm is a tool designed for Gensokyo and Onebotv11, providing a one-click solution for large models. It supports various Onebotv11 standard frameworks, HTTP-API, and reverse WS. The tool is lightweight, with built-in SQLite for context maintenance and proxy support. It allows easy integration with the Gensokyo framework by configuring reverse HTTP and forward HTTP addresses. Users can set system settings, role cards, and context length. Additionally, it offers an openai original flavor API with automatic context. The tool can be used as an API or integrated with QQ channel robots. It supports converting GPT's SSE type and ensures memory safety in concurrent SSE environments. The tool also supports multiple users simultaneously transmitting SSE bidirectionally.
PyTorch-Tutorial-2nd
The second edition of "PyTorch Practical Tutorial" was completed after 5 years, 4 years, and 2 years. On the basis of the essence of the first edition, rich and detailed deep learning application cases and reasoning deployment frameworks have been added, so that this book can more systematically cover the knowledge involved in deep learning engineers. As the development of artificial intelligence technology continues to emerge, the second edition of "PyTorch Practical Tutorial" is not the end, but the beginning, opening up new technologies, new fields, and new chapters. I hope to continue learning and making progress in artificial intelligence technology with you in the future.
api-for-open-llm
This project provides a unified backend interface for open large language models (LLMs), offering a consistent experience with OpenAI's ChatGPT API. It supports various open-source LLMs, enabling developers to seamlessly integrate them into their applications. The interface features streaming responses, text embedding capabilities, and support for LangChain, a tool for developing LLM-based applications. By modifying environment variables, developers can easily use open-source models as alternatives to ChatGPT, providing a cost-effective and customizable solution for various use cases.
BetterOCR
BetterOCR is a tool that enhances text detection by combining multiple OCR engines with LLM (Language Model). It aims to improve OCR results, especially for languages with limited training data or noisy outputs. The tool combines results from EasyOCR, Tesseract, and Pororo engines, along with LLM support from OpenAI. Users can provide custom context for better accuracy, view performance examples by language, and upcoming features include box detection, improved interface, and async support. The package is under rapid development and contributions are welcomed.
HMusic
HMusic is an intelligent music player that supports Xiaomi AI speakers. It offers dual modes: xiaomusic server mode and Xiaomi IoT direct connection mode. Users can choose between these modes based on their preferences and needs. The direct connection mode is suitable for regular users who want a plug-and-play experience, while the xiaomusic mode is ideal for users with NAS/servers who require advanced features like a local music library, playlists, and progress control. The tool provides functionalities such as music search, playback, and volume control, catering to a wide range of music enthusiasts.
runanywhere-sdks
RunAnywhere is an on-device AI tool for mobile apps that allows users to run LLMs, speech-to-text, text-to-speech, and voice assistant features locally, ensuring privacy, offline functionality, and fast performance. The tool provides a range of AI capabilities without relying on cloud services, reducing latency and ensuring that no data leaves the device. RunAnywhere offers SDKs for Swift (iOS/macOS), Kotlin (Android), React Native, and Flutter, making it easy for developers to integrate AI features into their mobile applications. The tool supports various models for LLM, speech-to-text, and text-to-speech, with detailed documentation and installation instructions available for each platform.

langfuse
Langfuse is a powerful tool that helps you develop, monitor, and test your LLM applications. With Langfuse, you can: * **Develop:** Instrument your app and start ingesting traces to Langfuse, inspect and debug complex logs, and manage, version, and deploy prompts from within Langfuse. * **Monitor:** Track metrics (cost, latency, quality) and gain insights from dashboards & data exports, collect and calculate scores for your LLM completions, run model-based evaluations, collect user feedback, and manually score observations in Langfuse. * **Test:** Track and test app behaviour before deploying a new version, test expected in and output pairs and benchmark performance before deploying, and track versions and releases in your application. Langfuse is easy to get started with and offers a generous free tier. You can sign up for Langfuse Cloud or deploy Langfuse locally or on your own infrastructure. Langfuse also offers a variety of integrations to make it easy to connect to your LLM applications.
For similar tasks
Wechat-AI-Assistant
Wechat AI Assistant is a project that enables multi-modal interaction with ChatGPT AI assistant within WeChat. It allows users to engage in conversations, role-playing, respond to voice messages, analyze images and videos, summarize articles and web links, and search the internet. The project utilizes the WeChatFerry library to control the Windows PC desktop WeChat client and leverages the OpenAI Assistant API for intelligent multi-modal message processing. Users can interact with ChatGPT AI in WeChat through text or voice, access various tools like bing_search, browse_link, image_to_text, text_to_image, text_to_speech, video_analysis, and more. The AI autonomously determines which code interpreter and external tools to use to complete tasks. Future developments include file uploads for AI to reference content, integration with other APIs, and login support for enterprise WeChat and WeChat official accounts.
aihub
AI Hub is a comprehensive solution that leverages artificial intelligence and cloud computing to provide functionalities such as document search and retrieval, call center analytics, image analysis, brand reputation analysis, form analysis, document comparison, and content safety moderation. It integrates various Azure services like Cognitive Search, ChatGPT, Azure Vision Services, and Azure Document Intelligence to offer scalable, extensible, and secure AI-powered capabilities for different use cases and scenarios.
ai-microcore
MicroCore is a collection of python adapters for Large Language Models and Vector Databases / Semantic Search APIs. It allows convenient communication with these services, easy switching between models & services, and separation of business logic from implementation details. Users can keep applications simple and try various models & services without changing application code. MicroCore connects MCP tools to language models easily, supports text completion and chat completion models, and provides features for configuring, installing vendor-specific packages, and using vector databases.

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.

airunner
AI Runner is a multi-modal AI interface that allows users to run open-source large language models and AI image generators on their own hardware. The tool provides features such as voice-based chatbot conversations, text-to-speech, speech-to-text, vision-to-text, text generation with large language models, image generation capabilities, image manipulation tools, utility functions, and more. It aims to provide a stable and user-friendly experience with security updates, a new UI, and a streamlined installation process. The application is designed to run offline on users' hardware without relying on a web server, offering a smooth and responsive user experience.
Generative-AI-Pharmacist
Generative AI Pharmacist is a project showcasing the use of generative AI tools to create an animated avatar named Macy, who delivers medication counseling in a realistic and professional manner. The project utilizes tools like Midjourney for image generation, ChatGPT for text generation, ElevenLabs for text-to-speech conversion, and D-ID for creating a photorealistic talking avatar video. The demo video featuring Macy discussing commonly-prescribed medications demonstrates the potential of generative AI in healthcare communication.
AnyGPT
AnyGPT is a unified multimodal language model that utilizes discrete representations for processing various modalities like speech, text, images, and music. It aligns the modalities for intermodal conversions and text processing. AnyInstruct dataset is constructed for generative models. The model proposes a generative training scheme using Next Token Prediction task for training on a Large Language Model (LLM). It aims to compress vast multimodal data on the internet into a single model for emerging capabilities. The tool supports tasks like text-to-image, image captioning, ASR, TTS, text-to-music, and music captioning.
Pallaidium
Pallaidium is a generative AI movie studio integrated into the Blender video editor. It allows users to AI-generate video, image, and audio from text prompts or existing media files. The tool provides various features such as text to video, text to audio, text to speech, text to image, image to image, image to video, video to video, image to text, and more. It requires a Windows system with a CUDA-supported Nvidia card and at least 6 GB VRAM. Pallaidium offers batch processing capabilities, text to audio conversion using Bark, and various performance optimization tips. Users can install the tool by downloading the add-on and following the installation instructions provided. The tool comes with a set of restrictions on usage, prohibiting the generation of harmful, pornographic, violent, or false content.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.