Best AI tools for< Reconstruct Scenes >
4 - AI tool Sites
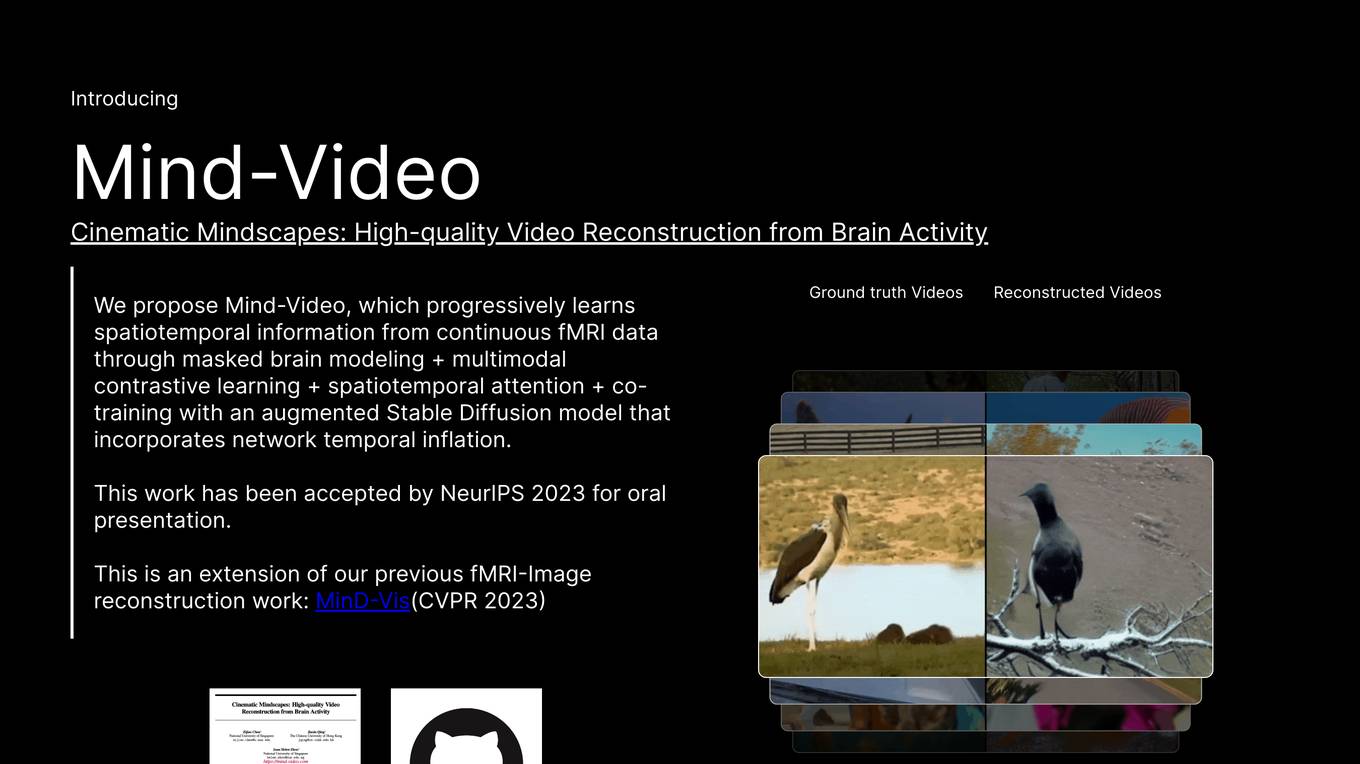
Mind-Video
Mind-Video is an AI tool that focuses on high-quality video reconstruction from brain activity data. It bridges the gap between image and video brain decoding by utilizing masked brain modeling, multimodal contrastive learning, spatiotemporal attention, and co-training with an augmented Stable Diffusion model. The tool aims to recover accurate semantic information from fMRI signals, enabling the generation of realistic videos based on brain activities.
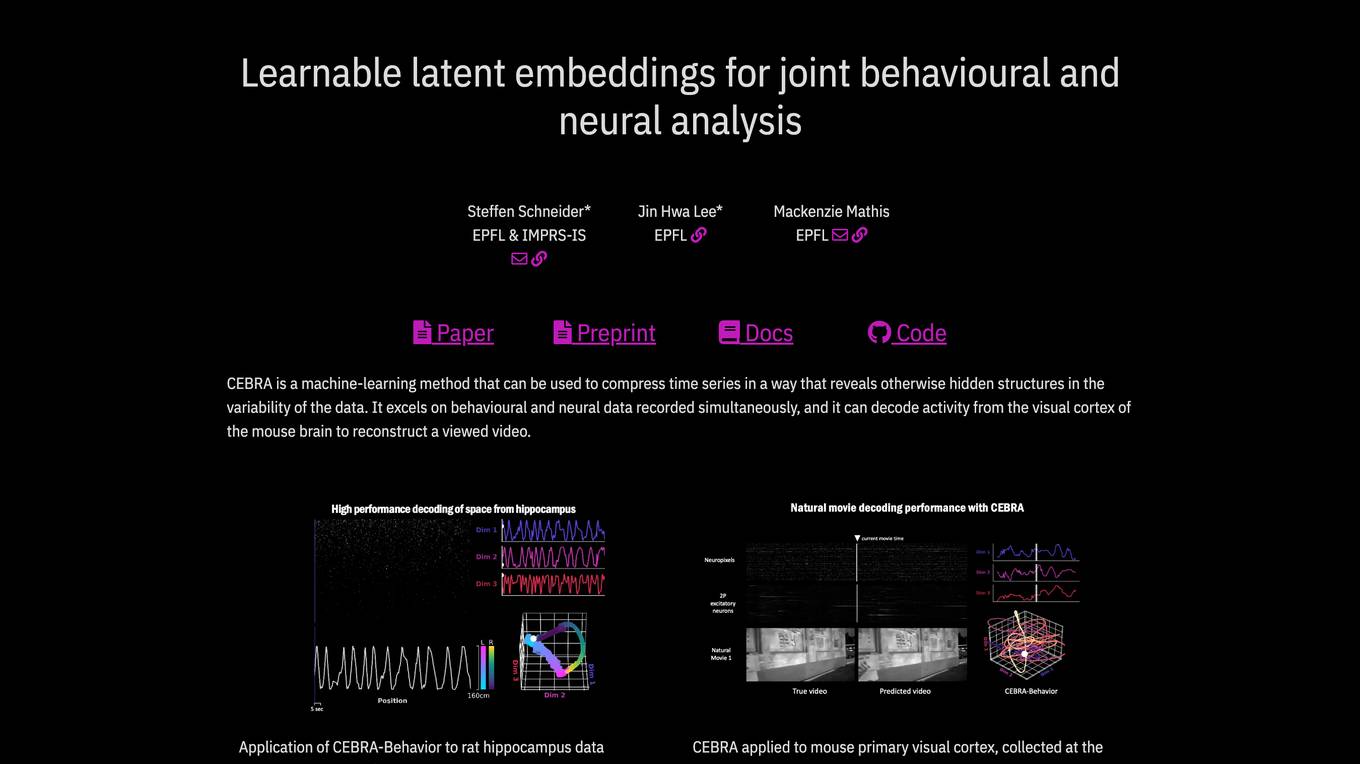
CEBRA
CEBRA is a self-supervised learning algorithm that provides interpretable embeddings of high-dimensional recordings using auxiliary variables. It excels in compressing time series data to reveal hidden structures, particularly in behavioral and neural data. The algorithm can decode activity from the visual cortex, reconstruct viewed videos, decode trajectories, and determine position during navigation. CEBRA is a valuable tool for joint behavioral and neural analysis, offering consistent and high-performance latent spaces for hypothesis testing and label-free usage across various datasets and species.

Remover.app
Remover.app is a free online tool that allows you to remove unwanted objects, people, or defects from your photos. It uses artificial intelligence to reconstruct the background behind the object, so you can achieve professional results in just a few clicks. Remover.app is easy to use, simply upload your photo and brush over the object you want to remove. The AI will do the rest! Remover.app is perfect for removing unwanted objects from product photos, real estate photos, and even family photos. It's also great for removing blemishes, wrinkles, and other imperfections from your photos.
Historica
Historica is an AI-powered history map application that offers a unique and immersive experience by crafting historical maps of civilizations' timelines. It leverages artificial intelligence to reconstruct landscapes of centuries past, providing users with a rich tapestry of history. The application aims to bring the world's history to life through technology and open access, enabling users to explore and learn about historical events in a visually engaging manner.
1 - Open Source AI Tools
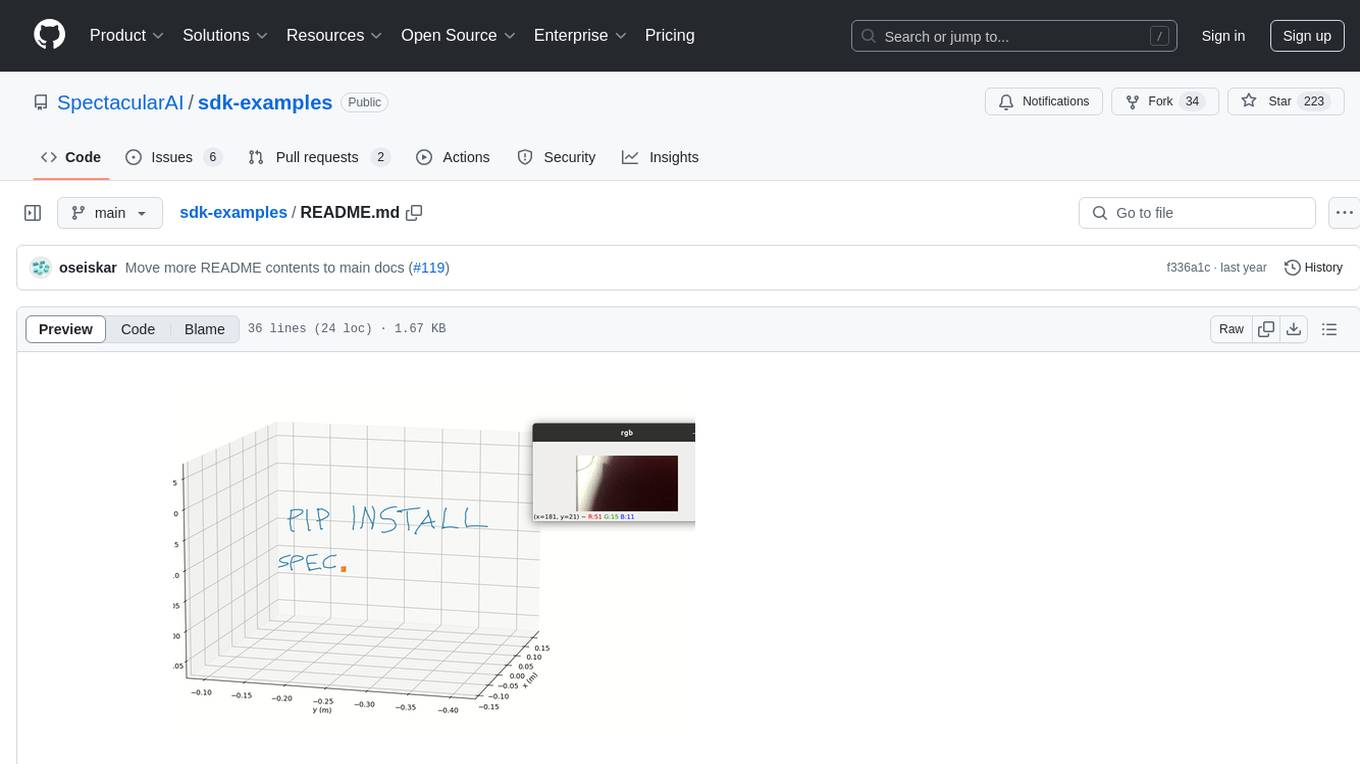
sdk-examples
Spectacular AI SDK fuses data from cameras and IMU sensors to output an accurate 6-degree-of-freedom pose of a device, enabling Visual-Inertial SLAM for tracking robots and vehicles, as well as Augmented, Mixed, and Virtual Reality. The SDK includes a Mapping API for real-time and offline 3D reconstruction use cases.
4 - OpenAI Gpts
Justice A.I.
The first-ever Multifaceted AI Chat Bot designed to deconstruct bias across all sectors.