
BIG-Bench-Mistake
A dataset of LLM-generated chain-of-thought steps annotated with mistake location.
Stars: 62
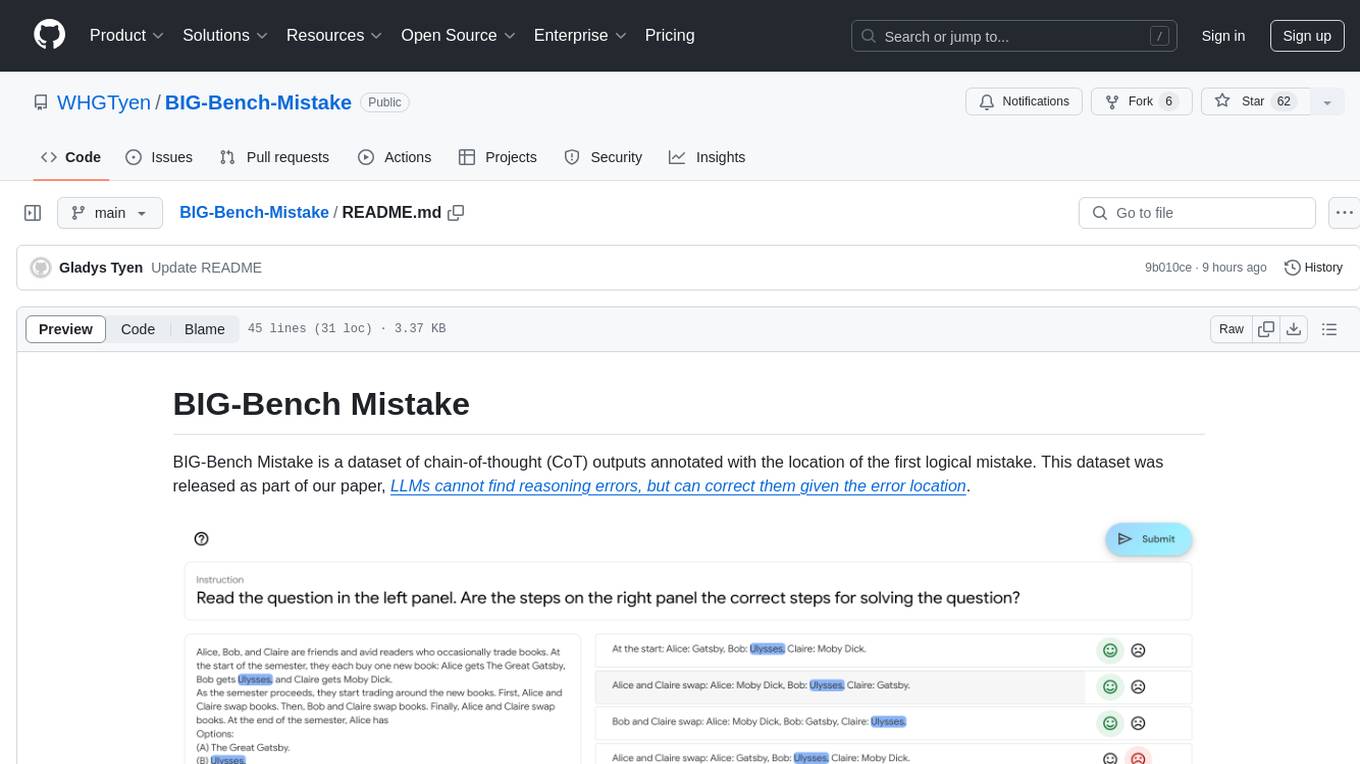
BIG-Bench Mistake is a dataset of chain-of-thought (CoT) outputs annotated with the location of the first logical mistake. It was released as part of a research paper focusing on benchmarking LLMs in terms of their mistake-finding ability. The dataset includes CoT traces for tasks like Word Sorting, Tracking Shuffled Objects, Logical Deduction, Multistep Arithmetic, and Dyck Languages. Human annotators were recruited to identify mistake steps in these tasks, with automated annotation for Dyck Languages. Each JSONL file contains input questions, steps in the chain of thoughts, model's answer, correct answer, and the index of the first logical mistake.
README:
BIG-Bench Mistake is a dataset of chain-of-thought (CoT) outputs annotated with the location of the first logical mistake. This dataset was released as part of our paper, LLMs cannot find reasoning errors, but can correct them given the error location.

In our paper, we use this dataset to benchmark LLMs in terms of their mistake-finding ability. We try 3 diffrent types of prompting, and find that LLMs struggle to identify logical mistakes. Results from GPT-4-Turbo, GPT-4, GPT-3.5-Turbo, Gemini Pro, and PaLM 2 Unicorn are shown below; for further details, please refer to our paper. Prompts used for mistake finding are found here.

We use PaLM 2-L (Unicorn) to generate CoT traces for 5 tasks:
- Word Sorting
- Tracking Shuffled Objects
- Logical Deduction
- Multistep arithmetic
- Dyck Languages
In our experiments, we treat Tracking Shuffled Objects and Logical Deduction as multiple choice tasks, while for Word Sorting, Multistep Arithmetic, and Dyck Languages we use exact matching.
We then recruit human annotators to identify mistake steps in 4 of the 5 tasks. For Dyck languages, we automatically annotate most of the traces using annotate_dyck_langauges.py. For further details, please refer to our paper.
Each JSONL file contains outputs for a task from the BIGBench dataset. Each line contains a dictionary with the following keys:
-
input: A string containing the input question. For multiple choice tasks (Tracking Shuffled Objects and Logical Deduction), this also includes the options. -
steps: A list of strings containing each step in the chain of thoughts. Note that this does not include the prefixesThought 1:,Thought 2:, etc. -
answer: A string containing the model's answer, extracted from the list of steps using the regex(?<=[Tt]he answer is).*$. For multiple choice tasks (Tracking Shuffled Objects and Logical Deduction), this is the letter indicating the option (e.g.(A)). -
target: A string containing the target "correct" answer. -
mistake_index: The index of the step containing the first logical mistake. Please note that this number is 0-indexed, so 0 indicates a mistake in the first step, 1 indicates a mistake in the second step, and so on. If there are no mistakes, this value is null.
@inproceedings{tyen-etal-2024-llms,
title = "{LLMs} cannot find reasoning errors, but can correct them given the error location",
author = "Tyen, Gladys and Mansoor, Hassan and C\u{a}rbune, Victor and Chen, Peter and Mak, Tony",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2024",
year = "2024",
publisher = "Association for Computational Linguistics",
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for BIG-Bench-Mistake
Similar Open Source Tools
BIG-Bench-Mistake
BIG-Bench Mistake is a dataset of chain-of-thought (CoT) outputs annotated with the location of the first logical mistake. It was released as part of a research paper focusing on benchmarking LLMs in terms of their mistake-finding ability. The dataset includes CoT traces for tasks like Word Sorting, Tracking Shuffled Objects, Logical Deduction, Multistep Arithmetic, and Dyck Languages. Human annotators were recruited to identify mistake steps in these tasks, with automated annotation for Dyck Languages. Each JSONL file contains input questions, steps in the chain of thoughts, model's answer, correct answer, and the index of the first logical mistake.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.

FigStep
FigStep is a black-box jailbreaking algorithm against large vision-language models (VLMs). It feeds harmful instructions through the image channel and uses benign text prompts to induce VLMs to output contents that violate common AI safety policies. The tool highlights the vulnerability of VLMs to jailbreaking attacks, emphasizing the need for safety alignments between visual and textual modalities.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!
Graph-CoT
This repository contains the source code and datasets for Graph Chain-of-Thought: Augmenting Large Language Models by Reasoning on Graphs accepted to ACL 2024. It proposes a framework called Graph Chain-of-thought (Graph-CoT) to enable Language Models to traverse graphs step-by-step for reasoning, interaction, and execution. The motivation is to alleviate hallucination issues in Language Models by augmenting them with structured knowledge sources represented as graphs.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.

LiveBench
LiveBench is a benchmark tool designed for Language Model Models (LLMs) with a focus on limiting contamination through monthly new questions based on recent datasets, arXiv papers, news articles, and IMDb movie synopses. It provides verifiable, objective ground-truth answers for accurate scoring without an LLM judge. The tool offers 18 diverse tasks across 6 categories and promises to release more challenging tasks over time. LiveBench is built on FastChat's llm_judge module and incorporates code from LiveCodeBench and IFEval.

rag-experiment-accelerator
The RAG Experiment Accelerator is a versatile tool that helps you conduct experiments and evaluations using Azure AI Search and RAG pattern. It offers a rich set of features, including experiment setup, integration with Azure AI Search, Azure Machine Learning, MLFlow, and Azure OpenAI, multiple document chunking strategies, query generation, multiple search types, sub-querying, re-ranking, metrics and evaluation, report generation, and multi-lingual support. The tool is designed to make it easier and faster to run experiments and evaluations of search queries and quality of response from OpenAI, and is useful for researchers, data scientists, and developers who want to test the performance of different search and OpenAI related hyperparameters, compare the effectiveness of various search strategies, fine-tune and optimize parameters, find the best combination of hyperparameters, and generate detailed reports and visualizations from experiment results.

minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.
parsee-core
Parsee AI is a high-level open source data extraction and structuring framework specialized for the extraction of data from a financial domain, but can be used for other use-cases as well. It aims to make the structuring of data from unstructured sources like PDFs, HTML files, and images as easy as possible. Parsee can be used locally in Python environments or through a hosted version for cloud-based jobs. It supports the extraction of tables, numbers, and other data elements, with the ability to create custom extraction templates and run jobs using different models.

pgai
pgai simplifies the process of building search and Retrieval Augmented Generation (RAG) AI applications with PostgreSQL. It brings embedding and generation AI models closer to the database, allowing users to create embeddings, retrieve LLM chat completions, reason over data for classification, summarization, and data enrichment directly from within PostgreSQL in a SQL query. The tool requires an OpenAI API key and a PostgreSQL client to enable AI functionality in the database. Users can install pgai from source, run it in a pre-built Docker container, or enable it in a Timescale Cloud service. The tool provides functions to handle API keys using psql or Python, and offers various AI functionalities like tokenizing, detokenizing, embedding, chat completion, and content moderation.
gptauthor
GPT Author is a command-line tool designed to help users write long form, multi-chapter stories by providing a story prompt and generating a synopsis and subsequent chapters using ChatGPT. Users can review and make changes to the generated content before finalizing the story output in Markdown and HTML formats. The tool aims to unleash storytelling genius by combining human input with AI-generated content, offering a seamless writing experience for creating engaging narratives.

Woodpecker
Woodpecker is a tool designed to correct hallucinations in Multimodal Large Language Models (MLLMs) by introducing a training-free method that picks out and corrects inconsistencies between generated text and image content. It consists of five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction. Woodpecker can be easily integrated with different MLLMs and provides interpretable results by accessing intermediate outputs of the stages. The tool has shown significant improvements in accuracy over baseline models like MiniGPT-4 and mPLUG-Owl.
cameratrapai
SpeciesNet is an ensemble of AI models designed for classifying wildlife in camera trap images. It consists of an object detector that finds objects of interest in wildlife camera images and an image classifier that classifies those objects to the species level. The ensemble combines these two models using heuristics and geographic information to assign each image to a single category. The models have been trained on a large dataset of camera trap images and are used for species recognition in the Wildlife Insights platform.
For similar tasks
BIG-Bench-Mistake
BIG-Bench Mistake is a dataset of chain-of-thought (CoT) outputs annotated with the location of the first logical mistake. It was released as part of a research paper focusing on benchmarking LLMs in terms of their mistake-finding ability. The dataset includes CoT traces for tasks like Word Sorting, Tracking Shuffled Objects, Logical Deduction, Multistep Arithmetic, and Dyck Languages. Human annotators were recruited to identify mistake steps in these tasks, with automated annotation for Dyck Languages. Each JSONL file contains input questions, steps in the chain of thoughts, model's answer, correct answer, and the index of the first logical mistake.

ailia-models
The collection of pre-trained, state-of-the-art AI models. ailia SDK is a self-contained, cross-platform, high-speed inference SDK for AI. The ailia SDK provides a consistent C++ API across Windows, Mac, Linux, iOS, Android, Jetson, and Raspberry Pi platforms. It also supports Unity (C#), Python, Rust, Flutter(Dart) and JNI for efficient AI implementation. The ailia SDK makes extensive use of the GPU through Vulkan and Metal to enable accelerated computing. # Supported models 323 models as of April 8th, 2024
Vitron
Vitron is a unified pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing static images and dynamic videos. It addresses challenges in existing vision LLMs such as superficial instance-level understanding, lack of unified support for images and videos, and insufficient coverage across various vision tasks. The tool requires Python >= 3.8, Pytorch == 2.1.0, and CUDA Version >= 11.8 for installation. Users can deploy Gradio demo locally and fine-tune their models for specific tasks.
sdk-examples
Spectacular AI SDK fuses data from cameras and IMU sensors to output an accurate 6-degree-of-freedom pose of a device, enabling Visual-Inertial SLAM for tracking robots and vehicles, as well as Augmented, Mixed, and Virtual Reality. The SDK includes a Mapping API for real-time and offline 3D reconstruction use cases.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.