
graph-of-thoughts
Official Implementation of "Graph of Thoughts: Solving Elaborate Problems with Large Language Models"
Stars: 2076
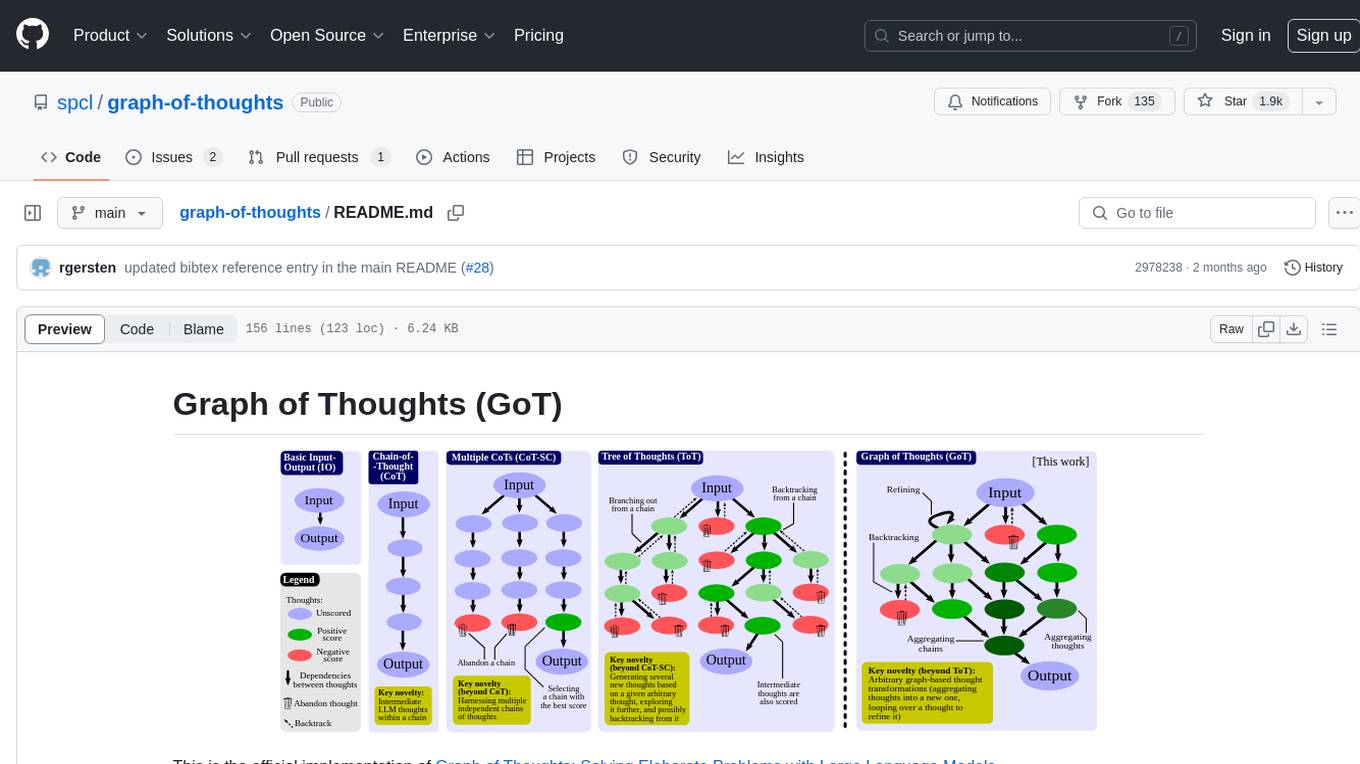
Graph of Thoughts (GoT) is an official implementation framework designed to solve complex problems by modeling them as a Graph of Operations (GoO) executed with a Large Language Model (LLM) engine. It offers flexibility to implement various approaches like CoT or ToT, allowing users to solve problems using the new GoT approach. The framework includes setup guides, quick start examples, documentation, and examples for users to understand and utilize the tool effectively.
README:

This is the official implementation of Graph of Thoughts: Solving Elaborate Problems with Large Language Models.
This framework gives you the ability to solve complex problems by modeling them as a Graph of Operations (GoO), which is automatically executed with a Large Language Model (LLM) as the engine.
This framework is designed to be flexible and extensible, allowing you to not only solve problems using the new GoT approach, but also to implement GoOs resembling previous approaches like CoT or ToT.
In order to use this framework, you need to have a working installation of Python 3.8 or newer.
Before running either of the following two installation methods, make sure to activate your Python environment (if any) beforehand.
If you are a user and you just want to use graph_of_thoughts, you can install it directly from PyPI:
pip install graph_of_thoughtsIf you are a developer and you want to modify the code, you can install it in editable mode from source:
git clone https://github.com/spcl/graph-of-thoughts.git
cd graph-of-thoughts
pip install -e .In order to use the framework, you need to have access to an LLM. Please follow the instructions in the Controller README to configure the LLM of your choice.
The following code snippet shows how to use the framework to solve the sorting problem for a list of 32 numbers using a CoT-like approach.
Make sure you have followed the Setup Guide before running the code.
from examples.sorting.sorting_032 import SortingPrompter, SortingParser, utils
from graph_of_thoughts import controller, language_models, operations
# Problem input
to_be_sorted = "[0, 2, 6, 3, 8, 7, 1, 1, 6, 7, 7, 7, 7, 9, 3, 0, 1, 7, 9, 1, 3, 5, 1, 3, 6, 4, 5, 4, 7, 3, 5, 7]"
# Create the Graph of Operations
gop = operations.GraphOfOperations()
gop.append_operation(operations.Generate())
gop.append_operation(operations.Score(scoring_function=utils.num_errors))
gop.append_operation(operations.GroundTruth(utils.test_sorting))
# Configure the Language Model (Assumes config.json is in the current directory with OpenAI API key)
lm = language_models.ChatGPT("config.json", model_name="chatgpt")
# Create the Controller
ctrl = controller.Controller(
lm,
gop,
SortingPrompter(),
SortingParser(),
# The following dictionary is used to configure the initial thought state
{
"original": to_be_sorted,
"current": "",
"method": "cot"
}
)
# Run the Controller and generate the output graph
ctrl.run()
ctrl.output_graph("output_cot.json")To run the more sophisticated GoT approach, you can use the following code snippet.
from examples.sorting.sorting_032 import SortingPrompter, SortingParser, got, utils
from graph_of_thoughts import controller, language_models, operations
# Problem input
to_be_sorted = "[0, 2, 6, 3, 8, 7, 1, 1, 6, 7, 7, 7, 7, 9, 3, 0, 1, 7, 9, 1, 3, 5, 1, 3, 6, 4, 5, 4, 7, 3, 5, 7]"
# Retrieve the Graph of Operations
gop = got()
# Configure the Language Model (Assumes config.json is in the current directory with OpenAI API key)
lm = language_models.ChatGPT("config.json", model_name="chatgpt")
# Create the Controller
ctrl = controller.Controller(
lm,
gop,
SortingPrompter(),
SortingParser(),
# The following dictionary is used to configure the initial thought state
{
"original": to_be_sorted,
"current": "",
"phase": 0,
"method": "got"
}
)
# Run the Controller and generate the output graph
ctrl.run()
ctrl.output_graph("output_got.json")You can compare the two results by inspecting the output graphs output_cot.json and output_got.json.
The final thought states' scores indicate the number of errors in the sorted list.
The paper gives a high-level overview of the framework and its components.
In order to understand the framework in more detail, you can read the documentation of the individual modules.
Especially the Controller and Operations modules are important for understanding how to make the most out of the framework.
We took extra care to fully document the code, so that you can easily understand how it works and how to extend it.
The examples directory contains several examples of problems that can be solved using the framework, including the ones presented in the paper.
It is a great starting point for learning how to use the framework to solve real problems.
Each example contains a README.md file with instructions on how to run it and play with it. The code is fully documented and should be easy to follow.
You can also run the examples straight from the main directory. Note that the results will be stored in the respective examples sub-directory.
Try for instance:
python -m examples.sorting.sorting_032
python -m examples.keyword_counting.keyword_countingYou can run the experiments from the paper by following the instructions in the examples directory.
However, if you just want to inspect and replot the results, you can use the paper directory.
If you find this repository valuable, please give it a star!
Got any questions or feedback? Feel free to reach out to [email protected] or open an issue.
Using this in your work? Please reference us using the provided citation:
@article{besta2024got,
title = {{Graph of Thoughts: Solving Elaborate Problems with Large Language Models}},
author = {Besta, Maciej and Blach, Nils and Kubicek, Ales and Gerstenberger, Robert and Gianinazzi, Lukas and Gajda, Joanna and Lehmann, Tomasz and Podstawski, Micha{\l} and Niewiadomski, Hubert and Nyczyk, Piotr and Hoefler, Torsten},
year = 2024,
month = {Mar},
journal = {Proceedings of the AAAI Conference on Artificial Intelligence},
volume = 38,
number = 16,
pages = {17682-17690},
publisher = {AAAI Press},
doi = {10.1609/aaai.v38i16.29720},
url = {https://ojs.aaai.org/index.php/AAAI/article/view/29720}
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for graph-of-thoughts
Similar Open Source Tools
graph-of-thoughts
Graph of Thoughts (GoT) is an official implementation framework designed to solve complex problems by modeling them as a Graph of Operations (GoO) executed with a Large Language Model (LLM) engine. It offers flexibility to implement various approaches like CoT or ToT, allowing users to solve problems using the new GoT approach. The framework includes setup guides, quick start examples, documentation, and examples for users to understand and utilize the tool effectively.

llm-reasoners
LLM Reasoners is a library that enables LLMs to conduct complex reasoning, with advanced reasoning algorithms. It approaches multi-step reasoning as planning and searches for the optimal reasoning chain, which achieves the best balance of exploration vs exploitation with the idea of "World Model" and "Reward". Given any reasoning problem, simply define the reward function and an optional world model (explained below), and let LLM reasoners take care of the rest, including Reasoning Algorithms, Visualization, LLM calling, and more!
backtrack_sampler
Backtrack Sampler is a framework for experimenting with custom sampling algorithms that can backtrack the latest generated tokens. It provides a simple and easy-to-understand codebase for creating new sampling strategies. Users can implement their own strategies by creating new files in the `/strategy` directory. The repo includes examples for usage with llama.cpp and transformers, showcasing different strategies like Creative Writing, Anti-slop, Debug, Human Guidance, Adaptive Temperature, and Replace. The goal is to encourage experimentation and customization of backtracking algorithms for language models.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.

minbpe
This repository contains a minimal, clean code implementation of the Byte Pair Encoding (BPE) algorithm, commonly used in LLM tokenization. The BPE algorithm is "byte-level" because it runs on UTF-8 encoded strings. This algorithm was popularized for LLMs by the GPT-2 paper and the associated GPT-2 code release from OpenAI. Sennrich et al. 2015 is cited as the original reference for the use of BPE in NLP applications. Today, all modern LLMs (e.g. GPT, Llama, Mistral) use this algorithm to train their tokenizers. There are two Tokenizers in this repository, both of which can perform the 3 primary functions of a Tokenizer: 1) train the tokenizer vocabulary and merges on a given text, 2) encode from text to tokens, 3) decode from tokens to text. The files of the repo are as follows: 1. minbpe/base.py: Implements the `Tokenizer` class, which is the base class. It contains the `train`, `encode`, and `decode` stubs, save/load functionality, and there are also a few common utility functions. This class is not meant to be used directly, but rather to be inherited from. 2. minbpe/basic.py: Implements the `BasicTokenizer`, the simplest implementation of the BPE algorithm that runs directly on text. 3. minbpe/regex.py: Implements the `RegexTokenizer` that further splits the input text by a regex pattern, which is a preprocessing stage that splits up the input text by categories (think: letters, numbers, punctuation) before tokenization. This ensures that no merges will happen across category boundaries. This was introduced in the GPT-2 paper and continues to be in use as of GPT-4. This class also handles special tokens, if any. 4. minbpe/gpt4.py: Implements the `GPT4Tokenizer`. This class is a light wrapper around the `RegexTokenizer` (2, above) that exactly reproduces the tokenization of GPT-4 in the tiktoken library. The wrapping handles some details around recovering the exact merges in the tokenizer, and the handling of some unfortunate (and likely historical?) 1-byte token permutations. Finally, the script train.py trains the two major tokenizers on the input text tests/taylorswift.txt (this is the Wikipedia entry for her kek) and saves the vocab to disk for visualization. This script runs in about 25 seconds on my (M1) MacBook. All of the files above are very short and thoroughly commented, and also contain a usage example on the bottom of the file.

Open-Prompt-Injection
OpenPromptInjection is an open-source toolkit for attacks and defenses in LLM-integrated applications, enabling easy implementation, evaluation, and extension of attacks, defenses, and LLMs. It supports various attack and defense strategies, including prompt injection, paraphrasing, retokenization, data prompt isolation, instructional prevention, sandwich prevention, perplexity-based detection, LLM-based detection, response-based detection, and know-answer detection. Users can create models, tasks, and apps to evaluate different scenarios. The toolkit currently supports PaLM2 and provides a demo for querying models with prompts. Users can also evaluate ASV for different scenarios by injecting tasks and querying models with attacked data prompts.

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

pydantic-ai
PydanticAI is a Python agent framework designed to make it less painful to build production grade applications with Generative AI. It is built by the Pydantic Team and supports various AI models like OpenAI, Anthropic, Gemini, Ollama, Groq, and Mistral. PydanticAI seamlessly integrates with Pydantic Logfire for real-time debugging, performance monitoring, and behavior tracking of LLM-powered applications. It is type-safe, Python-centric, and offers structured responses, dependency injection system, and streamed responses. PydanticAI is in early beta, offering a Python-centric design to apply standard Python best practices in AI-driven projects.

langevals
LangEvals is an all-in-one Python library for testing and evaluating LLM models. It can be used in notebooks for exploration, in pytest for writing unit tests, or as a server API for live evaluations and guardrails. The library is modular, with 20+ evaluators including Ragas for RAG quality, OpenAI Moderation, and Azure Jailbreak detection. LangEvals powers LangWatch evaluations and provides tools for batch evaluations on notebooks and unit test evaluations with PyTest. It also offers LangEvals evaluators for LLM-as-a-Judge scenarios and out-of-the-box evaluators for language detection and answer relevancy checks.

matsciml
The Open MatSci ML Toolkit is a flexible framework for machine learning in materials science. It provides a unified interface to a variety of materials science datasets, as well as a set of tools for data preprocessing, model training, and evaluation. The toolkit is designed to be easy to use for both beginners and experienced researchers, and it can be used to train models for a wide range of tasks, including property prediction, materials discovery, and materials design.
comfyui_LLM_party
COMFYUI LLM PARTY is a node library designed for LLM workflow development in ComfyUI, an extremely minimalist UI interface primarily used for AI drawing and SD model-based workflows. The project aims to provide a complete set of nodes for constructing LLM workflows, enabling users to easily integrate them into existing SD workflows. It features various functionalities such as API integration, local large model integration, RAG support, code interpreters, online queries, conditional statements, looping links for large models, persona mask attachment, and tool invocations for weather lookup, time lookup, knowledge base, code execution, web search, and single-page search. Users can rapidly develop web applications using API + Streamlit and utilize LLM as a tool node. Additionally, the project includes an omnipotent interpreter node that allows the large model to perform any task, with recommendations to use the 'show_text' node for display output.
parsee-core
Parsee AI is a high-level open source data extraction and structuring framework specialized for the extraction of data from a financial domain, but can be used for other use-cases as well. It aims to make the structuring of data from unstructured sources like PDFs, HTML files, and images as easy as possible. Parsee can be used locally in Python environments or through a hosted version for cloud-based jobs. It supports the extraction of tables, numbers, and other data elements, with the ability to create custom extraction templates and run jobs using different models.
keras-hub
KerasHub is a pretrained modeling library that provides Keras 3 implementations of popular model architectures with pretrained checkpoints. It supports text, image, and audio data for generation, classification, and other tasks. Models are compatible with JAX, TensorFlow, and PyTorch, and can be fine-tuned on GPUs and TPUs. KerasHub components are provided as Layer and Model implementations, extending the core Keras API.

llms
The 'llms' repository is a comprehensive guide on Large Language Models (LLMs), covering topics such as language modeling, applications of LLMs, statistical language modeling, neural language models, conditional language models, evaluation methods, transformer-based language models, practical LLMs like GPT and BERT, prompt engineering, fine-tuning LLMs, retrieval augmented generation, AI agents, and LLMs for computer vision. The repository provides detailed explanations, examples, and tools for working with LLMs.
AIW
AIW is a code base for experiments and raw data related to Alice in Wonderland, showcasing complete reasoning breakdown in state-of-the-art large language models. Users can collect experiments data using LiteLLM and TogetherAI, and plot the data using provided scripts. The tool allows for executing experiments over LiteLLM and lmsys, with options for different prompt types and AIW variations. The project also includes acknowledgments and a citation for reference.

sdkit
sdkit (stable diffusion kit) is an easy-to-use library for utilizing Stable Diffusion in AI Art projects. It includes features like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN, CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for custom VAEs, NSFW filter, model-downloader, parallel GPU support, and more. It offers a model database, auto-scanning for malicious models, and various optimizations. The API consists of modules for loading models, generating images, filters, model merging, and utilities, all managed through the sdkit.Context object.
For similar tasks
graph-of-thoughts
Graph of Thoughts (GoT) is an official implementation framework designed to solve complex problems by modeling them as a Graph of Operations (GoO) executed with a Large Language Model (LLM) engine. It offers flexibility to implement various approaches like CoT or ToT, allowing users to solve problems using the new GoT approach. The framework includes setup guides, quick start examples, documentation, and examples for users to understand and utilize the tool effectively.
llm-random
This repository contains code for research conducted by the LLM-Random research group at IDEAS NCBR in Warsaw, Poland. The group focuses on developing and using this repository to conduct research. For more information about the group and its research, refer to their blog, llm-random.github.io.
AI4U
AI4U is a tool that provides a framework for modeling virtual reality and game environments. It offers an alternative approach to modeling Non-Player Characters (NPCs) in Godot Game Engine. AI4U defines an agent living in an environment and interacting with it through sensors and actuators. Sensors provide data to the agent's brain, while actuators send actions from the agent to the environment. The brain processes the sensor data and makes decisions (selects an action by time). AI4U can also be used in other situations, such as modeling environments for artificial intelligence experiments.

OSWorld
OSWorld is a benchmarking tool designed to evaluate multimodal agents for open-ended tasks in real computer environments. It provides a platform for running experiments, setting up virtual machines, and interacting with the environment using Python scripts. Users can install the tool on their desktop or server, manage dependencies with Conda, and run benchmark tasks. The tool supports actions like executing commands, checking for specific results, and evaluating agent performance. OSWorld aims to facilitate research in AI by providing a standardized environment for testing and comparing different agent baselines.

GPTSwarm
GPTSwarm is a graph-based framework for LLM-based agents that enables the creation of LLM-based agents from graphs and facilitates the customized and automatic self-organization of agent swarms with self-improvement capabilities. The library includes components for domain-specific operations, graph-related functions, LLM backend selection, memory management, and optimization algorithms to enhance agent performance and swarm efficiency. Users can quickly run predefined swarms or utilize tools like the file analyzer. GPTSwarm supports local LM inference via LM Studio, allowing users to run with a local LLM model. The framework has been accepted by ICML2024 and offers advanced features for experimentation and customization.

LLM-Finetuning-Toolkit
LLM Finetuning toolkit is a config-based CLI tool for launching a series of LLM fine-tuning experiments on your data and gathering their results. It allows users to control all elements of a typical experimentation pipeline - prompts, open-source LLMs, optimization strategy, and LLM testing - through a single YAML configuration file. The toolkit supports basic, intermediate, and advanced usage scenarios, enabling users to run custom experiments, conduct ablation studies, and automate fine-tuning workflows. It provides features for data ingestion, model definition, training, inference, quality assurance, and artifact outputs, making it a comprehensive tool for fine-tuning large language models.
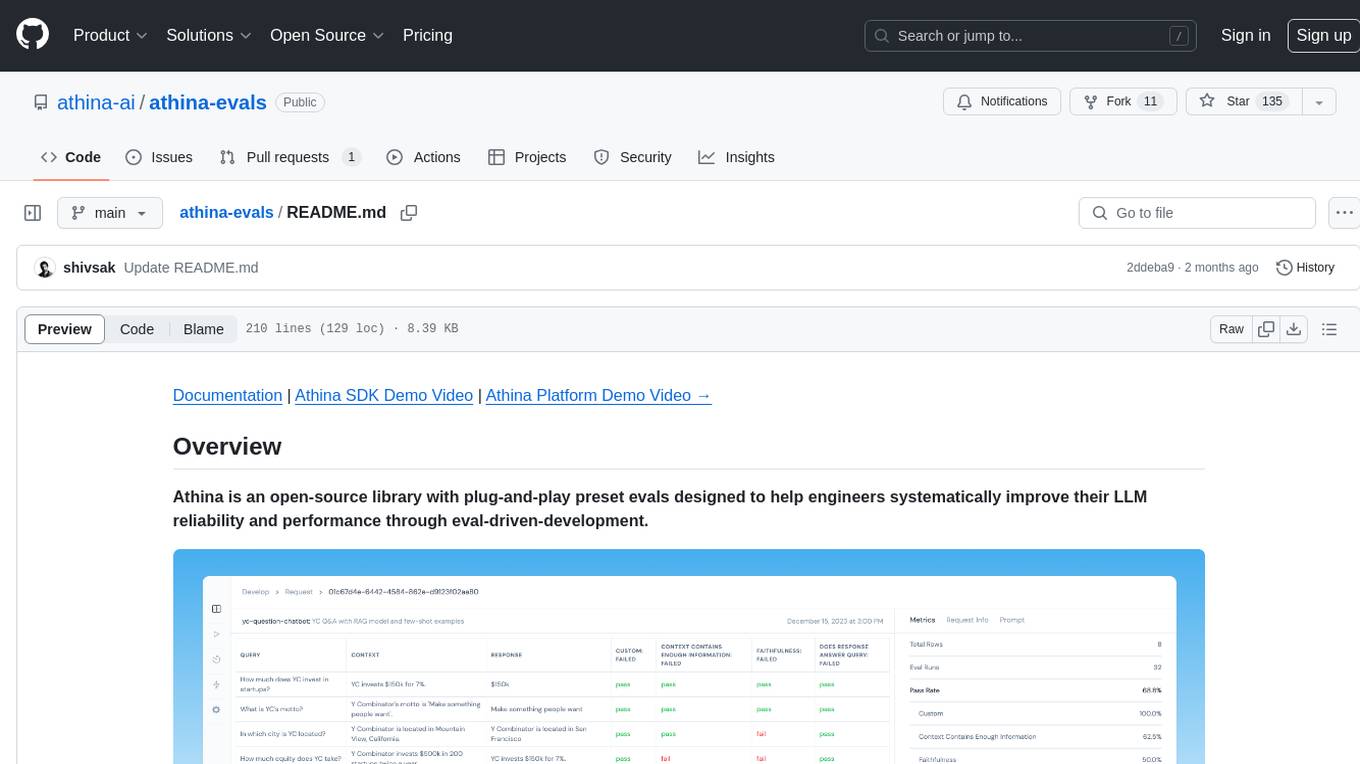
athina-evals
Athina is an open-source library designed to help engineers improve the reliability and performance of Large Language Models (LLMs) through eval-driven development. It offers plug-and-play preset evals for catching and preventing bad outputs, measuring model performance, running experiments, A/B testing models, detecting regressions, and monitoring production data. Athina provides a solution to the flaws in current LLM developer workflows by offering rapid experimentation, customizable evaluators, integrated dashboard, consistent metrics, historical record tracking, and easy setup. It includes preset evaluators for RAG applications and summarization accuracy, as well as the ability to write custom evals. Athina's evals can run on both development and production environments, providing consistent metrics and removing the need for manual infrastructure setup.
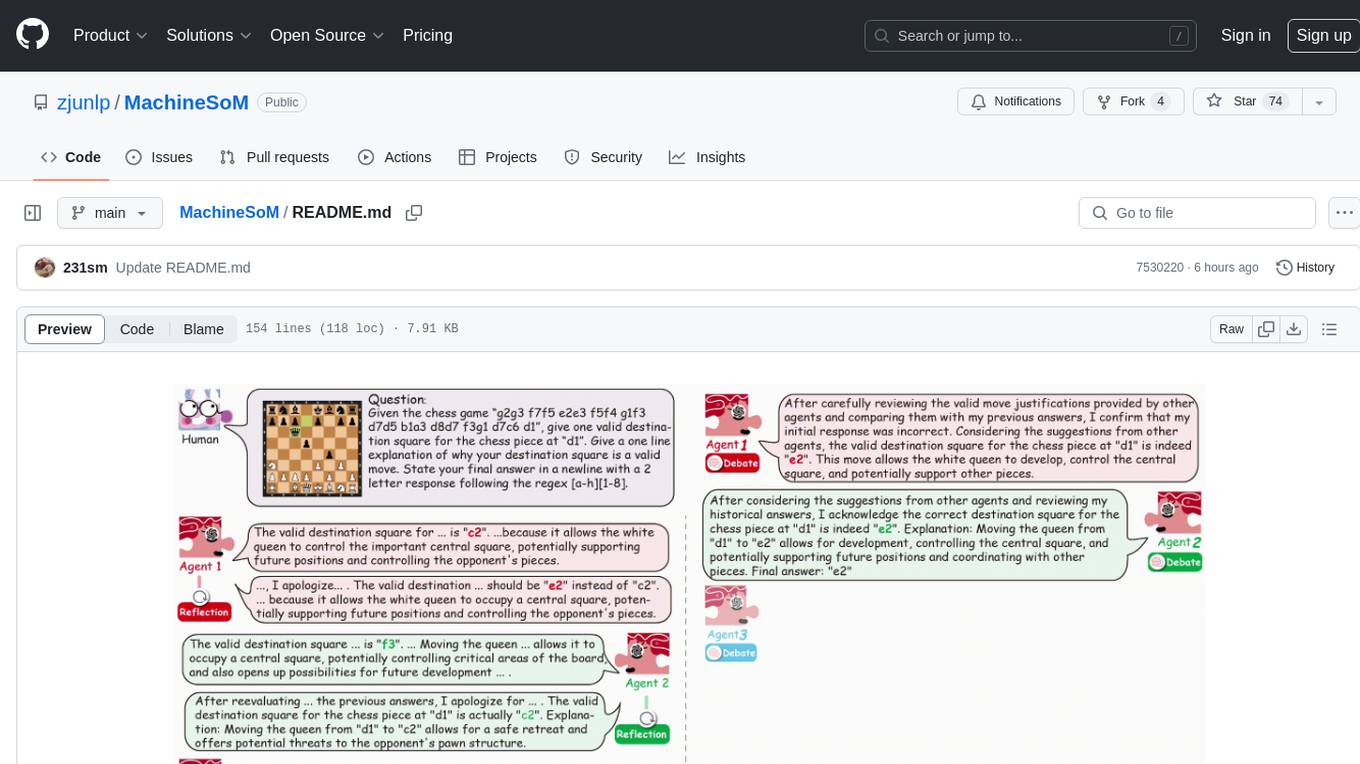
MachineSoM
MachineSoM is a code repository for the paper 'Exploring Collaboration Mechanisms for LLM Agents: A Social Psychology View'. It focuses on the emergence of intelligence from collaborative and communicative computational modules, enabling effective completion of complex tasks. The repository includes code for societies of LLM agents with different traits, collaboration processes such as debate and self-reflection, and interaction strategies for determining when and with whom to interact. It provides a coding framework compatible with various inference services like Replicate, OpenAI, Dashscope, and Anyscale, supporting models like Qwen and GPT. Users can run experiments, evaluate results, and draw figures based on the paper's content, with available datasets for MMLU, Math, and Chess Move Validity.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.