
aligner
Achieving Efficient Alignment through Learned Correction
Stars: 86
Aligner is a model-agnostic alignment tool that learns correctional residuals between preferred and dispreferred answers using a small model. It can be directly applied to various open-source and API-based models with only one-off training, suitable for rapid iteration and improving model performance. Aligner has shown significant improvements in helpfulness, harmlessness, and honesty dimensions across different large language models.
README:
With the rapid development of large language models (LLMs) and ever-evolving practical requirements, finding an efficient and effective alignment method has never been more critical. However, the tension between the complexity of current alignment methods and the need for rapid iteration in deployment scenarios necessitates the development of a model-agnostic alignment approach that can operate under these constraints. In this paper, we introduce Aligner, a novel and simple alignment paradigm that learns the correctional residuals between preferred and dispreferred answers using a small model. Designed as a model-agnostic, plug-and-play module, Aligner can be directly applied to various open-source and API-based models with only one-off training, making it suitable for rapid iteration. Notably, Aligner can be applied to powerful, large-scale upstream models. It can even iteratively bootstrap the upstream models using corrected responses as synthetic human preference data, breaking through the model's performance ceiling. Our experiments demonstrate performance improvements by deploying the same Aligner model across 11 different LLMs, evaluated on the 3H dimensions (helpfulness, harmlessness, and honesty). Specifically, Aligner-7B has achieved an average improvement of 68.9% in helpfulness and 23.8% in harmlessness across the tested LLMs while also effectively reducing hallucination. In the Alpaca-Eval leaderboard, stacking Aligner-2B on GPT-4 Turbo improved its LC Win Rate from 55.0% to 58.3%, surpassing GPT-4 Omni's 57.5% Win Rate (community report).
See our website for more details : https://aligner2024.github.io/
- Aligner: Achieving Efficient Alignment through Weak-to-Strong Correction
- Installation
- Training
- Dataset & Models
- Acknowledgment
As a plug-and-play module Aligner stack upon an upstream LLM. The Aligner redistributes initial answers from the upstream model into more helpful and harmless answers, thus aligning the composed LLM responses with human intentions.

Like a residual block that adds modifications via a shortcut without altering the base structure, the Aligner employs a copy and correct method to improve the original answer. This analogy highlights the Aligner's dual role in preserving the parameter of the upstream model while enhancing it to align with desired outcomes.

It is shown that Aligner achieves significant performances in all the settings. All assessments in this table were conducted based on integrating various models with Aligners to compare with the original models to quantify the percentage increase in the 3H standard. When integrated and assessed in conjunction with various upstream models, the Aligner requires only a single training session (i.e., the Aligner can operate in a zero-shot manner and enhance the performance of all upstream models.)

For more details, please refer to our website
Clone the source code from GitHub:
git clone https://github.com/Aligner2024/aligner.git
cd alignerNative Runner: Setup a conda environment using conda / mamba:
conda env create --file conda-recipe.yaml # or `mamba env create --file conda-recipe.yaml`aligner supports a complete pipeline for Aligner residual correction training.
- Follow the instructions in section Installation to setup the training environment properly.
conda activate aligner
export WANDB_API_KEY="..." # your W&B API key here- Supervised Fine-Tuning (SFT)
bash scripts/sft-correction.sh \
--train_datasets <your-correction-dataset> \
--model_name_or_path <your-model-name-or-checkpoint-path> \
--output_dir output/sftNOTE:
- You may need to update some of the parameters in the script according to your machine setup, such as the number of GPUs for training, the training batch size, etc.
- Your dataset format should be consistent with aligner/template-dataset.json
We have open-sourced a 20K training dataset and a 7B Aligner model. Further dataset and models will come soon.
This repository benefits from LLaMA, Stanford Alpaca, DeepSpeed, DeepSpeed-Chat and Safe-RLHF.
Thanks for their wonderful works and their efforts to further promote LLM research. Aligner and its related assets are built and open-sourced with love and respect.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aligner
Similar Open Source Tools
aligner
Aligner is a model-agnostic alignment tool that learns correctional residuals between preferred and dispreferred answers using a small model. It can be directly applied to various open-source and API-based models with only one-off training, suitable for rapid iteration and improving model performance. Aligner has shown significant improvements in helpfulness, harmlessness, and honesty dimensions across different large language models.

aligner
Aligner is a model-agnostic alignment tool designed to efficiently correct responses from large language models. It redistributes initial answers to align with human intentions, improving performance across various LLMs. The tool can be applied with minimal training, enhancing upstream models and reducing hallucination. Aligner's 'copy and correct' method preserves the base structure while enhancing responses. It achieves significant performance improvements in helpfulness, harmlessness, and honesty dimensions, with notable success in boosting Win Rates on evaluation leaderboards.

CoLLM
CoLLM is a novel method that integrates collaborative information into Large Language Models (LLMs) for recommendation. It converts recommendation data into language prompts, encodes them with both textual and collaborative information, and uses a two-step tuning method to train the model. The method incorporates user/item ID fields in prompts and employs a conventional collaborative model to generate user/item representations. CoLLM is built upon MiniGPT-4 and utilizes pretrained Vicuna weights for training.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.

magpie
This is the official repository for 'Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing'. Magpie is a tool designed to synthesize high-quality instruction data at scale by extracting it directly from an aligned Large Language Models (LLMs). It aims to democratize AI by generating large-scale alignment data and enhancing the transparency of model alignment processes. Magpie has been tested on various model families and can be used to fine-tune models for improved performance on alignment benchmarks such as AlpacaEval, ArenaHard, and WildBench.

SwiftSage
SwiftSage is a tool designed for conducting experiments in the field of machine learning and artificial intelligence. It provides a platform for researchers and developers to implement and test various algorithms and models. The tool is particularly useful for exploring new ideas and conducting experiments in a controlled environment. SwiftSage aims to streamline the process of developing and testing machine learning models, making it easier for users to iterate on their ideas and achieve better results. With its user-friendly interface and powerful features, SwiftSage is a valuable tool for anyone working in the field of AI and ML.

uncheatable_eval
Uncheatable Eval is a tool designed to assess the language modeling capabilities of LLMs on real-time, newly generated data from the internet. It aims to provide a reliable evaluation method that is immune to data leaks and cannot be gamed. The tool supports the evaluation of Hugging Face AutoModelForCausalLM models and RWKV models by calculating the sum of negative log probabilities on new texts from various sources such as recent papers on arXiv, new projects on GitHub, news articles, and more. Uncheatable Eval ensures that the evaluation data is not included in the training sets of publicly released models, thus offering a fair assessment of the models' performance.

R1-Searcher
R1-searcher is a tool designed to incentivize the search capability in large reasoning models (LRMs) via reinforcement learning. It enables LRMs to invoke web search and obtain external information during the reasoning process by utilizing a two-stage outcome-supervision reinforcement learning approach. The tool does not require instruction fine-tuning for cold start and is compatible with existing Base LLMs or Chat LLMs. It includes training code, inference code, model checkpoints, and a detailed technical report.

BitMat
BitMat is a Python package designed to optimize matrix multiplication operations by utilizing custom kernels written in Triton. It leverages the principles outlined in the "1bit-LLM Era" paper, specifically utilizing packed int8 data to enhance computational efficiency and performance in deep learning and numerical computing tasks.

OREAL
OREAL is a reinforcement learning framework designed for mathematical reasoning tasks, aiming to achieve optimal performance through outcome reward-based learning. The framework utilizes behavior cloning, reshaping rewards, and token-level reward models to address challenges in sparse rewards and partial correctness. OREAL has achieved significant results, with a 7B model reaching 94.0 pass@1 accuracy on MATH-500 and surpassing previous 32B models. The tool provides training tutorials and Hugging Face model repositories for easy access and implementation.

nextpy
Nextpy is a cutting-edge software development framework optimized for AI-based code generation. It provides guardrails for defining AI system boundaries, structured outputs for prompt engineering, a powerful prompt engine for efficient processing, better AI generations with precise output control, modularity for multiplatform and extensible usage, developer-first approach for transferable knowledge, and containerized & scalable deployment options. It offers 4-10x faster performance compared to Streamlit apps, with a focus on cooperation within the open-source community and integration of key components from various projects.

MemoryBear
MemoryBear is a next-generation AI memory system developed by RedBear AI, focusing on overcoming limitations in knowledge storage and multi-agent collaboration. It empowers AI with human-like memory capabilities, enabling deep knowledge understanding and cognitive collaboration. The system addresses challenges such as knowledge forgetting, memory gaps in multi-agent collaboration, and semantic ambiguity during reasoning. MemoryBear's core features include memory extraction engine, graph storage, hybrid search, memory forgetting engine, self-reflection engine, and FastAPI services. It offers a standardized service architecture for efficient integration and invocation across applications.

gepa
GEPA (Genetic-Pareto) is a framework for optimizing arbitrary systems composed of text components like AI prompts, code snippets, or textual specs against any evaluation metric. It employs LLMs to reflect on system behavior, using feedback from execution and evaluation traces to drive targeted improvements. Through iterative mutation, reflection, and Pareto-aware candidate selection, GEPA evolves robust, high-performing variants with minimal evaluations, co-evolving multiple components in modular systems for domain-specific gains. The repository provides the official implementation of the GEPA algorithm as proposed in the paper titled 'GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning'.
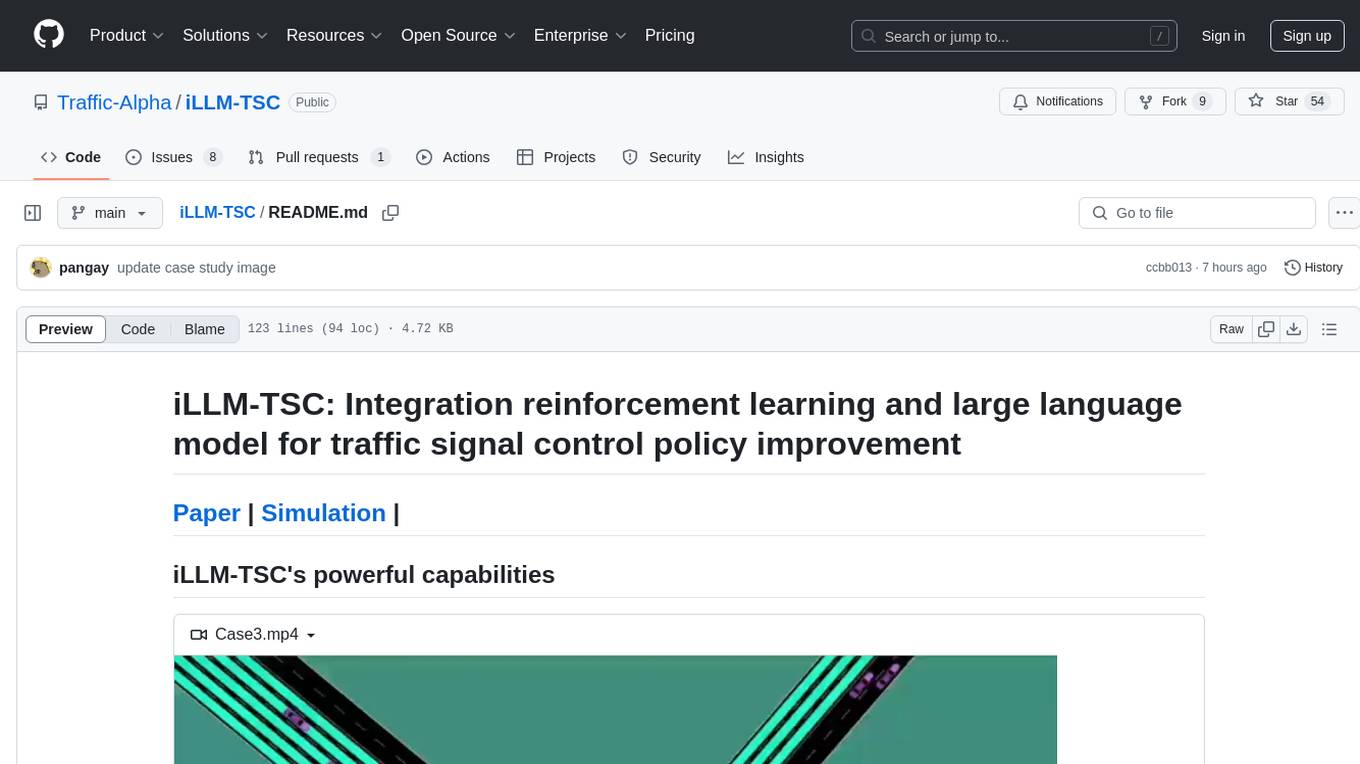
iLLM-TSC
iLLM-TSC is a framework that integrates reinforcement learning and large language models for traffic signal control policy improvement. It refines RL decisions based on real-world contexts and provides reasonable actions when RL agents make erroneous decisions. The framework includes cases where the large language model provides explanations and recommendations for RL agent actions, such as prioritizing emergency vehicles at intersections. Users can install and run the framework locally to train RL models and evaluate the combined RL+LLM approach.
Instruct2Act
Instruct2Act is a framework that utilizes Large Language Models to map multi-modal instructions to sequential actions for robotic manipulation tasks. It generates Python programs using the LLM model for perception, planning, and action. The framework leverages foundation models like SAM and CLIP to convert high-level instructions into policy codes, accommodating various instruction modalities and task demands. Instruct2Act has been validated on robotic tasks in tabletop manipulation domains, outperforming learning-based policies in several tasks.

nixtla
Nixtla is a production-ready generative pretrained transformer for time series forecasting and anomaly detection. It can accurately predict various domains such as retail, electricity, finance, and IoT with just a few lines of code. TimeGPT introduces a paradigm shift with its standout performance, efficiency, and simplicity, making it accessible even to users with minimal coding experience. The model is based on self-attention and is independently trained on a vast time series dataset to minimize forecasting error. It offers features like zero-shot inference, fine-tuning, API access, adding exogenous variables, multiple series forecasting, custom loss function, cross-validation, prediction intervals, and handling irregular timestamps.
For similar tasks
aligner
Aligner is a model-agnostic alignment tool that learns correctional residuals between preferred and dispreferred answers using a small model. It can be directly applied to various open-source and API-based models with only one-off training, suitable for rapid iteration and improving model performance. Aligner has shown significant improvements in helpfulness, harmlessness, and honesty dimensions across different large language models.
Gemini
Gemini is an open-source model designed to handle multiple modalities such as text, audio, images, and videos. It utilizes a transformer architecture with special decoders for text and image generation. The model processes input sequences by transforming them into tokens and then decoding them to generate image outputs. Gemini differs from other models by directly feeding image embeddings into the transformer instead of using a visual transformer encoder. The model also includes a component called Codi for conditional generation. Gemini aims to effectively integrate image, audio, and video embeddings to enhance its performance.
awesome-llms-fine-tuning
This repository is a curated collection of resources for fine-tuning Large Language Models (LLMs) like GPT, BERT, RoBERTa, and their variants. It includes tutorials, papers, tools, frameworks, and best practices to aid researchers, data scientists, and machine learning practitioners in adapting pre-trained models to specific tasks and domains. The resources cover a wide range of topics related to fine-tuning LLMs, providing valuable insights and guidelines to streamline the process and enhance model performance.
prompt-tuning-playbook
The LLM Prompt Tuning Playbook is a comprehensive guide for improving the performance of post-trained Language Models (LLMs) through effective prompting strategies. It covers topics such as pre-training vs. post-training, considerations for prompting, a rudimentary style guide for prompts, and a procedure for iterating on new system instructions. The playbook emphasizes the importance of clear, concise, and explicit instructions to guide LLMs in generating desired outputs. It also highlights the iterative nature of prompt development and the need for systematic evaluation of model responses.
Awesome_Test_Time_LLMs
This repository focuses on test-time computing, exploring various strategies such as test-time adaptation, modifying the input, editing the representation, calibrating the output, test-time reasoning, and search strategies. It covers topics like self-supervised test-time training, in-context learning, activation steering, nearest neighbor models, reward modeling, and multimodal reasoning. The repository provides resources including papers and code for researchers and practitioners interested in enhancing the reasoning capabilities of large language models.
HuaTuoAI
HuaTuoAI is an artificial intelligence image classification system specifically designed for traditional Chinese medicine. It utilizes deep learning techniques, such as Convolutional Neural Networks (CNN), to accurately classify Chinese herbs and ingredients based on input images. The project aims to unlock the secrets of plants, depict the unknown realm of Chinese medicine using technology and intelligence, and perpetuate ancient cultural heritage.
For similar jobs

responsible-ai-toolbox
Responsible AI Toolbox is a suite of tools providing model and data exploration and assessment interfaces and libraries for understanding AI systems. It empowers developers and stakeholders to develop and monitor AI responsibly, enabling better data-driven actions. The toolbox includes visualization widgets for model assessment, error analysis, interpretability, fairness assessment, and mitigations library. It also offers a JupyterLab extension for managing machine learning experiments and a library for measuring gender bias in NLP datasets.
LLMLingua
LLMLingua is a tool that utilizes a compact, well-trained language model to identify and remove non-essential tokens in prompts. This approach enables efficient inference with large language models, achieving up to 20x compression with minimal performance loss. The tool includes LLMLingua, LongLLMLingua, and LLMLingua-2, each offering different levels of prompt compression and performance improvements for tasks involving large language models.
llm-examples
Starter examples for building LLM apps with Streamlit. This repository showcases a growing collection of LLM minimum working examples, including a Chatbot, File Q&A, Chat with Internet search, LangChain Quickstart, LangChain PromptTemplate, and Chat with user feedback. Users can easily get their own OpenAI API key and set it as an environment variable in Streamlit apps to run the examples locally.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.

awesome-tool-llm
This repository focuses on exploring tools that enhance the performance of language models for various tasks. It provides a structured list of literature relevant to tool-augmented language models, covering topics such as tool basics, tool use paradigm, scenarios, advanced methods, and evaluation. The repository includes papers, preprints, and books that discuss the use of tools in conjunction with language models for tasks like reasoning, question answering, mathematical calculations, accessing knowledge, interacting with the world, and handling non-textual modalities.
gaianet-node
GaiaNet-node is a tool that allows users to run their own GaiaNet node, enabling them to interact with an AI agent. The tool provides functionalities to install the default node software stack, initialize the node with model files and vector database files, start the node, stop the node, and update configurations. Users can use pre-set configurations or pass a custom URL for initialization. The tool is designed to facilitate communication with the AI agent and access node information via a browser. GaiaNet-node requires sudo privilege for installation but can also be installed without sudo privileges with specific commands.

llmops-duke-aipi
LLMOps Duke AIPI is a course focused on operationalizing Large Language Models, teaching methodologies for developing applications using software development best practices with large language models. The course covers various topics such as generative AI concepts, setting up development environments, interacting with large language models, using local large language models, applied solutions with LLMs, extensibility using plugins and functions, retrieval augmented generation, introduction to Python web frameworks for APIs, DevOps principles, deploying machine learning APIs, LLM platforms, and final presentations. Students will learn to build, share, and present portfolios using Github, YouTube, and Linkedin, as well as develop non-linear life-long learning skills. Prerequisites include basic Linux and programming skills, with coursework available in Python or Rust. Additional resources and references are provided for further learning and exploration.
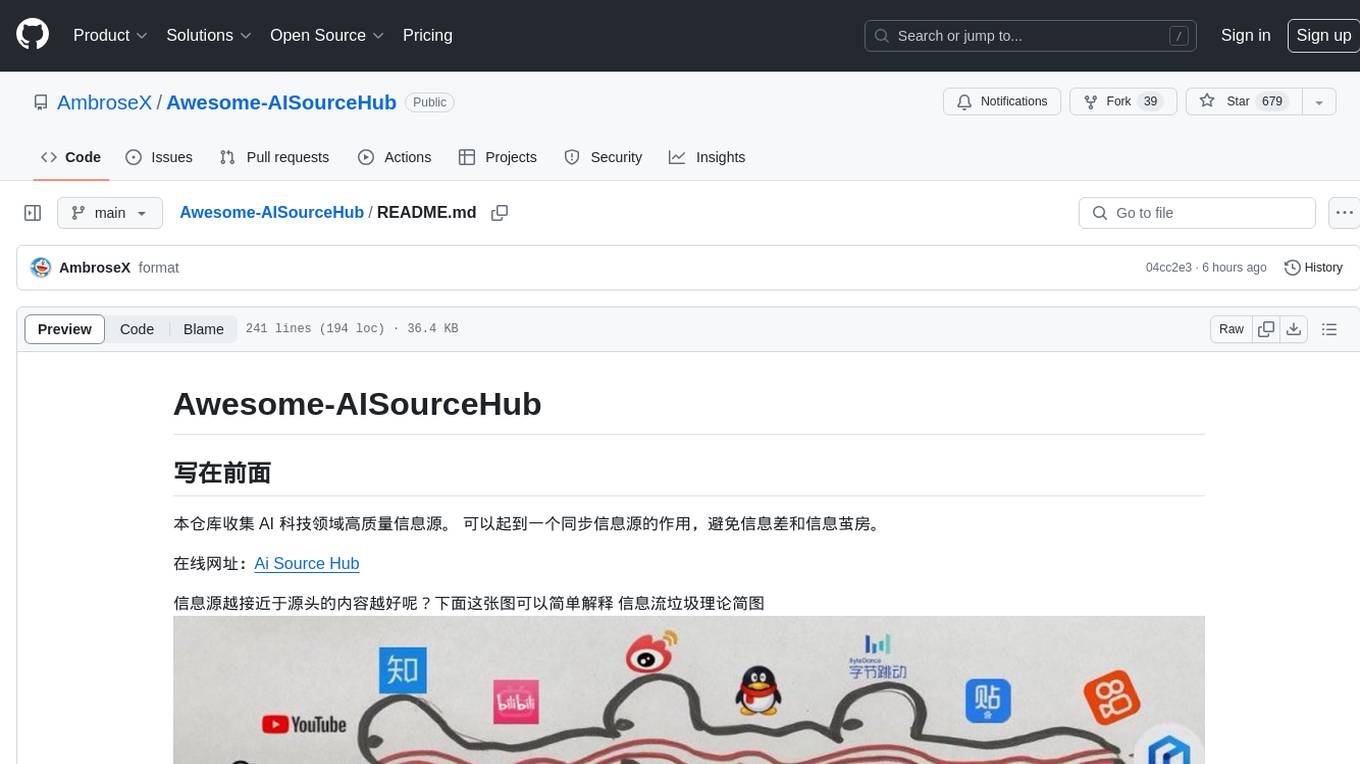
Awesome-AISourceHub
Awesome-AISourceHub is a repository that collects high-quality information sources in the field of AI technology. It serves as a synchronized source of information to avoid information gaps and information silos. The repository aims to provide valuable resources for individuals such as AI book authors, enterprise decision-makers, and tool developers who frequently use Twitter to share insights and updates related to AI advancements. The platform emphasizes the importance of accessing information closer to the source for better quality content. Users can contribute their own high-quality information sources to the repository by following specific steps outlined in the contribution guidelines. The repository covers various platforms such as Twitter, public accounts, knowledge planets, podcasts, blogs, websites, YouTube channels, and more, offering a comprehensive collection of AI-related resources for individuals interested in staying updated with the latest trends and developments in the AI field.