
Awesome_Test_Time_LLMs
None
Stars: 69
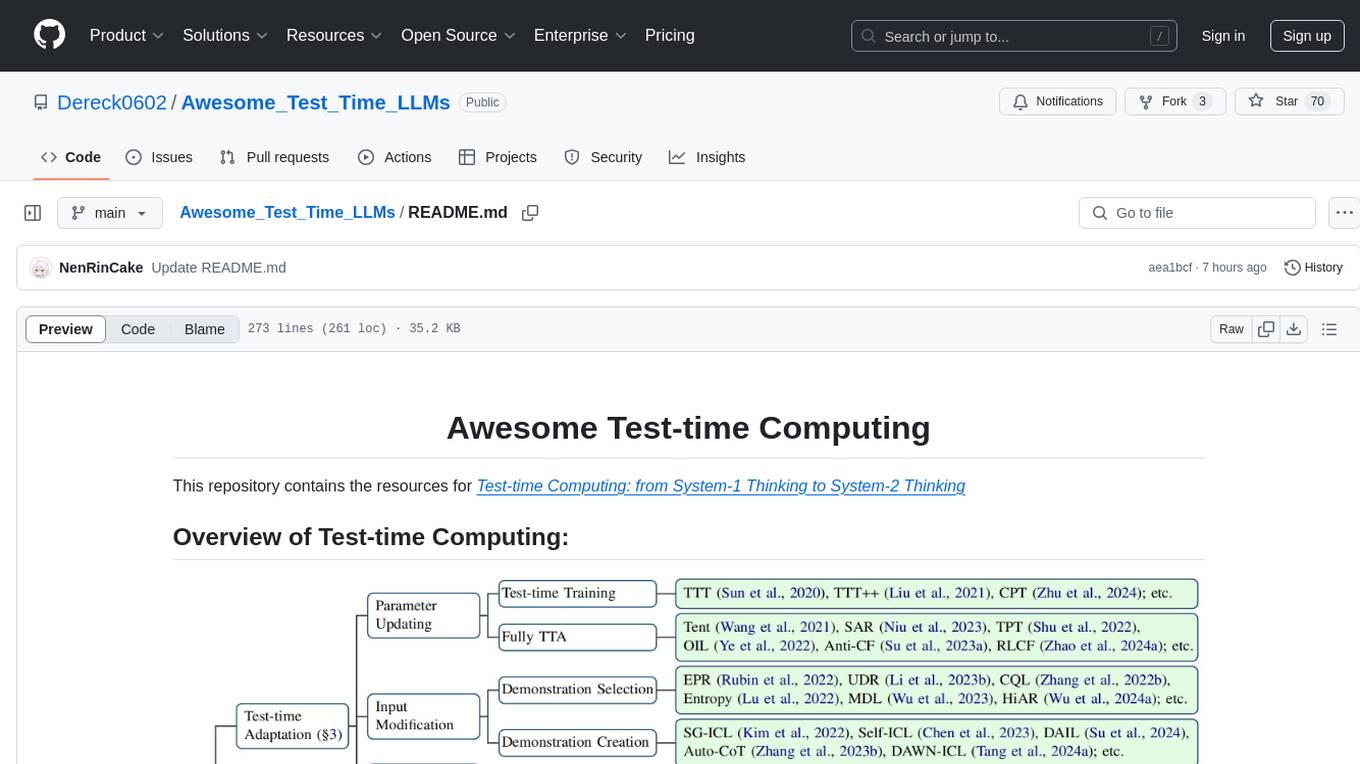
This repository focuses on test-time computing, exploring various strategies such as test-time adaptation, modifying the input, editing the representation, calibrating the output, test-time reasoning, and search strategies. It covers topics like self-supervised test-time training, in-context learning, activation steering, nearest neighbor models, reward modeling, and multimodal reasoning. The repository provides resources including papers and code for researchers and practitioners interested in enhancing the reasoning capabilities of large language models.
README:
This repository contains the resources for Test-time Computing: from System-1 Thinking to System-2 Thinking

- Test-Time Training with Self-Supervision for Generalization under Distribution Shifts [ICML 2020] paper
- MT3: Meta Test-Time Training for Self-Supervised Test-Time Adaption [AISTATS 2022] paper code
- Test-Time Training with Masked Autoencoders [NeurIPS 2022] paper
- TTT++: When Does Self-Supervised Test-Time Training Fail or Thrive? [NeurIPS 2021] paper code
- Efficient Test-Time Prompt Tuning for Vision-Language Models [arxiv 2024.8] paper
- Tent: Fully Test-time Adaptation by Entropy Minimization [ICLR 2021] paper code
- MEMO: Test Time Robustness via Adaptation and Augmentation [NeurIPS 2022] paper code
- The Entropy Enigma: Success and Failure of Entropy Minimization [arxiv 2024.5] paper code
- On Pitfalls of Test-Time Adaptation [ICML 2023] paper code
- Beware of Model Collapse! Fast and Stable Test-time Adaptation for Robust Question Answering [EMNLP 2023] paper code
- Align Your Prompts: Test-Time Prompting with Distribution Alignment for Zero-Shot Generalization [NeurIPS 2024] paper
- Protected Test-Time Adaptation via Online Entropy Matching: A Betting Approach [arxiv 2024.8] paper code
- Simulating Bandit Learning from User Feedback for Extractive Question Answering [ACL 2022] paper code
- Using Interactive Feedback to Improve the Accuracy and Explainability of Question Answering Systems Post-Deployment [ACL 2022] paper
- Test-time Adaptation for Machine Translation Evaluation by Uncertainty Minimization [ACL 2023] paper code
- COMET: A Neural Framework for MT Evaluation [EMNLP 2020] paper
- Test-Time Adaptation with CLIP Reward for Zero-Shot Generalization in Vision-Language Models [ICLR 2023] paper code
- Improving robustness against common corruptions by covariate shift adaptation [NeurIPS 2020] paper
- Selective Annotation Makes Language Models Better Few-Shot Learners [arxiv 2022.9] paper code
- Test-Time Adaptation with Perturbation Consistency Learning [arxiv 2023.4] paper
- Test-Time Prompt Adaptation for Vision-Language Models [NeurIPS 2023] paper
- Diverse Data Augmentation with Diffusions for Effective Test-time Prompt Tuning [ICCV 2023] paper code
- Test-Time Model Adaptation with Only Forward Passes [ICML 2024] paper code
- Test-Time Low Rank Adaptation via Confidence Maximization for Zero-Shot Generalization of Vision-Language Models [arxiv 2024.7] paper code
- StreamAdapter: Efficient Test Time Adaptation from Contextual Streams [arxiv 2024.11] paper
- Towards Stable Test-time Adaptation in Dynamic Wild World [ICLR 2023] paper code
- SoTTA: Robust Test-Time Adaptation on Noisy Data Streams [NeurIPS 2023] paper code
- Robust Question Answering against Distribution Shifts with Test-Time Adaption: An Empirical Study [EMNLP 2022] paper code
- What Makes Good In-Context Examples for GPT-3? [DeeLIO 2022] paper
- In-Context Learning with Iterative Demonstration Selection [EMNLP 2024] paper
- Dr.ICL: Demonstration-Retrieved In-context Learning [arxiv 2023.5] paper
- Learning To Retrieve Prompts for In-Context Learning [NAACL 2022] paper
- Unified Demonstration Retriever for In-Context Learning [ACL 2023] paper code
- Why Can GPT Learn In-Context? Language Models Secretly Perform Gradient Descent as Meta-Optimizers [ACL 2023] paper code
- Finding Support Examples for In-Context Learning [EMNLP 2023] paper code
- Large Language Models Are Latent Variable Models: Explaining and Finding Good Demonstrations for In-Context Learning [NeurIPS 2023] paper code
- Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity [ACL 2022] paper
- Self-Adaptive In-Context Learning: An Information Compression Perspective for In-Context Example Selection and Ordering [ACL 2023] paper
- RetICL: Sequential Retrieval of In-Context Examples with Reinforcement Learning [arxiv 2024.4] paper
- Automatic Chain of Thought Prompting in Large Language Models [ICLR 2022] paper code
- Self-ICL: Zero-Shot In-Context Learning with Self-Generated Demonstrations [EMNLP 2023] paper code
- Z-ICL: Zero-Shot In-Context Learning with Pseudo-Demonstrations [ACL 2023] paper
- Self-Generated In-Context Learning: Leveraging Auto-regressive Language Models as a Demonstration Generator [arxiv 2022.6] paper
- Demonstration Augmentation for Zero-shot In-context Learning [ACL 2024] paper code
- Plug and Play Language Models: A Simple Approach to Controlled Text Generation [ICLR 2022] paper
- Steering Language Models With Activation Engineering [arxiv 2024.10] paper
- Improving Instruction-Following in Language Models through Activation Steering [arxiv 2024.10] paper
- Inference-Time Intervention: Eliciting Truthful Answers from a Language Model [arxiv 2024.6] paper code
- Refusal in Language Models Is Mediated by a Single Direction [arxiv 2024.10] paper code
- In-context Vectors: Making In Context Learning More Effective and Controllable Through Latent Space Steering [arxiv 2024.2] paper code
- Investigating Bias Representations in Llama 2 Chat via Activation Steering [arxiv 2024.2] paper
- Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization [arxiv 2024.7] paper code
- Spectral Editing of Activations for Large Language Model Alignment [NeurIPS 2024] paper code
- Multi-property Steering of Large Language Models with Dynamic Activation Composition [BlackboxNLP 2024] paper code
- Generalization through Memorization: Nearest Neighbor Language Models [ICLR 2020] paper code
- Nearest Neighbor Machine Translation [ICLR 2021] paper code
- Efficient Cluster-Based k-Nearest-Neighbor Machine Translation [ACL 2022] paper code
- What Knowledge Is Needed? Towards Explainable Memory for kNN-MT Domain Adaptation [ACL 2023] paper code
- Efficient Domain Adaptation for Non-Autoregressive Machine Translation [ACL 2024] paper code
- kNN-NER: Named Entity Recognition with Nearest Neighbor Search [arxiv 2022.3] paper code
- kNN-CM: A Non-parametric Inference-Phase Adaptation of Parametric Text Classifiers [EMNLP 2023] paper code
- AdaNPC: Exploring Non-Parametric Classifier for Test-Time Adaptation [ICML 2023] paper code
- Scaling Laws for Reward Model Overoptimization [PMLR 2023] paper
- Training Verifiers to Solve Math Word Problems [arxiv 2021.10] paper
- Advancing LLM Reasoning Generalists with Preference Trees [arxiv 2024.4] paper code
- V-STaR: Training Verifiers for Self-Taught Reasoners [COLM 2024] paper
- Solving math word problems with process- and outcome-based feedback [arxiv 2022.11] paper
- Let's Verify Step by Step [ICLR 2024] paper code
- Entropy-Regularized Process Reward Model arxiv 2024.12 code
- Math-Shepherd: Verify and Reinforce LLMs Step-by-step without Human Annotations [ACL 2024] paper
- Improve Mathematical Reasoning in Language Models by Automated Process Supervision [arxiv 20224.6] paper
- Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning [arxiv 20224.10] paper
- AutoPSV: Automated Process-Supervised Verifier [NeurIPS 2024] paper code
- Free Process Rewards without Process Labels [arxiv 2024.12] paper code
- Critique-out-Loud Reward Models [arxiv 2024.8] paper code
- Improving Reward Models with Synthetic Critiques [arxiv 2024.5] paper
- Generative Verifiers: Reward Modeling as Next-Token Prediction [arxiv 2024.8] paper
- Self-Generated Critiques Boost Reward Modeling for Language Models [arxiv 2024.11] paper
- Is ChatGPT a Good NLG Evaluator? A Preliminary Study [ACL 2023] paper code
- ChatGPT as a Factual Inconsistency Evaluator for Text Summarization [arxiv 2023.3] paper
- G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment [ACL 2023] pdf code
- Can Large Language Models Be an Alternative to Human Evaluations? [ACL 2023] paper
- LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks [arxiv 2024.6] paper
- Large Language Models are not Fair Evaluators [ACL 2024] paper code
- Large Language Models are Inconsistent and Biased Evaluators [arxiv 2024.5] paper
- Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena [NeurIPS 2023] paper code
- PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization [ICLR 2024] paper
- JudgeLM: Fine-tuned Large Language Models are Scalable Judges [arxiv 2023.10] paper code
- Fennec: Fine-grained Language Model Evaluation and Correction Extended through Branching and Bridging [arxiv 2024.5] paper code
- REFINER: Reasoning Feedback on Intermediate Representations [ACL 2024] paper
- Shepherd: A Critic for Language Model Generation [arxiv 2023.8] paper code
- Generative Judge for Evaluating Alignment [ICLR 2024] paper code
- Can LLMs Produce Faithful Explanations For Fact-checking? Towards Faithful Explainable Fact-Checking via Multi-Agent Debate [ICLR 2024] paper
- Competition-level code generation with alphacode [Science 2022] paper code
- Code Llama: Open Foundation Models for Code [arxiv 2023.8] paper code
- More Agents Is All You Need [arxiv 2024.2] paper code
- Just Ask One More Time! Self-Agreement Improves Reasoning of Language Models in (Almost) All Scenarios [ACL 2024] paper
- Self-Consistency Improves Chain of Thought Reasoning in Language Models [ICLR 2023] paper
- Not All Votes Count! Programs as Verifiers Improve Self-Consistency of Language Models for Math Reasoning[arxiv 2024.10] paper code
- Learning to summarize with human feedback[NeurIPS 2020] paper
- Training Verifiers to Solve Math Word Problems[arxiv 2021.10] paper
- WebGPT: Browser-assisted question-answering with human feedback [arxiv 2021.12] paper
- Making Language Models Better Reasoners with Step-Aware Verifier [ACL 2023] paper code
- Accelerating Best-of-N via Speculative Rejection [ICML 2024] paper
- TreeBoN: Enhancing Inference-Time Alignment with Speculative Tree-Search and Best-of-N Sampling [arxiv 2024.10] paper
- Fast Best-of-N Decoding via Speculative Rejection [NeurIPS 2024] paper
- Adaptive Inference-Time Compute: LLMs Can Predict if They Can Do Better, Even Mid-Generation [arxiv 2024.10] paper code
- Preference-Guided Reflective Sampling for Aligning Language Models [EMNLP 2024] paper code
- Reinforced Self-Training (ReST) for Language Modeling[arxiv 2023.8] paper
- Variational Best-of-N Alignment [arxiv 2024.7] paper
- BoNBoN Alignment for Large Language Models and the Sweetness of Best-of-n Sampling [NeurIps 2024] paper
- BOND: Aligning LLMs with Best-of-N Distillation [arxiv 2024.7] paper
- Inference-Aware Fine-Tuning for Best-of-N Sampling in Large Language Models [arxiv 2024.12] paper
- Reflexion: Language Agents with Verbal Reinforcement Learning [arxiv 2023.3] paper code
- Interscript: A dataset for interactive learning of scripts through error feedback [arxiv 2021.12] paper code
- NL-EDIT: Correcting Semantic Parse Errors through Natural Language Interaction [ACL 2021] paper code
- Learning to repair: Repairing model output errors after deployment using a dynamic memory of feedback [ACL 2022] paper code
- CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing [ICLR 2024] paper code
- Teaching Large Language Models to Self-Debug [ICLR 2024] paper
- RARR: Researching and Revising What Language Models Say, Using Language Models [ACL 2023] paper code
- Graph-based, Self-Supervised Program Repair from Diagnostic Feedback [ICML 2020] paper
- Improving Factuality and Reasoning in Language Models through Multiagent Debate [arxiv 2023.5] paper code
- Examining Inter-Consistency of Large Language Models Collaboration: An In-depth Analysis via Debate [EMNLP 2023] paper code
- Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate [EMNLP 2024] paper code
- ReConcile: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs [ACL 2024] paper code
- Mixture-of-Agents Enhances Large Language Model Capabilities [arxiv 2024.6] paper code
- Can LLMs Produce Faithful Explanations For Fact-checking? Towards Faithful Explainable Fact-Checking via Multi-Agent Debate [arxiv 2024.7] paper
- Debating with More Persuasive LLMs Leads to More Truthful Answers [ICML 2024] paper code
- ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate [ICLR 2024] pdf
- ChainLM: Empowering Large Language Models with Improved Chain-of-Thought Prompting [IREC 2024] paper
- Are You Sure? Challenging LLMs Leads to Performance Drops in The FlipFlop Experiment [arxiv 2023.11] paper
- MultiAgent Collaboration Attack: Investigating Adversarial Attacks in Large Language Model Collaborations via Debate [arxiv 2024.6] paper
- Teaching Models to Balance Resisting and Accepting Persuasion [arxiv 2024.10] paper code
- GroupDebate: Enhancing the Efficiency of Multi-Agent Debate Using Group Discussion [arxiv 2024.9] paper
- Improving Multi-Agent Debate with Sparse Communication Topology [arxiv 2024.6] paper
- Self-Rewarding Language Models [arxiv 2024.1] paper
- Constitutional AI: Harmlessness from AI Feedback [arxiv 2022.12] paper code
- Self-Refine: Iterative Refinement with Self-Feedback [NeurIPS 2023] paper
- Language Models can Solve Computer Tasks [arxiv 2023.3] paper code
- Confidence Matters: Revisiting Intrinsic Self-Correction Capabilities of Large Language Models [arxiv 2024.2] paper code
- Is Self-Repair a Silver Bullet for Code Generation? [ICLR 2024] paper code
- Large Language Models Cannot Self-Correct Reasoning Yet [ICLR 2024] paper
- Reasoning in Token Economies: Budget-Aware Evaluation of LLM Reasoning Strategies [arxiv 2024.6] paper
- Can Large Language Models Really Improve by Self-critiquing Their Own Plans? [arxiv 2023.10] paper
- GPT-4 Doesn't Know It's Wrong: An Analysis of Iterative Prompting for Reasoning Problems [arxiv 2023.10] paper
- When Can LLMs Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLMs [arxiv 2024.6] paper
- LLMs cannot find reasoning errors, but can correct them given the error location [ACL 2024] paper code
- Self-critiquing models for assisting human evaluators [arxiv 2022.6] paper
- Recursive Introspection: Teaching Language Model Agents How to Self-Improve [arxiv 2024.7] paper
- Embedding Self-Correction as an Inherent Ability in Large Language Models for Enhanced Mathematical Reasoning [arxiv 2024.10] paper
- Learn Beyond The Answer: Training Language Models with Reflection for Mathematical Reasoning [arxiv 2024.6] paper code
- GLoRe: When, Where, and How to Improve LLM Reasoning via Global and Local Refinements [arxiv 2024.2] paper
- Generating Sequences by Learning to Self-Correct [ICLR 2023] paper code
- Training Language Models to Self-Correct via Reinforcement Learning [arxiv 2024.9] paper
- Tree of Thoughts: Deliberate Problem Solving with Large Language Models [NeurIPS 2023] paper code
- Self-Evaluation Guided Beam Search for Reasoning [NeurIPS 2023] paper code
- Reasoning with Language Model is Planning with World Model [EMNLP 2023] paper code
- Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B [arxiv 2024.6] paper code
- Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning [arxiv 2025.2] paper code
- Large Language Model Guided Tree-of-Thought [arxiv 2023.5] paper code
- Reasoning with Language Model is Planning with World Model [EMNLP 2023] paper code
- Alphazero-like Tree-Search can Guide Large Language Model Decoding and Training [arxiv 2023.9] paper
- Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers [arxiv 2024.8] paper code
- Interpretable Contrastive Monte Carlo Tree Search Reasoning [arxiv 2024.10] paper code
- ReST-MCTS: LLM Self-Training via Process Reward Guided Tree Search [arxiv 2024.6] pdf code
- Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning [arxiv 2024.5] paper code
- O1 Replication Journey: A Strategic Progress Report -- Part 1 [arxiv 2024.10] paper code
- Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions [arxiv 2024.11] paper code
- o1-Coder: an o1 Replication for Coding [arxiv 2024.12] paper code
- A Baseline Analysis of Reward Models’ Ability To Accurately Analyze Foundation Models Under Distribution Shift [arxiv 2023.10] paper
- Evaluating Robustness of Reward Models for Mathematical Reasoning [arxiv 2024.10] paper
- ODIN: Disentangled Reward Mitigates Hacking in RLHF [ICML 2024] paper
- Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts [arxiv 2024.6] paper code
- DogeRM: Equipping Reward Models with Domain Knowledge through Model Merging [EMNLP 2024] paper code
- Regularizing Hidden States Enables Learning Generalizable Reward Model for LLMs [NeurIPS 2024] paper code
- Generalizing Reward Modeling for Out-of-Distribution Preference Learning [ECML-PKDD 2024] paper code
- Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision [arxiv 2023.12] paper
- MAF: Multi-Aspect Feedback for Improving Reasoning in Large Language Models [EMNLP 2023] paper code
- Training language models to follow instructions with human feedback [arxiv 2022.3] paper
- Test-Time Adaptation with CLIP Reward for Zero-Shot Generalization in Vision-Language Models [ICLR 2024] paper code
- Multimodal Chain-of-Thought Reasoning in Language Models [TMLR 2024] paper code
- Mind's Eye of LLMs: Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models [NeurIPS 2024] paper
- KAM-CoT: Knowledge Augmented Multimodal Chain-of-Thoughts Reasoning [AAAI 2024] paper
- Multimodal Reasoning with Multimodal Knowledge Graph [ACL 2024] paper
- Interleaved-Modal Chain-of-Thought [arxiv 2024.11] paper
- LLaVA-Critic: Learning to Evaluate Multimodal Models [arxiv 2024.10] paper
- LLaVA-CoT: Let Vision Language Models Reason Step-by-Step [arxiv 2024.11] paper code
- Learning How Hard to Think: Input-Adaptive Allocation of LM Computation [arxiv 2024.10] paper
- Scaling LLM Inference with Optimized Sample Compute Allocation [arxiv 2024.10] paper code
- Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs [arxiv 2025.2] paper
- Reasoning in Token Economies: Budget-Aware Evaluation of LLM Reasoning Strategies [EMNLP 2024] paper
- Prometheus: Inducing Fine-Grained Evaluation Capability in Language Models [ICLR 2024] paper
- MoDE-CoTD: Chain-of-Thought Distillation for Complex Reasoning Tasks with Mixture of Decoupled LoRA-Experts [ACL 2024] paper
- Quantization Meets Reasoning: Exploring LLM Low-Bit Quantization Degradation for Mathematical Reasoning [arxiv 2025.2] paper
- LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference [arxiv 2024.7] paper
- Token-Budget-Aware LLM Reasoning [arxiv 2024.12] paper code
- Fast Inference from Transformers via Speculative Decoding [ICML 2022] paper
- Compressed Chain of Thought: Efficient Reasoning Through Dense Representations [arxiv 2024.12] paper
- Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding [arxiv 2024.6] paper code
- Large Language Monkeys: Scaling Inference Compute with Repeated Sampling [arxiv 2024.9] paper
- Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters [arxiv 2024.8] paper
- Inference Scaling Laws: An Empirical Analysis of Compute-Optimal Inference for Problem-Solving with Language Models [arxiv 2024.10] paper code
- A Simple and Provable Scaling Law for the Test-Time Compute of Large Language Models [arxiv 2024.11] paper
- The Surprising Effectiveness of Test-Time Training for Abstract Reasoning [arxiv 2024.11] paper code
- Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions [arxiv 2024.11] paper code
- Beyond Examples: High-level Automated Reasoning Paradigm in In-Context Learning via MCTS [arxiv 2024.11] paper
If our survey is helpful to your research, please cite our paper:
@article{ji2025test,
title={Test-time Computing: from System-1 Thinking to System-2 Thinking},
author={Ji, Yixin and Li, Juntao and Ye, Hai and Wu, Kaixin and Xu, Jia and Mo, Linjian and Zhang, Min},
journal={arXiv preprint arXiv:2501.02497},
year={2025}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome_Test_Time_LLMs
Similar Open Source Tools
Awesome_Test_Time_LLMs
This repository focuses on test-time computing, exploring various strategies such as test-time adaptation, modifying the input, editing the representation, calibrating the output, test-time reasoning, and search strategies. It covers topics like self-supervised test-time training, in-context learning, activation steering, nearest neighbor models, reward modeling, and multimodal reasoning. The repository provides resources including papers and code for researchers and practitioners interested in enhancing the reasoning capabilities of large language models.
Awesome-LLM-Interpretability
Awesome-LLM-Interpretability is a curated list of materials related to LLM (Large Language Models) interpretability, covering tutorials, code libraries, surveys, videos, papers, and blogs. It includes resources on transformer mechanistic interpretability, visualization, interventions, probing, fine-tuning, feature representation, learning dynamics, knowledge editing, hallucination detection, and redundancy analysis. The repository aims to provide a comprehensive overview of tools, techniques, and methods for understanding and interpreting the inner workings of large language models.
MedLLMsPracticalGuide
This repository serves as a practical guide for Medical Large Language Models (Medical LLMs) and provides resources, surveys, and tools for building, fine-tuning, and utilizing LLMs in the medical domain. It covers a wide range of topics including pre-training, fine-tuning, downstream biomedical tasks, clinical applications, challenges, future directions, and more. The repository aims to provide insights into the opportunities and challenges of LLMs in medicine and serve as a practical resource for constructing effective medical LLMs.
Awesome_papers_on_LLMs_detection
This repository is a curated list of papers focused on the detection of Large Language Models (LLMs)-generated content. It includes the latest research papers covering detection methods, datasets, attacks, and more. The repository is regularly updated to include the most recent papers in the field.
ai-agent-papers
The AI Agents Papers repository provides a curated collection of papers focusing on AI agents, covering topics such as agent capabilities, applications, architectures, and presentations. It includes a variety of papers on ideation, decision making, long-horizon tasks, learning, memory-based agents, self-evolving agents, and more. The repository serves as a valuable resource for researchers and practitioners interested in AI agent technologies and advancements.
ABigSurveyOfLLMs
ABigSurveyOfLLMs is a repository that compiles surveys on Large Language Models (LLMs) to provide a comprehensive overview of the field. It includes surveys on various aspects of LLMs such as transformers, alignment, prompt learning, data management, evaluation, societal issues, safety, misinformation, attributes of LLMs, efficient LLMs, learning methods for LLMs, multimodal LLMs, knowledge-based LLMs, extension of LLMs, LLMs applications, and more. The repository aims to help individuals quickly understand the advancements and challenges in the field of LLMs through a collection of recent surveys and research papers.
OpenRedTeaming
OpenRedTeaming is a repository focused on red teaming for generative models, specifically large language models (LLMs). The repository provides a comprehensive survey on potential attacks on GenAI and robust safeguards. It covers attack strategies, evaluation metrics, benchmarks, and defensive approaches. The repository also implements over 30 auto red teaming methods. It includes surveys, taxonomies, attack strategies, and risks related to LLMs. The goal is to understand vulnerabilities and develop defenses against adversarial attacks on large language models.
Paper-Reading-ConvAI
Paper-Reading-ConvAI is a repository that contains a list of papers, datasets, and resources related to Conversational AI, mainly encompassing dialogue systems and natural language generation. This repository is constantly updating.
awesome-LLM-game-agent-papers
This repository provides a comprehensive survey of research papers on large language model (LLM)-based game agents. LLMs are powerful AI models that can understand and generate human language, and they have shown great promise for developing intelligent game agents. This survey covers a wide range of topics, including adventure games, crafting and exploration games, simulation games, competition games, cooperation games, communication games, and action games. For each topic, the survey provides an overview of the state-of-the-art research, as well as a discussion of the challenges and opportunities for future work.

awesome-and-novel-works-in-slam
This repository contains a curated list of cutting-edge works in Simultaneous Localization and Mapping (SLAM). It includes research papers, projects, and tools related to various aspects of SLAM, such as 3D reconstruction, semantic mapping, novel algorithms, large-scale mapping, and more. The repository aims to showcase the latest advancements in SLAM technology and provide resources for researchers and practitioners in the field.
Awesome-World-Models
This repository is a curated list of papers related to World Models for General Video Generation, Embodied AI, and Autonomous Driving. It includes foundation papers, blog posts, technical reports, surveys, benchmarks, and specific world models for different applications. The repository serves as a valuable resource for researchers and practitioners interested in world models and their applications in robotics and AI.
awesome_LLM-harmful-fine-tuning-papers
This repository is a comprehensive survey of harmful fine-tuning attacks and defenses for large language models (LLMs). It provides a curated list of must-read papers on the topic, covering various aspects such as alignment stage defenses, fine-tuning stage defenses, post-fine-tuning stage defenses, mechanical studies, benchmarks, and attacks/defenses for federated fine-tuning. The repository aims to keep researchers updated on the latest developments in the field and offers insights into the vulnerabilities and safeguards related to fine-tuning LLMs.
Fueling-Ambitions-Via-Book-Discoveries
Fueling-Ambitions-Via-Book-Discoveries is an Advanced Machine Learning & AI Course designed for students, professionals, and AI researchers. The course integrates rigorous theoretical foundations with practical coding exercises, ensuring learners develop a deep understanding of AI algorithms and their applications in finance, healthcare, robotics, NLP, cybersecurity, and more. Inspired by MIT, Stanford, and Harvard’s AI programs, it combines academic research rigor with industry-standard practices used by AI engineers at companies like Google, OpenAI, Facebook AI, DeepMind, and Tesla. Learners can learn 50+ AI techniques from top Machine Learning & Deep Learning books, code from scratch with real-world datasets, projects, and case studies, and focus on ML Engineering & AI Deployment using Django & Streamlit. The course also offers industry-relevant projects to build a strong AI portfolio.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.
For similar tasks
Awesome_Test_Time_LLMs
This repository focuses on test-time computing, exploring various strategies such as test-time adaptation, modifying the input, editing the representation, calibrating the output, test-time reasoning, and search strategies. It covers topics like self-supervised test-time training, in-context learning, activation steering, nearest neighbor models, reward modeling, and multimodal reasoning. The repository provides resources including papers and code for researchers and practitioners interested in enhancing the reasoning capabilities of large language models.
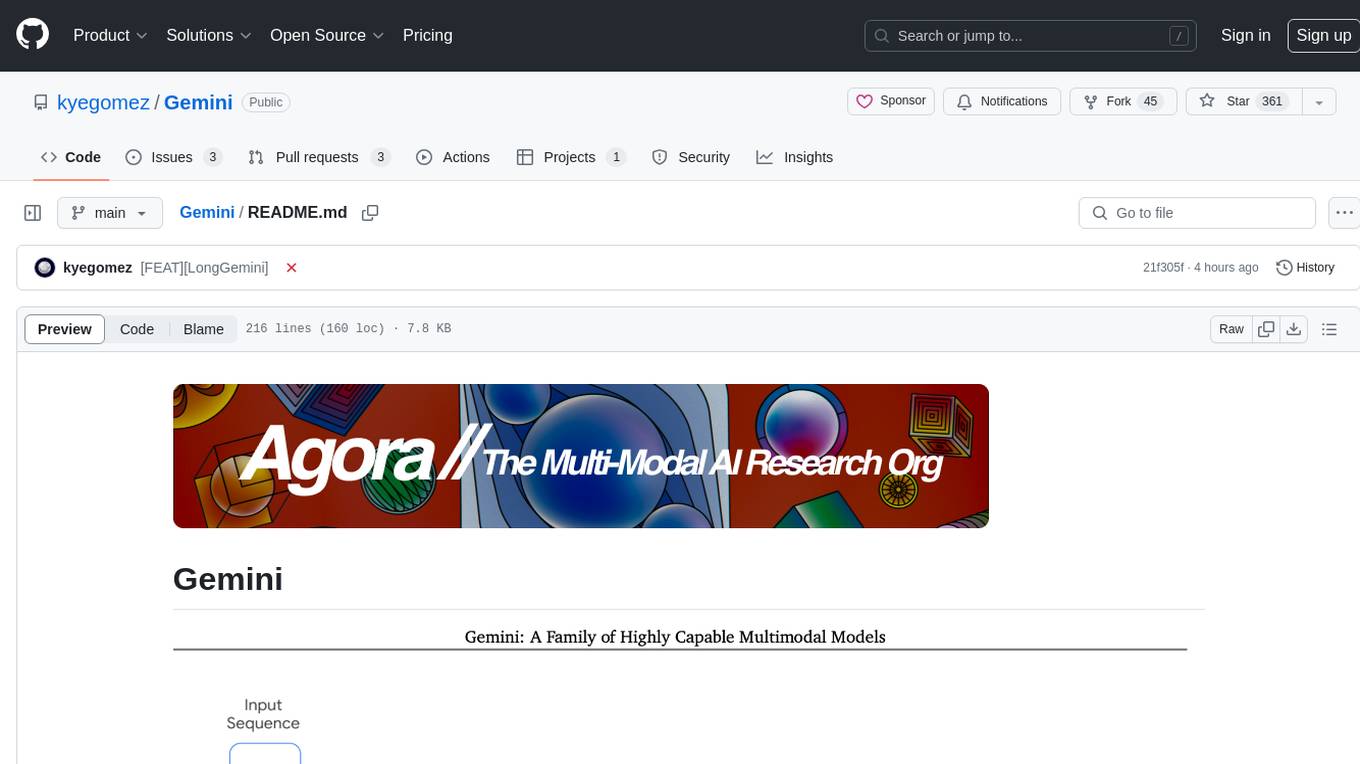
Gemini
Gemini is an open-source model designed to handle multiple modalities such as text, audio, images, and videos. It utilizes a transformer architecture with special decoders for text and image generation. The model processes input sequences by transforming them into tokens and then decoding them to generate image outputs. Gemini differs from other models by directly feeding image embeddings into the transformer instead of using a visual transformer encoder. The model also includes a component called Codi for conditional generation. Gemini aims to effectively integrate image, audio, and video embeddings to enhance its performance.
aligner
Aligner is a model-agnostic alignment tool that learns correctional residuals between preferred and dispreferred answers using a small model. It can be directly applied to various open-source and API-based models with only one-off training, suitable for rapid iteration and improving model performance. Aligner has shown significant improvements in helpfulness, harmlessness, and honesty dimensions across different large language models.
awesome-llms-fine-tuning
This repository is a curated collection of resources for fine-tuning Large Language Models (LLMs) like GPT, BERT, RoBERTa, and their variants. It includes tutorials, papers, tools, frameworks, and best practices to aid researchers, data scientists, and machine learning practitioners in adapting pre-trained models to specific tasks and domains. The resources cover a wide range of topics related to fine-tuning LLMs, providing valuable insights and guidelines to streamline the process and enhance model performance.
prompt-tuning-playbook
The LLM Prompt Tuning Playbook is a comprehensive guide for improving the performance of post-trained Language Models (LLMs) through effective prompting strategies. It covers topics such as pre-training vs. post-training, considerations for prompting, a rudimentary style guide for prompts, and a procedure for iterating on new system instructions. The playbook emphasizes the importance of clear, concise, and explicit instructions to guide LLMs in generating desired outputs. It also highlights the iterative nature of prompt development and the need for systematic evaluation of model responses.
HuaTuoAI
HuaTuoAI is an artificial intelligence image classification system specifically designed for traditional Chinese medicine. It utilizes deep learning techniques, such as Convolutional Neural Networks (CNN), to accurately classify Chinese herbs and ingredients based on input images. The project aims to unlock the secrets of plants, depict the unknown realm of Chinese medicine using technology and intelligence, and perpetuate ancient cultural heritage.

Step-DPO
Step-DPO is a method for enhancing long-chain reasoning ability of LLMs with a data construction pipeline creating a high-quality dataset. It significantly improves performance on math and GSM8K tasks with minimal data and training steps. The tool fine-tunes pre-trained models like Qwen2-7B-Instruct with Step-DPO, achieving superior results compared to other models. It provides scripts for training, evaluation, and deployment, along with examples and acknowledgements.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.