
OpenRedTeaming
Papers about red teaming LLMs and Multimodal models.
Stars: 68
OpenRedTeaming is a repository focused on red teaming for generative models, specifically large language models (LLMs). The repository provides a comprehensive survey on potential attacks on GenAI and robust safeguards. It covers attack strategies, evaluation metrics, benchmarks, and defensive approaches. The repository also implements over 30 auto red teaming methods. It includes surveys, taxonomies, attack strategies, and risks related to LLMs. The goal is to understand vulnerabilities and develop defenses against adversarial attacks on large language models.
README:
Our Survey: Against The Achilles’ Heel: A Survey on Red Teaming for Generative Models [Paper]
To gain a comprehensive understanding of potential attacks on GenAI and develop robust safeguards. We:
- Survey over 120 papers, cover the pipeline from risk taxonomy, attack strategies, evaluation metrics, and benchmarks to defensive approaches.
- propose a comprehensive taxonomy of LLM attack strategies grounded in the inherent capabilities of models developed during pretraining and fine-tuning.
- Implemented more than 30+ auto red teaming methods.
To stay updated or try our RedTeaming tool, please subscribe to our newsletter at our website or join us on Discord!
-
Personal LLM Agents: Insights and Survey about the Capability,Efficiency and Security [Paper]
-
TrustLLM: Trustworthiness in Large Language Models [Paper]
-
Risk Taxonomy,Mitigation,and Assessment Benchmarks of Large Language Model Systems [Paper]
-
Security and Privacy Challenges of Large Language Models: A Survey [Paper]
-
Robust Testing of AI Language Model Resiliency with Novel Adversarial Prompts [Paper]
-
Don't Listen To Me: Understanding and Exploring Jailbreak Prompts of Large Language Models [Paper]
-
Breaking Down the Defenses: A Comparative Survey of Attacks on Large Language Models [Paper]
-
LLM Jailbreak Attack versus Defense Techniques -- A Comprehensive Study [Paper]
-
An Early Categorization of Prompt Injection Attacks on Large Language Models [Paper]
-
Comprehensive Assessment of Jailbreak Attacks Against LLMs [Paper]
-
"Do Anything Now": Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models [Paper]
-
Survey of Vulnerabilities in Large Language Models Revealed by Adversarial Attacks [Paper]
-
Ignore This Title and HackAPrompt: Exposing Systemic Vulnerabilities of LLMs through a Global Scale Prompt Hacking Competition [Paper]
-
Adversarial Attacks and Defenses in Large Language Models: Old and New Threats [Paper]
-
Tricking LLMs into Disobedience: Formalizing,Analyzing,and Detecting Jailbreaks [Paper]
-
Summon a Demon and Bind it: A Grounded Theory of LLM Red Teaming in the Wild [Paper]
-
A Comprehensive Survey of Attack Techniques,Implementation,and Mitigation Strategies in Large Language Models [Paper]
-
Beyond Boundaries: A Comprehensive Survey of Transferable Attacks on AI Systems [Paper]
-
Beyond Boundaries: A Comprehensive Survey of Transferable Attacks on AI Systems [Paper]
-
Mapping LLM Security Landscapes: A Comprehensive Stakeholder Risk Assessment Proposal [Paper]
-
Securing Large Language Models: Threats,Vulnerabilities and Responsible Practices [Paper]
-
Privacy in Large Language Models: Attacks,Defenses and Future Directions [Paper]
-
Beyond the Safeguards: Exploring the Security Risks of ChatGPT [Paper]
-
Towards Safer Generative Language Models: A Survey on Safety Risks,Evaluations,and Improvements [Paper]
-
Use of LLMs for Illicit Purposes: Threats,Prevention Measures,and Vulnerabilities [Paper]
-
From ChatGPT to ThreatGPT: Impact of Generative AI in Cybersecurity and Privacy [Paper]
-
Identifying and Mitigating Vulnerabilities in LLM-Integrated Applications [Paper]
-
The power of generative AI in cybersecurity: Opportunities and challenges [Paper]
-
Coercing LLMs to do and reveal (almost) anything [Paper]
-
The History and Risks of Reinforcement Learning and Human Feedback [Paper]
-
From Chatbots to PhishBots? -- Preventing Phishing scams created using ChatGPT,Google Bard and Claude [Paper]
-
Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study [Paper]
-
Generating Phishing Attacks using ChatGPT [Paper]
-
Personalisation within bounds: A risk taxonomy and policy framework for the alignment of large language models with personalised feedback [Paper]
-
AI Deception: A Survey of Examples,Risks,and Potential Solutions [Paper]
-
A Security Risk Taxonomy for Large Language Models [Paper]
-
Red-Teaming for Generative AI: Silver Bullet or Security Theater? [Paper]
-
The Ethics of Interaction: Mitigating Security Threats in LLMs [Paper]
-
A Safe Harbor for AI Evaluation and Red Teaming [Paper]
-
Red teaming ChatGPT via Jailbreaking: Bias,Robustness,Reliability and Toxicity [Paper]
-
The Promise and Peril of Artificial Intelligence -- Violet Teaming Offers a Balanced Path Forward [Paper]
-
Red-Teaming Segment Anything Model [Paper]
-
A Mechanistic Understanding of Alignment Algorithms: A Case Study on DPO and Toxicity [Paper]
-
Speak Out of Turn: Safety Vulnerability of Large Language Models in Multi-turn Dialogue [Paper]
-
Tradeoffs Between Alignment and Helpfulness in Language Models [Paper]
-
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications [Paper]
-
"It's a Fair Game'',or Is It? Examining How Users Navigate Disclosure Risks and Benefits When Using LLM-Based Conversational Agents [Paper]
-
Exploiting Programmatic Behavior of LLMs: Dual-Use Through Standard Security Attacks [Paper]
-
Can Large Language Models Change User Preference Adversarially? [Paper]
-
Are aligned neural networks adversarially aligned? [Paper]
-
Fake Alignment: Are LLMs Really Aligned Well? [Paper]
-
Causality Analysis for Evaluating the Security of Large Language Models [Paper]
-
Transfer Attacks and Defenses for Large Language Models on Coding Tasks [Paper]
-
Few-Shot Adversarial Prompt Learning on Vision-Language Models [Paper]
-
Hijacking Context in Large Multi-modal Models [Paper]
-
Great,Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack [Paper]
-
BadChain: Backdoor Chain-of-Thought Prompting for Large Language Models [Paper]
-
Universal Vulnerabilities in Large Language Models: Backdoor Attacks for In-context Learning [Paper]
-
Nevermind: Instruction Override and Moderation in Large Language Models [Paper]
-
Red-Teaming Large Language Models using Chain of Utterances for Safety-Alignment [Paper]
-
Backdoor Attacks for In-Context Learning with Language Models [Paper]
-
Jailbreak and Guard Aligned Language Models with Only Few In-Context Demonstrations [Paper]
-
Analyzing the Inherent Response Tendency of LLMs: Real-World Instructions-Driven Jailbreak [Paper]
-
Bypassing the Safety Training of Open-Source LLMs with Priming Attacks [Paper]
-
Hijacking Large Language Models via Adversarial In-Context Learning [Paper]
-
On the Robustness of Large Multimodal Models Against Image Adversarial Attacks [Paper]
-
Vision-LLMs Can Fool Themselves with Self-Generated Typographic Attacks [Paper]
-
Images are Achilles' Heel of Alignment: Exploiting Visual Vulnerabilities for Jailbreaking Multimodal Large Language Models [Paper]
-
FigStep: Jailbreaking Large Vision-language Models via Typographic Visual Prompts [Paper]
-
InstructTA: Instruction-Tuned Targeted Attack for Large Vision-Language Models [Paper]
-
Abusing Images and Sounds for Indirect Instruction Injection in Multi-Modal LLMs [Paper]
-
Visual Adversarial Examples Jailbreak Aligned Large Language Models [Paper]
-
Jailbreak in pieces: Compositional Adversarial Attacks on Multi-Modal Language Models [Paper]
-
Play Guessing Game with LLM: Indirect Jailbreak Attack with Implicit Clues [Paper]
-
FuzzLLM: A Novel and Universal Fuzzing Framework for Proactively Discovering Jailbreak Vulnerabilities in Large Language Models [Paper]
-
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts [Paper]
-
Prompt Packer: Deceiving LLMs through Compositional Instruction with Hidden Attacks [Paper]
-
DeepInception: Hypnotize Large Language Model to Be Jailbreaker [Paper]
-
A Wolf in Sheep's Clothing: Generalized Nested Jailbreak Prompts can Fool Large Language Models Easily [Paper]
-
Safety Alignment in NLP Tasks: Weakly Aligned Summarization as an In-Context Attack [Paper]
-
Cognitive Overload: Jailbreaking Large Language Models with Overloaded Logical Thinking [Paper]
-
A Cross-Language Investigation into Jailbreak Attacks in Large Language Models [Paper]
-
The Language Barrier: Dissecting Safety Challenges of LLMs in Multilingual Contexts [Paper]
-
Sandwich attack: Multi-language Mixture Adaptive Attack on LLMs [Paper]
-
Backdoor Attack on Multilingual Machine Translation [Paper]
-
Multilingual Jailbreak Challenges in Large Language Models [Paper]
-
Low-Resource Languages Jailbreak GPT-4 [Paper]
-
Using Hallucinations to Bypass GPT4's Filter [Paper]
-
The Butterfly Effect of Altering Prompts: How Small Changes and Jailbreaks Affect Large Language Model Performance [Paper]
-
Making Them Ask and Answer: Jailbreaking Large Language Models in Few Queries via Disguise and Reconstruction [Paper]
-
PRP: Propagating Universal Perturbations to Attack Large Language Model Guard-Rails [Paper]
-
GPT-4 Is Too Smart To Be Safe: Stealthy Chat with LLMs via Cipher [Paper]
-
Punctuation Matters! Stealthy Backdoor Attack for Language Models [Paper]
-
Foot In The Door: Understanding Large Language Model Jailbreaking via Cognitive Psychology [Paper]
-
PsySafe: A Comprehensive Framework for Psychological-based Attack,Defense,and Evaluation of Multi-agent System Safety [Paper]
-
How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge AI Safety by Humanizing LLMs [Paper]
-
Scalable and Transferable Black-Box Jailbreaks for Language Models via Persona Modulation [Paper]
-
Who is ChatGPT? Benchmarking LLMs' Psychological Portrayal Using PsychoBench [Paper]
-
Exploiting Large Language Models (LLMs) through Deception Techniques and Persuasion Principles [Paper]
-
Shadowcast: Stealthy Data Poisoning Attacks Against Vision-Language Models [Paper]
-
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training [Paper]
-
What's in Your "Safe" Data?: Identifying Benign Data that Breaks Safety [Paper]
-
Data Poisoning Attacks on Off-Policy Policy Evaluation Methods [Paper]
-
BadEdit: Backdooring large language models by model editing [Paper]
-
Best-of-Venom: Attacking RLHF by Injecting Poisoned Preference Data [Paper]
-
Learning to Poison Large Language Models During Instruction Tuning [Paper]
-
Exploring Backdoor Vulnerabilities of Chat Models [Paper]
-
Instructions as Backdoors: Backdoor Vulnerabilities of Instruction Tuning for Large Language Models [Paper]
-
Forcing Generative Models to Degenerate Ones: The Power of Data Poisoning Attacks [Paper]
-
Stealthy and Persistent Unalignment on Large Language Models via Backdoor Injections [Paper]
-
Backdoor Activation Attack: Attack Large Language Models using Activation Steering for Safety-Alignment [Paper]
-
On the Exploitability of Reinforcement Learning with Human Feedback for Large Language Models [Paper]
-
Test-time Backdoor Mitigation for Black-Box Large Language Models with Defensive Demonstrations [Paper]
-
Universal Jailbreak Backdoors from Poisoned Human Feedback [Paper]
-
LoRA-as-an-Attack! Piercing LLM Safety Under The Share-and-Play Scenario [Paper]
-
Emulated Disalignment: Safety Alignment for Large Language Models May Backfire! [Paper]
-
LoRA Fine-tuning Efficiently Undoes Safety Training in Llama 2-Chat 70B [Paper]
-
BadLlama: cheaply removing safety fine-tuning from Llama 2-Chat 13B [Paper]
-
Language Model Unalignment: Parametric Red-Teaming to Expose Hidden Harms and Biases [Paper]
-
Removing RLHF Protections in GPT-4 via Fine-Tuning [Paper]
-
On the Safety of Open-Sourced Large Language Models: Does Alignment Really Prevent Them From Being Misused? [Paper]
-
Shadow Alignment: The Ease of Subverting Safely-Aligned Language Models [Paper]
-
Fine-tuning Aligned Language Models Compromises Safety,Even When Users Do Not Intend To! [Paper]
-
Prompting4Debugging: Red-Teaming Text-to-Image Diffusion Models by Finding Problematic Prompts [Paper]
-
From Noise to Clarity: Unraveling the Adversarial Suffix of Large Language Model Attacks via Translation of Text Embeddings [Paper]
-
Fast Adversarial Attacks on Language Models In One GPU Minute [Paper]
-
Gradient-Based Language Model Red Teaming [Paper]
-
Automatic and Universal Prompt Injection Attacks against Large Language Models [Paper]
-
$\textit{LinkPrompt}$: Natural and Universal Adversarial Attacks on Prompt-based Language Models [Paper]
-
Neural Exec: Learning (and Learning from) Execution Triggers for Prompt Injection Attacks [Paper]
-
Jailbreaking Leading Safety-Aligned LLMs with Simple Adaptive Attacks [Paper]
-
Rapid Optimization for Jailbreaking LLMs via Subconscious Exploitation and Echopraxia [Paper]
-
AutoDAN: Interpretable Gradient-Based Adversarial Attacks on Large Language Models [Paper]
-
Universal and Transferable Adversarial Attacks on Aligned Language Models [Paper]
-
Soft-prompt Tuning for Large Language Models to Evaluate Bias [Paper]
-
TrojLLM: A Black-box Trojan Prompt Attack on Large Language Models [Paper]
-
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models [Paper]
-
Eliciting Language Model Behaviors using Reverse Language Models [Paper]
(2023)
-
All in How You Ask for It: Simple Black-Box Method for Jailbreak Attacks [Paper]
-
Adversarial Attacks on GPT-4 via Simple Random Search [Paper]
-
Tastle: Distract Large Language Models for Automatic Jailbreak Attack [Paper]
-
Red Teaming Language Models with Language Models [Paper]
-
An LLM can Fool Itself: A Prompt-Based Adversarial Attack [Paper]
-
Jailbreaking Black Box Large Language Models in Twenty Queries [Paper]
-
Tree of Attacks: Jailbreaking Black-Box LLMs Automatically [Paper]
-
AART: AI-Assisted Red-Teaming with Diverse Data Generation for New LLM-powered Applications [Paper]
-
DALA: A Distribution-Aware LoRA-Based Adversarial Attack against Language Models [Paper]
-
JAB: Joint Adversarial Prompting and Belief Augmentation [Paper]
-
No Offense Taken: Eliciting Offensiveness from Language Models [Paper]
-
LoFT: Local Proxy Fine-tuning For Improving Transferability Of Adversarial Attacks Against Large Language Model [Paper]
-
Weak-to-Strong Jailbreaking on Large Language Models [Paper]
-
COLD-Attack: Jailbreaking LLMs with Stealthiness and Controllability [Paper]
-
Semantic Mirror Jailbreak: Genetic Algorithm Based Jailbreak Prompts Against Open-source LLMs [Paper]
-
Open Sesame! Universal Black Box Jailbreaking of Large Language Models [Paper]
-
SneakyPrompt: Jailbreaking Text-to-image Generative Models [Paper]
-
Red Teaming Game: A Game-Theoretic Framework for Red Teaming Language Models [Paper]
-
Explore,Establish,Exploit: Red Teaming Language Models from Scratch [Paper]
-
Unveiling the Implicit Toxicity in Large Language Models [Paper]
-
Configurable Safety Tuning of Language Models with Synthetic Preference Data [Paper]
-
Enhancing LLM Safety via Constrained Direct Preference Optimization [Paper]
-
Safe RLHF: Safe Reinforcement Learning from Human Feedback [Paper]
-
BeaverTails: Towards Improved Safety Alignment of LLM via a Human-Preference Dataset [Paper]
-
Safer-Instruct: Aligning Language Models with Automated Preference Data [Paper]
-
SafeGen: Mitigating Unsafe Content Generation in Text-to-Image Models [Paper]
-
Safety Fine-Tuning at (Almost) No Cost: A Baseline for Vision Large Language Models [Paper]
-
Developing Safe and Responsible Large Language Models -- A Comprehensive Framework [Paper]
-
Immunization against harmful fine-tuning attacks [Paper]
-
Mitigating Fine-tuning Jailbreak Attack with Backdoor Enhanced Alignment [Paper]
-
Dialectical Alignment: Resolving the Tension of 3H and Security Threats of LLMs [Paper]
-
Pruning for Protection: Increasing Jailbreak Resistance in Aligned LLMs Without Fine-Tuning [Paper]
-
Eraser: Jailbreaking Defense in Large Language Models via Unlearning Harmful Knowledge [Paper]
-
Two Heads are Better than One: Nested PoE for Robust Defense Against Multi-Backdoors [Paper]
-
Defending Against Weight-Poisoning Backdoor Attacks for Parameter-Efficient Fine-Tuning [Paper]
-
Safety-Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models that Follow Instructions [Paper]
-
Defending Against Alignment-Breaking Attacks via Robustly Aligned LLM [Paper]
-
Learn What NOT to Learn: Towards Generative Safety in Chatbots [Paper]
-
Jatmo: Prompt Injection Defense by Task-Specific Finetuning [Paper]
-
AdaShield: Safeguarding Multimodal Large Language Models from Structure-based Attack via Adaptive Shield Prompting [Paper]
-
Break the Breakout: Reinventing LM Defense Against Jailbreak Attacks with Self-Refinement [Paper]
-
On Prompt-Driven Safeguarding for Large Language Models [Paper]
-
Signed-Prompt: A New Approach to Prevent Prompt Injection Attacks Against LLM-Integrated Applications [Paper]
Xuchen Suo (2024)
-
Intention Analysis Makes LLMs A Good Jailbreak Defender [Paper]
-
Defending Against Indirect Prompt Injection Attacks With Spotlighting [Paper]
-
Ensuring Safe and High-Quality Outputs: A Guideline Library Approach for Language Models [Paper]
-
Goal-guided Generative Prompt Injection Attack on Large Language Models [Paper]
-
StruQ: Defending Against Prompt Injection with Structured Queries [Paper]
-
Studious Bob Fight Back Against Jailbreaking via Prompt Adversarial Tuning [Paper]
-
Self-Guard: Empower the LLM to Safeguard Itself [Paper]
-
Using In-Context Learning to Improve Dialogue Safety [Paper]
-
Defending Large Language Models Against Jailbreaking Attacks Through Goal Prioritization [Paper]
-
Bergeron: Combating Adversarial Attacks through a Conscience-Based Alignment Framework [Paper]
-
Combating Adversarial Attacks with Multi-Agent Debate [Paper]
-
TrustAgent: Towards Safe and Trustworthy LLM-based Agents through Agent Constitution [Paper]
-
AutoDefense: Multi-Agent LLM Defense against Jailbreak Attacks [Paper]
-
Learn to Disguise: Avoid Refusal Responses in LLM's Defense via a Multi-agent Attacker-Disguiser Game [Paper]
-
Jailbreaker in Jail: Moving Target Defense for Large Language Models [Paper]
-
UFID: A Unified Framework for Input-level Backdoor Detection on Diffusion Models [Paper]
-
Universal Prompt Optimizer for Safe Text-to-Image Generation [Paper]
-
Eyes Closed,Safety On: Protecting Multimodal LLMs via Image-to-Text Transformation [Paper]
-
Eyes Closed,Safety On: Protecting Multimodal LLMs via Image-to-Text Transformation [Paper]
-
MLLM-Protector: Ensuring MLLM's Safety without Hurting Performance [Paper]
-
Added Toxicity Mitigation at Inference Time for Multimodal and Massively Multilingual Translation [Paper]
-
A Mutation-Based Method for Multi-Modal Jailbreaking Attack Detection [Paper]
-
Detection and Defense Against Prominent Attacks on Preconditioned LLM-Integrated Virtual Assistants [Paper]
-
ShieldLM: Empowering LLMs as Aligned,Customizable and Explainable Safety Detectors [Paper]
-
Round Trip Translation Defence against Large Language Model Jailbreaking Attacks [Paper]
-
Gradient Cuff: Detecting Jailbreak Attacks on Large Language Models by Exploring Refusal Loss Landscapes [Paper]
-
Defending Jailbreak Prompts via In-Context Adversarial Game [Paper]
-
SPML: A DSL for Defending Language Models Against Prompt Attacks [Paper]
-
Robust Safety Classifier for Large Language Models: Adversarial Prompt Shield [Paper]
-
AI Control: Improving Safety Despite Intentional Subversion [Paper]
-
Maatphor: Automated Variant Analysis for Prompt Injection Attacks [Paper]
-
Defending LLMs against Jailbreaking Attacks via Backtranslation [Paper]
-
Robust Prompt Optimization for Defending Language Models Against Jailbreaking Attacks [Paper]
-
Jailbreaking is Best Solved by Definition [Paper]
-
LLM Self Defense: By Self Examination,LLMs Know They Are Being Tricked [Paper]
-
RigorLLM: Resilient Guardrails for Large Language Models against Undesired Content [Paper]
-
NeMo Guardrails: A Toolkit for Controllable and Safe LLM Applications with Programmable Rails [Paper]
-
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations [Paper]
-
Defending Large Language Models against Jailbreak Attacks via Semantic Smoothing [Paper]
-
Certifying LLM Safety against Adversarial Prompting [Paper]
-
Baseline Defenses for Adversarial Attacks Against Aligned Language Models [Paper]
-
Detecting Language Model Attacks with Perplexity [Paper]
-
SmoothLLM: Defending Large Language Models Against Jailbreaking Attacks [Paper]
-
Token-Level Adversarial Prompt Detection Based on Perplexity Measures and Contextual Information [Paper]
-
Towards Safety and Helpfulness Balanced Responses via Controllable Large Language Models [Paper]
-
SafeDecoding: Defending against Jailbreak Attacks via Safety-Aware Decoding [Paper]
-
A Novel Evaluation Framework for Assessing Resilience Against Prompt Injection Attacks in Large Language Models [Paper]
-
AttackEval: How to Evaluate the Effectiveness of Jailbreak Attacking on Large Language Models [Paper]
-
Take a Look at it! Rethinking How to Evaluate Language Model Jailbreak [Paper]
-
How (un)ethical are instruction-centric responses of LLMs? Unveiling the vulnerabilities of safety guardrails to harmful queries [Paper]
-
The Art of Defending: A Systematic Evaluation and Analysis of LLM Defense Strategies on Safety and Over-Defensiveness [Paper]
-
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models [Paper]
-
SafetyPrompts: a Systematic Review of Open Datasets for Evaluating and Improving Large Language Model Safety [Paper]
-
From Representational Harms to Quality-of-Service Harms: A Case Study on Llama 2 Safety Safeguards [Paper]
-
SALAD-Bench: A Hierarchical and Comprehensive Safety Benchmark for Large Language Models [Paper]
-
A StrongREJECT for Empty Jailbreaks [Paper]
-
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal [Paper]
-
SafetyBench: Evaluating the Safety of Large Language Models with Multiple Choice Questions [Paper]
-
XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models [Paper]
-
Do-Not-Answer: A Dataset for Evaluating Safeguards in LLMs [Paper]
-
Safety Assessment of Chinese Large Language Models [Paper]
-
Red Teaming Language Models to Reduce Harms: Methods,Scaling Behaviors,and Lessons Learned [Paper]
-
DICES Dataset: Diversity in Conversational AI Evaluation for Safety [Paper]
-
Latent Jailbreak: A Benchmark for Evaluating Text Safety and Output Robustness of Large Language Models [Paper]
-
Tensor Trust: Interpretable Prompt Injection Attacks from an Online Game [Paper]
-
Can LLMs Follow Simple Rules? [Paper]
-
SimpleSafetyTests: a Test Suite for Identifying Critical Safety Risks in Large Language Models [Paper]
-
Benchmarking and Defending Against Indirect Prompt Injection Attacks on Large Language Models [Paper]
-
SC-Safety: A Multi-round Open-ended Question Adversarial Safety Benchmark for Large Language Models in Chinese [Paper]
-
Walking a Tightrope -- Evaluating Large Language Models in High-Risk Domains [Paper]
-
MM-SafetyBench: A Benchmark for Safety Evaluation of Multimodal Large Language Models [Paper]
-
Agent Smith: A Single Image Can Jailbreak One Million Multimodal LLM Agents Exponentially Fast [Paper]
-
How Many Unicorns Are in This Image? A Safety Evaluation Benchmark for Vision LLMs [Paper]
-
Towards Red Teaming in Multimodal and Multilingual Translation [Paper]
-
JailBreakV-28K: A Benchmark for Assessing the Robustness of MultiModal Large Language Models against Jailbreak Attacks [Paper]
-
Red Teaming GPT-4V: Are GPT-4V Safe Against Uni/Multi-Modal Jailbreak Attacks? [Paper]
-
R-Judge: Benchmarking Safety Risk Awareness for LLM Agents [Paper]
-
GPT in Sheep's Clothing: The Risk of Customized GPTs [Paper]
-
ToolSword: Unveiling Safety Issues of Large Language Models in Tool Learning Across Three Stages [Paper]
-
A Trembling House of Cards? Mapping Adversarial Attacks against Language Agents [Paper]
-
Rapid Adoption,Hidden Risks: The Dual Impact of Large Language Model Customization [Paper]
-
Goal-Oriented Prompt Attack and Safety Evaluation for LLMs [Paper]
-
Identifying the Risks of LM Agents with an LM-Emulated Sandbox [Paper]
-
CValues: Measuring the Values of Chinese Large Language Models from Safety to Responsibility [Paper]
-
Exploiting Novel GPT-4 APIs [Paper]
-
Evil Geniuses: Delving into the Safety of LLM-based Agents [Paper]
-
Assessing Prompt Injection Risks in 200+ Custom GPTs [Paper]
-
DeceptPrompt: Exploiting LLM-driven Code Generation via Adversarial Natural Language Instructions [Paper]
-
Poisoned ChatGPT Finds Work for Idle Hands: Exploring Developers' Coding Practices with Insecure Suggestions from Poisoned AI Models [Paper]
-
Scaling Behavior of Machine Translation with Large Language Models under Prompt Injection Attacks [Paper]
-
From Prompt Injections to SQL Injection Attacks: How Protected is Your LLM-Integrated Web Application? [Paper]
-
Not what you've signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection [Paper]
-
Prompt Injection attack against LLM-integrated Applications [Paper]
-
Jailbreaking GPT-4V via Self-Adversarial Attacks with System Prompts [Paper]
-
Prompt Stealing Attacks Against Large Language Models [Paper]
-
Effective Prompt Extraction from Language Models [Paper]
-
Few-Shot Adversarial Prompt Learning on Vision-Language Models [Paper]
-
Hijacking Context in Large Multi-modal Models [Paper]
-
On the Robustness of Large Multimodal Models Against Image Adversarial Attacks [Paper]
-
Images are Achilles' Heel of Alignment: Exploiting Visual Vulnerabilities for Jailbreaking Multimodal Large Language Models [Paper]
-
Vision-LLMs Can Fool Themselves with Self-Generated Typographic Attacks [Paper]
-
Visual Adversarial Examples Jailbreak Aligned Large Language Models [Paper]
-
Jailbreak in pieces: Compositional Adversarial Attacks on Multi-Modal Language Models [Paper]
-
Abusing Images and Sounds for Indirect Instruction Injection in Multi-Modal LLMs [Paper]
-
FigStep: Jailbreaking Large Vision-language Models via Typographic Visual Prompts [Paper]
-
InstructTA: Instruction-Tuned Targeted Attack for Large Vision-Language Models [Paper]
-
Diffusion Attack: Leveraging Stable Diffusion for Naturalistic Image Attacking [Paper]
-
On the Adversarial Robustness of Multi-Modal Foundation Models [Paper]
-
How Robust is Google's Bard to Adversarial Image Attacks? [Paper]
-
Test-Time Backdoor Attacks on Multimodal Large Language Models [Paper]
-
SA-Attack: Improving Adversarial Transferability of Vision-Language Pre-training Models via Self-Augmentation [Paper]
-
MMA-Diffusion: MultiModal Attack on Diffusion Models [Paper]
-
Improving Adversarial Transferability of Visual-Language Pre-training Models through Collaborative Multimodal Interaction [Paper]
-
An Image Is Worth 1000 Lies: Transferability of Adversarial Images across Prompts on Vision-Language Models [Paper]
-
SneakyPrompt: Jailbreaking Text-to-image Generative Models [Paper]
-
Prompting4Debugging: Red-Teaming Text-to-Image Diffusion Models by Finding Problematic Prompts [Paper]
-
UFID: A Unified Framework for Input-level Backdoor Detection on Diffusion Models [Paper]
-
Universal Prompt Optimizer for Safe Text-to-Image Generation [Paper]
-
Eyes Closed,Safety On: Protecting Multimodal LLMs via Image-to-Text Transformation [Paper]
-
Eyes Closed,Safety On: Protecting Multimodal LLMs via Image-to-Text Transformation [Paper]
-
MLLM-Protector: Ensuring MLLM's Safety without Hurting Performance [Paper]
-
Added Toxicity Mitigation at Inference Time for Multimodal and Massively Multilingual Translation [Paper]
-
A Mutation-Based Method for Multi-Modal Jailbreaking Attack Detection [Paper]
-
SafeGen: Mitigating Unsafe Content Generation in Text-to-Image Models [Paper]
-
AdaShield: Safeguarding Multimodal Large Language Models from Structure-based Attack via Adaptive Shield Prompting [Paper]
-
Safety Fine-Tuning at (Almost) No Cost: A Baseline for Vision Large Language Models [Paper]
-
Red Teaming GPT-4V: Are GPT-4V Safe Against Uni/Multi-Modal Jailbreak Attacks? [Paper]
-
JailBreakV-28K: A Benchmark for Assessing the Robustness of MultiModal Large Language Models against Jailbreak Attacks [Paper]
-
Agent Smith: A Single Image Can Jailbreak One Million Multimodal LLM Agents Exponentially Fast [Paper]
-
MM-SafetyBench: A Benchmark for Safety Evaluation of Multimodal Large Language Models [Paper]
-
How Many Unicorns Are in This Image? A Safety Evaluation Benchmark for Vision LLMs [Paper]
-
Towards Red Teaming in Multimodal and Multilingual Translation [Paper]
-
Adversarial Nibbler: An Open Red-Teaming Method for Identifying Diverse Harms in Text-to-Image Generation [Paper]
-
Red Teaming Visual Language Models [Paper]
@article{lin2024achilles,
title={Against The Achilles' Heel: A Survey on Red Teaming for Generative Models},
author={Lizhi Lin and Honglin Mu and Zenan Zhai and Minghan Wang and Yuxia Wang and Renxi Wang and Junjie Gao and Yixuan Zhang and Wanxiang Che and Timothy Baldwin and Xudong Han and Haonan Li},
year={2024},
journal={arXiv preprint, arXiv:2404.00629},
primaryClass={cs.CL}
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for OpenRedTeaming
Similar Open Source Tools
OpenRedTeaming
OpenRedTeaming is a repository focused on red teaming for generative models, specifically large language models (LLMs). The repository provides a comprehensive survey on potential attacks on GenAI and robust safeguards. It covers attack strategies, evaluation metrics, benchmarks, and defensive approaches. The repository also implements over 30 auto red teaming methods. It includes surveys, taxonomies, attack strategies, and risks related to LLMs. The goal is to understand vulnerabilities and develop defenses against adversarial attacks on large language models.

tensorzero
TensorZero is an open-source platform that helps LLM applications graduate from API wrappers into defensible AI products. It enables a data & learning flywheel for LLMs by unifying inference, observability, optimization, and experimentation. The platform includes a high-performance model gateway, structured schema-based inference, observability, experimentation, and data warehouse for analytics. TensorZero Recipes optimize prompts and models, and the platform supports experimentation features and GitOps orchestration for deployment.
ToolUniverse
ToolUniverse is a collection of 211 biomedical tools designed for Agentic AI, providing access to biomedical knowledge for solving therapeutic reasoning tasks. The tools cover various aspects of drugs and diseases, linked to trusted sources like US FDA-approved drugs since 1939, Open Targets, and Monarch Initiative.
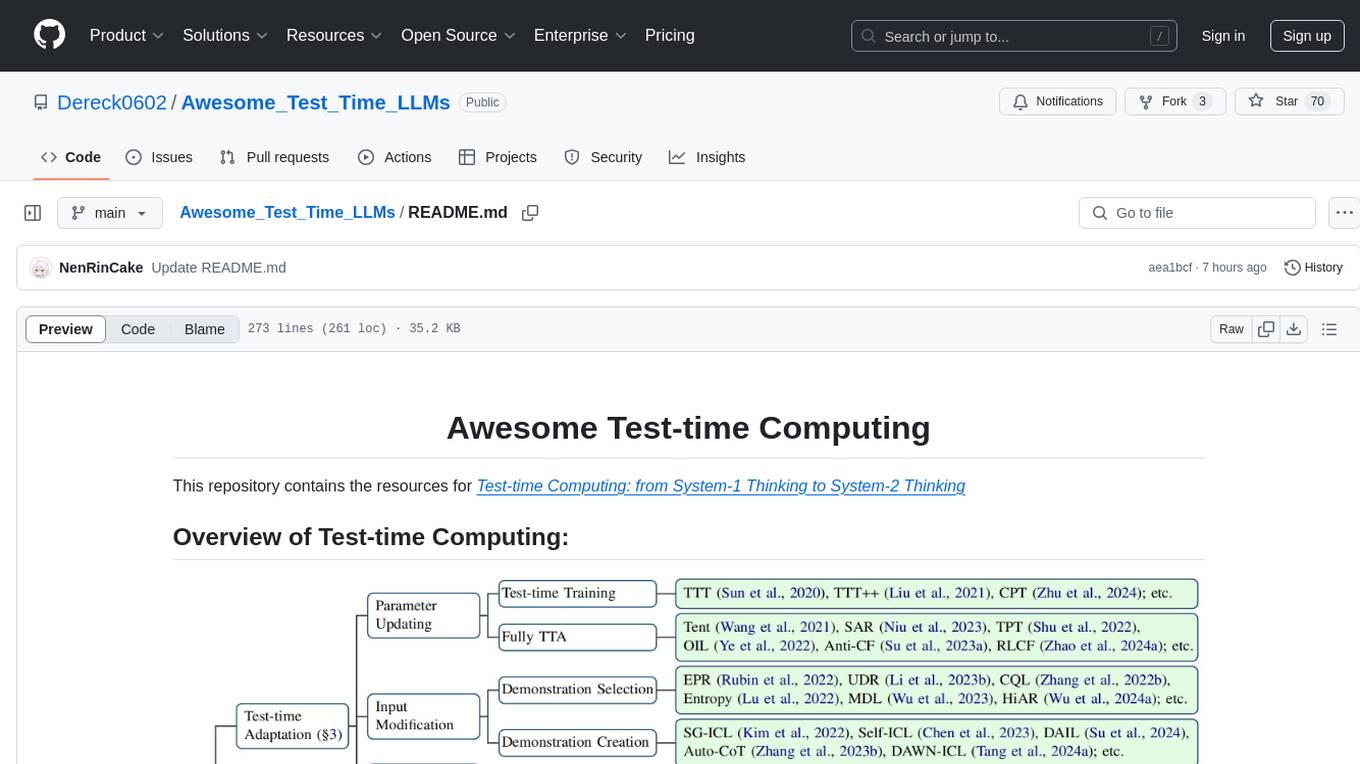
Awesome_Test_Time_LLMs
This repository focuses on test-time computing, exploring various strategies such as test-time adaptation, modifying the input, editing the representation, calibrating the output, test-time reasoning, and search strategies. It covers topics like self-supervised test-time training, in-context learning, activation steering, nearest neighbor models, reward modeling, and multimodal reasoning. The repository provides resources including papers and code for researchers and practitioners interested in enhancing the reasoning capabilities of large language models.
MedLLMsPracticalGuide
This repository serves as a practical guide for Medical Large Language Models (Medical LLMs) and provides resources, surveys, and tools for building, fine-tuning, and utilizing LLMs in the medical domain. It covers a wide range of topics including pre-training, fine-tuning, downstream biomedical tasks, clinical applications, challenges, future directions, and more. The repository aims to provide insights into the opportunities and challenges of LLMs in medicine and serve as a practical resource for constructing effective medical LLMs.
lawglance
LawGlance is an AI-powered legal assistant that aims to bridge the gap between people and legal access. It is a free, open-source initiative designed to provide quick and accurate legal support tailored to individual needs. The project covers various laws, with plans for international expansion in the future. LawGlance utilizes AI-powered Retriever-Augmented Generation (RAG) to deliver legal guidance accessible to both laypersons and professionals. The tool is developed with support from mentors and experts at Data Science Academy and Curvelogics.
gen-ai-experiments
Gen-AI-Experiments is a structured collection of Jupyter notebooks and AI experiments designed to guide users through various AI tools, frameworks, and models. It offers valuable resources for both beginners and experienced practitioners, covering topics such as AI agents, model testing, RAG systems, real-world applications, and open-source tools. The repository includes folders with curated libraries, AI agents, experiments, LLM testing, open-source libraries, RAG experiments, and educhain experiments, each focusing on different aspects of AI development and application.
Fueling-Ambitions-Via-Book-Discoveries
Fueling-Ambitions-Via-Book-Discoveries is an Advanced Machine Learning & AI Course designed for students, professionals, and AI researchers. The course integrates rigorous theoretical foundations with practical coding exercises, ensuring learners develop a deep understanding of AI algorithms and their applications in finance, healthcare, robotics, NLP, cybersecurity, and more. Inspired by MIT, Stanford, and Harvard’s AI programs, it combines academic research rigor with industry-standard practices used by AI engineers at companies like Google, OpenAI, Facebook AI, DeepMind, and Tesla. Learners can learn 50+ AI techniques from top Machine Learning & Deep Learning books, code from scratch with real-world datasets, projects, and case studies, and focus on ML Engineering & AI Deployment using Django & Streamlit. The course also offers industry-relevant projects to build a strong AI portfolio.
Awesome-Trustworthy-Embodied-AI
The Awesome Trustworthy Embodied AI repository focuses on the development of safe and trustworthy Embodied Artificial Intelligence (EAI) systems. It addresses critical challenges related to safety and trustworthiness in EAI, proposing a unified research framework and defining levels of safety and resilience. The repository provides a comprehensive review of state-of-the-art solutions, benchmarks, and evaluation metrics, aiming to bridge the gap between capability advancement and safety mechanisms in EAI development.
ITBench
ITBench is a platform designed to measure the performance of AI agents in complex and real-world inspired IT automation tasks. It focuses on three key use cases: Site Reliability Engineering (SRE), Compliance & Security Operations (CISO), and Financial Operations (FinOps). The platform provides a real-world representation of IT environments, open and extensible framework, push-button workflows, and Kubernetes-based scenario environments. Researchers and developers can replicate real-world incidents in Kubernetes environments, develop AI agents, and evaluate them using a fully-managed leaderboard.
Zettelgarden
Zettelgarden is a human-centric, open-source personal knowledge management system that helps users develop and maintain their understanding of the world. It focuses on creating and connecting atomic notes, thoughtful AI integration, and scalability from personal notes to company knowledge bases. The project is actively evolving, with features subject to change based on community feedback and development priorities.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.
ai-agent-papers
The AI Agents Papers repository provides a curated collection of papers focusing on AI agents, covering topics such as agent capabilities, applications, architectures, and presentations. It includes a variety of papers on ideation, decision making, long-horizon tasks, learning, memory-based agents, self-evolving agents, and more. The repository serves as a valuable resource for researchers and practitioners interested in AI agent technologies and advancements.

LLM-Agent-Survey
LLM-Agent-Survey is a comprehensive repository that provides a curated list of papers related to Large Language Model (LLM) agents. The repository categorizes papers based on LLM-Profiled Roles and includes high-quality publications from prestigious conferences and journals. It aims to offer a systematic understanding of LLM-based agents, covering topics such as tool use, planning, and feedback learning. The repository also includes unpublished papers with insightful analysis and novelty, marked for future updates. Users can explore a wide range of surveys, tool use cases, planning workflows, and benchmarks related to LLM agents.
llm.hunyuan.T1
Hunyuan-T1 is a cutting-edge large-scale hybrid Mamba reasoning model driven by reinforcement learning. It has been officially released as an upgrade to the Hunyuan Thinker-1-Preview model. The model showcases exceptional performance in deep reasoning tasks, leveraging the TurboS base and Mamba architecture to enhance inference capabilities and align with human preferences. With a focus on reinforcement learning training, the model excels in various reasoning tasks across different domains, showcasing superior abilities in mathematical, logical, scientific, and coding reasoning. Through innovative training strategies and alignment with human preferences, Hunyuan-T1 demonstrates remarkable performance in public benchmarks and internal evaluations, positioning itself as a leading model in the field of reasoning.
atom
Atom is an open-source, self-hosted AI agent platform that allows users to automate workflows by interacting with AI agents. Users can speak or type requests, and Atom's specialty agents can plan, verify, and execute complex workflows across various tech stacks. Unlike SaaS alternatives, Atom runs entirely on the user's infrastructure, ensuring data privacy. The platform offers features such as voice interface, specialty agents for sales, marketing, and engineering, browser and device automation, universal memory and context, agent governance system, deep integrations, dynamic skills, and more. Atom is designed for business automation, multi-agent workflows, and enterprise governance.
For similar tasks
OpenRedTeaming
OpenRedTeaming is a repository focused on red teaming for generative models, specifically large language models (LLMs). The repository provides a comprehensive survey on potential attacks on GenAI and robust safeguards. It covers attack strategies, evaluation metrics, benchmarks, and defensive approaches. The repository also implements over 30 auto red teaming methods. It includes surveys, taxonomies, attack strategies, and risks related to LLMs. The goal is to understand vulnerabilities and develop defenses against adversarial attacks on large language models.

watchtower
AIShield Watchtower is a tool designed to fortify the security of AI/ML models and Jupyter notebooks by automating model and notebook discoveries, conducting vulnerability scans, and categorizing risks into 'low,' 'medium,' 'high,' and 'critical' levels. It supports scanning of public GitHub repositories, Hugging Face repositories, AWS S3 buckets, and local systems. The tool generates comprehensive reports, offers a user-friendly interface, and aligns with industry standards like OWASP, MITRE, and CWE. It aims to address the security blind spots surrounding Jupyter notebooks and AI models, providing organizations with a tailored approach to enhancing their security efforts.
LLM-PLSE-paper
LLM-PLSE-paper is a repository focused on the applications of Large Language Models (LLMs) in Programming Language and Software Engineering (PL/SE) domains. It covers a wide range of topics including bug detection, specification inference and verification, code generation, fuzzing and testing, code model and reasoning, code understanding, IDE technologies, prompting for reasoning tasks, and agent/tool usage and planning. The repository provides a comprehensive collection of research papers, benchmarks, empirical studies, and frameworks related to the capabilities of LLMs in various PL/SE tasks.

invariant
Invariant Analyzer is an open-source scanner designed for LLM-based AI agents to find bugs, vulnerabilities, and security threats. It scans agent execution traces to identify issues like looping behavior, data leaks, prompt injections, and unsafe code execution. The tool offers a library of built-in checkers, an expressive policy language, data flow analysis, real-time monitoring, and extensible architecture for custom checkers. It helps developers debug AI agents, scan for security violations, and prevent security issues and data breaches during runtime. The analyzer leverages deep contextual understanding and a purpose-built rule matching engine for security policy enforcement.
Awesome-LLM4Cybersecurity
The repository 'Awesome-LLM4Cybersecurity' provides a comprehensive overview of the applications of Large Language Models (LLMs) in cybersecurity. It includes a systematic literature review covering topics such as constructing cybersecurity-oriented domain LLMs, potential applications of LLMs in cybersecurity, and research directions in the field. The repository analyzes various benchmarks, datasets, and applications of LLMs in cybersecurity tasks like threat intelligence, fuzzing, vulnerabilities detection, insecure code generation, program repair, anomaly detection, and LLM-assisted attacks.

quark-engine
Quark Engine is an AI-powered tool designed for analyzing Android APK files. It focuses on enhancing the detection process for auto-suggestion, enabling users to create detection workflows without coding. The tool offers an intuitive drag-and-drop interface for workflow adjustments and updates. Quark Agent, the core component, generates Quark Script code based on natural language input and feedback. The project is committed to providing a user-friendly experience for designing detection workflows through textual and visual methods. Various features are still under development and will be rolled out gradually.

vulnerability-analysis
The NVIDIA AI Blueprint for Vulnerability Analysis for Container Security showcases accelerated analysis on common vulnerabilities and exposures (CVE) at an enterprise scale, reducing mitigation time from days to seconds. It enables security analysts to determine software package vulnerabilities using large language models (LLMs) and retrieval-augmented generation (RAG). The blueprint is designed for security analysts, IT engineers, and AI practitioners in cybersecurity. It requires NVAIE developer license and API keys for vulnerability databases, search engines, and LLM model services. Hardware requirements include L40 GPU for pipeline operation and optional LLM NIM and Embedding NIM. The workflow involves LLM pipeline for CVE impact analysis, utilizing LLM planner, agent, and summarization nodes. The blueprint uses NVIDIA NIM microservices and Morpheus Cybersecurity AI SDK for vulnerability analysis.
CodeAsk
CodeAsk is a code analysis tool designed to tackle complex issues such as code that seems to self-replicate, cryptic comments left by predecessors, messy and unclear code, and long-lasting temporary solutions. It offers intelligent code organization and analysis, security vulnerability detection, code quality assessment, and other interesting prompts to help users understand and work with legacy code more efficiently. The tool aims to translate 'legacy code mountains' into understandable language, creating an illusion of comprehension and facilitating knowledge transfer to new team members.
For similar jobs
OpenRedTeaming
OpenRedTeaming is a repository focused on red teaming for generative models, specifically large language models (LLMs). The repository provides a comprehensive survey on potential attacks on GenAI and robust safeguards. It covers attack strategies, evaluation metrics, benchmarks, and defensive approaches. The repository also implements over 30 auto red teaming methods. It includes surveys, taxonomies, attack strategies, and risks related to LLMs. The goal is to understand vulnerabilities and develop defenses against adversarial attacks on large language models.
burp-ai-agent
Burp AI Agent is an extension for Burp Suite that integrates AI into your security workflow. It provides 7 AI backends, 53+ MCP tools, and 62 vulnerability classes. Users can configure privacy modes, perform audit logging, and connect external AI agents via MCP. The tool allows passive and active AI scanners to find vulnerabilities while users focus on manual testing. It requires Burp Suite, Java 21, and at least one AI backend configured.

ciso-assistant-community
CISO Assistant is a tool that helps organizations manage their cybersecurity posture and compliance. It provides a centralized platform for managing security controls, threats, and risks. CISO Assistant also includes a library of pre-built frameworks and tools to help organizations quickly and easily implement best practices.
PurpleLlama
Purple Llama is an umbrella project that aims to provide tools and evaluations to support responsible development and usage of generative AI models. It encompasses components for cybersecurity and input/output safeguards, with plans to expand in the future. The project emphasizes a collaborative approach, borrowing the concept of purple teaming from cybersecurity, to address potential risks and challenges posed by generative AI. Components within Purple Llama are licensed permissively to foster community collaboration and standardize the development of trust and safety tools for generative AI.
vpnfast.github.io
VPNFast is a lightweight and fast VPN service provider that offers secure and private internet access. With VPNFast, users can protect their online privacy, bypass geo-restrictions, and secure their internet connection from hackers and snoopers. The service provides high-speed servers in multiple locations worldwide, ensuring a reliable and seamless VPN experience for users. VPNFast is easy to use, with a user-friendly interface and simple setup process. Whether you're browsing the web, streaming content, or accessing sensitive information, VPNFast helps you stay safe and anonymous online.
taranis-ai
Taranis AI is an advanced Open-Source Intelligence (OSINT) tool that leverages Artificial Intelligence to revolutionize information gathering and situational analysis. It navigates through diverse data sources like websites to collect unstructured news articles, utilizing Natural Language Processing and Artificial Intelligence to enhance content quality. Analysts then refine these AI-augmented articles into structured reports that serve as the foundation for deliverables such as PDF files, which are ultimately published.
NightshadeAntidote
Nightshade Antidote is an image forensics tool used to analyze digital images for signs of manipulation or forgery. It implements several common techniques used in image forensics including metadata analysis, copy-move forgery detection, frequency domain analysis, and JPEG compression artifacts analysis. The tool takes an input image, performs analysis using the above techniques, and outputs a report summarizing the findings.
h4cker
This repository is a comprehensive collection of cybersecurity-related references, scripts, tools, code, and other resources. It is carefully curated and maintained by Omar Santos. The repository serves as a supplemental material provider to several books, video courses, and live training created by Omar Santos. It encompasses over 10,000 references that are instrumental for both offensive and defensive security professionals in honing their skills.