
LLM-PLSE-paper
None
Stars: 125
LLM-PLSE-paper is a repository focused on the applications of Large Language Models (LLMs) in Programming Language and Software Engineering (PL/SE) domains. It covers a wide range of topics including bug detection, specification inference and verification, code generation, fuzzing and testing, code model and reasoning, code understanding, IDE technologies, prompting for reasoning tasks, and agent/tool usage and planning. The repository provides a comprehensive collection of research papers, benchmarks, empirical studies, and frameworks related to the capabilities of LLMs in various PL/SE tasks.
README:
Benchmark and Empirical Study
-
LLMs: Understanding Code Syntax and Semantics for Code Analysis, arxiv 2024, Link
-
Top Score on the Wrong Exam: On Benchmarking in Machine Learning for Vulnerability Detection, arxiv 2024, Link
-
LLMs Cannot Reliably Identify and Reason About Security Vulnerabilities (Yet?): A Comprehensive Evaluation, Framework, and Benchmarks. S&P 2024, Link
-
Vulnerability Detection with Code Language Models: How Far Are We? arxiv 2024, Link
-
A Comprehensive Study of the Capabilities of Large Language Models for Vulnerability Detection, arxiv 2024, Link
-
How Far Have We Gone in Vulnerability Detection Using Large Language Models, arxiv, Link
-
Large Language Models for Code Analysis: Do LLMs Really Do Their Job?, Usenix Security 2023, Link
-
Understanding the Effectiveness of Large Language Models in Detecting Security Vulnerabilities, arxiv 2023, Link
-
Do Language Models Learn Semantics of Code? A Case Study in Vulnerability Detection, arXiv, Link
-
DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection, RAID 2023, Link
-
SkipAnalyzer: An Embodied Agent for Code Analysis with Large Language Models, Link
General Analysis
-
Program Slicing in the Era of Large Language Models, arxiv 2024, Link
-
LLMDFA: Analyzing Dataflow in Code with Large Language Models, NeurIPS 2024, Link
-
Sanitizing Large Language Models in Bug Detection with Data-Flow, Findings of EMNLP 2024, Link
-
LLM4Vuln: A Unified Evaluation Framework for Decoupling and Enhancing LLMs’ Vulnerability Reasoning, arxiv, Link
-
Predictive Program Slicing via Execution Knowledge-Guided Dynamic Dependence Learning, FSE 2024, Link
-
Large Language Models for Test-Free Fault Localization, ICSE 2024, Link
-
Your Instructions Are Not Always Helpful: Assessing the Efficacy of Instruction Fine-tuning for Software Vulnerability Detection, axiv, Link
-
Finetuning Large Language Models for Vulnerability Detection, arxiv, Link
-
A Learning-Based Approach to Static Program Slicing. OOPSLA 2024, Link
-
Dataflow Analysis-Inspired Deep Learning for Efficient Vulnerability Detection. ICSE 2024, Link
-
E&V: Prompting Large Language Models to Perform Static Analysis by Pseudo-code Execution and Verification. arXiv, Link
Domain-Specific Bug Detection(Domain-Specific Program & Bug Type)
-
Combining Fine-Tuning and LLM-based Agents for Intuitive Smart Contract Auditing with Justifications, ICSE 2025, Link
-
Interleaving Static Analysis and LLM Prompting, SOAP 2024, Link
-
Using an LLM to Help With Code Understanding, ICSE 2024, Link
-
Code Linting using Language Models, arxiv 2024, Link
-
LLM-Assisted Static Analysis for Detecting Security Vulnerabilities, arxiv, Link
-
SMARTINV: Multimodal Learning for Smart Contract Invariant Inference, S&P 2024, Link
-
LLM-based Resource-Oriented Intention Inference for Static Resource Detection, arxiv, Link
-
Enhancing Static Analysis for Practical Bug Detection: An LLM-Integrated Approach, OOPSLA 2024, Link
-
Do you still need a manual smart contract audit? Link
-
Harnessing the Power of LLM to Support Binary Taint Analysis, arxiv, Link
-
Large Language Model-Powered Smart Contract Vulnerability Detection: New Perspectives. arXiv, Link
-
GPTScan: Detecting Logic Vulnerabilities in Smart Contracts by Combining GPT with Program Analysis. ICSE 2024 Link
-
Continuous Learning for Android Malware Detection, USENIX Security 2023, Link
-
Beware of the Unexpected: Bimodal Taint Analysis, ISSTA 2023, Link
-
SpecEval: Evaluating Code Comprehension in Large Language Models via Program Specifications, arxiv 2024/09, Link
-
Can Large Language Models Transform Natural Language Intent into Formal Method Postconditions? FSE 2024, Link
-
Enchanting Program Specification Synthesis by Large Language Models using Static Analysis and Program Verification, CAV 2024, Link
-
SpecGen: Automated Generation of Formal Program Specifications via Large Language Models, Link
-
Lemur: Integrating Large Language Models in Automated Program Verification, ICLR 2024, Link
-
Zero and Few-shot Semantic Parsing with Ambiguous Inputs, ICLR 2024, Link
-
Finding Inductive Loop Invariants using Large Language Models, Link
-
Can ChatGPT support software verification? arXiv, Link
-
Impact of Large Language Models on Generating Software Specifications, Link
-
Can Large Language Models Reason about Program Invariants?, ICML 2023, Link
-
Ranking LLM-Generated Loop Invariants for Program Verification, Link
-
Generating Code World Models with Large Language Models Guided by Monte Carlo Tree Search, NeurIPS 2024, Link
-
EvoCodeBench: An Evolving Code Generation Benchmark Aligned with Real-World Code Repositories, arxiv 2024/03, Link
-
CodeBenchGen: Creating Scalable Execution-based Code Generation Benchmarks,
-
AutoCodeRover: Autonomous Program Improvement, ISSTA 2024, Link
-
Exploring and Unleashing the Power of Large Language Models in Automated Code Translation, FSE 2024, Link
-
Rectifier: Code Translation with Corrector via LLMs, arxiv 2024, Link
-
RepairAgent: An Autonomous, LLM-Based Agent for Program Repair, Link
-
LongCoder: A Long-Range Pre-trained Language Model for Code Completion, ICML 2023, Link
-
Learning Performance-Improving Code Edits, ICLR 2024, Link
-
PyDex: Repairing Bugs in Introductory Python Assignments using LLMs, OOPSLA 2024, Link
-
Automatic Programming: Large Language Models and Beyond, arxiv 2024, (Mark) Link
-
Towards AI-Assisted Synthesis of Verified Dafny Methods, FSE 2024, Link
-
Enabling Memory Safety of C Programs using LLMs, arxiv, Link
-
CodeChain: Towards Modular Code Generation Through Chain of Self-revisions with Representative Sub-modules, ICLR 2024, Link
-
Is Self-Repair a Silver Bullet for Code Generation? ICLR 2024, Link
-
Verified Multi-Step Synthesis using Large Language Models and Monte Carlo Tree Search Link
-
Hypothesis Search: Inductive Reasoning with Language Models, ICLR 2024, Link
-
CodePlan: Repository-level Coding using LLMs and Planning, FMDM & NIPS 2023, Link
-
Repository-Level Prompt Generation for Large Language Models of Code. ICML 2023, Link
-
Refactoring Programs Using Large Language Models with Few-Shot Examples. arXiv, Link
-
SWE-bench: Can Language Models Resolve Real-World GitHub Issues? Link
-
Guess & Sketch: Language Model Guided Transpilation, ICLR 2024, Link
-
Optimal Neural Program Synthesis from Multimodal Specifications, EMNLP 2021, Link
-
CodeTrek: Flexible Modeling of Code using an Extensible Relational Representation, ICLR 2022, Link
-
Sporq: An Interactive Environment for Exploring Code Using Query-by-Example, UIST 2021, Link
-
Data Extraction via Semantic Regular Expression Synthesis, OOPSLA 2023, Link
-
Web Question Answering with Neurosymbolic Program Synthesis, PLDI 2021, Link
-
Active Inductive Logic Programming for Code Search, ICSE 2019, Link
-
Effective Large Language Model Debugging with Best-first Tree Search, Link
-
Teaching Large Language Models to Self-Debug, ICLR 2024, Link
-
When Fuzzing Meets LLMs: Challenges and Opportunities, FSE 2024, Link
-
Evaluating Offensive Security Capabilities of Large Language Models, Google, Link
-
An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation, TSE 2024, Link
-
LLMorpheus: Mutation Testing using Large Language Models, arxiv 2014, Frank Tip, Link
-
Towards Understanding the Effectiveness of Large Langauge Models on Directed Test Input Generation, ASE 2024, Link
-
Evaluating Offensive Security Capabilities of Large Language Models, Google 2024/06, Link
-
Prompt Fuzzing for Fuzz Driver Generation, CCS 2024, Link
-
Sedar: Obtaining High-Quality Seeds for DBMS Fuzzing via Cross-DBMS SQL Transfer. ICSE 2024. Link
-
LLM4FUZZ: Guided Fuzzing of Smart Contracts with Large Language Models Link
-
Large Language Model guided Protocol Fuzzing, NDSS 2024, Link
-
Large Language Models are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models, ISSTA 2023, Link
-
Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risk of Language Models, arxiv 2024, Link
-
Language Agents as Hackers: Evaluating Cybersecurity Skills with Capture the Flag, MASEC@NeurIPS 2023, Link
-
Nuances are the Key: Unlocking ChatGPT to Find Failure-Inducing Tests with Differential Prompting, Link
-
LPR: Large Language Models-Aided Program Reduction. ISSTA 2024, Link
-
SemCoder: Training Code Language Models with Comprehensive Semantics, NeurIPS 2024, Link
-
Source Code Foundation Models are Transferable Binary Analysis Knowledge Bases, NeurIPS 2024, Link
-
CodeMind: A Framework to Challenge Large Language Models for Code Reasoning, arxiv, Link
-
CodeFort: Robust Training for Code Generation Models, EMNLP Findings 2024, Link
-
Meta Large Language Model Compiler: Foundation Models of Compiler Optimization, Meta, Link
-
Constrained Decoding for Secure Code Generation, arxiv, Link
-
Evaluating the Effectiveness of Deep Learning Models for Foundational Program Analysis Tasks, OOPSLA 2024, Link
-
Detecting Misuse of Security APIs: A Systematic Review, Arxiv 2024, Link
-
An Investigation into Misuse of Java Security APIs by Large Language Models, ASIACCS 2024, Link
-
Large Language Models for Code: Security Hardening and Adversarial Testing, CCS 2023, Link, Code
-
Instruction Tuning for Secure Code Generation, ICML 2024, Link
-
jTrans: jump-aware transformer for binary code similarity detection, ISSTA 2022, Link
-
Enhancing Code Understanding for Impact Analysis by Combining Transformers and Program Dependence Graphs, FSE 2024.
-
Which Syntactic Capabilities Are Statistically Learned by Masked Language Models for Code? ICSE 2024, Link
-
Source Code Vulnerability Detection: Combining Code Language Models and Code Property Graphs, arxiv, Link
-
CodeArt: Better Code Models by Attention Regularization When Symbols Are Lacking, FSE 2024, Link
-
FAIR: Flow Type-Aware Pre-Training of Compiler Intermediate Representations, ICSE 2024, Link
-
Symmetry-Preserving Program Representations for Learning Code Semantics Link
-
ReSym: Harnessing LLMs to Recover Variable and Data Structure Symbols from Stripped Binaries, CCS 2024, Link
-
LmPa: Improving Decompilation by Synergy of Large Language Model and Program Analysis, Link
-
When Do Program-of-Thought Works for Reasoning? AAAI 2024 Link
-
Grounded Copilot: How Programmers Interact with Code-Generating Models, OOPSLA 2023, Link
-
Extracting Training Data from Large Language Models, USENIX Security 2023, Link
-
How could Neural Networks understand Programs? ICML 2021, Link
-
ProGraML: A Graph-based Program Representation for Data Flow Analysis and Compiler Optimizations, ICML 2021, Link
-
GraphCodeBert: Pre-training Code Representations with Data Flow, ICLR 2021, Link
-
CodeBERT: A Pre-Trained Model for Programming and Natural Languages, EMNLP 2020, Link
-
Neural Code Comprehension: A Learnable Representation of Code Semantics, NeurIPS 2018, Link
-
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models, Apple, Link
-
Drowzee: Metamorphic Testing for Fact-Conflicting Hallucination Detection in Large Language Models, OOPSLA 2024, Link
-
Self-contradictory Hallucinations of Large Language Models: Evaluation, Detection and Mitigation, ICLR 2024, Link
-
LeanDojo: Theorem Proving with Retrieval-Augmented Language Models, NeurIPS 2023, Link
-
Large Language Models for Automatic Equation Discovery, arxiv, Link
-
Self-Evaluation Guided Beam Search for Reasoning, NeurIPS 2023, Link
-
Self-consistency improves chain of thought reasoning in language models. NeurIPS 2022, Link
-
Tree of Thoughts: Deliberate Problem Solving with Large Language Models. NeurIPS 2023, Link
-
Cumulative Reasoning With Large Language Models, Link
-
Explanation Selection Using Unlabeled Data for Chain-of-Thought Prompting, EMNLP 2023, Link
-
Complementary Explanations for Effective In-Context Learning, ACL 2023, Link
-
Wechat Post: 大语言模型的数学之路 Link
-
Blog: Prompt Engineering Link
-
Steering Large Language Models between Code Execution and Textual Reasoning, Microsoft, Link
-
Don’t Transform the Code, Code the Transforms: Towards Precise Code Rewriting using LLMs, Meta, Link
-
Natural Language Commanding via Program Synthesis, Microsoft Link
-
Chain of Code: Reasoning with a Language Model-Augmented Code Emulator, Feifei Li, Google Link
-
Real-world practices of AI Agents, Link
-
Cognitive Architectures for Language Agents, Link
-
The Rise and Potential of Large Language Model Based Agents: A Survey, Link
-
ReAct: Synergizing Reasoning and Acting in Language Models Link
-
Reflexion: Language Agents with Verbal Reinforcement Learning, NeurIPS 2023, Link
-
Wechat Post: AutoGen, Link
-
SATLM: Satisfiability-Aided Language Models Using Declarative Prompting, NeurIPS 2023, Link
-
Awesome things about LLM-powered agents: Papers, Repos, and Blogs, Link
-
ChatDev: Mastering the Virtual Social Realm, Shaping the Future of Intelligent Interactions. Link
-
SWE-bench: Can Language Models Resolve Real-World GitHub Issues? Link
-
LMFLow: An Extensible Toolkit for Finetuning and Inference of Large Foundation Models. Large Models for All. Link
-
codellama: Inference code for CodeLlama models, Link
-
CodeFuse: LLM for Code from Ant Group, Link
-
Owl-LM: Large Language Model for Blockchain, Link
-
Large Language Model-Based Agents for Software Engineering: A Survey Link
-
A Survey on Large Language Models for Code Generation, arxiv 2024, Link
-
Comprehensive Outline of Large Language Model-based Multi-Agent Research, Tsinghua NLP Group, Link
-
If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent Agents, Link
-
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing, Link
-
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions, Link
-
Large Language Models for Software Engineering: A Systematic Literature Review, Link
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-PLSE-paper
Similar Open Source Tools
LLM-PLSE-paper
LLM-PLSE-paper is a repository focused on the applications of Large Language Models (LLMs) in Programming Language and Software Engineering (PL/SE) domains. It covers a wide range of topics including bug detection, specification inference and verification, code generation, fuzzing and testing, code model and reasoning, code understanding, IDE technologies, prompting for reasoning tasks, and agent/tool usage and planning. The repository provides a comprehensive collection of research papers, benchmarks, empirical studies, and frameworks related to the capabilities of LLMs in various PL/SE tasks.
LLMEvaluation
The LLMEvaluation repository is a comprehensive compendium of evaluation methods for Large Language Models (LLMs) and LLM-based systems. It aims to assist academics and industry professionals in creating effective evaluation suites tailored to their specific needs by reviewing industry practices for assessing LLMs and their applications. The repository covers a wide range of evaluation techniques, benchmarks, and studies related to LLMs, including areas such as embeddings, question answering, multi-turn dialogues, reasoning, multi-lingual tasks, ethical AI, biases, safe AI, code generation, summarization, software performance, agent LLM architectures, long text generation, graph understanding, and various unclassified tasks. It also includes evaluations for LLM systems in conversational systems, copilots, search and recommendation engines, task utility, and verticals like healthcare, law, science, financial, and others. The repository provides a wealth of resources for evaluating and understanding the capabilities of LLMs in different domains.
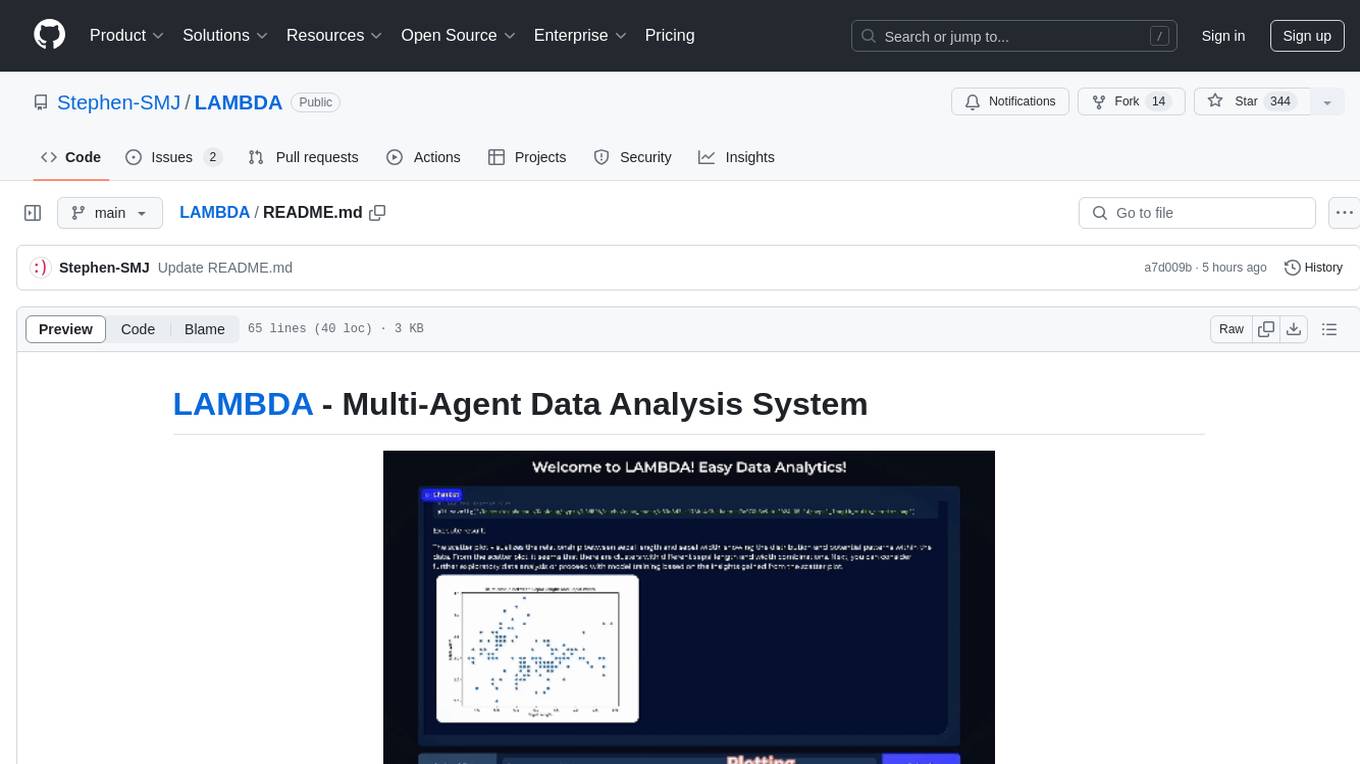
LAMBDA
LAMBDA is a code-free multi-agent data analysis system that utilizes large models to address data analysis challenges in complex data-driven applications. It allows users to perform complex data analysis tasks through human language instruction, seamlessly generate and debug code using two key agent roles, integrate external models and algorithms, and automatically generate reports. The system has demonstrated strong performance on various machine learning datasets, enhancing data science practice by integrating human and artificial intelligence.

Fast-dLLM
Fast-DLLM is a diffusion-based Large Language Model (LLM) inference acceleration framework that supports efficient inference for models like Dream and LLaDA. It offers fast inference support, multiple optimization strategies, code generation, evaluation capabilities, and an interactive chat interface. Key features include Key-Value Cache for Block-Wise Decoding, Confidence-Aware Parallel Decoding, and overall performance improvements. The project structure includes directories for Dream and LLaDA model-related code, with installation and usage instructions provided for using the LLaDA and Dream models.
Awesome-LLM4EDA
LLM4EDA is a repository dedicated to showcasing the emerging progress in utilizing Large Language Models for Electronic Design Automation. The repository includes resources, papers, and tools that leverage LLMs to solve problems in EDA. It covers a wide range of applications such as knowledge acquisition, code generation, code analysis, verification, and large circuit models. The goal is to provide a comprehensive understanding of how LLMs can revolutionize the EDA industry by offering innovative solutions and new interaction paradigms.
generative-ai-workbook
Generative AI Workbook is a central repository for generative AI-related work, including projects, personal projects, and tools. It also features a blog section with bite-sized posts on various generative AI concepts. The repository covers use cases of Large Language Models (LLMs) such as search, classification, clustering, data/text/code generation, summarization, rewriting, extractions, proofreading, and querying data.
llm-universe
This project is a tutorial on developing large model applications for novice developers. It aims to provide a comprehensive introduction to large model development, focusing on Alibaba Cloud servers and integrating personal knowledge assistant projects. The tutorial covers the following topics: 1. **Introduction to Large Models**: A simplified introduction for novice developers on what large models are, their characteristics, what LangChain is, and how to develop an LLM application. 2. **How to Call Large Model APIs**: This section introduces various methods for calling APIs of well-known domestic and foreign large model products, including calling native APIs, encapsulating them as LangChain LLMs, and encapsulating them as Fastapi calls. It also provides a unified encapsulation for various large model APIs, such as Baidu Wenxin, Xunfei Xinghuo, and Zh譜AI. 3. **Knowledge Base Construction**: Loading, processing, and vector database construction of different types of knowledge base documents. 4. **Building RAG Applications**: Integrating LLM into LangChain to build a retrieval question and answer chain, and deploying applications using Streamlit. 5. **Verification and Iteration**: How to implement verification and iteration in large model development, and common evaluation methods. The project consists of three main parts: 1. **Introduction to LLM Development**: A simplified version of V1 aims to help beginners get started with LLM development quickly and conveniently, understand the general process of LLM development, and build a simple demo. 2. **LLM Development Techniques**: More advanced LLM development techniques, including but not limited to: Prompt Engineering, processing of multiple types of source data, optimizing retrieval, recall ranking, Agent framework, etc. 3. **LLM Application Examples**: Introduce some successful open source cases, analyze the ideas, core concepts, and implementation frameworks of these application examples from the perspective of this course, and help beginners understand what kind of applications they can develop through LLM. Currently, the first part has been completed, and everyone is welcome to read and learn; the second and third parts are under creation. **Directory Structure Description**: requirements.txt: Installation dependencies in the official environment notebook: Notebook source code file docs: Markdown documentation file figures: Pictures data_base: Knowledge base source file used
PythonAiRoad
PythonAiRoad is a repository containing classic original articles source code from the 'Algorithm Gourmet House'. It is a platform for sharing algorithms and code related to artificial intelligence. Users are encouraged to contact the author for further discussions or collaborations. The repository serves as a valuable resource for those interested in AI algorithms and implementations.

NanoLLM
NanoLLM is a tool designed for optimized local inference for Large Language Models (LLMs) using HuggingFace-like APIs. It supports quantization, vision/language models, multimodal agents, speech, vector DB, and RAG. The tool aims to provide efficient and effective processing for LLMs on local devices, enhancing performance and usability for various AI applications.

Main
This repository contains material related to the new book _Synthetic Data and Generative AI_ by the author, including code for NoGAN, DeepResampling, and NoGAN_Hellinger. NoGAN is a tabular data synthesizer that outperforms GenAI methods in terms of speed and results, utilizing state-of-the-art quality metrics. DeepResampling is a fast NoGAN based on resampling and Bayesian Models with hyperparameter auto-tuning. NoGAN_Hellinger combines NoGAN and DeepResampling with the Hellinger model evaluation metric.
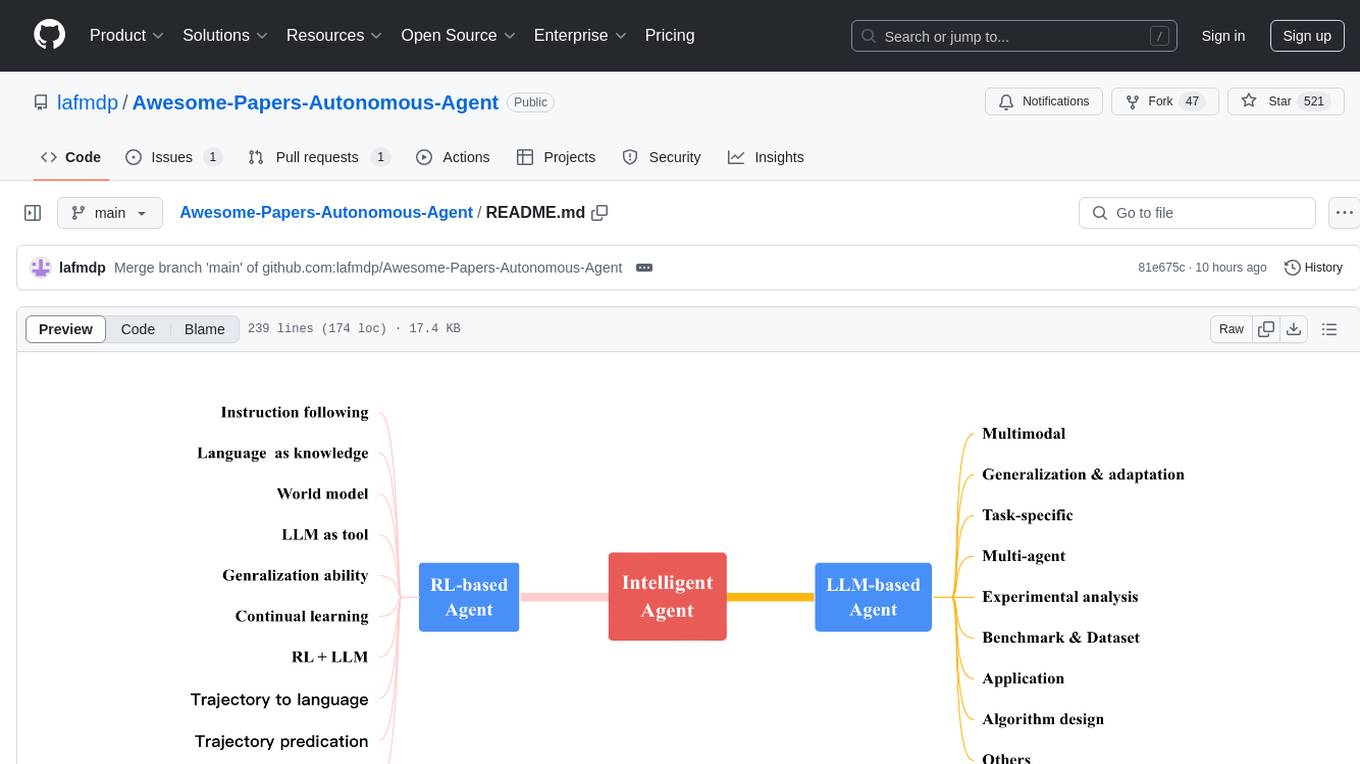
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.

VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.
awesome-ai-cybersecurity
This repository is a comprehensive collection of resources for utilizing AI in cybersecurity. It covers various aspects such as prediction, prevention, detection, response, monitoring, and more. The resources include tools, frameworks, case studies, best practices, tutorials, and research papers. The repository aims to assist professionals, researchers, and enthusiasts in staying updated and advancing their knowledge in the field of AI cybersecurity.
learning-ai
This repository is a collection of notes and code examples related to AI, covering topics such as Tokenization, Architectures, GGML, Llama.cpp, Position Embeddings, GPUs, Vector Databases, and Vision. It also includes in-progress work on Model Context Protocol (MCP) and Voice Activity Detection (VAD) for whisper.cpp. The repository offers exploration code for various AI-related concepts and tools like GGML, Llama.cpp, GPU technologies (CUDA, Kompute, Metal, OpenCL, ROCm, Vulkan), Word embeddings, Huggingface API, and Qdrant Vector Database in both Rust and Python.

RustGPT
A complete Large Language Model implementation in pure Rust with no external ML frameworks. Demonstrates building a transformer-based language model from scratch, including pre-training, instruction tuning, interactive chat mode, full backpropagation, and modular architecture. Model learns basic world knowledge and conversational patterns. Features custom tokenization, greedy decoding, gradient clipping, modular layer system, and comprehensive test coverage. Ideal for understanding modern LLMs and key ML concepts. Dependencies include ndarray for matrix operations and rand for random number generation. Contributions welcome for model persistence, performance optimizations, better sampling, evaluation metrics, advanced architectures, training improvements, data handling, and model analysis. Follows standard Rust conventions and encourages contributions at beginner, intermediate, and advanced levels.
amazon-sagemaker-generativeai
Repository for training and deploying Generative AI models, including text-text, text-to-image generation, prompt engineering playground and chain of thought examples using SageMaker Studio. The tool provides a platform for users to experiment with generative AI techniques, enabling them to create text and image outputs based on input data. It offers a range of functionalities for training and deploying models, as well as exploring different generative AI applications.
For similar tasks

watchtower
AIShield Watchtower is a tool designed to fortify the security of AI/ML models and Jupyter notebooks by automating model and notebook discoveries, conducting vulnerability scans, and categorizing risks into 'low,' 'medium,' 'high,' and 'critical' levels. It supports scanning of public GitHub repositories, Hugging Face repositories, AWS S3 buckets, and local systems. The tool generates comprehensive reports, offers a user-friendly interface, and aligns with industry standards like OWASP, MITRE, and CWE. It aims to address the security blind spots surrounding Jupyter notebooks and AI models, providing organizations with a tailored approach to enhancing their security efforts.
LLM-PLSE-paper
LLM-PLSE-paper is a repository focused on the applications of Large Language Models (LLMs) in Programming Language and Software Engineering (PL/SE) domains. It covers a wide range of topics including bug detection, specification inference and verification, code generation, fuzzing and testing, code model and reasoning, code understanding, IDE technologies, prompting for reasoning tasks, and agent/tool usage and planning. The repository provides a comprehensive collection of research papers, benchmarks, empirical studies, and frameworks related to the capabilities of LLMs in various PL/SE tasks.

invariant
Invariant Analyzer is an open-source scanner designed for LLM-based AI agents to find bugs, vulnerabilities, and security threats. It scans agent execution traces to identify issues like looping behavior, data leaks, prompt injections, and unsafe code execution. The tool offers a library of built-in checkers, an expressive policy language, data flow analysis, real-time monitoring, and extensible architecture for custom checkers. It helps developers debug AI agents, scan for security violations, and prevent security issues and data breaches during runtime. The analyzer leverages deep contextual understanding and a purpose-built rule matching engine for security policy enforcement.
OpenRedTeaming
OpenRedTeaming is a repository focused on red teaming for generative models, specifically large language models (LLMs). The repository provides a comprehensive survey on potential attacks on GenAI and robust safeguards. It covers attack strategies, evaluation metrics, benchmarks, and defensive approaches. The repository also implements over 30 auto red teaming methods. It includes surveys, taxonomies, attack strategies, and risks related to LLMs. The goal is to understand vulnerabilities and develop defenses against adversarial attacks on large language models.
Awesome-LLM4Cybersecurity
The repository 'Awesome-LLM4Cybersecurity' provides a comprehensive overview of the applications of Large Language Models (LLMs) in cybersecurity. It includes a systematic literature review covering topics such as constructing cybersecurity-oriented domain LLMs, potential applications of LLMs in cybersecurity, and research directions in the field. The repository analyzes various benchmarks, datasets, and applications of LLMs in cybersecurity tasks like threat intelligence, fuzzing, vulnerabilities detection, insecure code generation, program repair, anomaly detection, and LLM-assisted attacks.

quark-engine
Quark Engine is an AI-powered tool designed for analyzing Android APK files. It focuses on enhancing the detection process for auto-suggestion, enabling users to create detection workflows without coding. The tool offers an intuitive drag-and-drop interface for workflow adjustments and updates. Quark Agent, the core component, generates Quark Script code based on natural language input and feedback. The project is committed to providing a user-friendly experience for designing detection workflows through textual and visual methods. Various features are still under development and will be rolled out gradually.

vulnerability-analysis
The NVIDIA AI Blueprint for Vulnerability Analysis for Container Security showcases accelerated analysis on common vulnerabilities and exposures (CVE) at an enterprise scale, reducing mitigation time from days to seconds. It enables security analysts to determine software package vulnerabilities using large language models (LLMs) and retrieval-augmented generation (RAG). The blueprint is designed for security analysts, IT engineers, and AI practitioners in cybersecurity. It requires NVAIE developer license and API keys for vulnerability databases, search engines, and LLM model services. Hardware requirements include L40 GPU for pipeline operation and optional LLM NIM and Embedding NIM. The workflow involves LLM pipeline for CVE impact analysis, utilizing LLM planner, agent, and summarization nodes. The blueprint uses NVIDIA NIM microservices and Morpheus Cybersecurity AI SDK for vulnerability analysis.
CodeAsk
CodeAsk is a code analysis tool designed to tackle complex issues such as code that seems to self-replicate, cryptic comments left by predecessors, messy and unclear code, and long-lasting temporary solutions. It offers intelligent code organization and analysis, security vulnerability detection, code quality assessment, and other interesting prompts to help users understand and work with legacy code more efficiently. The tool aims to translate 'legacy code mountains' into understandable language, creating an illusion of comprehension and facilitating knowledge transfer to new team members.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.