
aws-machine-learning-university-responsible-ai
None
Stars: 60

This repository contains slides, notebooks, and data for the Machine Learning University (MLU) Responsible AI class. The mission is to make Machine Learning accessible to everyone, covering widely used ML techniques and applying them to real-world problems. The class includes lectures, final projects, and interactive visuals to help users learn about Responsible AI and core ML concepts.
README:
![]()
This repository contains slides, notebooks, and data for the Machine Learning University (MLU) Responsible AI class. Our mission is to make Machine Learning accessible to everyone. We have courses available across many topics of machine learning and believe knowledge of ML can be a key enabler for success. This class is designed to help you get started with Responsible AI, learn about widely used Machine Learning techniques, and apply them to real-world problems.
Watch all Responsible AI video recordings in this YouTube playlist from our YouTube channel.
There are three lectures and one final project for this class.
Lecture 1
| Title | Studio lab |
|---|---|
| Exploratory Data Analysis |  |
| Final Challenge Day 1 | |
| Completed Final Challenge Day 1 | |
Lecture 2
| Title | Studio lab |
|---|---|
| Data Preparation | |
| Disparate Impact | |
| Logistic Regression | |
| Final Challenge Day 2 | |
| Completed Final Challenge Day 2 | |
Lecture 3
| Title | Studio lab |
|---|---|
| Equalized Odds | |
| SHAP | |
| Clarify and Model Monitor | |
| Final Challenge Day 3 | |
| Completed Final Challenge Day 3 | |
Final Project: Practice working with a "real-world" dataset for the final project. Final project dataset is in the data/final_project folder. For more details on the final project, check out this notebook.
Interested in visual, interactive explanations of core machine learning concepts? Check out our MLU-Explain articles to learn at your own pace! Relevant for this class is this article on Equality of Odds.
If you would like to contribute to the project, see CONTRIBUTING for more information.
The license for this repository depends on the section. Data set for the course is being provided to you by permission of Amazon and is subject to the terms of the Amazon License and Access. You are expressly prohibited from copying, modifying, selling, exporting or using this data set in any way other than for the purpose of completing this course. The lecture slides are released under the CC-BY-SA-4.0 License. This project is licensed under the Apache-2.0 License. See each section's LICENSE file for details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aws-machine-learning-university-responsible-ai
Similar Open Source Tools
aws-machine-learning-university-responsible-ai
This repository contains slides, notebooks, and data for the Machine Learning University (MLU) Responsible AI class. The mission is to make Machine Learning accessible to everyone, covering widely used ML techniques and applying them to real-world problems. The class includes lectures, final projects, and interactive visuals to help users learn about Responsible AI and core ML concepts.
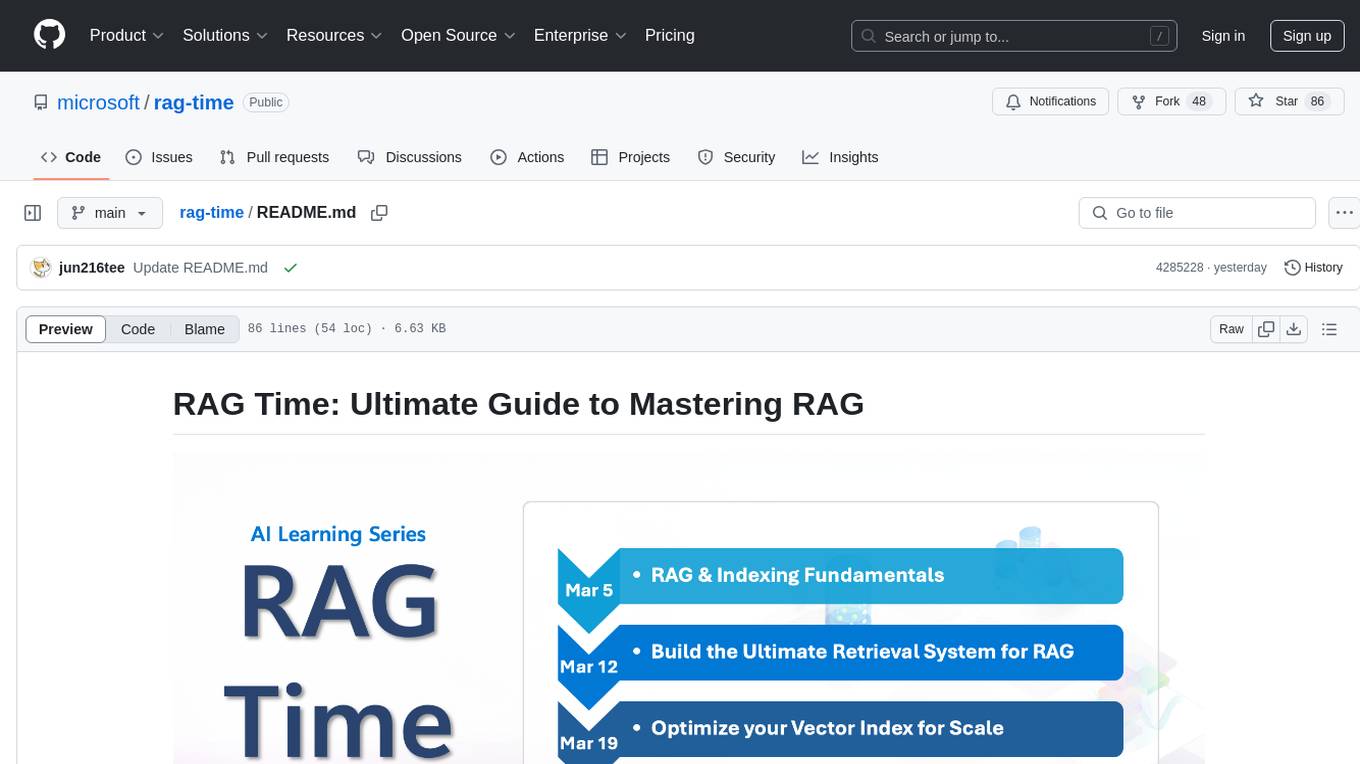
rag-time
RAG Time is a 5-week AI learning series focusing on Retrieval-Augmented Generation (RAG) concepts. The repository contains code samples, step-by-step guides, and resources to help users master RAG. It aims to teach foundational and advanced RAG concepts, demonstrate real-world applications, and provide hands-on samples for practical implementation.
uptrain
UpTrain is an open-source unified platform to evaluate and improve Generative AI applications. We provide grades for 20+ preconfigured evaluations (covering language, code, embedding use cases), perform root cause analysis on failure cases and give insights on how to resolve them.

babilong
BABILong is a generative benchmark designed to evaluate the performance of NLP models in processing long documents with distributed facts. It consists of 20 tasks that simulate interactions between characters and objects in various locations, requiring models to distinguish important information from irrelevant details. The tasks vary in complexity and reasoning aspects, with test samples potentially containing millions of tokens. The benchmark aims to challenge and assess the capabilities of Large Language Models (LLMs) in handling complex, long-context information.
yuna-ai
Yuna AI is a unique AI companion designed to form a genuine connection with users. It runs exclusively on the local machine, ensuring privacy and security. The project offers features like text generation, language translation, creative content writing, roleplaying, and informal question answering. The repository provides comprehensive setup and usage guides for Yuna AI, along with additional resources and tools to enhance the user experience.

Hands-On-Large-Language-Models
Hands-On Large Language Models is a repository containing code examples from the book 'The Illustrated LLM Book' by Jay Alammar and Maarten Grootendorst. The repository provides practical tools and concepts for using Large Language Models with over 250 custom-made figures. It covers topics such as language model introduction, tokens and embeddings, transformer LLMs, text classification, text clustering, prompt engineering, text generation techniques, semantic search, multimodal LLMs, text embedding models, fine-tuning representation models, and fine-tuning generation models. The examples are designed to be run on Google Colab with T4 GPU support, but can be adapted to other cloud platforms as well.

qlib
Qlib is an open-source, AI-oriented quantitative investment platform that supports diverse machine learning modeling paradigms, including supervised learning, market dynamics modeling, and reinforcement learning. It covers the entire chain of quantitative investment, from alpha seeking to order execution. The platform empowers researchers to explore ideas and implement productions using AI technologies in quantitative investment. Qlib collaboratively solves key challenges in quantitative investment by releasing state-of-the-art research works in various paradigms. It provides a full ML pipeline for data processing, model training, and back-testing, enabling users to perform tasks such as forecasting market patterns, adapting to market dynamics, and modeling continuous investment decisions.
reasoning-from-scratch
This repository contains the code for developing a large language model (LLM) reasoning model. The book 'Build a Reasoning Model (From Scratch)' provides a hands-on approach to understanding and implementing reasoning capabilities in LLMs. It guides users through creating a small but functional reasoning model, mirroring approaches used in large-scale models like DeepSeek R1 and GPT-5 Thinking. The code includes methods for loading weights of pretrained models.
LLMs-from-scratch
This repository contains the code for coding, pretraining, and finetuning a GPT-like LLM and is the official code repository for the book Build a Large Language Model (From Scratch). In _Build a Large Language Model (From Scratch)_, you'll discover how LLMs work from the inside out. In this book, I'll guide you step by step through creating your own LLM, explaining each stage with clear text, diagrams, and examples. The method described in this book for training and developing your own small-but-functional model for educational purposes mirrors the approach used in creating large-scale foundational models such as those behind ChatGPT.
dotnet-ai-workshop
The .NET AI Workshop is a comprehensive guide designed to help developers add AI features to .NET applications. It covers various AI-based features such as classification, summarization, data extraction/cleaning, anomaly detection, translation, sentiment detection, semantic search, Q&A chatbots, and voice assistants. The workshop is tailored for developers new to AI in .NET applications, focusing on the usage of AI services without the need for prior AI technology knowledge. It provides examples using .NET and C# with a focus on AI topics, aiming to enhance productivity and automation in applications.
llm-python
A set of instructional materials, code samples and Python scripts featuring LLMs (GPT etc) through interfaces like llamaindex, langchain, Chroma (Chromadb), Pinecone etc. Mainly used to store reference code for my LangChain tutorials on YouTube.

mlcourse.ai
mlcourse.ai is an open Machine Learning course by OpenDataScience (ods.ai), led by Yury Kashnitsky (yorko). The course offers a perfect balance between theory and practice, with math formulae in lectures and practical assignments including Kaggle Inclass competitions. It is currently in a self-paced mode, guiding users through 10 weeks of content covering topics from Pandas to Gradient Boosting. The course provides articles, lectures, and assignments to enhance understanding and application of machine learning concepts.

NineRec
NineRec is a benchmark dataset suite for evaluating transferable recommendation models. It provides datasets for pre-training and transfer learning in recommender systems, focusing on multimodal and foundation model tasks. The dataset includes user-item interactions, item texts in multiple languages, item URLs, and raw images. Researchers can use NineRec to develop more effective and efficient methods for pre-training recommendation models beyond end-to-end training. The dataset is accompanied by code for dataset preparation, training, and testing in PyTorch environment.
ragas
Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where Ragas (RAG Assessment) comes in. Ragas provides you with the tools based on the latest research for evaluating LLM-generated text to give you insights about your RAG pipeline. Ragas can be integrated with your CI/CD to provide continuous checks to ensure performance.
fAIr
fAIr is an open AI-assisted mapping service developed by the Humanitarian OpenStreetMap Team (HOT) to improve mapping efficiency and accuracy for humanitarian purposes. It uses AI models, specifically computer vision techniques, to detect objects like buildings, roads, waterways, and trees from satellite and UAV imagery. The service allows OSM community members to create and train their own AI models for mapping in their region of interest and ensures models are relevant to local communities. Constant feedback loop with local communities helps eliminate model biases and improve model accuracy.
making-games-with-ai-course
This repository hosts the Machine Learning for Games Course, providing mdx files and notebooks for learning. The course covers various topics related to applying machine learning techniques in game development. It offers a syllabus and resources for users to sign up and access the content for free. The project is maintained by Thomas Simonini and is available on GitHub for citation in publications.
For similar tasks
aws-machine-learning-university-responsible-ai
This repository contains slides, notebooks, and data for the Machine Learning University (MLU) Responsible AI class. The mission is to make Machine Learning accessible to everyone, covering widely used ML techniques and applying them to real-world problems. The class includes lectures, final projects, and interactive visuals to help users learn about Responsible AI and core ML concepts.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

djl
Deep Java Library (DJL) is an open-source, high-level, engine-agnostic Java framework for deep learning. It is designed to be easy to get started with and simple to use for Java developers. DJL provides a native Java development experience and allows users to integrate machine learning and deep learning models with their Java applications. The framework is deep learning engine agnostic, enabling users to switch engines at any point for optimal performance. DJL's ergonomic API interface guides users with best practices to accomplish deep learning tasks, such as running inference and training neural networks.
craftgen
Craftgen.ai is an innovative AI platform designed for both technical and non-technical users. It's built on a foundation of graph architecture for scalability and the Actor Model for efficient concurrent operations, tailored to both technical and non-technical users. A key aspect of Craftgen.ai is its modular AI approach, allowing users to assemble and customize AI components like building blocks to fit their specific needs. The platform's robustness is enhanced by its event-driven architecture, ensuring reliable data processing and featuring browser web technologies for universal access. Craftgen.ai excels in dynamic tool and workflow generation, with strong offline capabilities for secure environments and plans for desktop application integration. A unique and valuable feature of Craftgen.ai is its marketplace, where users can access a variety of pre-built AI solutions. This marketplace accelerates the deployment of AI tools but also fosters a community of sharing and innovation. Users can contribute to and leverage this repository of solutions, enhancing the platform's versatility and practicality. Craftgen.ai uses JSON schema for industry-standard alignment, enabling seamless integration with any API following the OpenAPI spec. This allows for a broad range of applications, from automating data analysis to streamlining content management. The platform is designed to bridge the gap between advanced AI technology and practical usability. It's a flexible, secure, and intuitive platform that empowers users, from developers seeking to create custom AI solutions to businesses looking to automate routine tasks. Craftgen.ai's goal is to make AI technology an integral, seamless part of everyday problem-solving and innovation, providing a platform where modular AI and a thriving marketplace converge to meet the diverse needs of its users.
Data-Science-EBooks
This repository contains a collection of resources in the form of eBooks related to Data Science, Machine Learning, and similar topics.

BambooAI
BambooAI is a lightweight library utilizing Large Language Models (LLMs) to provide natural language interaction capabilities, much like a research and data analysis assistant enabling conversation with your data. You can either provide your own data sets, or allow the library to locate and fetch data for you. It supports Internet searches and external API interactions.
ai_wiki
This repository provides a comprehensive collection of resources, open-source tools, and knowledge related to quantitative analysis. It serves as a valuable knowledge base and navigation guide for individuals interested in various aspects of quantitative investing, including platforms, programming languages, mathematical foundations, machine learning, deep learning, and practical applications. The repository is well-structured and organized, with clear sections covering different topics. It includes resources on system platforms, programming codes, mathematical foundations, algorithm principles, machine learning, deep learning, reinforcement learning, graph networks, model deployment, and practical applications. Additionally, there are dedicated sections on quantitative trading and investment, as well as large models. The repository is actively maintained and updated, ensuring that users have access to the latest information and resources.

free-for-life
A massive list including a huge amount of products and services that are completely free! ⭐ Star on GitHub • 🤝 Contribute # Table of Contents * APIs, Data & ML * Artificial Intelligence * BaaS * Code Editors * Code Generation * DNS * Databases * Design & UI * Domains * Email * Font * For Students * Forms * Linux Distributions * Messaging & Streaming * PaaS * Payments & Billing * SSL
For similar jobs

responsible-ai-toolbox
Responsible AI Toolbox is a suite of tools providing model and data exploration and assessment interfaces and libraries for understanding AI systems. It empowers developers and stakeholders to develop and monitor AI responsibly, enabling better data-driven actions. The toolbox includes visualization widgets for model assessment, error analysis, interpretability, fairness assessment, and mitigations library. It also offers a JupyterLab extension for managing machine learning experiments and a library for measuring gender bias in NLP datasets.
fairlearn
Fairlearn is a Python package designed to help developers assess and mitigate fairness issues in artificial intelligence (AI) systems. It provides mitigation algorithms and metrics for model assessment. Fairlearn focuses on two types of harms: allocation harms and quality-of-service harms. The package follows the group fairness approach, aiming to identify groups at risk of experiencing harms and ensuring comparable behavior across these groups. Fairlearn consists of metrics for assessing model impacts and algorithms for mitigating unfairness in various AI tasks under different fairness definitions.

Open-Prompt-Injection
OpenPromptInjection is an open-source toolkit for attacks and defenses in LLM-integrated applications, enabling easy implementation, evaluation, and extension of attacks, defenses, and LLMs. It supports various attack and defense strategies, including prompt injection, paraphrasing, retokenization, data prompt isolation, instructional prevention, sandwich prevention, perplexity-based detection, LLM-based detection, response-based detection, and know-answer detection. Users can create models, tasks, and apps to evaluate different scenarios. The toolkit currently supports PaLM2 and provides a demo for querying models with prompts. Users can also evaluate ASV for different scenarios by injecting tasks and querying models with attacked data prompts.
aws-machine-learning-university-responsible-ai
This repository contains slides, notebooks, and data for the Machine Learning University (MLU) Responsible AI class. The mission is to make Machine Learning accessible to everyone, covering widely used ML techniques and applying them to real-world problems. The class includes lectures, final projects, and interactive visuals to help users learn about Responsible AI and core ML concepts.

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

Awesome-Interpretability-in-Large-Language-Models
This repository is a collection of resources focused on interpretability in large language models (LLMs). It aims to help beginners get started in the area and keep researchers updated on the latest progress. It includes libraries, blogs, tutorials, forums, tools, programs, papers, and more related to interpretability in LLMs.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

llm-misinformation-survey
The 'llm-misinformation-survey' repository is dedicated to the survey on combating misinformation in the age of Large Language Models (LLMs). It explores the opportunities and challenges of utilizing LLMs to combat misinformation, providing insights into the history of combating misinformation, current efforts, and future outlook. The repository serves as a resource hub for the initiative 'LLMs Meet Misinformation' and welcomes contributions of relevant research papers and resources. The goal is to facilitate interdisciplinary efforts in combating LLM-generated misinformation and promoting the responsible use of LLMs in fighting misinformation.