
fairlearn
A Python package to assess and improve fairness of machine learning models.
Stars: 2011
Fairlearn is a Python package designed to help developers assess and mitigate fairness issues in artificial intelligence (AI) systems. It provides mitigation algorithms and metrics for model assessment. Fairlearn focuses on two types of harms: allocation harms and quality-of-service harms. The package follows the group fairness approach, aiming to identify groups at risk of experiencing harms and ensuring comparable behavior across these groups. Fairlearn consists of metrics for assessing model impacts and algorithms for mitigating unfairness in various AI tasks under different fairness definitions.
README:
|MIT license| |PyPI| |Discord| |StackOverflow|
Fairlearn is a Python package that empowers developers of artificial intelligence (AI) systems to assess their system's fairness and mitigate any observed unfairness issues. Fairlearn contains mitigation algorithms as well as metrics for model assessment. Besides the source code, this repository also contains Jupyter notebooks with examples of Fairlearn usage.
Website: https://fairlearn.org/
-
Current release <#current-release>__ -
What we mean by *fairness* <#what-we-mean-by-fairness>__ -
Overview of Fairlearn <#overview-of-fairlearn>__ -
Fairlearn metrics <#fairlearn-metrics>__ -
Fairlearn algorithms <#fairlearn-algorithms>__ -
Install Fairlearn <#install-fairlearn>__ -
Usage <#usage>__ -
Contributing <#contributing>__ -
Maintainers <#maintainers>__ -
Code of conduct <#code-of-conduct>__ -
Issues <#issues>__
-
The current stable release is available on
PyPI <https://pypi.org/project/fairlearn/>__. -
Our current version may differ substantially from earlier versions. Users of earlier versions should visit our
version guide <https://fairlearn.org/main/user_guide/installation_and_version_guide/version_guide.html>__ to navigate significant changes and find information on how to migrate.
An AI system can behave unfairly for a variety of reasons. In Fairlearn, we define whether an AI system is behaving unfairly in terms of its impact on people – i.e., in terms of harms. We focus on two kinds of harms:
-
Allocation harms. These harms can occur when AI systems extend or withhold opportunities, resources, or information. Some of the key applications are in hiring, school admissions, and lending.
-
Quality-of-service harms. Quality of service refers to whether a system works as well for one person as it does for another, even if no opportunities, resources, or information are extended or withheld.
We follow the approach known as group fairness, which asks: Which groups of individuals are at risk for experiencing harms? The relevant groups need to be specified by the data scientist and are application specific.
Group fairness is formalized by a set of constraints, which require that
some aspect (or aspects) of the AI system's behavior be comparable
across the groups. The Fairlearn package enables assessment and
mitigation of unfairness under several common definitions. To learn more
about our definitions of fairness, please visit our
user guide on Fairness of AI Systems <https://fairlearn.org/main/user_guide/fairness_in_machine_learning.html#fairness-of-ai-systems>__.
*Note*: Fairness is fundamentally a sociotechnical challenge. Many
aspects of fairness, such as justice and due process, are not
captured by quantitative fairness metrics. Furthermore, there are
many quantitative fairness metrics which cannot all be satisfied
simultaneously. Our goal is to enable humans to assess different
mitigation strategies and then make trade-offs appropriate to their
scenario.
The Fairlearn Python package has two components:
-
Metrics for assessing which groups are negatively impacted by a model, and for comparing multiple models in terms of various fairness and accuracy metrics.
-
Algorithms for mitigating unfairness in a variety of AI tasks and along a variety of fairness definitions.
Fairlearn metrics
Check out our in-depth `guide on the Fairlearn metrics <https://fairlearn.org/main/user_guide/assessment>`__.
Fairlearn algorithms
For an overview of our algorithms please refer to our
website <https://fairlearn.org/main/user_guide/mitigation/index.html>__.
For instructions on how to install Fairlearn check out our Quickstart guide <https://fairlearn.org/main/quickstart.html>__.
For common usage refer to the Jupyter notebooks <https://fairlearn.org/main/auto_examples/index.html>__ and
our user guide <https://fairlearn.org/main/user_guide/index.html>.
Please note that our APIs are subject to change, so notebooks downloaded
from main may not be compatible with Fairlearn installed with
pip. In this case, please navigate the tags in the repository (e.g.
v0.7.0 <https://github.com/fairlearn/fairlearn/tree/v0.7.0>) to
locate the appropriate version of the notebook.
To contribute please check our contributor guide <https://fairlearn.org/main/contributor_guide/index.html>__.
A list of current maintainers is
on our website <https://fairlearn.org/main/about/index.html>__.
Fairlearn follows the Fairlearn Organization’s Code of Conduct <https://github.com/fairlearn/governance/blob/main/code-of-conduct.md>__.
Usage Questions
Pose questions and help answer them on `Stack
Overflow <https://stackoverflow.com/questions/tagged/fairlearn>`__ with
the tag ``fairlearn`` or on
`Discord <https://discord.gg/R22yCfgsRn>`__.
Regular (non-security) issues
Issues are meant for bugs, feature requests, and documentation
improvements. Please submit a report through
GitHub issues <https://github.com/fairlearn/fairlearn/issues>__.
A maintainer will respond promptly as appropriate.
Maintainers will try to link duplicate issues when possible.
Reporting security issues
To report security issues please send an email to
``[email protected]``.
.. |MIT license| image:: https://img.shields.io/badge/License-MIT-blue.svg
:target: https://github.com/fairlearn/fairlearn/blob/main/LICENSE
.. |PyPI| image:: https://img.shields.io/pypi/v/fairlearn?color=blue
:target: https://pypi.org/project/fairlearn/
.. |Discord| image:: https://img.shields.io/discord/840099830160031744
:target: https://discord.gg/R22yCfgsRn
.. |StackOverflow| image:: https://img.shields.io/badge/StackOverflow-questions-blueviolet
:target: https://stackoverflow.com/questions/tagged/fairlearn
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for fairlearn
Similar Open Source Tools
fairlearn
Fairlearn is a Python package designed to help developers assess and mitigate fairness issues in artificial intelligence (AI) systems. It provides mitigation algorithms and metrics for model assessment. Fairlearn focuses on two types of harms: allocation harms and quality-of-service harms. The package follows the group fairness approach, aiming to identify groups at risk of experiencing harms and ensuring comparable behavior across these groups. Fairlearn consists of metrics for assessing model impacts and algorithms for mitigating unfairness in various AI tasks under different fairness definitions.

eval-dev-quality
DevQualityEval is an evaluation benchmark and framework designed to compare and improve the quality of code generation of Language Model Models (LLMs). It provides developers with a standardized benchmark to enhance real-world usage in software development and offers users metrics and comparisons to assess the usefulness of LLMs for their tasks. The tool evaluates LLMs' performance in solving software development tasks and measures the quality of their results through a point-based system. Users can run specific tasks, such as test generation, across different programming languages to evaluate LLMs' language understanding and code generation capabilities.

artkit
ARTKIT is a Python framework developed by BCG X for automating prompt-based testing and evaluation of Gen AI applications. It allows users to develop automated end-to-end testing and evaluation pipelines for Gen AI systems, supporting multi-turn conversations and various testing scenarios like Q&A accuracy, brand values, equitability, safety, and security. The framework provides a simple API, asynchronous processing, caching, model agnostic support, end-to-end pipelines, multi-turn conversations, robust data flows, and visualizations. ARTKIT is designed for customization by data scientists and engineers to enhance human-in-the-loop testing and evaluation, emphasizing the importance of tailored testing for each Gen AI use case.
strwythura
Strwythura is a library and tutorial focused on constructing a knowledge graph from unstructured data sources using state-of-the-art models for named entity recognition. It implements an enhanced GraphRAG approach and curates semantics for optimizing AI application outcomes within a specific domain. The tutorial emphasizes the use of sophisticated NLP pipelines based on spaCy, GLiNER, TextRank, and related libraries to provide better/faster/cheaper results with more control over the intentional arrangement of the knowledge graph. It leverages neurosymbolic AI methods and combines practices from natural language processing, graph data science, entity resolution, ontology pipeline, context engineering, and human-in-the-loop processes.

OlympicArena
OlympicArena is a comprehensive benchmark designed to evaluate advanced AI capabilities across various disciplines. It aims to push AI towards superintelligence by tackling complex challenges in science and beyond. The repository provides detailed data for different disciplines, allows users to run inference and evaluation locally, and offers a submission platform for testing models on the test set. Additionally, it includes an annotation interface and encourages users to cite their paper if they find the code or dataset helpful.

LLMeBench
LLMeBench is a flexible framework designed for accelerating benchmarking of Large Language Models (LLMs) in the field of Natural Language Processing (NLP). It supports evaluation of various NLP tasks using model providers like OpenAI, HuggingFace Inference API, and Petals. The framework is customizable for different NLP tasks, LLM models, and datasets across multiple languages. It features extensive caching capabilities, supports zero- and few-shot learning paradigms, and allows on-the-fly dataset download and caching. LLMeBench is open-source and continuously expanding to support new models accessible through APIs.

storm
STORM is a LLM system that writes Wikipedia-like articles from scratch based on Internet search. While the system cannot produce publication-ready articles that often require a significant number of edits, experienced Wikipedia editors have found it helpful in their pre-writing stage. **Try out our [live research preview](https://storm.genie.stanford.edu/) to see how STORM can help your knowledge exploration journey and please provide feedback to help us improve the system 🙏!**

MultiPL-E
MultiPL-E is a system for translating unit test-driven neural code generation benchmarks to new languages. It is part of the BigCode Code Generation LM Harness and allows for evaluating Code LLMs using various benchmarks. The tool supports multiple versions with improvements and new language additions, providing a scalable and polyglot approach to benchmarking neural code generation. Users can access a tutorial for direct usage and explore the dataset of translated prompts on the Hugging Face Hub.

LayerSkip
LayerSkip is an implementation enabling early exit inference and self-speculative decoding. It provides a code base for running models trained using the LayerSkip recipe, offering speedup through self-speculative decoding. The tool integrates with Hugging Face transformers and provides checkpoints for various LLMs. Users can generate tokens, benchmark on datasets, evaluate tasks, and sweep over hyperparameters to optimize inference speed. The tool also includes correctness verification scripts and Docker setup instructions. Additionally, other implementations like gpt-fast and Native HuggingFace are available. Training implementation is a work-in-progress, and contributions are welcome under the CC BY-NC license.

probsem
ProbSem is a repository that provides a framework to leverage large language models (LLMs) for assigning context-conditional probability distributions over queried strings. It supports OpenAI engines and HuggingFace CausalLM models, and is flexible for research applications in linguistics, cognitive science, program synthesis, and NLP. Users can define prompts, contexts, and queries to derive probability distributions over possible completions, enabling tasks like cloze completion, multiple-choice QA, semantic parsing, and code completion. The repository offers CLI and API interfaces for evaluation, with options to customize models, normalize scores, and adjust temperature for probability distributions.

giskard
Giskard is an open-source Python library that automatically detects performance, bias & security issues in AI applications. The library covers LLM-based applications such as RAG agents, all the way to traditional ML models for tabular data.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.
fabrice-ai
A lightweight, functional, and composable framework for building AI agents that work together to solve complex tasks. Built with TypeScript and designed to be serverless-ready. Fabrice embraces functional programming principles, remains stateless, and stays focused on composability. It provides core concepts like easy teamwork creation, infrastructure-agnosticism, statelessness, and includes all tools and features needed to build AI teams. Agents are specialized workers with specific roles and capabilities, able to call tools and complete tasks. Workflows define how agents collaborate to achieve a goal, with workflow states representing the current state of the workflow. Providers handle requests to the LLM and responses. Tools extend agent capabilities by providing concrete actions they can perform. Execution involves running the workflow to completion, with options for custom execution and BDD testing.

mentals-ai
Mentals AI is a tool designed for creating and operating agents that feature loops, memory, and various tools, all through straightforward markdown syntax. This tool enables you to concentrate solely on the agent’s logic, eliminating the necessity to compose underlying code in Python or any other language. It redefines the foundational frameworks for future AI applications by allowing the creation of agents with recursive decision-making processes, integration of reasoning frameworks, and control flow expressed in natural language. Key concepts include instructions with prompts and references, working memory for context, short-term memory for storing intermediate results, and control flow from strings to algorithms. The tool provides a set of native tools for message output, user input, file handling, Python interpreter, Bash commands, and short-term memory. The roadmap includes features like a web UI, vector database tools, agent's experience, and tools for image generation and browsing. The idea behind Mentals AI originated from studies on psychoanalysis executive functions and aims to integrate 'System 1' (cognitive executor) with 'System 2' (central executive) to create more sophisticated agents.
For similar tasks
fairlearn
Fairlearn is a Python package designed to help developers assess and mitigate fairness issues in artificial intelligence (AI) systems. It provides mitigation algorithms and metrics for model assessment. Fairlearn focuses on two types of harms: allocation harms and quality-of-service harms. The package follows the group fairness approach, aiming to identify groups at risk of experiencing harms and ensuring comparable behavior across these groups. Fairlearn consists of metrics for assessing model impacts and algorithms for mitigating unfairness in various AI tasks under different fairness definitions.
seismometer
Seismometer is a suite of tools designed to evaluate AI model performance in healthcare settings. It helps healthcare organizations assess the accuracy of AI models and ensure equitable care for diverse patient populations. The tool allows users to validate model performance using standardized evaluation criteria based on local data and workflows. It includes templates for analyzing statistical performance, fairness across different cohorts, and the impact of interventions on outcomes. Seismometer is continuously evolving to incorporate new validation and analysis techniques.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.
ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.

lighteval
LightEval is a lightweight LLM evaluation suite that Hugging Face has been using internally with the recently released LLM data processing library datatrove and LLM training library nanotron. We're releasing it with the community in the spirit of building in the open. Note that it is still very much early so don't expect 100% stability ^^' In case of problems or question, feel free to open an issue!
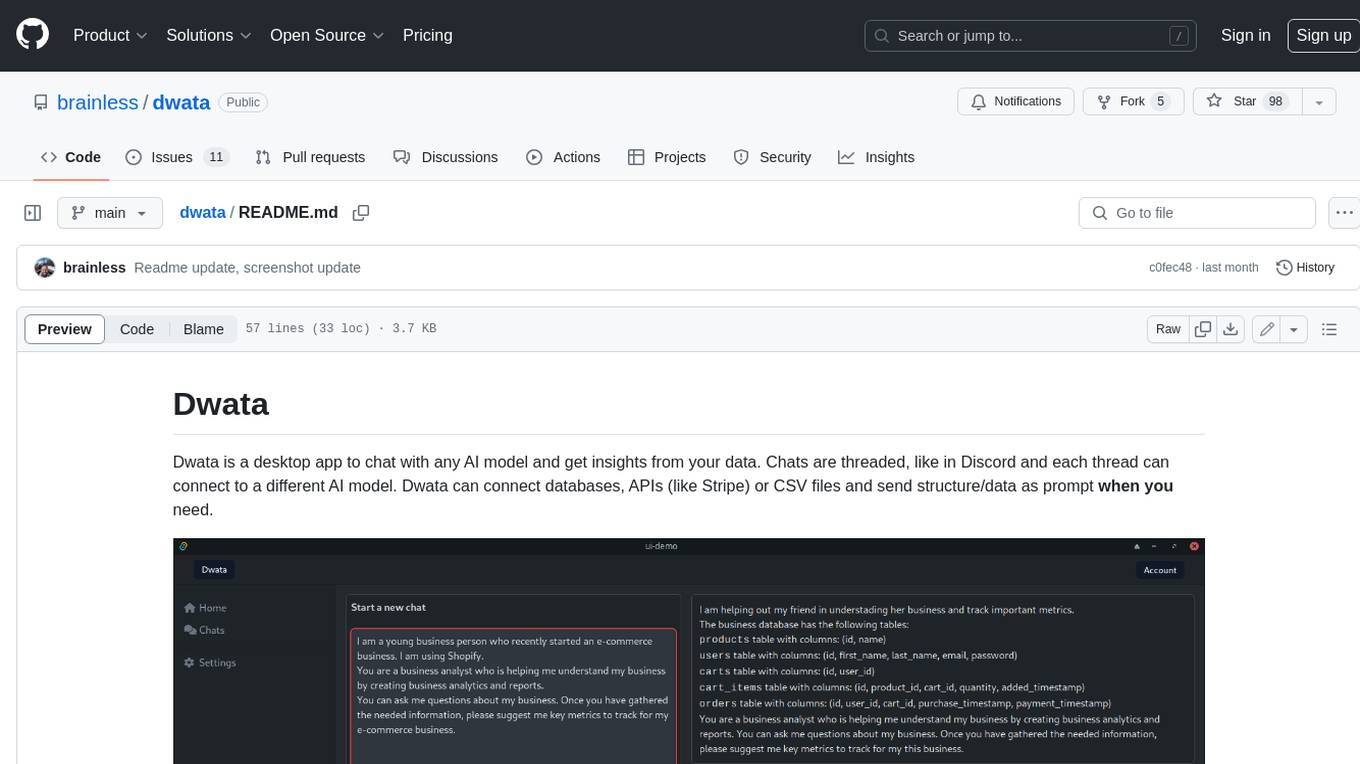
dwata
Dwata is a desktop application that allows users to chat with any AI model and gain insights from their data. Chats are organized into threads, similar to Discord, with each thread connecting to a different AI model. Dwata can connect to databases, APIs (such as Stripe), or CSV files and send structured data as prompts when needed. The AI's response will often include SQL or Python code, which can be used to extract the desired insights. Dwata can validate AI-generated SQL to ensure that the tables and columns referenced are correct and can execute queries against the database from within the application. Python code (typically using Pandas) can also be executed from within Dwata, although this feature is still in development. Dwata supports a range of AI models, including OpenAI's GPT-4, GPT-4 Turbo, and GPT-3.5 Turbo; Groq's LLaMA2-70b and Mixtral-8x7b; Phind's Phind-34B and Phind-70B; Anthropic's Claude; and Ollama's Llama 2, Mistral, and Phi-2 Gemma. Dwata can compare chats from different models, allowing users to see the responses of multiple models to the same prompts. Dwata can connect to various data sources, including databases (PostgreSQL, MySQL, MongoDB), SaaS products (Stripe, Shopify), CSV files/folders, and email (IMAP). The desktop application does not collect any private or business data without the user's explicit consent.
For similar jobs

responsible-ai-toolbox
Responsible AI Toolbox is a suite of tools providing model and data exploration and assessment interfaces and libraries for understanding AI systems. It empowers developers and stakeholders to develop and monitor AI responsibly, enabling better data-driven actions. The toolbox includes visualization widgets for model assessment, error analysis, interpretability, fairness assessment, and mitigations library. It also offers a JupyterLab extension for managing machine learning experiments and a library for measuring gender bias in NLP datasets.
fairlearn
Fairlearn is a Python package designed to help developers assess and mitigate fairness issues in artificial intelligence (AI) systems. It provides mitigation algorithms and metrics for model assessment. Fairlearn focuses on two types of harms: allocation harms and quality-of-service harms. The package follows the group fairness approach, aiming to identify groups at risk of experiencing harms and ensuring comparable behavior across these groups. Fairlearn consists of metrics for assessing model impacts and algorithms for mitigating unfairness in various AI tasks under different fairness definitions.

Open-Prompt-Injection
OpenPromptInjection is an open-source toolkit for attacks and defenses in LLM-integrated applications, enabling easy implementation, evaluation, and extension of attacks, defenses, and LLMs. It supports various attack and defense strategies, including prompt injection, paraphrasing, retokenization, data prompt isolation, instructional prevention, sandwich prevention, perplexity-based detection, LLM-based detection, response-based detection, and know-answer detection. Users can create models, tasks, and apps to evaluate different scenarios. The toolkit currently supports PaLM2 and provides a demo for querying models with prompts. Users can also evaluate ASV for different scenarios by injecting tasks and querying models with attacked data prompts.

aws-machine-learning-university-responsible-ai
This repository contains slides, notebooks, and data for the Machine Learning University (MLU) Responsible AI class. The mission is to make Machine Learning accessible to everyone, covering widely used ML techniques and applying them to real-world problems. The class includes lectures, final projects, and interactive visuals to help users learn about Responsible AI and core ML concepts.

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

Awesome-Interpretability-in-Large-Language-Models
This repository is a collection of resources focused on interpretability in large language models (LLMs). It aims to help beginners get started in the area and keep researchers updated on the latest progress. It includes libraries, blogs, tutorials, forums, tools, programs, papers, and more related to interpretability in LLMs.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.

llm-misinformation-survey
The 'llm-misinformation-survey' repository is dedicated to the survey on combating misinformation in the age of Large Language Models (LLMs). It explores the opportunities and challenges of utilizing LLMs to combat misinformation, providing insights into the history of combating misinformation, current efforts, and future outlook. The repository serves as a resource hub for the initiative 'LLMs Meet Misinformation' and welcomes contributions of relevant research papers and resources. The goal is to facilitate interdisciplinary efforts in combating LLM-generated misinformation and promoting the responsible use of LLMs in fighting misinformation.