
dockershrink
Dockershrink is an AI Agent that reduces the size of your Docker Images
Stars: 300
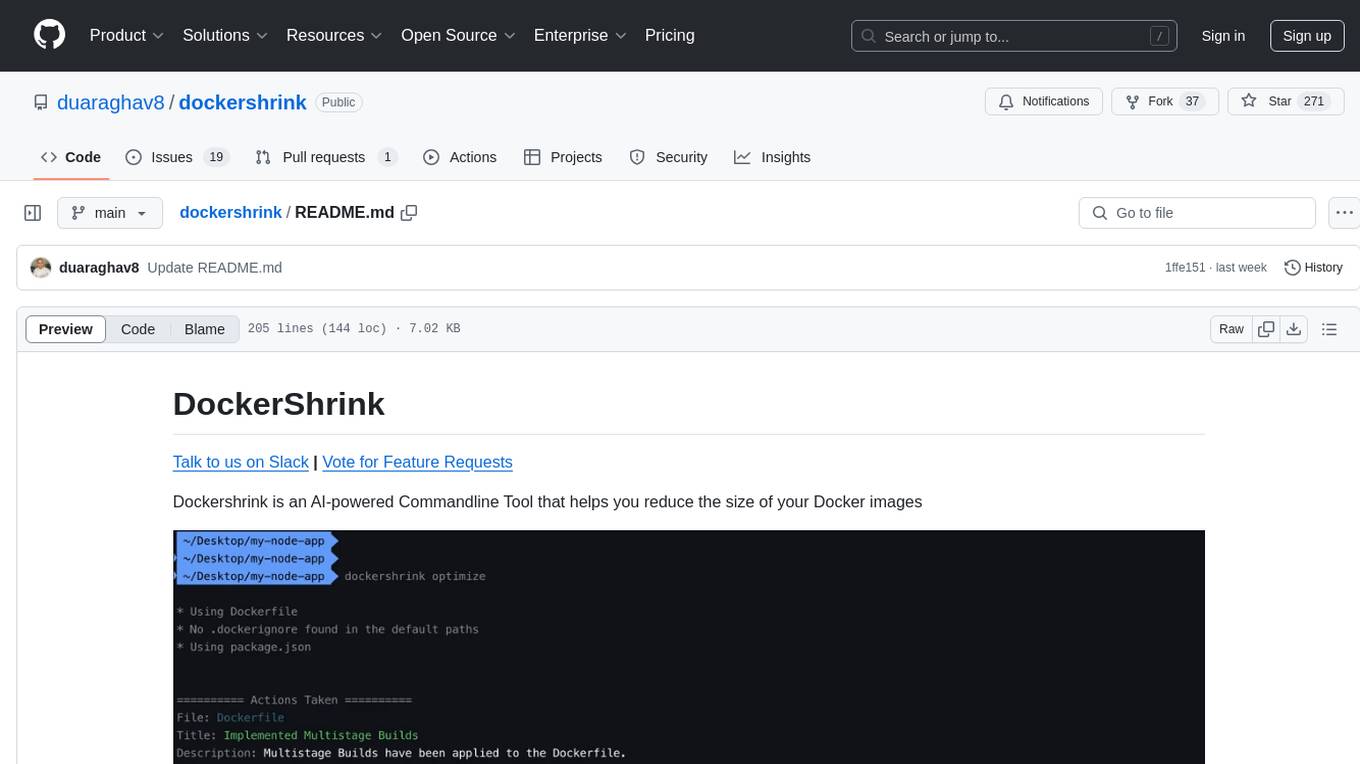
Dockershrink is an AI-powered Commandline Tool designed to help reduce the size of Docker images. It combines traditional Rule-based analysis with Generative AI techniques to optimize Image configurations. The tool supports NodeJS applications and aims to save costs on storage, data transfer, and build times while increasing developer productivity. By automatically applying advanced optimization techniques, Dockershrink simplifies the process for engineers and organizations, resulting in significant savings and efficiency improvements.
README:

Talk to us on Slack | Vote for Feature Requests
Dockershrink is an AI-powered Commandline Tool that helps you reduce the size of your Docker images

It combines the power of algorithmic analysis with Generative AI to apply state-of-the-art optimizations to your Image configurations 🧠
Dockershrink can automatically apply techniques like Multi-Stage builds, switching to Lighter base images like alpine and running dependency checks. PLUS a lot more is on the roadmap 🚀
Currently, the tool only supports NodeJS applications.
[!IMPORTANT] Dockershrink is BETA software.
You can provide your feedback by creating an Issue in this repository.
Every org using containers in development or production environments understands the pain of managing hundreds or even thousands of bloated Docker images in their infrastructure.
High data storage and transfer costs, long build times, underprodctive developers - we've seen it all.
The issue becomes even more painful and costly with interpreted languages such as Nodejs & Python. Apps written in these languages need to pack the interpreters and all their dependencies inside their container images, significantly increasing their size.
But not everyone realizes that by just implementing some basic techniques, they can reduce the size of a 1GB Docker image down to as little as 100 MB!
(I also made a video on how to do this.)
Imagine the costs saved in storage & data transfer, decrease in build times AND the productivity gains for developers 🤯
Dockershrink aims to automatically apply advanced optimization techniques so engineers don't have to waste time on it and the organization still saves 💰!
You're welcome 😉
When you invoke the dockershrink CLI on your project, it analyzes code files.
Dockershrink looks for the following files:
👉 Dockerfile (Required)
👉 package.json (Optional)
👉 .dockerignore (Optional, created if it doesn't already exist)
It then creates a new directory (default: dockershrink.optimized) inside the project, which contains modified versions of your configuration files that will result in a smaller Docker Image.
The CLI outputs a list of actions it took over your files.
It may also include suggestions on further improvements you could make.
You can install dockershrink using PIP or PIPX
$ pip install dockershrink$ pipx install dockershrinkAlternatively, you can also install it using Homebrew:
brew install duaraghav8/tap/dockershrinkBut you should prefer to use pip instead because installation via brew takes a lot longer and occupies significanlty more space on your system (see this issue)
Navigate into the root directory of one of your Node.js projects and invoke dockershrink with the optimize command:
$ dockershrink optimizeDockershrink will create a new directory with the optimized files and output the actions taken and (maybe) some more suggestions.
For detailed information about the optimize command, run
dockershrink optimize --helpYou can also use the --verbose option to get stack traces in case of failures:
$ dockershrink optimize --verboseTo enable DEBUG logs, you can set the environment variable
export DOCKERSHRINK_CLI_LOGLEVEL=DEBUG
dockershrink optimize[!NOTE] Using AI features is optional, but highly recommended for more customized and powerful optimizations.
To use AI, you need to supply your own OpenAI API key, so even though Dockershrink itself is free, openai usage might incur some cost for you.
By default, dockershrink only runs rule-based analysis to optimize your image definition.
If you want to enable AI, you must supply your OpenAI API Key.
dockershrink optimize --openai-api-key <your openai api key>
# Alternatively, you can supply the key as an environment variable
export OPENAI_API_KEY=<your openai api key>
dockershrink optimize[!NOTE] Dockershrink does not store your OpenAI API Key.
So you must provide your key every time you want "optimize" to use AI features. This is to avoid any unexpected costs.
By default, the CLI looks for the files to optimize in the current directory.
You can also specify the paths to all files using options (see dockershrink optimize --help for the available options).
[!NOTE] This section is for authors and contributors. If you're simply interested in using Dockershrink, you can skip this section.
- Clone this repository
- Navigate inside the root directory of the project and create a new virtual environment
python3 -m venv .venv
source .venv/bin/activate- Install all dependencies
pip install --no-cache-dir -r requirements.txt- Install the editable CLI tool
# -e ensures that the tool is editable, ie, code changes reflect in the tool immediately, without having to re-install it
pip install -e .
# Try running the cli
dockershrink --help- Make your code changes
- Run black
black .- In case of any changes in dependencies, update requirements.txt
pip freeze > requirements.txtOnce all code changes have been made for the next release:
- Upgrade the version in pyproject.toml and cli.py
- Make sure that dependencies and their versions are updated in requirements.txt and pyproject.toml
Then proceed to follow these steps to release new dockershrink version on PyPI:
- Build dockershrink from source
python -m build- Upload to testpypi
twine upload --repository testpypi dist/*- The new version of the package should now be available in TestPyPI.
- Try installing the test package
pip install --index-url https://test.pypi.org/simple/ --no-deps dockershrink- Create a new Tag and push it
git tag -a <VERSION> -m "Tag version <VERSION>"
git push origin <VERSION>- Create a new release in this repository
- Upload the package to PyPI
twine upload dist/*- The new version of the package should now be available in PyPI
- Update the package in Dockershrink Homebrew Tap as well.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for dockershrink
Similar Open Source Tools
dockershrink
Dockershrink is an AI-powered Commandline Tool designed to help reduce the size of Docker images. It combines traditional Rule-based analysis with Generative AI techniques to optimize Image configurations. The tool supports NodeJS applications and aims to save costs on storage, data transfer, and build times while increasing developer productivity. By automatically applying advanced optimization techniques, Dockershrink simplifies the process for engineers and organizations, resulting in significant savings and efficiency improvements.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.
openui
OpenUI is a tool designed to simplify the process of building UI components by allowing users to describe UI using their imagination and see it rendered live. It supports converting HTML to React, Svelte, Web Components, etc. The tool is open source and aims to make UI development fun, fast, and flexible. It integrates with various AI services like OpenAI, Groq, Gemini, Anthropic, Cohere, and Mistral, providing users with the flexibility to use different models. OpenUI also supports LiteLLM for connecting to various LLM services and allows users to create custom proxy configs. The tool can be run locally using Docker or Python, and it offers a development environment for quick setup and testing.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
aiarena-web
aiarena-web is a website designed for running the aiarena.net infrastructure. It consists of different modules such as core functionality, web API endpoints, frontend templates, and a module for linking users to their Patreon accounts. The website serves as a platform for obtaining new matches, reporting results, featuring match replays, and connecting with Patreon supporters. The project is licensed under GPLv3 in 2019.
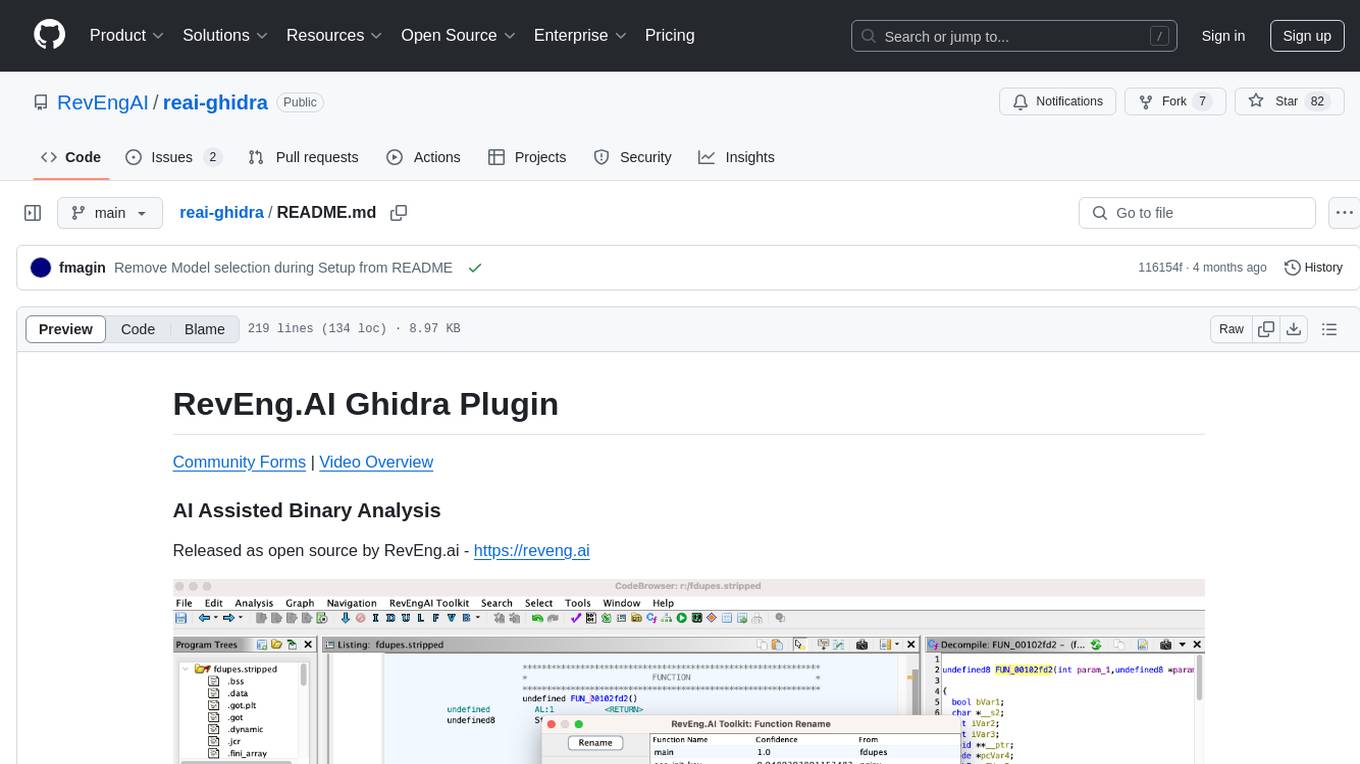
reai-ghidra
The RevEng.AI Ghidra Plugin by RevEng.ai allows users to interact with their API within Ghidra for Binary Code Similarity analysis to aid in Reverse Engineering stripped binaries. Users can upload binaries, rename functions above a confidence threshold, and view similar functions for a selected function.
polis
Polis is an AI powered sentiment gathering platform that offers a more organic approach than surveys and requires less effort than focus groups. It provides a comprehensive wiki, main deployment at https://pol.is, discussions, issue tracking, and project board for users. Polis can be set up using Docker infrastructure and offers various commands for building and running containers. Users can test their instance, update the system, and deploy Polis for production. The tool also provides developer conveniences for code reloading, type checking, and database connections. Additionally, Polis supports end-to-end browser testing using Cypress and offers troubleshooting tips for common Docker and npm issues.
concierge
Concierge is a versatile automation tool designed to streamline repetitive tasks and workflows. It provides a user-friendly interface for creating custom automation scripts without the need for extensive coding knowledge. With Concierge, users can automate various tasks across different platforms and applications, increasing efficiency and productivity. The tool offers a wide range of pre-built automation templates and allows users to customize and schedule their automation processes. Concierge is suitable for individuals and businesses looking to automate routine tasks and improve overall workflow efficiency.

jaison-core
J.A.I.son is a Python project designed for generating responses using various components and applications. It requires specific plugins like STT, T2T, TTSG, and TTSC to function properly. Users can customize responses, voice, and configurations. The project provides a Discord bot, Twitch events and chat integration, and VTube Studio Animation Hotkeyer. It also offers features for managing conversation history, training AI models, and monitoring conversations.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.

airbyte_serverless
AirbyteServerless is a lightweight tool designed to simplify the management of Airbyte connectors. It offers a serverless mode for running connectors, allowing users to easily move data from any source to their data warehouse. Unlike the full Airbyte-Open-Source-Platform, AirbyteServerless focuses solely on the Extract-Load process without a UI, database, or transform layer. It provides a CLI tool, 'abs', for managing connectors, creating connections, running jobs, selecting specific data streams, handling secrets securely, and scheduling remote runs. The tool is scalable, allowing independent deployment of multiple connectors. It aims to streamline the connector management process and provide a more agile alternative to the comprehensive Airbyte platform.

agentok
Agentok Studio is a visual tool built for AutoGen, a cutting-edge agent framework from Microsoft and various contributors. It offers intuitive visual tools to simplify the construction and management of complex agent-based workflows. Users can create workflows visually as graphs, chat with agents, and share flow templates. The tool is designed to streamline the development process for creators and developers working on next-generation Multi-Agent Applications.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.
aiCoder
aiCoder is an AI-powered tool designed to streamline the coding process by automating repetitive tasks, providing intelligent code suggestions, and facilitating the integration of new features into existing codebases. It offers a chat interface for natural language interactions, methods and stubs lists for code modification, and settings customization for project-specific prompts. Users can leverage aiCoder to enhance code quality, focus on higher-level design, and save time during development.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.
For similar tasks
dockershrink
Dockershrink is an AI-powered Commandline Tool designed to help reduce the size of Docker images. It combines traditional Rule-based analysis with Generative AI techniques to optimize Image configurations. The tool supports NodeJS applications and aims to save costs on storage, data transfer, and build times while increasing developer productivity. By automatically applying advanced optimization techniques, Dockershrink simplifies the process for engineers and organizations, resulting in significant savings and efficiency improvements.
For similar jobs

AirGo
AirGo is a front and rear end separation, multi user, multi protocol proxy service management system, simple and easy to use. It supports vless, vmess, shadowsocks, and hysteria2.

mosec
Mosec is a high-performance and flexible model serving framework for building ML model-enabled backend and microservices. It bridges the gap between any machine learning models you just trained and the efficient online service API. * **Highly performant** : web layer and task coordination built with Rust 🦀, which offers blazing speed in addition to efficient CPU utilization powered by async I/O * **Ease of use** : user interface purely in Python 🐍, by which users can serve their models in an ML framework-agnostic manner using the same code as they do for offline testing * **Dynamic batching** : aggregate requests from different users for batched inference and distribute results back * **Pipelined stages** : spawn multiple processes for pipelined stages to handle CPU/GPU/IO mixed workloads * **Cloud friendly** : designed to run in the cloud, with the model warmup, graceful shutdown, and Prometheus monitoring metrics, easily managed by Kubernetes or any container orchestration systems * **Do one thing well** : focus on the online serving part, users can pay attention to the model optimization and business logic

llm-code-interpreter
The 'llm-code-interpreter' repository is a deprecated plugin that provides a code interpreter on steroids for ChatGPT by E2B. It gives ChatGPT access to a sandboxed cloud environment with capabilities like running any code, accessing Linux OS, installing programs, using filesystem, running processes, and accessing the internet. The plugin exposes commands to run shell commands, read files, and write files, enabling various possibilities such as running different languages, installing programs, starting servers, deploying websites, and more. It is powered by the E2B API and is designed for agents to freely experiment within a sandboxed environment.

pezzo
Pezzo is a fully cloud-native and open-source LLMOps platform that allows users to observe and monitor AI operations, troubleshoot issues, save costs and latency, collaborate, manage prompts, and deliver AI changes instantly. It supports various clients for prompt management, observability, and caching. Users can run the full Pezzo stack locally using Docker Compose, with prerequisites including Node.js 18+, Docker, and a GraphQL Language Feature Support VSCode Extension. Contributions are welcome, and the source code is available under the Apache 2.0 License.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.

gcloud-aio
This repository contains shared codebase for two projects: gcloud-aio and gcloud-rest. gcloud-aio is built for Python 3's asyncio, while gcloud-rest is a threadsafe requests-based implementation. It provides clients for Google Cloud services like Auth, BigQuery, Datastore, KMS, PubSub, Storage, and Task Queue. Users can install the library using pip and refer to the documentation for usage details. Developers can contribute to the project by following the contribution guide.

fluid
Fluid is an open source Kubernetes-native Distributed Dataset Orchestrator and Accelerator for data-intensive applications, such as big data and AI applications. It implements dataset abstraction, scalable cache runtime, automated data operations, elasticity and scheduling, and is runtime platform agnostic. Key concepts include Dataset and Runtime. Prerequisites include Kubernetes version > 1.16, Golang 1.18+, and Helm 3. The tool offers features like accelerating remote file accessing, machine learning, accelerating PVC, preloading dataset, and on-the-fly dataset cache scaling. Contributions are welcomed, and the project is under the Apache 2.0 license with a vendor-neutral approach.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.