
reai-ghidra
RevEng.AI Ghidra Plugin
Stars: 128
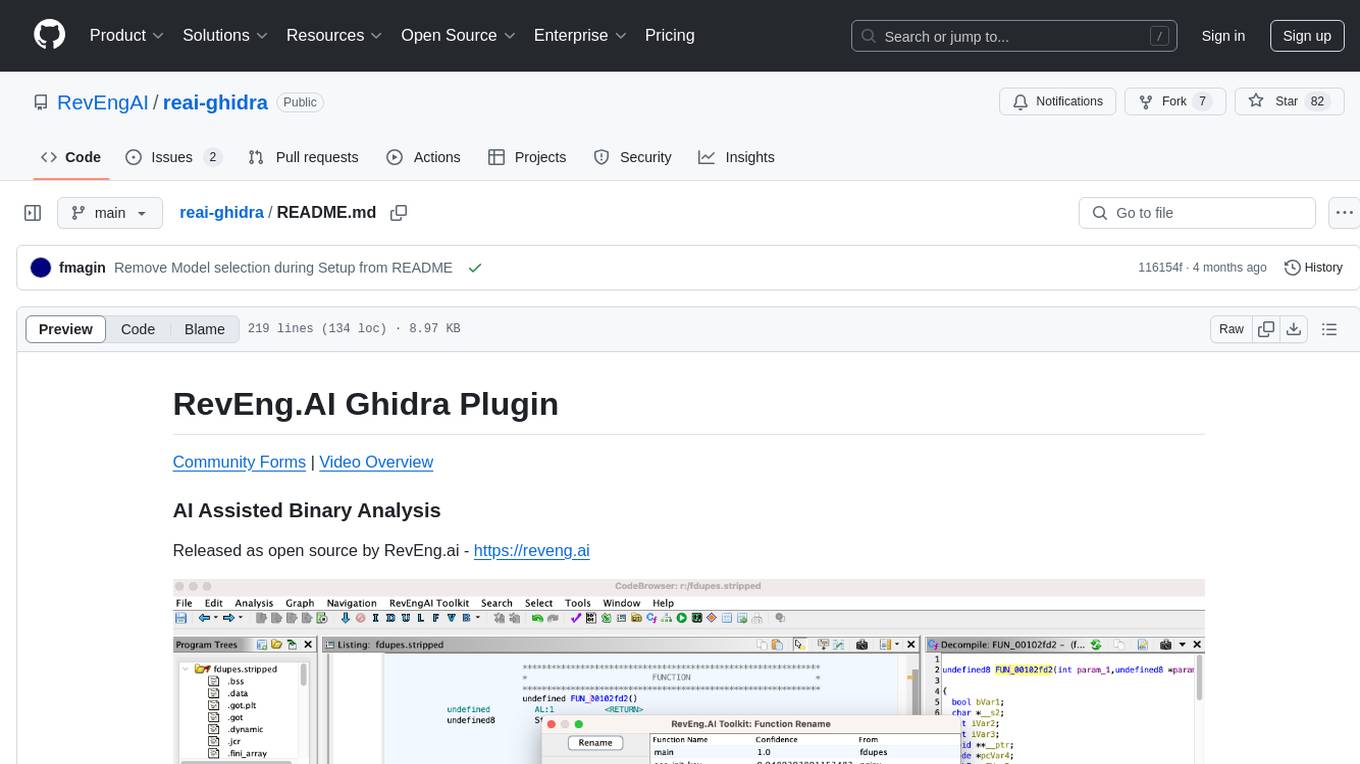
The RevEng.AI Ghidra Plugin by RevEng.ai allows users to interact with their API within Ghidra for Binary Code Similarity analysis to aid in Reverse Engineering stripped binaries. Users can upload binaries, rename functions above a confidence threshold, and view similar functions for a selected function.
README:
Community Forms | Video Overview
Released as open source by RevEng.ai - https://reveng.ai

The RevEng.AI Toolkit allows you to interact with our API from within Ghidra. This allows you to upload your currently open binary for analysis, and use it for Binary Code Similarity to help you Reverse Engineer stripped binaries.
- Upload the current binary for analysis
- Automatically rename all functions above a confidence threshold
- Show similar functions and their names for one selected function
The builds for latest stable version of the RevEng.AI Toolkit for common Ghidra versions can be downloaded from the Releases page.
We support all versions compatible with Ghidra 11.
The CI builds for all patch versions of the latest major version (11.3.X), and for the latest patch for each major (11.0.3, 11.1.2, 11.2.1). In practice the plugin should work.
If you are using a custom version of Ghidra (e.g. nightly builds), then you need to build your own version of the plugin against it,
otherwise Ghidra complains about a version mismatch when trying to install the plugin.
You can do this via ./gradlew -PGHIDRA_INSTALL_DIR=/opt/ghidra buildExtension, and then use the zip from the dist/ folder.
- Launch Ghidra.
- Navigate to the Install Extensions window.
-
File->Install Extensions...
-
- Click the green "+" icon at the top-right corner.
- Select the downloaded ZIP file to load the plugin into Ghidra.
- Click the "OK" button to exit the Install Extensions window.
- Restart Ghidra when prompted.
Once installed, you can enable the plugin via the Configure tool.
- Navigate to Ghidra's Configure tool
-
File->Configure
-
- Click
Configureunder theRevEng.AIplugin group - Select the checkbox next to each of the plugins you want to enable

Each plugin is dependent on the CorePlugin, for instance, by enabling the BinarySimularityPlugin you will automatically enable the CorePlugin.
In this section, we provide an example workflow for our plugin that uses test binaries from src/test/resources.
Once the plugin is loaded, there will be additional controls in the toolbar under RevEngAI Toolkit.
The first thing we need to do is configure the tool with our API key and the host to use.
When you load the plugin for the first time, or by selecting RevEngAI -> Run Setup Wizard, you will be guided through the configuration process.

Enter your API Key from the RevEng.AI Portal into the API Key field where they will be validated and saved for future use.
You are now ready to upload a binary.
Import src/test/resources/fdupes into Ghidra and then create a new RevEng analysis, by going to RevEngAI Toolkit -> Create New Analysis for Binary.
We are using
fdupeswith symbols to allow the model to learn what these functions look like, and to provide meaningful labels that we can use later to rename similar binaries.
You can check the status of your request by selecting Check Analysis Status from the same menu.
Starting an analysis also triggers a background Ghidra thread that will periodically check the status
and pop a notification when the analysis is complete.
We now have uploaded fdupes to our dataset, meaning we can now use it for our binary similarity tasks. Let's see how this works on a stripped version of fdupes.
Import src/test/resourcesfdupes.stripped using the same steps as before. Once this has been completed, you can move on to the next step.
With fdupes.stripped open in Ghidra, select a funtion in Ghidra's listing or decompiler view, and right-click -> Rename from Similar Functions, or CTRL-Shift + R.
This will open the function renaming window.


The list of functions is returned and displayed inside this panel for you.
You can then click Refresh to update the returned functions based on updated parameters.
You can also batch analyse the binary to rename functions using the Auto Analyse tool.
Move the slider to determine the confidence level you want to use for batch renaming. Any function returned that is higher than this value will automatically be renamed in the listing view. Clicking the start button will kick off the analysis, which you can track in the blue progress bar
Use Fetch Similar Functions to load matches from the API above the confidence threshold.

Once the results are retrieved, you can look at them more closely.
Each match is represented by a row in the table, and comes with various associated information
in each column. Not all of them are shown by default,
you can configure the displayed columns via the Add/Remove Columns entry in the context menu of a column.
You can now simply accept all displayed results via the Apply Filtered Results button,
or you can investigate them more closely yourself.
Ghidra comes with a powerful table including filtering and we integrate with this feature. Double-clicking a table entry will open the corresponding function in the listing view.
You can search by strings in all matches,
or you can access the advanced filter options via the Create Column Filter button:

Here you can now set up more complex filters, e.g. if you only want to apply matches that satisfy certain criteria.

After you apply the filter, the Apply Filtered Results button will only apply the matches that satisfy the filter.

Alternatively, you can select individual entries via Ctrl+Click and Shift+Click and apply only those via the
Apply Selected Results button.
We welcome pull requests from the community.
The plugin is still undergoing active development currently, and we are looking for feedback on how to improve the plugin.
We have tried to decompose the plugin into a series of individual plugins dependent on a CorePlugin.
The CorePlugin provides services that are shared across all parts of the toolkit, namely configuration and API Services.
You should therefore group related features into a Feature Plugin, and then acquire services from the CorePlugin as required. This gives users the flexiblity to enable / disable features based on their use-case and/or preferences.
Gradle can be used to build REAIT from its source code.
-
Clone the REAIT for Ghidra GitHub repository.
git clone https://github.com/RevEngAI/reait-ghidra.git -
Enter the repository and build with gradle.
cd reait-ghidra gradle -PGHIDRA_INSTALL_DIR=<ghidra_install_dir>- Replace
<ghidra_install_dir>with the path to your local Ghidra installation path.
- Replace
-
After building, the plugin ZIP file will be located in the
dist/folder.
Developing in Eclipse is the prefered method, but it does require some setup on the developers part, below is a (non-exhaustive) summary of what you need to do.
- Import the project into Eclipse
- Under Preferences -> Gradle
- Add a Program Argument:
-PGHIDRA_INSTALL_DIR=PATH2GHIDRA
- Add a Program Argument:
- Link you project with Ghidra using GhidraDev
- Update your classpath to point at
jar's inlib/- Again this can be found in your project
preferences
- Again this can be found in your project
If you've found a bug in reait-ghidra, please open an issue via GitHub, or create a post on our Community Forms.
Plugin configuration is not appearing after installation:
Check that the downloaded folder is called reai-ghidra and not reai-ghidra-2 due to multiple downloads of the same folder.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for reai-ghidra
Similar Open Source Tools
reai-ghidra
The RevEng.AI Ghidra Plugin by RevEng.ai allows users to interact with their API within Ghidra for Binary Code Similarity analysis to aid in Reverse Engineering stripped binaries. Users can upload binaries, rename functions above a confidence threshold, and view similar functions for a selected function.
reai-ida
RevEng.AI IDA Pro Plugin is a tool that integrates with the RevEng.AI platform to provide various features such as uploading binaries for analysis, downloading analysis logs, renaming function names, generating AI summaries, synchronizing functions between local analysis and the platform, and configuring plugin settings. Users can upload files for analysis, synchronize function names, rename functions, generate block summaries, and explain function behavior using this plugin. The tool requires IDA Pro v8.0 or later with Python 3.9 and higher. It relies on the 'reait' package for functionality.
langgraph-studio
LangGraph Studio is a specialized agent IDE that enables visualization, interaction, and debugging of complex agentic applications. It offers visual graphs and state editing to better understand agent workflows and iterate faster. Users can collaborate with teammates using LangSmith to debug failure modes. The tool integrates with LangSmith and requires Docker installed. Users can create and edit threads, configure graph runs, add interrupts, and support human-in-the-loop workflows. LangGraph Studio allows interactive modification of project config and graph code, with live sync to the interactive graph for easier iteration on long-running agents.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
CLI
Bito CLI provides a command line interface to the Bito AI chat functionality, allowing users to interact with the AI through commands. It supports complex automation and workflows, with features like long prompts and slash commands. Users can install Bito CLI on Mac, Linux, and Windows systems using various methods. The tool also offers configuration options for AI model type, access key management, and output language customization. Bito CLI is designed to enhance user experience in querying AI models and automating tasks through the command line interface.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.
n8n-docs
n8n is an extendable workflow automation tool that enables you to connect anything to everything. It is open-source and can be self-hosted or used as a service. n8n provides a visual interface for creating workflows, which can be used to automate tasks such as data integration, data transformation, and data analysis. n8n also includes a library of pre-built nodes that can be used to connect to a variety of applications and services. This makes it easy to create complex workflows without having to write any code.

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.
aiarena-web
aiarena-web is a website designed for running the aiarena.net infrastructure. It consists of different modules such as core functionality, web API endpoints, frontend templates, and a module for linking users to their Patreon accounts. The website serves as a platform for obtaining new matches, reporting results, featuring match replays, and connecting with Patreon supporters. The project is licensed under GPLv3 in 2019.
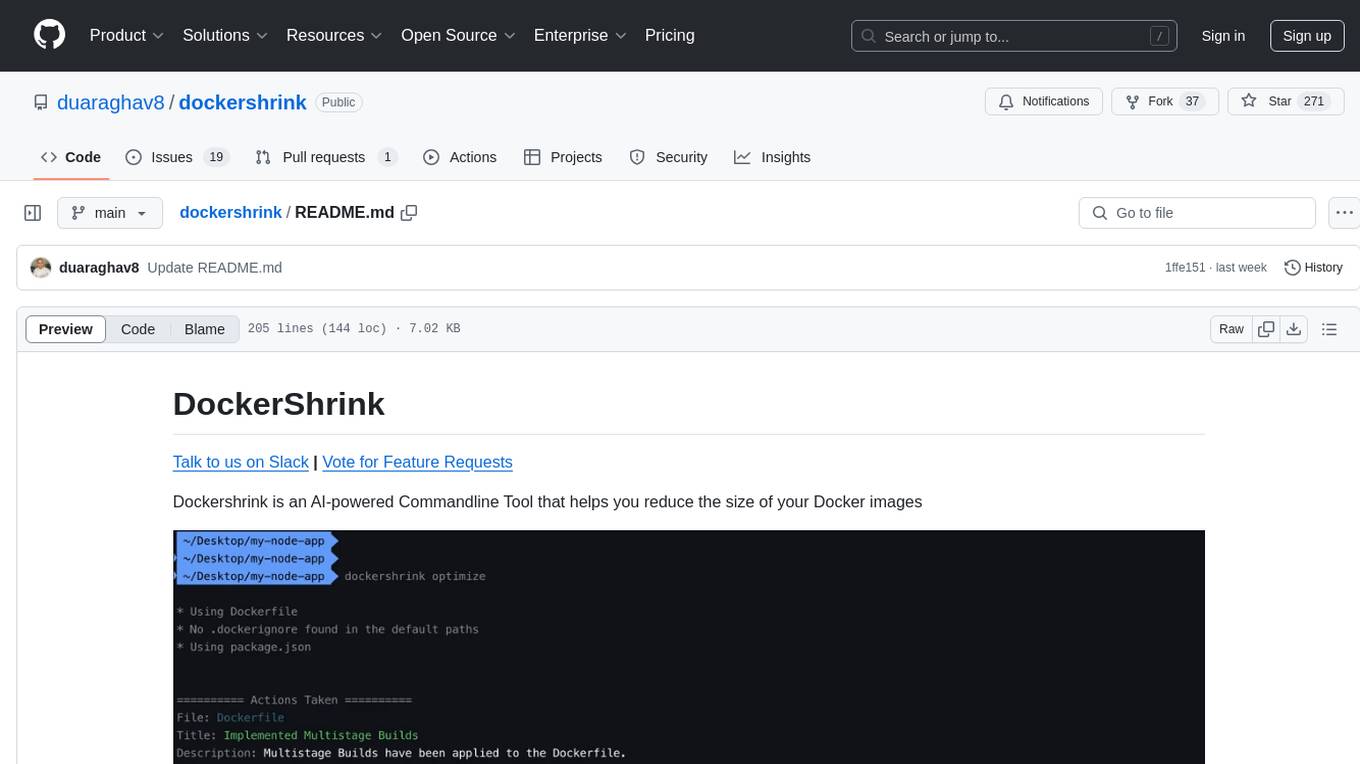
dockershrink
Dockershrink is an AI-powered Commandline Tool designed to help reduce the size of Docker images. It combines traditional Rule-based analysis with Generative AI techniques to optimize Image configurations. The tool supports NodeJS applications and aims to save costs on storage, data transfer, and build times while increasing developer productivity. By automatically applying advanced optimization techniques, Dockershrink simplifies the process for engineers and organizations, resulting in significant savings and efficiency improvements.
comfyui_LLM_party
COMFYUI LLM PARTY is a node library designed for LLM workflow development in ComfyUI, an extremely minimalist UI interface primarily used for AI drawing and SD model-based workflows. The project aims to provide a complete set of nodes for constructing LLM workflows, enabling users to easily integrate them into existing SD workflows. It features various functionalities such as API integration, local large model integration, RAG support, code interpreters, online queries, conditional statements, looping links for large models, persona mask attachment, and tool invocations for weather lookup, time lookup, knowledge base, code execution, web search, and single-page search. Users can rapidly develop web applications using API + Streamlit and utilize LLM as a tool node. Additionally, the project includes an omnipotent interpreter node that allows the large model to perform any task, with recommendations to use the 'show_text' node for display output.
openui
OpenUI is a tool designed to simplify the process of building UI components by allowing users to describe UI using their imagination and see it rendered live. It supports converting HTML to React, Svelte, Web Components, etc. The tool is open source and aims to make UI development fun, fast, and flexible. It integrates with various AI services like OpenAI, Groq, Gemini, Anthropic, Cohere, and Mistral, providing users with the flexibility to use different models. OpenUI also supports LiteLLM for connecting to various LLM services and allows users to create custom proxy configs. The tool can be run locally using Docker or Python, and it offers a development environment for quick setup and testing.

jaison-core
J.A.I.son is a Python project designed for generating responses using various components and applications. It requires specific plugins like STT, T2T, TTSG, and TTSC to function properly. Users can customize responses, voice, and configurations. The project provides a Discord bot, Twitch events and chat integration, and VTube Studio Animation Hotkeyer. It also offers features for managing conversation history, training AI models, and monitoring conversations.

ultimate-rvc
Ultimate RVC is an extension of AiCoverGen, offering new features and improvements for generating audio content using RVC. It is designed for users looking to integrate singing functionality into AI assistants/chatbots/vtubers, create character voices for songs or books, and train voice models. The tool provides easy setup, voice conversion enhancements, TTS functionality, voice model training suite, caching system, UI improvements, and support for custom configurations. It is available for local and Google Colab use, with a PyPI package for easy access. The tool also offers CLI usage and customization through environment variables.

azure-search-openai-javascript
This sample demonstrates a few approaches for creating ChatGPT-like experiences over your own data using the Retrieval Augmented Generation pattern. It uses Azure OpenAI Service to access the ChatGPT model (gpt-35-turbo), and Azure AI Search for data indexing and retrieval.

cog-comfyui
Cog-ComfyUI is a tool designed to run ComfyUI workflows on Replicate. It allows users to easily integrate their own workflows into their app or website using the Replicate API. The tool includes popular model weights and custom nodes, with the option to request more custom nodes or models. Users can get their API JSON, gather input files, and use custom LoRAs from CivitAI or HuggingFace. Additionally, users can run their workflows and set up their own dedicated instances for better performance and control. The tool provides options for private deployments, forking using Cog, or creating new models from the train tab on Replicate. It also offers guidance on developing locally and running the Web UI from a Cog container.
For similar tasks
reai-ghidra
The RevEng.AI Ghidra Plugin by RevEng.ai allows users to interact with their API within Ghidra for Binary Code Similarity analysis to aid in Reverse Engineering stripped binaries. Users can upload binaries, rename functions above a confidence threshold, and view similar functions for a selected function.
reai-ida
RevEng.AI IDA Pro Plugin is a tool that integrates with the RevEng.AI platform to provide various features such as uploading binaries for analysis, downloading analysis logs, renaming function names, generating AI summaries, synchronizing functions between local analysis and the platform, and configuring plugin settings. Users can upload files for analysis, synchronize function names, rename functions, generate block summaries, and explain function behavior using this plugin. The tool requires IDA Pro v8.0 or later with Python 3.9 and higher. It relies on the 'reait' package for functionality.
For similar jobs
last_layer
last_layer is a security library designed to protect LLM applications from prompt injection attacks, jailbreaks, and exploits. It acts as a robust filtering layer to scrutinize prompts before they are processed by LLMs, ensuring that only safe and appropriate content is allowed through. The tool offers ultra-fast scanning with low latency, privacy-focused operation without tracking or network calls, compatibility with serverless platforms, advanced threat detection mechanisms, and regular updates to adapt to evolving security challenges. It significantly reduces the risk of prompt-based attacks and exploits but cannot guarantee complete protection against all possible threats.
aircrack-ng
Aircrack-ng is a comprehensive suite of tools designed to evaluate the security of WiFi networks. It covers various aspects of WiFi security, including monitoring, attacking (replay attacks, deauthentication, fake access points), testing WiFi cards and driver capabilities, and cracking WEP and WPA PSK. The tools are command line-based, allowing for extensive scripting and have been utilized by many GUIs. Aircrack-ng primarily works on Linux but also supports Windows, macOS, FreeBSD, OpenBSD, NetBSD, Solaris, and eComStation 2.

reverse-engineering-assistant
ReVA (Reverse Engineering Assistant) is a project aimed at building a disassembler agnostic AI assistant for reverse engineering tasks. It utilizes a tool-driven approach, providing small tools to the user to empower them in completing complex tasks. The assistant is designed to accept various inputs, guide the user in correcting mistakes, and provide additional context to encourage exploration. Users can ask questions, perform tasks like decompilation, class diagram generation, variable renaming, and more. ReVA supports different language models for online and local inference, with easy configuration options. The workflow involves opening the RE tool and program, then starting a chat session to interact with the assistant. Installation includes setting up the Python component, running the chat tool, and configuring the Ghidra extension for seamless integration. ReVA aims to enhance the reverse engineering process by breaking down actions into small parts, including the user's thoughts in the output, and providing support for monitoring and adjusting prompts.
AutoAudit
AutoAudit is an open-source large language model specifically designed for the field of network security. It aims to provide powerful natural language processing capabilities for security auditing and network defense, including analyzing malicious code, detecting network attacks, and predicting security vulnerabilities. By coupling AutoAudit with ClamAV, a security scanning platform has been created for practical security audit applications. The tool is intended to assist security professionals with accurate and fast analysis and predictions to combat evolving network threats.
aif
Arno's Iptables Firewall (AIF) is a single- & multi-homed firewall script with DSL/ADSL support. It is a free software distributed under the GNU GPL License. The script provides a comprehensive set of configuration files and plugins for setting up and managing firewall rules, including support for NAT, load balancing, and multirouting. It offers detailed instructions for installation and configuration, emphasizing security best practices and caution when modifying settings. The script is designed to protect against hostile attacks by blocking all incoming traffic by default and allowing users to configure specific rules for open ports and network interfaces.

watchtower
AIShield Watchtower is a tool designed to fortify the security of AI/ML models and Jupyter notebooks by automating model and notebook discoveries, conducting vulnerability scans, and categorizing risks into 'low,' 'medium,' 'high,' and 'critical' levels. It supports scanning of public GitHub repositories, Hugging Face repositories, AWS S3 buckets, and local systems. The tool generates comprehensive reports, offers a user-friendly interface, and aligns with industry standards like OWASP, MITRE, and CWE. It aims to address the security blind spots surrounding Jupyter notebooks and AI models, providing organizations with a tailored approach to enhancing their security efforts.
Academic_LLM_Sec_Papers
Academic_LLM_Sec_Papers is a curated collection of academic papers related to LLM Security Application. The repository includes papers sorted by conference name and published year, covering topics such as large language models for blockchain security, software engineering, machine learning, and more. Developers and researchers are welcome to contribute additional published papers to the list. The repository also provides information on listed conferences and journals related to security, networking, software engineering, and cryptography. The papers cover a wide range of topics including privacy risks, ethical concerns, vulnerabilities, threat modeling, code analysis, fuzzing, and more.
DeGPT
DeGPT is a tool designed to optimize decompiler output using Large Language Models (LLM). It requires manual installation of specific packages and setting up API key for OpenAI. The tool provides functionality to perform optimization on decompiler output by running specific scripts.