
ultravox
A fast multimodal LLM for real-time voice
Stars: 870

Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.
README:

Latest News
- 2024/08 — Ultravox 0.4 available
- 2024/08 — Ultravox 0.3 available
- 2024/08 — Preview of Ultravox APIs available, more information here
Ultravox is a new kind of multimodal LLM that can understand text as well as human speech, without the need for a separate Audio Speech Recognition (ASR) stage. Building on research like AudioLM, SeamlessM4T, Gazelle, SpeechGPT, and others, we've extended Meta's Llama 3 model with a multimodal projector that converts audio directly into the high-dimensional space used by Llama 3. This direct coupling allows Ultravox to respond much more quickly than systems that combine separate ASR and LLM components. In the future this will also allow Ultravox to natively understand the paralinguistic cues of timing and emotion that are omnipresent in human speech.
The current version of Ultravox (v0.3), when invoked with audio content, has a time-to-first-token (TTFT) of approximately 150ms, and a tokens-per-second rate of ~60, all using a Llama 3.1 8B backbone. While quite fast, we believe there is considerable room for improvement in these numbers. We look forward to working with LLM hosting providers to deliver state-of-the-art performance for Ultravox.
Ultravox currently takes in audio and emits streaming text. As we evolve the model, we'll train it to be able to emit a stream of speech tokens that can then be converted directly into raw audio by an appropriate unit vocoder. We're interested in working with interested parties to build this functionality!
See Ultravox in action via a voice call with an AI in our app, ai.town. (Note: there's been a lot of traffic to our inference server and we've hit a few bugs. If the demo seems to be erroring out please try again in a bit.)
Join us on our Discord server here.
If you're interested in working on Ultravox fulltime, we're hiring! Check out our jobs page here.
You can try out Ultravox using your own audio content (as a WAV file) by spinning up an Ultravox instance on our partner, BaseTen: https://www.baseten.co/library/ultravox/. They offer free credits to get started.
If you're interested in running Ultravox in a real-time capacity, we offer a set of managed APIs as well. You can learn more about getting access to those here.
You can download the latest weights from the Ultravox Hugging Face page.

Read on if you're interested in training your own version of Ultravox.
Install the basic tools:
-
Homebrewis a package manager for MacOS that also mostly works for Linux. If you're running Debian or Ubuntu Linux, you can alternatively get by with apt. -
Justsimplifies our shell workflows. It frequently functions as our interface to all the other tools.
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
brew update
brew install justCreate a Python virtual environment and install the necessary packages:
just installWe're using Poetry to manage the Python virtual environment.
If you want to use Mosaic for trainig , you need to setup a few things to run on the Mosaic Platform.
- Install & login to the Mosaic CLI
pip install --upgrade mosaicml-cli
mcli init
mcli set api-key <new-value>- set API keys for tools we use:
# Huggging Face token for accessing walled data and models
mcli create secret env HF_TOKEN=hf_<your_token>
# WandB token for logging experiments
mcli create secret env WANDB_PROJECT=ultravox
mcli create secret env WANDB_API_KEY=<your_wandb_key>
# GCP credentials for accessing data (e.g. BoolQ)
# Get service_account.json file from Justin/Farzad and put it in the root dir, then
mcli create secret gcpCurrently, we keep both the LLM and the audio encoder frozen and only train the adapter/projector. Training Ultraox v0.4 took 2-3 hours on 8xH100 GPUs for 14K training steps.
Why would you want to (re-) train Ultravox? Here are a few scenarios:
-
You want to use a different LLM or audio encoder backbone.
a. In this case you need to re-train the adapter. You can use
release_config.yaml, which contains our config for our latest release, and you should be able to simply change the base LLM or encoder by specifying--text-model <hf-model-id-for-llm>and/or--audio-model <hf-model-id-for-encoder>. -
You want to improve the knowledge of the model --> NO NEED TO TRAIN ULTRAVOX!
a. We suggest to either use RAG on the fly (no training needed), or fine-tune the LLM backbone instead. You might need to re-train Ultravox if you fine-tune the LLM.
-
You want to use your own audio data, for example to add support for a new language.
a. First step, prepare your dataset: at bare minimum, the samples should have an
audioand a textcontinuationfield.b. Take a look at
ds_tool.pyandcontinuation.jinjaas well as our variant of Common Voice that was created usingds_toolto add thecontinuationfield.c. Add your dataset to the dataset mix in
release_config.yamland train.
There's no one-size fits all. If you need help you can find us on our Discord server here.
We do most of our training on the MosaicML platform and therefore most of our tooling and docs are Mosaic-related. However, you can do the same training on your own GPU without much difficulty. Here we assume you have the environment set up (run just install). You can also take a look at setup.sh
To kick off a training run you can do:
poetry run python -m ultravox.training.train --config_path ultravox/training/configs/release_config.yamlFor DDP training make sure to add torchrun. We also recommend prefetching weights in advance:
TRAIN_ARGS="--config_path ultravox/training/configs/release_config.yaml"
poetry run python -m ultravox.training.helpers.prefetch_weights $TRAIN_ARGS
poetry run torchrun --nproc_per_node=8 -m ultravox.training.train $TRAIN_ARGSFor a debug run, you can use smaller models, datasets, or batch size. Here's a config that uses TinyLlama as the LLM backbone:
poetry run python -m ultravox.training.train --config_path ultravox/training/configs/asr_tinyllama_100s.yaml --batch_size 1 --report_logs_to tensorboardWe use SimpleParsing for configs. Configs are composable (i.e. you can specify zero or many configs) and meta_config.yaml is always used as the default.
See configs_base.py to find the parameters you modify, such as the --text-model, --device, --exp-name, etc.
Before running any training jobs, you need to setup your SSH key in the Mosaic Platform: https://docs.mosaicml.com/projects/mcli/en/latest/resources/secrets/ssh.html#page-secrets-ssh
## Create a new SSH key and add it to the Mosaic Platform
# ssh-keygen -f ~/.ssh/mclid_id_rsa
## add the **public** key to Github
# mcli create secret ssh ~/.ssh/mclid_id_rsa
mcli run -f mcloud.yaml --followOther useful commands:
mcli get clusters
mcli util r7z2
mcli get runs
mcli get runs --cluster r7z2
mcli run -f mcloud.yaml --followFor interactive runs you can use:
just mcloud --image mosaicml/composer:latest --max-duration 1IMPORTANT: Make sure to monitor your jobs and stop the machine when you're done with any job, specially interactive ones!
- Use
infer_tool.py --json > fileto create a jsonl output from a given model/dataset combo, where each line contains two values: question and answer. - Use
eval_tool.py -f fileto evaluate the jsonl file, which will produce an average score for the model on the dataset.
The Justfile is a good resource for finding popular commands. Here are a few:
just update # update dependencies
just format # run formatting (black, isort, autoflake)
just test # run tests
just python # activate venv and run pythonFor Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ultravox
Similar Open Source Tools
ultravox
Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.

Open-LLM-VTuber
Open-LLM-VTuber is a project in early stages of development that allows users to interact with Large Language Models (LLM) using voice commands and receive responses through a Live2D talking face. The project aims to provide a minimum viable prototype for offline use on macOS, Linux, and Windows, with features like long-term memory using MemGPT, customizable LLM backends, speech recognition, and text-to-speech providers. Users can configure the project to chat with LLMs, choose different backend services, and utilize Live2D models for visual representation. The project supports perpetual chat, offline operation, and GPU acceleration on macOS, addressing limitations of existing solutions on macOS.

lovelaice
Lovelaice is an AI-powered assistant for your terminal and editor. It can run bash commands, search the Internet, answer general and technical questions, complete text files, chat casually, execute code in various languages, and more. Lovelaice is configurable with API keys and LLM models, and can be used for a wide range of tasks requiring bash commands or coding assistance. It is designed to be versatile, interactive, and helpful for daily tasks and projects.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.
maxheadbox
Max Headbox is an open-source voice-activated LLM Agent designed to run on a Raspberry Pi. It can be configured to execute a variety of tools and perform actions. The project requires specific hardware and software setups, and provides detailed instructions for installation, configuration, and usage. Users can create custom tools by making JavaScript modules and backend API handlers. The project acknowledges the use of various open-source projects and resources in its development.

Mapperatorinator
Mapperatorinator is a multi-model framework that uses spectrogram inputs to generate fully featured osu! beatmaps for all gamemodes and assist modding beatmaps. The project aims to automatically generate rankable quality osu! beatmaps from any song with a high degree of customizability. The tool is built upon osuT5 and osu-diffusion, utilizing GPU compute and instances on vast.ai for development. Users can responsibly use AI in their beatmaps with this tool, ensuring disclosure of AI usage. Installation instructions include cloning the repository, creating a virtual environment, and installing dependencies. The tool offers a Web GUI for user-friendly experience and a Command-Line Inference option for advanced configurations. Additionally, an Interactive CLI script is available for terminal-based workflow with guided setup. The tool provides generation tips and features MaiMod, an AI-driven modding tool for osu! beatmaps. Mapperatorinator tokenizes beatmaps, utilizes a model architecture based on HF Transformers Whisper model, and offers multitask training format for conditional generation. The tool ensures seamless long generation, refines coordinates with diffusion, and performs post-processing for improved beatmap quality. Super timing generator enhances timing accuracy, and LoRA fine-tuning allows adaptation to specific styles or gamemodes. The project acknowledges credits and related works in the osu! community.
polis
Polis is an AI powered sentiment gathering platform that offers a more organic approach than surveys and requires less effort than focus groups. It provides a comprehensive wiki, main deployment at https://pol.is, discussions, issue tracking, and project board for users. Polis can be set up using Docker infrastructure and offers various commands for building and running containers. Users can test their instance, update the system, and deploy Polis for production. The tool also provides developer conveniences for code reloading, type checking, and database connections. Additionally, Polis supports end-to-end browser testing using Cypress and offers troubleshooting tips for common Docker and npm issues.
kobold_assistant
Kobold-Assistant is a fully offline voice assistant interface to KoboldAI's large language model API. It can work online with the KoboldAI horde and online speech-to-text and text-to-speech models. The assistant, called Jenny by default, uses the latest coqui 'jenny' text to speech model and openAI's whisper speech recognition. Users can customize the assistant name, speech-to-text model, text-to-speech model, and prompts through configuration. The tool requires system packages like GCC, portaudio development libraries, and ffmpeg, along with Python >=3.7, <3.11, and runs on Ubuntu/Debian systems. Users can interact with the assistant through commands like 'serve' and 'list-mics'.

gpt-subtrans
GPT-Subtrans is an open-source subtitle translator that utilizes large language models (LLMs) as translation services. It supports translation between any language pairs that the language model supports. Note that GPT-Subtrans requires an active internet connection, as subtitles are sent to the provider's servers for translation, and their privacy policy applies.
openui
OpenUI is a tool designed to simplify the process of building UI components by allowing users to describe UI using their imagination and see it rendered live. It supports converting HTML to React, Svelte, Web Components, etc. The tool is open source and aims to make UI development fun, fast, and flexible. It integrates with various AI services like OpenAI, Groq, Gemini, Anthropic, Cohere, and Mistral, providing users with the flexibility to use different models. OpenUI also supports LiteLLM for connecting to various LLM services and allows users to create custom proxy configs. The tool can be run locally using Docker or Python, and it offers a development environment for quick setup and testing.

ezkl
EZKL is a library and command-line tool for doing inference for deep learning models and other computational graphs in a zk-snark (ZKML). It enables the following workflow: 1. Define a computational graph, for instance a neural network (but really any arbitrary set of operations), as you would normally in pytorch or tensorflow. 2. Export the final graph of operations as an .onnx file and some sample inputs to a .json file. 3. Point ezkl to the .onnx and .json files to generate a ZK-SNARK circuit with which you can prove statements such as: > "I ran this publicly available neural network on some private data and it produced this output" > "I ran my private neural network on some public data and it produced this output" > "I correctly ran this publicly available neural network on some public data and it produced this output" In the backend we use the collaboratively-developed Halo2 as a proof system. The generated proofs can then be verified with much less computational resources, including on-chain (with the Ethereum Virtual Machine), in a browser, or on a device.

civitai
Civitai is a platform where people can share their stable diffusion models (textual inversions, hypernetworks, aesthetic gradients, VAEs, and any other crazy stuff people do to customize their AI generations), collaborate with others to improve them, and learn from each other's work. The platform allows users to create an account, upload their models, and browse models that have been shared by others. Users can also leave comments and feedback on each other's models to facilitate collaboration and knowledge sharing.
AlwaysReddy
AlwaysReddy is a simple LLM assistant with no UI that you interact with entirely using hotkeys. It can easily read from or write to your clipboard, and voice chat with you via TTS and STT. Here are some of the things you can use AlwaysReddy for: - Explain a new concept to AlwaysReddy and have it save the concept (in roughly your words) into a note. - Ask AlwaysReddy "What is X called?" when you know how to roughly describe something but can't remember what it is called. - Have AlwaysReddy proofread the text in your clipboard before you send it. - Ask AlwaysReddy "From the comments in my clipboard, what do the r/LocalLLaMA users think of X?" - Quickly list what you have done today and get AlwaysReddy to write a journal entry to your clipboard before you shutdown the computer for the day.
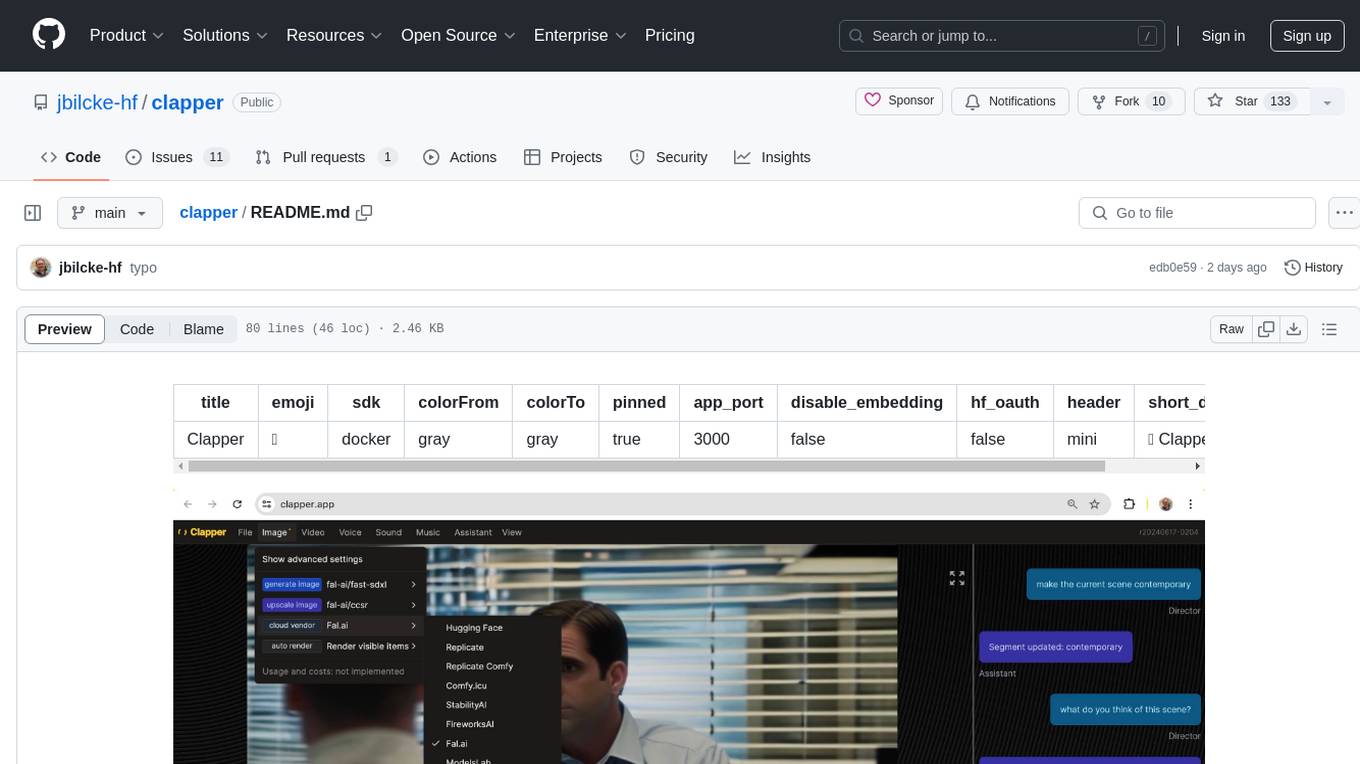
clapper
Clapper is an open-source AI story visualization tool that can interpret screenplays and render them into storyboards, videos, voice, sound, and music. It is currently in early development stages and not recommended for general use due to some non-functional features and lack of tutorials. A public alpha version is available on Hugging Face's platform. Users can sponsor specific features through bounties and developers can contribute to the project under the GPL v3 license. The tool lacks automated tests and code conventions like Prettier or a Linter.

ray-llm
RayLLM (formerly known as Aviary) is an LLM serving solution that makes it easy to deploy and manage a variety of open source LLMs, built on Ray Serve. It provides an extensive suite of pre-configured open source LLMs, with defaults that work out of the box. RayLLM supports Transformer models hosted on Hugging Face Hub or present on local disk. It simplifies the deployment of multiple LLMs, the addition of new LLMs, and offers unique autoscaling support, including scale-to-zero. RayLLM fully supports multi-GPU & multi-node model deployments and offers high performance features like continuous batching, quantization and streaming. It provides a REST API that is similar to OpenAI's to make it easy to migrate and cross test them. RayLLM supports multiple LLM backends out of the box, including vLLM and TensorRT-LLM.

llm-subtrans
LLM-Subtrans is an open source subtitle translator that utilizes LLMs as a translation service. It supports translating subtitles between any language pairs supported by the language model. The application offers multiple subtitle formats support through a pluggable system, including .srt, .ssa/.ass, and .vtt files. Users can choose to use the packaged release for easy usage or install from source for more control over the setup. The tool requires an active internet connection as subtitles are sent to translation service providers' servers for translation.
For similar tasks
ultravox
Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.
Awesome-Audio-LLM
Awesome-Audio-LLM is a repository dedicated to various models and methods related to audio and language processing. It includes a wide range of research papers and models developed by different institutions and authors. The repository covers topics such as bridging audio and language, speech emotion recognition, voice assistants, and more. It serves as a comprehensive resource for those interested in the intersection of audio and language processing.

LocalAI
LocalAI is a free and open-source OpenAI alternative that acts as a drop-in replacement REST API compatible with OpenAI (Elevenlabs, Anthropic, etc.) API specifications for local AI inferencing. It allows users to run LLMs, generate images, audio, and more locally or on-premises with consumer-grade hardware, supporting multiple model families and not requiring a GPU. LocalAI offers features such as text generation with GPTs, text-to-audio, audio-to-text transcription, image generation with stable diffusion, OpenAI functions, embeddings generation for vector databases, constrained grammars, downloading models directly from Huggingface, and a Vision API. It provides a detailed step-by-step introduction in its Getting Started guide and supports community integrations such as custom containers, WebUIs, model galleries, and various bots for Discord, Slack, and Telegram. LocalAI also offers resources like an LLM fine-tuning guide, instructions for local building and Kubernetes installation, projects integrating LocalAI, and a how-tos section curated by the community. It encourages users to cite the repository when utilizing it in downstream projects and acknowledges the contributions of various software from the community.
local_multimodal_ai_chat
Local Multimodal AI Chat is a hands-on project that teaches you how to build a multimodal chat application. It integrates different AI models to handle audio, images, and PDFs in a single chat interface. This project is perfect for anyone interested in AI and software development who wants to gain practical experience with these technologies.

openai-cf-workers-ai
OpenAI for Workers AI is a simple, quick, and dirty implementation of OpenAI's API on Cloudflare's new Workers AI platform. It allows developers to use the OpenAI SDKs with the new LLMs without having to rewrite all of their code. The API currently supports completions, chat completions, audio transcription, embeddings, audio translation, and image generation. It is not production ready but will be semi-regularly updated with new features as they roll out to Workers AI.

ruby-openai
Use the OpenAI API with Ruby! 🤖🩵 Stream text with GPT-4, transcribe and translate audio with Whisper, or create images with DALL·E... Hire me | 🎮 Ruby AI Builders Discord | 🐦 Twitter | 🧠 Anthropic Gem | 🚂 Midjourney Gem ## Table of Contents * Ruby OpenAI * Table of Contents * Installation * Bundler * Gem install * Usage * Quickstart * With Config * Custom timeout or base URI * Extra Headers per Client * Logging * Errors * Faraday middleware * Azure * Ollama * Counting Tokens * Models * Examples * Chat * Streaming Chat * Vision * JSON Mode * Functions * Edits * Embeddings * Batches * Files * Finetunes * Assistants * Threads and Messages * Runs * Runs involving function tools * Image Generation * DALL·E 2 * DALL·E 3 * Image Edit * Image Variations * Moderations * Whisper * Translate * Transcribe * Speech * Errors * Development * Release * Contributing * License * Code of Conduct

deepgram-js-sdk
Deepgram JavaScript SDK. Power your apps with world-class speech and Language AI models.
Whisper-WebUI
Whisper-WebUI is a Gradio-based browser interface for Whisper, serving as an Easy Subtitle Generator. It supports generating subtitles from various sources such as files, YouTube, and microphone. The tool also offers speech-to-text and text-to-text translation features, utilizing Facebook NLLB models and DeepL API. Users can translate subtitle files from other languages to English and vice versa. The project integrates faster-whisper for improved VRAM usage and transcription speed, providing efficiency metrics for optimized whisper models. Additionally, users can choose from different Whisper models based on size and language requirements.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.