Best AI tools for< Speech Scientist >
Infographic
20 - AI tool Sites
SpeechMap.AI
SpeechMap.AI is a public research project that explores the boundaries of AI-generated speech. It focuses on testing how language models respond to sensitive and controversial prompts across different providers, countries, and topics. The platform aims to reveal the invisible boundaries of AI speech by analyzing what models avoid, refuse, or shut down. By measuring and comparing AI models' responses, SpeechMap.AI sheds light on the evolving landscape of AI-generated speech and its impact on public expression.
pyannote AI Speaker Intelligence Platform
The pyannote AI Speaker Intelligence Platform is an advanced AI tool designed for developers to detect, segment, label, and separate speakers in any language. It offers state-of-the-art speaker diarization models that accurately identify speakers in audio recordings, providing valuable insights and improving productivity. With optimized AI models, the platform saves time, effort, and money by delivering top-tier performance. The tool is language agnostic and offers advanced features such as speaker partitioning, identification, overlapping speech detection, voice activity detection, speaker separation, and confidence scoring.
AssemblyAI
AssemblyAI is an industry-leading Speech AI tool that offers powerful SpeechAI models for accurate transcription and understanding of speech. It provides breakthrough speech-to-text models, real-time captioning, and advanced speech understanding capabilities. AssemblyAI is designed to help developers build world-class products with unmatched accuracy and transformative audio intelligence.
Deepgram
Deepgram is a powerful API platform that provides developers with tools for building speech-to-text, text-to-speech, and intelligence applications. With Deepgram, developers can easily add speech recognition, text-to-speech, and other AI-powered features to their applications.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio and video files using domain-specific speech recognition technology. The application provides various features to transcribe, edit, and export audio content in different formats. With state-of-the-art deep neural network models, SpeechText.AI achieves close to human accuracy in converting audio to text. The tool is widely used for transcription of interviews, medical data, conference calls, podcasts, and more, catering to various industries such as finance, healthcare, legal, and HR.
Picovoice
Picovoice is an on-device Voice AI and local LLM platform designed for enterprises. It offers a range of voice AI and LLM solutions, including speech-to-text, noise suppression, speaker recognition, speech-to-index, wake word detection, and more. Picovoice empowers developers to build virtual assistants and AI-powered products with compliance, reliability, and scalability in mind. The platform allows enterprises to process data locally without relying on third-party remote servers, ensuring data privacy and security. With a focus on cutting-edge AI technology, Picovoice enables users to stay ahead of the curve and adapt quickly to changing customer needs.
VoxSigma
Vocapia Research develops leading-edge, multilingual speech processing technologies exploiting AI methods such as machine learning. These technologies enable large vocabulary continuous speech recognition, automatic audio segmentation, language identification, speaker diarization and audio-text synchronization. Vocapia's VoxSigma™ speech-to-text software suite delivers state-of-the-art performance in many languages for a variety of audio data types, including broadcast data, parliamentary hearings and conversational data.
AssemblyAI
AssemblyAI is an AI tool that provides AI models for transcribing and understanding speech. Their products include Speech-to-Text Streaming, Speech Understanding, and more. AssemblyAI's research focuses on building new AI systems that can understand human speech with superhuman abilities. They offer industry-leading accuracy, low Word Error Rate (WER), and advanced capabilities like speaker identification and multilingual speech recognition. The platform is designed to be easy to use, scalable, and cost-effective for developers. AssemblyAI is trusted by top Voice AI companies for launching innovative products quickly and efficiently.
AppTek
AppTek is a global leader in artificial intelligence (AI) and machine learning (ML) technologies for automatic speech recognition (ASR), neural machine translation (NMT), natural language processing/understanding (NLP/U) and text-to-speech (TTS) technologies. The AppTek platform delivers industry-leading solutions for organizations across a breadth of global markets such as media and entertainment, call centers, government, enterprise business, and more. Built by scientists and research engineers who are recognized among the best in the world, AppTek’s solutions cover a wide array of languages/ dialects, channels, domains and demographics.
Resemble AI
Resemble AI is an AI-powered platform that offers AI Voice Generator and Deepfake Detection services for enterprises. The platform provides features such as Generative AI Voice Cloning, Text to Speech, Speech to Speech conversion, Multilingual support, Audio Editing, and Open Source Voice Cloning AI Model. Resemble AI focuses on delivering state-of-the-art AI models for voice generation and deepfake detection, ensuring security and trust for its users.
Globose Technology Solutions
Globose Technology Solutions Pvt Ltd (GTS) is an AI data collection company that provides various datasets such as image datasets, video datasets, text datasets, speech datasets, etc., to train machine learning models. They offer premium data collection services with a human touch, aiming to refine AI vision and propel AI forward. With over 25+ years of experience, they specialize in data management, annotation, and effective data collection techniques for AI/ML. The company focuses on unlocking high-quality data, understanding AI's transformative impact, and ensuring data accuracy as the backbone of reliable AI.

Columns
Columns is an AI tool that automates data storytelling. It enables users to create compelling narratives and visualizations from their data without the need for manual intervention. With Columns, users can easily transform raw data into engaging stories, making data analysis more accessible and impactful. The tool leverages advanced algorithms to analyze data sets, identify patterns, and generate insights that can be presented in a visually appealing format. Columns streamlines the process of data storytelling, saving users time and effort while enhancing the effectiveness of their data-driven communication.
Ragobble
Ragobble is an audio to LLM data tool that allows you to easily convert audio files into text data that can be used to train large language models (LLMs). With Ragobble, you can quickly and easily create high-quality training data for your LLM projects.
Reka
Reka is a cutting-edge AI application offering next-generation multimodal AI models that empower agents to see, hear, and speak. Their flagship model, Reka Core, competes with industry leaders like OpenAI and Google, showcasing top performance across various evaluation metrics. Reka's models are natively multimodal, capable of tasks such as generating textual descriptions from videos, translating speech, answering complex questions, writing code, and more. With advanced reasoning capabilities, Reka enables users to solve a wide range of complex problems. The application provides end-to-end support for 32 languages, image and video comprehension, multilingual understanding, tool use, function calling, and coding, as well as speech input and output.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing. The company's products and services are used by businesses and governments around the world to develop and deploy AI applications. NVIDIA's AI platform includes hardware, software, and tools that make it easy to build and train AI models. The company also offers a range of cloud-based AI services that make it easy to deploy and manage AI applications. NVIDIA's AI platform is used in a wide variety of industries, including healthcare, manufacturing, retail, and transportation. The company's AI technology is helping to improve the efficiency and accuracy of a wide range of tasks, from medical diagnosis to product design.
Future Tools
Future Tools is a website that collects and organizes AI tools. It provides a comprehensive list of AI tools categorized into various domains, including AI detection, aggregators, avatar chat, copywriting, finance, gaming, generative art, generative code, generative video, image improvement, image scanning, inspiration, marketing, motion capture, music, podcasting, productivity, prompt guides, research, self-improvement, social media, speech-to-text, text-to-speech, text-to-video, translation, video editing, and voice modulation. The website also offers a search bar to help users find specific tools based on their needs.
Association for the Advancement of Artificial Intelligence
The Association for the Advancement of Artificial Intelligence (AAAI) is a scientific society dedicated to advancing the scientific understanding of the mechanisms underlying thought and intelligent behavior and their embodiment in machines. AAAI's mission is to promote research in AI and to promote the use of AI technology for the benefit of humanity.

Deep Learning
The Deep Learning textbook is a resource intended to help students and practitioners enter the field of machine learning in general and deep learning in particular. The online version of the book is now complete and will remain available online for free. The deep learning textbook can now be ordered on Amazon. For up to date announcements, join our mailing list.
Aya Data
Aya Data is an AI tool that offers services such as data annotation, computer vision, natural language annotation, 3D annotation, AI data acquisition, and AI consulting. They provide cutting-edge tools to transform raw data into training datasets for AI models, deliver bespoke AI solutions for various industries, and offer AI-powered products like AyaGrow for crop management and AyaSpeech for speech-to-speech translation. Aya Data focuses on exceptional accuracy, rapid development cycles, and high performance in real-world scenarios.

OdiaGenAI
OdiaGenAI is a collaborative initiative focused on conducting research on Generative AI and Large Language Models (LLM) for the Odia Language. The project aims to leverage AI technology to develop Generative AI and LLM-based solutions for the overall development of Odisha and the Odia language through collaboration among Odia technologists. The initiative offers pre-trained models, codes, and datasets for non-commercial and research purposes, with a focus on building language models for Indic languages like Odia and Bengali.
17 - Open Source Tools

VoiceStreamAI
VoiceStreamAI is a Python 3-based server and JavaScript client solution for near-realtime audio streaming and transcription using WebSocket. It employs Huggingface's Voice Activity Detection (VAD) and OpenAI's Whisper model for accurate speech recognition. The system features real-time audio streaming, modular design for easy integration of VAD and ASR technologies, customizable audio chunk processing strategies, support for multilingual transcription, and secure sockets support. It uses a factory and strategy pattern implementation for flexible component management and provides a unit testing framework for robust development.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.

RVC_CLI
RVC_CLI is a command line interface tool for retrieval-based voice conversion. It provides functionalities for installation, getting started, inference, training, UVR, additional features, and API integration. Users can perform tasks like single inference, batch inference, TTS inference, preprocess dataset, extract features, start training, generate index file, model extract, model information, model blender, launch TensorBoard, download models, audio analyzer, and prerequisites download. The tool is built on various projects like ContentVec, HIFIGAN, audio-slicer, python-audio-separator, RMVPE, FCPE, VITS, So-Vits-SVC, Harmonify, and others.
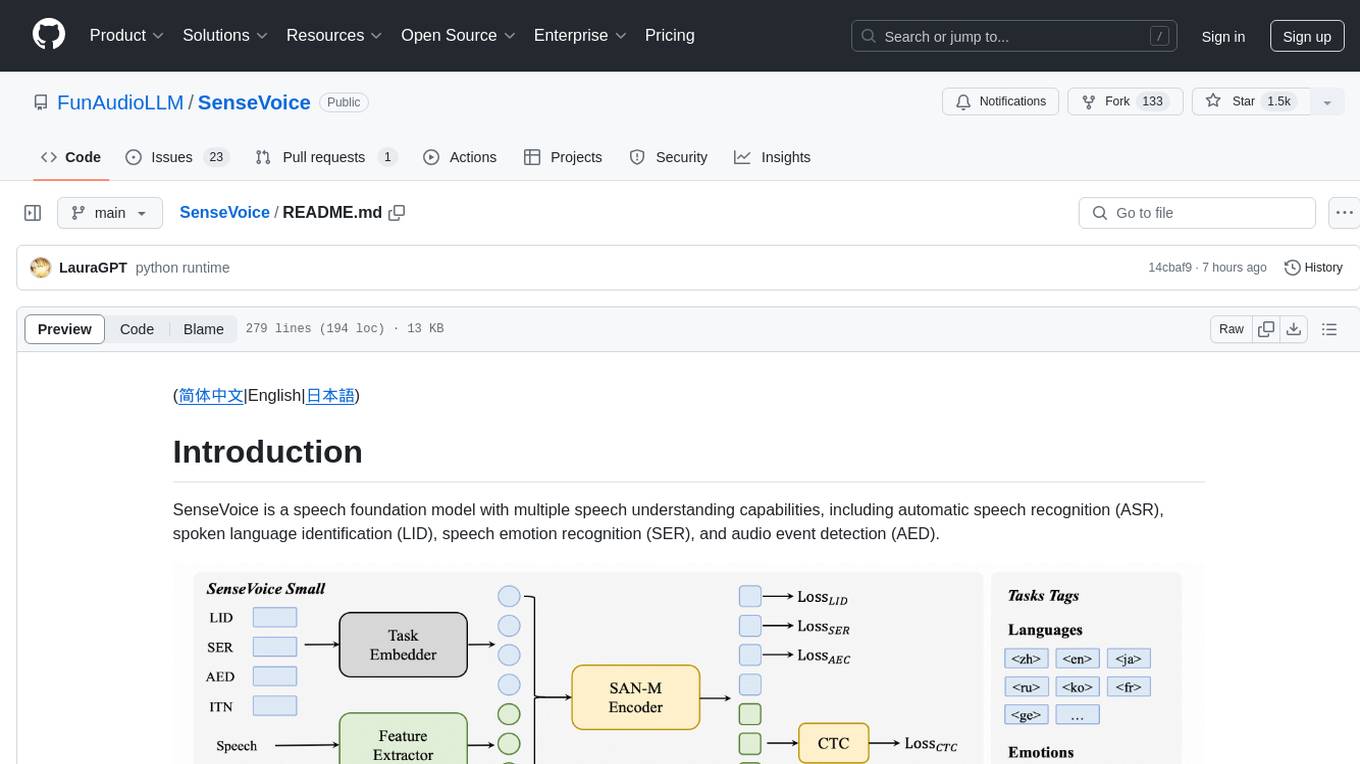
SenseVoice
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.
awesome-khmer-language
Awesome Khmer Language is a comprehensive collection of resources for the Khmer language, including tools, datasets, research papers, projects/models, blogs/slides, and miscellaneous items. It covers a wide range of topics related to Khmer language processing, such as character normalization, word segmentation, part-of-speech tagging, optical character recognition, text-to-speech, and more. The repository aims to support the development of natural language processing applications for the Khmer language by providing a diverse set of resources and tools for researchers and developers.

ultravox
Ultravox is a fast multimodal Language Model (LLM) that can understand both text and human speech in real-time without the need for a separate Audio Speech Recognition (ASR) stage. By extending Meta's Llama 3 model with a multimodal projector, Ultravox converts audio directly into a high-dimensional space used by Llama 3, enabling quick responses and potential understanding of paralinguistic cues like timing and emotion in human speech. The current version (v0.3) has impressive speed metrics and aims for further enhancements. Ultravox currently converts audio to streaming text and plans to emit speech tokens for direct audio conversion. The tool is open for collaboration to enhance this functionality.

MooER
MooER (摩耳) is an LLM-based speech recognition and translation model developed by Moore Threads. It allows users to transcribe speech into text (ASR) and translate speech into other languages (AST) in an end-to-end manner. The model was trained using 5K hours of data and is now also available with an 80K hours version. MooER is the first LLM-based speech model trained and inferred using domestic GPUs. The repository includes pretrained models, inference code, and a Gradio demo for a better user experience.
speech-to-speech
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.

AudioLLM
AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.

VoiceBench
VoiceBench is a repository containing code and data for benchmarking LLM-Based Voice Assistants. It includes a leaderboard with rankings of various voice assistant models based on different evaluation metrics. The repository provides setup instructions, datasets, evaluation procedures, and a curated list of awesome voice assistants. Users can submit new voice assistant results through the issue tracker for updates on the ranking list.

ichigo
Ichigo is a local real-time voice AI tool that uses an early fusion technique to extend a text-based LLM to have native 'listening' ability. It is an open research experiment with improved multiturn capabilities and the ability to refuse processing inaudible queries. The tool is designed for open data, open weight, on-device Siri-like functionality, inspired by Meta's Chameleon paper. Ichigo offers a web UI demo and Gradio web UI for users to interact with the tool. It has achieved enhanced MMLU scores, stronger context handling, advanced noise management, and improved multi-turn capabilities for a robust user experience.

LLMVoX
LLMVoX is a lightweight 30M-parameter, LLM-agnostic, autoregressive streaming Text-to-Speech (TTS) system designed to convert text outputs from Large Language Models into high-fidelity streaming speech with low latency. It achieves significantly lower Word Error Rate compared to speech-enabled LLMs while operating at comparable latency and speech quality. Key features include being lightweight & fast with only 30M parameters, LLM-agnostic for easy integration with existing models, multi-queue streaming for continuous speech generation, and multilingual support for easy adaptation to new languages.
VideoChat
VideoChat is a real-time voice interaction digital human tool that supports end-to-end voice solutions (GLM-4-Voice - THG) and cascade solutions (ASR-LLM-TTS-THG). Users can customize appearance and voice, support voice cloning, and achieve low first-packet delay of 3s. The tool offers various modules such as ASR, LLM, MLLM, TTS, and THG for different functionalities. It requires specific hardware and software configurations for local deployment, and provides options for weight downloads and customization of digital human appearance and voice. The tool also addresses known issues related to resource availability, video streaming optimization, and model loading.
echosharp
EchoSharp is an open-source library designed for near-real-time audio processing, orchestrating different AI models seamlessly for various audio analysis scopes. It focuses on flexibility and performance, allowing near-real-time Transcription and Translation by integrating components for Speech-to-Text and Voice Activity Detection. With interchangeable components, easy orchestration, and first-party components like Whisper.net, SileroVad, OpenAI Whisper, AzureAI SpeechServices, WebRtcVadSharp, Onnx.Whisper, and Onnx.Sherpa, EchoSharp provides efficient audio analysis solutions for developers.
20 - OpenAI Gpts
Deep Learning Master
Guiding you through the depths of deep learning with accuracy and respect.
Atatürk'ün Yolu
Atatürk'ün Söylev ve Demeçleri ile Nutuk'u kaynak kabul eden fikir paylaşma aracı
AI Speech Guide
A helpful coach for speech writing, offering constructive advice and support
Dedicated Speech-Language Pathologist
Expert Speech-Language Pathologist offering tailored medical consultations.
Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.

Detailed Speech Drafting Wizard
Crafts speeches from PowerPoint slides and reference materials, adding depth and context.
AI.EX Wedding Speech Consultant
Your partner in crafting perfect wedding speeches. Let me be your guide to writing impactful, memorable speeches for unforgettable moments.

AI Phonetics and Reading Coach with Speech
Phonetics and reading coach with interactive voice capabilities, tailored for adult beginners.

SpeechTherapist GPT
Your very own speech therapy assistant. Completely private and confidential.

Cat Translator
Your Feline Language Specialist for translating human speech to cat sounds.