
VideoChat
实时语音交互数字人,支持端到端语音方案(GLM-4-Voice - THG)和级联方案(ASR-LLM-TTS-THG)。可自定义形象与音色,无须训练,支持音色克隆,首包延迟低至3s。Real-time voice interactive digital human, supporting end-to-end voice solutions (GLM-4-Voice - THG) and cascaded solutions (ASR-LLM-TTS-THG). Customizable appearance and voice, supporting voice cloning, with initial package delay as low as 3s.
Stars: 811
VideoChat is a real-time voice interaction digital human tool that supports end-to-end voice solutions (GLM-4-Voice - THG) and cascade solutions (ASR-LLM-TTS-THG). Users can customize appearance and voice, support voice cloning, and achieve low first-packet delay of 3s. The tool offers various modules such as ASR, LLM, MLLM, TTS, and THG for different functionalities. It requires specific hardware and software configurations for local deployment, and provides options for weight downloads and customization of digital human appearance and voice. The tool also addresses known issues related to resource availability, video streaming optimization, and model loading.
README:
实时语音交互数字人,支持端到端语音方案(GLM-4-Voice - THG)和级联方案(ASR-LLM-TTS-THG)。可自定义形象与音色,支持音色克隆,首包延迟低至3s。
在线demo:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
详细的技术介绍请看这篇文章
中文简体 | English
- [x] TTS模块添加音色克隆功能
- [x] TTS模块添加edge-tts
- [x] LLM模块添加qwen本地推理
- [x] 支持GLM-4-Voice,提供ASR-LLM-TTS-THG和MLLM-THG两种生成方式
- [ ] GLM-4-Voice集成vllm推理加速
- [ ] 集成gradio-webrtc(需等待支持音视频同步),提高视频流稳定性
- ASR (Automatic Speech Recognition): FunASR
- LLM (Large Language Model): Qwen
- End-to-end MLLM (Multimodal Large Language Model): GLM-4-Voice
- TTS (Text to speech): GPT-SoVITS, CosyVoice, edge-tts
- THG (Talking Head Generation): MuseTalk
-
级联方案(ASR-LLM-TTS-THG):约8G,首包约3s(单张A100)。
-
端到端语音方案(MLLM-THG):约20G,首包约7s(单张A100)。
对于不需要使用端到端 MLLM 的开发者,可以选择仅包含级联方案的cascade_only分支。
$ git checkout cascade_only- ubuntu 22.04
- python 3.10
- CUDA 12.2
- torch 2.3.0
$ git lfs install
$ git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git
$ conda create -n metahuman python=3.10
$ conda activate metahuman
$ cd video_chat
$ pip install -r requirements.txt创空间仓库已设置git lfs追踪权重文件,如果是通过git clone https://www.modelscope.cn/studios/AI-ModelScope/video_chat.git克隆,则无需额外配置
参考这个链接
目录如下:
./weights/
├── dwpose
│ └── dw-ll_ucoco_384.pth
├── face-parse-bisent
│ ├── 79999_iter.pth
│ └── resnet18-5c106cde.pth
├── musetalk
│ ├── musetalk.json
│ └── pytorch_model.bin
├── sd-vae-ft-mse
│ ├── config.json
│ └── diffusion_pytorch_model.bin
└── whisper
└── tiny.pt
参考这个链接
在app.py中添加如下代码即可完成下载。
from modelscope import snapshot_download
snapshot_download('ZhipuAI/glm-4-voice-tokenizer',cache_dir='./weights')
snapshot_download('ZhipuAI/glm-4-voice-decoder',cache_dir='./weights')
snapshot_download('ZhipuAI/glm-4-voice-9b',cache_dir='./weights')LLM模块和TTS模块提供了多种方式,可自行选择推理方式
对于LLM模块和TTS模块,如果本地机器性能有限,可使用阿里云大模型服务平台百炼提供的Qwen API和CosyVoice API,请在app.py(line 14)中配置API-KEY。
参考这个链接完成API-KEY的获取与配置。
os.environ["DASHSCOPE_API_KEY"] = "INPUT YOUR API-KEY HERE"如果不使用API-KEY,请参考以下说明修改相关代码。
src/llm.py中提供了Qwen和Qwen_API两个类分别处理本地推理和调用API。若不使用API-KEY,有以下两种方式进行本地推理:
- 使用
Qwen完成本地推理。 -
Qwen_API默认调用API完成推理,若不使用API-KEY,还可以使用vLLM加速LLM推理。可参考如下方式安装vLLM:安装完成后,参考这个链接进行部署,使用$ git clone https://github.com/vllm-project/vllm.git $ cd vllm $ python use_existing_torch.py $ pip install -r requirements-build.txt $ pip install -e . --no-build-isolation
Qwen_API(api_key="EMPTY",base_url="http://localhost:8000/v1")初始化实例调用本地推理服务。
src/tts.py中提供了GPT_SoVits_TTS和CosyVoice_API分别处理本地推理和调用API。若不使用API-KEY,可直接删除CosyVoice_API相关的内容,使用Edge_TTS调用Edge浏览器的免费TTS服务进行推理。
$ python app.py- 在
/data/video/中添加录制好的数字人形象视频 - 修改
/src/thg.py中Muse_Talk类的avatar_list,加入(形象名, bbox_shfit),关于bbox_shift的说明参考这个链接 - 在
/app.py中Gradio的avatar_name中加入数字人形象名后重新启动服务,等待完成初始化即可。
GPT-SoVits支持自定义音色。demo中可使用音色克隆功能,上传任意语音内容的参考音频后开始对话,或将音色永久添加到demo中:
- 在
/data/audio中添加音色参考音频,音频长度3-10s,命名格式为x.wav - 在
/app.py中Gradio的avatar_voice中加入音色名(命名格式为x (GPT-SoVits))后重新启动服务。 - TTS选型选择
GPT-SoVits,开始对话
-
报错无法找到某资源:按照报错提示下载对应的资源即可

-
右侧视频流播放卡顿:需等待Gradio优化Video Streaming效果
-
与模型加载相关:检查权重是否下载完整
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for VideoChat
Similar Open Source Tools
VideoChat
VideoChat is a real-time voice interaction digital human tool that supports end-to-end voice solutions (GLM-4-Voice - THG) and cascade solutions (ASR-LLM-TTS-THG). Users can customize appearance and voice, support voice cloning, and achieve low first-packet delay of 3s. The tool offers various modules such as ASR, LLM, MLLM, TTS, and THG for different functionalities. It requires specific hardware and software configurations for local deployment, and provides options for weight downloads and customization of digital human appearance and voice. The tool also addresses known issues related to resource availability, video streaming optimization, and model loading.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.
ZcChat
ZcChat is an AI desktop pet suitable for Galgame characters, featuring long-term memory, expressive actions, control over the computer, and voice functions. It utilizes Letta for AI long-term memory, Galgame-style character illustrations for more actions and expressions, and voice interaction with support for various voice synthesis tools like Vits. Users can configure characters, install Letta, set up voice synthesis and input, and control the pet to interact with the computer. The tool enhances visual and auditory experiences for users interested in AI desktop pets.
XYBotV2
XYBot V2 is a feature-rich WeChat robot framework that supports various interactive functions and gameplays. It provides AI chat, daily news updates, song requests, weather queries, and gaming functionalities like Gomoku and Warthunder player lookup. The tool is open-source and intended for learning and research purposes only, not for commercial or illegal activities. Users must comply with relevant laws and respect WeChat's copyrights and privacy. The tool's functionalities can be extended through a plugin system, allowing for dynamic loading/unloading of plugins.
AINO
AINO is a no-code system construction platform that includes front-end applications, back-end API services, and database management tools. The project structure consists of AINO-server for back-end API services, AINO-studio for front-end applications, AINO-APP for front-end client applications, docs for project documentation, start-all.sh for one-click starting of all services, stop-all.sh for stopping all services, status.sh for checking service status, and logs for service logs. AINO utilizes Hono + TypeScript + Drizzle ORM for the back-end, Next.js + React + TypeScript for the front-end, PostgreSQL for the database, and pnpm as the package manager.
himarket
HiMarket is an out-of-the-box AI open platform solution that can be used to build enterprise-level AI capability markets and developer ecosystem centers. It consists of three core components tailored to different roles within the enterprise: 1. AI open platform management backend (for administrators/operators) for easy packaging of diverse AI capabilities such as model services, MCP Server, Agent, etc., into standardized 'AI products' in API form with comprehensive documentation and examples for one-click publishing to the portal. 2. AI open platform portal (for developers/internal users) as a 'storefront' for developers to complete registration, create consumers, obtain credentials, browse and subscribe to AI products, test online, and monitor their own call status and costs clearly. 3. AI Gateway: As a subproject of the Higress community, the Higress AI Gateway carries out all AI call authentication, security, flow control, protocol conversion, and observability capabilities.
AIMedia
AIMedia is a fully automated AI media software that automatically fetches hot news, generates news, and publishes on various platforms. It supports hot news fetching from platforms like Douyin, NetEase News, Weibo, The Paper, China Daily, and Sohu News. Additionally, it enables AI-generated images for text-only news to enhance originality and reading experience. The tool is currently commercialized with plans to support video auto-generation for platform publishing in the future. It requires a minimum CPU of 4 cores or above, 8GB RAM, and supports Windows 10 or above. Users can deploy the tool by cloning the repository, modifying the configuration file, creating a virtual environment using Conda, and starting the web interface. Feedback and suggestions can be submitted through issues or pull requests.

AstrBot
AstrBot is an open-source one-stop Agentic chatbot platform and development framework. It supports large model conversations, multiple messaging platforms, Agent capabilities, plugin extensions, and WebUI for visual configuration and management of the chatbot.
LLMForEverybody
LLMForEverybody is a comprehensive repository covering various aspects of large language models (LLMs) including pre-training, architecture, optimizers, activation functions, attention mechanisms, tokenization, parallel strategies, training frameworks, deployment, fine-tuning, quantization, GPU parallelism, prompt engineering, agent design, RAG architecture, enterprise deployment challenges, evaluation metrics, and current hot topics in the field. It provides detailed explanations, tutorials, and insights into the workings and applications of LLMs, making it a valuable resource for researchers, developers, and enthusiasts interested in understanding and working with large language models.
Long-Novel-GPT
Long-Novel-GPT is a long novel generator based on large language models like GPT. It utilizes a hierarchical outline/chapter/text structure to maintain the coherence of long novels. It optimizes API calls cost through context management and continuously improves based on self or user feedback until reaching the set goal. The tool aims to continuously refine and build novel content based on user-provided initial ideas, ultimately generating long novels at the level of human writers.
FisherAI
FisherAI is a Chrome extension designed to improve learning efficiency. It supports automatic summarization, web and video translation, multi-turn dialogue, and various large language models such as gpt/azure/gemini/deepseek/mistral/groq/yi/moonshot. Users can enjoy flexible and powerful AI tools with FisherAI.
ESP32_AI_LLM
ESP32_AI_LLM is a project that uses ESP32 to connect to Xunfei Xinghuo, Dou Bao, and Tongyi Qianwen large models to achieve voice chat functions, supporting online voice wake-up, continuous conversation, music playback, and real-time display of conversation content on an external screen. The project requires specific hardware components and provides functionalities such as voice wake-up, voice conversation, convenient network configuration, music playback, volume adjustment, LED control, model switching, and screen display. Users can deploy the project by setting up Xunfei services, cloning the repository, configuring necessary parameters, installing drivers, compiling, and burning the code.
prose-polish
prose-polish is a tool for AI interaction through drag-and-drop cards, focusing on editing copy and manuscripts. It can recognize Markdown-formatted documents, automatically breaking them into paragraph cards. Users can create prefabricated prompt cards and quickly connect them to the manuscript for editing. The modified manuscript is still presented in card form, allowing users to drag it out as a new paragraph. To use it smoothly, users just need to remember one rule: 'Plug the plug into the socket!'
new-api
New API is an open-source project based on One API with additional features and improvements. It offers a new UI interface, supports Midjourney-Proxy(Plus) interface, online recharge functionality, model-based charging, channel weight randomization, data dashboard, token-controlled models, Telegram authorization login, Suno API support, Rerank model integration, and various third-party models. Users can customize models, retry channels, and configure caching settings. The deployment can be done using Docker with SQLite or MySQL databases. The project provides documentation for Midjourney and Suno interfaces, and it is suitable for AI enthusiasts and developers looking to enhance AI capabilities.
Code-Review-GPT-Gitlab
A project that utilizes large models to help with Code Review on Gitlab, aimed at improving development efficiency. The project is customized for Gitlab and is developing a Multi-Agent plugin for collaborative review. It integrates various large models for code security issues and stays updated with the latest Code Review trends. The project architecture is designed to be powerful, flexible, and efficient, with easy integration of different models and high customization for developers.
awesome-chatgpt-zh
The Awesome ChatGPT Chinese Guide project aims to help Chinese users understand and use ChatGPT. It collects various free and paid ChatGPT resources, as well as methods to communicate more effectively with ChatGPT in Chinese. The repository contains a rich collection of ChatGPT tools, applications, and examples.
For similar tasks
VideoChat
VideoChat is a real-time voice interaction digital human tool that supports end-to-end voice solutions (GLM-4-Voice - THG) and cascade solutions (ASR-LLM-TTS-THG). Users can customize appearance and voice, support voice cloning, and achieve low first-packet delay of 3s. The tool offers various modules such as ASR, LLM, MLLM, TTS, and THG for different functionalities. It requires specific hardware and software configurations for local deployment, and provides options for weight downloads and customization of digital human appearance and voice. The tool also addresses known issues related to resource availability, video streaming optimization, and model loading.
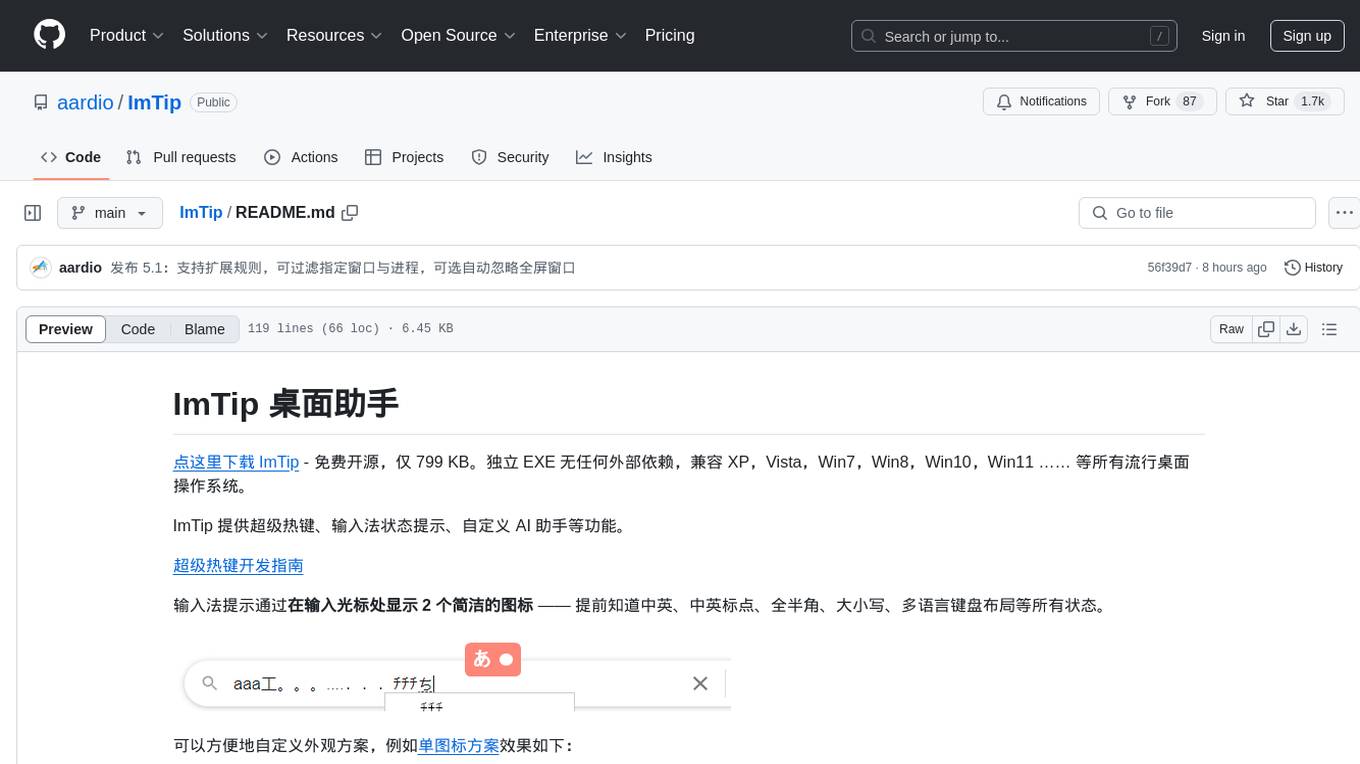
ImTip
ImTip is a lightweight desktop assistant tool that provides features such as super hotkeys, input method status prompts, and custom AI assistant. It displays concise icons at the input cursor to show various input method and keyboard status, allowing users to customize appearance schemes. With ImTip, users can easily manage input method status without cluttering the screen with the built-in status bar. The tool supports visual editing of status prompt appearance and programmable extensions for super hotkeys. ImTip has low CPU usage and offers customizable tracking speed to adjust CPU consumption. It supports various input methods and languages, making it a versatile tool for enhancing typing efficiency and accuracy.
Open-LLM-VTuber
Open-LLM-VTuber is a voice-interactive AI companion supporting real-time voice conversations and featuring a Live2D avatar. It can run offline on Windows, macOS, and Linux, offering web and desktop client modes. Users can customize appearance and persona, with rich LLM inference, text-to-speech, and speech recognition support. The project is highly customizable, extensible, and actively developed with exciting features planned. It provides privacy with offline mode, persistent chat logs, and various interaction features like voice interruption, touch feedback, Live2D expressions, pet mode, and more.
pixel-banner
Pixel Banner is a powerful Obsidian plugin that enhances note-taking by creating visually stunning headers with customizable banner images. It offers AI-generated banners, professional banner images from a store, local image support, and direct URL banners. Users can customize banner placement, appearance, display modes, and add decorative icons. The plugin provides efficient workflow with quick banner selection, command integration, and custom field names. It also offers smart organization features like folder-specific settings and image shuffling. Premium features include a token-based system for AI banners, banner history, and prompt inspiration. Enhance your Obsidian experience with beautiful, intelligent banners that make your notes visually distinctive and organized.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.
AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.