
SenseVoice
Multilingual Voice Understanding Model
Stars: 1608
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.
README:
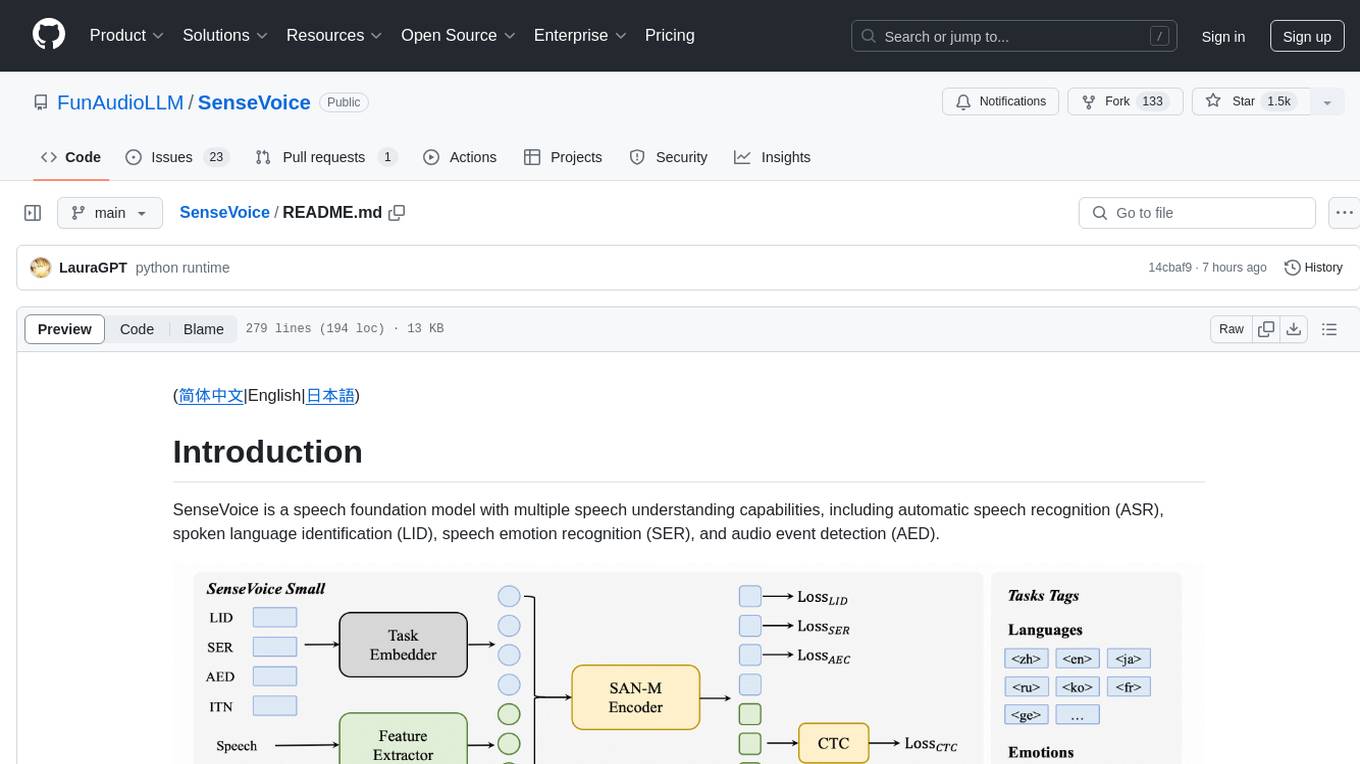
SenseVoice is a speech foundation model with multiple speech understanding capabilities, including automatic speech recognition (ASR), spoken language identification (LID), speech emotion recognition (SER), and audio event detection (AED).

Homepage | What's News | Benchmarks | Install | Usage | Community
Model Zoo: modelscope, huggingface
Online Demo: modelscope demo, huggingface space
SenseVoice focuses on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection.
- Multilingual Speech Recognition: Trained with over 400,000 hours of data, supporting more than 50 languages, the recognition performance surpasses that of the Whisper model.
-
Rich transcribe:
- Possess excellent emotion recognition capabilities, achieving and surpassing the effectiveness of the current best emotion recognition models on test data.
- Offer sound event detection capabilities, supporting the detection of various common human-computer interaction events such as bgm, applause, laughter, crying, coughing, and sneezing.
- Efficient Inference: The SenseVoice-Small model utilizes a non-autoregressive end-to-end framework, leading to exceptionally low inference latency. It requires only 70ms to process 10 seconds of audio, which is 15 times faster than Whisper-Large.
- Convenient Finetuning: Provide convenient finetuning scripts and strategies, allowing users to easily address long-tail sample issues according to their business scenarios.
- Service Deployment: Offer service deployment pipeline, supporting multi-concurrent requests, with client-side languages including Python, C++, HTML, Java, and C#, among others.
- 2024/7: Added Export Features for ONNX and libtorch, as well as Python Version Runtimes: funasr-onnx-0.4.0, funasr-torch-0.1.1
- 2024/7: The SenseVoice-Small voice understanding model is open-sourced, which offers high-precision multilingual speech recognition, emotion recognition, and audio event detection capabilities for Mandarin, Cantonese, English, Japanese, and Korean and leads to exceptionally low inference latency.
- 2024/7: The CosyVoice for natural speech generation with multi-language, timbre, and emotion control. CosyVoice excels in multi-lingual voice generation, zero-shot voice generation, cross-lingual voice cloning, and instruction-following capabilities. CosyVoice repo and CosyVoice space.
- 2024/7: FunASR is a fundamental speech recognition toolkit that offers a variety of features, including speech recognition (ASR), Voice Activity Detection (VAD), Punctuation Restoration, Language Models, Speaker Verification, Speaker Diarization and multi-talker ASR.
We compared the performance of multilingual speech recognition between SenseVoice and Whisper on open-source benchmark datasets, including AISHELL-1, AISHELL-2, Wenetspeech, LibriSpeech, and Common Voice. In terms of Chinese and Cantonese recognition, the SenseVoice-Small model has advantages.


Due to the current lack of widely-used benchmarks and methods for speech emotion recognition, we conducted evaluations across various metrics on multiple test sets and performed a comprehensive comparison with numerous results from recent benchmarks. The selected test sets encompass data in both Chinese and English, and include multiple styles such as performances, films, and natural conversations. Without finetuning on the target data, SenseVoice was able to achieve and exceed the performance of the current best speech emotion recognition models.

Furthermore, we compared multiple open-source speech emotion recognition models on the test sets, and the results indicate that the SenseVoice-Large model achieved the best performance on nearly all datasets, while the SenseVoice-Small model also surpassed other open-source models on the majority of the datasets.

Although trained exclusively on speech data, SenseVoice can still function as a standalone event detection model. We compared its performance on the environmental sound classification ESC-50 dataset against the widely used industry models BEATS and PANN. The SenseVoice model achieved commendable results on these tasks. However, due to limitations in training data and methodology, its event classification performance has some gaps compared to specialized AED models.

The SenseVoice-Small model deploys a non-autoregressive end-to-end architecture, resulting in extremely low inference latency. With a similar number of parameters to the Whisper-Small model, it infers more than 5 times faster than Whisper-Small and 15 times faster than Whisper-Large.

pip install -r requirements.txtSupports input of audio in any format and of any duration.
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = AutoModel(
model=model_dir,
trust_remote_code=True,
remote_code="./model.py",
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device="cuda:0",
)
# en
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True, #
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)Parameter Description (Click to Expand)
-
model_dir: The name of the model, or the path to the model on the local disk. -
trust_remote_code:- When
True, it means that the model's code implementation is loaded fromremote_code, which specifies the exact location of themodelcode (for example,model.pyin the current directory). It supports absolute paths, relative paths, and network URLs. - When
False, it indicates that the model's code implementation is the integrated version within FunASR. At this time, modifications made tomodel.pyin the current directory will not be effective, as the version loaded is the internal one from FunASR. For the model code, click here to view.
- When
-
vad_model: This indicates the activation of VAD (Voice Activity Detection). The purpose of VAD is to split long audio into shorter clips. In this case, the inference time includes both VAD and SenseVoice total consumption, and represents the end-to-end latency. If you wish to test the SenseVoice model's inference time separately, the VAD model can be disabled. -
vad_kwargs: Specifies the configurations for the VAD model.max_single_segment_time: denotes the maximum duration for audio segmentation by thevad_model, with the unit being milliseconds (ms). -
use_itn: Whether the output result includes punctuation and inverse text normalization. -
batch_size_s: Indicates the use of dynamic batching, where the total duration of audio in the batch is measured in seconds (s). -
merge_vad: Whether to merge short audio fragments segmented by the VAD model, with the merged length beingmerge_length_s, in seconds (s). -
ban_emo_unk: Whether to ban the output of theemo_unktoken.
If all inputs are short audios (<30s), and batch inference is needed to speed up inference efficiency, the VAD model can be removed, and batch_size can be set accordingly.
model = AutoModel(model=model_dir, trust_remote_code=True, device="cuda:0")
res = model.generate(
input=f"{model.model_path}/example/en.mp3",
cache={},
language="zh", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
batch_size=64,
)For more usage, please refer to docs
Supports input of audio in any format, with an input duration limit of 30 seconds or less.
from model import SenseVoiceSmall
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
m, kwargs = SenseVoiceSmall.from_pretrained(model=model_dir, device="cuda:0")
m.eval()
res = m.inference(
data_in=f"{kwargs['model_path']}/example/en.mp3",
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
ban_emo_unk=False,
**kwargs,
)
text = rich_transcription_postprocess(res[0][0]["text"])
print(text)ONNX and Libtorch Export
# pip3 install -U funasr funasr-onnx
from pathlib import Path
from funasr_onnx import SenseVoiceSmall
from funasr_onnx.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = SenseVoiceSmall(model_dir, batch_size=10, quantize=True)
# inference
wav_or_scp = ["{}/.cache/modelscope/hub/{}/example/en.mp3".format(Path.home(), model_dir)]
res = model(wav_or_scp, language="auto", use_itn=True)
print([rich_transcription_postprocess(i) for i in res])Note: ONNX model is exported to the original model directory.
from pathlib import Path
from funasr_torch import SenseVoiceSmall
from funasr_torch.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = SenseVoiceSmall(model_dir, batch_size=10, device="cuda:0")
wav_or_scp = ["{}/.cache/modelscope/hub/{}/example/en.mp3".format(Path.home(), model_dir)]
res = model(wav_or_scp, language="auto", use_itn=True)
print([rich_transcription_postprocess(i) for i in res])Note: Libtorch model is exported to the original model directory.
export SENSEVOICE_DEVICE=cuda:0
fastapi run --port 50000git clone https://github.com/alibaba/FunASR.git && cd FunASR
pip3 install -e ./Data examples
{"key": "YOU0000008470_S0000238_punc_itn", "text_language": "<|en|>", "emo_target": "<|NEUTRAL|>", "event_target": "<|Speech|>", "with_or_wo_itn": "<|withitn|>", "target": "Including legal due diligence, subscription agreement, negotiation.", "source": "/cpfs01/shared/Group-speech/beinian.lzr/data/industrial_data/english_all/audio/YOU0000008470_S0000238.wav", "target_len": 7, "source_len": 140}
{"key": "AUD0000001556_S0007580", "text_language": "<|en|>", "emo_target": "<|NEUTRAL|>", "event_target": "<|Speech|>", "with_or_wo_itn": "<|woitn|>", "target": "there is a tendency to identify the self or take interest in what one has got used to", "source": "/cpfs01/shared/Group-speech/beinian.lzr/data/industrial_data/english_all/audio/AUD0000001556_S0007580.wav", "target_len": 18, "source_len": 360}
Full ref to data/train_example.jsonl
Data Prepare Details
Description:
-
key: audio file unique ID -
source:path to the audio file -
source_len:number of fbank frames of the audio file -
target:transcription -
target_len:length of target -
text_language:language id of the audio file -
emo_target:emotion label of the audio file -
event_target:event label of the audio file -
with_or_wo_itn:whether includes punctuation and inverse text normalization
train_text.txt
BAC009S0764W0121 甚至出现交易几乎停滞的情况
BAC009S0916W0489 湖北一公司以员工名义贷款数十员工负债千万
asr_example_cn_en 所有只要处理 data 不管你是做 machine learning 做 deep learning 做 data analytics 做 data science 也好 scientist 也好通通都要都做的基本功啊那 again 先先对有一些>也许对
ID0012W0014 he tried to think how it could betrain_wav.scp
BAC009S0764W0121 https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/BAC009S0764W0121.wav
BAC009S0916W0489 https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/BAC009S0916W0489.wav
asr_example_cn_en https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_cn_en.wav
ID0012W0014 https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_en.wavtrain_text_language.txt
The language ids include <|zh|>、<|en|>、<|yue|>、<|ja|> and <|ko|>.
BAC009S0764W0121 <|zh|>
BAC009S0916W0489 <|zh|>
asr_example_cn_en <|zh|>
ID0012W0014 <|en|>train_emo.txt
The emotion labels include<|HAPPY|>、<|SAD|>、<|ANGRY|>、<|NEUTRAL|>、<|FEARFUL|>、<|DISGUSTED|> and <|SURPRISED|>.
BAC009S0764W0121 <|NEUTRAL|>
BAC009S0916W0489 <|NEUTRAL|>
asr_example_cn_en <|NEUTRAL|>
ID0012W0014 <|NEUTRAL|>train_event.txt
The event labels include<|BGM|>、<|Speech|>、<|Applause|>、<|Laughter|>、<|Cry|>、<|Sneeze|>、<|Breath|> and <|Cough|>.
BAC009S0764W0121 <|Speech|>
BAC009S0916W0489 <|Speech|>
asr_example_cn_en <|Speech|>
ID0012W0014 <|Speech|>Command
# generate train.jsonl and val.jsonl from wav.scp, text.txt, text_language.txt, emo_target.txt, event_target.txt
sensevoice2jsonl \
++scp_file_list='["../../../data/list/train_wav.scp", "../../../data/list/train_text.txt", "../../../data/list/train_text_language.txt", "../../../data/list/train_emo.txt", "../../../data/list/train_event.txt"]' \
++data_type_list='["source", "target", "text_language", "emo_target", "event_target"]' \
++jsonl_file_out="../../../data/list/train.jsonl"If there is no train_text_language.txt, train_emo_target.txt and train_event_target.txt, the language, emotion and event label will be predicted automatically by using the SenseVoice model.
# generate train.jsonl and val.jsonl from wav.scp and text.txt
sensevoice2jsonl \
++scp_file_list='["../../../data/list/train_wav.scp", "../../../data/list/train_text.txt"]' \
++data_type_list='["source", "target"]' \
++jsonl_file_out="../../../data/list/train.jsonl" \
++model_dir='iic/SenseVoiceSmall'Ensure to modify the train_tool in finetune.sh to the absolute path of funasr/bin/train_ds.py from the FunASR installation directory you have set up earlier.
bash finetune.shpython webui.py
- Triton (GPU) Deployment Best Practices: Using Triton + TensorRT, tested with FP32, achieving an acceleration ratio of 526 on V100 GPU. FP16 support is in progress. Repository
- Sherpa-onnx Deployment Best Practices: Supports using SenseVoice in 10 programming languages: C++, C, Python, C#, Go, Swift, Kotlin, Java, JavaScript, and Dart. Also supports deploying SenseVoice on platforms like iOS, Android, and Raspberry Pi. Repository
If you encounter problems in use, you can directly raise Issues on the github page.
You can also scan the following DingTalk group QR code to join the community group for communication and discussion.
| FunAudioLLM | FunASR |
|---|---|
 |
 |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for SenseVoice
Similar Open Source Tools
SenseVoice
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.

ChatRex
ChatRex is a Multimodal Large Language Model (MLLM) designed to seamlessly integrate fine-grained object perception and robust language understanding. By adopting a decoupled architecture with a retrieval-based approach for object detection and leveraging high-resolution visual inputs, ChatRex addresses key challenges in perception tasks. It is powered by the Rexverse-2M dataset with diverse image-region-text annotations. ChatRex can be applied to various scenarios requiring fine-grained perception, such as object detection, grounded conversation, grounded image captioning, and region understanding.
gritlm
The 'gritlm' repository provides all materials for the paper Generative Representational Instruction Tuning. It includes code for inference, training, evaluation, and known issues related to the GritLM model. The repository also offers models for embedding and generation tasks, along with instructions on how to train and evaluate the models. Additionally, it contains visualizations, acknowledgements, and a citation for referencing the work.
cappr
CAPPr is a tool for text classification that does not require training or post-processing. It allows users to have their language models pick from a list of choices or compute the probability of a completion given a prompt. The tool aims to help users get more out of open source language models by simplifying the text classification process. CAPPr can be used with GGUF models, Hugging Face models, models from the OpenAI API, and for tasks like caching instructions, extracting final answers from step-by-step completions, and running predictions in batches with different sets of completions.

LLM-Blender
LLM-Blender is a framework for ensembling large language models (LLMs) to achieve superior performance. It consists of two modules: PairRanker and GenFuser. PairRanker uses pairwise comparisons to distinguish between candidate outputs, while GenFuser merges the top-ranked candidates to create an improved output. LLM-Blender has been shown to significantly surpass the best LLMs and baseline ensembling methods across various metrics on the MixInstruct benchmark dataset.

llm2vec
LLM2Vec is a simple recipe to convert decoder-only LLMs into text encoders. It consists of 3 simple steps: 1) enabling bidirectional attention, 2) training with masked next token prediction, and 3) unsupervised contrastive learning. The model can be further fine-tuned to achieve state-of-the-art performance.

xFinder
xFinder is a model specifically designed for key answer extraction from large language models (LLMs). It addresses the challenges of unreliable evaluation methods by optimizing the key answer extraction module. The model achieves high accuracy and robustness compared to existing frameworks, enhancing the reliability of LLM evaluation. It includes a specialized dataset, the Key Answer Finder (KAF) dataset, for effective training and evaluation. xFinder is suitable for researchers and developers working with LLMs to improve answer extraction accuracy.

LightRAG
LightRAG is a PyTorch library designed for building and optimizing Retriever-Agent-Generator (RAG) pipelines. It follows principles of simplicity, quality, and optimization, offering developers maximum customizability with minimal abstraction. The library includes components for model interaction, output parsing, and structured data generation. LightRAG facilitates tasks like providing explanations and examples for concepts through a question-answering pipeline.
flow-prompt
Flow Prompt is a dynamic library for managing and optimizing prompts for large language models. It facilitates budget-aware operations, dynamic data integration, and efficient load distribution. Features include CI/CD testing, dynamic prompt development, multi-model support, real-time insights, and prompt testing and evolution.

kor
Kor is a prototype tool designed to help users extract structured data from text using Language Models (LLMs). It generates prompts, sends them to specified LLMs, and parses the output. The tool works with the parsing approach and is integrated with the LangChain framework. Kor is compatible with pydantic v2 and v1, and schema is typed checked using pydantic. It is primarily used for extracting information from text based on provided reference examples and schema documentation. Kor is designed to work with all good-enough LLMs regardless of their support for function/tool calling or JSON modes.
pipelex
Pipelex is an open-source devtool designed to transform how users build repeatable AI workflows. It acts as a Docker or SQL for AI operations, allowing users to create modular 'pipes' using different LLMs for structured outputs. These pipes can be connected sequentially, in parallel, or conditionally to build complex knowledge transformations from reusable components. With Pipelex, users can share and scale proven methods instantly, saving time and effort in AI workflow development.

marqo
Marqo is more than a vector database, it's an end-to-end vector search engine for both text and images. Vector generation, storage and retrieval are handled out of the box through a single API. No need to bring your own embeddings.

curator
Bespoke Curator is an open-source tool for data curation and structured data extraction. It provides a Python library for generating synthetic data at scale, with features like programmability, performance optimization, caching, and integration with HuggingFace Datasets. The tool includes a Curator Viewer for dataset visualization and offers a rich set of functionalities for creating and refining data generation strategies.

empower-functions
Empower Functions is a family of large language models (LLMs) that provide GPT-4 level capabilities for real-world 'tool using' use cases. These models offer compatibility support to be used as drop-in replacements, enabling interactions with external APIs by recognizing when a function needs to be called and generating JSON containing necessary arguments based on user inputs. This capability is crucial for building conversational agents and applications that convert natural language into API calls, facilitating tasks such as weather inquiries, data extraction, and interactions with knowledge bases. The models can handle multi-turn conversations, choose between tools or standard dialogue, ask for clarification on missing parameters, integrate responses with tool outputs in a streaming fashion, and efficiently execute multiple functions either in parallel or sequentially with dependencies.

AirGym
AirGym is an open source Python quadrotor simulator based on IsaacGym, providing a high-fidelity dynamics and Deep Reinforcement Learning (DRL) framework for quadrotor robot learning research. It offers a lightweight and customizable platform with strict alignment with PX4 logic, multiple control modes, and Sim-to-Real toolkits. Users can perform tasks such as Hovering, Balloon, Tracking, Avoid, and Planning, with the ability to create customized environments and tasks. The tool also supports training from scratch, visual encoding approaches, playing and testing of trained models, and customization of new tasks and assets.

raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.
For similar tasks
SenseVoice
SenseVoice is a speech foundation model focusing on high-accuracy multilingual speech recognition, speech emotion recognition, and audio event detection. Trained with over 400,000 hours of data, it supports more than 50 languages and excels in emotion recognition and sound event detection. The model offers efficient inference with low latency and convenient finetuning scripts. It can be deployed for service with support for multiple client-side languages. SenseVoice-Small model is open-sourced and provides capabilities for Mandarin, Cantonese, English, Japanese, and Korean. The tool also includes features for natural speech generation and fundamental speech recognition tasks.

nuitrack-sdk
Nuitrack™ is an ultimate 3D body tracking solution developed by 3DiVi Inc. It enables body motion analytics applications for virtually any widespread depth sensors and hardware platforms, supporting a wide range of applications from real-time gesture recognition on embedded platforms to large-scale multisensor analytical systems. Nuitrack provides highly-sophisticated 3D skeletal tracking, basic facial analysis, hand tracking, and gesture recognition APIs for UI control. It offers two skeletal tracking engines: classical for embedded hardware and AI for complex poses, providing a human-centric spatial understanding tool for natural and intelligent user engagement.
multimodal_cognitive_ai
The multimodal cognitive AI repository focuses on research work related to multimodal cognitive artificial intelligence. It explores the integration of multiple modes of data such as text, images, and audio to enhance AI systems' cognitive capabilities. The repository likely contains code, datasets, and research papers related to multimodal AI applications, including natural language processing, computer vision, and audio processing. Researchers and developers interested in advancing AI systems' understanding of multimodal data can find valuable resources and insights in this repository.
LLM-Project
LLM-Project is a machine learning model for sentiment analysis. It is designed to analyze text data and classify it into positive, negative, or neutral sentiments. The model uses natural language processing techniques to extract features from the text and train a classifier to make predictions. LLM-Project is suitable for researchers, developers, and data scientists who are working on sentiment analysis tasks. It provides a pre-trained model that can be easily integrated into existing projects or used for experimentation and research purposes. The codebase is well-documented and easy to understand, making it accessible to users with varying levels of expertise in machine learning and natural language processing.
Friend
Friend is an open-source AI wearable device that records everything you say, gives you proactive feedback and advice. It has real-time AI audio processing capabilities, low-powered Bluetooth, open-source software, and a wearable design. The device is designed to be affordable and easy to use, with a total cost of less than $20. To get started, you can clone the repo, choose the version of the app you want to install, and follow the instructions for installing the firmware and assembling the device. Friend is still a prototype project and is provided "as is", without warranty of any kind. Use of the device should comply with all local laws and regulations concerning privacy and data protection.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.

openvino-plugins-ai-audacity
OpenVINO™ AI Plugins for Audacity* are a set of AI-enabled effects, generators, and analyzers for Audacity®. These AI features run 100% locally on your PC -- no internet connection necessary! OpenVINO™ is used to run AI models on supported accelerators found on the user's system such as CPU, GPU, and NPU. * **Music Separation**: Separate a mono or stereo track into individual stems -- Drums, Bass, Vocals, & Other Instruments. * **Noise Suppression**: Removes background noise from an audio sample. * **Music Generation & Continuation**: Uses MusicGen LLM to generate snippets of music, or to generate a continuation of an existing snippet of music. * **Whisper Transcription**: Uses whisper.cpp to generate a label track containing the transcription or translation for a given selection of spoken audio or vocals.
OpenAI-Api-Unreal
The OpenAIApi Plugin provides access to the OpenAI API in Unreal Engine, allowing users to generate images, transcribe speech, and power NPCs using advanced AI models. It offers blueprint nodes for making API calls, setting parameters, and accessing completion values. Users can authenticate using an API key directly or as an environment variable. The plugin supports various tasks such as generating images, transcribing speech, and interacting with NPCs through chat endpoints.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.