
AudioLLM
Audio Large Language Models
Stars: 71

AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.
README:
This repository is a curated collection of research papers focused on the development, implementation, and evaluation of language models for audio data. Our goal is to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. Contributions and suggestions for new papers are highly encouraged!
| Date | Model | Key Affiliations | Paper | Link |
|---|---|---|---|---|
| 2024-10 | DiVA | Georgia Tech, Stanford | Distilling an End-to-End Voice Assistant Without Instruction Training Data | Paper / Project |
| 2024-09 | Moshi | Kyutai | Moshi: a speech-text foundation model for real-time dialogue | Paper / Code |
| 2024-09 | LLaMA-Omni | CAS | LLaMA-Omni: Seamless Speech Interaction with Large Language Models | Paper / Code |
| 2024-09 | Ultravox | fixie-ai | GitHub Open Source | Code |
| 2024-08 | Mini-Omni | Tsinghua | Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming | Paper / Code |
| 2024-08 | Typhoon-Audio | Typhoon | Typhoon-Audio Preview Release | Page |
| 2024-08 | USDM | SNU | Integrating Paralinguistics in Speech-Empowered Large Language Models for Natural Conversation | Paper |
| 2024-08 | MooER | Moore Threads | MooER: LLM-based Speech Recognition and Translation Models from Moore Threads | Paper / Code |
| 2024-07 | GAMA | UMD | GAMA: A Large Audio-Language Model with Advanced Audio Understanding and Complex Reasoning Abilities | Paper / Code |
| 2024-07 | LLaST | CUHK-SZ | LLaST: Improved End-to-end Speech Translation System Leveraged by Large Language Models | Paper / Code |
| 2024-07 | CompA | University of Maryland | CompA: Addressing the Gap in Compositional Reasoning in Audio-Language Models | Paper / Code / Project |
| 2024-07 | Qwen2-Audio | Alibaba | Qwen2-Audio Technical Report | Paper / Code |
| 2024-07 | FunAudioLLM | Alibaba | FunAudioLLM: Voice Understanding and Generation Foundation Models for Natural Interaction Between Humans and LLMs | Paper / Code / Demo |
| 2024-06 | DeSTA | NTU-Taiwan, Nvidia | DeSTA: Enhancing Speech Language Models through Descriptive Speech-Text Alignment | Paper / Code |
| 2024-05 | AudioChatLlama | Meta | AudioChatLlama: Towards General-Purpose Speech Abilities for LLMs | Paper |
| 2024-05 | Audio Flamingo | Nvidia | Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities | Paper / Code |
| 2024-05 | SpeechVerse | AWS | SpeechVerse: A Large-scale Generalizable Audio Language Model | Paper |
| 2024-04 | SALMONN | Tsinghua | SALMONN: Towards Generic Hearing Abilities for Large Language Models | Paper / Code / Demo |
| 2024-03 | WavLLM | CUHK | WavLLM: Towards Robust and Adaptive Speech Large Language Model | Paper / Code |
| 2024-02 | SLAM-LLM | MoE Key Lab of Artificial Intelligence | An Embarrassingly Simple Approach for LLM with Strong ASR Capacity | Paper / Code |
| 2024-01 | Pengi | Microsoft | Pengi: An Audio Language Model for Audio Tasks | Paper / Code |
| 2023-12 | Qwen-Audio | Alibaba | Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models | Paper / Code / Demo |
| 2023-12 | LTU-AS | MIT | Joint Audio and Speech Understanding | Paper / Code / Demo |
| 2023-10 | Speech-LLaMA | Microsoft | On decoder-only architecture for speech-to-text and large language model integration | Paper |
| 2023-10 | UniAudio | CUHK | An Audio Foundation Model Toward Universal Audio Generation | Paper / Code / Demo |
| 2023-09 | LLaSM | LinkSoul.AI | LLaSM: Large Language and Speech Model | Paper / Code |
| 2023-06 | AudioPaLM | AudioPaLM: A Large Language Model that Can Speak and Listen | Paper / Demo | |
| 2023-05 | VioLA | Microsoft | VioLA: Unified Codec Language Models for Speech Recognition, Synthesis, and Translation | Paper |
| 2023-05 | SpeechGPT | Fudan | SpeechGPT: Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities | Paper / Code / Demo |
| 2023-04 | AudioGPT | Zhejiang Uni | AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head | Paper / Code |
| 2022-09 | AudioLM | AudioLM: a Language Modeling Approach to Audio Generation | Paper / Demo |
| Date | Model | Key Affiliations | Paper | Link |
|---|---|---|---|---|
| 2024-09 | EMOVA | HKUST | EMOVA: Empowering Language Models to See, Hear and Speak with Vivid Emotions | Paper / Demo |
| 2023-11 | CoDi-2 | UC Berkeley | CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation | Paper / Code / Demo |
| 2023-06 | Macaw-LLM | Tencent | Macaw-LLM: Multi-Modal Language Modeling with Image, Video, Audio, and Text Integration | Paper / Code |
| Date | Name | Key Affiliations | Paper | Link |
|---|---|---|---|---|
| 2024-09 | AudioBERT | Postech | AudioBERT: Audio Knowledge Augmented Language Model | Paper / Code |
| 2024-09 | MoWE-Audio | A*STAR | MoWE-Audio: Multitask AudioLLMs with Mixture of Weak Encoders | Paper |
| 2024-09 | - | Tsinghua SIGS | Comparing Discrete and Continuous Space LLMs for Speech Recognition | Paper |
| 2024-06 | Speech ReaLLM | Meta | Speech ReaLLM – Real-time Streaming Speech Recognition with Multimodal LLMs by Teaching the Flow of Time | Paper |
| 2023-09 | Segment-level Q-Former | Tsinghua | Connecting Speech Encoder and Large Language Model for ASR | Paper |
| 2023-07 | - | Meta | Prompting Large Language Models with Speech Recognition Abilities | Paper |
| Date | Name | Key Affiliations | Paper | Link |
|---|---|---|---|---|
| 2024-05 | VoiceJailbreak | CISPA | Voice Jailbreak Attacks Against GPT-4o | Paper |
| Date | Name | Key Affiliations | Paper | Link |
|---|---|---|---|---|
| 2024-06 | AudioBench | A*STAR | AudioBench: A Universal Benchmark for Audio Large Language Models | Paper / Code / LeaderBoard |
| 2024-05 | AIR-Bench | ZJU, Alibaba | AIR-Bench: Benchmarking Large Audio-Language Models via Generative Comprehension | Paper / Code |
| 2024-08 | MuChoMusic | UPF, QMUL, UMG | MuChoMusic: Evaluating Music Understanding in Multimodal Audio-Language Models | Paper / Code |
| 2023-09 | Dynamic-SUPERB | NTU-Taiwan, etc. | Dynamic-SUPERB: Towards A Dynamic, Collaborative, and Comprehensive Instruction-Tuning Benchmark for Speech | Paper / Code |
Audio Models are different from Audio Large Language Models.
| Date | Name | Key Affiliations | Paper | Link |
|---|---|---|---|---|
| 2024-09 | Salmon | Hebrew University of Jerusalem | A Suite for Acoustic Language Model Evaluation | Paper / Code |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for AudioLLM
Similar Open Source Tools
AudioLLM
AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.
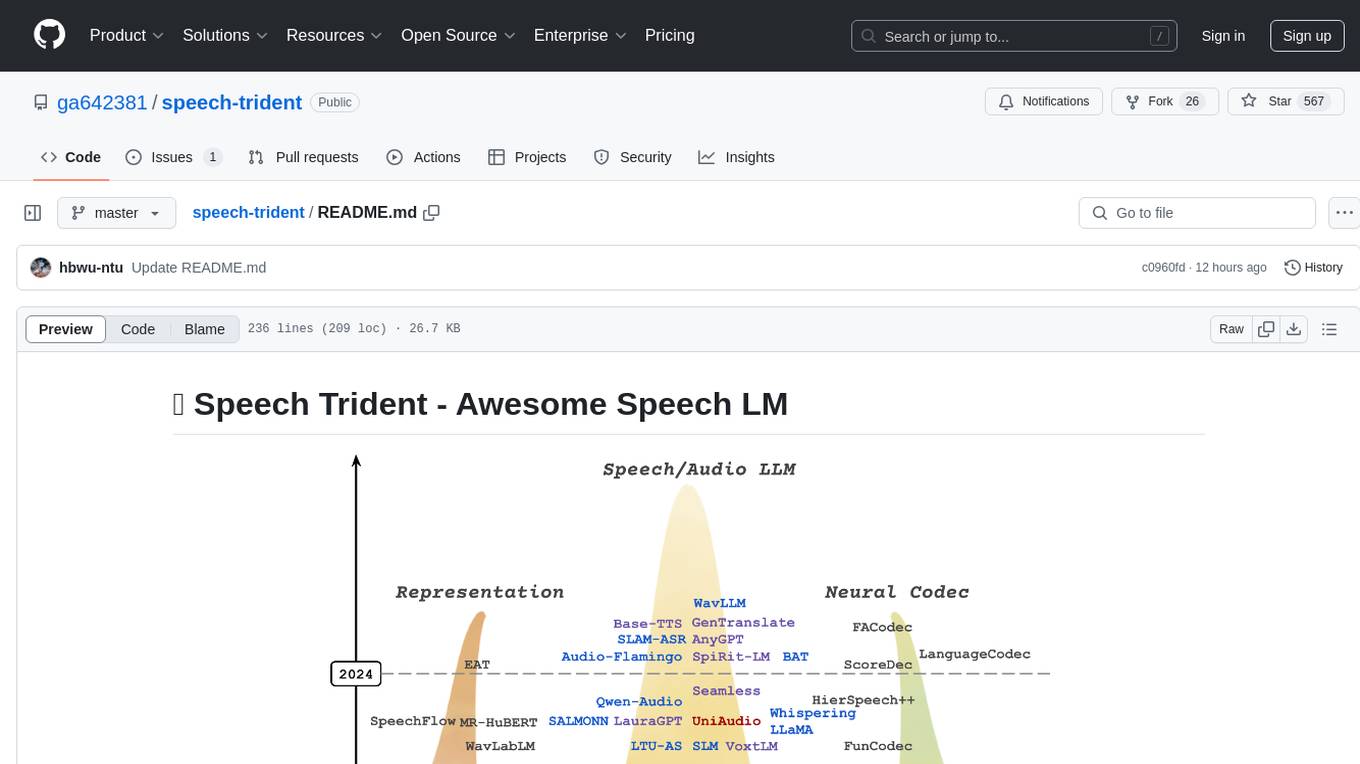
speech-trident
Speech Trident is a repository focusing on speech/audio large language models, covering representation learning, neural codec, and language models. It explores speech representation models, speech neural codec models, and speech large language models. The repository includes contributions from various researchers and provides a comprehensive list of speech/audio language models, representation models, and codec models.
Awesome-LLM-3D
This repository is a curated list of papers related to 3D tasks empowered by Large Language Models (LLMs). It covers tasks such as 3D understanding, reasoning, generation, and embodied agents. The repository also includes other Foundation Models like CLIP and SAM to provide a comprehensive view of the area. It is actively maintained and updated to showcase the latest advances in the field. Users can find a variety of research papers and projects related to 3D tasks and LLMs in this repository.

LLM-Agent-Survey
Autonomous agents are designed to achieve specific objectives through self-guided instructions. With the emergence and growth of large language models (LLMs), there is a growing trend in utilizing LLMs as fundamental controllers for these autonomous agents. This repository conducts a comprehensive survey study on the construction, application, and evaluation of LLM-based autonomous agents. It explores essential components of AI agents, application domains in natural sciences, social sciences, and engineering, and evaluation strategies. The survey aims to be a resource for researchers and practitioners in this rapidly evolving field.

open-llms
Open LLMs is a repository containing various Large Language Models licensed for commercial use. It includes models like T5, GPT-NeoX, UL2, Bloom, Cerebras-GPT, Pythia, Dolly, and more. These models are designed for tasks such as transfer learning, language understanding, chatbot development, code generation, and more. The repository provides information on release dates, checkpoints, papers/blogs, parameters, context length, and licenses for each model. Contributions to the repository are welcome, and it serves as a resource for exploring the capabilities of different language models.
Github-Ranking-AI
This repository provides a list of the most starred and forked repositories on GitHub. It is updated automatically and includes information such as the project name, number of stars, number of forks, language, number of open issues, description, and last commit date. The repository is divided into two sections: LLM and chatGPT. The LLM section includes repositories related to large language models, while the chatGPT section includes repositories related to the chatGPT chatbot.
Cool-GenAI-Fashion-Papers
Cool-GenAI-Fashion-Papers is a curated list of resources related to GenAI-Fashion, including papers, workshops, companies, and products. It covers a wide range of topics such as fashion design synthesis, outfit recommendation, fashion knowledge extraction, trend analysis, and more. The repository provides valuable insights and resources for researchers, industry professionals, and enthusiasts interested in the intersection of AI and fashion.
ai-game-development-tools
Here we will keep track of the AI Game Development Tools, including LLM, Agent, Code, Writer, Image, Texture, Shader, 3D Model, Animation, Video, Audio, Music, Singing Voice and Analytics. 🔥 * Tool (AI LLM) * Game (Agent) * Code * Framework * Writer * Image * Texture * Shader * 3D Model * Avatar * Animation * Video * Audio * Music * Singing Voice * Speech * Analytics * Video Tool

Awesome-Tabular-LLMs
This repository is a collection of papers on Tabular Large Language Models (LLMs) specialized for processing tabular data. It includes surveys, models, and applications related to table understanding tasks such as Table Question Answering, Table-to-Text, Text-to-SQL, and more. The repository categorizes the papers based on key ideas and provides insights into the advancements in using LLMs for processing diverse tables and fulfilling various tabular tasks based on natural language instructions.
LLM4EC
LLM4EC is an interdisciplinary research repository focusing on the intersection of Large Language Models (LLM) and Evolutionary Computation (EC). It provides a comprehensive collection of papers and resources exploring various applications, enhancements, and synergies between LLM and EC. The repository covers topics such as LLM-assisted optimization, EA-based LLM architecture search, and applications in code generation, software engineering, neural architecture search, and other generative tasks. The goal is to facilitate research and development in leveraging LLM and EC for innovative solutions in diverse domains.

LLM-KG4QA
LLM-KG4QA is a repository focused on the integration of Large Language Models (LLMs) and Knowledge Graphs (KGs) for Question Answering (QA). It covers various aspects such as using KGs as background knowledge, reasoning guideline, and refiner/filter. The repository provides detailed information on pre-training, fine-tuning, and Retrieval Augmented Generation (RAG) techniques for enhancing QA performance. It also explores complex QA tasks like Explainable QA, Multi-Modal QA, Multi-Document QA, Multi-Hop QA, Multi-run and Conversational QA, Temporal QA, Multi-domain and Multilingual QA, along with advanced topics like Optimization and Data Management. Additionally, it includes benchmark datasets, industrial and scientific applications, demos, and related surveys in the field.
Awesome-Model-Merging-Methods-Theories-Applications
A comprehensive repository focusing on 'Model Merging in LLMs, MLLMs, and Beyond', providing an exhaustive overview of model merging methods, theories, applications, and future research directions. The repository covers various advanced methods, applications in foundation models, different machine learning subfields, and tasks like pre-merging methods, architecture transformation, weight alignment, basic merging methods, and more.
LLM4Opt
LLM4Opt is a collection of references and papers focusing on applying Large Language Models (LLMs) for diverse optimization tasks. The repository includes research papers, tutorials, workshops, competitions, and related collections related to LLMs in optimization. It covers a wide range of topics such as algorithm search, code generation, machine learning, science, industry, and more. The goal is to provide a comprehensive resource for researchers and practitioners interested in leveraging LLMs for optimization tasks.
For similar tasks
AnyGPT
AnyGPT is a unified multimodal language model that utilizes discrete representations for processing various modalities like speech, text, images, and music. It aligns the modalities for intermodal conversions and text processing. AnyInstruct dataset is constructed for generative models. The model proposes a generative training scheme using Next Token Prediction task for training on a Large Language Model (LLM). It aims to compress vast multimodal data on the internet into a single model for emerging capabilities. The tool supports tasks like text-to-image, image captioning, ASR, TTS, text-to-music, and music captioning.
speech-trident
Speech Trident is a repository focusing on speech/audio large language models, covering representation learning, neural codec, and language models. It explores speech representation models, speech neural codec models, and speech large language models. The repository includes contributions from various researchers and provides a comprehensive list of speech/audio language models, representation models, and codec models.
AudioLLM
AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.
bolna
Bolna is an open-source platform for building voice-driven conversational applications using large language models (LLMs). It provides a comprehensive set of tools and integrations to handle various aspects of voice-based interactions, including telephony, transcription, LLM-based conversation handling, and text-to-speech synthesis. Bolna simplifies the process of creating voice agents that can perform tasks such as initiating phone calls, transcribing conversations, generating LLM-powered responses, and synthesizing speech. It supports multiple providers for each component, allowing users to customize their setup based on their specific needs. Bolna is designed to be easy to use, with a straightforward local setup process and well-documented APIs. It is also extensible, enabling users to integrate with other telephony providers or add custom functionality.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.

nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.