Best AI tools for< Translate Speech To Text >
20 - AI tool Sites
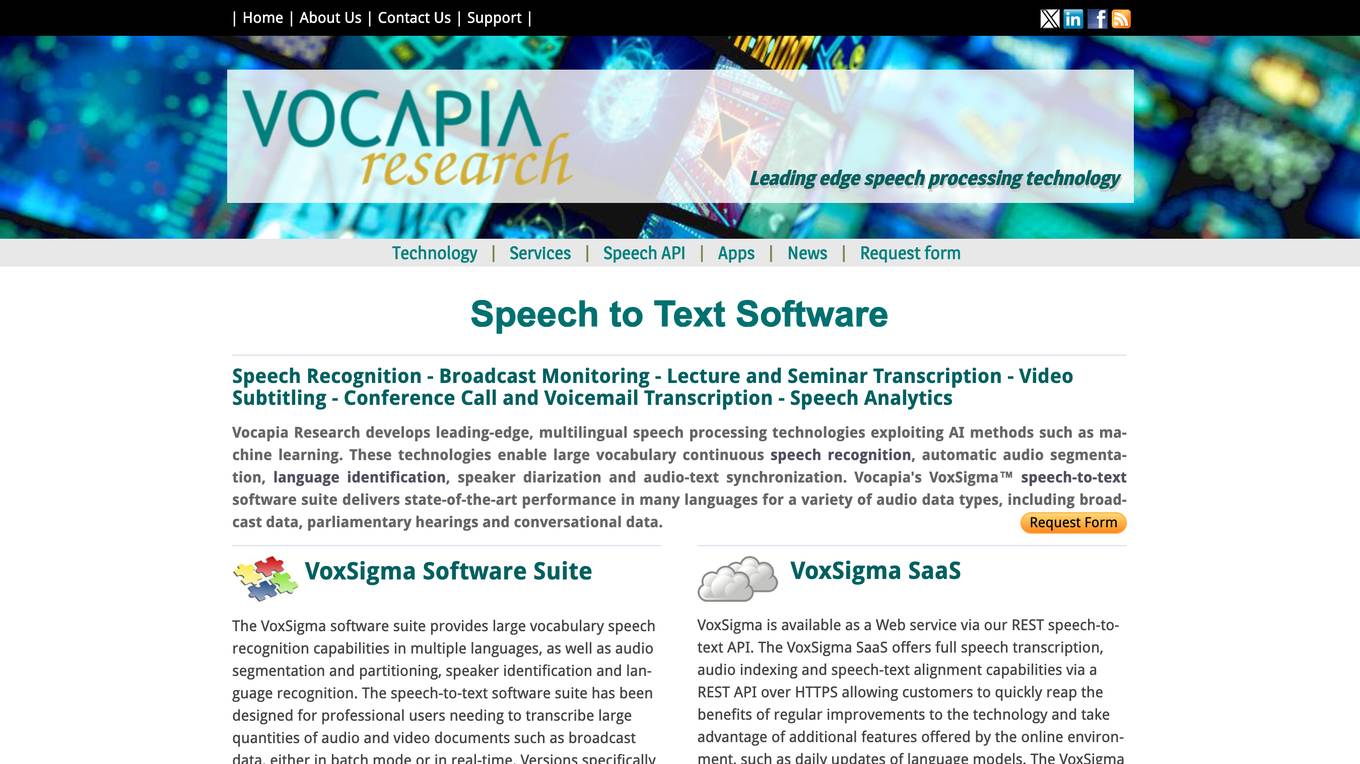
VoxSigma
Vocapia Research develops leading-edge, multilingual speech processing technologies exploiting AI methods such as machine learning. These technologies enable large vocabulary continuous speech recognition, automatic audio segmentation, language identification, speaker diarization and audio-text synchronization. Vocapia's VoxSigma™ speech-to-text software suite delivers state-of-the-art performance in many languages for a variety of audio data types, including broadcast data, parliamentary hearings and conversational data.
Interpre-X
Interpre-X is a real-time speech translation tool powered by AI. It offers speech-to-speech, speech-to-text, text-to-speech, and text-to-text translation in over 10 languages. Interpre-X is designed to break down language barriers and facilitate communication between people who speak different languages. It is suitable for both personal and professional use, and it can be used in a variety of settings, such as travel, business meetings, and language learning.
Gladia
Gladia provides a fast and accurate way to turn unstructured audio data into valuable business knowledge. Its Audio Intelligence API helps capture, enrich, and leverage hidden insights in audio data, powered by optimized Whisper ASR. Key features include highly accurate audio and video transcription, speech-to-text translation in 99 languages, in-depth insights with add-ons, and secure hosting options. Gladia's AI transcription and multilingual audio intelligence features enhance user experience and boost retention in various industries, including content and media, virtual meetings, workspace collaboration, and call centers. Developers can easily integrate cutting-edge AI into their products without AI expertise or setup costs.
AppTek
AppTek is a global leader in artificial intelligence (AI) and machine learning (ML) technologies for automatic speech recognition (ASR), neural machine translation (NMT), natural language processing/understanding (NLP/U) and text-to-speech (TTS) technologies. The AppTek platform delivers industry-leading solutions for organizations across a breadth of global markets such as media and entertainment, call centers, government, enterprise business, and more. Built by scientists and research engineers who are recognized among the best in the world, AppTek’s solutions cover a wide array of languages/ dialects, channels, domains and demographics.
DubSmart
DubSmart is an AI-powered platform that offers advanced video dubbing and voice cloning services. It allows users to transform text into lifelike speech, dub videos with voice cloning technology, and generate subtitles for audio or video content. With a user-friendly interface, DubSmart enables users to create unique voices, edit projects, and download finished projects in various formats. The platform supports 33 languages for AI dubbing and 60+ languages for speech-to-text conversion. DubSmart caters to small creators, YouTubers, and companies looking to enhance their audiovisual content with personalized voices and multilingual capabilities.
GPT4Audio
GPT4Audio is an AI-based desktop application that offers speech-to-text and text-to-speech capabilities. It allows users to transcribe and translate audio files from multiple languages, as well as dictate text and generate audio recordings in real time. The application also includes an Article Wizard feature that can help users create homework essays, marketing content, articles, or blogs quickly and easily.
Lingvanex
Lingvanex is a cloud-based machine translation and speech recognition platform that provides businesses with a variety of tools to translate text, documents, and speech in over 100 languages. The platform is powered by artificial intelligence (AI) and machine learning (ML) technologies, which enable it to deliver high-quality translations that are both accurate and fluent. Lingvanex also offers a variety of features that make it easy for businesses to integrate translation and speech recognition into their workflows, including APIs, SDKs, and plugins for popular programming languages and platforms.
Vocaldo
Vocaldo is a revolutionary speech-to-text application that utilizes cutting-edge AI technology to transcribe speech into text in over 100 languages. It offers accurate, fast, and easy-to-use transcription services, allowing users to effortlessly convert audio or video files into text with high precision. Vocaldo supports multiple speakers, various accents, and background noise, making it a versatile tool for content creators, journalists, and businesses worldwide.
Lemonfox.ai
Lemonfox.ai is an affordable and easy-to-use Speech-To-Text API that allows users to transcribe audio files quickly and accurately. With features like support for over 100 languages, speaker recognition, high accuracy, and secure processing, Lemonfox.ai is a cost-effective solution for developers and non-developers alike. The API offers simple and affordable pricing plans, with the first month free to get started. Privacy and data security are prioritized, with all data being deleted immediately after processing. Lemonfox.ai is powered by the latest speech recognition AI model, Whisper large-v3, ensuring top-notch performance and competitive pricing.
SpeechFlow
SpeechFlow is a powerful speech-to-text API that transcribes audio and video files into text with high accuracy. It supports 14 languages and offers features such as punctuation, easy deployment, scalability, and fast processing. SpeechFlow is ideal for businesses and individuals who need accurate and timely transcription services.
Podcastle
Podcastle is an all-in-one podcasting software that empowers creators of all backgrounds and experience levels with an intuitive, AI-powered platform. It offers a wide range of features, including a recording studio, audio editor, video editor, AI-generated voices, and hosting hub, making it easy to create, edit, and publish high-quality podcasts and videos. Podcastle is designed to be user-friendly and accessible, with no prior experience or technical expertise required.
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.
WhisperUI
WhisperUI is an affordable Speech to Text application powered by OpenAI Whisper. It allows users to easily convert audio files into text and SRT files with high accuracy. The application is trusted by members of leading organizations and universities. Users can upload various audio file formats and benefit from premium features such as uploading multiple files at once and unlimited daily file uploads. WhisperUI supports multiple languages and is known for its robustness in transcribing speech in the presence of accents, background noise, and technical language.
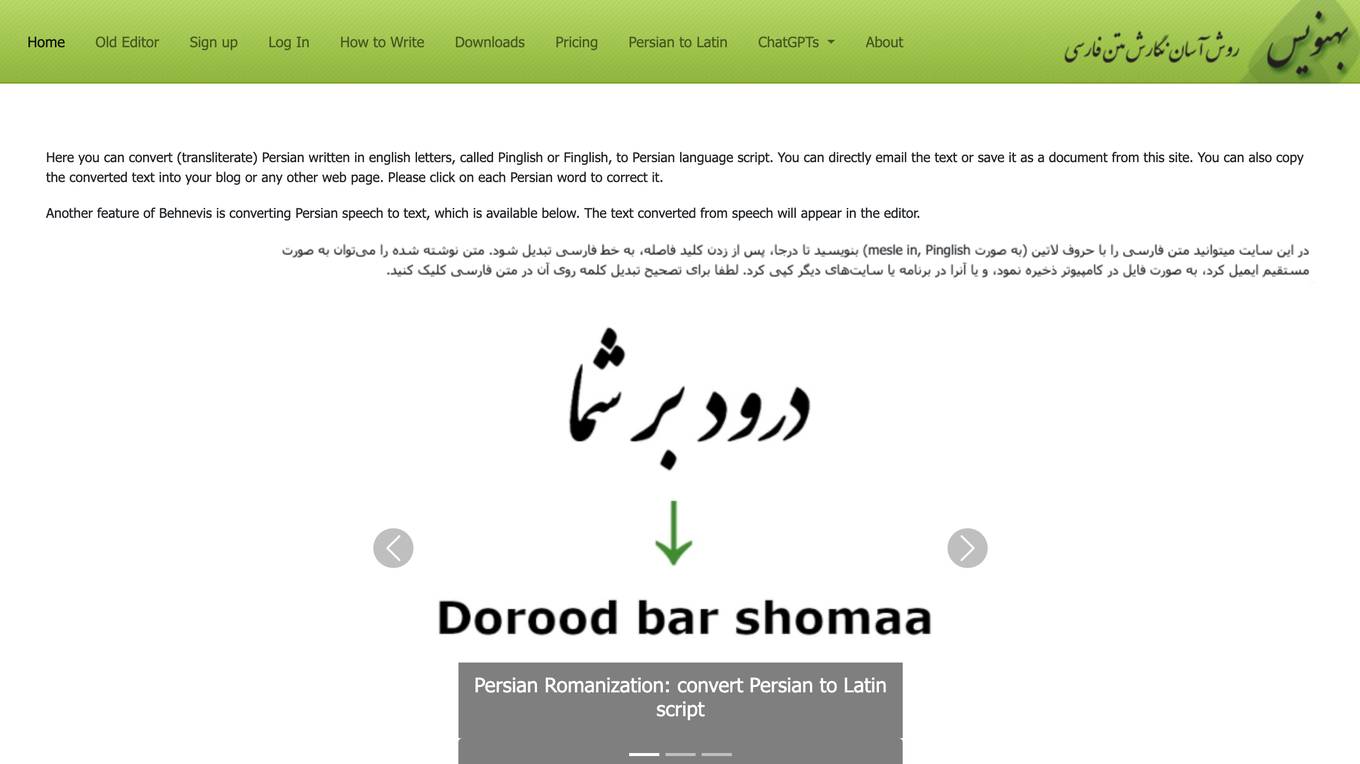
Behnevis
Behnevis is a Persian (Farsi) keyboard, editor, and speech-to-text tool. It allows users to convert Persian written in English letters (Pinglish or Finglish) to the Persian language script. Users can also convert Persian speech to text using the tool. Behnevis offers a paid premium plan with additional features, but the legacy two-part interface is still available for free without limitations.
Auri
Auri is an AI assistant that offers a range of writing, communication, and productivity tools. It includes an AI-powered keyboard with features like grammar checking, translation, and paraphrasing, as well as an AI chat, voice recorder and transcriber, and smart notes. Auri is available on iPhone, iPad, Mac, and Apple Watch.
Genailia
Genailia is an AI platform that offers a range of products and services such as translation, transcription, chatbot, LLM, GPT, TTS, ASR, and social media insights. It harnesses AI to redefine possibilities by providing generative AI, linguistic interfaces, accelerators, and more in a single platform. The platform aims to streamline various tasks through AI technology, making it a valuable tool for businesses and individuals seeking efficient solutions.
Trint
Trint is an AI transcription software that converts video, audio, and speech to text in over 40 languages with up to 99% accuracy. It allows users to transcribe, translate, edit, and collaborate seamlessly in a single workflow. Trint is trusted by professionals in various industries for its efficiency and accuracy in transcription tasks.
Vatis Tech
Vatis Tech is an AI-powered speech-to-text infrastructure that offers transcription software to help teams and individuals streamline their workflow. The platform provides accurate, accessible, and affordable speech-to-text API, caption generator, and audio intelligence solutions. It caters to various industries such as contact centers, broadcasting, medical, legal, media, newsrooms, and more. Vatis Tech's technology is powered by state-of-the-art AI, enabling near-human accuracy in transcribing speech with fast turnaround times. The platform also offers features like real-time transcription, custom AI models, and support for multiple languages.
Transkriptor
Transkriptor is an AI-powered tool that allows users to convert audio or video files into text with high accuracy and efficiency. It supports over 100 languages and offers features like automatic transcription, translation, rich export options, and collaboration tools. With state-of-the-art AI technology, Transkriptor simplifies the transcription process for various purposes such as meetings, interviews, lectures, and more. The platform ensures fast, accurate, and affordable transcription services, making it a valuable tool for professionals and students across different industries.
EasySub
EasySub is an online automatic subtitle generator and editor that uses advanced AI algorithms to generate accurate subtitles for videos and audio files. It supports over 150 languages, multiple export resolutions, and allows users to easily add text and subtitles to videos. EasySub is free to use and offers a variety of features, including automatic transcription, subtitle translation, and video editing.
1 - Open Source AI Tools

AudioLLM
AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.
20 - OpenAI Gpts

Cat Translator
Your Feline Language Specialist for translating human speech to cat sounds.
Will's Quill
With quill in hand, I weave tales of yore. "Shakespearean Echo," a voice from the past,

Ultimate Translator
Speak, snap, and understand the world. Your pocket-sized translator deciphers docs, images, and speech in a heartbeat with pronunciation guides and motivational boosts!
Animal Translator
Your expert in translating human speech into animal languages, with a playful and educational twist.
Universal Bilingual Translator
The universal bilingual translation GPT is suitable for dialogue between different languages, simultaneous interpretation, and other speaking scenarios. Starts with a pair of language name, such as "Chinese English", "English French"