Best AI tools for< Synthesize Speech >
20 - AI tool Sites
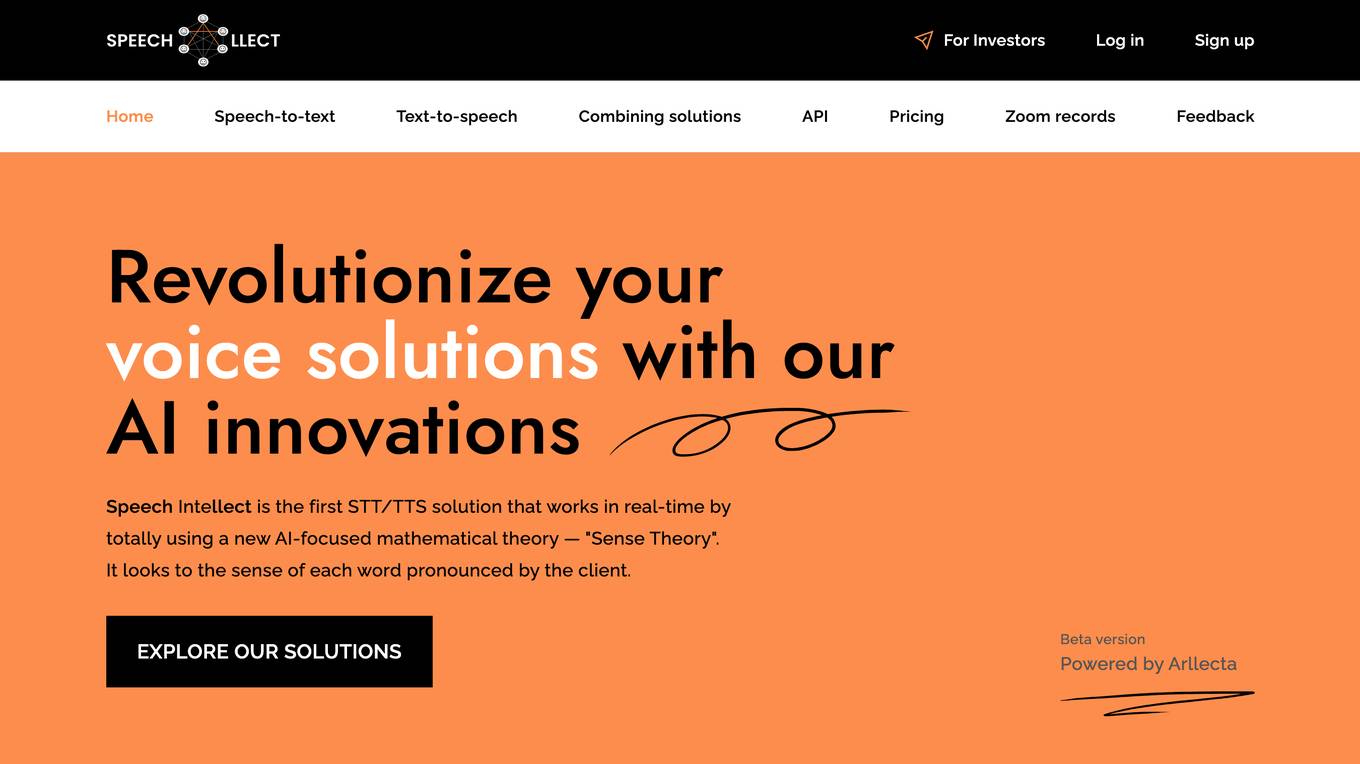
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.
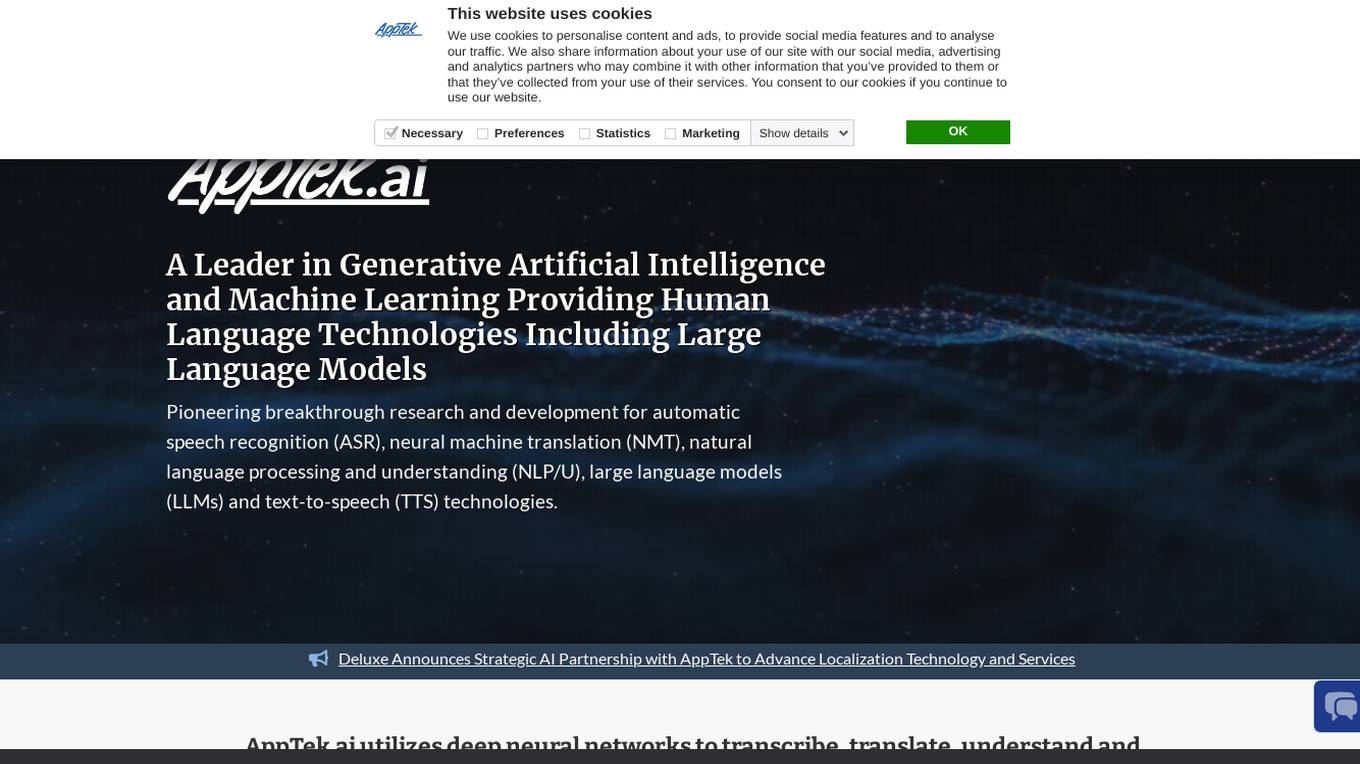
AppTek.ai
AppTek.ai is a global leader in artificial intelligence (AI) and machine learning (ML) technologies, providing advanced solutions in automatic speech recognition, neural machine translation, natural language processing/understanding, large language models, and text-to-speech technologies. The platform offers industry-leading language solutions for various sectors such as media and entertainment, call centers, government, and enterprise business. AppTek.ai combines cutting-edge AI research with real-world applications, delivering accurate and efficient tools for speech transcription, translation, understanding, and synthesis across multiple languages and dialects.
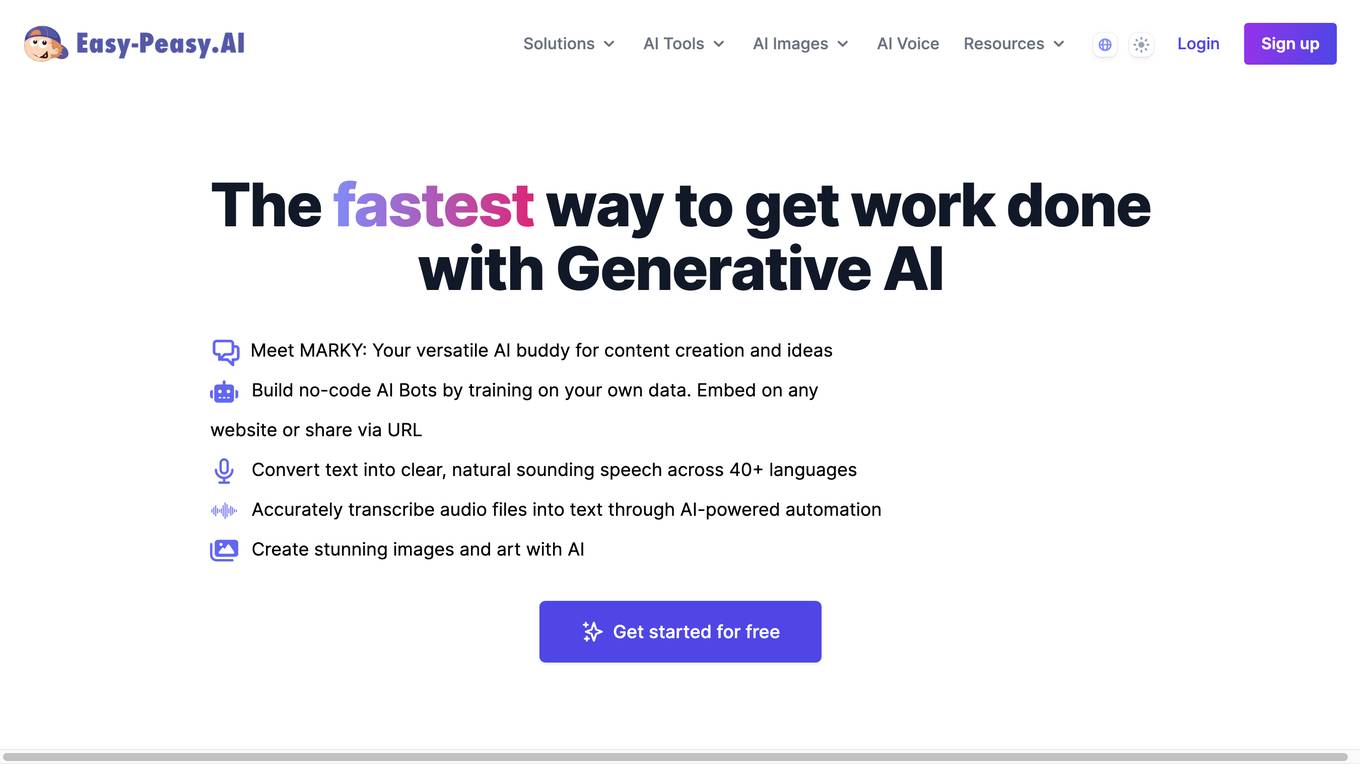
Easy-Peasy.AI
Easy-Peasy.AI is an all-in-one AI platform that offers a variety of AI tools and solutions to assist users in content generation, copywriting, chatbot creation, image creation, audio transcription, and text-to-speech tasks. The platform provides a user-friendly interface and powerful technology to help users create high-quality content, improve writing skills, and automate various tasks using AI technology.
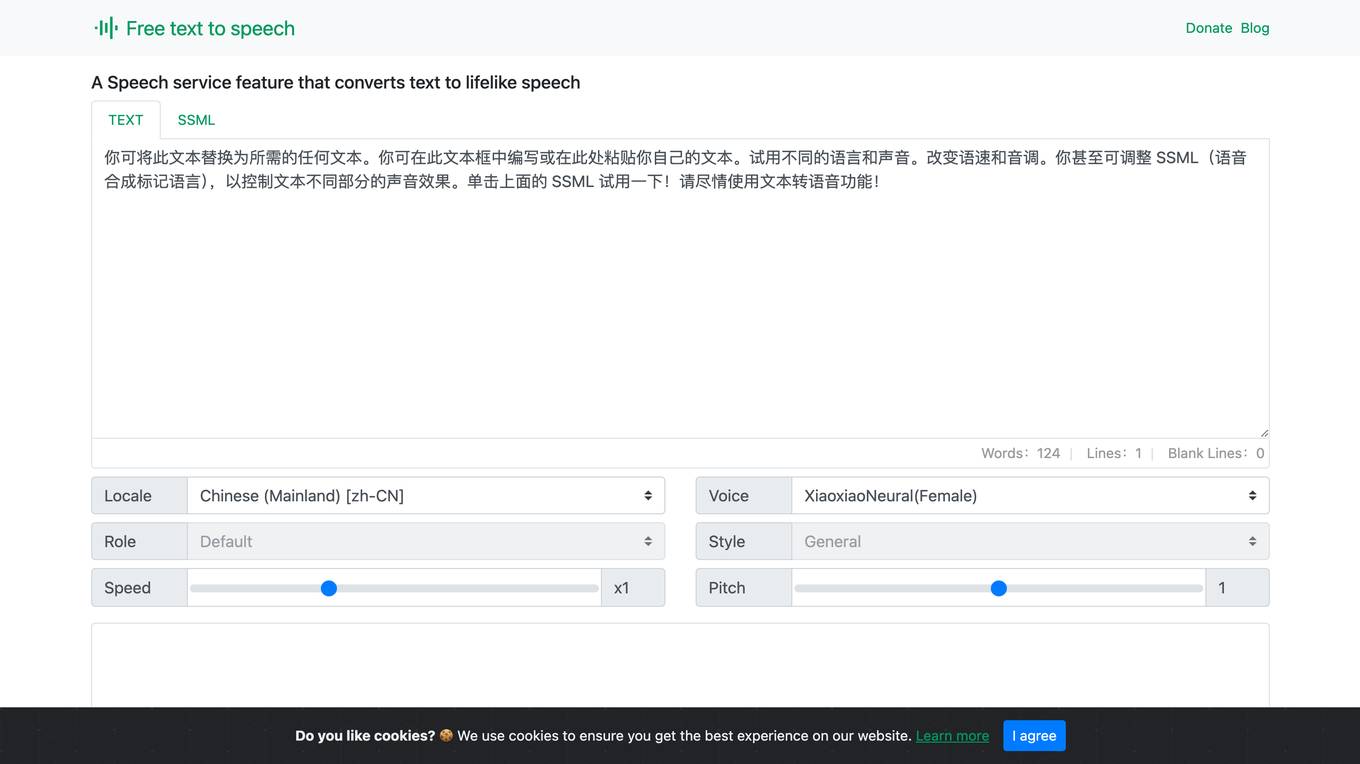
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
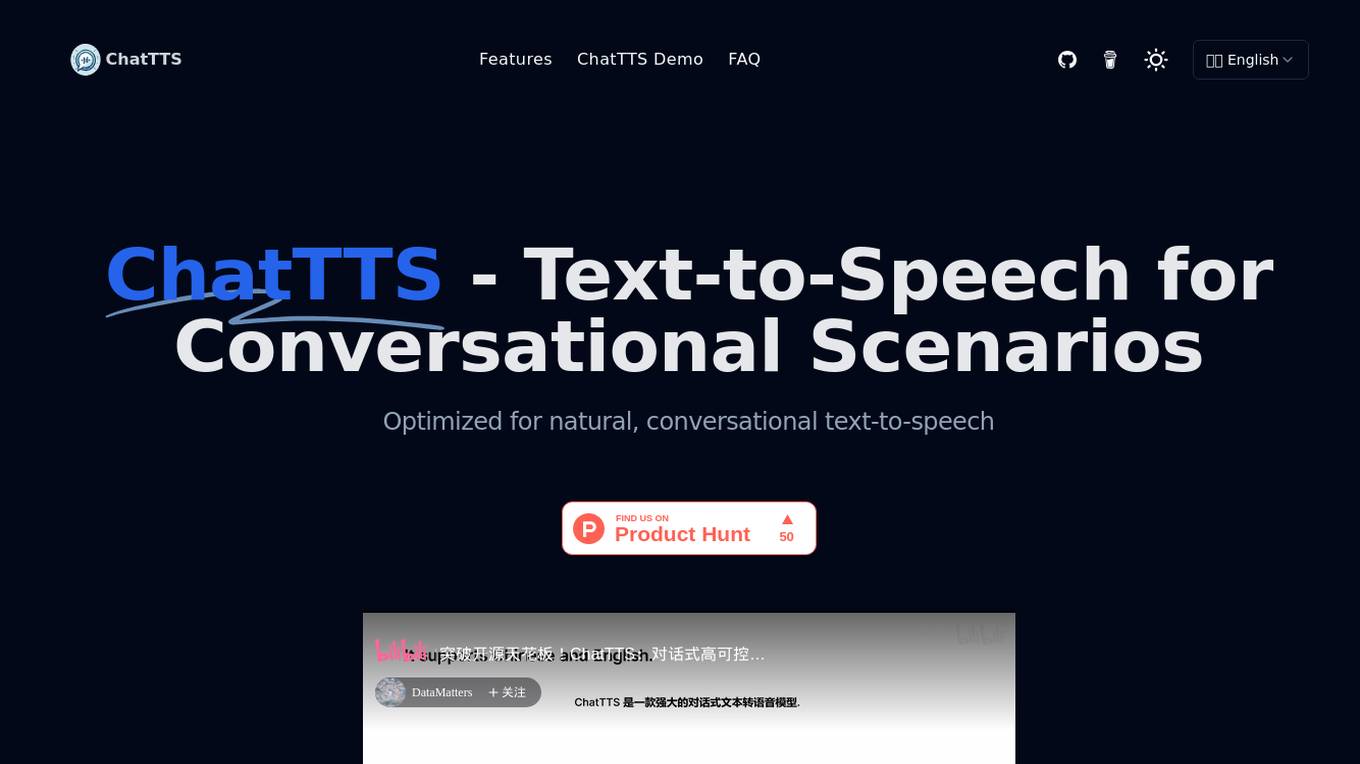
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.
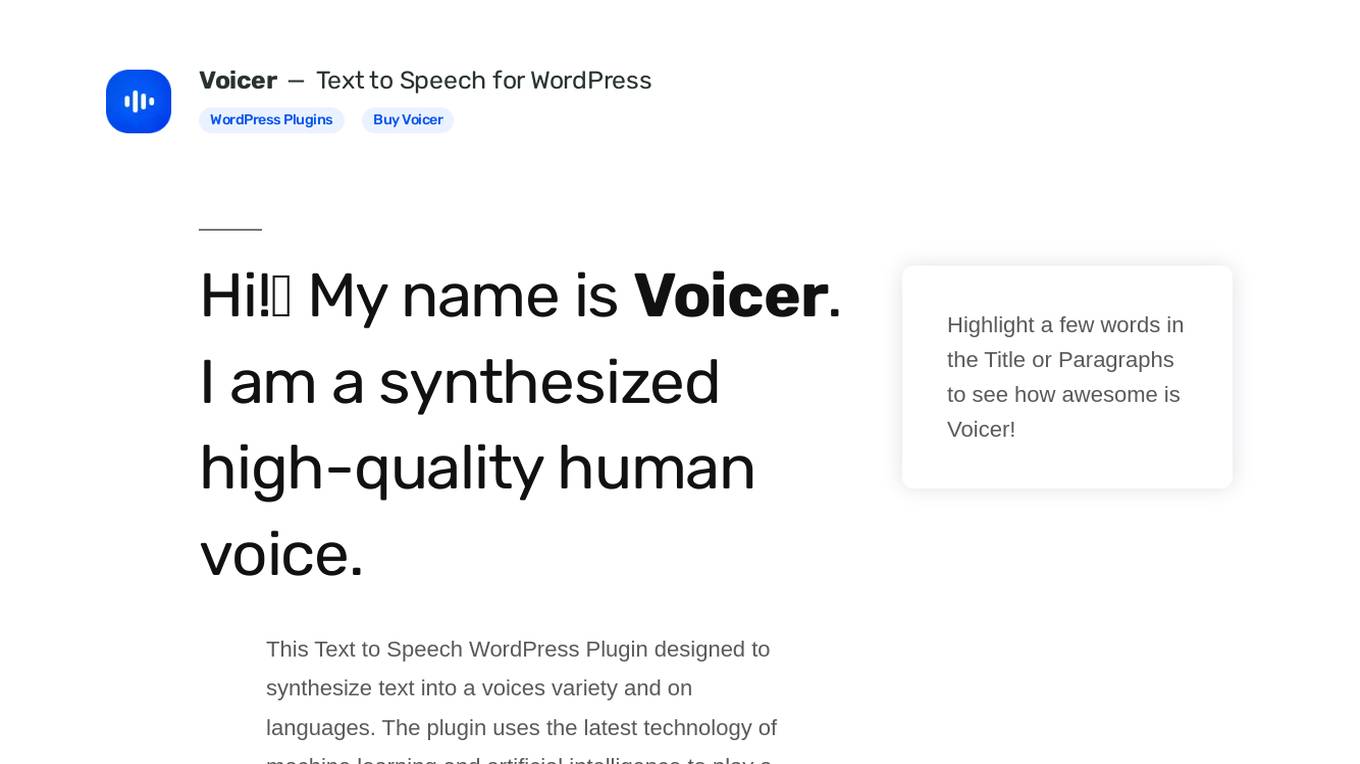
Voicer
Voicer is a Text to Speech WordPress Plugin that utilizes machine learning and artificial intelligence to synthesize text into high-quality human voices across 45+ languages and variants. It offers more than 275 human-like voices, works with all WordPress themes, and is perfect for RTL direction. The plugin applies advanced deep learning neural network algorithms to create lifelike interactions with users, transforming customer service and device interaction.

Tilde.ai
Tilde.ai is a language technology platform that offers a wide range of AI-powered solutions for translation, speech technologies, and conversational AI. It combines human and artificial intelligence to help people connect and work efficiently. The platform provides machine translation, speech-to-text conversion, text-to-speech synthesis, real-time transcription, AI chatbots, internal knowledge assistants, and meeting support services. Tilde.ai aims to bridge language barriers and enhance communication by leveraging advanced language technologies.
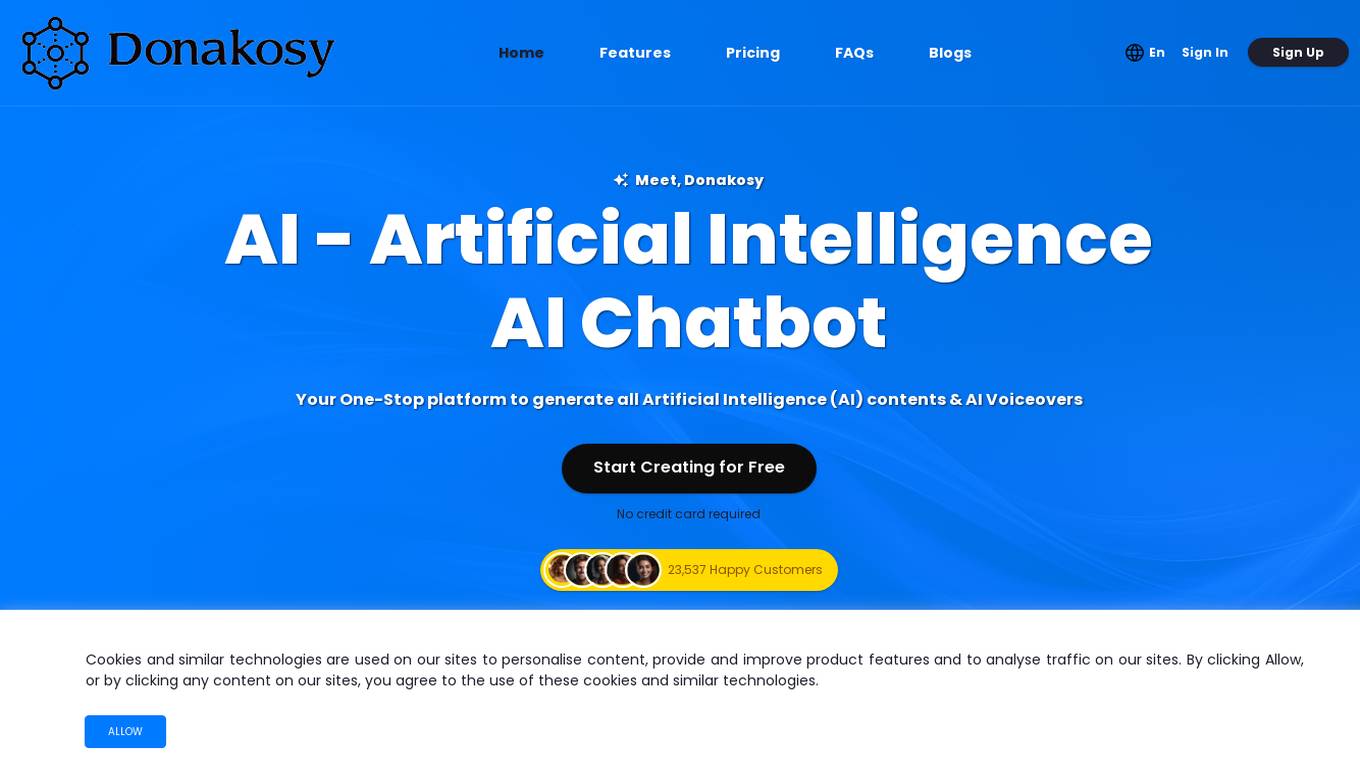
Donakosy
Donakosy is an AI-powered content and voiceover generation platform that helps professionals and content creators save time and effort while creating high-quality written content and lifelike voiceovers. With its advanced AI algorithms and machine learning capabilities, Donakosy analyzes vast amounts of data to understand patterns, styles, and context, enabling it to generate content that is not only accurate and relevant but also exhibits a human-like touch. The platform offers a wide range of features, including the ability to generate written content up to 100K characters, synthesize voices in multiple languages, and provide lifelike audio content. Donakosy is designed to be user-friendly and accessible to individuals with no prior AI knowledge or experience, making it a valuable tool for professionals and content creators alike.
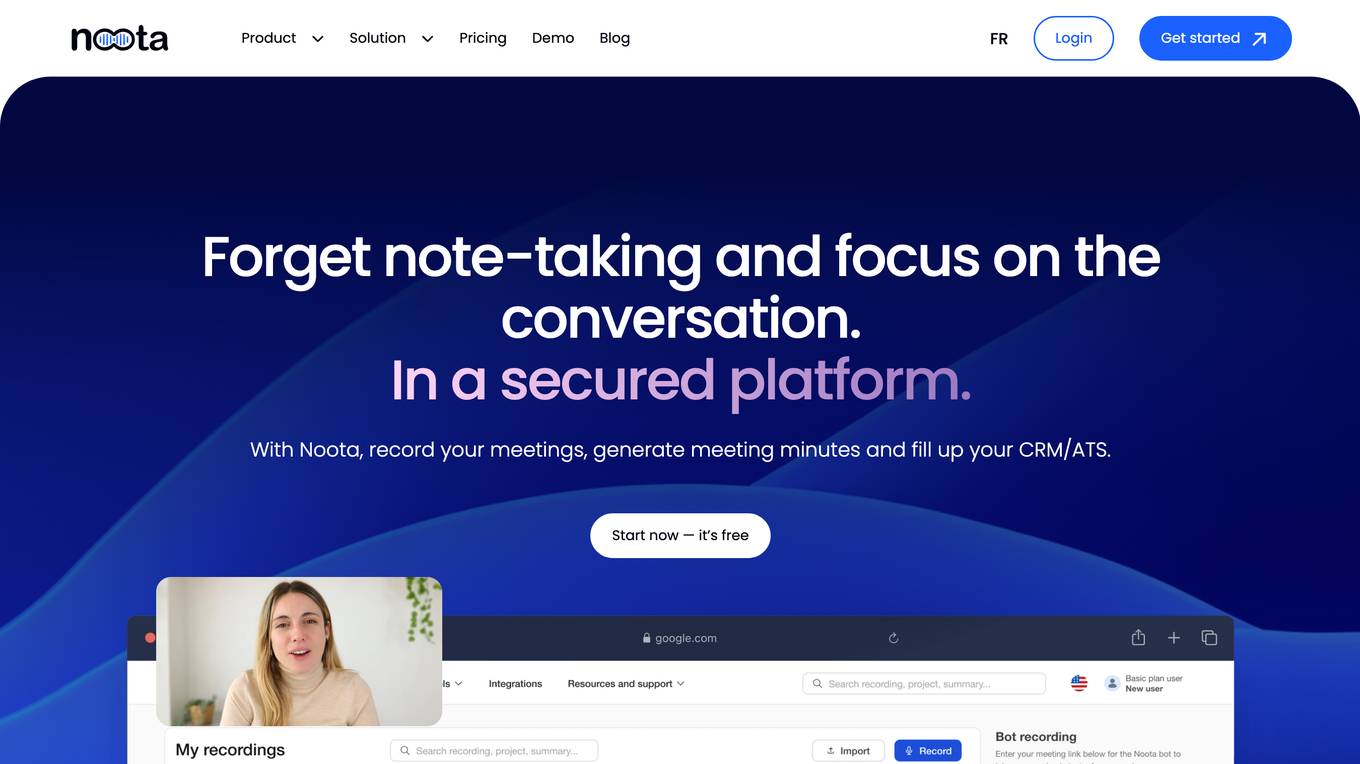
Noota
Noota is a conversational intelligence platform that helps businesses record, transcribe, and generate meeting minutes. It also offers features such as automated interview reports, structured interviews, automated ATS job ad generator, generic meeting recorder, and conversational intelligence. Noota integrates with popular video conferencing platforms such as Zoom, Teams, and Meet, and offers a variety of subscription plans to meet the needs of different businesses.
Dewagear CreateAI
Dewagear CreateAI is an advanced AI tool that serves as a platform for creating AI Virtual Assistants and generating various AI content, including AI Voiceovers, AI Images, AI Speech to Text, and AI Codes. It offers a diverse range of features and templates to assist users in creating high-quality content efficiently and effectively. With a focus on personalization, security, and user experience, Dewagear CreateAI aims to empower individuals in the digital space by providing cutting-edge AI solutions.

Nubrain.ai
**Nubrain.ai** is a comprehensive AI toolkit that offers a wide range of features to streamline content creation and enhance productivity. With its user-friendly interface and powerful AI capabilities, Nubrain.ai empowers users to generate unique and engaging content, create stunning visuals, transcribe speech, synthesize voiceovers, and write code effortlessly. The platform's advanced features, such as custom template creation, multilingual support, and seamless payment options, make it an ideal solution for individuals, teams, and businesses seeking to optimize their content creation process.
SocialMate Creator
SocialMate Creator is a comprehensive AI-powered platform that provides a wide range of content creation tools. With SocialMate Creator, you can generate text, images, AI voiceovers, and text-to-speech conversions. The platform is designed to be user-friendly and accessible to users of all technical backgrounds. SocialMate Creator offers a variety of subscription plans and prepaid packs to meet the needs of different users. The platform also provides free trials and demos to allow users to experience the full capabilities of the platform before making a subscription decision.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
PlayAI
PlayAI is a leading AI voice generator and text-to-speech platform that offers a wide range of features to create high-quality audio content. With over 206 natural-sounding voices in 30+ languages, users can generate multi-speaker AI voices indistinguishable from humans. The platform allows users to enhance audio with speech styles, pronunciations, and SSML tags, making it ideal for audiobooks, YouTube videos, podcasts, and more. PlayAI's AI voice generator works by converting written text into natural-sounding speech through advanced text-to-speech technology, with real-time conversion and customizability options. The platform also supports voice cloning, API integration, and industry-leading AI voice products for various applications.
Synthesizer V
Dreamtonics is a Tokyo-based startup company specializing in computer music and speech technologies. They build music software to suit customers' creativity needs and offer technology licensing and the creation of artificial voices as a service for corporate clients. Their flagship product is Synthesizer V, a singing synthesizer that combines a powerful audio processing engine with an intuitive user interface. With Synthesizer V, users can create their own songs by sketching out the melody and filling in the lyrics.
Everbility
Everbility is an AI-powered clinical documentation tool designed for Allied Health Professionals. It helps in writing reports, synthesizing client notes, brainstorming ideas, and focusing on client care. The tool saves time by generating progress notes, letters, and assessment reports, while ensuring data privacy and compliance with regulations like HIPAA and Australian Privacy Principles.

Emvoice
Emvoice is a cutting-edge vocal synthesis platform that empowers users to create realistic and expressive synthetic voices. With its advanced AI algorithms and intuitive interface, Emvoice makes it easy to generate high-quality voiceovers, audiobooks, and other audio content. Whether you're a professional voice actor, a content creator, or simply looking to add a touch of personality to your projects, Emvoice has the tools you need to bring your words to life.
Project Infinite
Project Infinite is a revolutionary platform that empowers you to create an AI-powered version of yourself, ensuring your stories, wisdom, and legacy live on for generations to come. Through an intuitive storytelling platform, you can share your experiences, thoughts, and memories, which are then synthesized by advanced AI algorithms to create a dynamic digital persona that mimics your speech patterns, values, and even sense of humor. This Infinite Avatar can interact with your loved ones anytime, anywhere, providing guidance, inspiration, and a comforting connection to your presence.
Synthesis
Synthesis is a web-based application that allows users to create realistic-sounding synthetic speech from text. The application uses a variety of AI techniques, including natural language processing and machine learning, to generate speech that is both natural-sounding and easy to understand. Synthesis can be used for a variety of purposes, including creating voiceovers for videos, podcasts, and presentations.
VoiceCanvas
VoiceCanvas is an advanced AI-powered multilingual voice synthesis and voice cloning platform that offers instant text-to-speech in over 40 languages. It utilizes cutting-edge AI technology to provide high-quality voice synthesis with natural intonation and rhythm, along with personalized voice cloning for more human-like AI speech. Users can upload voice samples, have AI analyze voice features, generate personalized AI voice models, input text for conversion, and apply the cloned AI voice model to generate natural voice speech. VoiceCanvas is highly praised by language learners, content creators, teachers, business owners, voice actors, and educators for its exceptional voice quality, multiple language support, and ease of use in creating voiceovers, learning materials, and podcast content.
14 - Open Source AI Tools
bolna
Bolna is an open-source platform for building voice-driven conversational applications using large language models (LLMs). It provides a comprehensive set of tools and integrations to handle various aspects of voice-based interactions, including telephony, transcription, LLM-based conversation handling, and text-to-speech synthesis. Bolna simplifies the process of creating voice agents that can perform tasks such as initiating phone calls, transcribing conversations, generating LLM-powered responses, and synthesizing speech. It supports multiple providers for each component, allowing users to customize their setup based on their specific needs. Bolna is designed to be easy to use, with a straightforward local setup process and well-documented APIs. It is also extensible, enabling users to integrate with other telephony providers or add custom functionality.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.

nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.

AudioLLM
AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.
FireRedTTS
FireRedTTS is a foundation text-to-speech framework designed for industry-level generative speech applications. It offers a rich-punctuation model with expanded punctuation coverage and enhanced audio production consistency. The tool provides pre-trained checkpoints, inference code, and an interactive demo space. Users can clone the repository, create a conda environment, download required model files, and utilize the tool for synthesizing speech in various languages. FireRedTTS aims to enhance stability and provide controllable human-like speech generation capabilities.
ASR-LLM-TTS
ASR-LLM-TTS is a repository that provides detailed tutorials for setting up the environment, including installing anaconda, ffmpeg, creating virtual environments, and installing necessary libraries such as pytorch, torchaudio, edge-tts, funasr, and more. It also introduces features like voiceprint recognition, custom wake words, and conversation history memory. The repository combines CosyVoice for speech synthesis, SenceVoice for speech recognition, and QWen2.5 for dialogue understanding. It offers multiple speech synthesis methods including CoosyVoice, pyttsx3, and edgeTTS, with scripts for interactive inference provided. The repository aims to enable real-time speech interaction and multi-modal interactions involving audio and video.
BrowserAI
BrowserAI is a production-ready tool that allows users to run AI models directly in the browser, offering simplicity, speed, privacy, and open-source capabilities. It provides WebGPU acceleration for fast inference, zero server costs, offline capability, and developer-friendly features. Perfect for web developers, companies seeking privacy-conscious AI solutions, researchers experimenting with browser-based AI, and hobbyists exploring AI without infrastructure overhead. The tool supports various AI tasks like text generation, speech recognition, and text-to-speech, with pre-configured popular models ready to use. It offers a simple SDK with multiple engine support and seamless switching between MLC and Transformers engines.
MemoAI
MemoAI is an AI-powered tool that provides podcast, video-to-text, and subtitling capabilities for immediate use. It supports audio and video transcription, model selection for paragraph effects, local subtitles translation, text translation using Google, Microsoft, Volcano Translation, DeepL, and AI Translation, speech synthesis in multiple languages, and exporting text and subtitles in common formats. MemoAI is designed to simplify the process of transcribing, translating, and creating subtitles for various media content.
simulflow
Simulflow is a Clojure framework for building real-time voice-enabled AI applications using a data-driven, functional approach. It provides a composable pipeline architecture for processing audio, text, and AI interactions with built-in support for major AI providers. The framework uses processors that communicate through specialized frames to create voice-enabled AI agents, allowing for mental multitasking and rational thought. Simulflow offers a flow-based architecture, data-first design, streaming architecture, extensibility, flexible frame system, and built-in services for seamless integration with major AI providers. Users can easily swap components, add new functionality, or debug individual stages without affecting the entire system.
bella-openapi
Bella OpenAPI is an API gateway that provides rich AI capabilities, similar to openrouter. In addition to chat completion ability, it also offers text embedding, ASR, TTS, image-to-image, and text-to-image AI capabilities. It integrates billing, rate limiting, and resource management functions. All integrated capabilities have been validated in large-scale production environments. The tool supports various AI capabilities, metadata management, unified login service, billing and rate limiting, and has been validated in large-scale production environments for stability and reliability. It offers a user-friendly experience with Java-friendly technology stack, convenient cloud-based experience service, and Dockerized deployment.

siliconflow-plugin
SiliconFlow-PLUGIN (SF-PLUGIN) is a versatile AI integration plugin for the Yunzai robot framework, supporting multiple AI services and models. It includes features such as AI drawing, intelligent conversations, real-time search, text-to-speech synthesis, resource management, link handling, video parsing, group functions, WebSocket support, and Jimeng-Api interface. The plugin offers functionalities for drawing, conversation, search, image link retrieval, video parsing, group interactions, and more, enhancing the capabilities of the Yunzai framework.
Ai-with-Chucky-Colab-Notebooks
Ai-with-Chucky-Colab-Notebooks is a collection of Colab notebooks optimized for various AI tasks. The notebooks provide a comfortable user interface and are designed to enhance the efficiency of AI experiments. The repository includes tools like Z-Image Turbo Pro and Kani TTS-2 for English text-to-speech synthesis. Users can easily access and run these notebooks in Google Colab, making it convenient for AI enthusiasts and researchers to experiment with different AI models and techniques.
20 - OpenAI Gpts

PANˈDÔRƏ
Pandora is a Posthuman Prompt Engineer powered by the MANNS engine. Surpass human creative limitations by synthesizing diverse knowledge, advanced pattern recognition, and algorithmic creativity

AstroLex
Expertly guides users to identify gaps in research by analyzing and summarizing academic papers.


AI Debate Synthesizer OPED
Game-like GPT in which five AIs dynamically debate a given "theme" and lead to a proposal-based conclusion.
Work Contribution Record Table Synthesizer
Guides in creating a Work Contribution Record Table.