
nexa-sdk
Run frontier LLMs and VLMs with day-0 model support across GPU, NPU, and CPU, with comprehensive runtime coverage for PC (Python/C++), mobile (Android & iOS), and Linux/IoT (Arm64 & x86 Docker). Supporting OpenAI GPT-OSS, IBM Granite-4, Qwen-3-VL, Gemma-3n, Ministral-3, and more.
Stars: 7726

Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.
README:




NexaSDK lets you build the smartest and fastest on-device AI with minimum energy. It is a highly performant local inference framework that runs the latest multimodal AI models locally on NPU, GPU, and CPU - across Android, Windows, Linux, macOS, and iOS devices with a few lines of code.
NexaSDK supports latest models weeks or months before anyone else — Qwen3-VL, DeepSeek-OCR, Gemma3n (Vision), and more.
⭐ Star this repo to keep up with exciting updates and new releases about latest on-device AI capabilities.
- Qualcomm featured us 3 times in official blogs.
- Qwen featured us for Day-0 Qwen3-VL support on NPU, GPU, and CPU. We were 3 weeks ahead of Ollama and llama.cpp on GGUF support, and no one else supports it on NPU to date.
- IBM featured our NexaML inference engine alongside vLLM, llama.cpp, and MLX in official IBM blog and also for Day-0 Granite 4.0 support.
- Google featured us for EmbeddingGemma Day-0 NPU support.
- AMD featured us for enabling SDXL-turbo image generation on AMD NPU.
- NVIDIA featured Hyperlink, a viral local AI app powered by NexaSDK, in their official blog.
- Microsoft presented us on stage at Microsoft Ignite 2025 as official partner.
- Intel featured us for Intel NPU support in NexaSDK.
| Platform | Links |
|---|---|
| 🖥️ CLI | Quick Start | Docs |
| 🐍 Python | Quick Start | Docs |
| 🤖 Android | Quick Start | Docs |
| 🐳 Linux Docker | Quick Start | Docs |
| 🍎 iOS | Quick Start | Docs |
Download:
| Windows | macOS | Linux |
|---|---|---|
| arm64 (Qualcomm NPU) | arm64 (Apple Silicon) | arm64 |
| x64 (Intel/AMD NPU) | x64 | x64 |
Run your first model:
# Chat with Qwen3
nexa infer ggml-org/Qwen3-1.7B-GGUF
# Multimodal: drag images into the CLI
nexa infer NexaAI/Qwen3-VL-4B-Instruct-GGUF
# NPU (Windows arm64 with Snapdragon X Elite)
nexa infer NexaAI/OmniNeural-4B- Models: LLM, Multimodal, ASR, OCR, Rerank, Object Detection, Image Generation, Embedding
- Formats: GGUF, MLX, NEXA
- NPU Models: Model Hub
- 📖 CLI Reference Docs
pip install nexaaifrom nexaai import LLM, GenerationConfig, ModelConfig, LlmChatMessage
llm = LLM.from_(model="NexaAI/Qwen3-0.6B-GGUF", config=ModelConfig())
conversation = [
LlmChatMessage(role="user", content="Hello, tell me a joke")
]
prompt = llm.apply_chat_template(conversation)
for token in llm.generate_stream(prompt, GenerationConfig(max_tokens=100)):
print(token, end="", flush=True)- Models: LLM, Multimodal, ASR, OCR, Rerank, Object Detection, Image Generation, Embedding
- Formats: GGUF, MLX, NEXA
- NPU Models: Model Hub
- 📖 Python SDK Docs
Add to your app/AndroidManifest.xml
<application android:extractNativeLibs="true">Add to your build.gradle.kts:
dependencies {
implementation("ai.nexa:core:0.0.19")
}// Initialize SDK
NexaSdk.getInstance().init(this)
// Load and run model
VlmWrapper.builder()
.vlmCreateInput(VlmCreateInput(
model_name = "omni-neural",
model_path = "/data/data/your.app/files/models/OmniNeural-4B/files-1-1.nexa",
plugin_id = "npu",
config = ModelConfig()
))
.build()
.onSuccess { vlm ->
vlm.generateStreamFlow("Hello!", GenerationConfig()).collect { print(it) }
}- Requirements: Android minSdk 27, Qualcomm Snapdragon 8 Gen 4 Chip
- Models: LLM, Multimodal, ASR, OCR, Rerank, Embedding
- NPU Models: Supported Models
- 📖 Android SDK Docs
docker pull nexa4ai/nexasdk:latest
export NEXA_TOKEN="your_token_here"
docker run --rm -it --privileged \
-e NEXA_TOKEN \
nexa4ai/nexasdk:latest infer NexaAI/Granite-4.0-h-350M-NPU- Requirements: Qualcomm Dragonwing IQ9, ARM64 systems
- Models: LLM, VLM, ASR, CV, Rerank, Embedding
- NPU Models: Supported Models
- 📖 Linux Docker Docs
Download NexaSdk.xcframework and add to your Xcode project.
import NexaSdk
// Example: Speech Recognition
let asr = try Asr(plugin: .ane)
try await asr.load(from: modelURL)
let result = try await asr.transcribe(options: .init(audioPath: "audio.wav"))
print(result.asrResult.transcript)- Requirements: iOS 17.0+ / macOS 15.0+, Swift 5.9+
- Models: LLM, ASR, OCR, Rerank, Embedding
- ANE Models: Apple Neural Engine Models
- 📖 iOS SDK Docs
| Features | NexaSDK | Ollama | llama.cpp | LM Studio |
|---|---|---|---|---|
| NPU support | ✅ NPU-first | ❌ | ❌ | ❌ |
| Android/iOS SDK support | ✅ NPU/GPU/CPU support | ❌ | ||
| Linux support (Docker image) | ✅ | ✅ | ✅ | ❌ |
| Day-0 model support in GGUF, MLX, NEXA | ✅ | ❌ | ❌ | |
| Full multimodality support | ✅ Image, Audio, Text, Embedding, Rerank, ASR, TTS | |||
| Cross-platform support | ✅ Desktop, Mobile (Android, iOS), Automotive, IoT (Linux) | |||
| One line of code to run | ✅ | ✅ | ✅ | |
| OpenAI-compatible API + Function calling | ✅ | ✅ | ✅ | ✅ |
Legend:
✅ Supported |
We would like to thank the following projects:
NexaSDK uses a dual licensing model:
Licensed under Apache License 2.0.
- Personal Use: Free license key available from Nexa AI Model Hub. Each key activates 1 device for NPU usage.
- Commercial Use: Contact [email protected] for licensing.
For model launching partner, business inquiries, or any other questions, please schedule a call with us here.
Want more model support, backend support, device support or other features? We'd love to hear from you!
Feel free to submit an issue on our GitHub repository with your requests, suggestions, or feedback. Your input helps us prioritize what to build next.
Join our community:
- Discord
- Slack
- Nexa Wishlist — Request and vote for the models you want to run on-device.
Round 1: Build a working Android AI app that runs fully on-device on Qualcomm Hexagon NPU with NexaSDK.
Timeline (PT): Jan 15 → Feb 15 Prizes: $6,500 cash prize, Qualcomm official spotlight, flagship Snapdragon device, expert mentorship, and more
👉 Join & details: https://sdk.nexa.ai/bounty
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for nexa-sdk
Similar Open Source Tools
nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.

LocalLLMClient
LocalLLMClient is a Swift package designed to interact with local Large Language Models (LLMs) on Apple platforms. It supports GGUF, MLX models, and the FoundationModels framework, providing streaming API, multimodal capabilities, and tool calling functionalities. Users can easily integrate this tool to work with various models for text generation and processing. The package also includes advanced features for low-level API control and multimodal image processing. LocalLLMClient is experimental and subject to API changes, offering support for iOS, macOS, and Linux platforms.

GraphLLM
GraphLLM is a graph-based framework designed to process data using LLMs. It offers a set of tools including a web scraper, PDF parser, YouTube subtitles downloader, Python sandbox, and TTS engine. The framework provides a GUI for building and debugging graphs with advanced features like loops, conditionals, parallel execution, streaming of results, hierarchical graphs, external tool integration, and dynamic scheduling. GraphLLM is a low-level framework that gives users full control over the raw prompt and output of models, with a steeper learning curve. It is tested with llama70b and qwen 32b, under heavy development with breaking changes expected.
RWKV_APP
RWKV App is an experimental application that enables users to run Large Language Models (LLMs) offline on their edge devices. It offers a privacy-first, on-device LLM experience for everyday devices. Users can engage in multi-turn conversations, text-to-speech, visual understanding, and more, all without requiring an internet connection. The app supports switching between different models, running locally without internet, and exploring various AI tasks such as chat, speech generation, and visual understanding. It is built using Flutter and Dart FFI for cross-platform compatibility and efficient communication with the C++ inference engine. The roadmap includes integrating features into the RWKV Chat app, supporting more model weights, hardware, operating systems, and devices.
mllm
mllm is a fast and lightweight multimodal LLM inference engine for mobile and edge devices. It is a Plain C/C++ implementation without dependencies, optimized for multimodal LLMs like fuyu-8B, and supports ARM NEON and x86 AVX2. The engine offers 4-bit and 6-bit integer quantization, making it suitable for intelligent personal agents, text-based image searching/retrieval, screen VQA, and various mobile applications without compromising user privacy.
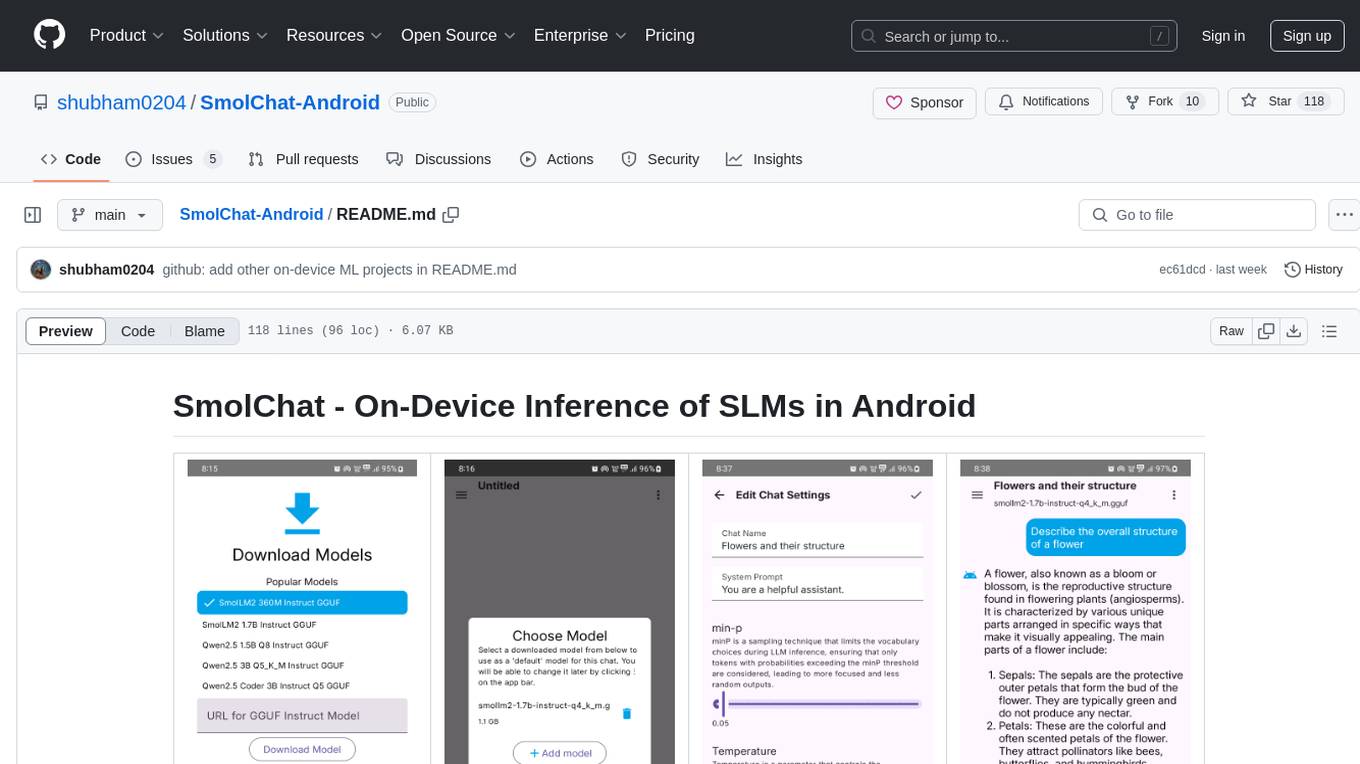
SmolChat-Android
SmolChat-Android is a mobile application that enables users to interact with local small language models (SLMs) on-device. Users can add/remove SLMs, modify system prompts and inference parameters, create downstream tasks, and generate responses. The app uses llama.cpp for model execution, ObjectBox for database storage, and Markwon for markdown rendering. It provides a simple, extensible codebase for on-device machine learning projects.

llm.nvim
llm.nvim is a universal plugin for a large language model (LLM) designed to enable users to interact with LLM within neovim. Users can customize various LLMs such as gpt, glm, kimi, and local LLM. The plugin provides tools for optimizing code, comparing code, translating text, and more. It also supports integration with free models from Cloudflare, Github models, siliconflow, and others. Users can customize tools, chat with LLM, quickly translate text, and explain code snippets. The plugin offers a flexible window interface for easy interaction and customization.

AIaW
AIaW is a next-generation LLM client with full functionality, lightweight, and extensible. It supports various basic functions such as streaming transfer, image uploading, and latex formulas. The tool is cross-platform with a responsive interface design. It supports multiple service providers like OpenAI, Anthropic, and Google. Users can modify questions, regenerate in a forked manner, and visualize conversations in a tree structure. Additionally, it offers features like file parsing, video parsing, plugin system, assistant market, local storage with real-time cloud sync, and customizable interface themes. Users can create multiple workspaces, use dynamic prompt word variables, extend plugins, and benefit from detailed design elements like real-time content preview, optimized code pasting, and support for various file types.
qwen-code
Qwen Code is an open-source AI agent optimized for Qwen3-Coder, designed to help users understand large codebases, automate tedious work, and expedite the shipping process. It offers an agentic workflow with rich built-in tools, a terminal-first approach with optional IDE integration, and supports both OpenAI-compatible API and Qwen OAuth authentication methods. Users can interact with Qwen Code in interactive mode, headless mode, IDE integration, and through a TypeScript SDK. The tool can be configured via settings.json, environment variables, and CLI flags, and offers benchmark results for performance evaluation. Qwen Code is part of an ecosystem that includes AionUi and Gemini CLI Desktop for graphical interfaces, and troubleshooting guides are available for issue resolution.

py-gpt
Py-GPT is a Python library that provides an easy-to-use interface for OpenAI's GPT-3 API. It allows users to interact with the powerful GPT-3 model for various natural language processing tasks. With Py-GPT, developers can quickly integrate GPT-3 capabilities into their applications, enabling them to generate text, answer questions, and more with just a few lines of code.

DB-GPT
DB-GPT is an open source AI native data app development framework with AWEL(Agentic Workflow Expression Language) and agents. It aims to build infrastructure in the field of large models, through the development of multiple technical capabilities such as multi-model management (SMMF), Text2SQL effect optimization, RAG framework and optimization, Multi-Agents framework collaboration, AWEL (agent workflow orchestration), etc. Which makes large model applications with data simpler and more convenient.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.
jadx-mcp-server
JADX-MCP-SERVER is a standalone Python server that interacts with JADX-AI-MCP Plugin to analyze Android APKs using LLMs like Claude. It enables live communication with decompiled Android app context, uncovering vulnerabilities, parsing manifests, and facilitating reverse engineering effortlessly. The tool combines JADX-AI-MCP and JADX MCP SERVER to provide real-time reverse engineering support with LLMs, offering features like quick analysis, vulnerability detection, AI code modification, static analysis, and reverse engineering helpers. It supports various MCP tools for fetching class information, text, methods, fields, smali code, AndroidManifest.xml content, strings.xml file, resource files, and more. Tested on Claude Desktop, it aims to support other LLMs in the future, enhancing Android reverse engineering and APK modification tools connectivity for easier reverse engineering purely from vibes.
ai21-python
The AI21 Labs Python SDK is a comprehensive tool for interacting with the AI21 API. It provides functionalities for chat completions, conversational RAG, token counting, error handling, and support for various cloud providers like AWS, Azure, and Vertex. The SDK offers both synchronous and asynchronous usage, along with detailed examples and documentation. Users can quickly get started with the SDK to leverage AI21's powerful models for various natural language processing tasks.
koog
Koog is a Kotlin-based framework for building and running AI agents entirely in idiomatic Kotlin. It allows users to create agents that interact with tools, handle complex workflows, and communicate with users. Key features include pure Kotlin implementation, MCP integration, embedding capabilities, custom tool creation, ready-to-use components, intelligent history compression, powerful streaming API, persistent agent memory, comprehensive tracing, flexible graph workflows, modular feature system, scalable architecture, and multiplatform support.

llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.
For similar tasks

open-llms
Open LLMs is a repository containing various Large Language Models licensed for commercial use. It includes models like T5, GPT-NeoX, UL2, Bloom, Cerebras-GPT, Pythia, Dolly, and more. These models are designed for tasks such as transfer learning, language understanding, chatbot development, code generation, and more. The repository provides information on release dates, checkpoints, papers/blogs, parameters, context length, and licenses for each model. Contributions to the repository are welcome, and it serves as a resource for exploring the capabilities of different language models.
speech-to-speech
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.
nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.
text2text
Text2Text is a comprehensive language modeling toolkit that offers a wide range of functionalities for text processing and generation. It provides tools for tokenization, embedding, TF-IDF calculations, BM25 scoring, indexing, translation, data augmentation, distance measurement, training/finetuning models, language identification, and serving models via a web server. The toolkit is designed to be user-friendly and efficient, offering a variety of features for natural language processing tasks.
generative-ai
This repository contains notebooks, code samples, sample apps, and other resources that demonstrate how to use, develop and manage generative AI workflows using Generative AI on Google Cloud, powered by Vertex AI. For more Vertex AI samples, please visit the Vertex AI samples Github repository.

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.
generative-ai-for-beginners
This course has 18 lessons. Each lesson covers its own topic so start wherever you like! Lessons are labeled either "Learn" lessons explaining a Generative AI concept or "Build" lessons that explain a concept and code examples in both **Python** and **TypeScript** when possible. Each lesson also includes a "Keep Learning" section with additional learning tools. **What You Need** * Access to the Azure OpenAI Service **OR** OpenAI API - _Only required to complete coding lessons_ * Basic knowledge of Python or Typescript is helpful - *For absolute beginners check out these Python and TypeScript courses. * A Github account to fork this entire repo to your own GitHub account We have created a **Course Setup** lesson to help you with setting up your development environment. Don't forget to star (🌟) this repo to find it easier later. ## 🧠 Ready to Deploy? If you are looking for more advanced code samples, check out our collection of Generative AI Code Samples in both **Python** and **TypeScript**. ## 🗣️ Meet Other Learners, Get Support Join our official AI Discord server to meet and network with other learners taking this course and get support. ## 🚀 Building a Startup? Sign up for Microsoft for Startups Founders Hub to receive **free OpenAI credits** and up to **$150k towards Azure credits to access OpenAI models through Azure OpenAI Services**. ## 🙏 Want to help? Do you have suggestions or found spelling or code errors? Raise an issue or Create a pull request ## 📂 Each lesson includes: * A short video introduction to the topic * A written lesson located in the README * Python and TypeScript code samples supporting Azure OpenAI and OpenAI API * Links to extra resources to continue your learning ## 🗃️ Lessons | | Lesson Link | Description | Additional Learning | | :-: | :------------------------------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------: | ------------------------------------------------------------------------------ | | 00 | Course Setup | **Learn:** How to Setup Your Development Environment | Learn More | | 01 | Introduction to Generative AI and LLMs | **Learn:** Understanding what Generative AI is and how Large Language Models (LLMs) work. | Learn More | | 02 | Exploring and comparing different LLMs | **Learn:** How to select the right model for your use case | Learn More | | 03 | Using Generative AI Responsibly | **Learn:** How to build Generative AI Applications responsibly | Learn More | | 04 | Understanding Prompt Engineering Fundamentals | **Learn:** Hands-on Prompt Engineering Best Practices | Learn More | | 05 | Creating Advanced Prompts | **Learn:** How to apply prompt engineering techniques that improve the outcome of your prompts. | Learn More | | 06 | Building Text Generation Applications | **Build:** A text generation app using Azure OpenAI | Learn More | | 07 | Building Chat Applications | **Build:** Techniques for efficiently building and integrating chat applications. | Learn More | | 08 | Building Search Apps Vector Databases | **Build:** A search application that uses Embeddings to search for data. | Learn More | | 09 | Building Image Generation Applications | **Build:** A image generation application | Learn More | | 10 | Building Low Code AI Applications | **Build:** A Generative AI application using Low Code tools | Learn More | | 11 | Integrating External Applications with Function Calling | **Build:** What is function calling and its use cases for applications | Learn More | | 12 | Designing UX for AI Applications | **Learn:** How to apply UX design principles when developing Generative AI Applications | Learn More | | 13 | Securing Your Generative AI Applications | **Learn:** The threats and risks to AI systems and methods to secure these systems. | Learn More | | 14 | The Generative AI Application Lifecycle | **Learn:** The tools and metrics to manage the LLM Lifecycle and LLMOps | Learn More | | 15 | Retrieval Augmented Generation (RAG) and Vector Databases | **Build:** An application using a RAG Framework to retrieve embeddings from a Vector Databases | Learn More | | 16 | Open Source Models and Hugging Face | **Build:** An application using open source models available on Hugging Face | Learn More | | 17 | AI Agents | **Build:** An application using an AI Agent Framework | Learn More | | 18 | Fine-Tuning LLMs | **Learn:** The what, why and how of fine-tuning LLMs | Learn More |
cog-comfyui
Cog-comfyui allows users to run ComfyUI workflows on Replicate. ComfyUI is a visual programming tool for creating and sharing generative art workflows. With cog-comfyui, users can access a variety of pre-trained models and custom nodes to create their own unique artworks. The tool is easy to use and does not require any coding experience. Users simply need to upload their API JSON file and any necessary input files, and then click the "Run" button. Cog-comfyui will then generate the output image or video file.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.