
aichat
All-in-one LLM CLI tool featuring Shell Assistant, Chat-REPL, RAG, AI Tools & Agents, with access to OpenAI, Claude, Gemini, Ollama, Groq, and more.
Stars: 6192
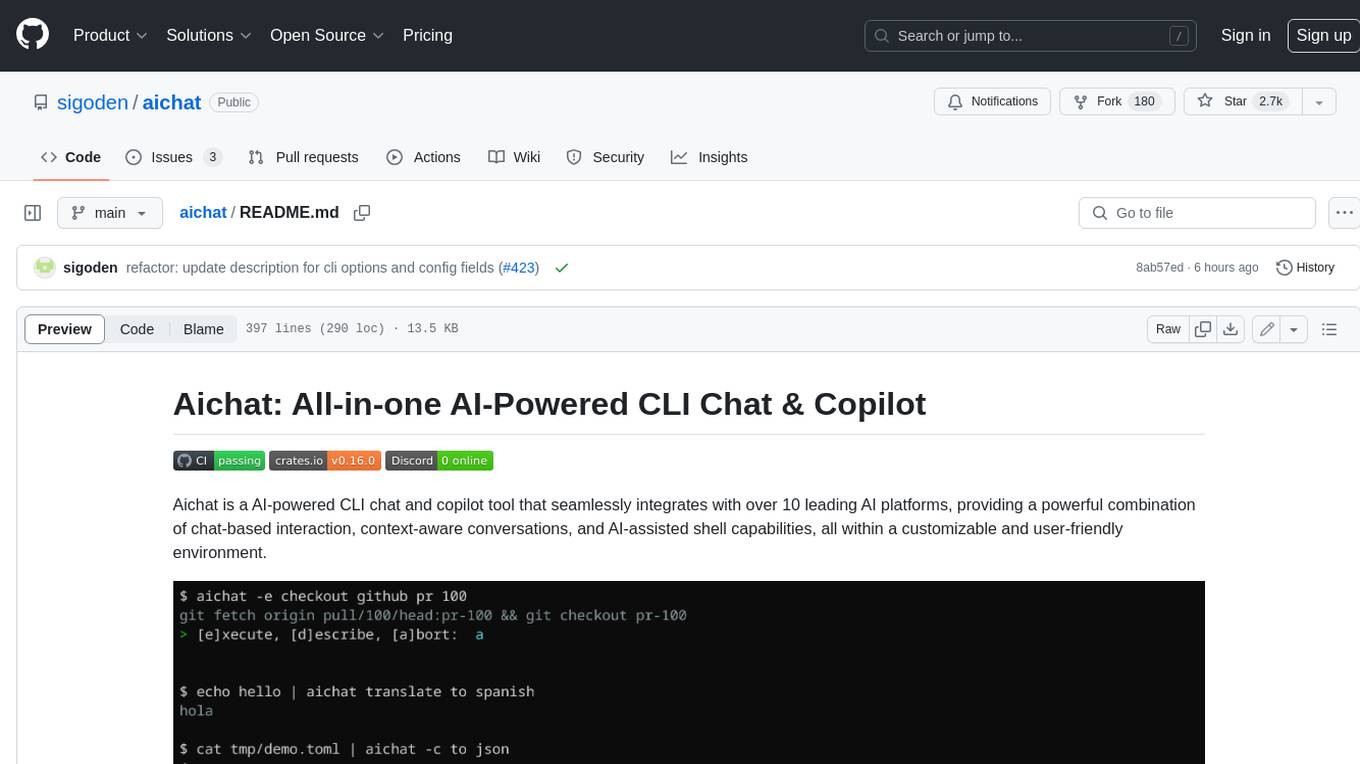
Aichat is an AI-powered CLI chat and copilot tool that seamlessly integrates with over 10 leading AI platforms, providing a powerful combination of chat-based interaction, context-aware conversations, and AI-assisted shell capabilities, all within a customizable and user-friendly environment.
README:
![]()


AIChat is an all-in-one LLM CLI tool featuring Shell Assistant, CMD & REPL Mode, RAG, AI Tools & Agents, and More.
-
Rust Developers:
cargo install aichat -
Homebrew/Linuxbrew Users:
brew install aichat -
Pacman Users:
pacman -S aichat -
Windows Scoop Users:
scoop install aichat -
Android Termux Users:
pkg install aichat
Download pre-built binaries for macOS, Linux, and Windows from GitHub Releases, extract them, and add the aichat binary to your $PATH.
Integrate seamlessly with over 20 leading LLM providers through a unified interface. Supported providers include OpenAI, Claude, Gemini (Google AI Studio), Ollama, Groq, Azure-OpenAI, VertexAI, Bedrock, Github Models, Mistral, Deepseek, AI21, XAI Grok, Cohere, Perplexity, Cloudflare, OpenRouter, Ernie, Qianwen, Moonshot, ZhipuAI, Lingyiwanwu, MiniMax, Deepinfra, VoyageAI, any OpenAI-Compatible API provider.
Explore powerful command-line functionalities with AIChat's CMD mode.
Experience an interactive Chat-REPL with features like tab autocompletion, multi-line input support, history search, configurable keybindings, and custom REPL prompts.
Elevate your command-line efficiency. Describe your tasks in natural language, and let AIChat transform them into precise shell commands. AIChat intelligently adjusts to your OS and shell environment.
Accept diverse input forms such as stdin, local files and directories, and remote URLs, allowing flexibility in data handling.
| Input | CMD | REPL |
|---|---|---|
| CMD | aichat hello |
|
| STDIN | cat data.txt | aichat |
|
| Last Reply | .file %% |
|
| Local files | aichat -f image.png -f data.txt |
.file image.png data.txt |
| Local directories | aichat -f dir/ |
.file dir/ |
| Remote URLs | aichat -f https://example.com |
.file https://example.com |
| External commands | aichat -f '`git diff`' |
.file `git diff` |
| Combine Inputs | aichat -f dir/ -f data.txt explain |
.file dir/ data.txt -- explain |
Customize roles to tailor LLM behavior, enhancing interaction efficiency and boosting productivity.
The role consists of a prompt and model configuration.
Maintain context-aware conversations through sessions, ensuring continuity in interactions.
The left side uses a session, while the right side does not use a session.
Streamline repetitive tasks by combining a series of REPL commands into a custom macro.
Integrate external documents into your LLM conversations for more accurate and contextually relevant responses.
Function calling supercharges LLMs by connecting them to external tools and data sources. This unlocks a world of possibilities, enabling LLMs to go beyond their core capabilities and tackle a wider range of tasks.
We have created a new repository https://github.com/sigoden/llm-functions to help you make the most of this feature.
Integrate external tools to automate tasks, retrieve information, and perform actions directly within your workflow.
AI Agent = Instructions (Prompt) + Tools (Function Callings) + Documents (RAG).
AIChat includes a lightweight built-in HTTP server for easy deployment.
$ aichat --serve
Chat Completions API: http://127.0.0.1:8000/v1/chat/completions
Embeddings API: http://127.0.0.1:8000/v1/embeddings
Rerank API: http://127.0.0.1:8000/v1/rerank
LLM Playground: http://127.0.0.1:8000/playground
LLM Arena: http://127.0.0.1:8000/arena?num=2
The LLM Arena is a web-based platform where you can compare different LLMs side-by-side.
Test with curl:
curl -X POST -H "Content-Type: application/json" -d '{
"model":"claude:claude-3-5-sonnet-20240620",
"messages":[{"role":"user","content":"hello"}],
"stream":true
}' http://127.0.0.1:8000/v1/chat/completionsA web application to interact with supported LLMs directly from your browser.
A web platform to compare different LLMs side-by-side.
AIChat supports custom dark and light themes, which highlight response text and code blocks.
- Chat-REPL Guide
- Command-Line Guide
- Role Guide
- Macro Guide
- RAG Guide
- Environment Variables
- Configuration Guide
- Custom Theme
- Custom REPL Prompt
- FAQ
Copyright (c) 2023-2025 aichat-developers.
AIChat is made available under the terms of either the MIT License or the Apache License 2.0, at your option.
See the LICENSE-APACHE and LICENSE-MIT files for license details.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for aichat
Similar Open Source Tools
aichat
Aichat is an AI-powered CLI chat and copilot tool that seamlessly integrates with over 10 leading AI platforms, providing a powerful combination of chat-based interaction, context-aware conversations, and AI-assisted shell capabilities, all within a customizable and user-friendly environment.
polaris
Polaris establishes a novel, industry‑certified standard to foster the development of impactful methods in AI-based drug discovery. This library is a Python client to interact with the Polaris Hub. It allows you to download Polaris datasets and benchmarks, evaluate a custom method against a Polaris benchmark, and create and upload new datasets and benchmarks.
star-vector
StarVector is a multimodal vision-language model for Scalable Vector Graphics (SVG) generation. It can be used to perform image2SVG and text2SVG generation. StarVector works directly in the SVG code space, leveraging visual understanding to apply accurate SVG primitives. It achieves state-of-the-art performance in producing compact and semantically rich SVGs. The tool provides Hugging Face model checkpoints for image2SVG vectorization, with models like StarVector-8B and StarVector-1B. It also offers datasets like SVG-Stack, SVG-Fonts, SVG-Icons, SVG-Emoji, and SVG-Diagrams for evaluation. StarVector can be trained using Deepspeed or FSDP for tasks like Image2SVG and Text2SVG generation. The tool provides a demo with options for HuggingFace generation or VLLM backend for faster generation speed.
HyperChat
HyperChat is an open Chat client that utilizes various LLM APIs to enhance the Chat experience and offer productivity tools through the MCP protocol. It supports multiple LLMs like OpenAI, Claude, Qwen, Deepseek, GLM, Ollama. The platform includes a built-in MCP plugin market for easy installation and also allows manual installation of third-party MCPs. Features include Windows and MacOS support, resource support, tools support, English and Chinese language support, built-in MCP client 'hypertools', 'fetch' + 'search', Bot support, Artifacts rendering, KaTeX for mathematical formulas, WebDAV synchronization, and a MCP plugin market. Future plans include permission pop-up, scheduled tasks support, Projects + RAG support, tools implementation by LLM, and a local shell + nodejs + js on web runtime environment.

agentscope
AgentScope is a multi-agent platform designed to empower developers to build multi-agent applications with large-scale models. It features three high-level capabilities: Easy-to-Use, High Robustness, and Actor-Based Distribution. AgentScope provides a list of `ModelWrapper` to support both local model services and third-party model APIs, including OpenAI API, DashScope API, Gemini API, and ollama. It also enables developers to rapidly deploy local model services using libraries such as ollama (CPU inference), Flask + Transformers, Flask + ModelScope, FastChat, and vllm. AgentScope supports various services, including Web Search, Data Query, Retrieval, Code Execution, File Operation, and Text Processing. Example applications include Conversation, Game, and Distribution. AgentScope is released under Apache License 2.0 and welcomes contributions.

nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.
pipecat
Pipecat is an open-source framework designed for building generative AI voice bots and multimodal assistants. It provides code building blocks for interacting with AI services, creating low-latency data pipelines, and transporting audio, video, and events over the Internet. Pipecat supports various AI services like speech-to-text, text-to-speech, image generation, and vision models. Users can implement new services and contribute to the framework. Pipecat aims to simplify the development of applications like personal coaches, meeting assistants, customer support bots, and more by providing a complete framework for integrating AI services.

VILA
VILA is a family of open Vision Language Models optimized for efficient video understanding and multi-image understanding. It includes models like NVILA, LongVILA, VILA-M3, VILA-U, and VILA-1.5, each offering specific features and capabilities. The project focuses on efficiency, accuracy, and performance in various tasks related to video, image, and language understanding and generation. VILA models are designed to be deployable on diverse NVIDIA GPUs and support long-context video understanding, medical applications, and multi-modal design.

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.
MaskLLM
MaskLLM is a learnable pruning method that establishes Semi-structured Sparsity in Large Language Models (LLMs) to reduce computational overhead during inference. It is scalable and benefits from larger training datasets. The tool provides examples for running MaskLLM with Megatron-LM, preparing LLaMA checkpoints, pre-tokenizing C4 data for Megatron, generating prior masks, training MaskLLM, and evaluating the model. It also includes instructions for exporting sparse models to Huggingface.
TokenPacker
TokenPacker is a novel visual projector that compresses visual tokens by 75%∼89% with high efficiency. It adopts a 'coarse-to-fine' scheme to generate condensed visual tokens, achieving comparable or better performance across diverse benchmarks. The tool includes TokenPacker for general use and TokenPacker-HD for high-resolution image understanding. It provides training scripts, checkpoints, and supports various compression ratios and patch numbers.

FlagEmbedding
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently: * **Long-Context LLM** : Activation Beacon * **Fine-tuning of LM** : LM-Cocktail * **Embedding Model** : Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding * **Reranker Model** : llm rerankers, BGE Reranker * **Benchmark** : C-MTEB
cortex.cpp
Cortex is a C++ AI engine with a Docker-like command-line interface and client libraries. It supports running AI models using ONNX, TensorRT-LLM, and llama.cpp engines. Cortex can function as a standalone server or be integrated as a library. The tool provides support for various engines and models, allowing users to easily deploy and interact with AI models. It offers a range of CLI commands for managing models, embeddings, and engines, as well as a REST API for interacting with models. Cortex is designed to simplify the deployment and usage of AI models in C++ applications.
livekit
LiveKit is an open source project providing scalable, multi-user conferencing based on WebRTC. It offers a server written in Go, client SDKs, and advanced features like speaker detection, end-to-end encryption, and SVC codecs. The tool is easy to deploy with support for JWT authentication and robust networking. LiveKit ecosystem includes agents for AI applications, tools like CLI and Docker image, and SDKs for both client and server-side development.

auto-news
Auto-News is an automatic news aggregator tool that utilizes Large Language Models (LLM) to pull information from various sources such as Tweets, RSS feeds, YouTube videos, web articles, Reddit, and journal notes. The tool aims to help users efficiently read and filter content based on personal interests, providing a unified reading experience and organizing information effectively. It features feed aggregation with summarization, transcript generation for videos and articles, noise reduction, task organization, and deep dive topic exploration. The tool supports multiple LLM backends, offers weekly top-k aggregations, and can be deployed on Linux/MacOS using docker-compose or Kubernetes.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.