
WeKnora
LLM-powered framework for deep document understanding, semantic retrieval, and context-aware answers using RAG paradigm.
Stars: 12950

WeKnora is a document understanding and semantic retrieval framework based on large language models (LLM), designed specifically for scenarios with complex structures and heterogeneous content. The framework adopts a modular architecture, integrating multimodal preprocessing, semantic vector indexing, intelligent recall, and large model generation reasoning to build an efficient and controllable document question-answering process. The core retrieval process is based on the RAG (Retrieval-Augmented Generation) mechanism, combining context-relevant segments with language models to achieve higher-quality semantic answers. It supports various document formats, intelligent inference, flexible extension, efficient retrieval, ease of use, and security and control. Suitable for enterprise knowledge management, scientific literature analysis, product technical support, legal compliance review, and medical knowledge assistance.
README:
![]()
Overview • Architecture • Key Features • Getting Started • API Reference • Developer Guide
WeKnora is an LLM-powered framework designed for deep document understanding and semantic retrieval, especially for handling complex, heterogeneous documents.
It adopts a modular architecture that combines multimodal preprocessing, semantic vector indexing, intelligent retrieval, and large language model inference. At its core, WeKnora follows the RAG (Retrieval-Augmented Generation) paradigm, enabling high-quality, context-aware answers by combining relevant document chunks with model reasoning.
Website: https://weknora.weixin.qq.com
v0.3.0 Highlights:
- 🏢 Shared Space: Shared space with member invitations, shared knowledge bases and agents across members, tenant-isolated retrieval
- 🧩 Agent Skills: Agent skills system with preloaded skills for smart-reasoning agent, sandboxed execution environment for security isolation
- 🤖 Custom Agents: Support for creating, configuring, and selecting custom agents with knowledge base selection modes (all/specified/disabled)
- 📊 Data Analyst Agent: Built-in Data Analyst agent with DataSchema tool for CSV/Excel analysis
- 🧠 Thinking Mode: Support thinking mode for LLM and agents, intelligent filtering of thinking content
- 🔍 Web Search Providers: Added Bing and Google search providers alongside DuckDuckGo
- 📋 Enhanced FAQ: Batch import dry run, similar questions, matched question in search results, large imports offloaded to object storage
- 🔑 API Key Auth: API Key authentication mechanism with Swagger documentation security
- 📎 In-Input Selection: Select knowledge bases and files directly in the input box with @mention display
- ☸️ Helm Chart: Complete Helm chart for Kubernetes deployment with Neo4j GraphRAG support
- 🌍 i18n: Added Korean (한국어) language support
- 🔒 Security Hardening: SSRF-safe HTTP client, enhanced SQL validation, MCP stdio transport security, sandbox-based execution
- ⚡ Infrastructure: Qdrant vector DB support, Redis ACL, configurable log level, Ollama embedding optimization,
DISABLE_REGISTRATIONcontrol
v0.2.0 Highlights:
- 🤖 Agent Mode: New ReACT Agent mode that can call built-in tools, MCP tools, and web search, providing comprehensive summary reports through multiple iterations and reflection
- 📚 Multi-Type Knowledge Bases: Support for FAQ and document knowledge base types, with new features including folder import, URL import, tag management, and online entry
- ⚙️ Conversation Strategy: Support for configuring Agent models, normal mode models, retrieval thresholds, and Prompts, with precise control over multi-turn conversation behavior
- 🌐 Web Search: Support for extensible web search engines with built-in DuckDuckGo search engine
- 🔌 MCP Tool Integration: Support for extending Agent capabilities through MCP, with built-in uvx and npx launchers, supporting multiple transport methods
- 🎨 New UI: Optimized conversation interface with Agent mode/normal mode switching, tool call process display, and comprehensive knowledge base management interface upgrade
- ⚡ Infrastructure Upgrade: Introduced MQ async task management, support for automatic database migration, and fast development mode
Important: Starting from v0.1.3, WeKnora includes login authentication functionality to enhance system security. For production deployments, we strongly recommend:
- Deploy WeKnora services in internal/private network environments rather than public internet
- Avoid exposing the service directly to public networks to prevent potential information leakage
- Configure proper firewall rules and access controls for your deployment environment
- Regularly update to the latest version for security patches and improvements

WeKnora employs a modern modular design to build a complete document understanding and retrieval pipeline. The system primarily includes document parsing, vector processing, retrieval engine, and large model inference as core modules, with each component being flexibly configurable and extendable.
- 🤖 Agent Mode: Support for ReACT Agent mode that can use built-in tools to retrieve knowledge bases, MCP tools, and web search tools to access external services, providing comprehensive summary reports through multiple iterations and reflection
- 🔍 Precise Understanding: Structured content extraction from PDFs, Word documents, images and more into unified semantic views
- 🧠 Intelligent Reasoning: Leverages LLMs to understand document context and user intent for accurate Q&A and multi-turn conversations
- 📚 Multi-Type Knowledge Bases: Support for FAQ and document knowledge base types, with folder import, URL import, tag management, and online entry capabilities
- 🔧 Flexible Extension: All components from parsing and embedding to retrieval and generation are decoupled for easy customization
- ⚡ Efficient Retrieval: Hybrid retrieval strategies combining keywords, vectors, and knowledge graphs, with cross-knowledge base retrieval support
- 🌐 Web Search: Support for extensible web search engines with built-in DuckDuckGo search engine
- 🔌 MCP Tool Integration: Support for extending Agent capabilities through MCP, with built-in uvx and npx launchers, supporting multiple transport methods
- ⚙️ Conversation Strategy: Support for configuring Agent models, normal mode models, retrieval thresholds, and Prompts, with precise control over multi-turn conversation behavior
- 🎯 User-Friendly: Intuitive web interface and standardized APIs for zero technical barriers
- 🔒 Secure & Controlled: Support for local deployment and private cloud, ensuring complete data sovereignty
| Scenario | Applications | Core Value |
|---|---|---|
| Enterprise Knowledge Management | Internal document retrieval, policy Q&A, operation manual search | Improve knowledge discovery efficiency, reduce training costs |
| Academic Research Analysis | Paper retrieval, research report analysis, scholarly material organization | Accelerate literature review, assist research decisions |
| Product Technical Support | Product manual Q&A, technical documentation search, troubleshooting | Enhance customer service quality, reduce support burden |
| Legal & Compliance Review | Contract clause retrieval, regulatory policy search, case analysis | Improve compliance efficiency, reduce legal risks |
| Medical Knowledge Assistance | Medical literature retrieval, treatment guideline search, case analysis | Support clinical decisions, improve diagnosis quality |
| Module | Support | Description |
|---|---|---|
| Agent Mode | ✅ ReACT Agent Mode | Support for using built-in tools to retrieve knowledge bases, MCP tools, and web search, with cross-knowledge base retrieval and multiple iterations |
| Knowledge Base Types | ✅ FAQ / Document | Support for creating FAQ and document knowledge base types, with folder import, URL import, tag management, and online entry |
| Document Formats | ✅ PDF / Word / Txt / Markdown / Images (with OCR / Caption) | Support for structured and unstructured documents with text extraction from images |
| Model Management | ✅ Centralized configuration, built-in model sharing | Centralized model configuration with model selection in knowledge base settings, support for multi-tenant shared built-in models |
| Embedding Models | ✅ Local models, BGE / GTE APIs, etc. | Customizable embedding models, compatible with local deployment and cloud vector generation APIs |
| Vector DB Integration | ✅ PostgreSQL (pgvector), Elasticsearch | Support for mainstream vector index backends, flexible switching for different retrieval scenarios |
| Retrieval Strategies | ✅ BM25 / Dense Retrieval / GraphRAG | Support for sparse/dense recall and knowledge graph-enhanced retrieval with customizable retrieve-rerank-generate pipelines |
| LLM Integration | ✅ Support for Qwen, DeepSeek, etc., with thinking/non-thinking mode switching | Compatible with local models (e.g., via Ollama) or external API services with flexible inference configuration |
| Conversation Strategy | ✅ Agent models, normal mode models, retrieval thresholds, Prompt configuration | Support for configuring Agent models, normal mode models, retrieval thresholds, online Prompt configuration, precise control over multi-turn conversation behavior |
| Web Search | ✅ Extensible search engines, DuckDuckGo / Google | Support for extensible web search engines with built-in DuckDuckGo search engine |
| MCP Tools | ✅ uvx, npx launchers, Stdio/HTTP Streamable/SSE | Support for extending Agent capabilities through MCP, with built-in uvx and npx launchers, supporting three transport methods |
| QA Capabilities | ✅ Context-aware, multi-turn dialogue, prompt templates | Support for complex semantic modeling, instruction control and chain-of-thought Q&A with configurable prompts and context windows |
| E2E Testing | ✅ Retrieval+generation process visualization and metric evaluation | End-to-end testing tools for evaluating recall hit rates, answer coverage, BLEU/ROUGE and other metrics |
| Deployment Modes | ✅ Support for local deployment / Docker images | Meets private, offline deployment and flexible operation requirements, with fast development mode support |
| User Interfaces | ✅ Web UI + RESTful API | Interactive interface and standard API endpoints, with Agent mode/normal mode switching and tool call process display |
| Task Management | ✅ MQ async tasks, automatic database migration | MQ-based async task state maintenance, support for automatic database schema and data migration during version upgrades |
Make sure the following tools are installed on your system:
# Clone the main repository
git clone https://github.com/Tencent/WeKnora.git
cd WeKnora# Copy example env file
cp .env.example .env
# Edit .env and set required values
# All variables are documented in the .env.example commentsCheck the images that need to be started in the .env file.
./scripts/start_all.shor
make start-allollama serve > /dev/null 2>&1 &- Minimum core services
docker compose up -d- All features enabled
docker-compose --profile full up -d- Tracing logs required
docker-compose --profile jaeger up -d- Neo4j knowledge graph required
docker-compose --profile neo4j up -d- Minio file storage service required
docker-compose --profile minio up -d- Multiple options combination
docker-compose --profile neo4j --profile minio up -d./scripts/start_all.sh --stop
# Or
make stop-allOnce started, services will be available at:
- Web UI:
http://localhost - Backend API:
http://localhost:8080 - Jaeger Tracing:
http://localhost:16686
WeKnora serves as the core technology framework for the WeChat Dialog Open Platform, providing a more convenient usage approach:
- Zero-code Deployment: Simply upload knowledge to quickly deploy intelligent Q&A services within the WeChat ecosystem, achieving an "ask and answer" experience
- Efficient Question Management: Support for categorized management of high-frequency questions, with rich data tools to ensure accurate, reliable, and easily maintainable answers
- WeChat Ecosystem Integration: Through the WeChat Dialog Open Platform, WeKnora's intelligent Q&A capabilities can be seamlessly integrated into WeChat Official Accounts, Mini Programs, and other WeChat scenarios, enhancing user interaction experiences
git clone https://github.com/Tencent/WeKnora
It is recommended to directly refer to the MCP Configuration Guide for configuration.
Configure the MCP client to connect to the server:
{
"mcpServers": {
"weknora": {
"args": [
"path/to/WeKnora/mcp-server/run_server.py"
],
"command": "python",
"env":{
"WEKNORA_API_KEY":"Enter your WeKnora instance, open developer tools, check the request header x-api-key starting with sk",
"WEKNORA_BASE_URL":"http(s)://your-weknora-address/api/v1"
}
}
}
}Run directly using stdio command:
pip install weknora-mcp-server
python -m weknora-mcp-server
To help users quickly configure various models and reduce trial-and-error costs, we've improved the original configuration file initialization method by adding a Web UI interface for model configuration. Before using, please ensure the code is updated to the latest version. The specific steps are as follows: If this is your first time using this project, you can skip steps ①② and go directly to steps ③④.
./scripts/start_all.sh --stopmake clean-db./scripts/start_all.shOn your first visit, you will be automatically redirected to the registration/login page. After completing registration, please create a new knowledge base and finish the relevant settings on its configuration page.
Knowledge Base Management
|
Conversation Settings
|
Agent Mode Tool Call Process
|
|
Knowledge Base Management: Support for creating FAQ and document knowledge base types, with multiple import methods including drag-and-drop, folder import, and URL import. Automatically identifies document structures and extracts core knowledge to establish indexes. Supports tag management and online entry. The system clearly displays processing progress and document status, achieving efficient knowledge base management.
Agent Mode: Support for ReACT Agent mode that can use built-in tools to retrieve knowledge bases, call user-configured MCP tools and web search tools to access external services, providing comprehensive summary reports through multiple iterations and reflection. Supports cross-knowledge base retrieval, allowing selection of multiple knowledge bases for simultaneous retrieval.
Conversation Strategy: Support for configuring Agent models, normal mode models, retrieval thresholds, and online Prompt configuration, with precise control over multi-turn conversation behavior and retrieval execution methods. The conversation input box supports Agent mode/normal mode switching, enabling/disabling web search, and selecting conversation models.
WeKnora supports transforming documents into knowledge graphs, displaying the relationships between different sections of the documents. Once the knowledge graph feature is enabled, the system analyzes and constructs an internal semantic association network that not only helps users understand document content but also provides structured support for indexing and retrieval, enhancing the relevance and breadth of search results.
For detailed configuration, please refer to the Knowledge Graph Configuration Guide.
Please refer to the MCP Configuration Guide for the necessary setup.
Troubleshooting FAQ: Troubleshooting FAQ
Detailed API documentation is available at: API Docs
If you need to frequently modify code, you don't need to rebuild Docker images every time! Use fast development mode:
# Method 1: Using Make commands (Recommended)
make dev-start # Start infrastructure
make dev-app # Start backend (new terminal)
make dev-frontend # Start frontend (new terminal)
# Method 2: One-click start
./scripts/quick-dev.sh
# Method 3: Using scripts
./scripts/dev.sh start # Start infrastructure
./scripts/dev.sh app # Start backend (new terminal)
./scripts/dev.sh frontend # Start frontend (new terminal)Development Advantages:
- ✅ Frontend modifications auto hot-reload (no restart needed)
- ✅ Backend modifications quick restart (5-10 seconds, supports Air hot-reload)
- ✅ No need to rebuild Docker images
- ✅ Support IDE breakpoint debugging
Detailed Documentation: Development Environment Quick Start
WeKnora/
├── client/ # go client
├── cmd/ # Main entry point
├── config/ # Configuration files
├── docker/ # docker images files
├── docreader/ # Document parsing app
├── docs/ # Project documentation
├── frontend/ # Frontend app
├── internal/ # Core business logic
├── mcp-server/ # MCP server
├── migrations/ # DB migration scripts
└── scripts/ # Shell scripts
We welcome community contributions! For suggestions, bugs, or feature requests, please submit an Issue or directly create a Pull Request.
- 🐛 Bug Fixes: Discover and fix system defects
- ✨ New Features: Propose and implement new capabilities
- 📚 Documentation: Improve project documentation
- 🧪 Test Cases: Write unit and integration tests
- 🎨 UI/UX Enhancements: Improve user interface and experience
- Fork the project to your GitHub account
-
Create a feature branch
git checkout -b feature/amazing-feature -
Commit changes
git commit -m 'Add amazing feature' -
Push branch
git push origin feature/amazing-feature - Create a Pull Request with detailed description of changes
- Follow Go Code Review Comments
- Format code using
gofmt - Add necessary unit tests
- Update relevant documentation
Use Conventional Commits standard:
feat: Add document batch upload functionality
fix: Resolve vector retrieval precision issue
docs: Update API documentation
test: Add retrieval engine test cases
refactor: Restructure document parsing module
Thanks to these excellent contributors:
This project is licensed under the MIT License. You are free to use, modify, and distribute the code with proper attribution.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for WeKnora
Similar Open Source Tools
WeKnora
WeKnora is a document understanding and semantic retrieval framework based on large language models (LLM), designed specifically for scenarios with complex structures and heterogeneous content. The framework adopts a modular architecture, integrating multimodal preprocessing, semantic vector indexing, intelligent recall, and large model generation reasoning to build an efficient and controllable document question-answering process. The core retrieval process is based on the RAG (Retrieval-Augmented Generation) mechanism, combining context-relevant segments with language models to achieve higher-quality semantic answers. It supports various document formats, intelligent inference, flexible extension, efficient retrieval, ease of use, and security and control. Suitable for enterprise knowledge management, scientific literature analysis, product technical support, legal compliance review, and medical knowledge assistance.

ApeRAG
ApeRAG is a production-ready platform for Retrieval-Augmented Generation (RAG) that combines Graph RAG, vector search, and full-text search with advanced AI agents. It is ideal for building Knowledge Graphs, Context Engineering, and deploying intelligent AI agents for autonomous search and reasoning across knowledge bases. The platform offers features like advanced index types, intelligent AI agents with MCP support, enhanced Graph RAG with entity normalization, multimodal processing, hybrid retrieval engine, MinerU integration for document parsing, production-grade deployment with Kubernetes, enterprise management features, MCP integration, and developer-friendly tools for customization and contribution.
wanwu
Wanwu AI Agent Platform is an enterprise-grade one-stop commercially friendly AI agent development platform designed for business scenarios. It provides enterprises with a safe, efficient, and compliant one-stop AI solution. The platform integrates cutting-edge technologies such as large language models and business process automation to build an AI engineering platform covering model full life-cycle management, MCP, web search, AI agent rapid development, enterprise knowledge base construction, and complex workflow orchestration. It supports modular architecture design, flexible functional expansion, and secondary development, reducing the application threshold of AI technology while ensuring security and privacy protection of enterprise data. It accelerates digital transformation, cost reduction, efficiency improvement, and business innovation for enterprises of all sizes.
accelerated-intelligent-document-processing-on-aws
Accelerated Intelligent Document Processing on AWS is a scalable, serverless solution for automated document processing and information extraction using AWS services. It combines OCR capabilities with generative AI to convert unstructured documents into structured data at scale. The solution features a serverless architecture built on AWS technologies, modular processing patterns, advanced classification support, few-shot example support, custom business logic integration, high throughput processing, built-in resilience, cost optimization, comprehensive monitoring, web user interface, human-in-the-loop integration, AI-powered evaluation, extraction confidence assessment, and document knowledge base query. The architecture uses nested CloudFormation stacks to support multiple document processing patterns while maintaining common infrastructure for queueing, tracking, and monitoring.
GhidrAssist
GhidrAssist is an advanced LLM-powered plugin for interactive reverse engineering assistance in Ghidra. It integrates Large Language Models (LLMs) to provide intelligent assistance for binary exploration and reverse engineering. The tool supports various OpenAI v1-compatible APIs, including local models and cloud providers. Key features include code explanation, interactive chat, custom queries, Graph-RAG knowledge system with semantic knowledge graph, community detection, security feature extraction, semantic graph tab, extended thinking/reasoning control, ReAct agentic mode, MCP integration, function calling, actions tab, RAG (Retrieval Augmented Generation), and RLHF dataset generation. The plugin uses a modular, service-oriented architecture with core services, Graph-RAG backend, data layer, and UI components.

cline-based-code-generator
HAI Code Generator is a cutting-edge tool designed to simplify and automate task execution while enhancing code generation workflows. Leveraging Specif AI, it streamlines processes like task execution, file identification, and code documentation through intelligent automation and AI-driven capabilities. Built on Cline's powerful foundation for AI-assisted development, HAI Code Generator boosts productivity and precision by automating task execution and integrating file management capabilities. It combines intelligent file indexing, context generation, and LLM-driven automation to minimize manual effort and ensure task accuracy. Perfect for developers and teams aiming to enhance their workflows.
suna
Kortix is an open-source platform designed to build, manage, and train AI agents for various tasks. It allows users to create autonomous agents, from general-purpose assistants to specialized automation tools. The platform offers capabilities such as browser automation, file management, web intelligence, system operations, API integrations, and agent building tools. Users can create custom agents tailored to specific domains, workflows, or business needs, enabling tasks like research & analysis, browser automation, file & document management, data processing & analysis, and system administration.
heurist-agent-framework
Heurist Agent Framework is a flexible multi-interface AI agent framework that allows processing text and voice messages, generating images and videos, interacting across multiple platforms, fetching and storing information in a knowledge base, accessing external APIs and tools, and composing complex workflows using Mesh Agents. It supports various platforms like Telegram, Discord, Twitter, Farcaster, REST API, and MCP. The framework is built on a modular architecture and provides core components, tools, workflows, and tool integration with MCP support.
synmetrix
Synmetrix is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube.js to consolidate metrics from various sources and distribute them downstream via a SQL API. Use cases include data democratization, business intelligence and reporting, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.

mlcraft
Synmetrix (prev. MLCraft) is an open source data engineering platform and semantic layer for centralized metrics management. It provides a complete framework for modeling, integrating, transforming, aggregating, and distributing metrics data at scale. Key features include data modeling and transformations, semantic layer for unified data model, scheduled reports and alerts, versioning, role-based access control, data exploration, caching, and collaboration on metrics modeling. Synmetrix leverages Cube (Cube.js) for flexible data models that consolidate metrics from various sources, enabling downstream distribution via a SQL API for integration into BI tools, reporting, dashboards, and data science. Use cases include data democratization, business intelligence, embedded analytics, and enhancing accuracy in data handling and queries. The tool speeds up data-driven workflows from metrics definition to consumption by combining data engineering best practices with self-service analytics capabilities.
CortexON
CortexON is an open-source, multi-agent AI system designed to automate and simplify everyday tasks. It integrates specialized agents like Web Agent, File Agent, Coder Agent, Executor Agent, and API Agent to accomplish user-defined objectives. CortexON excels at executing complex workflows, research tasks, technical operations, and business process automations by dynamically coordinating the agents' unique capabilities. It offers advanced research automation, multi-agent orchestration, integration with third-party APIs, code generation and execution, efficient file and data management, and personalized task execution for travel planning, market analysis, educational content creation, and business intelligence.

aigne-framework
AIGNE Framework is a functional AI application development framework designed to simplify and accelerate the process of building modern applications. It combines functional programming features, powerful artificial intelligence capabilities, and modular design principles to help developers easily create scalable solutions. With key features like modular design, TypeScript support, multiple AI model support, flexible workflow patterns, MCP protocol integration, code execution capabilities, and Blocklet ecosystem integration, AIGNE Framework offers a comprehensive solution for developers. The framework provides various workflow patterns such as Workflow Router, Workflow Sequential, Workflow Concurrency, Workflow Handoff, Workflow Reflection, Workflow Orchestration, Workflow Code Execution, and Workflow Group Chat to address different application scenarios efficiently. It also includes built-in MCP support for running MCP servers and integrating with external MCP servers, along with packages for core functionality, agent library, CLI, and various models like OpenAI, Gemini, Claude, and Nova.
PDF_Accessibility
This repository provides two complementary solutions for PDF accessibility: PDF-to-PDF Remediation processes PDFs while maintaining the PDF format, and PDF-to-HTML Remediation converts PDFs to accessible HTML format. Both solutions leverage AWS services and generative AI to improve content accessibility according to WCAG 2.1 Level AA standards. The repository includes automated deployment scripts, testing instructions, architecture overviews, troubleshooting guides, and monitoring solutions for both PDF-to-PDF and PDF-to-HTML remediation. Users can contribute to the project and seek support via email or GitHub issues.
JamAIBase
JamAI Base is an open-source platform integrating SQLite and LanceDB databases with managed memory and RAG capabilities. It offers built-in LLM, vector embeddings, and reranker orchestration accessible through a spreadsheet-like UI and REST API. Users can transform static tables into dynamic entities, facilitate real-time interactions, manage structured data, and simplify chatbot development. The tool focuses on ease of use, scalability, flexibility, declarative paradigm, and innovative RAG techniques, making complex data operations accessible to users with varying technical expertise.
gateway
CentralMind Gateway is an AI-first data gateway that securely connects any data source and automatically generates secure, LLM-optimized APIs. It filters out sensitive data, adds traceability, and optimizes for AI workloads. Suitable for companies deploying AI agents for customer support and analytics.
obsidian-llmsider
LLMSider is an AI assistant plugin for Obsidian that offers flexible multi-model support, deep workflow integration, privacy-first design, and a professional tool ecosystem. It provides comprehensive AI capabilities for personal knowledge management, from intelligent writing assistance to complex task automation, making AI a capable assistant for thinking and creating while ensuring data privacy.
For similar tasks
WeKnora
WeKnora is a document understanding and semantic retrieval framework based on large language models (LLM), designed specifically for scenarios with complex structures and heterogeneous content. The framework adopts a modular architecture, integrating multimodal preprocessing, semantic vector indexing, intelligent recall, and large model generation reasoning to build an efficient and controllable document question-answering process. The core retrieval process is based on the RAG (Retrieval-Augmented Generation) mechanism, combining context-relevant segments with language models to achieve higher-quality semantic answers. It supports various document formats, intelligent inference, flexible extension, efficient retrieval, ease of use, and security and control. Suitable for enterprise knowledge management, scientific literature analysis, product technical support, legal compliance review, and medical knowledge assistance.
For similar jobs
Mindolph
Mindolph is an open source personal knowledge management software for all desktop platforms. It allows users to create and manage their own files in separate workspaces with saving in their local storage, organize their files as a tree in their workspaces, and have multiple tabs for opening files instead of a single file window. Mindolph supports Mind Map, Markdown, PlantUML, CSV sheet, and plain text file formats. It also has features such as quickly navigating to files and searching text in files under a specific folder, editing mind maps easily and quickly with key shortcuts, supporting themes and providing some pre-defined themes, importing from other mind map formats, and exporting to other file formats.

book
Podwise is an AI knowledge management app designed specifically for podcast listeners. With the Podwise platform, you only need to follow your favorite podcasts, such as "Hardcore Hackers". When a program is released, Podwise will use AI to transcribe, extract, summarize, and analyze the podcast content, helping you to break down the hard-core podcast knowledge. At the same time, it is connected to platforms such as Notion, Obsidian, Logseq, and Readwise, embedded in your knowledge management workflow, and integrated with content from other channels including news, newsletters, and blogs, helping you to improve your second brain 🧠.

sycamore
Sycamore is a conversational search and analytics platform for complex unstructured data, such as documents, presentations, transcripts, embedded tables, and internal knowledge repositories. It retrieves and synthesizes high-quality answers through bringing AI to data preparation, indexing, and retrieval. Sycamore makes it easy to prepare unstructured data for search and analytics, providing a toolkit for data cleaning, information extraction, enrichment, summarization, and generation of vector embeddings that encapsulate the semantics of data. Sycamore uses your choice of generative AI models to make these operations simple and effective, and it enables quick experimentation and iteration. Additionally, Sycamore uses OpenSearch for indexing, enabling hybrid (vector + keyword) search, retrieval-augmented generation (RAG) pipelining, filtering, analytical functions, conversational memory, and other features to improve information retrieval.

deep-seek
DeepSeek is a new experimental architecture for a large language model (LLM) powered internet-scale retrieval engine. Unlike current research agents designed as answer engines, DeepSeek aims to process a vast amount of sources to collect a comprehensive list of entities and enrich them with additional relevant data. The end result is a table with retrieved entities and enriched columns, providing a comprehensive overview of the topic. DeepSeek utilizes both standard keyword search and neural search to find relevant content, and employs an LLM to extract specific entities and their associated contents. It also includes a smaller answer agent to enrich the retrieved data, ensuring thoroughness. DeepSeek has the potential to revolutionize research and information gathering by providing a comprehensive and structured way to access information from the vastness of the internet.

swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.

databerry
Chaindesk is a no-code platform that allows users to easily set up a semantic search system for personal data without technical knowledge. It supports loading data from various sources such as raw text, web pages, files (Word, Excel, PowerPoint, PDF, Markdown, Plain Text), and upcoming support for web sites, Notion, and Airtable. The platform offers a user-friendly interface for managing datastores, querying data via a secure API endpoint, and auto-generating ChatGPT Plugins for each datastore. Chaindesk utilizes a Vector Database (Qdrant), Openai's text-embedding-ada-002 for embeddings, and has a chunk size of 1024 tokens. The technology stack includes Next.js, Joy UI, LangchainJS, PostgreSQL, Prisma, and Qdrant, inspired by the ChatGPT Retrieval Plugin.
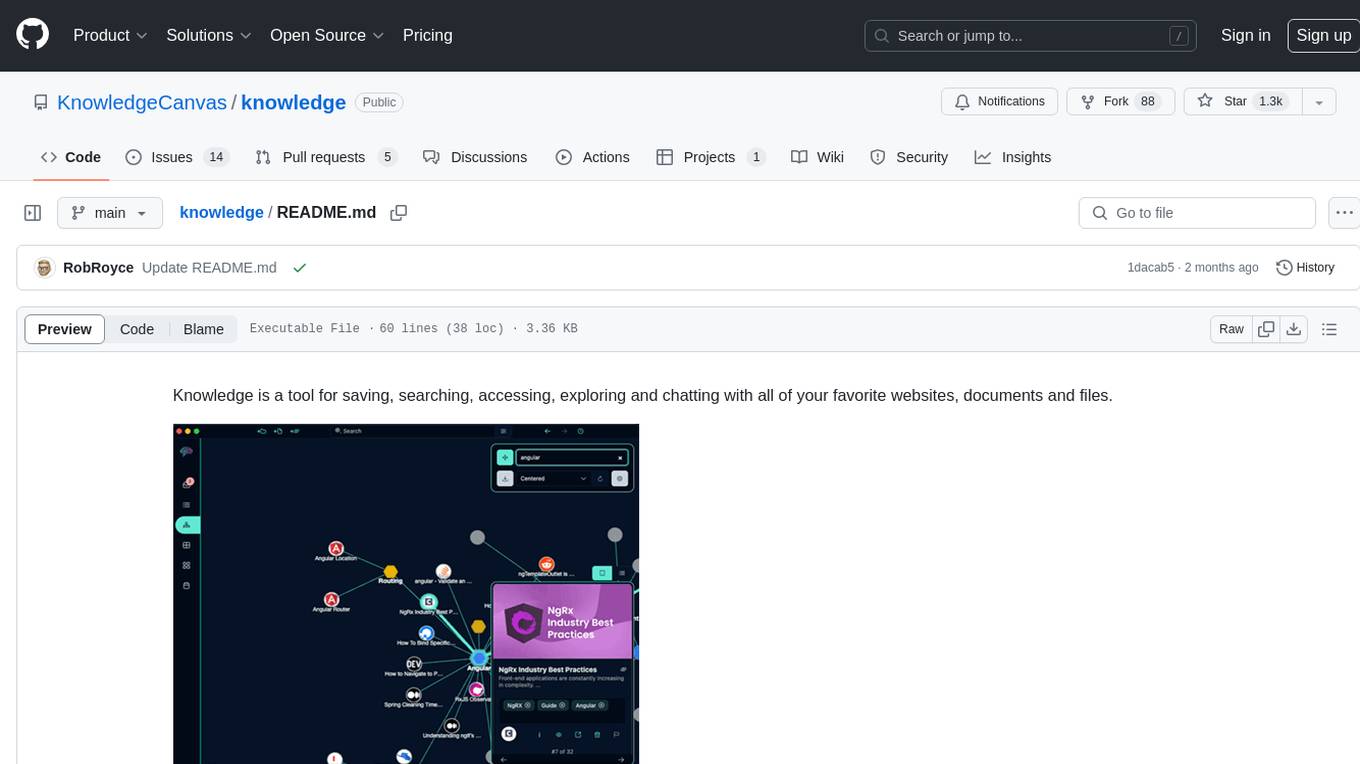
knowledge
Knowledge is a tool for saving, searching, accessing, exploring and chatting with all of your favorite websites, documents and files. Dive into a more interactive learning experience with Knowledge's new Chat feature! Engage in dynamic conversations with your Projects and Sources, leveraging the power of Large Language Models. The Chat feature is designed to transform the way you interact with your data, offering a more engaging and exploratory approach to learning. Unleash the power of context with the built-in Chromium browser. Transform your browsing into knowledge gathering effortlessly.
obsidian-arcana
Arcana is a plugin for Obsidian that offers a collection of AI-powered tools inspired by famous historical figures to enhance creativity and productivity. It includes tools for conversation, text-to-speech transcription, speech-to-text replies, metadata markup, text generation, file moving, flashcard generation, auto tagging, and note naming. Users can interact with these tools using the command palette and sidebar views, with an OpenAI API key required for usage. The plugin aims to assist users in various note-taking and knowledge management tasks within the Obsidian vault environment.