
FireRedTTS
An Open-Sourced LLM-empowered Foundation TTS System
Stars: 313
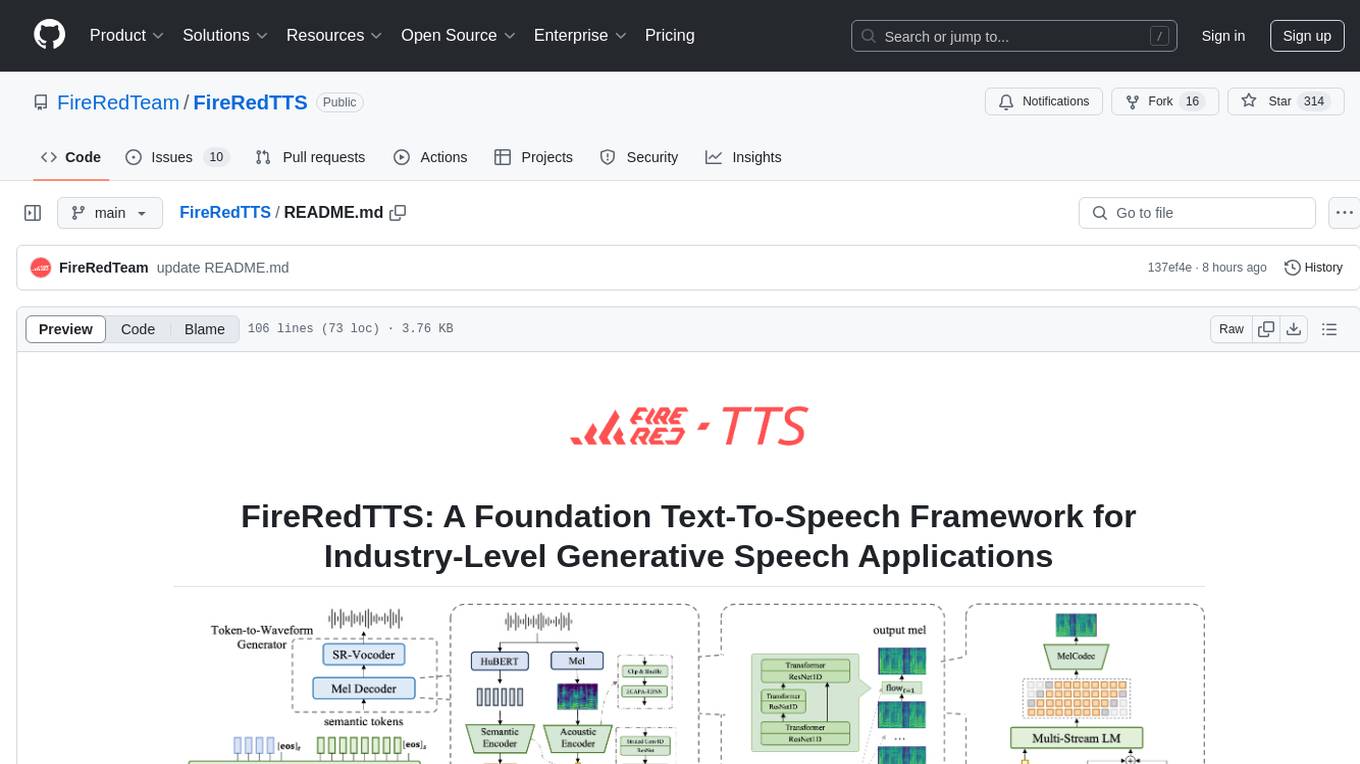
FireRedTTS is a foundation text-to-speech framework designed for industry-level generative speech applications. It offers a rich-punctuation model with expanded punctuation coverage and enhanced audio production consistency. The tool provides pre-trained checkpoints, inference code, and an interactive demo space. Users can clone the repository, create a conda environment, download required model files, and utilize the tool for synthesizing speech in various languages. FireRedTTS aims to enhance stability and provide controllable human-like speech generation capabilities.
README:

👉🏻 FireRedTTS Paper 👈🏻
👉🏻 FireRedTTS Demos 👈🏻
- [2024/10/17] 🔥 We release new rich-punctuation model, offering expanded punctuation coverage and enhanced audio production consistency. In addition, we have strengthened the capabilities of the text front-end and enhanced the stability of synthesis.
- [2024/09/26] 🔥 Our model is already available on huggingface space,try it through the interactive interface.
- [2024/09/20] 🔥 We release the pre-trained checkpoints and inference code.
- [2024/09/06] 🔥 We release the technical report and project page
-
[ ] 2024/09
- [x] Release the pre-trained checkpoints and inference code.
- [ ] Release testing set.
-
[ ] 2024/10
- [x] Release rich punctuation version.
- [ ] Release finetuned checkpoints for controllable human-like speech generation.
- Clone the repo
https://github.com/FireRedTeam/FireRedTTS.git
cd FireRedTTS- Create conda env
# step1.create env
conda create --name redtts python=3.10
# stpe2.install torch (pytorch should match the cuda-version on your machine)
# CUDA 11.8
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=11.8 -c pytorch -c nvidia
# CUDA 12.1
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia
# step3.install fireredtts form source
pip install -e .
# step4.install other requirements
pip install -r requirements.txtDownload the required model files from Model_Lists and place them in the folder pretrained_models
import os
import torchaudio
from fireredtts.fireredtts import FireRedTTS
tts = FireRedTTS(
config_path="configs/config_24k.json",
pretrained_path=<pretrained_models_dir>,
)
#same language
rec_wavs = tts.synthesize(
prompt_wav="examples/prompt_1.wav",
text="小红书,是中国大陆的网络购物和社交平台,成立于二零一三年六月。",
lang="zh",
)
rec_wavs = rec_wavs.detach().cpu()
out_wav_path = os.path.join("./example.wav")
torchaudio.save(out_wav_path, rec_wavs, 24000)- Removing the long silence (>1s) in the middle of prompt_wav may bring better stability. If there are too many long silences in your prompt_wav and it causes stability problems, it is recommended to use our tool(
tools/process_prompts.py) to remove the silence.
-
Tortoise-tts and XTTS-v2 offer invaluable insights for constructing an autoregressive-style system.
-
Matcha-TTS and CosyVoice demonstrate the excellent ability of flow-matching in converting audio code to mel.
-
BigVGAN-v2, utilized for vocoding.
-
We referred to whisper’s text tokenizer solution.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for FireRedTTS
Similar Open Source Tools
FireRedTTS
FireRedTTS is a foundation text-to-speech framework designed for industry-level generative speech applications. It offers a rich-punctuation model with expanded punctuation coverage and enhanced audio production consistency. The tool provides pre-trained checkpoints, inference code, and an interactive demo space. Users can clone the repository, create a conda environment, download required model files, and utilize the tool for synthesizing speech in various languages. FireRedTTS aims to enhance stability and provide controllable human-like speech generation capabilities.
APOLLO
APOLLO is a memory-efficient optimizer designed for large language model (LLM) pre-training and full-parameter fine-tuning. It offers SGD-like memory cost with AdamW-level performance. The optimizer integrates low-rank approximation and optimizer state redundancy reduction to achieve significant memory savings while maintaining or surpassing the performance of Adam(W). Key contributions include structured learning rate updates for LLM training, approximated channel-wise gradient scaling in a low-rank auxiliary space, and minimal-rank tensor-wise gradient scaling. APOLLO aims to optimize memory efficiency during training large language models.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.

llmaz
llmaz is an easy, advanced inference platform for large language models on Kubernetes. It aims to provide a production-ready solution that integrates with state-of-the-art inference backends. The platform supports efficient model distribution, accelerator fungibility, SOTA inference, various model providers, multi-host support, and scaling efficiency. Users can quickly deploy LLM services with minimal configurations and benefit from a wide range of advanced inference backends. llmaz is designed to optimize cost and performance while supporting cutting-edge researches like Speculative Decoding or Splitwise on Kubernetes.
zero-true
Zero-True is a Python and SQL reactive computational notebook designed for building and collaborating on data-driven applications. It offers an integrated and simple environment with transparent updates, dynamic and interactive UI rendering, fast prototyping capabilities, and open-source community contributions. Users can create rich, reactive apps with ease and publish them confidently. Zero-True aims to improve data accessibility and foster collaboration among users.
TavernAI
TavernAI is an atmospheric frontend tool for chat and storywriting, compatible with various backends. It offers features like character creation, online character database, group chat, story mode, world info, message swiping, configurable settings, interface themes, backgrounds, message editing, GPT-4.5, and Claude picture recognition. The tool supports backends like Kobold series, Oobabooga's Text Generation Web UI, OpenAI, NovelAI, and Claude. Users can easily install TavernAI on different operating systems and start using it for interactive storytelling and chat experiences.
codefuse-ide
CodeFuse IDE is an AI-native integrated development environment that leverages AI technologies to enhance productivity and streamline workflows. It supports seamless integration of various models, enabling developers to customize and extend functionality. The platform is compatible with VS Code extensions, providing access to a rich ecosystem of plugins. CodeFuse IDE uses electron-forge for packaging desktop applications and supports development, building, packaging, and auto updates.

DevoxxGenieIDEAPlugin
Devoxx Genie is a Java-based IntelliJ IDEA plugin that integrates with local and cloud-based LLM providers to aid in reviewing, testing, and explaining project code. It supports features like code highlighting, chat conversations, and adding files/code snippets to context. Users can modify REST endpoints and LLM parameters in settings, including support for cloud-based LLMs. The plugin requires IntelliJ version 2023.3.4 and JDK 17. Building and publishing the plugin is done using Gradle tasks. Users can select an LLM provider, choose code, and use commands like review, explain, or generate unit tests for code analysis.

long-llms-learning
A repository sharing the panorama of the methodology literature on Transformer architecture upgrades in Large Language Models for handling extensive context windows, with real-time updating the newest published works. It includes a survey on advancing Transformer architecture in long-context large language models, flash-ReRoPE implementation, latest news on data engineering, lightning attention, Kimi AI assistant, chatglm-6b-128k, gpt-4-turbo-preview, benchmarks like InfiniteBench and LongBench, long-LLMs-evals for evaluating methods for enhancing long-context capabilities, and LLMs-learning for learning technologies and applicated tasks about Large Language Models.
chat-with-mlx
Chat with MLX is an all-in-one Chat Playground using Apple MLX on Apple Silicon Macs. It provides privacy-enhanced AI for secure conversations with various models, easy integration of HuggingFace and MLX Compatible Open-Source Models, and comes with default models like Llama-3, Phi-3, Yi, Qwen, Mistral, Codestral, Mixtral, StableLM. The tool is designed for developers and researchers working with machine learning models on Apple Silicon.
better-chatbot
Better Chatbot is an open-source AI chatbot designed for individuals and teams, inspired by various AI models. It integrates major LLMs, offers powerful tools like MCP protocol and data visualization, supports automation with custom agents and visual workflows, enables collaboration by sharing configurations, provides a voice assistant feature, and ensures an intuitive user experience. The platform is built with Vercel AI SDK and Next.js, combining leading AI services into one platform for enhanced chatbot capabilities.
LLM-FuzzX
LLM-FuzzX is an open-source user-friendly fuzz testing tool for large language models (e.g., GPT, Claude, LLaMA), equipped with advanced task-aware mutation strategies, fine-grained evaluation, and jailbreak detection capabilities. It helps researchers and developers quickly discover potential security vulnerabilities and enhance model robustness. The tool features a user-friendly web interface for visual configuration and real-time monitoring, supports various advanced mutation methods, integrates RoBERTa model for real-time jailbreak detection and evaluation, supports multiple language models like GPT, Claude, LLaMA, provides visualization analysis with seed flowcharts and experiment data statistics, and offers detailed logging support for main, mutation, and jailbreak logs.

TaskingAI
TaskingAI brings Firebase's simplicity to **AI-native app development**. The platform enables the creation of GPTs-like multi-tenant applications using a wide range of LLMs from various providers. It features distinct, modular functions such as Inference, Retrieval, Assistant, and Tool, seamlessly integrated to enhance the development process. TaskingAI’s cohesive design ensures an efficient, intelligent, and user-friendly experience in AI application development.
midscene
Midscene.js is an AI-powered automation SDK that allows users to control web pages, perform assertions, and extract data in JSON format using natural language. It offers features such as natural language interaction, understanding UI and providing responses in JSON, intuitive assertion based on AI understanding, compatibility with public multimodal LLMs like GPT-4o, visualization tool for easy debugging, and a brand new experience in automation development.
Software-Engineer-AI-Agent-Atlas
This repository provides activation patterns to transform a general AI into a specialized AI Software Engineer Agent. It addresses issues like context rot, hidden capabilities, chaos in vibecoding, and repetitive setup. The solution is a Persistent Consciousness Architecture framework named ATLAS, offering activated neural pathways, persistent identity, pattern recognition, specialized agents, and modular context management. Recent enhancements include abstraction power documentation, a specialized agent ecosystem, and a streamlined structure. Users can clone the repo, set up projects, initialize AI sessions, and manage context effectively for collaboration. Key files and directories organize identity, context, projects, specialized agents, logs, and critical information. The approach focuses on neuron activation through structure, context engineering, and vibecoding with guardrails to deliver a reliable AI Software Engineer Agent.

LinguaHaru
Next-generation AI translation tool that provides high-quality, precise translations for various common file formats with a single click. It is based on cutting-edge large language models, offering exceptional translation quality with minimal operation, supporting multiple document formats and languages. Features include multi-format compatibility, global language translation, one-click rapid translation, flexible translation engines, and LAN sharing for efficient collaborative work.
For similar tasks
farfalle
Farfalle is an open-source AI-powered search engine that allows users to run their own local LLM or utilize the cloud. It provides a tech stack including Next.js for frontend, FastAPI for backend, Tavily for search API, Logfire for logging, and Redis for rate limiting. Users can get started by setting up prerequisites like Docker and Ollama, and obtaining API keys for Tavily, OpenAI, and Groq. The tool supports models like llama3, mistral, and gemma. Users can clone the repository, set environment variables, run containers using Docker Compose, and deploy the backend and frontend using services like Render and Vercel.
chatllm.cpp
ChatLLM.cpp is a pure C++ implementation tool for real-time chatting with RAG on your computer. It supports inference of various models ranging from less than 1B to more than 300B. The tool provides accelerated memory-efficient CPU inference with quantization, optimized KV cache, and parallel computing. It allows streaming generation with a typewriter effect and continuous chatting with virtually unlimited content length. ChatLLM.cpp also offers features like Retrieval Augmented Generation (RAG), LoRA, Python/JavaScript/C bindings, web demo, and more possibilities. Users can clone the repository, quantize models, build the project using make or CMake, and run quantized models for interactive chatting.
airdcpp-windows
AirDC++ for Windows 10/11 is a file sharing client with a focus on ease of use and performance. It is designed to provide a seamless experience for users looking to share and download files over the internet. The tool is built using Visual Studio 2022 and offers a range of features to enhance the file sharing process. Users can easily clone the repository to access the latest version and contribute to the development of the tool.
oaic
Open AI Cellular is the core software for Open AI Cellular. It provides documentation on installation, quick start guide, and usage. The repository contains submodules and requires sphinx with the read-the-docs theme for building core documentation. The resulting documentation is stored in the 'docs/build/html' directory.
CJA_Comprehensive_Jailbreak_Assessment
This public repository contains the paper 'Comprehensive Assessment of Jailbreak Attacks Against LLMs'. It provides a labeling method to label results using Python and offers the opportunity to submit evaluation results to the leaderboard. Full codes will be released after the paper is accepted.
FireRedTTS
FireRedTTS is a foundation text-to-speech framework designed for industry-level generative speech applications. It offers a rich-punctuation model with expanded punctuation coverage and enhanced audio production consistency. The tool provides pre-trained checkpoints, inference code, and an interactive demo space. Users can clone the repository, create a conda environment, download required model files, and utilize the tool for synthesizing speech in various languages. FireRedTTS aims to enhance stability and provide controllable human-like speech generation capabilities.
comfy-cli
Comfy-cli is a command line tool designed to facilitate the installation and management of ComfyUI, an open-source machine learning framework. Users can easily set up ComfyUI, install packages, and manage custom nodes directly from the terminal. The tool offers features such as easy installation, seamless package management, custom node management, checkpoint downloads, cross-platform compatibility, and comprehensive documentation. Comfy-cli simplifies the process of working with ComfyUI, making it convenient for users to handle various tasks related to the framework.

sdkit
sdkit (stable diffusion kit) is an easy-to-use library for utilizing Stable Diffusion in AI Art projects. It includes features like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN, CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for custom VAEs, NSFW filter, model-downloader, parallel GPU support, and more. It offers a model database, auto-scanning for malicious models, and various optimizations. The API consists of modules for loading models, generating images, filters, model merging, and utilities, all managed through the sdkit.Context object.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.