
sdkit
sdkit (stable diffusion kit) is an easy-to-use library for using Stable Diffusion in your AI Art projects. It is fast, feature-packed, and memory-efficient.
Stars: 164

sdkit (stable diffusion kit) is an easy-to-use library for utilizing Stable Diffusion in AI Art projects. It includes features like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN, CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for custom VAEs, NSFW filter, model-downloader, parallel GPU support, and more. It offers a model database, auto-scanning for malicious models, and various optimizations. The API consists of modules for loading models, generating images, filters, model merging, and utilities, all managed through the sdkit.Context object.
README:
sdkit (stable diffusion kit) is an easy-to-use library for using Stable Diffusion in your AI Art projects. It is fast, feature-packed, and memory-efficient.

New: Stable Diffusion XL, ControlNets, LoRAs and Embeddings are now supported!
This is a community project, so please feel free to contribute (and to use it in your project)!

The goal is to let you be productive quickly (at your AI art project), so it bundles Stable Diffusion along with commonly-used features (like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN and CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for loading custom VAEs, NSFW filter etc).
Advanced features include a model-downloader (with a database of commonly used models), support for running in parallel on multiple GPUs, auto-scanning for malicious models, etc. Full list of features
Tested with Python 3.8. Supports Windows, Linux, and Mac.
Windows/Linux:
pip install torch torchvision --extra-index-url https://download.pytorch.org/whl/cu116- Run
pip install sdkit
Mac:
- Run
pip install sdkit
A simple example for generating an image from a Stable Diffusion model file (already present on the disk):
import sdkit
from sdkit.models import load_model
from sdkit.generate import generate_images
from sdkit.utils import log
context = sdkit.Context()
# set the path to the model file on the disk (.ckpt or .safetensors file)
context.model_paths['stable-diffusion'] = 'D:\\path\\to\\512-base-ema.ckpt'
load_model(context, 'stable-diffusion')
# generate the image
images = generate_images(context, prompt='Photograph of an astronaut riding a horse', seed=42, width=512, height=512)
# save the image
images[0].save("image.png") # images is a list of PIL.Image
log.info("Generated images!")A simple example for automatically downloading a known Stable Diffusion model file:
import sdkit
from sdkit.models import download_models, resolve_downloaded_model_path, load_model
from sdkit.generate import generate_images
from sdkit.utils import save_images
context = sdkit.Context()
download_models(context, models={'stable-diffusion': '1.5-pruned-emaonly'}) # downloads the known "SD 1.5-pruned-emaonly" model
context.model_paths['stable-diffusion'] = resolve_downloaded_model_path(context, 'stable-diffusion', '1.5-pruned-emaonly')
load_model(context, 'stable-diffusion')
images = generate_images(context, prompt='Photograph of an astronaut riding a horse', seed=42, width=512, height=512)
save_images(images, dir_path='D:\\path\\to\\images\\directory')Please see the list of examples, to learn how to use the other features (like filters, VAE, ControlNet, Embeddings, LoRA, memory optimizations, running on multiple GPUs etc).
Please see the API Reference page for a detailed summary.
Broadly, the API contains 5 modules:
sdkit.models # load/unloading models, downloading known models, scanning models
sdkit.generate # generating images
sdkit.filter # face restoration, upscaling
sdkit.train # model merge, and (in the future) more training methods
sdkit.utilsAnd a sdkit.Context object is passed around, which encapsulates the data related to the runtime (e.g. device and vram_optimizations) as well as references to the loaded model files and paths. Context is a thread-local object.
Click here to see the list of known models.
sdkit includes a database of known models and their configurations. This lets you download a known model with a single line of code. (You can customize where it saves the downloaded model)
Additionally, sdkit will attempt to automatically determine the configuration for a given model (when loading from disk). E.g. if an SD 2.1 model is being loaded, sdkit will automatically know to use fp32 for attn_precision. If an SD 2.0 v-type model is being loaded, sdkit will automatically know to use the v2-inference-v.yaml configuration. It does this by matching the quick-hash of the given model file, with the list of known quick-hashes.
For models that don't match a known hash (e.g. custom models), or if you want to override the config file, you can set the path to the config file in context.model_paths. e.g. context.model_paths['stable-diffusion'] = 'path/to/config.yaml'
It was born out of a popular Stable Diffusion UI, splitting out the battle-tested core engine into sdkit.
Features include: SD 2.1, SDXL, ControlNet, LoRAs, Embeddings, txt2img, img2img, inpainting, NSFW filter, multiple GPU support, Mac Support, GFPGAN and CodeFormer (fix faces), RealESRGAN (upscale), 16 samplers (including k-samplers and UniPC), custom VAE, low-memory optimizations, model merging, safetensor support, picklescan, etc. Click here to see the full list of features.
📢 We're looking to add support for Lycoris, AMD, Pix2Pix, and outpainting. We'd love some code contributions for these!
It is pretty fast, and close to the fastest. For the same image, sdkit took 5.5 seconds, while automatic1111 WebUI took 4.95 seconds. 📢 We're looking for code contributions to make sdkit even faster!
xformers is supported experimentally, which will make sdkit even faster.
Details of the benchmark:
Windows 11, NVIDIA 3060 12GB, 512x512 image, sd-v1-4.ckpt, euler_a sampler, number of steps: 25, seed 42, guidance scale 7.5.
No xformers. No VRAM optimizations for low-memory usage.
| Time taken | Iterations/sec | Peak VRAM usage | |
|---|---|---|---|
sdkit |
5.5 sec | 6.0 it/s | 5.1 GB |
automatic1111 webui |
4.95 sec | 6.15 it/s | 5.1 GB |
Yes. It works on NVIDIA/Mac GPUs with at least 2GB of VRAM. For PCs without a compatible GPU, it can run entirely on the CPU. Running on the CPU will be very slow, but at least you'll be able to try it out!
📢 We don't support AMD yet on Windows (it'll run in CPU mode, or in Linux), but we're looking for code contributions for AMD support!
You can certainly use diffusers. sdkit is in fact using diffusers internally, so you can think of sdkit as a convenient API and a collection of tools, focused on Stable Diffusion projects.
sdkit:
- is a simple, lightweight toolkit for Stable Diffusion projects.
- natively includes frequently-used projects like GFPGAN, CodeFormer, and RealESRGAN.
- works with the popular
.ckptand.safetensorsmodel format. - includes memory optimizations for low-end GPUs.
- built-in support for running on multiple GPUs.
- can download models from any server.
- Auto scans for malicious models.
- includes 16 samplers (including k-samplers).
- born out of the needs of the new Stable Diffusion AI Art scene, starting Aug 2022.
- Easy Diffusion (cmdr2 UI) for Stable Diffusion.
- Arthemy AI
If your project is using sdkit, you can add it to this list. Please feel free to open a pull request (or let us know at our Discord community).
We'd love to accept code contributions. Please feel free to drop by our Discord community!
📢 We're looking for code contributions for these features (or anything else you'd like to work on):
- Lycoris.
- Outpainting.
- Pix2Pix.
- AMD support.
If you'd like to set up a developer version on your PC (to contribute code changes), please follow these instructions.
Instructions for running automated tests: Running Tests.
- Stable Diffusion: https://github.com/Stability-AI/stablediffusion
- CodeFormer: https://github.com/sczhou/CodeFormer (license: https://github.com/sczhou/CodeFormer/blob/master/LICENSE)
- GFPGAN: https://github.com/TencentARC/GFPGAN
- RealESRGAN: https://github.com/xinntao/Real-ESRGAN
- k-diffusion: https://github.com/crowsonkb/k-diffusion
- Code contributors and artists on Easy Diffusion (cmdr2 UI): https://github.com/easydiffusion/easydiffusion and Discord (https://discord.com/invite/u9yhsFmEkB)
- Lots of contributors on the internet
The authors of this project are not responsible for any content generated using this project.
The license of this software forbids you from sharing any content that:
- Violates any laws.
- Produces any harm to a person or persons.
- Disseminates (spreads) any personal information that would be meant for harm.
- Spreads misinformation.
- Target vulnerable groups.
For the full list of restrictions please read the License. By using this software you agree to the terms.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for sdkit
Similar Open Source Tools
sdkit
sdkit (stable diffusion kit) is an easy-to-use library for utilizing Stable Diffusion in AI Art projects. It includes features like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN, CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for custom VAEs, NSFW filter, model-downloader, parallel GPU support, and more. It offers a model database, auto-scanning for malicious models, and various optimizations. The API consists of modules for loading models, generating images, filters, model merging, and utilities, all managed through the sdkit.Context object.
keras-hub
KerasHub is a pretrained modeling library that provides Keras 3 implementations of popular model architectures with pretrained checkpoints. It supports text, image, and audio data for generation, classification, and other tasks. Models are compatible with JAX, TensorFlow, and PyTorch, and can be fine-tuned on GPUs and TPUs. KerasHub components are provided as Layer and Model implementations, extending the core Keras API.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

MARS5-TTS
MARS5 is a novel English speech model (TTS) developed by CAMB.AI, featuring a two-stage AR-NAR pipeline with a unique NAR component. The model can generate speech for various scenarios like sports commentary and anime with just 5 seconds of audio and a text snippet. It allows steering prosody using punctuation and capitalization in the transcript. Speaker identity is specified using an audio reference file, enabling 'deep clone' for improved quality. The model can be used via torch.hub or HuggingFace, supporting both shallow and deep cloning for inference. Checkpoints are provided for AR and NAR models, with hardware requirements of 750M+450M params on GPU. Contributions to improve model stability, performance, and reference audio selection are welcome.

hi-ml
The Microsoft Health Intelligence Machine Learning Toolbox is a repository that provides low-level and high-level building blocks for Machine Learning / AI researchers and practitioners. It simplifies and streamlines work on deep learning models for healthcare and life sciences by offering tested components such as data loaders, pre-processing tools, deep learning models, and cloud integration utilities. The repository includes two Python packages, 'hi-ml-azure' for helper functions in AzureML, 'hi-ml' for ML components, and 'hi-ml-cpath' for models and workflows related to histopathology images.

kafka-ml
Kafka-ML is a framework designed to manage the pipeline of Tensorflow/Keras and PyTorch machine learning models on Kubernetes. It enables the design, training, and inference of ML models with datasets fed through Apache Kafka, connecting them directly to data streams like those from IoT devices. The Web UI allows easy definition of ML models without external libraries, catering to both experts and non-experts in ML/AI.

LeanCopilot
Lean Copilot is a tool that enables the use of large language models (LLMs) in Lean for proof automation. It provides features such as suggesting tactics/premises, searching for proofs, and running inference of LLMs. Users can utilize built-in models from LeanDojo or bring their own models to run locally or on the cloud. The tool supports platforms like Linux, macOS, and Windows WSL, with optional CUDA and cuDNN for GPU acceleration. Advanced users can customize behavior using Tactic APIs and Model APIs. Lean Copilot also allows users to bring their own models through ExternalGenerator or ExternalEncoder. The tool comes with caveats such as occasional crashes and issues with premise selection and proof search. Users can get in touch through GitHub Discussions for questions, bug reports, feature requests, and suggestions. The tool is designed to enhance theorem proving in Lean using LLMs.

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

CogAgent
CogAgent is an advanced intelligent agent model designed for automating operations on graphical interfaces across various computing devices. It supports platforms like Windows, macOS, and Android, enabling users to issue commands, capture device screenshots, and perform automated operations. The model requires a minimum of 29GB of GPU memory for inference at BF16 precision and offers capabilities for executing tasks like sending Christmas greetings and sending emails. Users can interact with the model by providing task descriptions, platform specifications, and desired output formats.
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.

ray-llm
RayLLM (formerly known as Aviary) is an LLM serving solution that makes it easy to deploy and manage a variety of open source LLMs, built on Ray Serve. It provides an extensive suite of pre-configured open source LLMs, with defaults that work out of the box. RayLLM supports Transformer models hosted on Hugging Face Hub or present on local disk. It simplifies the deployment of multiple LLMs, the addition of new LLMs, and offers unique autoscaling support, including scale-to-zero. RayLLM fully supports multi-GPU & multi-node model deployments and offers high performance features like continuous batching, quantization and streaming. It provides a REST API that is similar to OpenAI's to make it easy to migrate and cross test them. RayLLM supports multiple LLM backends out of the box, including vLLM and TensorRT-LLM.

langchain
LangChain is a framework for developing Elixir applications powered by language models. It enables applications to connect language models to other data sources and interact with the environment. The library provides components for working with language models and off-the-shelf chains for specific tasks. It aims to assist in building applications that combine large language models with other sources of computation or knowledge. LangChain is written in Elixir and is not aimed for parity with the JavaScript and Python versions due to differences in programming paradigms and design choices. The library is designed to make it easy to integrate language models into applications and expose features, data, and functionality to the models.

llamabot
LlamaBot is a Pythonic bot interface to Large Language Models (LLMs), providing an easy way to experiment with LLMs in Jupyter notebooks and build Python apps utilizing LLMs. It supports all models available in LiteLLM. Users can access LLMs either through local models with Ollama or by using API providers like OpenAI and Mistral. LlamaBot offers different bot interfaces like SimpleBot, ChatBot, QueryBot, and ImageBot for various tasks such as rephrasing text, maintaining chat history, querying documents, and generating images. The tool also includes CLI demos showcasing its capabilities and supports contributions for new features and bug reports from the community.

pydantic-ai
PydanticAI is a Python agent framework designed to make it less painful to build production grade applications with Generative AI. It is built by the Pydantic Team and supports various AI models like OpenAI, Anthropic, Gemini, Ollama, Groq, and Mistral. PydanticAI seamlessly integrates with Pydantic Logfire for real-time debugging, performance monitoring, and behavior tracking of LLM-powered applications. It is type-safe, Python-centric, and offers structured responses, dependency injection system, and streamed responses. PydanticAI is in early beta, offering a Python-centric design to apply standard Python best practices in AI-driven projects.

AI-Scientist
The AI Scientist is a comprehensive system for fully automatic scientific discovery, enabling Foundation Models to perform research independently. It aims to tackle the grand challenge of developing agents capable of conducting scientific research and discovering new knowledge. The tool generates papers on various topics using Large Language Models (LLMs) and provides a platform for exploring new research ideas. Users can create their own templates for specific areas of study and run experiments to generate papers. However, caution is advised as the codebase executes LLM-written code, which may pose risks such as the use of potentially dangerous packages and web access.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text
For similar tasks
comfy-cli
Comfy-cli is a command line tool designed to facilitate the installation and management of ComfyUI, an open-source machine learning framework. Users can easily set up ComfyUI, install packages, and manage custom nodes directly from the terminal. The tool offers features such as easy installation, seamless package management, custom node management, checkpoint downloads, cross-platform compatibility, and comprehensive documentation. Comfy-cli simplifies the process of working with ComfyUI, making it convenient for users to handle various tasks related to the framework.
sdkit
sdkit (stable diffusion kit) is an easy-to-use library for utilizing Stable Diffusion in AI Art projects. It includes features like ControlNets, LoRAs, Textual Inversion Embeddings, GFPGAN, CodeFormer for face restoration, RealESRGAN for upscaling, k-samplers, support for custom VAEs, NSFW filter, model-downloader, parallel GPU support, and more. It offers a model database, auto-scanning for malicious models, and various optimizations. The API consists of modules for loading models, generating images, filters, model merging, and utilities, all managed through the sdkit.Context object.

Jlama
Jlama is a modern Java inference engine designed for large language models. It supports various model types such as Gemma, Llama, Mistral, GPT-2, BERT, and more. The tool implements features like Flash Attention, Mixture of Experts, and supports different model quantization formats. Built with Java 21 and utilizing the new Vector API for faster inference, Jlama allows users to add LLM inference directly to their Java applications. The tool includes a CLI for running models, a simple UI for chatting with LLMs, and examples for different model types.
olah
Olah is a self-hosted lightweight Huggingface mirror service that implements mirroring feature for Huggingface resources at file block level, enhancing download speeds and saving bandwidth. It offers cache control policies and allows administrators to configure accessible repositories. Users can install Olah with pip or from source, set up the mirror site, and download models and datasets using huggingface-cli. Olah provides additional configurations through a configuration file for basic setup and accessibility restrictions. Future work includes implementing an administrator and user system, OOS backend support, and mirror update schedule task. Olah is released under the MIT License.
gemma
Gemma is a family of open-weights Large Language Model (LLM) by Google DeepMind, based on Gemini research and technology. This repository contains an inference implementation and examples, based on the Flax and JAX frameworks. Gemma can run on CPU, GPU, and TPU, with model checkpoints available for download. It provides tutorials, reference implementations, and Colab notebooks for tasks like sampling and fine-tuning. Users can contribute to Gemma through bug reports and pull requests. The code is licensed under the Apache License, Version 2.0.
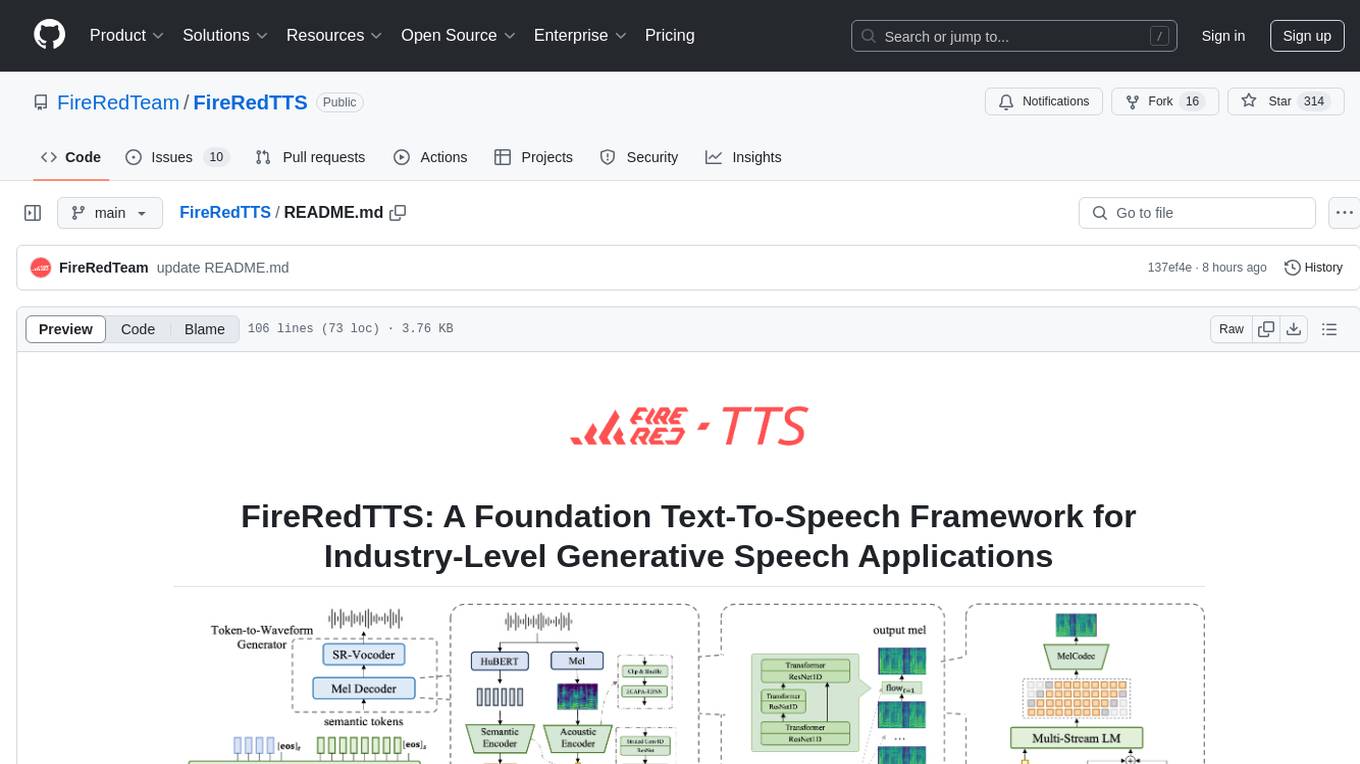
FireRedTTS
FireRedTTS is a foundation text-to-speech framework designed for industry-level generative speech applications. It offers a rich-punctuation model with expanded punctuation coverage and enhanced audio production consistency. The tool provides pre-trained checkpoints, inference code, and an interactive demo space. Users can clone the repository, create a conda environment, download required model files, and utilize the tool for synthesizing speech in various languages. FireRedTTS aims to enhance stability and provide controllable human-like speech generation capabilities.
ai-dev-gallery
The AI Dev Gallery is an app designed to help Windows developers integrate AI capabilities within their own apps and projects. It contains over 25 interactive samples powered by local AI models, allows users to explore, download, and run models from Hugging Face and GitHub, and provides the ability to view the C# source code and export a standalone Visual Studio project for each sample. The app is open-source and welcomes contributions and suggestions from the community.
Ling
Ling is a MoE LLM provided and open-sourced by InclusionAI. It includes two different sizes, Ling-Lite with 16.8 billion parameters and Ling-Plus with 290 billion parameters. These models show impressive performance and scalability for various tasks, from natural language processing to complex problem-solving. The open-source nature of Ling encourages collaboration and innovation within the AI community, leading to rapid advancements and improvements. Users can download the models from Hugging Face and ModelScope for different use cases. Ling also supports offline batched inference and online API services for deployment. Additionally, users can fine-tune Ling models using Llama-Factory for tasks like SFT and DPO.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.