
libedgetpu
Source code for the userspace level runtime driver for Coral.ai devices.
Stars: 177
This repository contains the source code for the userspace level runtime driver for Coral devices. The software is distributed in binary form at coral.ai/software. Users can build the library using Docker + Bazel, Bazel, or Makefile methods. It supports building on Linux, macOS, and Windows. The library is used to enable the Edge TPU runtime, which may heat up during operation. Google does not accept responsibility for any loss or damage if the device is operated outside the recommended ambient temperature range.
README:
This repo contains the source code for the userspace level runtime driver for Coral devices. This software is distributed in the binary form at coral.ai/software.
There are three ways to build libedgetpu:
- Docker + Bazel: Compatible with Linux, MacOS and Windows (via Dockerfile.windows and build.bat), this method ensures a known-good build enviroment and pulls all external depedencies needed.
- Bazel: Supports Linux, macOS, and Windows (via build.bat). A proper enviroment setup is required before using this technique.
- Makefile: Supporting only Linux and Native builds, this strategy is pure Makefile and doesn't require Bazel or external dependencies to be pulled at runtime.
For Debian/Ubuntu, install the following libraries:
$ sudo apt install docker.io devscripts
Build Linux binaries inside Docker container (works on Linux and macOS):
DOCKER_CPUS="k8" DOCKER_IMAGE="ubuntu:22.04" DOCKER_TARGETS=libedgetpu make docker-build
DOCKER_CPUS="armv7a aarch64" DOCKER_IMAGE="debian:bookworm" DOCKER_TARGETS=libedgetpu make docker-build
All built binaries go to the out directory. Note that the bazel-* are not copied to the host from the Docker container.
To package a Debian deb for arm64,armhf,amd64 respectively:
debuild -us -uc -tc -b -a arm64 -d
debuild -us -uc -tc -b -a armhf -d
debuild -us -uc -tc -b -a amd64 -d
The version of bazel needs to be the same as that recommended for the corresponding version of tensorflow. For example, it requires Bazel 6.5.0 to compile TF 2.16.1.
Current version of tensorflow supported is 2.16.1.
Build native binaries on Linux and macOS:
$ make
Required libraries for Linux:
$ sudo apt install python3-dev
Build native binaries on Windows:
$ build.bat
Cross-compile for ARMv7-A (32 bit), and ARMv8-A (64 bit) on Linux:
$ CPU=armv7a make
$ CPU=aarch64 make
To package a Debian deb:
debuild -us -uc -tc -b
NOTE for MacOS: Compilation with MacOS fails. Two requirements:
- install
flatbuffers(via macports) - after failure in compilation, add the following line to the temporary file that is created by bazel in
/var/tmp/_bazl_xxxxx/xxxxxxxxxxxxx/external/local_config_cc/BUILDline 48:
"darwin_x86_64": ":cc-compiler-darwin",
Repeat compilation.
If only building for native systems, it is possible to significantly reduce the complexity of the build by removing Bazel (and Docker). This simple approach builds only what is needed, removes build-time depenency fetching, increases the speed, and uses upstream Debian packages.
To prepare your system, you'll need the following packages (both available on Debian Bookworm, Bullseye or Buster-Backports):
sudo apt install libabsl-dev libflatbuffers-dev
Next, you'll need to clone the Tensorflow Repo at the desired checkout (using TF head isn't advised). If you are planning to use libcoral or pycoral libraries, this should match the ones in those repos' WORKSPACE files. For example, if you are using TF2.15, we can check that tag in the TF Repo get the latest commit for that stable release and then checkout that address:
git clone https://github.com/tensorflow/tensorflow
git checkout v2.16.1
To build the library:
TFROOT=<Directory of Tensorflow> make -f makefile_build/Makefile -j$(nproc) libedgetpu
If you have question, comments or requests concerning this library, please reach out to [email protected].
If you're using the Coral USB Accelerator, it may heat up during operation, depending on the computation workloads and operating frequency. Touching the metal part of the USB Accelerator after it has been operating for an extended period of time may lead to discomfort and/or skin burns. As such, if you enable the Edge TPU runtime using the maximum operating frequency, the USB Accelerator should be operated at an ambient temperature of 25°C or less. Alternatively, if you enable the Edge TPU runtime using the reduced operating frequency, then the device is intended to safely operate at an ambient temperature of 35°C or less.
Google does not accept any responsibility for any loss or damage if the device is operated outside of the recommended ambient temperature range.
Note: This issue affects only USB-based Coral devices, and is irrelevant for PCIe devices.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for libedgetpu
Similar Open Source Tools
libedgetpu
This repository contains the source code for the userspace level runtime driver for Coral devices. The software is distributed in binary form at coral.ai/software. Users can build the library using Docker + Bazel, Bazel, or Makefile methods. It supports building on Linux, macOS, and Windows. The library is used to enable the Edge TPU runtime, which may heat up during operation. Google does not accept responsibility for any loss or damage if the device is operated outside the recommended ambient temperature range.
nx_open
The `nx_open` repository contains open-source components for the Network Optix Meta Platform, used to build products like Nx Witness Video Management System. It includes source code, specifications, and a Desktop Client. The repository is licensed under Mozilla Public License 2.0. Users can build the Desktop Client and customize it using a zip file. The build environment supports Windows, Linux, and macOS platforms with specific prerequisites. The repository provides scripts for building, signing executable files, and running the Desktop Client. Compatibility with VMS Server versions is crucial, and automatic VMS updates are disabled for the open-source Desktop Client.

StableSwarmUI
StableSwarmUI is a modular Stable Diffusion web user interface that emphasizes making power tools easily accessible, high performance, and extensible. It is designed to be a one-stop-shop for all things Stable Diffusion, providing a wide range of features and capabilities to enhance the user experience.
Demucs-Gui
Demucs GUI is a graphical user interface for the music separation project Demucs. It aims to allow users without coding experience to easily separate tracks. The tool provides a user-friendly interface for running the Demucs project, which originally used the scientific library torch. The GUI simplifies the process of separating tracks and provides support for different platforms such as Windows, macOS, and Linux. Users can donate to support the development of new models for the project, and the tool has specific system requirements including minimum system versions and hardware specifications.
trinityX
TrinityX is an open-source HPC, AI, and cloud platform designed to provide all services required in a modern system, with full customization options. It includes default services like Luna node provisioner, OpenLDAP, SLURM or OpenPBS, Prometheus, Grafana, OpenOndemand, and more. TrinityX also sets up NFS-shared directories, OpenHPC applications, environment modules, HA, and more. Users can install TrinityX on Enterprise Linux, configure network interfaces, set up passwordless authentication, and customize the installation using Ansible playbooks. The platform supports HA, OpenHPC integration, and provides detailed documentation for users to contribute to the project.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.
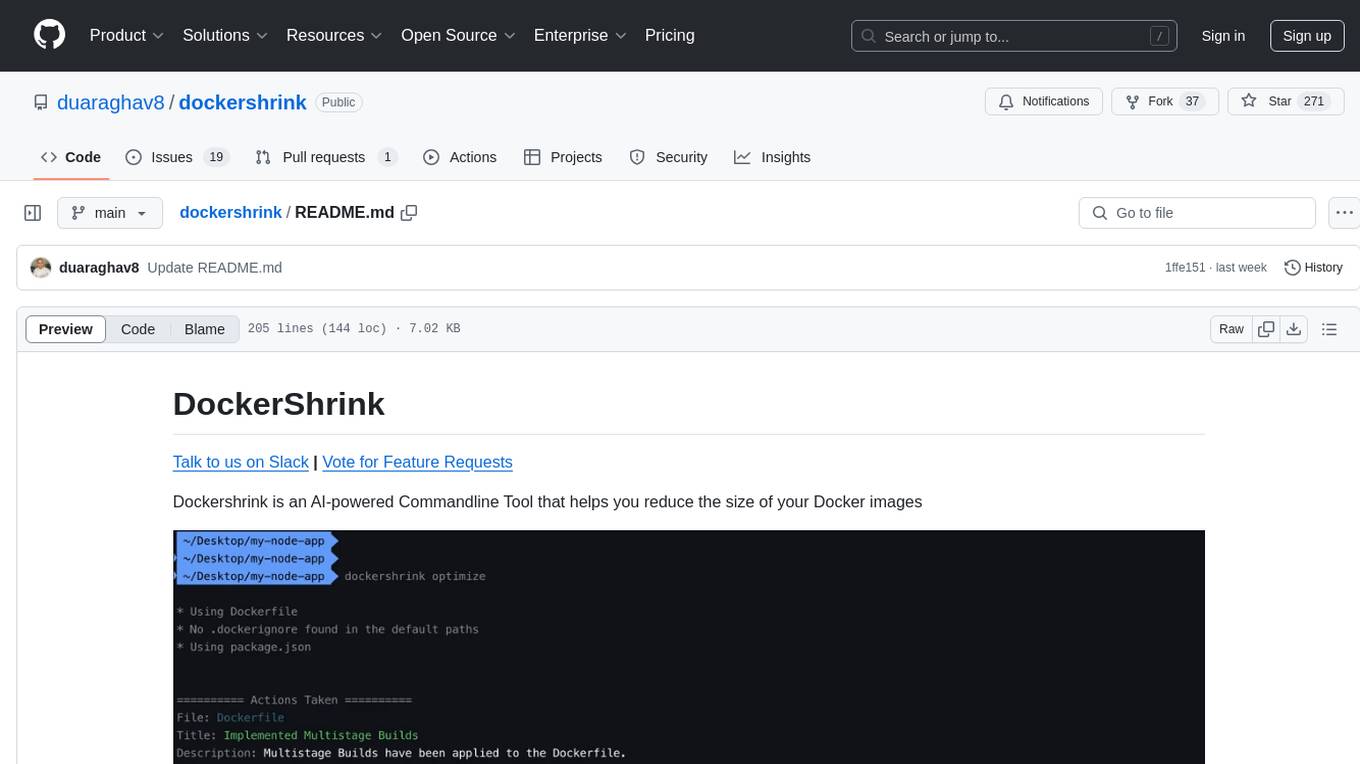
dockershrink
Dockershrink is an AI-powered Commandline Tool designed to help reduce the size of Docker images. It combines traditional Rule-based analysis with Generative AI techniques to optimize Image configurations. The tool supports NodeJS applications and aims to save costs on storage, data transfer, and build times while increasing developer productivity. By automatically applying advanced optimization techniques, Dockershrink simplifies the process for engineers and organizations, resulting in significant savings and efficiency improvements.
REINVENT4
REINVENT is a molecular design tool for de novo design, scaffold hopping, R-group replacement, linker design, molecule optimization, and other small molecule design tasks. It uses a Reinforcement Learning (RL) algorithm to generate optimized molecules compliant with a user-defined property profile defined as a multi-component score. Transfer Learning (TL) can be used to create or pre-train a model that generates molecules closer to a set of input molecules.
hugescm
HugeSCM is a cloud-based version control system designed to address R&D repository size issues. It effectively manages large repositories and individual large files by separating data storage and utilizing advanced algorithms and data structures. It aims for optimal performance in handling version control operations of large-scale repositories, making it suitable for single large library R&D, AI model development, and game or driver development.
holohub
Holohub is a central repository for the NVIDIA Holoscan AI sensor processing community to share reference applications, operators, tutorials, and benchmarks. It includes example applications, community components, package configurations, and tutorials. Users and developers of the Holoscan platform are invited to reuse and contribute to this repository. The repository provides detailed instructions on prerequisites, building, running applications, contributing, and glossary terms. It also offers a searchable catalog of available components on the Holoscan SDK User Guide website.

jaison-core
J.A.I.son is a Python project designed for generating responses using various components and applications. It requires specific plugins like STT, T2T, TTSG, and TTSC to function properly. Users can customize responses, voice, and configurations. The project provides a Discord bot, Twitch events and chat integration, and VTube Studio Animation Hotkeyer. It also offers features for managing conversation history, training AI models, and monitoring conversations.
uwazi
Uwazi is a flexible database application designed for capturing and organizing collections of information, with a focus on document management. It is developed and supported by HURIDOCS, benefiting human rights organizations globally. The tool requires NodeJs, ElasticSearch, ICU Analysis Plugin, MongoDB, Yarn, and pdftotext for installation. It offers production and development installation guides, including Docker setup. Uwazi supports hot reloading, unit and integration testing with JEST, and end-to-end testing with Nightmare or Puppeteer. The system requirements include RAM, CPU, and disk space recommendations for on-premises and development usage.
LLM_AppDev-HandsOn
This repository showcases how to build a simple LLM-based chatbot for answering questions based on documents using retrieval augmented generation (RAG) technique. It also provides guidance on deploying the chatbot using Podman or on the OpenShift Container Platform. The workshop associated with this repository introduces participants to LLMs & RAG concepts and demonstrates how to customize the chatbot for specific purposes. The software stack relies on open-source tools like streamlit, LlamaIndex, and local open LLMs via Ollama, making it accessible for GPU-constrained environments.
LlamaEdge
The LlamaEdge project makes it easy to run LLM inference apps and create OpenAI-compatible API services for the Llama2 series of LLMs locally. It provides a Rust+Wasm stack for fast, portable, and secure LLM inference on heterogeneous edge devices. The project includes source code for text generation, chatbot, and API server applications, supporting all LLMs based on the llama2 framework in the GGUF format. LlamaEdge is committed to continuously testing and validating new open-source models and offers a list of supported models with download links and startup commands. It is cross-platform, supporting various OSes, CPUs, and GPUs, and provides troubleshooting tips for common errors.

LARS
LARS is an application that enables users to run Large Language Models (LLMs) locally on their devices, upload their own documents, and engage in conversations where the LLM grounds its responses with the uploaded content. The application focuses on Retrieval Augmented Generation (RAG) to increase accuracy and reduce AI-generated inaccuracies. LARS provides advanced citations, supports various file formats, allows follow-up questions, provides full chat history, and offers customization options for LLM settings. Users can force enable or disable RAG, change system prompts, and tweak advanced LLM settings. The application also supports GPU-accelerated inferencing, multiple embedding models, and text extraction methods. LARS is open-source and aims to be the ultimate RAG-centric LLM application.
AirSane
AirSane is a SANE frontend and scanner server that supports Apple's AirScan protocol. It automatically detects scanners and publishes them through mDNS. Acquired images can be transferred in JPEG, PNG, and PDF/raster format. The tool is intended to be used with AirScan/eSCL clients such as Apple's Image Capture, sane-airscan on Linux, and the eSCL client built into Windows 10 and 11. It provides a simple web interface and encodes images on-the-fly to keep memory/storage demands low, making it suitable for devices like Raspberry Pi. Authentication and secure communication are supported in conjunction with a proxy server like nginx. AirSane has been reverse-engineered from Apple's AirScanScanner client communication protocol and offers a range of installation and configuration options for different operating systems.
For similar tasks
libedgetpu
This repository contains the source code for the userspace level runtime driver for Coral devices. The software is distributed in binary form at coral.ai/software. Users can build the library using Docker + Bazel, Bazel, or Makefile methods. It supports building on Linux, macOS, and Windows. The library is used to enable the Edge TPU runtime, which may heat up during operation. Google does not accept responsibility for any loss or damage if the device is operated outside the recommended ambient temperature range.
quantcoder
QuantCoder is a local-first CLI tool that generates QuantConnect trading algorithms from academic research papers. It uses local LLMs for code generation, refinement, and error fixing. The tool does not require cloud API keys and offers models for reasoning, summarization, and chat. Users can interact with QuantCoder through interactive, CLI, programmatic, and autonomous modes. It also features an evolution mode inspired by AlphaEvolve, backtesting with detailed metrics, library building, and integration with QuantConnect for backtesting and deployment. The tool's architecture includes components for CLI, configuration management, NLP, multi-agent system, evolution engine, self-improving pipeline, library builder, and integration with QuantConnect MCP.
For similar jobs
turnkeyml
TurnkeyML is a tools framework that integrates models, toolchains, and hardware backends to simplify the evaluation and actuation of deep learning models. It supports use cases like exporting ONNX files, performance validation, functional coverage measurement, stress testing, and model insights analysis. The framework consists of analysis, build, runtime, reporting tools, and a models corpus, seamlessly integrated to provide comprehensive functionality with simple commands. Extensible through plugins, it offers support for various export and optimization tools and AI runtimes. The project is actively seeking collaborators and is licensed under Apache 2.0.
libedgetpu
This repository contains the source code for the userspace level runtime driver for Coral devices. The software is distributed in binary form at coral.ai/software. Users can build the library using Docker + Bazel, Bazel, or Makefile methods. It supports building on Linux, macOS, and Windows. The library is used to enable the Edge TPU runtime, which may heat up during operation. Google does not accept responsibility for any loss or damage if the device is operated outside the recommended ambient temperature range.

FlagPerf
FlagPerf is an integrated AI hardware evaluation engine jointly built by the Institute of Intelligence and AI hardware manufacturers. It aims to establish an industry-oriented metric system to evaluate the actual capabilities of AI hardware under software stack combinations (model + framework + compiler). FlagPerf features a multidimensional evaluation metric system that goes beyond just measuring 'whether the chip can support specific model training.' It covers various scenarios and tasks, including computer vision, natural language processing, speech, multimodal, with support for multiple training frameworks and inference engines to connect AI hardware with software ecosystems. It also supports various testing environments to comprehensively assess the performance of domestic AI chips in different scenarios.

tt-xla
TT-XLA is a repository that enables running PyTorch and JAX models on Tenstorrent's AI hardware. It serves as a backend integration between the JAX ecosystem and Tenstorrent's ML accelerators using the PJRT (Portable JAX Runtime) interface. It supports ingestion of PyTorch models through PyTorch/XLA and JAX models via jit compile, providing a StableHLO (SHLO) graph to TT-MLIR compiler.

executorch
ExecuTorch is an end-to-end solution for enabling on-device inference capabilities across mobile and edge devices including wearables, embedded devices and microcontrollers. It is part of the PyTorch Edge ecosystem and enables efficient deployment of PyTorch models to edge devices. Key value propositions of ExecuTorch are: * **Portability:** Compatibility with a wide variety of computing platforms, from high-end mobile phones to highly constrained embedded systems and microcontrollers. * **Productivity:** Enabling developers to use the same toolchains and SDK from PyTorch model authoring and conversion, to debugging and deployment to a wide variety of platforms. * **Performance:** Providing end users with a seamless and high-performance experience due to a lightweight runtime and utilizing full hardware capabilities such as CPUs, NPUs, and DSPs.
holoscan-sdk
The Holoscan SDK is part of NVIDIA Holoscan, the AI sensor processing platform that combines hardware systems for low-latency sensor and network connectivity, optimized libraries for data processing and AI, and core microservices to run streaming, imaging, and other applications, from embedded to edge to cloud. It can be used to build streaming AI pipelines for a variety of domains, including Medical Devices, High Performance Computing at the Edge, Industrial Inspection and more.
panda
Panda is a car interface tool that speaks CAN and CAN FD, running on STM32F413 and STM32H725. It provides safety modes and controls_allowed feature for message handling. The tool ensures code rigor through CI regression tests, including static code analysis, MISRA C:2012 violations check, unit tests, and hardware-in-the-loop tests. The software interface supports Python library, C++ library, and socketcan in kernel. Panda is licensed under the MIT license.
aiocoap
aiocoap is a Python library that implements the Constrained Application Protocol (CoAP) using native asyncio methods in Python 3. It supports various CoAP standards such as RFC7252, RFC7641, RFC7959, RFC8323, RFC7967, RFC8132, RFC9176, RFC8613, and draft-ietf-core-oscore-groupcomm-17. The library provides features for clients and servers, including multicast support, blockwise transfer, CoAP over TCP, TLS, and WebSockets, No-Response, PATCH/FETCH, OSCORE, and Group OSCORE. It offers an easy-to-use interface for concurrent operations and is suitable for IoT applications.