
chatllm.cpp
Pure C++ implementation of several models for real-time chatting on your computer (CPU & GPU)
Stars: 708
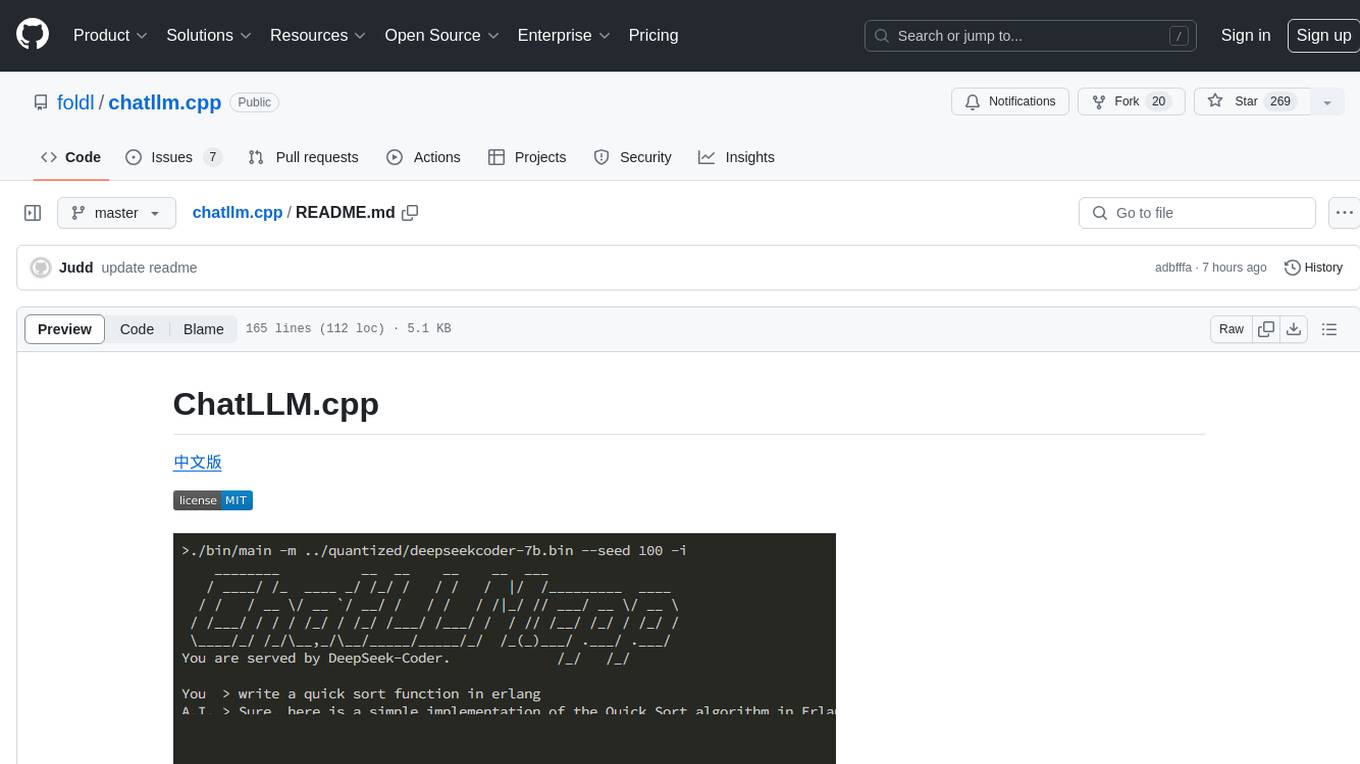
ChatLLM.cpp is a pure C++ implementation tool for real-time chatting with RAG on your computer. It supports inference of various models ranging from less than 1B to more than 300B. The tool provides accelerated memory-efficient CPU inference with quantization, optimized KV cache, and parallel computing. It allows streaming generation with a typewriter effect and continuous chatting with virtually unlimited content length. ChatLLM.cpp also offers features like Retrieval Augmented Generation (RAG), LoRA, Python/JavaScript/C bindings, web demo, and more possibilities. Users can clone the repository, quantize models, build the project using make or CMake, and run quantized models for interactive chatting.
README:
![]()

Inference of a bunch of models from less than 1B to more than 300B, for real-time multimodal chat with RAG on your computer (CPU & GPU), pure C++ implementation based on @ggerganov's ggml.
| Supported Models | Download Quantized Models |
graph TD;
ggml --> chatllm.cpp
chatllm.cpp --> AlphaGeometryRE
chatllm.cpp --> WritingTools
chatllm.cpp --> LittleAcademia
subgraph coding[ ]
AlphaGeometryRE
WritingTools
LittleAcademia
end
ggml[<a href="https://github.com/ggml-org/ggml" style="text-decoration:none;">ggml</a> <br><span style="font-size:10px;">Machine learning library</span>];
chatllm.cpp[<a href="https://github.com/foldl/chatllm.cpp" style="text-decoration:none;">chatllm.cpp</a> <br><span style="font-size:10px;">LLM inference</span>];
AlphaGeometryRE[<a href="https://github.com/foldl/alphageometryre" style="text-decoration:none;">AlphaGeometryRE</a> <br><span style="font-size:10px;">AlphaGeometry Re-engineered</span>];
WritingTools[<a href="https://github.com/foldl/WritingTools" style="text-decoration:none;">Writing Tools</a> <br><span style="font-size:10px;">AI aided writing</span>];
LittleAcademia[<a href="https://github.com/foldl/little-academia" style="text-decoration:none;">Little Academia</a> <br><span style="font-size:10px;">Learn programming</span>];What's New:
- 2025-09-23: Qwen2.5-VL
- 2025-09-15: Ling/Ring-mini-2.0
- 2025-09-08: GroveMoE
- 2025-09-03: Apertus
- 2025-08-22: Seed-OSS
- 2025-08-11: GPT-OSS
- 2025-08-05: Pangu-Embedded
- 2025-07-29: Jiutian
- 2025-07-10: SmolLM-3
- 2025-07-05: Pangu-Pro-MoE
- 2025-07-04: ERNIE-MoE
- 2025-06-30: Hunyuan-A13B, ERNIE-Dense
- 2025-06-21: I can hear: Qwen2-Audio
- 2025-06-10: SmolVLM2
- 2025-06-07: MiniCPM4
- 2025-06-06: Qwen-3 Embedding & Reranker
- 2025-06-03: Kimi-VL
- 2025-05-28: Gemma3 fully supported
- 2025-05-23: I can see: Fuyu
- 2025-05-21: Re-quantization when loading (e.g.
--re-quantize q4_k) - 2025-05-19: OuteTTS
- 2025-05-17: I can speak: Orpheus-TTS
- 2025-05-11: Seed-Coder
- 2025-04-30: QWen3, MiMo
- 2025-03-24: GGMM file format
- 2025-02-21: Distributed inference
- 2025-02-10: GPU acceleration 🔥
- 2024-12-09: Reversed role
- 2024-11-21: Continued generation
- 2024-11-01: generation steering
- 2024-06-15: Tool calling
- 2024-05-29: ggml is forked instead of submodule
- 2024-05-14: OpenAI API, CodeGemma Base & Instruct supported
- 2024-05-08: Layer shuffling
-
[x] Accelerated memory-efficient CPU/GPU inference with int4/int8 quantization, optimized KV cache and parallel computing;
-
[x] Use OOP to address the similarities between different Transformer based models;
-
[x] Streaming generation with typewriter effect;
-
[x] Continuous chatting (content length is virtually unlimited)
Two methods are available: Restart and Shift. See
--extendingoptions. -
[x] Retrieval Augmented Generation (RAG) 🔥
-
[x] LoRA;
-
[x] Python/JavaScript/C/Nim Bindings, web demo, and more possibilities.
As simple as main_nim -i -m :model_id. Check it out.
Clone the ChatLLM.cpp repository into your local machine:
git clone --recursive https://github.com/foldl/chatllm.cpp.git && cd chatllm.cppIf you forgot the --recursive flag when cloning the repository, run the following command in the chatllm.cpp folder:
git submodule update --init --recursiveSome quantized models can be downloaded on demand.
Install dependencies of convert.py:
pip install -r requirements.txtUse convert.py to transform models into quantized GGML format. For example, to convert the fp16 base model to q8_0 (quantized int8) GGML model, run:
# For models such as ChatLLM2-6B, InternLM, LlaMA, LlaMA-2, Baichuan-2, etc
python convert.py -i path/to/model -t q8_0 -o quantized.bin --name ModelName
# For some models such as CodeLlaMA, model type should be provided by `-a`
# Find `-a ...` option for each model in `docs/models.md`.
python convert.py -i path/to/model -t q8_0 -o quantized.bin -a CodeLlaMA --name ModelNameUse --name to specify model's name in English. Optionally, use --native_name to specify model's name in another language.
Use -l to specify the path of the LoRA model to be merged, such as:
python convert.py -i path/to/model -l path/to/lora/model -o quantized.bin --name ModelNameNote: Appropriately, only HF format is supported (with a few exceptions); Format of the generated .bin files is different from the one (GGUF) used by llama.cpp.
In order to build this project you have several different options.
-
Using
CMake:cmake -B build cmake --build build -j --config Release
The executable is
./build/bin/main.There are lots of
GGML_...options to play with. Example: Vulkan acceleration together with RPC and backend dynamic loading:cmake -B build -DGGML_VULKAN=1 -DGGML_RPC=1 -DGGML_CPU_ALL_VARIANTS=1 -DGGML_BACKEND_DL=1
Now you may chat with a quantized model by running:
./build/bin/main -m llama2.bin --seed 100 # Llama-2-Chat-7B
# Hello! I'm here to help you with any questions or concerns ....To run the model in interactive mode, add the -i flag. For example:
# On Windows
.\build\bin\Release\main -m model.bin -i
# On Linux (or WSL)
rlwrap ./build/bin/main -m model.bin -iIn interactive mode, your chat history will serve as the context for the next-round conversation.
Run ./build/bin/main -h to explore more options!
-
This project is started as refactoring of ChatGLM.cpp, without which, this project could not be possible.
-
Thank those who have released their the model sources and checkpoints.
-
chat_ui.htmladapted from Ollama-Chat.
This project is my hobby project to learn DL & GGML, and under active development. PRs of features won't be accepted, while PRs for bug fixes are warmly welcome.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for chatllm.cpp
Similar Open Source Tools
chatllm.cpp
ChatLLM.cpp is a pure C++ implementation tool for real-time chatting with RAG on your computer. It supports inference of various models ranging from less than 1B to more than 300B. The tool provides accelerated memory-efficient CPU inference with quantization, optimized KV cache, and parallel computing. It allows streaming generation with a typewriter effect and continuous chatting with virtually unlimited content length. ChatLLM.cpp also offers features like Retrieval Augmented Generation (RAG), LoRA, Python/JavaScript/C bindings, web demo, and more possibilities. Users can clone the repository, quantize models, build the project using make or CMake, and run quantized models for interactive chatting.
face-api
FaceAPI is an AI-powered tool for face detection, rotation tracking, face description, recognition, age, gender, and emotion prediction. It can be used in both browser and NodeJS environments using TensorFlow/JS. The tool provides live demos for processing images and webcam feeds, along with NodeJS examples for various tasks such as face similarity comparison and multiprocessing. FaceAPI offers different pre-built versions for client-side browser execution and server-side NodeJS execution, with or without TFJS pre-bundled. It is compatible with TFJS 2.0+ and TFJS 3.0+.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

AnglE
AnglE is a library for training state-of-the-art BERT/LLM-based sentence embeddings with just a few lines of code. It also serves as a general sentence embedding inference framework, allowing for inferring a variety of transformer-based sentence embeddings. The library supports various loss functions such as AnglE loss, Contrastive loss, CoSENT loss, and Espresso loss. It provides backbones like BERT-based models, LLM-based models, and Bi-directional LLM-based models for training on single or multi-GPU setups. AnglE has achieved significant performance on various benchmarks and offers official pretrained models for both BERT-based and LLM-based models.

DeepResearch
Tongyi DeepResearch is an agentic large language model with 30.5 billion total parameters, designed for long-horizon, deep information-seeking tasks. It demonstrates state-of-the-art performance across various search benchmarks. The model features a fully automated synthetic data generation pipeline, large-scale continual pre-training on agentic data, end-to-end reinforcement learning, and compatibility with two inference paradigms. Users can download the model directly from HuggingFace or ModelScope. The repository also provides benchmark evaluation scripts and information on the Deep Research Agent Family.
SG-Nav
SG-Nav is an online 3D scene graph prompting tool designed for LLM-based zero-shot object navigation. It proposes a framework that constructs an online 3D scene graph to prompt LLMs, allowing direct application to various scenes and categories without the need for training.

candle-vllm
Candle-vllm is an efficient and easy-to-use platform designed for inference and serving local LLMs, featuring an OpenAI compatible API server. It offers a highly extensible trait-based system for rapid implementation of new module pipelines, streaming support in generation, efficient management of key-value cache with PagedAttention, and continuous batching. The tool supports chat serving for various models and provides a seamless experience for users to interact with LLMs through different interfaces.

evalchemy
Evalchemy is a unified and easy-to-use toolkit for evaluating language models, focusing on post-trained models. It integrates multiple existing benchmarks such as RepoBench, AlpacaEval, and ZeroEval. Key features include unified installation, parallel evaluation, simplified usage, and results management. Users can run various benchmarks with a consistent command-line interface and track results locally or integrate with a database for systematic tracking and leaderboard submission.
libllm
libLLM is an open-source project designed for efficient inference of large language models (LLM) on personal computers and mobile devices. It is optimized to run smoothly on common devices, written in C++14 without external dependencies, and supports CUDA for accelerated inference. Users can build the tool for CPU only or with CUDA support, and run libLLM from the command line. Additionally, there are API examples available for Python and the tool can export Huggingface models.

dexto
Dexto is a lightweight runtime for creating and running AI agents that turn natural language into real-world actions. It serves as the missing intelligence layer for building AI applications, standalone chatbots, or as the reasoning engine inside larger products. Dexto features a powerful CLI and Web UI for running AI agents, supports multiple interfaces, allows hot-swapping of LLMs from various providers, connects to remote tool servers via the Model Context Protocol, is config-driven with version-controlled YAML, offers production-ready core features, extensibility for custom services, and enables multi-agent collaboration via MCP and A2A.
Flowise
Flowise is a tool that allows users to build customized LLM flows with a drag-and-drop UI. It is open-source and self-hostable, and it supports various deployments, including AWS, Azure, Digital Ocean, GCP, Railway, Render, HuggingFace Spaces, Elestio, Sealos, and RepoCloud. Flowise has three different modules in a single mono repository: server, ui, and components. The server module is a Node backend that serves API logics, the ui module is a React frontend, and the components module contains third-party node integrations. Flowise supports different environment variables to configure your instance, and you can specify these variables in the .env file inside the packages/server folder.
auto-engineer
Auto Engineer is a tool designed to automate the Software Development Life Cycle (SDLC) by building production-grade applications with a combination of human and AI agents. It offers a plugin-based architecture that allows users to install only the necessary functionality for their projects. The tool guides users through key stages including Flow Modeling, IA Generation, Deterministic Scaffolding, AI Coding & Testing Loop, and Comprehensive Quality Checks. Auto Engineer follows a command/event-driven architecture and provides a modular plugin system for specific functionalities. It supports TypeScript with strict typing throughout and includes a built-in message bus server with a web dashboard for monitoring commands and events.

LEANN
LEANN is an innovative vector database that democratizes personal AI, transforming your laptop into a powerful RAG system that can index and search through millions of documents using 97% less storage than traditional solutions without accuracy loss. It achieves this through graph-based selective recomputation and high-degree preserving pruning, computing embeddings on-demand instead of storing them all. LEANN allows semantic search of file system, emails, browser history, chat history, codebase, or external knowledge bases on your laptop with zero cloud costs and complete privacy. It is a drop-in semantic search MCP service fully compatible with Claude Code, enabling intelligent retrieval without changing your workflow.
LLMTSCS
LLMLight is a novel framework that employs Large Language Models (LLMs) as decision-making agents for Traffic Signal Control (TSC). The framework leverages the advanced generalization capabilities of LLMs to engage in a reasoning and decision-making process akin to human intuition for effective traffic control. LLMLight has been demonstrated to be remarkably effective, generalizable, and interpretable against various transportation-based and RL-based baselines on nine real-world and synthetic datasets.
green-bit-llm
Green-Bit-LLM is a Python toolkit designed for fine-tuning, inferencing, and evaluating GreenBitAI's low-bit Language Models (LLMs). It utilizes the Bitorch Engine for efficient operations on low-bit LLMs, enabling high-performance inference on various GPUs and supporting full-parameter fine-tuning using quantized LLMs. The toolkit also provides evaluation tools to validate model performance on benchmark datasets. Green-Bit-LLM is compatible with AutoGPTQ series of 4-bit quantization and compression models.
aiologic
aiologic is a locking library for tasks synchronization and their communication. It provides primitives that are both async-aware and thread-aware, and can be used for interaction between async codes (async <-> async) in one thread as regular async primitives, async codes (async <-> async) in multiple threads, async code and sync one (async <-> sync) in one thread, async code and sync one (async <-> sync) in multiple threads, sync codes (sync <-> sync) in one thread as regular sync primitives, sync codes (sync <-> sync) in multiple threads as regular sync primitives. It offers synchronization primitives like events, barriers, semaphores, capacity limiters, locks, readers-writer locks, condition variables, communication primitives like queues, non-blocking primitives like flags and resource guards, and supports various concurrency libraries like asyncio, curio, trio, anyio, eventlet, gevent, and threading. aiologic is implemented entirely on effectively atomic operations, providing incredible speedup on PyPy compared to alternatives from the threading module. It works in free-threaded mode and ensures atomic operations even with GIL.
For similar tasks
alog
ALog is an open-source project designed to facilitate the deployment of server-side code to Cloudflare. It provides a step-by-step guide on creating a Cloudflare worker, configuring environment variables, and updating API base URL. The project aims to simplify the process of deploying server-side code and interacting with OpenAI API. ALog is distributed under the GNU General Public License v2.0, allowing users to modify and distribute the app while adhering to App Store Review Guidelines.
crabml
Crabml is a llama.cpp compatible AI inference engine written in Rust, designed for efficient inference on various platforms with WebGPU support. It focuses on running inference tasks with SIMD acceleration and minimal memory requirements, supporting multiple models and quantization methods. The project is hackable, embeddable, and aims to provide high-performance AI inference capabilities.
chatllm.cpp
ChatLLM.cpp is a pure C++ implementation tool for real-time chatting with RAG on your computer. It supports inference of various models ranging from less than 1B to more than 300B. The tool provides accelerated memory-efficient CPU inference with quantization, optimized KV cache, and parallel computing. It allows streaming generation with a typewriter effect and continuous chatting with virtually unlimited content length. ChatLLM.cpp also offers features like Retrieval Augmented Generation (RAG), LoRA, Python/JavaScript/C bindings, web demo, and more possibilities. Users can clone the repository, quantize models, build the project using make or CMake, and run quantized models for interactive chatting.
ai-dial-core
AI DIAL Core is an HTTP Proxy that provides a unified API to different chat completion and embedding models, assistants, and applications. It is written in Java 17 and built on Eclipse Vert.x. The core functionality includes handling static and dynamic settings, deployment on Kubernetes using Helm charts, and storing user data in Blob Storage and Redis. It supports various identity providers, storage providers like AWS S3, Google Cloud Storage, and Azure Blob Store, and features like AI DIAL Addons, Interceptors, Assistants, Applications, and Models with customizable parameters and configurations.
coze-js
Coze-js is a monorepo containing packages for Coze API and Realtime API. It provides usage examples for Node.js and React Web, as well as full console and sample call up demos. The tool requires Node.js 18+, pnpm 9.12.0, and Rush 5.140.0 for installation. Developers can start developing projects within the repository by following the provided steps. Each package in the monorepo can be developed and published independently, with documentation on contributing guidelines and publishing. The tool is licensed under MIT.
mcp-framework
MCP-Framework is a TypeScript framework for building Model Context Protocol (MCP) servers with automatic directory-based discovery for tools, resources, and prompts. It provides powerful abstractions, simple server setup, and a CLI for rapid development and project scaffolding.
TheNinjaRPG
TheNinja-RPG is the official source code for the game www.TheNinja-RPG.com. It relies on external services for authentication, websockets, database, etc. Users need to sign up for free accounts on services like Clerk, UploadThing, and Replicate. The codebase provides various 'make' commands for setup, building, and database management. The project does not have a specific license and is under exclusive copyright protection.
farfalle
Farfalle is an open-source AI-powered search engine that allows users to run their own local LLM or utilize the cloud. It provides a tech stack including Next.js for frontend, FastAPI for backend, Tavily for search API, Logfire for logging, and Redis for rate limiting. Users can get started by setting up prerequisites like Docker and Ollama, and obtaining API keys for Tavily, OpenAI, and Groq. The tool supports models like llama3, mistral, and gemma. Users can clone the repository, set environment variables, run containers using Docker Compose, and deploy the backend and frontend using services like Render and Vercel.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.