
crabml
a fast cross platform AI inference engine 🤖 using Rust 🦀 and WebGPU 🎮
Stars: 412
Crabml is a llama.cpp compatible AI inference engine written in Rust, designed for efficient inference on various platforms with WebGPU support. It focuses on running inference tasks with SIMD acceleration and minimal memory requirements, supporting multiple models and quantization methods. The project is hackable, embeddable, and aims to provide high-performance AI inference capabilities.
README:

crabml is a llama.cpp compatible (and equally fast!) AI inference engine written in 🦀 Rust, which runs everywhere with the help of 🎮 WebGPU.
crabml is designed with the following objectives in mind:
- 🤖 Focus solely on inference.
- 🎮 Runs on browsers, desktops, and servers everywhere with the help of WebGPU.
- ⏩ SIMD-accelerated inference on inexpensive hardware.
- 💼
mmap()from day one, minimized memory requirement with various quantization support. - 👾 Hackable & embeddable.
crabml supports the following models in GGUF format:
- 🦙 Llama
- 🦙 CodeLlama
- 🦙 Gemma
- 〽️ Mistral
- 🚄 On the way: Mistral MoE, Phi, QWen, StarCoder, Llava, and more!
For more information, you can visit How to Get GGUF Models to learn how to download the GGUF files you need.
crabml supports the following quantization methods on CPUs with SIMD acceleration for ARM (including Apple Silicon) and x86 architectures:
| Bits | Native CPU | NEON | AVX2 | RISC-V SIMD | WebGPU | |
|---|---|---|---|---|---|---|
| Q8_0 | 8 bits | ✅ | ✅ | ✅ | WIP | WIP |
| Q8_K | 8 bits | ✅ | ✅ | ✅ | WIP | WIP |
| Q6_K | 6 bits | ✅ | WIP | WIP | WIP | WIP |
| Q5_0 | 5 bits | ✅ | ✅ | ✅ | WIP | WIP |
| Q5_1 | 5 bits | ✅ | ✅ | ✅ | WIP | WIP |
| Q5_K | 5 bits | ✅ | WIP | WIP | WIP | WIP |
| Q4_0 | 4 bits | ✅ | ✅ | ✅ | WIP | WIP |
| Q4_1 | 4 bits | ✅ | ✅ | ✅ | WIP | WIP |
| Q4_K | 4 bits | ✅ | WIP | WIP | WIP | WIP |
| Q3_K | 3 bits | ✅ | WIP | WIP | WIP | WIP |
| Q2_K | 2 bits | ✅ | WIP | WIP | WIP | WIP |
As the table above suggests, WebGPU-accelerated quantizations are still under busy development, and Q8_0, Q4_0, Q4_1 are currently the most recommended quantization methods on CPUs!
To build crabml, set the RUSTFLAGS environment variable to enable specific target features. For example, to enable NEON on ARM architectures, use RUSTFLAGS="-C target-feature=+neon". Then build the project with the following command:
cargo build --releaseThis command compiles the project in release mode, which optimizes the binary for performance.
After building the project, you can run an example inference by executing the crabml-cli binary with appropriate arguments. For instance, to use the tinyllamas-stories-15m-f32.gguf model to generate text based on the prompt "captain america", execute the command below:
./target/release/crabml-cli \
-m ./testdata/tinyllamas-stories-15m-f32.gguf \
"captain america" --steps 100 \
-t 0.8 -p 1.0In this command:
-
-mspecifies the checkpoint file. -
--stepsdefines the number of tokens to generate. -
-tsets the temperature, which controls the randomness of the output. -
-psets the probability of sampling from the top-p.
This contribution is licensed under Apache License, Version 2.0, (LICENSE or http://www.apache.org/licenses/LICENSE-2.0)
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for crabml
Similar Open Source Tools
crabml
Crabml is a llama.cpp compatible AI inference engine written in Rust, designed for efficient inference on various platforms with WebGPU support. It focuses on running inference tasks with SIMD acceleration and minimal memory requirements, supporting multiple models and quantization methods. The project is hackable, embeddable, and aims to provide high-performance AI inference capabilities.

awsome-distributed-training
This repository contains reference architectures and test cases for distributed model training with Amazon SageMaker Hyperpod, AWS ParallelCluster, AWS Batch, and Amazon EKS. The test cases cover different types and sizes of models as well as different frameworks and parallel optimizations (Pytorch DDP/FSDP, MegatronLM, NemoMegatron...).
bionemo-framework
NVIDIA BioNeMo Framework is a collection of programming tools, libraries, and models for computational drug discovery. It accelerates building and adapting biomolecular AI models by providing domain-specific, optimized models and tooling for GPU-based computational resources. The framework offers comprehensive documentation and support for both community and enterprise users.

dl_model_infer
This project is a c++ version of the AI reasoning library that supports the reasoning of tensorrt models. It provides accelerated deployment cases of deep learning CV popular models and supports dynamic-batch image processing, inference, decode, and NMS. The project has been updated with various models and provides tutorials for model exports. It also includes a producer-consumer inference model for specific tasks. The project directory includes implementations for model inference applications, backend reasoning classes, post-processing, pre-processing, and target detection and tracking. Speed tests have been conducted on various models, and onnx downloads are available for different models.
aikit
AIKit is a one-stop shop to quickly get started to host, deploy, build and fine-tune large language models (LLMs). AIKit offers two main capabilities: Inference: AIKit uses LocalAI, which supports a wide range of inference capabilities and formats. LocalAI provides a drop-in replacement REST API that is OpenAI API compatible, so you can use any OpenAI API compatible client, such as Kubectl AI, Chatbot-UI and many more, to send requests to open-source LLMs! Fine Tuning: AIKit offers an extensible fine tuning interface. It supports Unsloth for fast, memory efficient, and easy fine-tuning experience.
aikit
AIKit is a comprehensive platform for hosting, deploying, building, and fine-tuning large language models (LLMs). It offers inference using LocalAI, extensible fine-tuning interface, and OCI packaging for distributing models. AIKit supports various models, multi-modal model and image generation, Kubernetes deployment, and supply chain security. It can run on AMD64 and ARM64 CPUs, NVIDIA GPUs, and Apple Silicon (experimental). Users can quickly get started with AIKit without a GPU and access pre-made models. The platform is OpenAI API compatible and provides easy-to-use configuration for inference and fine-tuning.

EasyEdit
EasyEdit is a Python package for edit Large Language Models (LLM) like `GPT-J`, `Llama`, `GPT-NEO`, `GPT2`, `T5`(support models from **1B** to **65B**), the objective of which is to alter the behavior of LLMs efficiently within a specific domain without negatively impacting performance across other inputs. It is designed to be easy to use and easy to extend.

PredictorLLM
PredictorLLM is an advanced trading agent framework that utilizes large language models to automate trading in financial markets. It includes a profiling module to establish agent characteristics, a layered memory module for retaining and prioritizing financial data, and a decision-making module to convert insights into trading strategies. The framework mimics professional traders' behavior, surpassing human limitations in data processing and continuously evolving to adapt to market conditions for superior investment outcomes.

qserve
QServe is a serving system designed for efficient and accurate Large Language Models (LLM) on GPUs with W4A8KV4 quantization. It achieves higher throughput compared to leading industry solutions, allowing users to achieve A100-level throughput on cheaper L40S GPUs. The system introduces the QoQ quantization algorithm with 4-bit weight, 8-bit activation, and 4-bit KV cache, addressing runtime overhead challenges. QServe improves serving throughput for various LLM models by implementing compute-aware weight reordering, register-level parallelism, and fused attention memory-bound techniques.
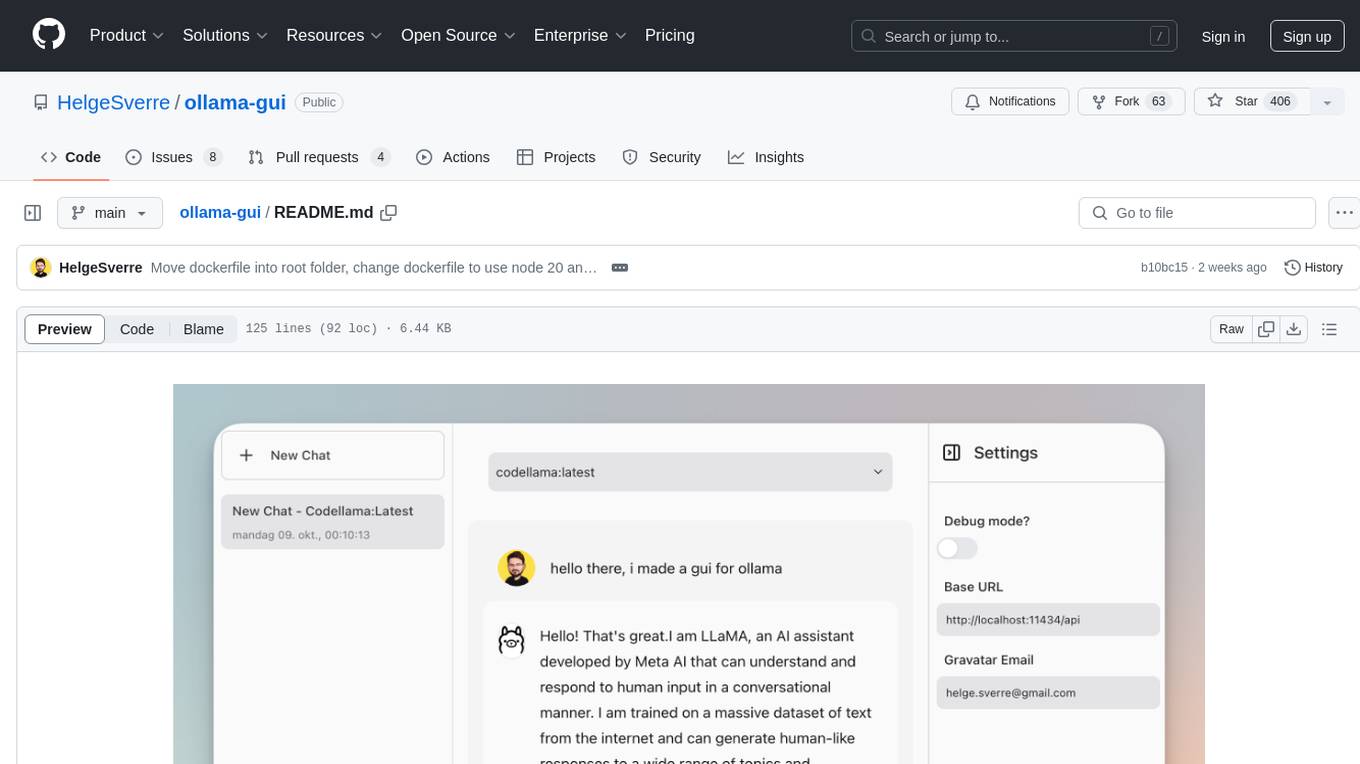
ollama-gui
Ollama GUI is a web interface for ollama.ai, a tool that enables running Large Language Models (LLMs) on your local machine. It provides a user-friendly platform for chatting with LLMs and accessing various models for text generation. Users can easily interact with different models, manage chat history, and explore available models through the web interface. The tool is built with Vue.js, Vite, and Tailwind CSS, offering a modern and responsive design for seamless user experience.
ai-hands-on
A complete, hands-on guide to becoming an AI Engineer. This repository is designed to help you learn AI from first principles, build real neural networks, and understand modern LLM systems end-to-end. Progress through math, PyTorch, deep learning, transformers, RAG, and OCR with clean, intuitive Jupyter notebooks guiding you at every step. Suitable for beginners and engineers leveling up, providing clarity, structure, and intuition to build real AI systems.

llm-compression-intelligence
This repository presents the findings of the paper "Compression Represents Intelligence Linearly". The study reveals a strong linear correlation between the intelligence of LLMs, as measured by benchmark scores, and their ability to compress external text corpora. Compression efficiency, derived from raw text corpora, serves as a reliable evaluation metric that is linearly associated with model capabilities. The repository includes the compression corpora used in the paper, code for computing compression efficiency, and data collection and processing pipelines.
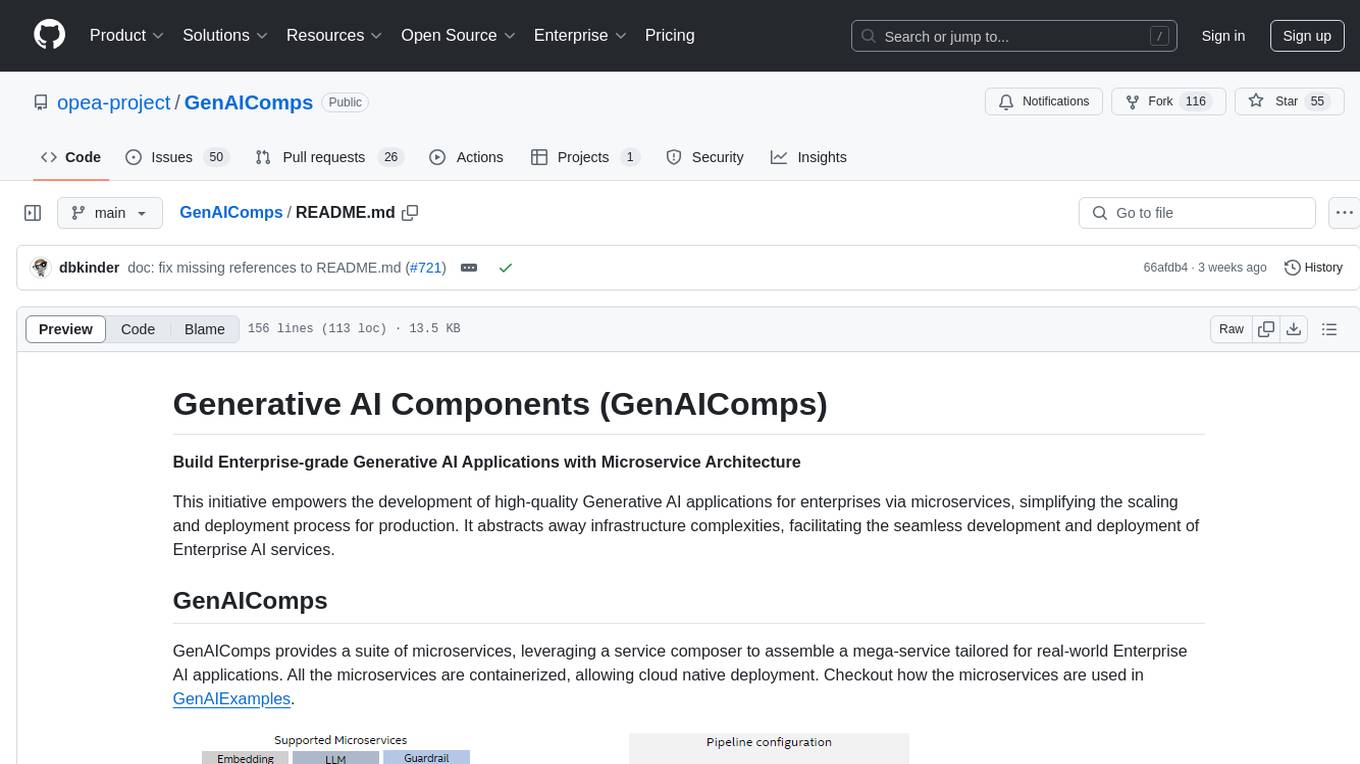
GenAIComps
GenAIComps is an initiative aimed at building enterprise-grade Generative AI applications using a microservice architecture. It simplifies the scaling and deployment process for production, abstracting away infrastructure complexities. GenAIComps provides a suite of containerized microservices that can be assembled into a mega-service tailored for real-world Enterprise AI applications. The modular approach of microservices allows for independent development, deployment, and scaling of individual components, promoting modularity, flexibility, and scalability. The mega-service orchestrates multiple microservices to deliver comprehensive solutions, encapsulating complex business logic and workflow orchestration. The gateway serves as the interface for users to access the mega-service, providing customized access based on user requirements.
beet
Beet is a collection of crates for authoring and running web pages, games and AI behaviors. It includes crates like `beet_flow` for scenes-as-control-flow bevy library, `beet_spatial` for spatial behaviors, `beet_ml` for machine learning, `beet_sim` for simulation tooling, `beet_rsx` for authoring tools for html and bevy, and `beet_router` for file-based router for web docs. The `beet` crate acts as a base crate that re-exports sub-crates based on feature flags, similar to the `bevy` crate structure.
awesome-generative-ai-data-scientist
A curated list of 50+ resources to help you become a Generative AI Data Scientist. This repository includes resources on building GenAI applications with Large Language Models (LLMs), and deploying LLMs and GenAI with Cloud-based solutions.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.
For similar tasks
alog
ALog is an open-source project designed to facilitate the deployment of server-side code to Cloudflare. It provides a step-by-step guide on creating a Cloudflare worker, configuring environment variables, and updating API base URL. The project aims to simplify the process of deploying server-side code and interacting with OpenAI API. ALog is distributed under the GNU General Public License v2.0, allowing users to modify and distribute the app while adhering to App Store Review Guidelines.
crabml
Crabml is a llama.cpp compatible AI inference engine written in Rust, designed for efficient inference on various platforms with WebGPU support. It focuses on running inference tasks with SIMD acceleration and minimal memory requirements, supporting multiple models and quantization methods. The project is hackable, embeddable, and aims to provide high-performance AI inference capabilities.
chatllm.cpp
ChatLLM.cpp is a pure C++ implementation tool for real-time chatting with RAG on your computer. It supports inference of various models ranging from less than 1B to more than 300B. The tool provides accelerated memory-efficient CPU inference with quantization, optimized KV cache, and parallel computing. It allows streaming generation with a typewriter effect and continuous chatting with virtually unlimited content length. ChatLLM.cpp also offers features like Retrieval Augmented Generation (RAG), LoRA, Python/JavaScript/C bindings, web demo, and more possibilities. Users can clone the repository, quantize models, build the project using make or CMake, and run quantized models for interactive chatting.
ai-dial-core
AI DIAL Core is an HTTP Proxy that provides a unified API to different chat completion and embedding models, assistants, and applications. It is written in Java 17 and built on Eclipse Vert.x. The core functionality includes handling static and dynamic settings, deployment on Kubernetes using Helm charts, and storing user data in Blob Storage and Redis. It supports various identity providers, storage providers like AWS S3, Google Cloud Storage, and Azure Blob Store, and features like AI DIAL Addons, Interceptors, Assistants, Applications, and Models with customizable parameters and configurations.
coze-js
Coze-js is a monorepo containing packages for Coze API and Realtime API. It provides usage examples for Node.js and React Web, as well as full console and sample call up demos. The tool requires Node.js 18+, pnpm 9.12.0, and Rush 5.140.0 for installation. Developers can start developing projects within the repository by following the provided steps. Each package in the monorepo can be developed and published independently, with documentation on contributing guidelines and publishing. The tool is licensed under MIT.
mcp-framework
MCP-Framework is a TypeScript framework for building Model Context Protocol (MCP) servers with automatic directory-based discovery for tools, resources, and prompts. It provides powerful abstractions, simple server setup, and a CLI for rapid development and project scaffolding.
TheNinjaRPG
TheNinja-RPG is the official source code for the game www.TheNinja-RPG.com. It relies on external services for authentication, websockets, database, etc. Users need to sign up for free accounts on services like Clerk, UploadThing, and Replicate. The codebase provides various 'make' commands for setup, building, and database management. The project does not have a specific license and is under exclusive copyright protection.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.