
MemoAI
MemoAI Video to translated text, subtitles and notes made easy.
Stars: 610
MemoAI is an AI-powered tool that provides podcast, video-to-text, and subtitling capabilities for immediate use. It supports audio and video transcription, model selection for paragraph effects, local subtitles translation, text translation using Google, Microsoft, Volcano Translation, DeepL, and AI Translation, speech synthesis in multiple languages, and exporting text and subtitles in common formats. MemoAI is designed to simplify the process of transcribing, translating, and creating subtitles for various media content.
README:
Ai-powered podcast, video-to-text, and subtitling tools for immediate experience.
Welcome to MemoAI. This article will show you all the capabilities of Memo and how to use it.
Memo support macOS Silicon, macOS Intel and Windows.
https://github.com/Makememo/MemoAI/releases
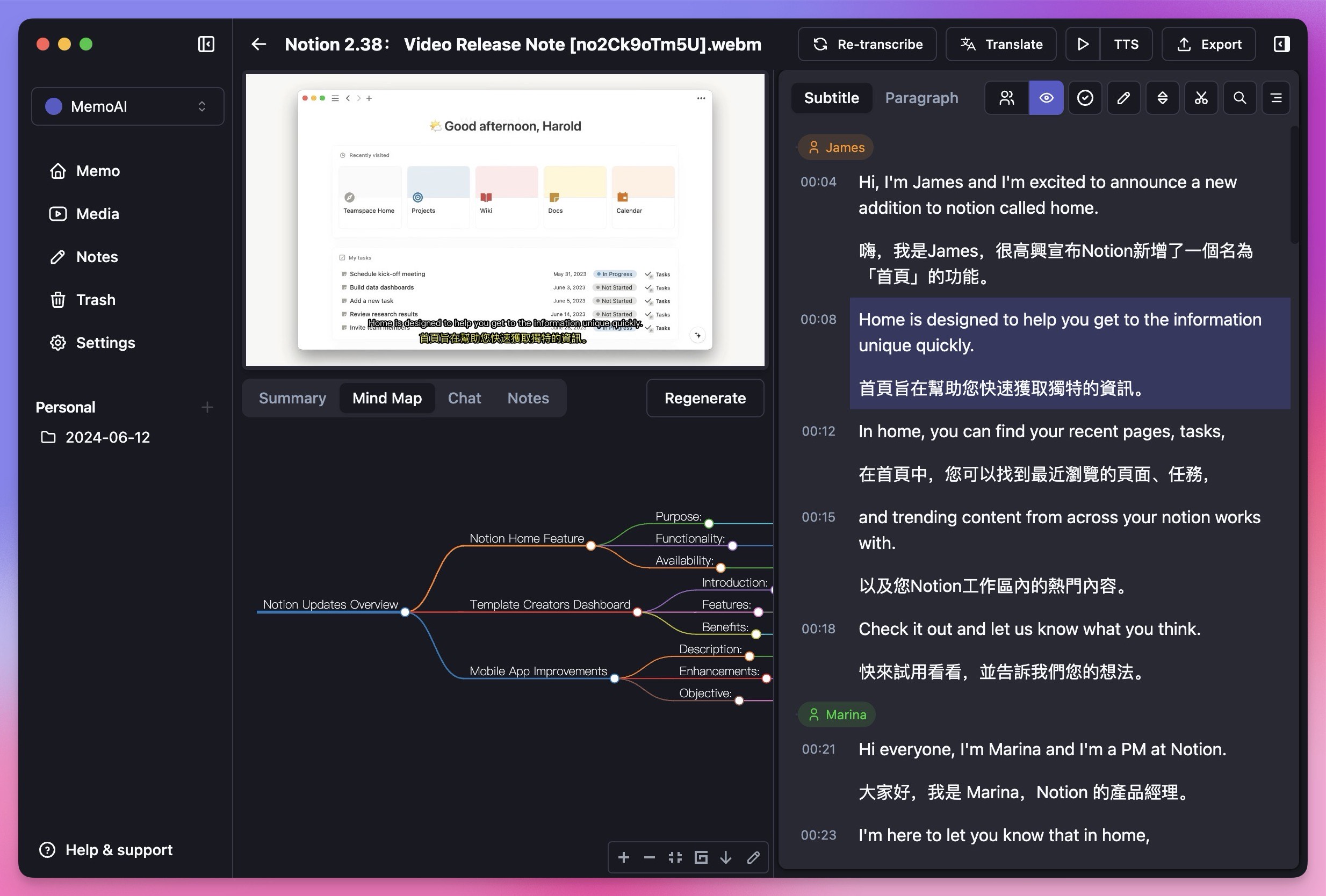
Memo supports online and local audio and video file conversion.
- Copy YouTube link or podcast link
- Paste into the Memo input box
- Click transcribe to start the conversion process.
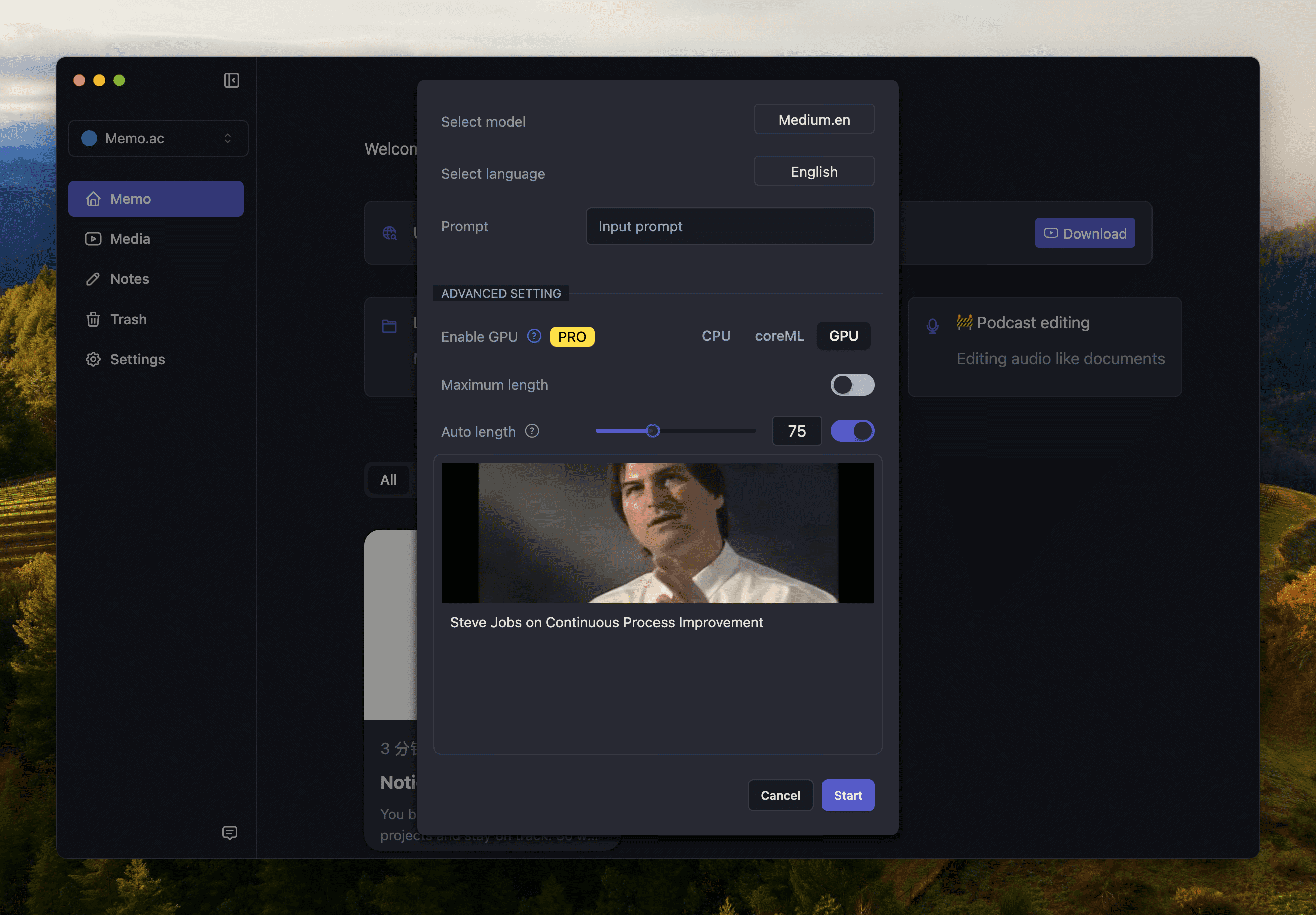
MemoAI can transcribe local files in audio and video formats such as MP4, MP3, AAC, M4A, etc. without the need for conversion. Please note that the name of the file to be converted should not contain special characters, otherwise MemoAI will not recognize it.
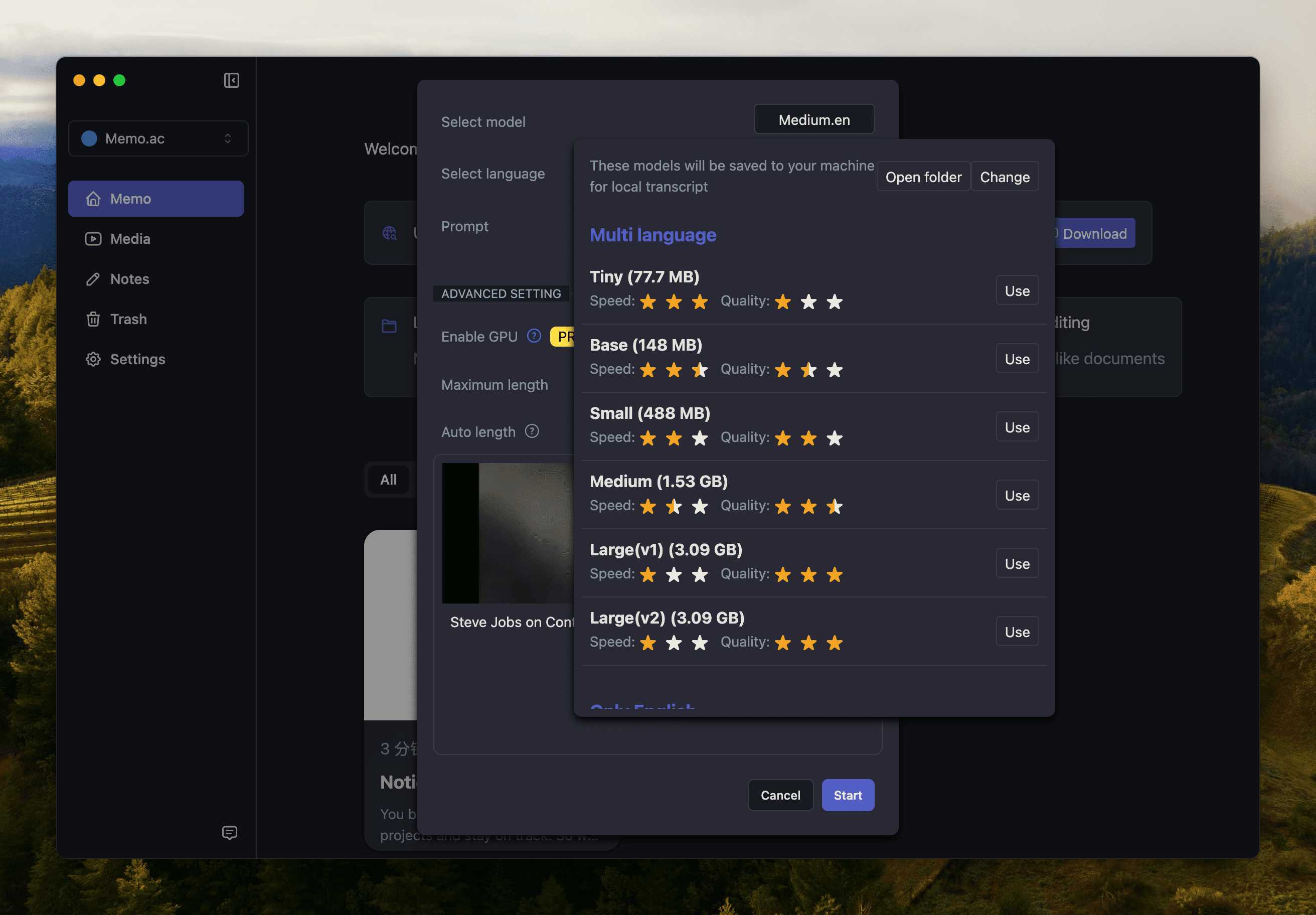
Need AI output paragraph effect? You can directly adjust the maximum number of words in the paragraph, usually 300.
If you already have a subtitle file and only need to translate it, you can upload the file directly. We currently support SRT and VTT formats.
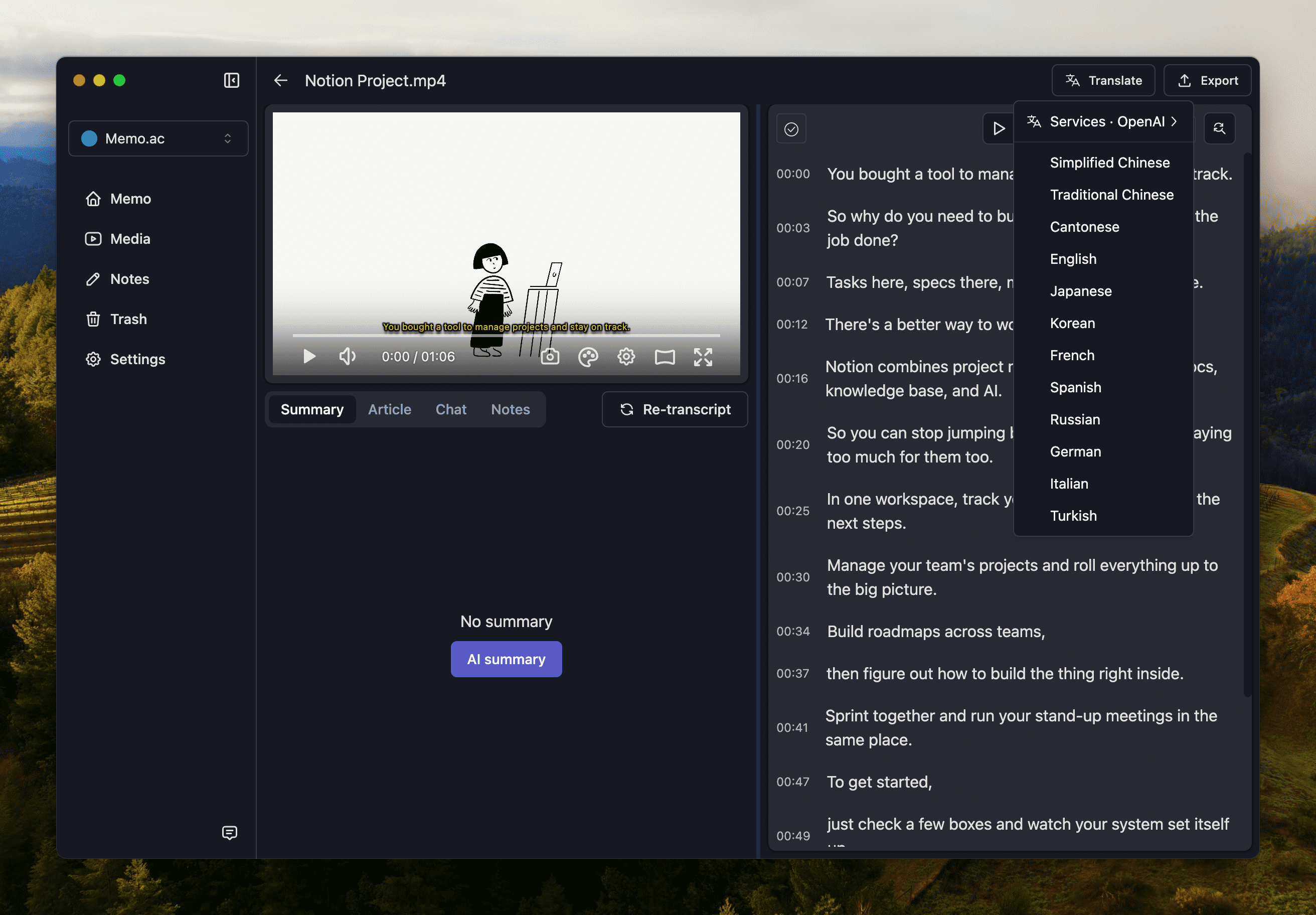
Memo has two built-in free translations, Google and Microsoft, which can meet the needs of daily use. If you prefer other translation services, you can use Volcano Translation, DeepL and AI Translation.
If the translation is not satisfactory, you can click the line translation option to translate again.
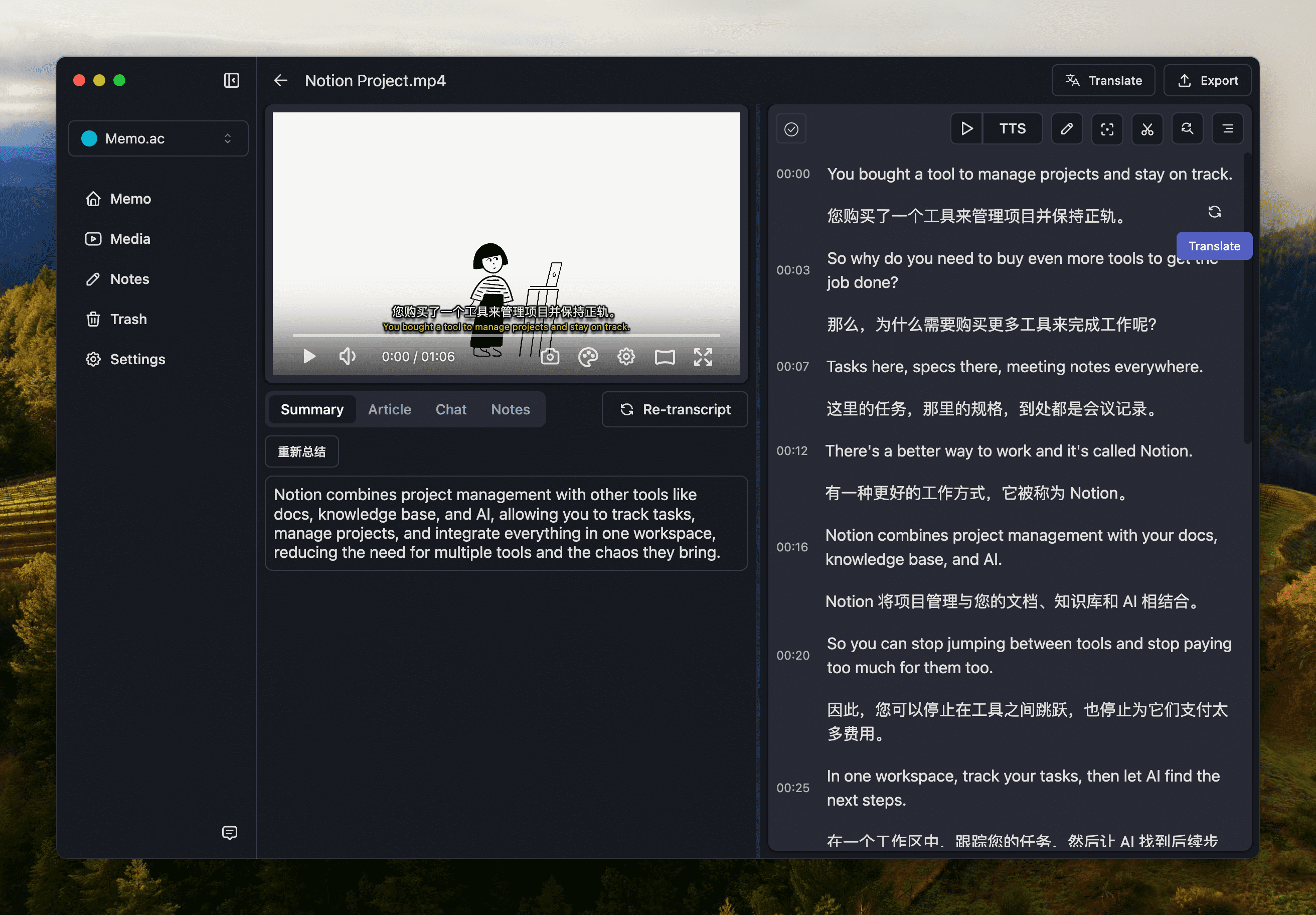
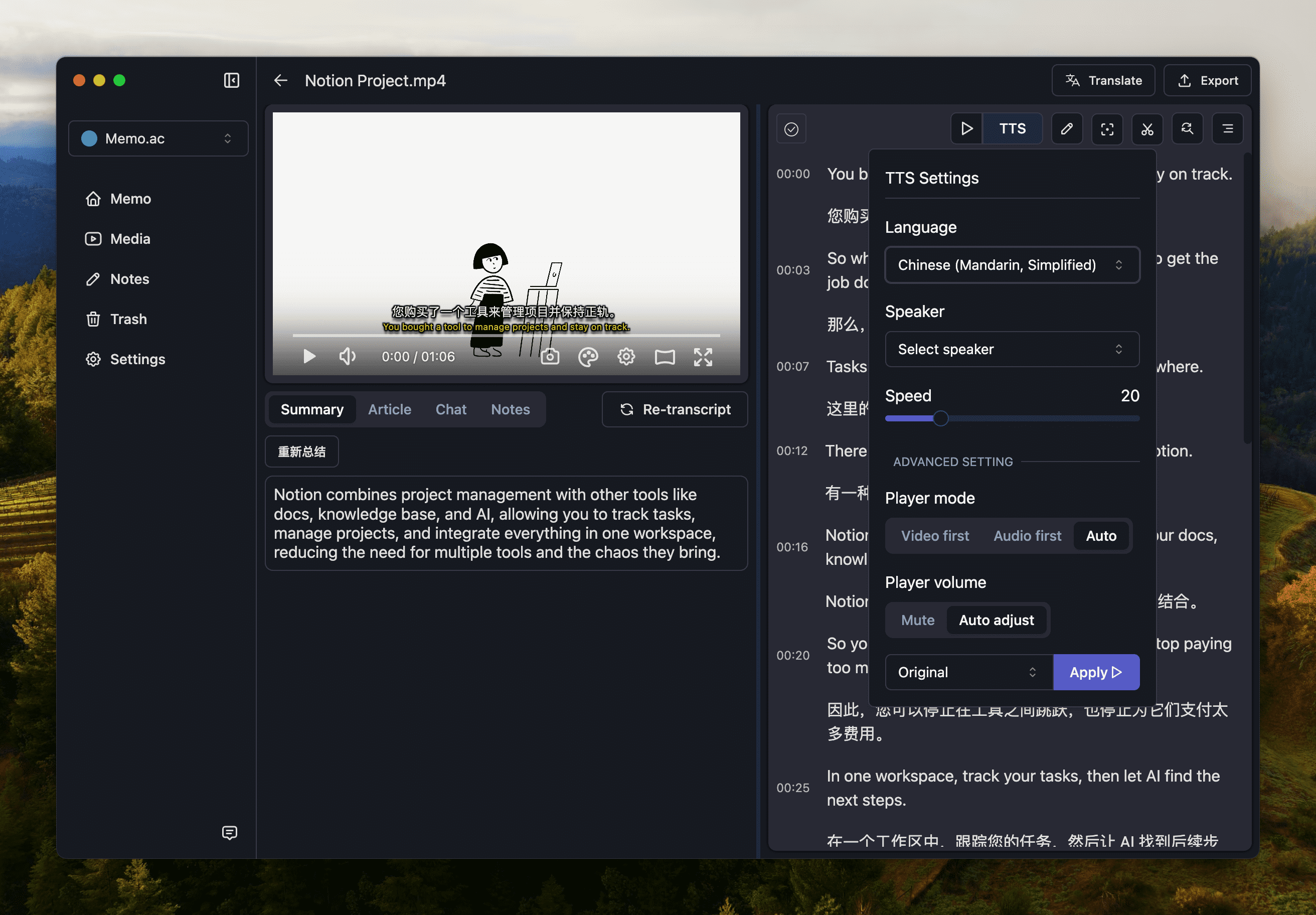
We support a variety of speech synthesis methods, and other translated languages can be dubbed over the original media.
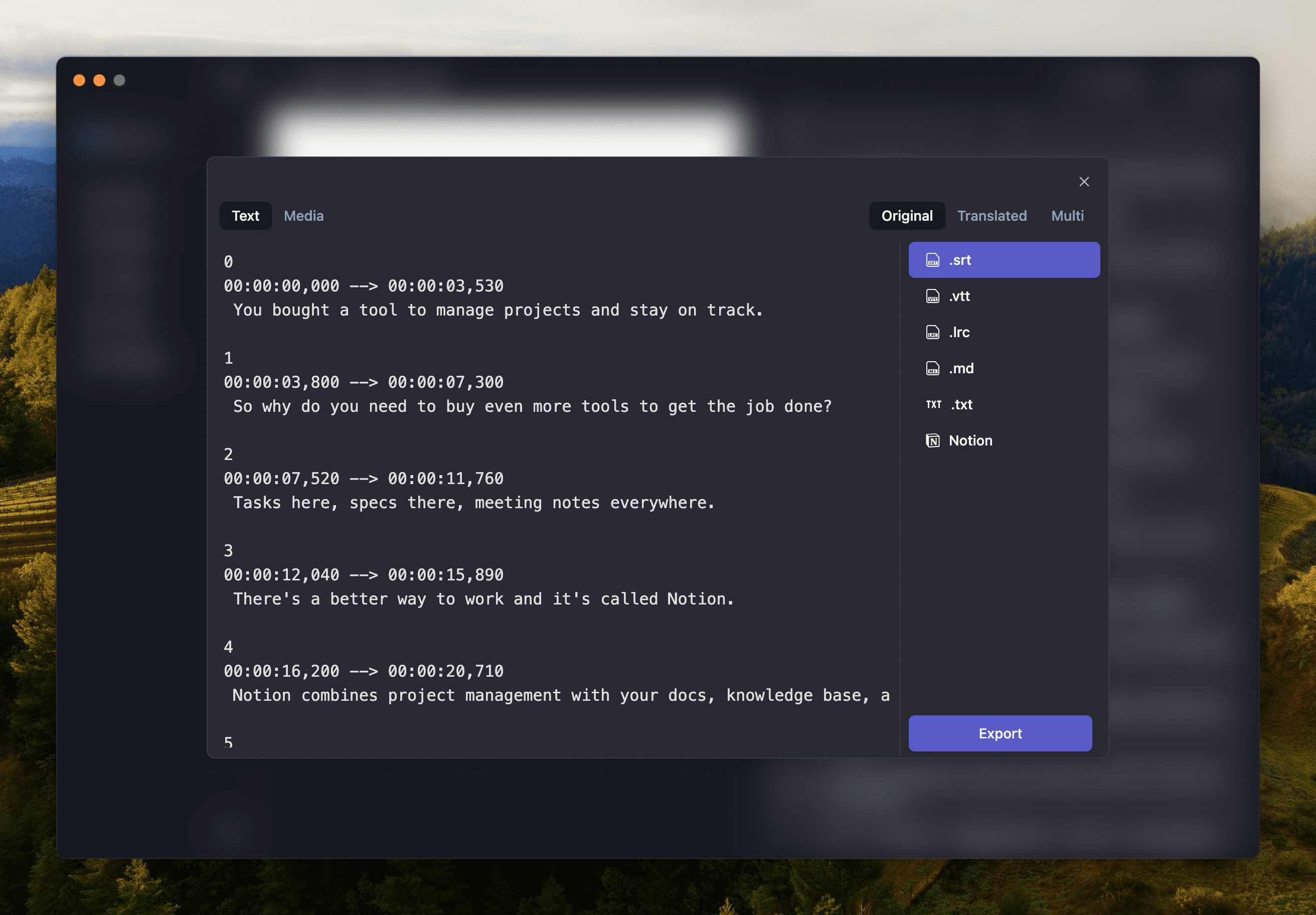
Memo supports exporting common subtitle formats such as SRT, VTT, etc., eliminating the need for manual adjustments. We also support synchronized export with Markdown and other tools.
- Twitter: https://twitter.com/FemoHQ
- What's New: https://memo.ac/releases
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MemoAI
Similar Open Source Tools
MemoAI
MemoAI is an AI-powered tool that provides podcast, video-to-text, and subtitling capabilities for immediate use. It supports audio and video transcription, model selection for paragraph effects, local subtitles translation, text translation using Google, Microsoft, Volcano Translation, DeepL, and AI Translation, speech synthesis in multiple languages, and exporting text and subtitles in common formats. MemoAI is designed to simplify the process of transcribing, translating, and creating subtitles for various media content.

TeroSubtitler
Tero Subtitler is an open source, cross-platform, and free subtitle editing software with a user-friendly interface. It offers fully fledged editing with SMPTE and MEDIA modes, support for various subtitle formats, multi-level undo/redo, search and replace, auto-backup, source and transcription modes, translation memory, audiovisual preview, timeline with waveform visualizer, manipulation tools, formatting options, quality control features, translation and transcription capabilities, validation tools, automation for correcting errors, and more. It also includes features like exporting subtitles to MP3, importing/exporting Blu-ray SUP format, generating blank video, generating video with hardcoded subtitles, video dubbing, and more. The tool utilizes powerful multimedia playback engines like mpv, advanced audio/video manipulation tools like FFmpeg, tools for automatic transcription like whisper.cpp/Faster-Whisper, auto-translation API like Google Translate, and ElevenLabs TTS for video dubbing.
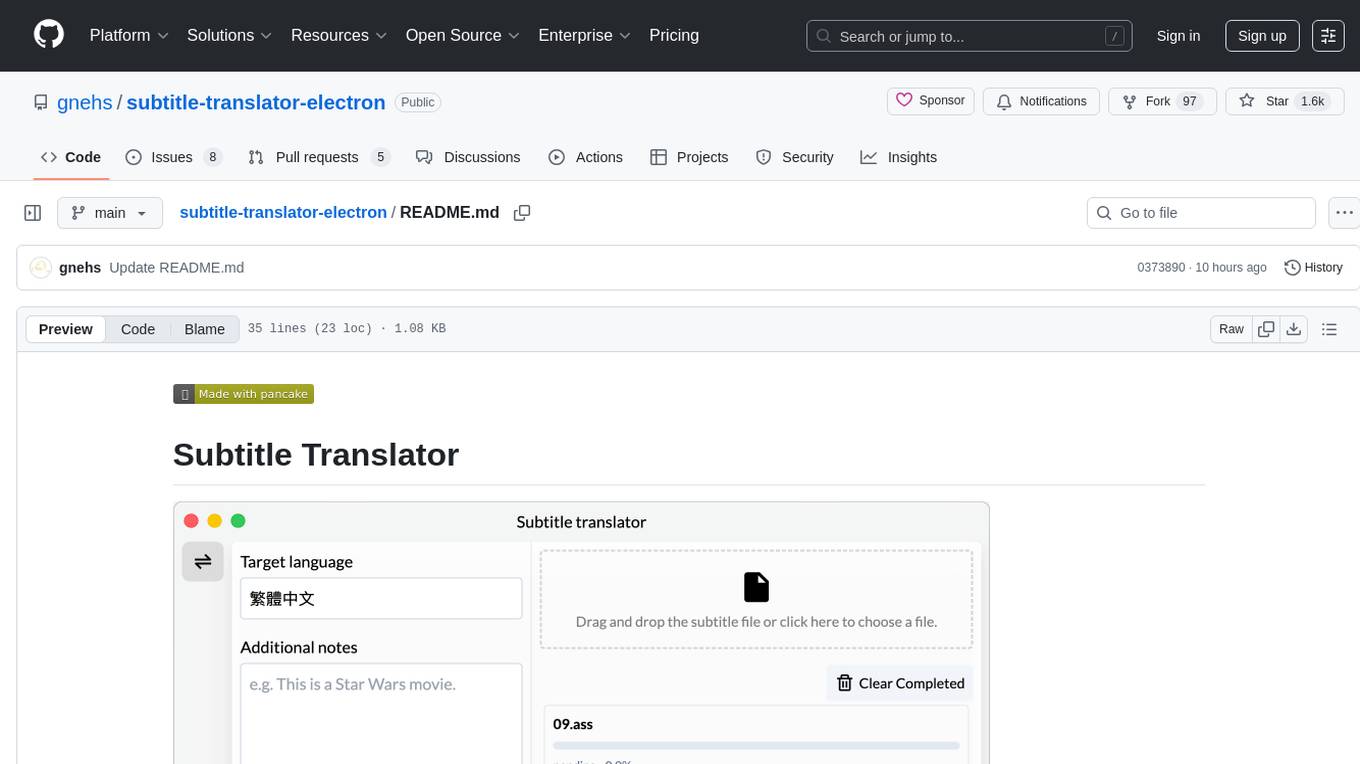
subtitle-translator-electron
Subtitle Translator is a tool that utilizes ChatGPT to translate subtitles in various formats such as .ass, .srt, .ssa, and .vtt. It supports multiple languages and provides translations based on context from preceding and following sentences. Users can download the stable version from the Releases page and contribute through pull requests. The tool aims to simplify the process of translating subtitles for different media content.
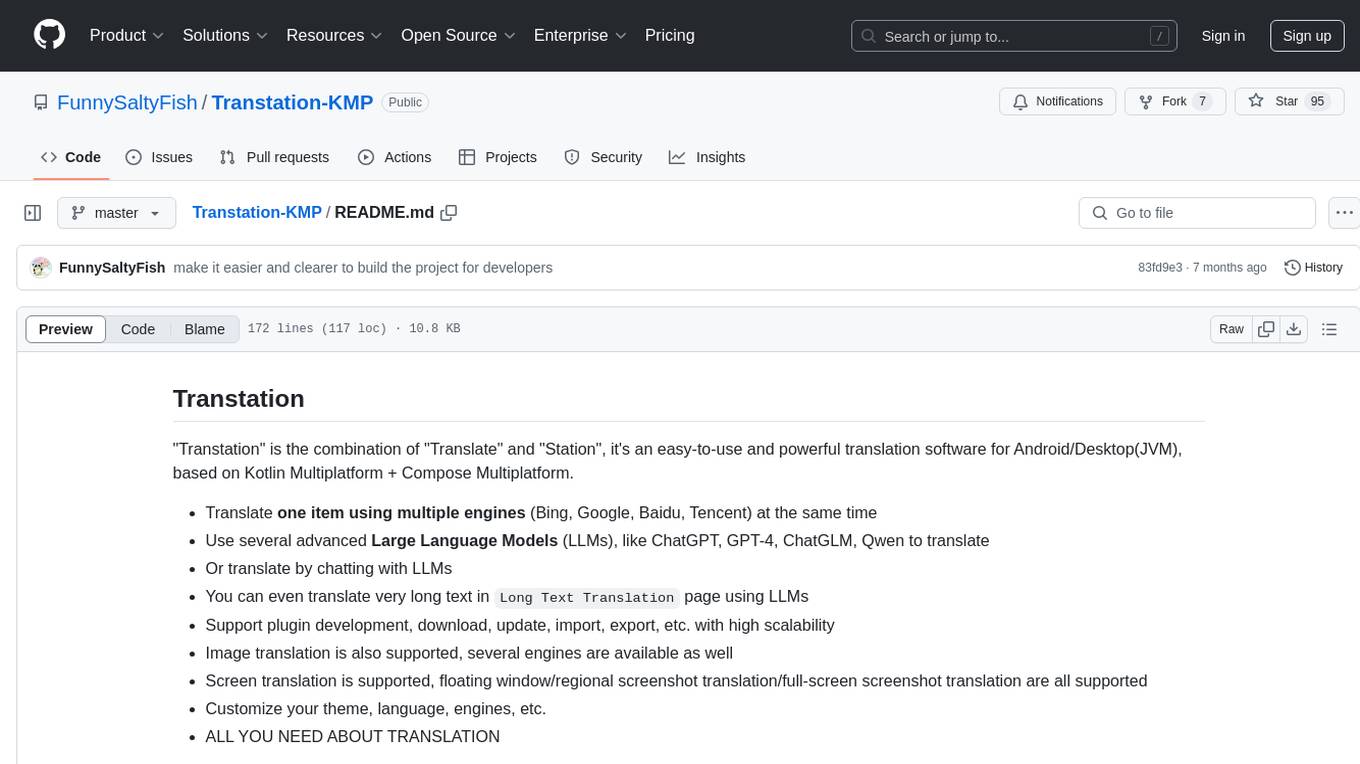
Transtation-KMP
Transtation is an easy-to-use and powerful translation software for Android/Desktop based on Kotlin Multiplatform + Compose Multiplatform. It allows users to translate one item using multiple engines simultaneously, utilize advanced Large Language Models for translation, chat with LLMs for translation, translate long text, support plugin development, image translation, and screen translation. The application is designed for Chinese users and serves as a reference for learning Jetpack Compose or Compose Multiplatform. It features Kotlin Multiplatform, Compose Multiplatform, MVVM, Kotlin Coroutine, Flow, SqlDelight, synchronized translation with multiple engines, plugin development, and makes use of Kotlin language features like lazy loading, Coroutine, sealed classes, and reflection. The application gradually adapts to Android13 with features like setting application language separately and supporting Monet icon.
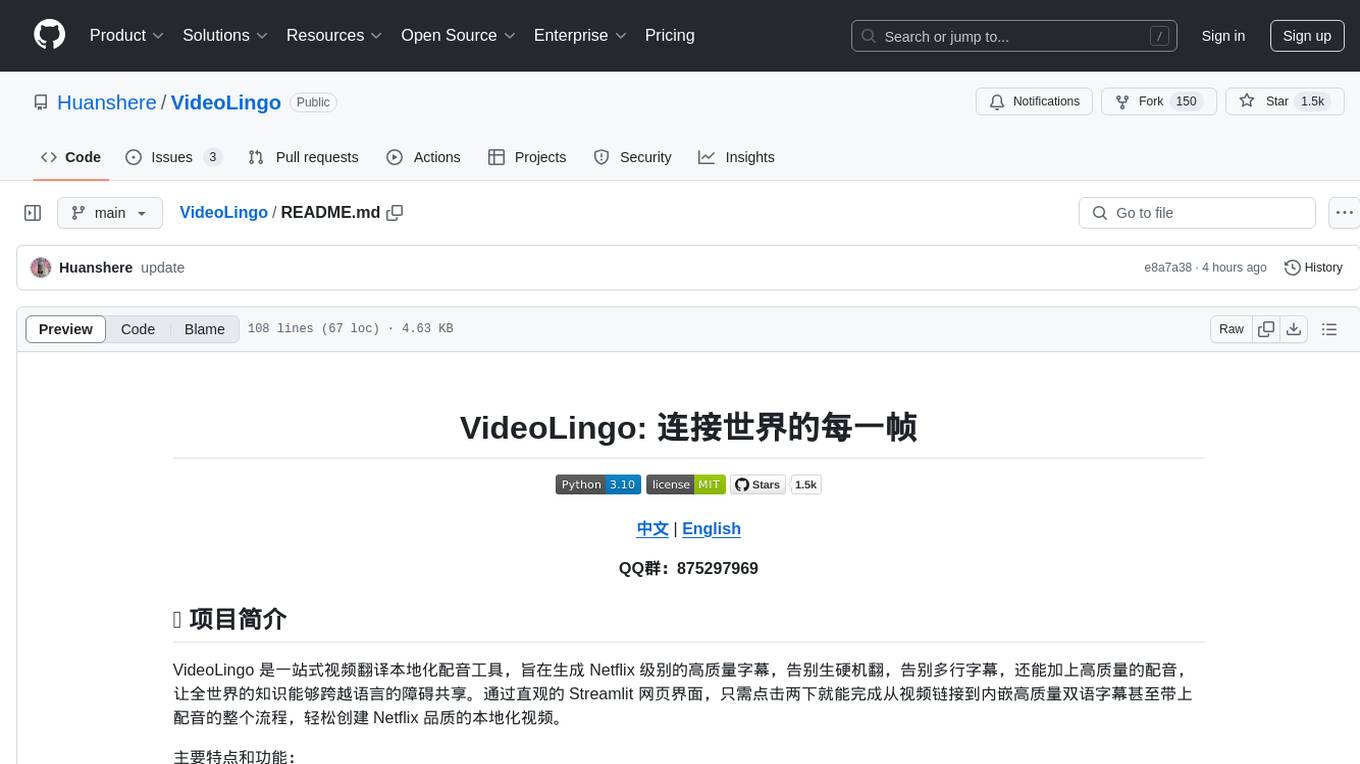
VideoLingo
VideoLingo is an all-in-one video translation and localization dubbing tool designed to generate Netflix-level high-quality subtitles. It aims to eliminate stiff machine translation, multiple lines of subtitles, and can even add high-quality dubbing, allowing knowledge from around the world to be shared across language barriers. Through an intuitive Streamlit web interface, the entire process from video link to embedded high-quality bilingual subtitles and even dubbing can be completed with just two clicks, easily creating Netflix-quality localized videos. Key features and functions include using yt-dlp to download videos from Youtube links, using WhisperX for word-level timeline subtitle recognition, using NLP and GPT for subtitle segmentation based on sentence meaning, summarizing intelligent term knowledge base with GPT for context-aware translation, three-step direct translation, reflection, and free translation to eliminate strange machine translation, checking single-line subtitle length and translation quality according to Netflix standards, using GPT-SoVITS for high-quality aligned dubbing, and integrating package for one-click startup and one-click output in streamlit.
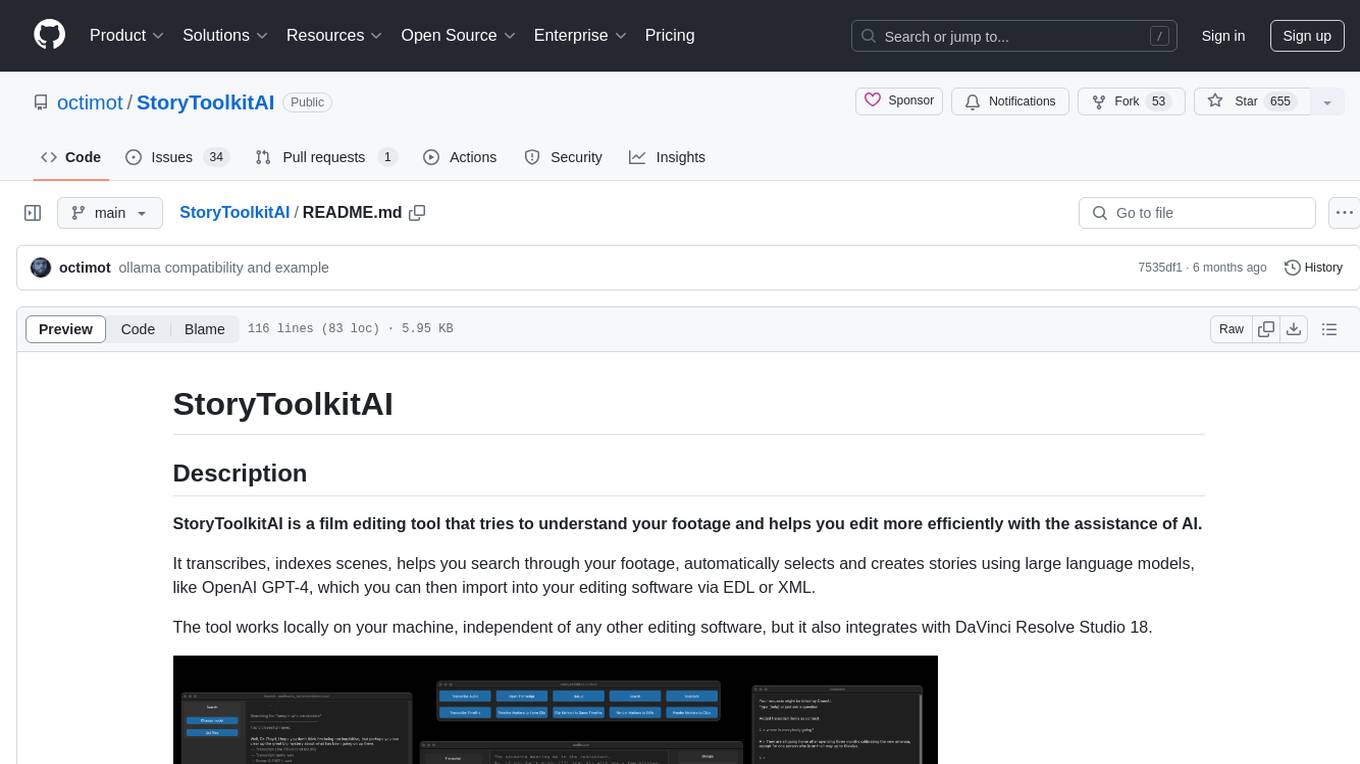
StoryToolkitAI
StoryToolkitAI is a film editing tool that utilizes AI to transcribe, index scenes, search through footage, and create stories. It offers features like full video indexing, automatic transcriptions and translations, compatibility with OpenAI GPT and ollama, story editor for screenplay writing, speaker detection, project file management, and more. It integrates with DaVinci Resolve Studio 18 and offers planned features like automatic topic classification and integration with other AI tools. The tool is developed by Octavian Mot and is actively being updated with new features based on user needs and feedback.
AiEditor
AiEditor is a next-generation rich text editor for AI, based on Web Component and supporting various front-end frameworks. It offers two themes, light and dark, along with flexible configuration for developing text editing applications. The editor includes features for basic text formatting, enhancements like undo/redo and format painter, support for attachments like images and videos, code-related functionalities, table manipulation, Markdown support, AI-related features such as continuation and optimization, and more. Planned improvements include collaboration, automated testing, AI picture insertion and drawing, enhanced paste features, WORD and PDF export, Notion-like operations, and integration with ChatGPT.

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.
groqnotes
Groqnotes is a streamlit app that helps users generate organized lecture notes from transcribed audio using Groq's Whisper API. It utilizes Llama3-8b and Llama3-70b models to structure and create content quickly. The app offers markdown styling for aesthetic notes, allows downloading notes as text or PDF files, and strategically switches between models for speed and quality balance. Users can access the hosted version at groqnotes.streamlit.app or run it locally with streamlit by setting up the Groq API key and installing dependencies.
manim-voiceover
Manim Voiceover is a plugin for the Manim animation library that allows users to easily add voiceovers to their videos directly in Python without the need for a separate video editor. It also provides the ability to record voiceovers using a command line interface and supports auto-generated AI voices from various services. Users can trigger animations at specific words in the voiceover, thanks to OpenAI Whisper. The plugin supports TTS services such as Azure Text to Speech, Coqui TTS, gTTS, and pyttsx3. It also offers features for translating voiceovers into other languages using machine translation services like DeepL.
obsidian-ai-assistant
Obsidian AI Assistant is a simple plugin that enables interactions with various AI models such as OpenAI ChatGPT, Anthropic Claude, OpenAI DALL·E, and OpenAI Whisper directly from Obsidian notes. The plugin offers features like text assistance, image generation, and speech-to-text functionality. Users can chat with the AI assistant, generate images for notes, and dictate notes using speech-to-text. The plugin allows customization of text models, image generation options, and language settings for speech-to-text. It requires official API keys for using OpenAI and Anthropic Claude models.

pyqt-openai
VividNode is a cross-platform AI desktop chatbot application for LLM such as GPT, Claude, Gemini, Llama chatbot interaction and image generation. It offers customizable features, local chat history, and enhanced performance without requiring a browser. The application is powered by GPT4Free and allows users to interact with chatbots and generate images seamlessly. VividNode supports Windows, Mac, and Linux, securely stores chat history locally, and provides features like chat interface customization, image generation, focus and accessibility modes, and extensive customization options with keyboard shortcuts for efficient operations.
duix.ai
Duix is a silicon-based digital human SDK for intelligent interaction, providing users with instant virtual human interaction experience on devices like Android and iOS. The SDK offers intuitive effect display and supports user customization through open documentation. It is fully open-source, allowing developers to understand its workings, optimize, and innovate further.

Easy-Voice-Toolkit
Easy Voice Toolkit is a toolkit based on open source voice projects, providing automated audio tools including speech model training. Users can seamlessly integrate functions like audio processing, voice recognition, voice transcription, dataset creation, model training, and voice conversion to transform raw audio files into ideal speech models. The toolkit supports multiple languages and is currently only compatible with Windows systems. It acknowledges the contributions of various projects and offers local deployment options for both users and developers. Additionally, cloud deployment on Google Colab is available. The toolkit has been tested on Windows OS devices and includes a FAQ section and terms of use for academic exchange purposes.
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.
SummaryYou
Summary You is a tool that utilizes AI to summarize YouTube videos, articles, images, and documents. Users can set the length of the summary and have the option to listen to the summaries. The tool also includes a history section, intelligent paywall detection, OLED-Dark Mode, and a user-friendly Material Design 3 style UI with dynamic color themes. It uses GPT-3.5 OpenAI/Mixtral 8x7B Groq for summarization. The backend is implemented in Python with Chaquopy, and some UI designs and codes are borrowed from Seal Material color utilities.
For similar tasks
MemoAI
MemoAI is an AI-powered tool that provides podcast, video-to-text, and subtitling capabilities for immediate use. It supports audio and video transcription, model selection for paragraph effects, local subtitles translation, text translation using Google, Microsoft, Volcano Translation, DeepL, and AI Translation, speech synthesis in multiple languages, and exporting text and subtitles in common formats. MemoAI is designed to simplify the process of transcribing, translating, and creating subtitles for various media content.
bolna
Bolna is an open-source platform for building voice-driven conversational applications using large language models (LLMs). It provides a comprehensive set of tools and integrations to handle various aspects of voice-based interactions, including telephony, transcription, LLM-based conversation handling, and text-to-speech synthesis. Bolna simplifies the process of creating voice agents that can perform tasks such as initiating phone calls, transcribing conversations, generating LLM-powered responses, and synthesizing speech. It supports multiple providers for each component, allowing users to customize their setup based on their specific needs. Bolna is designed to be easy to use, with a straightforward local setup process and well-documented APIs. It is also extensible, enabling users to integrate with other telephony providers or add custom functionality.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.

nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.

AudioLLM
AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.
FireRedTTS
FireRedTTS is a foundation text-to-speech framework designed for industry-level generative speech applications. It offers a rich-punctuation model with expanded punctuation coverage and enhanced audio production consistency. The tool provides pre-trained checkpoints, inference code, and an interactive demo space. Users can clone the repository, create a conda environment, download required model files, and utilize the tool for synthesizing speech in various languages. FireRedTTS aims to enhance stability and provide controllable human-like speech generation capabilities.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.