
ASR-LLM-TTS
This is a speech interaction system built on an open-source model, integrating ASR, LLM, and TTS in sequence. The ASR model is SenceVoice, the LLM models are QWen2.5-0.5B/1.5B, and there are three TTS models: CosyVoice, Edge-TTS, and pyttsx3
Stars: 272
ASR-LLM-TTS is a repository that provides detailed tutorials for setting up the environment, including installing anaconda, ffmpeg, creating virtual environments, and installing necessary libraries such as pytorch, torchaudio, edge-tts, funasr, and more. It also introduces features like voiceprint recognition, custom wake words, and conversation history memory. The repository combines CosyVoice for speech synthesis, SenceVoice for speech recognition, and QWen2.5 for dialogue understanding. It offers multiple speech synthesis methods including CoosyVoice, pyttsx3, and edgeTTS, with scripts for interactive inference provided. The repository aims to enable real-time speech interaction and multi-modal interactions involving audio and video.
README:
环境配置详细教程 B站
- anaconda\ffmpeg安装
网上很多教程,自行搜索
- 创建虚拟环境
conda create -n chatAudio python=3.10
conda activate chatAudio
- 安装pytorch+cuda版本,本地测试2.0以上版本均可,这里安装torch=2.3.1+cuda11.8
pip install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu118
其它适合自己电脑的torch+cuda版本可在torch官网查找
https://pytorch.org/get-started/previous-versions/
- 简易版本安装,不使用cosyvoice时依赖项较少
pip install edge-tts==6.1.17 funasr==1.1.12 ffmpeg==1.4 opencv-python==4.10.0.84 transformers==4.45.2 webrtcvad==2.0.10 qwen-vl-utils==0.0.8 pygame==2.6.1 langid==1.1.6 langdetect==1.0.9 accelerate==0.33.0 PyAudio==0.2.14
可执行验证:
python 13_SenceVoice_QWen2.5_edgeTTS_realTime.py
至此,不调用cosyvoice作为合成的交互可成功调用了。
- cosyvoice依赖库
大家反馈较多pynini、wetext安装方法:
conda install -c conda-forge pynini=2.1.6
pip install WeTextProcessing --no-deps
- cosyvoice其它依赖项安装(如遇到权限问题导致安装失败,以管理员形式打开终端)
pip install HyperPyYAML==1.2.2 modelscope==1.15.0 onnxruntime==1.19.2 openai-whisper==20231117 importlib_resources==6.4.5 sounddevice==0.5.1 matcha-tts==0.0.7.0
可执行验证:
python 10_SenceVoice_QWen2.5_cosyVoice.py
设置固定声纹注册语音存储目录,如目录为空则自动进入声纹注册模式。默认注册语音时长大于3秒,可自定义,一般而言时长越长,声纹效果越稳定。 声纹模型采用阿里开源的CAM++,其采用3D-Speaker中文数据训练,符合中文对话需求
使用SenceVoice的语音识别能力实现,将语音识别的汉字转为拼音进行匹配。将唤醒词/指令词设置为中文对应拼音,可自由定制。15.0_SenceVoice_kws_CAM++.py中默认为'ni hao xiao qian',15.1_SenceVoice_kws_CAM++.py中默认为'zhan qi lai'[暗影君王实在太cool辣]
通过建立user、system历史队列实现。开启新一轮对话时,首先获取历史记忆,而后拼接新的输入指令。可自由定义最大历史长度,默认为512。
对应脚本:
无历史记忆:15.0_SenceVoice_kws_CAM++.py
有历史记忆:15.1_SenceVoice_kws_CAM++.py
[演示demo,B站] (https://www.bilibili.com/video/BV1Q6zpYpEgv)
Have fun! 😊
使用webrtcvad进行实时vad检测,设置一个检测时间段=0.5s,有效语音激活率=40%,每个检测chunk=20ms。也就是说500ms/20ms=25个检测段,如果25*0.4=10个片段激活,则该0.5秒为有效音,加入缓存。
可改进点:使用模型VAD,去除噪声干扰
13_SenceVoice_QWen2.5_edgeTTS_realTime.py
基于以上逻辑,替换QWen2.5-1.5B模型为QWen2-VL-2B,可实现音视频多模态交互。模型具有两种输入格式,图片/视频
14_SenceVoice_QWen2VL_edgeTTS_realTime.py
[演示demo,B站] (https://www.bilibili.com/video/BV1uQBCYrEYL)
SenceVoice-QWen2.5-CosyVoice搭建
此工程主代码来于[CosyVoice] (https://github.com/FunAudioLLM/CosyVoice)
在CosyVoice基础上添加[SenceVoice] (https://github.com/modelscope/FunASR) 作为语音识别模型
添加[QWwn2.5] (https://github.com/QwenLM/Qwen2.5) 作为大语言模型进行对话理解
CoosyVoice推理速度慢,严重影响对话实时性,额外添加pyttsx3和edgeTTS
EdgeTTS实验过程出现链接错误问题,升级版本至6.1.17解决,无需科学上网
All dependencies are listed in requirements.txt, the interactive inference scripts are 10/11/12_SenceVoice_QWen2.5_xxx.py.
Have fun! 😊
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ASR-LLM-TTS
Similar Open Source Tools
ASR-LLM-TTS
ASR-LLM-TTS is a repository that provides detailed tutorials for setting up the environment, including installing anaconda, ffmpeg, creating virtual environments, and installing necessary libraries such as pytorch, torchaudio, edge-tts, funasr, and more. It also introduces features like voiceprint recognition, custom wake words, and conversation history memory. The repository combines CosyVoice for speech synthesis, SenceVoice for speech recognition, and QWen2.5 for dialogue understanding. It offers multiple speech synthesis methods including CoosyVoice, pyttsx3, and edgeTTS, with scripts for interactive inference provided. The repository aims to enable real-time speech interaction and multi-modal interactions involving audio and video.
live2d-TTS-LLM-GPT-SoVITS-Vtuber
This repository is a modification based on the pixi-live2d-display project. It provides a platform for TTS (Text-to-Speech) functionality and a large model voice chat page. Users can install node.js, run the provided commands, and access the specified URLs to utilize the features.
mcp-llm-bridge
The MCP LLM Bridge is a tool that acts as a bridge connecting Model Context Protocol (MCP) servers to OpenAI-compatible LLMs. It provides a bidirectional protocol translation layer between MCP and OpenAI's function-calling interface, enabling any OpenAI-compatible language model to leverage MCP-compliant tools through a standardized interface. The tool supports primary integration with the OpenAI API and offers additional compatibility for local endpoints that implement the OpenAI API specification. Users can configure the tool for different endpoints and models, facilitating the execution of complex queries and tasks using cloud-based or local models like Ollama and LM Studio.

lector
Lector is a text analysis tool that helps users extract insights from unstructured text data. It provides functionalities such as sentiment analysis, keyword extraction, entity recognition, and text summarization. With Lector, users can easily analyze large volumes of text data to uncover patterns, trends, and valuable information. The tool is designed to be user-friendly and efficient, making it suitable for both beginners and experienced users in the field of natural language processing and text mining.

ControlLLM
ControlLLM is a framework that empowers large language models to leverage multi-modal tools for solving complex real-world tasks. It addresses challenges like ambiguous user prompts, inaccurate tool selection, and inefficient tool scheduling by utilizing a task decomposer, a Thoughts-on-Graph paradigm, and an execution engine with a rich toolbox. The framework excels in tasks involving image, audio, and video processing, showcasing superior accuracy, efficiency, and versatility compared to existing methods.

openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.

llama.vim
llama.vim is a plugin that provides local LLM-assisted text completion for Vim users. It offers features such as auto-suggest on cursor movement, manual suggestion toggling, suggestion acceptance with Tab and Shift+Tab, control over text generation time, context configuration, ring context with chunks from open and edited files, and performance stats display. The plugin requires a llama.cpp server instance to be running and supports FIM-compatible models. It aims to be simple, lightweight, and provide high-quality and performant local FIM completions even on consumer-grade hardware.

ichigo
Ichigo is a local real-time voice AI tool that uses an early fusion technique to extend a text-based LLM to have native 'listening' ability. It is an open research experiment with improved multiturn capabilities and the ability to refuse processing inaudible queries. The tool is designed for open data, open weight, on-device Siri-like functionality, inspired by Meta's Chameleon paper. Ichigo offers a web UI demo and Gradio web UI for users to interact with the tool. It has achieved enhanced MMLU scores, stronger context handling, advanced noise management, and improved multi-turn capabilities for a robust user experience.
topicGPT
TopicGPT is a repository containing scripts and prompts for the paper 'TopicGPT: Topic Modeling by Prompting Large Language Models' (NAACL'24). The 'topicgpt_python' package offers functions to generate high-level and specific topics, refine topics, assign topics to input text, and correct generated topics. It supports various APIs like OpenAI, VertexAI, Azure, Gemini, and vLLM for inference. Users can prepare data in JSONL format, run the pipeline using provided scripts, and evaluate topic alignment with ground-truth labels.
mem-kk-logic
This repository provides a PyTorch implementation of the paper 'On Memorization of Large Language Models in Logical Reasoning'. The work investigates memorization of Large Language Models (LLMs) in reasoning tasks, proposing a memorization metric and a logical reasoning benchmark based on Knights and Knaves puzzles. It shows that LLMs heavily rely on memorization to solve training puzzles but also improve generalization performance through fine-tuning. The repository includes code, data, and tools for evaluation, fine-tuning, probing model internals, and sample classification.
Grounded-Video-LLM
Grounded-VideoLLM is a Video Large Language Model specialized in fine-grained temporal grounding. It excels in tasks such as temporal sentence grounding, dense video captioning, and grounded VideoQA. The model incorporates an additional temporal stream, discrete temporal tokens with specific time knowledge, and a multi-stage training scheme. It shows potential as a versatile video assistant for general video understanding. The repository provides pretrained weights, inference scripts, and datasets for training. Users can run inference queries to get temporal information from videos and train the model from scratch.

ComfyUI-IF_AI_tools
ComfyUI-IF_AI_tools is a set of custom nodes for ComfyUI that allows you to generate prompts using a local Large Language Model (LLM) via Ollama. This tool enables you to enhance your image generation workflow by leveraging the power of language models.
llm-past-tense
The 'llm-past-tense' repository contains code related to the research paper 'Does Refusal Training in LLMs Generalize to the Past Tense?' by Maksym Andriushchenko and Nicolas Flammarion. It explores the generalization of refusal training in large language models (LLMs) to the past tense. The code includes experiments and examples for running different models and requests related to the study. Users can cite the work if found useful in their research, and the codebase is released under the MIT License.
CALF
CALF (LLaTA) is a cross-modal fine-tuning framework that bridges the distribution discrepancy between temporal data and the textual nature of LLMs. It introduces three cross-modal fine-tuning techniques: Cross-Modal Match Module, Feature Regularization Loss, and Output Consistency Loss. The framework aligns time series and textual inputs, ensures effective weight updates, and maintains consistent semantic context for time series data. CALF provides scripts for long-term and short-term forecasting, requires Python 3.9, and utilizes word token embeddings for model training.

sieves
sieves is a library for zero- and few-shot NLP tasks with structured generation, enabling rapid prototyping of NLP applications without the need for training. It simplifies NLP prototyping by bundling capabilities into a single library, providing zero- and few-shot model support, a unified interface for structured generation, built-in tasks for common NLP operations, easy extendability, document-based pipeline architecture, caching to prevent redundant model calls, and more. The tool draws inspiration from spaCy and spacy-llm, offering features like immediate inference, observable pipelines, integrated tools for document parsing and text chunking, ready-to-use tasks such as classification, summarization, translation, and more, persistence for saving and loading pipelines, distillation for specialized model creation, and caching to optimize performance.
AIMNet2
AIMNet2 Calculator is a package that integrates the AIMNet2 neural network potential into simulation workflows, providing fast and reliable energy, force, and property calculations for molecules with diverse elements. It excels at modeling various systems, offers flexible interfaces for popular simulation packages, and supports long-range interactions using DSF or Ewald summation Coulomb models. The tool is designed for accurate and versatile molecular simulations, suitable for large molecules and periodic calculations.
For similar tasks
ASR-LLM-TTS
ASR-LLM-TTS is a repository that provides detailed tutorials for setting up the environment, including installing anaconda, ffmpeg, creating virtual environments, and installing necessary libraries such as pytorch, torchaudio, edge-tts, funasr, and more. It also introduces features like voiceprint recognition, custom wake words, and conversation history memory. The repository combines CosyVoice for speech synthesis, SenceVoice for speech recognition, and QWen2.5 for dialogue understanding. It offers multiple speech synthesis methods including CoosyVoice, pyttsx3, and edgeTTS, with scripts for interactive inference provided. The repository aims to enable real-time speech interaction and multi-modal interactions involving audio and video.
bolna
Bolna is an open-source platform for building voice-driven conversational applications using large language models (LLMs). It provides a comprehensive set of tools and integrations to handle various aspects of voice-based interactions, including telephony, transcription, LLM-based conversation handling, and text-to-speech synthesis. Bolna simplifies the process of creating voice agents that can perform tasks such as initiating phone calls, transcribing conversations, generating LLM-powered responses, and synthesizing speech. It supports multiple providers for each component, allowing users to customize their setup based on their specific needs. Bolna is designed to be easy to use, with a straightforward local setup process and well-documented APIs. It is also extensible, enabling users to integrate with other telephony providers or add custom functionality.

agents
The LiveKit Agent Framework is designed for building real-time, programmable participants that run on servers. Easily tap into LiveKit WebRTC sessions and process or generate audio, video, and data streams. The framework includes plugins for common workflows, such as voice activity detection and speech-to-text. Agents integrates seamlessly with LiveKit server, offloading job queuing and scheduling responsibilities to it. This eliminates the need for additional queuing infrastructure. Agent code developed on your local machine can scale to support thousands of concurrent sessions when deployed to a server in production.

RVC_CLI
**RVC_CLI: Retrieval-based Voice Conversion Command Line Interface** This command-line interface (CLI) provides a comprehensive set of tools for voice conversion, enabling you to modify the pitch, timbre, and other characteristics of audio recordings. It leverages advanced machine learning models to achieve realistic and high-quality voice conversions. **Key Features:** * **Inference:** Convert the pitch and timbre of audio in real-time or process audio files in batch mode. * **TTS Inference:** Synthesize speech from text using a variety of voices and apply voice conversion techniques. * **Training:** Train custom voice conversion models to meet specific requirements. * **Model Management:** Extract, blend, and analyze models to fine-tune and optimize performance. * **Audio Analysis:** Inspect audio files to gain insights into their characteristics. * **API:** Integrate the CLI's functionality into your own applications or workflows. **Applications:** The RVC_CLI finds applications in various domains, including: * **Music Production:** Create unique vocal effects, harmonies, and backing vocals. * **Voiceovers:** Generate voiceovers with different accents, emotions, and styles. * **Audio Editing:** Enhance or modify audio recordings for podcasts, audiobooks, and other content. * **Research and Development:** Explore and advance the field of voice conversion technology. **For Jobs:** * Audio Engineer * Music Producer * Voiceover Artist * Audio Editor * Machine Learning Engineer **AI Keywords:** * Voice Conversion * Pitch Shifting * Timbre Modification * Machine Learning * Audio Processing **For Tasks:** * Convert Pitch * Change Timbre * Synthesize Speech * Train Model * Analyze Audio

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.

nexa-sdk
Nexa SDK is a comprehensive toolkit supporting ONNX and GGML models for text generation, image generation, vision-language models (VLM), and text-to-speech (TTS) capabilities. It offers an OpenAI-compatible API server with JSON schema mode and streaming support, along with a user-friendly Streamlit UI. Users can run Nexa SDK on any device with Python environment, with GPU acceleration supported. The toolkit provides model support, conversion engine, inference engine for various tasks, and differentiating features from other tools.

AudioLLM
AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.
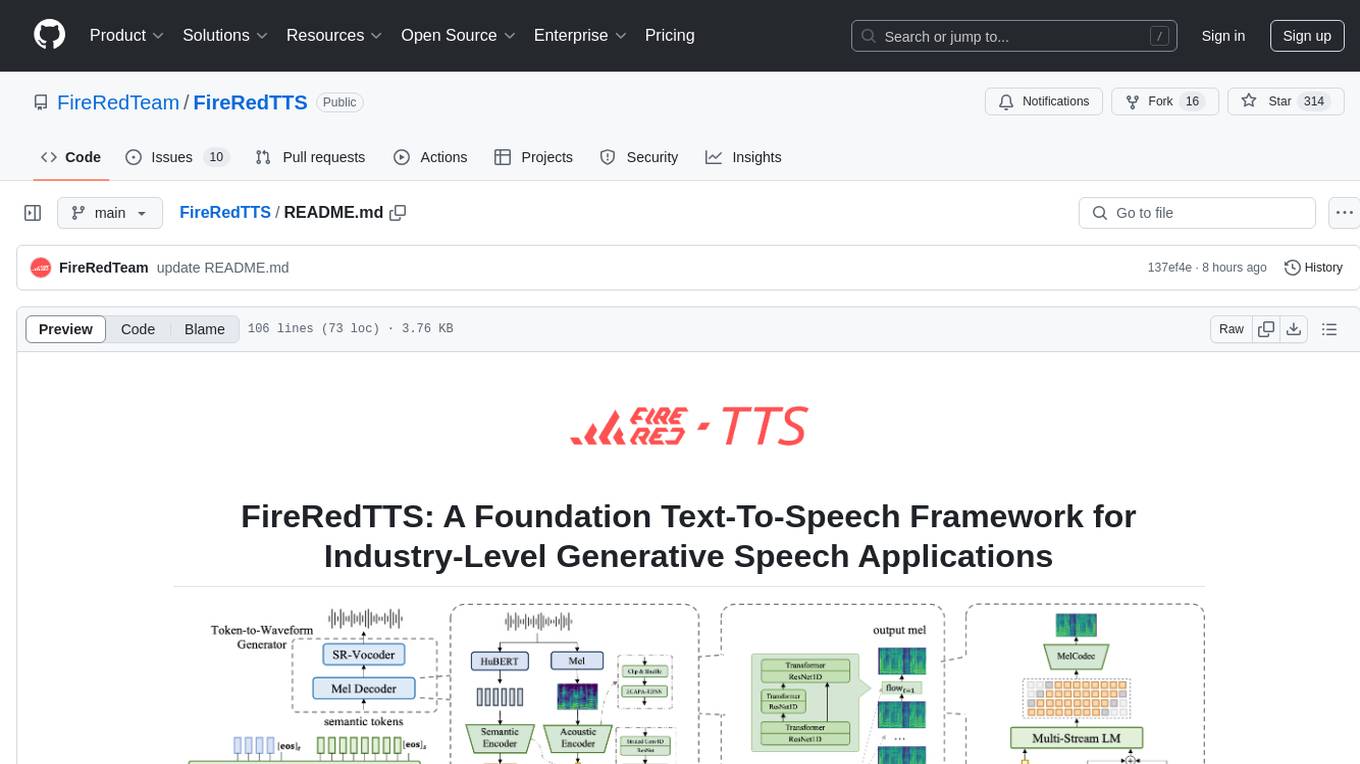
FireRedTTS
FireRedTTS is a foundation text-to-speech framework designed for industry-level generative speech applications. It offers a rich-punctuation model with expanded punctuation coverage and enhanced audio production consistency. The tool provides pre-trained checkpoints, inference code, and an interactive demo space. Users can clone the repository, create a conda environment, download required model files, and utilize the tool for synthesizing speech in various languages. FireRedTTS aims to enhance stability and provide controllable human-like speech generation capabilities.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.