
LLMDebugger
LDB: A Large Language Model Debugger via Verifying Runtime Execution Step by Step
Stars: 302
This repository contains the code and dataset for LDB, a novel debugging framework that enables Large Language Models (LLMs) to refine their generated programs by tracking the values of intermediate variables throughout the runtime execution. LDB segments programs into basic blocks, allowing LLMs to concentrate on simpler code units, verify correctness block by block, and pinpoint errors efficiently. The tool provides APIs for debugging and generating code with debugging messages, mimicking how human developers debug programs.
README:
![]()
This repository contains the code and dataset for our paper LDB: A Large Language Model Debugger via Verifying Runtime Execution Step by Step.(ACL 2024)
We introduce 🛠️LDB, a novel debugging framework that enables LLMs to refine their generated programs with the runtime execution information. Specifically, LDB imitates how human developers debug programs. It segments the programs into basic blocks and tracks the values of intermediate variables after each block throughout the runtime execution. This allows LLMs to concentrate on simpler code units within the overall execution flow, verify their correctness against the task description block by block, and efficiently pinpoint any potential errors.
📢 We update results of LDB on GPT-4o. It achieves accuracy of 98.2% based on seeds from Reflexion!

conda create -n ldb python=3.10
conda activate ldb
python -m pip install -r requirements.txtIf you use OpenAI models as backbones:
export OPENAI_API_KEY=[your OpenAI API Key]If you use starcoder or codellama, we recommend to setup an OpenAI compatible server based on vLLM. Here is the instruction Setup vLLM backbones.
cd ./programming
./run_simple.sh [dataset] [model] [output_dir]The result is in output_data/simple/[dataset]/[model]/[output_dir].
Available options:
| Option | Value |
|---|---|
| dataset |
humaneval, mbpp, transcoder
|
| model |
gpt-3.5-turbo-0613, gpt-4-1106-preview, starcoder, codellama (codellama/CodeLlama-34b-Instruct-hf) |
Run the script:
cd ./programming
./run_ldb.sh [dataset] [model] [seed] [output_dir]The result is in output_data/ldb/[dataset]/[model]/[output_dir]
Available options:
| Option | Value |
|---|---|
| dataset |
humaneval, mbpp, transcoder
|
| model |
gpt-3.5-turbo-0613, gpt-4-1106-preview, starcoder, codellama (codellama/CodeLlama-34b-Instruct-hf) |
| seed | Path to the seed program you want to debug. You can find the seed programs we use in experiments in input_data/[dataset]/seed/[model]/seed.jsonl. |
We use the OpenAI compatible server based on vLLM. Please refer OpenAI-Compatible Server for detailed instructions to setup the local servers. To start the server:
python -m vllm.entrypoints.openai.api_server --model bigcode/starcoderLDB automatically sets up the connection to your local servers when you specify model starcoder or codellama.
If your server port is not the default 8000, please set the option --port in run_simple.sh or run_ldb.sh to your local server port.
LDB provides APIs for debugging and generating code with the debugging messages:
class PyGenerator:
ldb_debugldb_debug(self, prompt: str, prev_func_impl: str, failed_test: str, entry: str, model: ModelBase, prev_msg: List[Message], dataset_type: str = "", level: str = "block")
Args:
prompt (str): Text description or the code to be translated.
prev_func_impl (str): Implementation of the previous function.
failed_test (str): One failed test.
entry (str): Entry point where debugging is initiated.
model (ModelBase): Model used for debugging. The values could be 'gpt-3.5-turbo-1106', 'gpt-4-1106-preview', 'StarCoder', 'CodeLlama'.
prev_msg (List[Message]): Previous debugging messages and information.
dataset_type (str, optional): Type of dataset being processed. The values could be 'HumanEval' for text-to-code tasks, and 'TransCoder' for C++-to-Python translation tasks.
level (str, optional): Level of debugging to be performed. Default is "block". The values could be 'line', 'block', 'function'.
ldb_generate(self, func_sig: str, model: ModelBase, messages: List[Message], prev_func_impl: Optional[str] = None, failed_tests: Optional[str] = None, num_comps: int = 1, temperature: float = 0.0, dataset_type: str = "") -> Union[str, List[str]]
Args:
func_sig (str): Signature of the function to be generated.
model (ModelBase): Model used for code generation. Possible values: 'gpt-3.5-turbo-1106', 'gpt-4-1106-preview', 'StarCoder', 'CodeLlama'.
messages (List[Message]): Debugging messages and information.
prev_func_impl (str, optional): Implementation of the previous function.
failed_tests (str, optional): A failed test (this arg is not used in this function).
num_comps (int, optional): Number of completions to generate. Default is 1.
temperature (float, optional): Sampling temperature for text generation. Default is 0.0.
dataset_type (str, optional): Type of dataset being processed. Possible values: 'HumanEval' for text-to-code tasks, 'TransCoder' for C++-to-Python translation tasks. Default is an empty string.
Returns:
Union[str, List[str]]: Generated code or list of generated codes.
"""
Here is an example for debugging one round:
# One round debugging
gen = PyGenerator()
messages = gen.ldb_debug(prompt, code, test, entry_point, model, "", dataset_type, "block")
fixed_code, messages = gen.ldb_generate(
func_sig=task,
model=model,
prev_func_impl=code,
messages=messages,
failed_tests=test,
dataset_type=dataset_type,
)
For more details, see the example usage in our demo.
If you have any questions, feel free to post issues in this repo.
If you find our work helpful, please cite us:
@inproceedings{zhong2024ldb,
title={LDB: A Large Language Model Debugger via Verifying Runtime Execution Step-by-step},
author={Li Zhong and Zilong Wang and Jingbo Shang},
booktitle={Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics: Findings.},
year={2024}
}
Our implementation adapts code from Reflexion and staticfg. We thank authors of these projects for providing high quality open source code!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLMDebugger
Similar Open Source Tools
LLMDebugger
This repository contains the code and dataset for LDB, a novel debugging framework that enables Large Language Models (LLMs) to refine their generated programs by tracking the values of intermediate variables throughout the runtime execution. LDB segments programs into basic blocks, allowing LLMs to concentrate on simpler code units, verify correctness block by block, and pinpoint errors efficiently. The tool provides APIs for debugging and generating code with debugging messages, mimicking how human developers debug programs.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output based on a Context-Free Grammar (CFG). It supports various programming languages like Python, Go, SQL, Math, JSON, and more. Users can define custom grammars using EBNF syntax. SynCode offers fast generation, seamless integration with HuggingFace Language Models, and the ability to sample with different decoding strategies.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output with respect to defined Context-Free Grammar (CFG) rules. It supports general-purpose programming languages like Python, Go, SQL, JSON, and more, allowing users to define custom grammars using EBNF syntax. The tool compares favorably to other constrained decoders and offers features like fast grammar-guided generation, compatibility with HuggingFace Language Models, and the ability to work with various decoding strategies.

IntelliNode
IntelliNode is a javascript module that integrates cutting-edge AI models like ChatGPT, LLaMA, WaveNet, Gemini, and Stable diffusion into projects. It offers functions for generating text, speech, and images, as well as semantic search, multi-model evaluation, and chatbot capabilities. The module provides a wrapper layer for low-level model access, a controller layer for unified input handling, and a function layer for abstract functionality tailored to various use cases.
monacopilot
Monacopilot is a powerful and customizable AI auto-completion plugin for the Monaco Editor. It supports multiple AI providers such as Anthropic, OpenAI, Groq, and Google, providing real-time code completions with an efficient caching system. The plugin offers context-aware suggestions, customizable completion behavior, and framework agnostic features. Users can also customize the model support and trigger completions manually. Monacopilot is designed to enhance coding productivity by providing accurate and contextually appropriate completions in daily spoken language.

LightRAG
LightRAG is a PyTorch library designed for building and optimizing Retriever-Agent-Generator (RAG) pipelines. It follows principles of simplicity, quality, and optimization, offering developers maximum customizability with minimal abstraction. The library includes components for model interaction, output parsing, and structured data generation. LightRAG facilitates tasks like providing explanations and examples for concepts through a question-answering pipeline.
flow-prompt
Flow Prompt is a dynamic library for managing and optimizing prompts for large language models. It facilitates budget-aware operations, dynamic data integration, and efficient load distribution. Features include CI/CD testing, dynamic prompt development, multi-model support, real-time insights, and prompt testing and evolution.

lionagi
LionAGI is a robust framework for orchestrating multi-step AI operations with precise control. It allows users to bring together multiple models, advanced reasoning, tool integrations, and custom validations in a single coherent pipeline. The framework is structured, expandable, controlled, and transparent, offering features like real-time logging, message introspection, and tool usage tracking. LionAGI supports advanced multi-step reasoning with ReAct, integrates with Anthropic's Model Context Protocol, and provides observability and debugging tools. Users can seamlessly orchestrate multiple models, integrate with Claude Code CLI SDK, and leverage a fan-out fan-in pattern for orchestration. The framework also offers optional dependencies for additional functionalities like reader tools, local inference support, rich output formatting, database support, and graph visualization.

wllama
Wllama is a WebAssembly binding for llama.cpp, a high-performance and lightweight language model library. It enables you to run inference directly on the browser without the need for a backend or GPU. Wllama provides both high-level and low-level APIs, allowing you to perform various tasks such as completions, embeddings, tokenization, and more. It also supports model splitting, enabling you to load large models in parallel for faster download. With its Typescript support and pre-built npm package, Wllama is easy to integrate into your React Typescript projects.
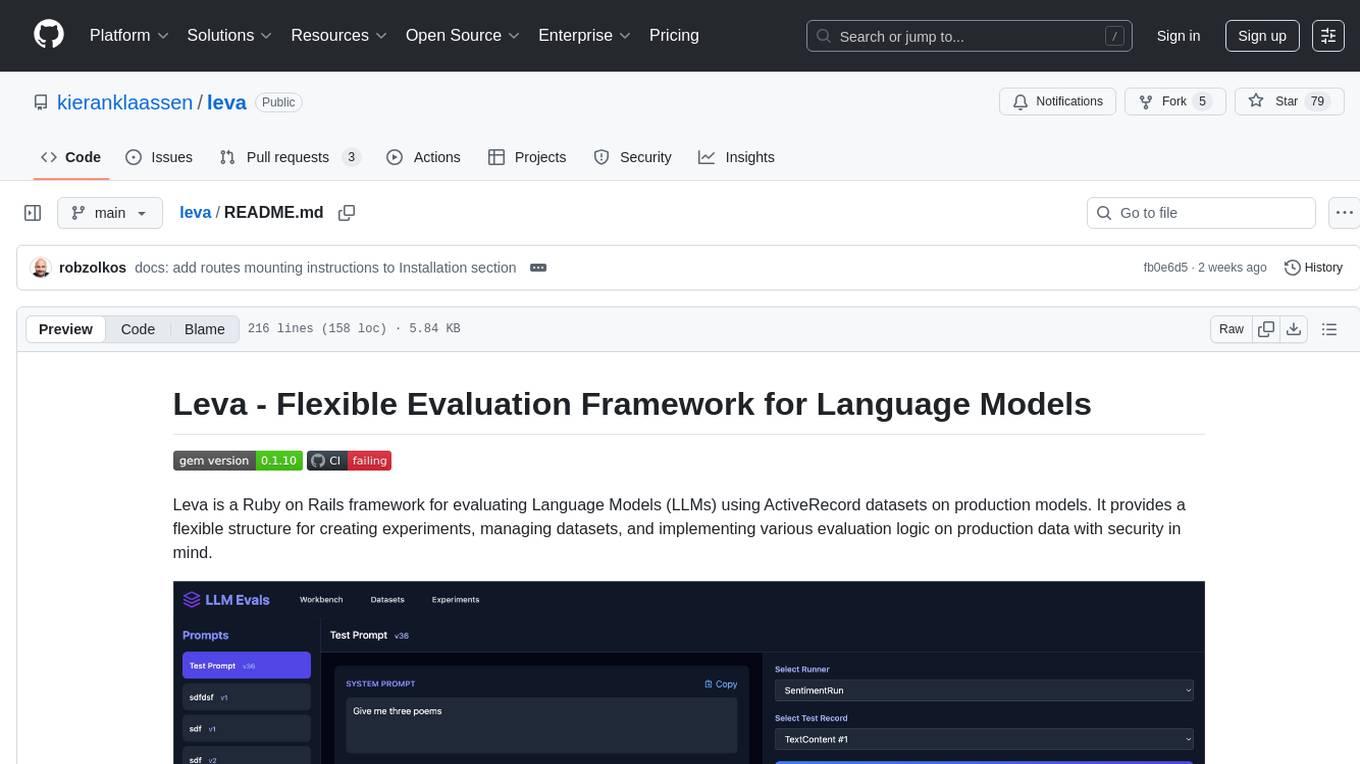
leva
Leva is a Ruby on Rails framework designed for evaluating Language Models (LLMs) using ActiveRecord datasets on production models. It offers a flexible structure for creating experiments, managing datasets, and implementing various evaluation logic on production data with security in mind. Users can set up datasets, implement runs and evals, run experiments with different configurations, use prompts, and analyze results. Leva's components include classes like Leva, Leva::BaseRun, and Leva::BaseEval, as well as models like Leva::Dataset, Leva::DatasetRecord, Leva::Experiment, Leva::RunnerResult, Leva::EvaluationResult, and Leva::Prompt. The tool aims to provide a comprehensive solution for evaluating language models efficiently and securely.

python-aiplatform
The Vertex AI SDK for Python is a library that provides a convenient way to use the Vertex AI API. It offers a high-level interface for creating and managing Vertex AI resources, such as datasets, models, and endpoints. The SDK also provides support for training and deploying custom models, as well as using AutoML models. With the Vertex AI SDK for Python, you can quickly and easily build and deploy machine learning models on Vertex AI.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

xlstm
xLSTM is a new Recurrent Neural Network architecture based on ideas of the original LSTM. Through Exponential Gating with appropriate normalization and stabilization techniques and a new Matrix Memory it overcomes the limitations of the original LSTM and shows promising performance on Language Modeling when compared to Transformers or State Space Models. The package is based on PyTorch and was tested for versions >=1.8. For the CUDA version of xLSTM, you need Compute Capability >= 8.0. The xLSTM tool provides two main components: xLSTMBlockStack for non-language applications or integrating in other architectures, and xLSTMLMModel for language modeling or other token-based applications.
laravel-slower
Laravel Slower is a powerful package designed for Laravel developers to optimize the performance of their applications by identifying slow database queries and providing AI-driven suggestions for optimal indexing strategies and performance improvements. It offers actionable insights for debugging and monitoring database interactions, enhancing efficiency and scalability.

Lumos
Lumos is a Chrome extension powered by a local LLM co-pilot for browsing the web. It allows users to summarize long threads, news articles, and technical documentation. Users can ask questions about reviews and product pages. The tool requires a local Ollama server for LLM inference and embedding database. Lumos supports multimodal models and file attachments for processing text and image content. It also provides options to customize models, hosts, and content parsers. The extension can be easily accessed through keyboard shortcuts and offers tools for automatic invocation based on prompts.
For similar tasks
LLMDebugger
This repository contains the code and dataset for LDB, a novel debugging framework that enables Large Language Models (LLMs) to refine their generated programs by tracking the values of intermediate variables throughout the runtime execution. LDB segments programs into basic blocks, allowing LLMs to concentrate on simpler code units, verify correctness block by block, and pinpoint errors efficiently. The tool provides APIs for debugging and generating code with debugging messages, mimicking how human developers debug programs.
Visual-Code-Space
Visual Code Space is a modern code editor designed specifically for Android devices. It offers a seamless and efficient coding environment with features like blazing fast file explorer, multi-language syntax highlighting, tabbed editor, integrated terminal emulator, ad-free experience, and plugin support. Users can enhance their mobile coding experience with this cutting-edge editor that allows customization through custom plugins written in BeanShell. The tool aims to simplify coding on the go by providing a user-friendly interface and powerful functionalities.
MaixCDK
MaixCDK (Maix C/CPP Development Kit) is a C/C++ development kit that integrates practical functions such as AI, machine vision, and IoT. It provides easy-to-use encapsulation for quickly building projects in vision, artificial intelligence, IoT, robotics, industrial cameras, and more. It supports hardware-accelerated execution of AI models, common vision algorithms, OpenCV, and interfaces for peripheral operations. MaixCDK offers cross-platform support, easy-to-use API, simple environment setup, online debugging, and a complete ecosystem including MaixPy and MaixVision. Supported devices include Sipeed MaixCAM, Sipeed MaixCAM-Pro, and partial support for Common Linux.
nanocoder
Nanocoder is a versatile code editor designed for beginners and experienced programmers alike. It provides a user-friendly interface with features such as syntax highlighting, code completion, and error checking. With Nanocoder, you can easily write and debug code in various programming languages, making it an ideal tool for learning, practicing, and developing software projects. Whether you are a student, hobbyist, or professional developer, Nanocoder offers a seamless coding experience to boost your productivity and creativity.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

mistral.rs
Mistral.rs is a fast LLM inference platform written in Rust. We support inference on a variety of devices, quantization, and easy-to-use application with an Open-AI API compatible HTTP server and Python bindings.
generative-ai-python
The Google AI Python SDK is the easiest way for Python developers to build with the Gemini API. The Gemini API gives you access to Gemini models created by Google DeepMind. Gemini models are built from the ground up to be multimodal, so you can reason seamlessly across text, images, and code.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.