
MemoryLLM
The official implementation of the ICML 2024 paper "MemoryLLM: Towards Self-Updatable Large Language Models"
Stars: 104

MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.
README:

- [2024/08/30] 🔥 We release memoryllm-8b-chat, the chat model built on top of memoryllm-8b.
- [2024/08/23] 🔥 We release memoryllm-8b with 1.67B memory equipped on Llama3!
- [2024/06/21] 🔥 Training code is provided in the folder
train. - [2024/06/02] 🔥 MemoryLLM checkpoint is released!
- [2024/05/02] 🔥 MemoryLLM is accepted to ICML 2024!
conda create --name memoryllm
conda activate memoryllm
pip install -r requirements.txt
First clone the repository and get into the repository:
git clone [email protected]:wangyu-ustc/MemoryLLM.git
cd MemoryLLM
Then simply use the following code to load the model:
import torch
from modeling_memoryllm import MemoryLLM
from transformers import AutoTokenizer
# load pretrained model
model = MemoryLLM.from_pretrained("YuWangX/memoryllm-8b", attn_implementation="flash_attention_2", torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained("YuWangX/memoryllm-8b")
model = model.cuda()
# load chat model
model = MemoryLLM.from_pretrained("YuWangX/memoryllm-8b-chat", attn_implementation="flash_attention_2", torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained("YuWangX/memoryllm-8b-chat")
model = model.cuda()If you want to use MemoryLLM-7B (the last version), please go to the branch memoryllm-7b.
Inject a piece of context into the model using the following script:
# Self-Update with the new context
ctx = "Last week, John had a wonderful picnic with David. During their conversation, David mentioned multiple times that he likes eating apples. Though he didn't mention any other fruits, John says he can infer that David also like bananas."
# please make sure the context to inject into the memory is larger than 16 tokens, this is the hard minimum when training the model. The memory will be disturbed when less than 16 tokens are injected into the memory.
model.inject_memory(tokenizer(ctx, return_tensors='pt', add_special_tokens=False).input_ids.cuda(), update_memory=True)Then for chat model, use the following template:
# Generation
messages = [{
'role': 'user', "content": "What fruits does David like?",
}]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True)[:, 1:] # remove bos tokens as the model has its own trained bos embeddings.
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(input_ids=inputs.cuda(),
max_new_tokens=20,
eos_token_id=terminators)
response = tokenizer.decode(outputs[0])For the pretrained model, use the following template:
inputs = tokenizer("Question: What fruits does David like? Answer: David likes", return_tensors='pt', add_special_tokens=False).input_ids.cuda()
outputs = model.generate(input_ids=inputs, max_new_tokens=20)
response = tokenizer.decode(outputs[0][inputs.shape[1]:])We put our reimplementation of various model-editing baselines and MemoryLLM in the repo EditingLlama.
To prepare the dataset, please download from here. Please download the dataset and put them as the following structure:
- data
- squad
- indices_squad_3.npy
- dev-v2.0.json
- train-v2.0.json
- nq
- indices_nq_4.npy
- v1.0-simplified_nq-dev-all.jsonl
- v1.0-simplified_simplified-nq-train.jsonl
We will evaluate our model on the validation set where the unrelated contexts are sampled from the training set. To evaluate the model, we could use the following script:
mkdir results
python test_qa_memory.py --model YuWangX/memoryllm-7b --nuc 10 --datasets naturalqa squad --num_samples 100
here nuc means the number of irrelevant contexts, and naturalqa squad means the datasets to evaluate the model on.
python longbench_pred.py --model memoryllm-7b --datasets hotpotqa --max_length 16384
Here max_length is the maximum length used when truncating the context.
Then the generated results are all saved in the folder longbench for evaluation.
Evaluation results on the knowledge-retention tasks are as follows: (we updated the evaluation dataset by filtering out the examples whose questions can be answered by Llama3-8B. The new dataset is here)


Evaluation results on LongBench are as follows:

In our implementations, we train Llama2-7B on C4 dataset. However, this may lead to the poor performance on the benchmark qasper (see Figure 4 in the paper). Thus we put the script of training on red-pajama here, which is the dataset we have been using in the models we are currently exploring.
Please check the folder train using the following command:
cd train
Please follow the instructions below to prepare the datasets: (make sure you have the datasets from here prepared.)
cd data
# Please use the softlink to link the validation datasets into the current directory.
ln -s ../../data/nq ./
ln -s ../../data/squad ./
# Then please download the redpajama dataset
cd redpajama
sh download.sh
After preparing all the datasets, you can run the following code to start training:
python main.py -t --base MemoryLLM/configs/llama/llama_30x256.yaml
We have not conducted training on openllama but we do have the script on openllama for debugging purposes. So if you want to see the training on openllama, please run the following command:
python main.py -t --base MemoryLLM/configs/openllama/openllama_4x256.yaml
If you find this repo helpful, please consider cite our paper:
@misc{memoryllm,
title={MEMORYLLM: Towards Self-Updatable Large Language Models},
author={Yu Wang and Yifan Gao and Xiusi Chen and Haoming Jiang and Shiyang Li and Jingfeng Yang and Qingyu Yin and Zheng Li and Xian Li and Bing Yin and Jingbo Shang and Julian McAuley},
year={2024},
eprint={2402.04624},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2402.04624},
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MemoryLLM
Similar Open Source Tools
MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.

ScandEval
ScandEval is a framework for evaluating pretrained language models on mono- or multilingual language tasks. It provides a unified interface for benchmarking models on a variety of tasks, including sentiment analysis, question answering, and machine translation. ScandEval is designed to be easy to use and extensible, making it a valuable tool for researchers and practitioners alike.

WildBench
WildBench is a tool designed for benchmarking Large Language Models (LLMs) with challenging tasks sourced from real users in the wild. It provides a platform for evaluating the performance of various models on a range of tasks. Users can easily add new models to the benchmark by following the provided guidelines. The tool supports models from Hugging Face and other APIs, allowing for comprehensive evaluation and comparison. WildBench facilitates running inference and evaluation scripts, enabling users to contribute to the benchmark and collaborate on improving model performance.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.

qa-mdt
This repository provides an implementation of QA-MDT, integrating state-of-the-art models for music generation. It offers a Quality-Aware Masked Diffusion Transformer for enhanced music generation. The code is based on various repositories like AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. The implementation allows for training and fine-tuning the model with different strategies and datasets. The repository also includes instructions for preparing datasets in LMDB format and provides a script for creating a toy LMDB dataset. The model can be used for music generation tasks, with a focus on quality injection to enhance the musicality of generated music.

LLM-Pruner
LLM-Pruner is a tool for structural pruning of large language models, allowing task-agnostic compression while retaining multi-task solving ability. It supports automatic structural pruning of various LLMs with minimal human effort. The tool is efficient, requiring only 3 minutes for pruning and 3 hours for post-training. Supported LLMs include Llama-3.1, Llama-3, Llama-2, LLaMA, BLOOM, Vicuna, and Baichuan. Updates include support for new LLMs like GQA and BLOOM, as well as fine-tuning results achieving high accuracy. The tool provides step-by-step instructions for pruning, post-training, and evaluation, along with a Gradio interface for text generation. Limitations include issues with generating repetitive or nonsensical tokens in compressed models and manual operations for certain models.

swe-rl
SWE-RL is the official codebase for the paper 'SWE-RL: Advancing LLM Reasoning via Reinforcement Learning on Open Software Evolution'. It is the first approach to scale reinforcement learning based LLM reasoning for real-world software engineering, leveraging open-source software evolution data and rule-based rewards. The code provides prompt templates and the implementation of the reward function based on sequence similarity. Agentless Mini, a part of SWE-RL, builds on top of Agentless with improvements like fast async inference, code refactoring for scalability, and support for using multiple reproduction tests for reranking. The tool can be used for localization, repair, and reproduction test generation in software engineering tasks.

allms
allms is a versatile and powerful library designed to streamline the process of querying Large Language Models (LLMs). Developed by Allegro engineers, it simplifies working with LLM applications by providing a user-friendly interface, asynchronous querying, automatic retrying mechanism, error handling, and output parsing. It supports various LLM families hosted on different platforms like OpenAI, Google, Azure, and GCP. The library offers features for configuring endpoint credentials, batch querying with symbolic variables, and forcing structured output format. It also provides documentation, quickstart guides, and instructions for local development, testing, updating documentation, and making new releases.
ollama-r
The Ollama R library provides an easy way to integrate R with Ollama for running language models locally on your machine. It supports working with standard data structures for different LLMs, offers various output formats, and enables integration with other libraries/tools. The library uses the Ollama REST API and requires the Ollama app to be installed, with GPU support for accelerating LLM inference. It is inspired by Ollama Python and JavaScript libraries, making it familiar for users of those languages. The installation process involves downloading the Ollama app, installing the 'ollamar' package, and starting the local server. Example usage includes testing connection, downloading models, generating responses, and listing available models.
Search-R1
Search-R1 is a tool that trains large language models (LLMs) to reason and call a search engine using reinforcement learning. It is a reproduction of DeepSeek-R1 methods for training reasoning and searching interleaved LLMs, built upon veRL. Through rule-based outcome reward, the base LLM develops reasoning and search engine calling abilities independently. Users can train LLMs on their own datasets and search engines, with preliminary results showing improved performance in search engine calling and reasoning tasks.

simpleAI
SimpleAI is a self-hosted alternative to the not-so-open AI API, focused on replicating main endpoints for LLM such as text completion, chat, edits, and embeddings. It allows quick experimentation with different models, creating benchmarks, and handling specific use cases without relying on external services. Users can integrate and declare models through gRPC, query endpoints using Swagger UI or API, and resolve common issues like CORS with FastAPI middleware. The project is open for contributions and welcomes PRs, issues, documentation, and more.
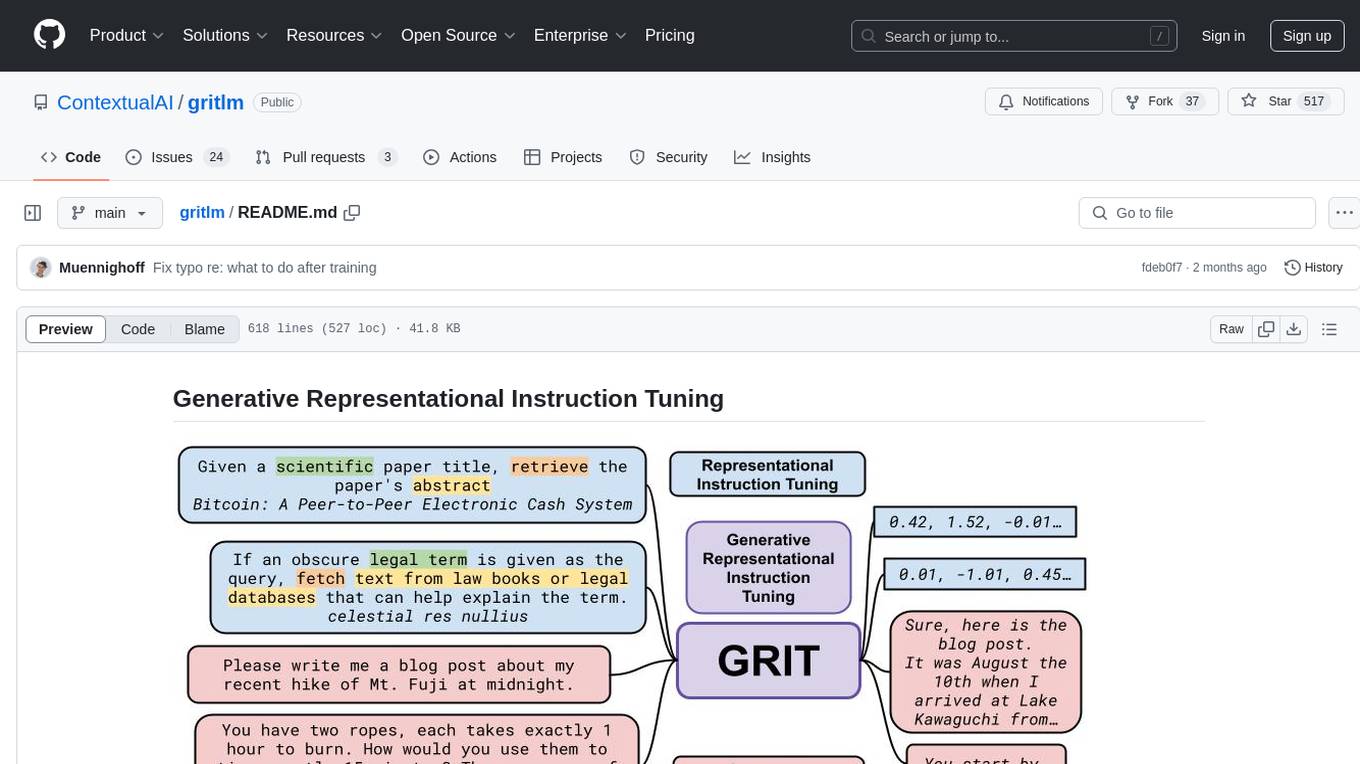
gritlm
The 'gritlm' repository provides all materials for the paper Generative Representational Instruction Tuning. It includes code for inference, training, evaluation, and known issues related to the GritLM model. The repository also offers models for embedding and generation tasks, along with instructions on how to train and evaluate the models. Additionally, it contains visualizations, acknowledgements, and a citation for referencing the work.

ash_ai
Ash AI is a tool that provides a Model Context Protocol (MCP) server for exposing tool definitions to an MCP client. It allows for the installation of dev and production MCP servers, and supports features like OAuth2 flow with AshAuthentication, tool data access, tool execution callbacks, prompt-backed actions, and vectorization strategies. Users can also generate a chat feature for their Ash & Phoenix application using `ash_oban` and `ash_postgres`, and specify LLM API keys for OpenAI. The tool is designed to help developers experiment with tools and actions, monitor tool execution, and expose actions as tool calls.

VMind
VMind is an open-source solution for intelligent visualization, providing an intelligent chart component based on LLM by VisActor. It allows users to create chart narrative works with natural language interaction, edit charts through dialogue, and export narratives as videos or GIFs. The tool is easy to use, scalable, supports various chart types, and offers one-click export functionality. Users can customize chart styles, specify themes, and aggregate data using LLM models. VMind aims to enhance efficiency in creating data visualization works through dialogue-based editing and natural language interaction.

raid
RAID is the largest and most comprehensive dataset for evaluating AI-generated text detectors. It contains over 10 million documents spanning 11 LLMs, 11 genres, 4 decoding strategies, and 12 adversarial attacks. RAID is designed to be the go-to location for trustworthy third-party evaluation of popular detectors. The dataset covers diverse models, domains, sampling strategies, and attacks, making it a valuable resource for training detectors, evaluating generalization, protecting against adversaries, and comparing to state-of-the-art models from academia and industry.
Phi-3-Vision-MLX
Phi-3-MLX is a versatile AI framework that leverages both the Phi-3-Vision multimodal model and the Phi-3-Mini-128K language model optimized for Apple Silicon using the MLX framework. It provides an easy-to-use interface for a wide range of AI tasks, from advanced text generation to visual question answering and code execution. The project features support for batched generation, flexible agent system, custom toolchains, model quantization, LoRA fine-tuning capabilities, and API integration for extended functionality.
For similar tasks

Open-Prompt-Injection
OpenPromptInjection is an open-source toolkit for attacks and defenses in LLM-integrated applications, enabling easy implementation, evaluation, and extension of attacks, defenses, and LLMs. It supports various attack and defense strategies, including prompt injection, paraphrasing, retokenization, data prompt isolation, instructional prevention, sandwich prevention, perplexity-based detection, LLM-based detection, response-based detection, and know-answer detection. Users can create models, tasks, and apps to evaluate different scenarios. The toolkit currently supports PaLM2 and provides a demo for querying models with prompts. Users can also evaluate ASV for different scenarios by injecting tasks and querying models with attacked data prompts.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.
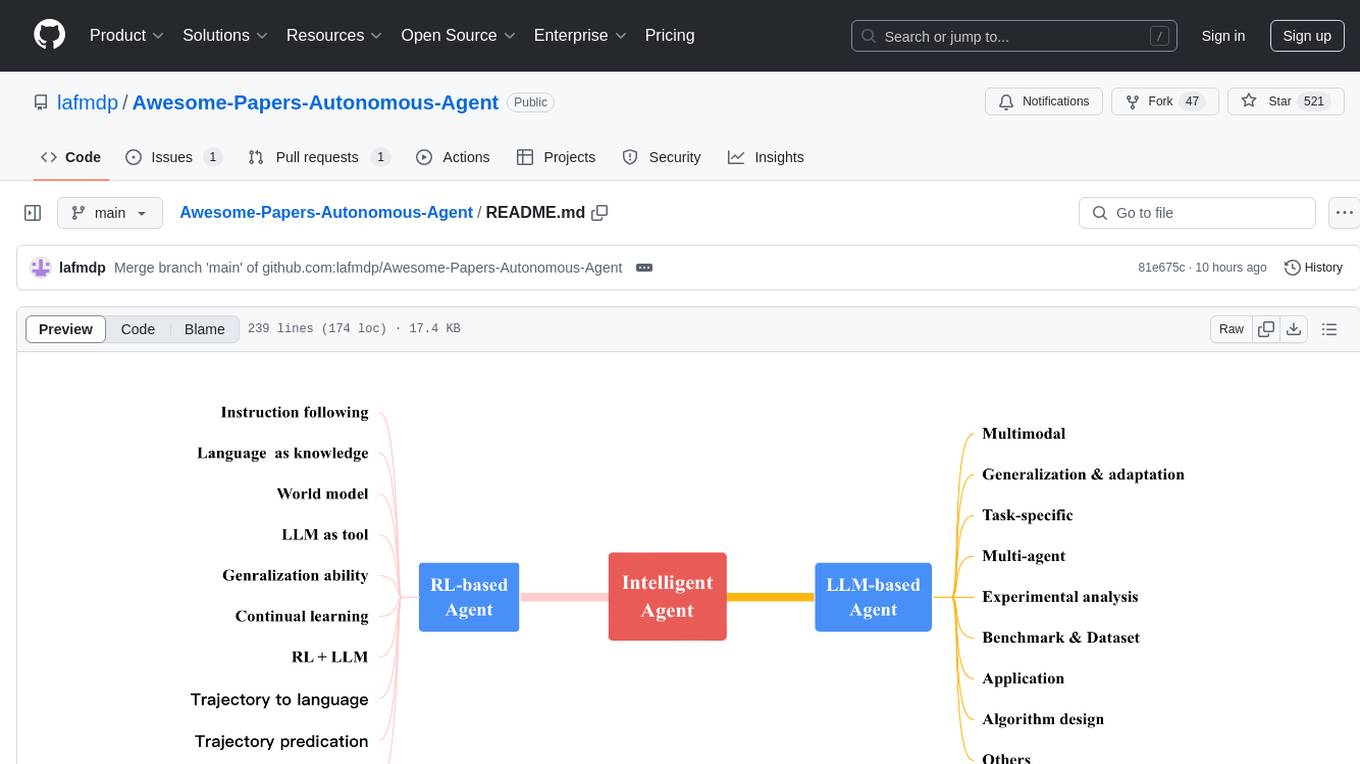
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.

SwiftSage
SwiftSage is a tool designed for conducting experiments in the field of machine learning and artificial intelligence. It provides a platform for researchers and developers to implement and test various algorithms and models. The tool is particularly useful for exploring new ideas and conducting experiments in a controlled environment. SwiftSage aims to streamline the process of developing and testing machine learning models, making it easier for users to iterate on their ideas and achieve better results. With its user-friendly interface and powerful features, SwiftSage is a valuable tool for anyone working in the field of AI and ML.
MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.
ppl.llm.kernel.cuda
Primitive cuda kernel library for ppl.nn.llm, part of PPL.LLM system, tested on Ampere and Hopper, requires Linux on x86_64 or arm64 CPUs, GCC >= 9.4.0, CMake >= 3.18, Git >= 2.7.0, CUDA Toolkit >= 11.4. 11.6 recommended. Provides cuda kernel functionalities for deep learning tasks.
craftium
Craftium is an open-source platform based on the Minetest voxel game engine and the Gymnasium and PettingZoo APIs, designed for creating fast, rich, and diverse single and multi-agent environments. It allows for connecting to Craftium's Python process, executing actions as keyboard and mouse controls, extending the Lua API for creating RL environments and tasks, and supporting client/server synchronization for slow agents. Craftium is fully extensible, extensively documented, modern RL API compatible, fully open source, and eliminates the need for Java. It offers a variety of environments for research and development in reinforcement learning.
LLMsKnow
LLMs Know More Than They Show is a repository containing code to reproduce the results in the paper. It includes scripts to generate model answers, extract exact answers, probe all layers and tokens, probe specific layers and tokens, conduct generalization experiments, perform resampling for error type probing and answer selection experiments, and run other baselines like logprob detection and p_true detection. The repository supports various datasets such as TriviaQA, Movies, HotpotQA, Winobias, Winogrande, NLI, IMDB, Math, and Natural questions. It also provides supported models like Mistral-7B-Instruct-v0.2, Mistral-7B-v0.3, Meta-Llama-3-8B, and Meta-Llama-3-8B-Instruct.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.