
ppl.llm.kernel.cuda
None
Stars: 140
Primitive cuda kernel library for ppl.nn.llm, part of PPL.LLM system, tested on Ampere and Hopper, requires Linux on x86_64 or arm64 CPUs, GCC >= 9.4.0, CMake >= 3.18, Git >= 2.7.0, CUDA Toolkit >= 11.4. 11.6 recommended. Provides cuda kernel functionalities for deep learning tasks.
README:
ppl.llm.kernel.cuda is a part of PPL.LLM system.

We recommend users who are new to this project to read the Overview of system.
Primitive cuda kernel library for ppl.nn.llm
Currently, only Ampere and Hopper have been tested.
- Linux running on x86_64 or arm64 CPUs
- GCC >= 9.4.0
- CMake >= 3.18
- Git >= 2.7.0
- CUDA Toolkit >= 11.4. 11.6 recommended. (for CUDA)
-
Installing Prerequisites(on Debian or Ubuntu for example)
apt-get install build-essential cmake git
-
Cloning Source Code
git clone https://github.com/openppl-public/ppl.llm.kernel.cuda.git
-
Building from Source
./build.sh -DPPLNN_CUDA_ENABLE_NCCL=ON -DPPLNN_ENABLE_CUDA_JIT=OFF -DPPLNN_CUDA_ARCHITECTURES="'80;86;87'" -DPPLCOMMON_CUDA_ARCHITECTURES="'80;86;87'"
This project is distributed under the Apache License, Version 2.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ppl.llm.kernel.cuda
Similar Open Source Tools
ppl.llm.kernel.cuda
Primitive cuda kernel library for ppl.nn.llm, part of PPL.LLM system, tested on Ampere and Hopper, requires Linux on x86_64 or arm64 CPUs, GCC >= 9.4.0, CMake >= 3.18, Git >= 2.7.0, CUDA Toolkit >= 11.4. 11.6 recommended. Provides cuda kernel functionalities for deep learning tasks.
Scrapling
Scrapling is a high-performance, intelligent web scraping library for Python that automatically adapts to website changes while significantly outperforming popular alternatives. For both beginners and experts, Scrapling provides powerful features while maintaining simplicity. It offers features like fast and stealthy HTTP requests, adaptive scraping with smart element tracking and flexible selection, high performance with lightning-fast speed and memory efficiency, and developer-friendly navigation API and rich text processing. It also includes advanced parsing features like smart navigation, content-based selection, handling structural changes, and finding similar elements. Scrapling is designed to handle anti-bot protections and website changes effectively, making it a versatile tool for web scraping tasks.
rag-chat
The `@upstash/rag-chat` package simplifies the development of retrieval-augmented generation (RAG) chat applications by providing Next.js compatibility with streaming support, built-in vector store, optional Redis compatibility for fast chat history management, rate limiting, and disableRag option. Users can easily set up the environment variables and initialize RAGChat to interact with AI models, manage knowledge base, chat history, and enable debugging features. Advanced configuration options allow customization of RAGChat instance with built-in rate limiting, observability via Helicone, and integration with Next.js route handlers and Vercel AI SDK. The package supports OpenAI models, Upstash-hosted models, and custom providers like TogetherAi and Replicate.

crawl4ai
Crawl4AI is a powerful and free web crawling service that extracts valuable data from websites and provides LLM-friendly output formats. It supports crawling multiple URLs simultaneously, replaces media tags with ALT, and is completely free to use and open-source. Users can integrate Crawl4AI into Python projects as a library or run it as a standalone local server. The tool allows users to crawl and extract data from specified URLs using different providers and models, with options to include raw HTML content, force fresh crawls, and extract meaningful text blocks. Configuration settings can be adjusted in the `crawler/config.py` file to customize providers, API keys, chunk processing, and word thresholds. Contributions to Crawl4AI are welcome from the open-source community to enhance its value for AI enthusiasts and developers.
gpt-computer-assistant
GPT Computer Assistant (GCA) is an open-source framework designed to build vertical AI agents that can automate tasks on Windows, macOS, and Ubuntu systems. It leverages the Model Context Protocol (MCP) and its own modules to mimic human-like actions and achieve advanced capabilities. With GCA, users can empower themselves to accomplish more in less time by automating tasks like updating dependencies, analyzing databases, and configuring cloud security settings.

chat
deco.chat is an open-source foundation for building AI-native software, providing developers, engineers, and AI enthusiasts with robust tools to rapidly prototype, develop, and deploy AI-powered applications. It empowers Vibecoders to prototype ideas and Agentic engineers to deploy scalable, secure, and sustainable production systems. The core capabilities include an open-source runtime for composing tools and workflows, MCP Mesh for secure integration of models and APIs, a unified TypeScript stack for backend logic and custom frontends, global modular infrastructure built on Cloudflare, and a visual workspace for building agents and orchestrating everything in code.

curator
Bespoke Curator is an open-source tool for data curation and structured data extraction. It provides a Python library for generating synthetic data at scale, with features like programmability, performance optimization, caching, and integration with HuggingFace Datasets. The tool includes a Curator Viewer for dataset visualization and offers a rich set of functionalities for creating and refining data generation strategies.
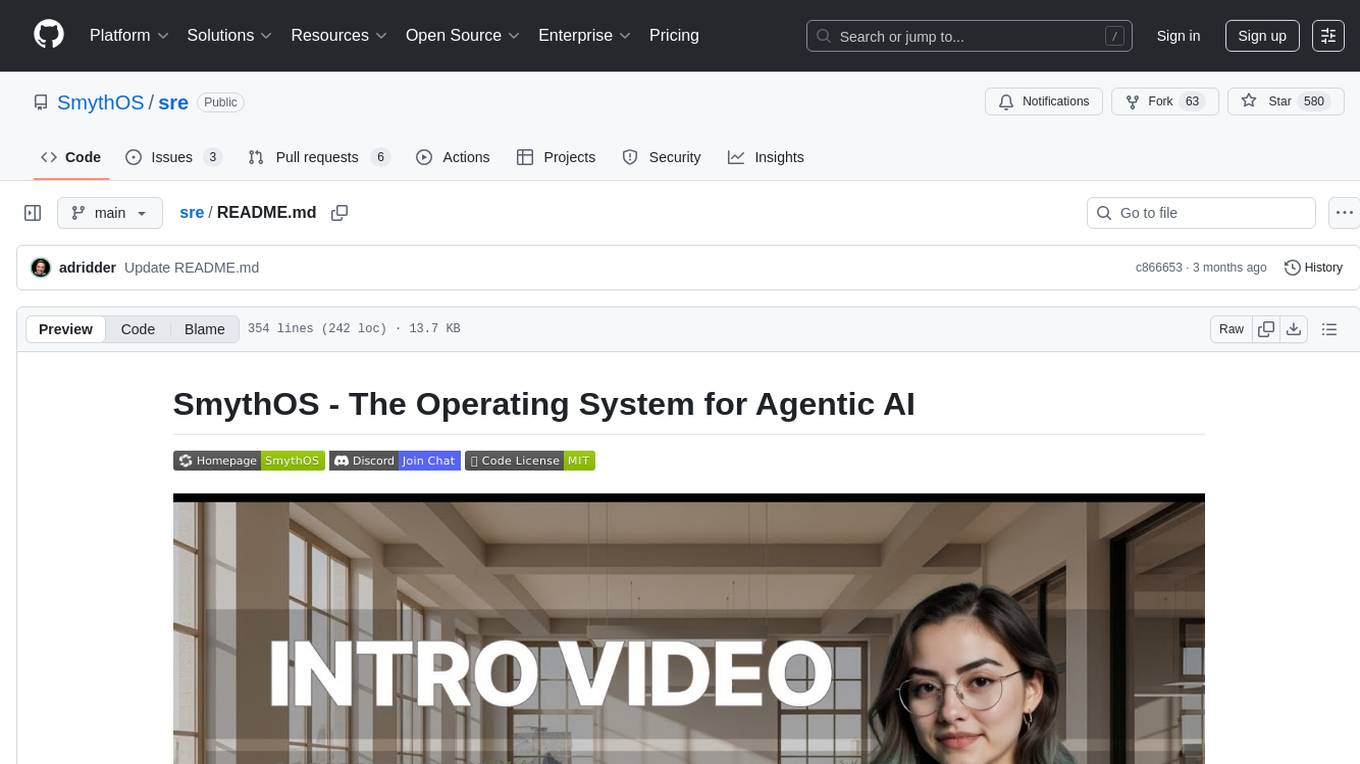
sre
SmythOS is an operating system designed for building, deploying, and managing intelligent AI agents at scale. It provides a unified SDK and resource abstraction layer for various AI services, making it easy to scale and flexible. With an agent-first design, developer-friendly SDK, modular architecture, and enterprise security features, SmythOS offers a robust foundation for AI workloads. The system is built with a philosophy inspired by traditional operating system kernels, ensuring autonomy, control, and security for AI agents. SmythOS aims to make shipping production-ready AI agents accessible and open for everyone in the coming Internet of Agents era.
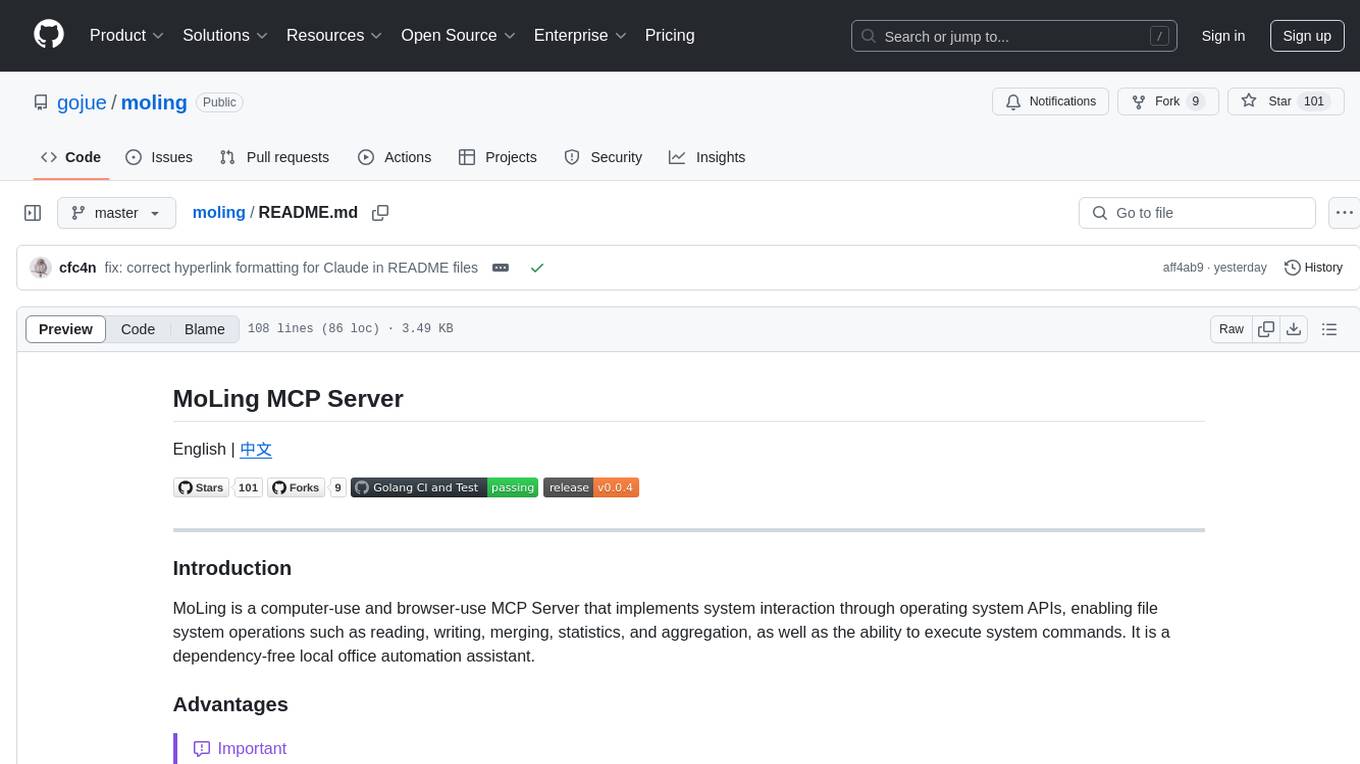
moling
MoLing is a computer-use and browser-use MCP Server that implements system interaction through operating system APIs, enabling file system operations such as reading, writing, merging, statistics, and aggregation, as well as the ability to execute system commands. It is a dependency-free local office automation assistant. Requiring no installation of any dependencies, MoLing can be run directly and is compatible with multiple operating systems, including Windows, Linux, and macOS. This eliminates the hassle of dealing with environment conflicts involving Node.js, Python, Docker, and other development environments. Command-line operations are dangerous and should be used with caution. MoLing supports features like file system operations, command-line terminal execution, browser control powered by 'github.com/chromedp/chromedp', and future plans for personal PC data organization, document writing assistance, schedule planning, and life assistant features. MoLing has been tested on macOS but may have issues on other operating systems.
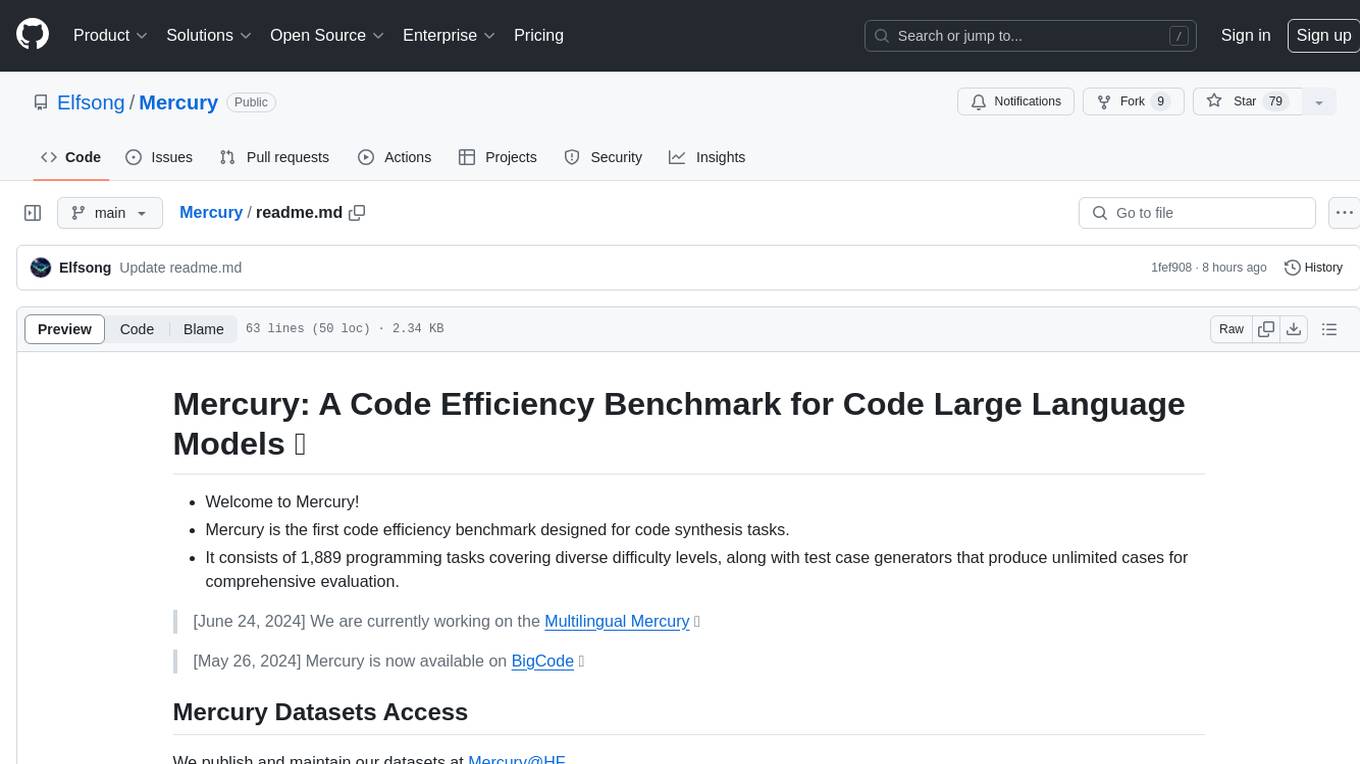
Mercury
Mercury is a code efficiency benchmark designed for code synthesis tasks. It includes 1,889 programming tasks of varying difficulty levels and provides test case generators for comprehensive evaluation. The benchmark aims to assess the efficiency of large language models in generating code solutions.
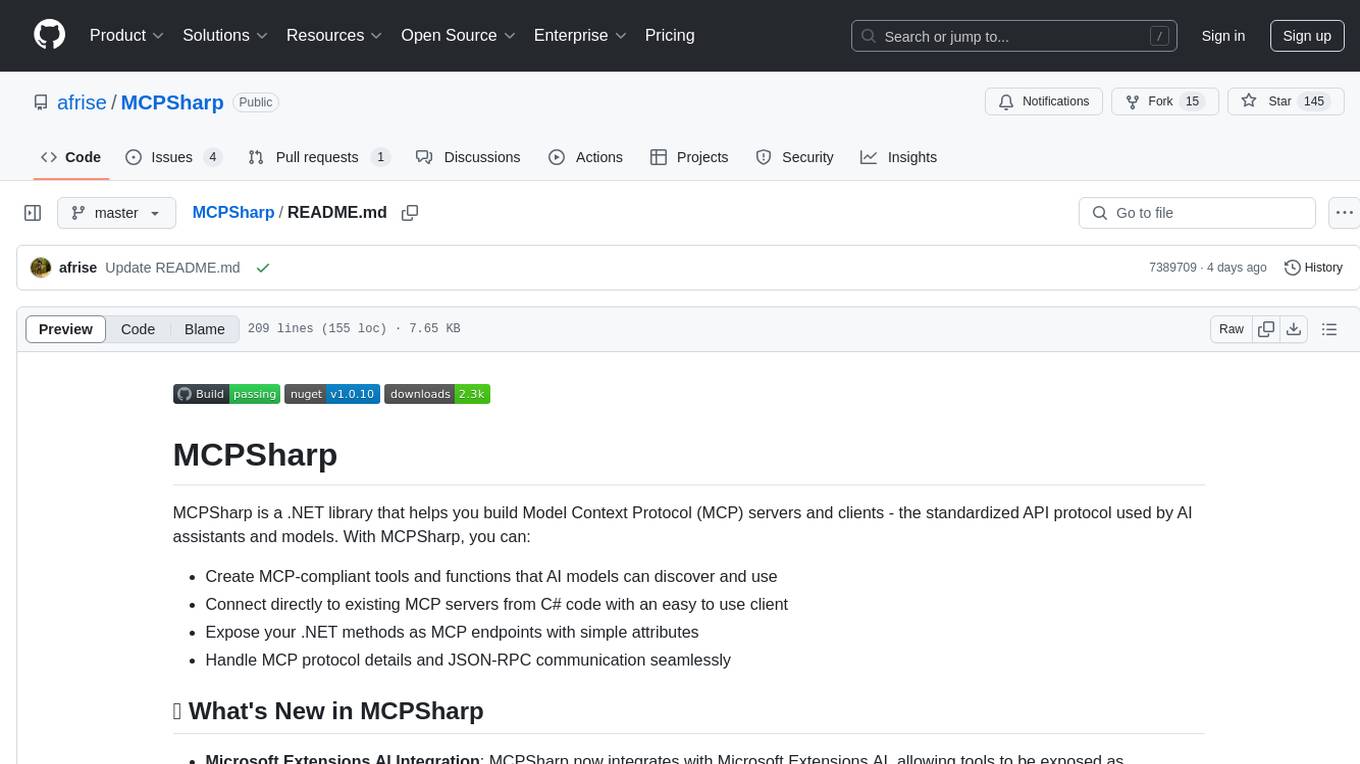
MCPSharp
MCPSharp is a .NET library that helps build Model Context Protocol (MCP) servers and clients for AI assistants and models. It allows creating MCP-compliant tools, connecting to existing MCP servers, exposing .NET methods as MCP endpoints, and handling MCP protocol details seamlessly. With features like attribute-based API, JSON-RPC support, parameter validation, and type conversion, MCPSharp simplifies the development of AI capabilities in applications through standardized interfaces.
Learn_Prompting
Learn Prompting is a platform offering free resources, courses, and webinars to master prompt engineering and generative AI. It provides a Prompt Engineering Guide, courses on Generative AI, workshops, and the HackAPrompt competition. The platform also offers AI Red Teaming and AI Safety courses, research reports on prompting techniques, and welcomes contributions in various forms such as content suggestions, translations, artwork, and typo fixes. Users can locally develop the website using Visual Studio Code, Git, and Node.js, and run it in development mode to preview changes.

obsei
Obsei is an open-source, low-code, AI powered automation tool that consists of an Observer to collect unstructured data from various sources, an Analyzer to analyze the collected data with various AI tasks, and an Informer to send analyzed data to various destinations. The tool is suitable for scheduled jobs or serverless applications as all Observers can store their state in databases. Obsei is still in alpha stage, so caution is advised when using it in production. The tool can be used for social listening, alerting/notification, automatic customer issue creation, extraction of deeper insights from feedbacks, market research, dataset creation for various AI tasks, and more based on creativity.

ApeRAG
ApeRAG is a production-ready platform for Retrieval-Augmented Generation (RAG) that combines Graph RAG, vector search, and full-text search with advanced AI agents. It is ideal for building Knowledge Graphs, Context Engineering, and deploying intelligent AI agents for autonomous search and reasoning across knowledge bases. The platform offers features like advanced index types, intelligent AI agents with MCP support, enhanced Graph RAG with entity normalization, multimodal processing, hybrid retrieval engine, MinerU integration for document parsing, production-grade deployment with Kubernetes, enterprise management features, MCP integration, and developer-friendly tools for customization and contribution.
BodhiApp
Bodhi App runs Open Source Large Language Models locally, exposing LLM inference capabilities as OpenAI API compatible REST APIs. It leverages llama.cpp for GGUF format models and huggingface.co ecosystem for model downloads. Users can run fine-tuned models for chat completions, create custom aliases, and convert Huggingface models to GGUF format. The CLI offers commands for environment configuration, model management, pulling files, serving API, and more.
enferno
Enferno is a modern Flask framework optimized for AI-assisted development workflows. It combines carefully crafted development patterns, smart Cursor Rules, and modern libraries to enable developers to build sophisticated web applications with unprecedented speed. Enferno's intelligent patterns and contextual guides help create production-ready SAAS applications faster than ever. It includes features like modern stack, authentication, OAuth integration, database support, task queue, frontend components, security measures, Docker readiness, and more.
For similar tasks

Open-Prompt-Injection
OpenPromptInjection is an open-source toolkit for attacks and defenses in LLM-integrated applications, enabling easy implementation, evaluation, and extension of attacks, defenses, and LLMs. It supports various attack and defense strategies, including prompt injection, paraphrasing, retokenization, data prompt isolation, instructional prevention, sandwich prevention, perplexity-based detection, LLM-based detection, response-based detection, and know-answer detection. Users can create models, tasks, and apps to evaluate different scenarios. The toolkit currently supports PaLM2 and provides a demo for querying models with prompts. Users can also evaluate ASV for different scenarios by injecting tasks and querying models with attacked data prompts.

LLM-LieDetector
This repository contains code for reproducing experiments on lie detection in black-box LLMs by asking unrelated questions. It includes Q/A datasets, prompts, and fine-tuning datasets for generating lies with language models. The lie detectors rely on asking binary 'elicitation questions' to diagnose whether the model has lied. The code covers generating lies from language models, training and testing lie detectors, and generalization experiments. It requires access to GPUs and OpenAI API calls for running experiments with open-source models. Results are stored in the repository for reproducibility.
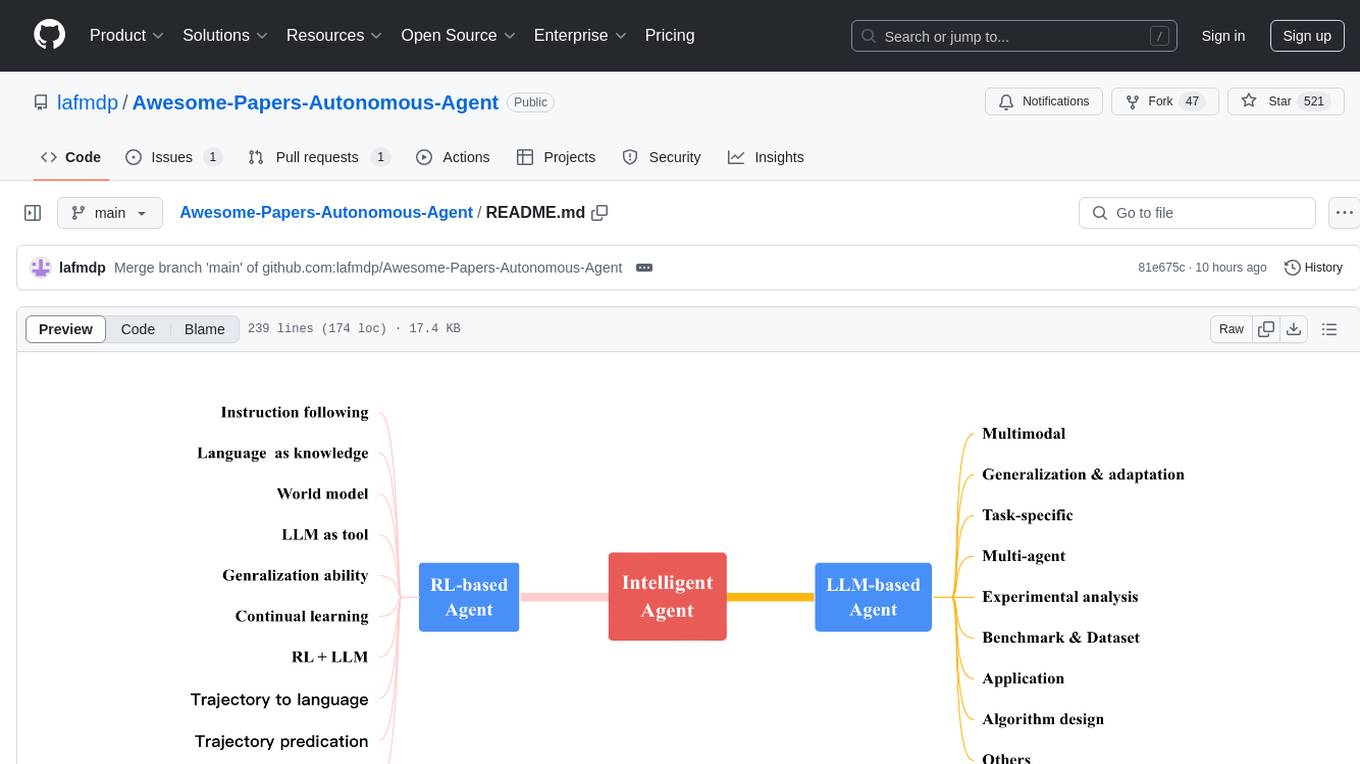
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.

SwiftSage
SwiftSage is a tool designed for conducting experiments in the field of machine learning and artificial intelligence. It provides a platform for researchers and developers to implement and test various algorithms and models. The tool is particularly useful for exploring new ideas and conducting experiments in a controlled environment. SwiftSage aims to streamline the process of developing and testing machine learning models, making it easier for users to iterate on their ideas and achieve better results. With its user-friendly interface and powerful features, SwiftSage is a valuable tool for anyone working in the field of AI and ML.

MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.
ppl.llm.kernel.cuda
Primitive cuda kernel library for ppl.nn.llm, part of PPL.LLM system, tested on Ampere and Hopper, requires Linux on x86_64 or arm64 CPUs, GCC >= 9.4.0, CMake >= 3.18, Git >= 2.7.0, CUDA Toolkit >= 11.4. 11.6 recommended. Provides cuda kernel functionalities for deep learning tasks.
craftium
Craftium is an open-source platform based on the Minetest voxel game engine and the Gymnasium and PettingZoo APIs, designed for creating fast, rich, and diverse single and multi-agent environments. It allows for connecting to Craftium's Python process, executing actions as keyboard and mouse controls, extending the Lua API for creating RL environments and tasks, and supporting client/server synchronization for slow agents. Craftium is fully extensible, extensively documented, modern RL API compatible, fully open source, and eliminates the need for Java. It offers a variety of environments for research and development in reinforcement learning.
LLMsKnow
LLMs Know More Than They Show is a repository containing code to reproduce the results in the paper. It includes scripts to generate model answers, extract exact answers, probe all layers and tokens, probe specific layers and tokens, conduct generalization experiments, perform resampling for error type probing and answer selection experiments, and run other baselines like logprob detection and p_true detection. The repository supports various datasets such as TriviaQA, Movies, HotpotQA, Winobias, Winogrande, NLI, IMDB, Math, and Natural questions. It also provides supported models like Mistral-7B-Instruct-v0.2, Mistral-7B-v0.3, Meta-Llama-3-8B, and Meta-Llama-3-8B-Instruct.
For similar jobs
ppl.llm.kernel.cuda
ppl.llm.kernel.cuda is a primitive cuda kernel library for ppl.nn.llm system, designed for Ampere and Hopper architectures. It requires Linux running on x86_64 or arm64 CPUs with specific versions of GCC, CMake, Git, and CUDA Toolkit. Users can follow the provided Quick Start guide to install prerequisites, clone the source code, and build from source. The project is distributed under the Apache License, Version 2.0.

how-to-optim-algorithm-in-cuda
This repository documents how to optimize common algorithms based on CUDA. It includes subdirectories with code implementations for specific optimizations. The optimizations cover topics such as compiling PyTorch from source, NVIDIA's reduce optimization, OneFlow's elementwise template, fast atomic add for half data types, upsample nearest2d optimization in OneFlow, optimized indexing in PyTorch, OneFlow's softmax kernel, linear attention optimization, and more. The repository also includes learning resources related to deep learning frameworks, compilers, and optimization techniques.
ppl.llm.kernel.cuda
Primitive cuda kernel library for ppl.nn.llm, part of PPL.LLM system, tested on Ampere and Hopper, requires Linux on x86_64 or arm64 CPUs, GCC >= 9.4.0, CMake >= 3.18, Git >= 2.7.0, CUDA Toolkit >= 11.4. 11.6 recommended. Provides cuda kernel functionalities for deep learning tasks.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.