
ppl.llm.kernel.cuda
None
Stars: 127
ppl.llm.kernel.cuda is a primitive cuda kernel library for ppl.nn.llm system, designed for Ampere and Hopper architectures. It requires Linux running on x86_64 or arm64 CPUs with specific versions of GCC, CMake, Git, and CUDA Toolkit. Users can follow the provided Quick Start guide to install prerequisites, clone the source code, and build from source. The project is distributed under the Apache License, Version 2.0.
README:
ppl.llm.kernel.cuda is a part of PPL.LLM system.

We recommend users who are new to this project to read the Overview of system.
Primitive cuda kernel library for ppl.nn.llm
Currently, only Ampere and Hopper have been tested.
- Linux running on x86_64 or arm64 CPUs
- GCC >= 9.4.0
- CMake >= 3.18
- Git >= 2.7.0
- CUDA Toolkit >= 11.4. 11.6 recommended. (for CUDA)
-
Installing Prerequisites(on Debian or Ubuntu for example)
apt-get install build-essential cmake git
-
Cloning Source Code
git clone https://github.com/openppl-public/ppl.llm.kernel.cuda.git
-
Building from Source
./build.sh -DPPLNN_CUDA_ENABLE_NCCL=ON -DPPLNN_ENABLE_CUDA_JIT=OFF -DPPLNN_CUDA_ARCHITECTURES="'80;86;87'" -DPPLCOMMON_CUDA_ARCHITECTURES="'80;86;87'"
This project is distributed under the Apache License, Version 2.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ppl.llm.kernel.cuda
Similar Open Source Tools
ppl.llm.kernel.cuda
ppl.llm.kernel.cuda is a primitive cuda kernel library for ppl.nn.llm system, designed for Ampere and Hopper architectures. It requires Linux running on x86_64 or arm64 CPUs with specific versions of GCC, CMake, Git, and CUDA Toolkit. Users can follow the provided Quick Start guide to install prerequisites, clone the source code, and build from source. The project is distributed under the Apache License, Version 2.0.

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.
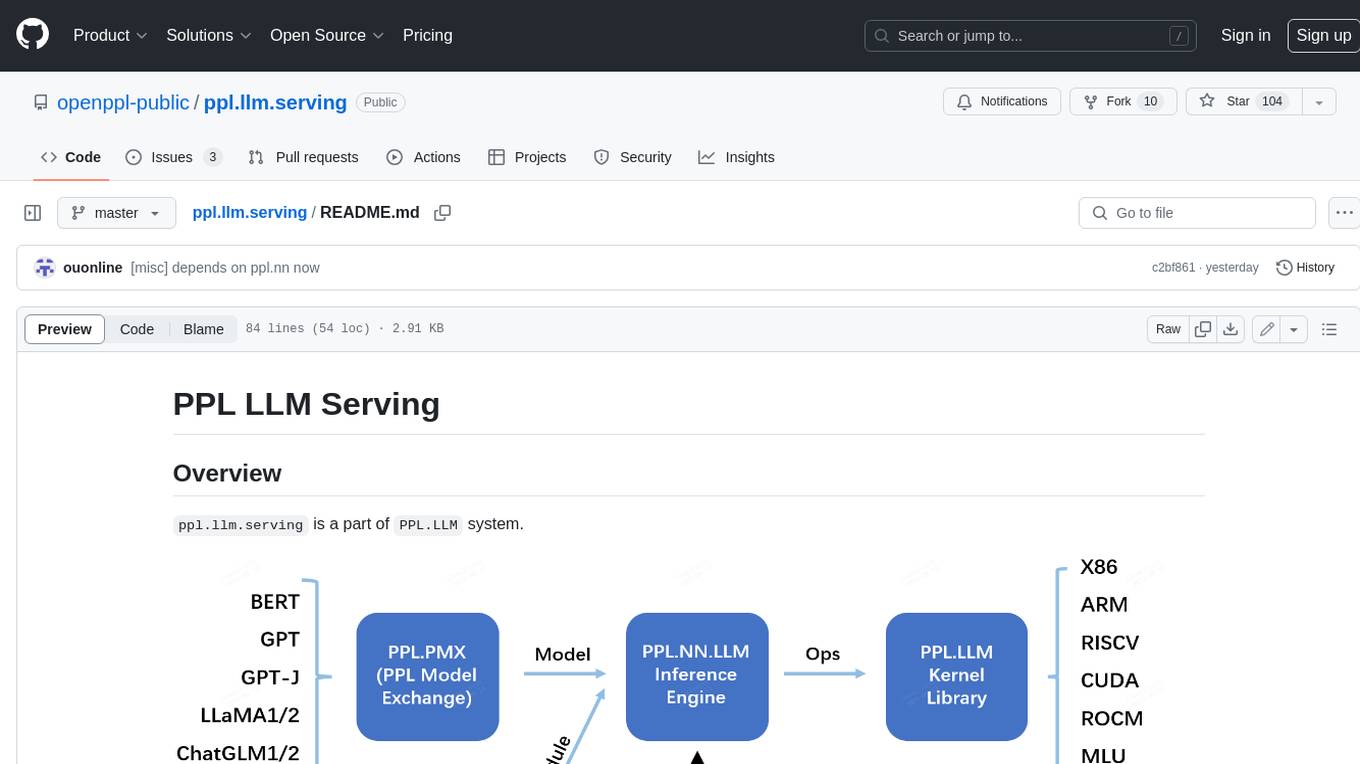
ppl.llm.serving
PPL LLM Serving is a serving based on ppl.nn for various Large Language Models (LLMs). It provides inference support for LLaMA. Key features include: * **High Performance:** Optimized for fast and efficient inference on LLM models. * **Scalability:** Supports distributed deployment across multiple GPUs or machines. * **Flexibility:** Allows for customization of model configurations and inference pipelines. * **Ease of Use:** Provides a user-friendly interface for deploying and managing LLM models. This tool is suitable for various tasks, including: * **Text Generation:** Generating text, stories, or code from scratch or based on a given prompt. * **Text Summarization:** Condensing long pieces of text into concise summaries. * **Question Answering:** Answering questions based on a given context or knowledge base. * **Language Translation:** Translating text between different languages. * **Chatbot Development:** Building conversational AI systems that can engage in natural language interactions. Keywords: llm, large language model, natural language processing, text generation, question answering, language translation, chatbot development
MobChip
MobChip is an all-in-one Entity AI and Bosses Library for Minecraft 1.13 and above. It simplifies the implementation of Minecraft's native entity AI into plugins, offering documentation, API usage, and utilities for ease of use. The library is flexible, using Reflection and Abstraction for modern functionality on older versions, and ensuring compatibility across multiple Minecraft versions. MobChip is open source, providing features like Bosses Library, Pathfinder Goals, Behaviors, Villager Gossip, Ender Dragon Phases, and more.

openai-kotlin
OpenAI Kotlin API client is a Kotlin client for OpenAI's API with multiplatform and coroutines capabilities. It allows users to interact with OpenAI's API using Kotlin programming language. The client supports various features such as models, chat, images, embeddings, files, fine-tuning, moderations, audio, assistants, threads, messages, and runs. It also provides guides on getting started, chat & function call, file source guide, and assistants. Sample apps are available for reference, and troubleshooting guides are provided for common issues. The project is open-source and licensed under the MIT license, allowing contributions from the community.
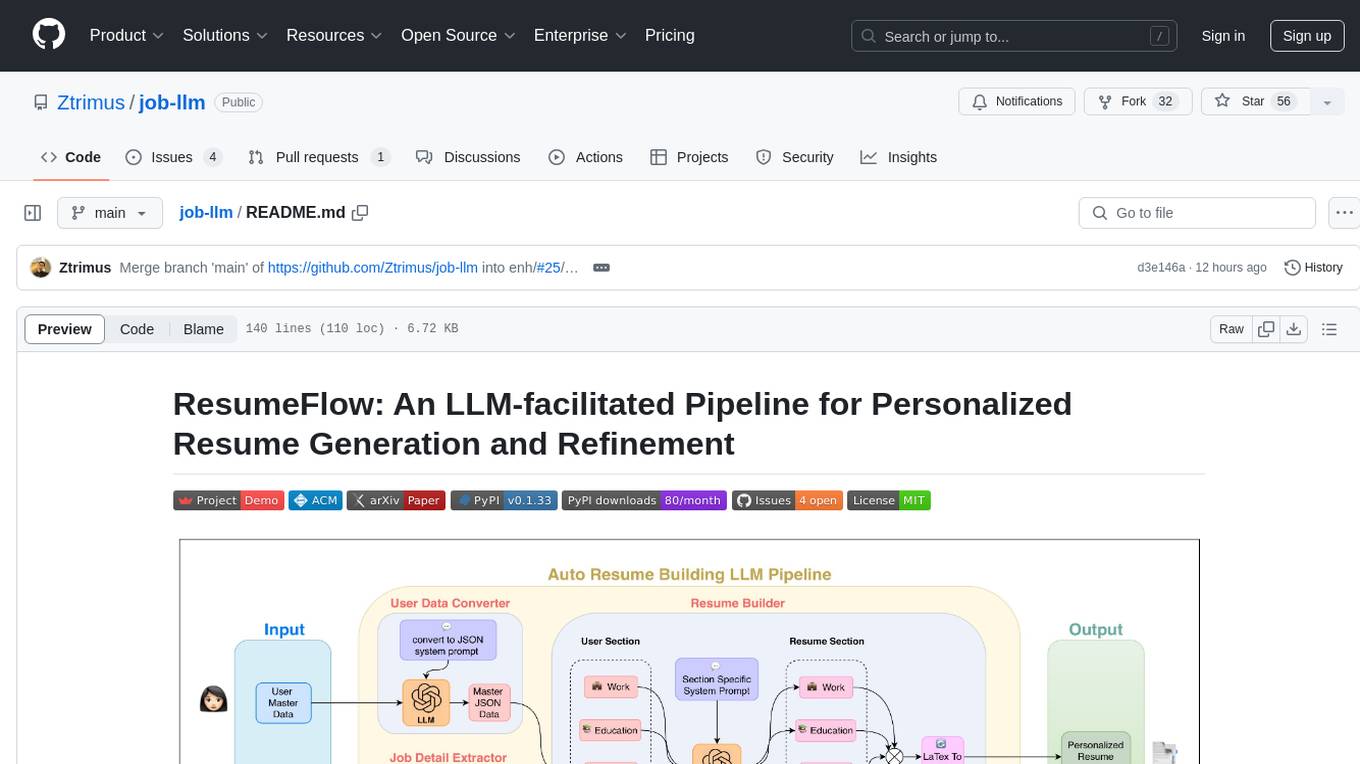
job-llm
ResumeFlow is an automated system utilizing Large Language Models (LLMs) to streamline the job application process. It aims to reduce human effort in various steps of job hunting by integrating LLM technology. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code. The project focuses on leveraging LLMs to automate tasks such as resume generation and refinement, making job applications smoother and more efficient.
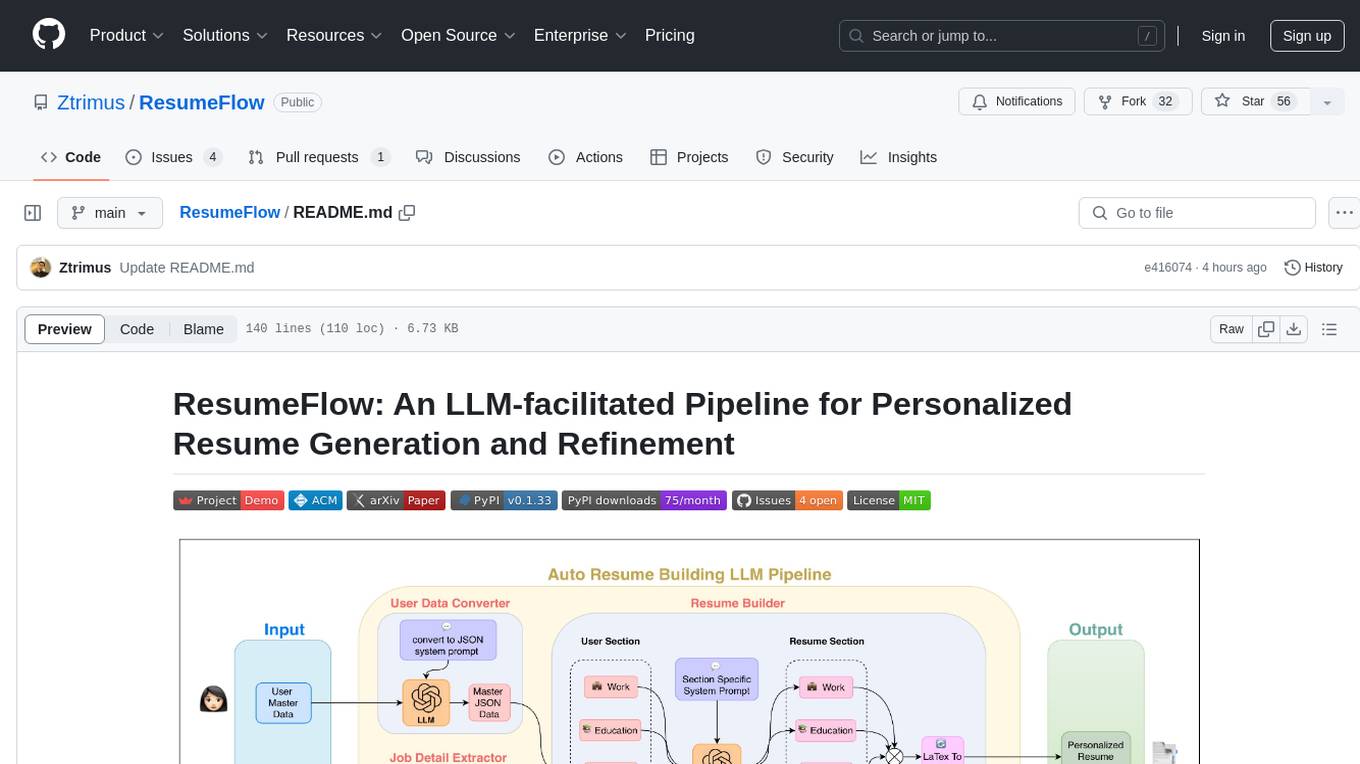
ResumeFlow
ResumeFlow is an automated system that leverages Large Language Models (LLMs) to streamline the job application process. By integrating LLM technology, the tool aims to automate various stages of job hunting, making it easier for users to apply for jobs. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code from GitHub. The tool requires Python 3.11.6 or above and an LLM API key from OpenAI or Gemini Pro for usage. ResumeFlow offers functionalities such as generating curated resumes and cover letters based on job URLs and user's master resume data.
tlm
tlm is a local CLI copilot tool powered by CodeLLaMa, providing efficient command line suggestions without the need for an API key or internet connection. It works on macOS, Linux, and Windows, with automatic shell detection for Powershell, Bash, and Zsh. The tool offers one-liner generation and command explanation, and can be installed via an installation script or using Go Install. Ollama is required to download necessary models, and the tool can be easily deployed and configured. Contributors are welcome to enhance the tool's functionality.
airbadge
Airbadge is a Stripe addon for Auth.js that provides an easy way to create a SaaS site without writing any authentication or payment code. It integrates Stripe Checkout into the signup flow, offers over 50 OAuth options for authentication, allows route and UI restriction based on subscription, enables self-service account management, handles all Stripe webhooks, supports trials and free plans, includes subscription and plan data in the session, and is open source with a BSL license. The project also provides components for conditional UI display based on subscription status and helper functions to restrict route access. Additionally, it offers a billing endpoint with various routes for billing operations. Setup involves installing @airbadge/sveltekit, setting up a database provider for Auth.js, adding environment variables, configuring authentication and billing options, and forwarding Stripe events to localhost.
ChatGPT-desktop
ChatGPT Desktop Application is a multi-platform tool that provides a powerful AI wrapper for generating text. It offers features like text-to-speech, exporting chat history in various formats, automatic application upgrades, system tray hover window, support for slash commands, customization of global shortcuts, and pop-up search. The application is built using Tauri and aims to enhance user experience by simplifying text generation tasks. It is available for Mac, Windows, and Linux, and is designed for personal learning and research purposes.
bittensor
Bittensor is an internet-scale neural network that incentivizes computers to provide access to machine learning models in a decentralized and censorship-resistant manner. It operates through a token-based mechanism where miners host, train, and procure machine learning systems to fulfill verification problems defined by validators. The network rewards miners and validators for their contributions, ensuring continuous improvement in knowledge output. Bittensor allows anyone to participate, extract value, and govern the network without centralized control. It supports tasks such as generating text, audio, images, and extracting numerical representations.
Vitron
Vitron is a unified pixel-level vision LLM designed for comprehensive understanding, generating, segmenting, and editing static images and dynamic videos. It addresses challenges in existing vision LLMs such as superficial instance-level understanding, lack of unified support for images and videos, and insufficient coverage across various vision tasks. The tool requires Python >= 3.8, Pytorch == 2.1.0, and CUDA Version >= 11.8 for installation. Users can deploy Gradio demo locally and fine-tune their models for specific tasks.
tgpt
tgpt is a cross-platform command-line interface (CLI) tool that allows users to interact with AI chatbots in the Terminal without needing API keys. It supports various AI providers such as KoboldAI, Phind, Llama2, Blackbox AI, and OpenAI. Users can generate text, code, and images using different flags and options. The tool can be installed on GNU/Linux, MacOS, FreeBSD, and Windows systems. It also supports proxy configurations and provides options for updating and uninstalling the tool.
aiohttp-client-cache
aiohttp-client-cache is an asynchronous persistent cache for aiohttp client requests, based on requests-cache. It is easy to use, customizable, and persistent, with several storage backends available, including SQLite, DynamoDB, MongoDB, DragonflyDB, and Redis.
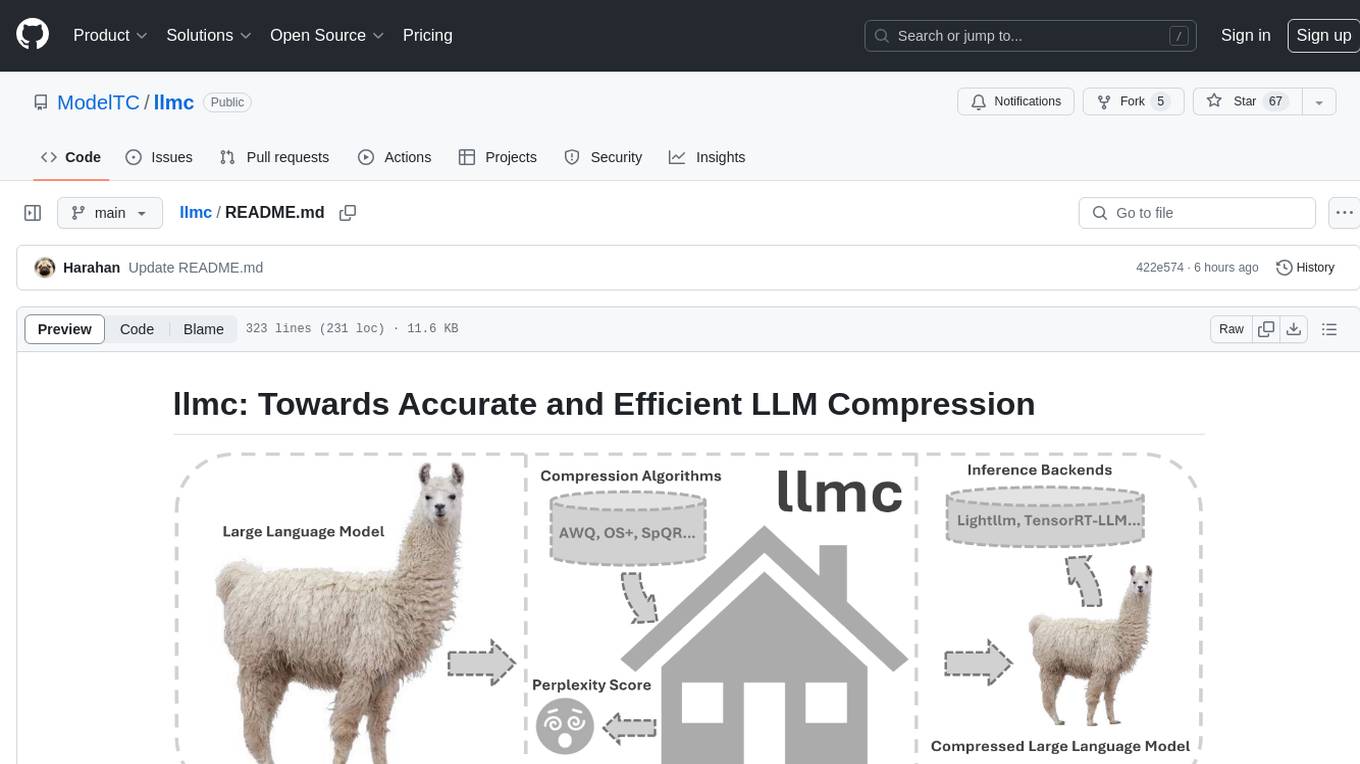
llmc
llmc is an off-the-shell tool designed for compressing LLM, leveraging state-of-the-art compression algorithms to enhance efficiency and reduce model size without compromising performance. It provides users with the ability to quantize LLMs, choose from various compression algorithms, export transformed models for further optimization, and directly infer compressed models with a shallow memory footprint. The tool supports a range of model types and quantization algorithms, with ongoing development to include pruning techniques. Users can design their configurations for quantization and evaluation, with documentation and examples planned for future updates. llmc is a valuable resource for researchers working on post-training quantization of large language models.

llama_index
LlamaIndex is a data framework for building LLM applications. It provides tools for ingesting, structuring, and querying data, as well as integrating with LLMs and other tools. LlamaIndex is designed to be easy to use for both beginner and advanced users, and it provides a comprehensive set of features for building LLM applications.
For similar tasks

stable-diffusion.cpp
The stable-diffusion.cpp repository provides an implementation for inferring stable diffusion in pure C/C++. It offers features such as support for different versions of stable diffusion, lightweight and dependency-free implementation, various quantization support, memory-efficient CPU inference, GPU acceleration, and more. Users can download the built executable program or build it manually. The repository also includes instructions for downloading weights, building from scratch, using different acceleration methods, running the tool, converting weights, and utilizing various features like Flash Attention, ESRGAN upscaling, PhotoMaker support, and more. Additionally, it mentions future TODOs and provides information on memory requirements, bindings, UIs, contributors, and references.
FileKitty
FileKitty is a simple file selection and concatenation tool that allows users to select files from a directory, concatenate them into a single file, save the concatenated file, and copy files to the clipboard. It is useful for concatenating files for use in a single file format and pasting file contents into an LLM to provide context to a prompt. The tool is built using Poetry to manage dependencies and build the app.
ppl.llm.kernel.cuda
ppl.llm.kernel.cuda is a primitive cuda kernel library for ppl.nn.llm system, designed for Ampere and Hopper architectures. It requires Linux running on x86_64 or arm64 CPUs with specific versions of GCC, CMake, Git, and CUDA Toolkit. Users can follow the provided Quick Start guide to install prerequisites, clone the source code, and build from source. The project is distributed under the Apache License, Version 2.0.
awesome-cuda-tensorrt-fpga
Okay, here is a JSON object with the requested information about the awesome-cuda-tensorrt-fpga repository:
python-sc2
python-sc2 is an easy-to-use library for writing AI Bots for StarCraft II in Python 3. It aims for simplicity and ease of use while providing both high and low level abstractions. The library covers only the raw scripted interface and intends to help new bot authors with added functions. Users can install the library using pip and need a StarCraft II executable to run bots. The API configuration options allow users to customize bot behavior and performance. The community provides support through Discord servers, and users can contribute to the project by creating new issues or pull requests following style guidelines.
For similar jobs
ppl.llm.kernel.cuda
ppl.llm.kernel.cuda is a primitive cuda kernel library for ppl.nn.llm system, designed for Ampere and Hopper architectures. It requires Linux running on x86_64 or arm64 CPUs with specific versions of GCC, CMake, Git, and CUDA Toolkit. Users can follow the provided Quick Start guide to install prerequisites, clone the source code, and build from source. The project is distributed under the Apache License, Version 2.0.

how-to-optim-algorithm-in-cuda
This repository documents how to optimize common algorithms based on CUDA. It includes subdirectories with code implementations for specific optimizations. The optimizations cover topics such as compiling PyTorch from source, NVIDIA's reduce optimization, OneFlow's elementwise template, fast atomic add for half data types, upsample nearest2d optimization in OneFlow, optimized indexing in PyTorch, OneFlow's softmax kernel, linear attention optimization, and more. The repository also includes learning resources related to deep learning frameworks, compilers, and optimization techniques.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.