
ppl.llm.serving
None
Stars: 114
PPL LLM Serving is a serving based on ppl.nn for various Large Language Models (LLMs). It provides inference support for LLaMA. Key features include: * **High Performance:** Optimized for fast and efficient inference on LLM models. * **Scalability:** Supports distributed deployment across multiple GPUs or machines. * **Flexibility:** Allows for customization of model configurations and inference pipelines. * **Ease of Use:** Provides a user-friendly interface for deploying and managing LLM models. This tool is suitable for various tasks, including: * **Text Generation:** Generating text, stories, or code from scratch or based on a given prompt. * **Text Summarization:** Condensing long pieces of text into concise summaries. * **Question Answering:** Answering questions based on a given context or knowledge base. * **Language Translation:** Translating text between different languages. * **Chatbot Development:** Building conversational AI systems that can engage in natural language interactions. Keywords: llm, large language model, natural language processing, text generation, question answering, language translation, chatbot development
README:
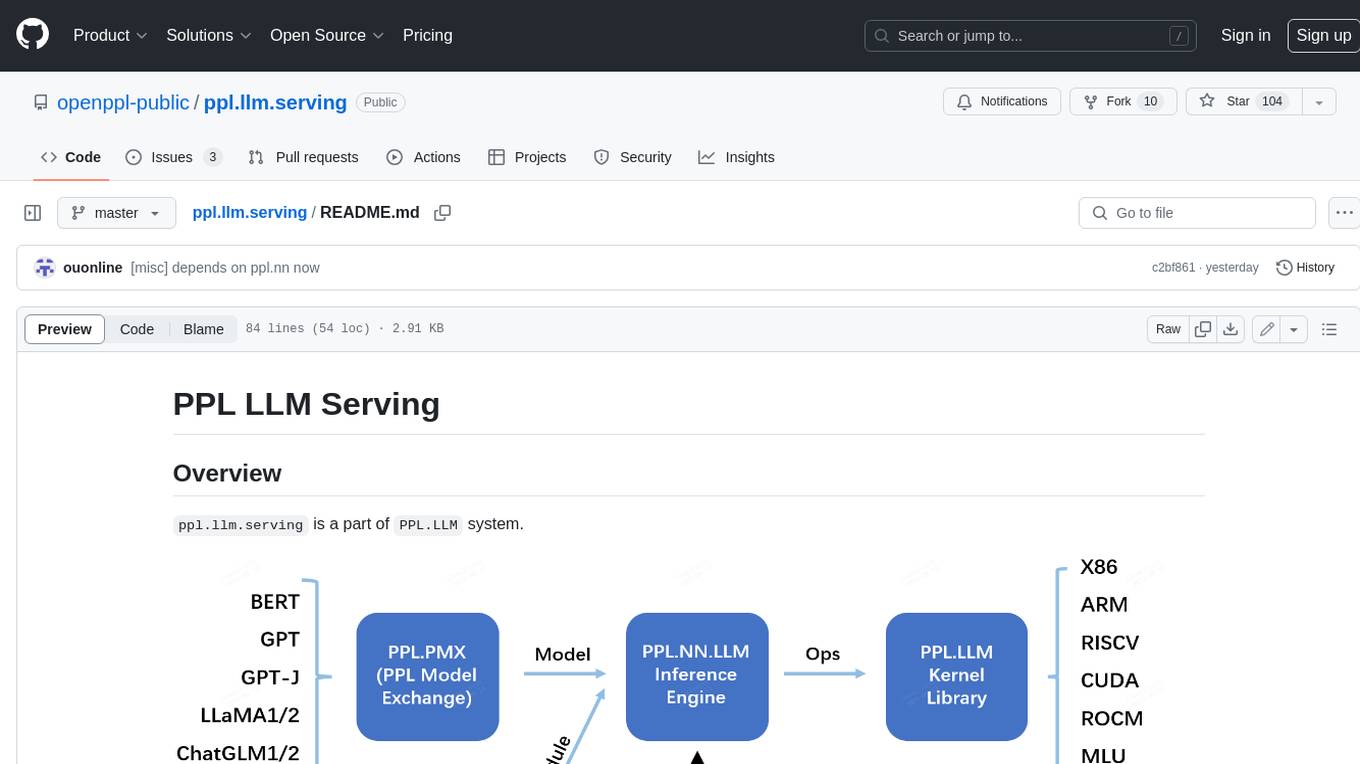
ppl.llm.serving is a part of PPL.LLM system.

We recommend users who are new to this project to read the Overview of system.
ppl.llm.serving is a serving based on ppl.nn for various Large Language Models(LLMs). This repository contains a server based on gRPC and inference support for LLaMA.
- Linux running on x86_64 or arm64 CPUs
- GCC >= 9.4.0
- CMake >= 3.18
- Git >= 2.7.0
- CUDA Toolkit >= 11.4. 11.6 recommended. (for CUDA)
Here is a brief tutorial, refer to LLaMA Guide for more details.
-
Installing Prerequisites(on Debian or Ubuntu for example)
apt-get install build-essential cmake git
-
Cloning Source Code
git clone https://github.com/openppl-public/ppl.llm.serving.git
-
Building from Source
./build.sh -DPPLNN_USE_LLM_CUDA=ON -DPPLNN_CUDA_ENABLE_NCCL=ON -DPPLNN_ENABLE_CUDA_JIT=OFF -DPPLNN_CUDA_ARCHITECTURES="'80;86;87'" -DPPLCOMMON_CUDA_ARCHITECTURES="'80;86;87'"
NCCL is required if multiple GPU devices are used.
-
Exporting Models
Refer to ppl.pmx for details.
-
Running Server
./ppl-build/ppl_llama_server /path/to/server/config.json
Server config examples can be found in
src/models/llama/conf. You are expected to give the correct values before running the server.-
model_dir: path of models exported by ppl.pmx. -
model_param_path: params of models.$model_dir/params.json. -
tokenizer_path: tokenizer files forsentencepiece.
-
-
Running client: send request through gRPC to query the model
./ppl-build/client_sample 127.0.0.1:23333
See tools/client_sample.cc for more details.
-
Benchmarking
./ppl-build/client_qps_measure --target=127.0.0.1:23333 --tokenizer=/path/to/tokenizer/path --dataset=tools/samples_1024.json --request_rate=inf
See tools/client_qps_measure.cc for more details.
--request_rateis the number of request per second, and valueinfmeans send all client request with no interval. -
Running inference offline:
./ppl-build/offline_inference /path/to/server/config.json
See tools/offline_inference.cc for more details.
This project is distributed under the Apache License, Version 2.0.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ppl.llm.serving
Similar Open Source Tools
ppl.llm.serving
PPL LLM Serving is a serving based on ppl.nn for various Large Language Models (LLMs). It provides inference support for LLaMA. Key features include: * **High Performance:** Optimized for fast and efficient inference on LLM models. * **Scalability:** Supports distributed deployment across multiple GPUs or machines. * **Flexibility:** Allows for customization of model configurations and inference pipelines. * **Ease of Use:** Provides a user-friendly interface for deploying and managing LLM models. This tool is suitable for various tasks, including: * **Text Generation:** Generating text, stories, or code from scratch or based on a given prompt. * **Text Summarization:** Condensing long pieces of text into concise summaries. * **Question Answering:** Answering questions based on a given context or knowledge base. * **Language Translation:** Translating text between different languages. * **Chatbot Development:** Building conversational AI systems that can engage in natural language interactions. Keywords: llm, large language model, natural language processing, text generation, question answering, language translation, chatbot development
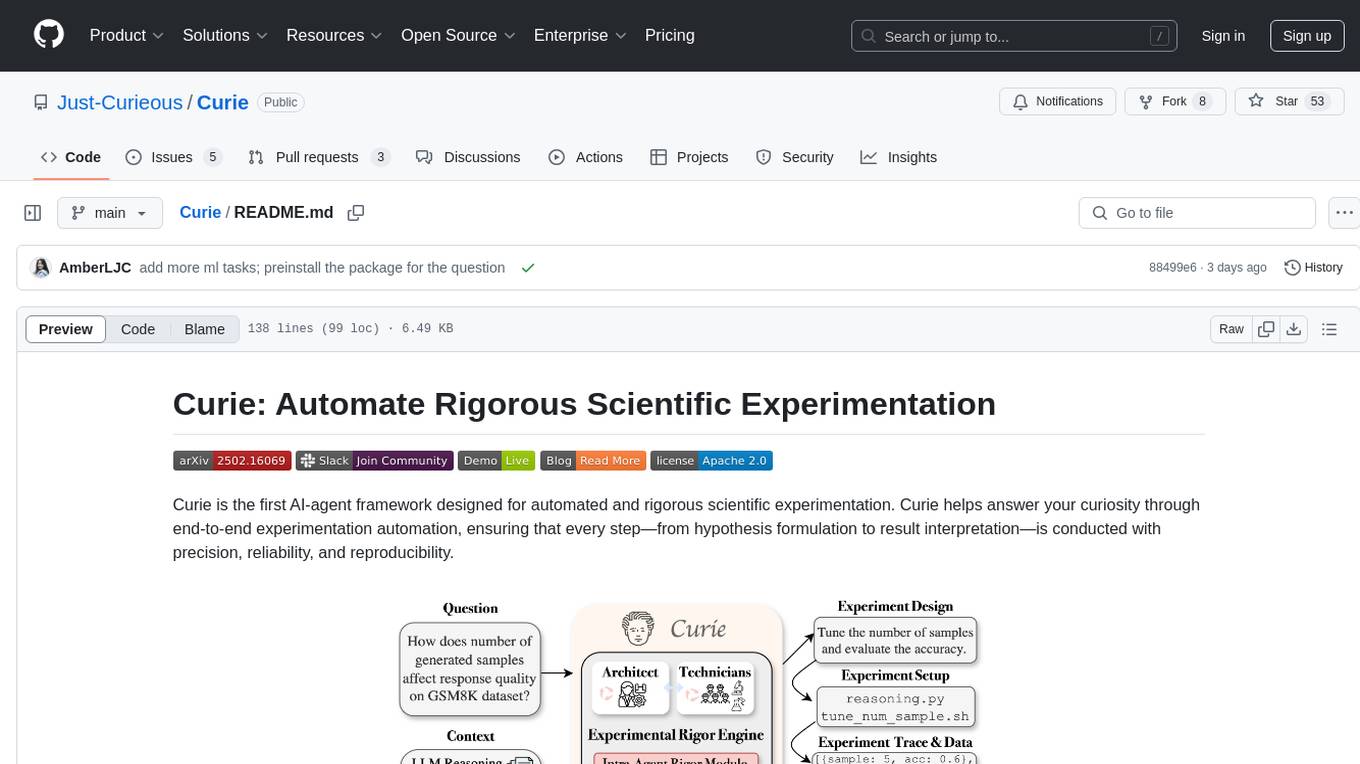
Curie
Curie is an AI-agent framework designed for automated and rigorous scientific experimentation. It automates end-to-end workflow management, ensures methodical procedure, reliability, and interpretability, and supports ML research, system analysis, and scientific discovery. It provides a benchmark with questions from 4 Computer Science domains. Users can customize experiment agents and adapt to their own tasks by configuring base_config.json. Curie is suitable for hyperparameter tuning, algorithm behavior analysis, system performance benchmarking, and automating computational simulations.

RainbowGPT
RainbowGPT is a versatile tool that offers a range of functionalities, including Stock Analysis for financial decision-making, MySQL Management for database navigation, and integration of AI technologies like GPT-4 and ChatGlm3. It provides a user-friendly interface suitable for all skill levels, ensuring seamless information flow and continuous expansion of emerging technologies. The tool enhances adaptability, creativity, and insight, making it a valuable asset for various projects and tasks.
distillKitPlus
DistillKitPlus is an open-source toolkit designed for knowledge distillation (KLD) in low computation resource settings. It supports logit distillation, pre-computed logits for memory-efficient training, LoRA fine-tuning integration, and model quantization for faster inference. The toolkit utilizes a JSON configuration file for project, dataset, model, tokenizer, training, distillation, LoRA, and quantization settings. Users can contribute to the toolkit and contact the developers for technical questions or issues.
sec-parser
The `sec-parser` project simplifies extracting meaningful information from SEC EDGAR HTML documents by organizing them into semantic elements and a tree structure. It helps in parsing SEC filings for financial and regulatory analysis, analytics and data science, AI and machine learning, causal AI, and large language models. The tool is especially beneficial for AI, ML, and LLM applications by streamlining data pre-processing and feature extraction.
ppl.llm.kernel.cuda
ppl.llm.kernel.cuda is a primitive cuda kernel library for ppl.nn.llm system, designed for Ampere and Hopper architectures. It requires Linux running on x86_64 or arm64 CPUs with specific versions of GCC, CMake, Git, and CUDA Toolkit. Users can follow the provided Quick Start guide to install prerequisites, clone the source code, and build from source. The project is distributed under the Apache License, Version 2.0.
airbadge
Airbadge is a Stripe addon for Auth.js that provides an easy way to create a SaaS site without writing any authentication or payment code. It integrates Stripe Checkout into the signup flow, offers over 50 OAuth options for authentication, allows route and UI restriction based on subscription, enables self-service account management, handles all Stripe webhooks, supports trials and free plans, includes subscription and plan data in the session, and is open source with a BSL license. The project also provides components for conditional UI display based on subscription status and helper functions to restrict route access. Additionally, it offers a billing endpoint with various routes for billing operations. Setup involves installing @airbadge/sveltekit, setting up a database provider for Auth.js, adding environment variables, configuring authentication and billing options, and forwarding Stripe events to localhost.
tinystruct
Tinystruct is a simple Java framework designed for easy development with better performance. It offers a modern approach with features like CLI and web integration, built-in lightweight HTTP server, minimal configuration philosophy, annotation-based routing, and performance-first architecture. Developers can focus on real business logic without dealing with unnecessary complexities, making it transparent, predictable, and extensible.
openmeter
OpenMeter is a real-time and scalable usage metering tool for AI, usage-based billing, infrastructure, and IoT use cases. It provides a REST API for integrations and offers client SDKs in Node.js, Python, Go, and Web. OpenMeter is licensed under the Apache 2.0 License.
metta
Metta AI is an open-source research project focusing on the emergence of cooperation and alignment in multi-agent AI systems. It explores the impact of social dynamics like kinship and mate selection on learning and cooperative behaviors of AI agents. The project introduces a reward-sharing mechanism mimicking familial bonds and mate selection to observe the evolution of complex social behaviors among AI agents. Metta aims to contribute to the discussion on safe and beneficial AGI by creating an environment where AI agents can develop general intelligence through continuous learning and adaptation.
Foxel
Foxel is a highly extensible private cloud storage solution for individuals and teams, featuring AI-powered semantic search. It offers unified file management, pluggable storage backends, semantic search capabilities, built-in file preview, permissions and sharing options, and a task processing center. Users can easily manage files, search content within unstructured data, preview various file types, share files, and process tasks asynchronously. Foxel is designed to centralize file management and enhance search capabilities for users.
MobChip
MobChip is an all-in-one Entity AI and Bosses Library for Minecraft 1.13 and above. It simplifies the implementation of Minecraft's native entity AI into plugins, offering documentation, API usage, and utilities for ease of use. The library is flexible, using Reflection and Abstraction for modern functionality on older versions, and ensuring compatibility across multiple Minecraft versions. MobChip is open source, providing features like Bosses Library, Pathfinder Goals, Behaviors, Villager Gossip, Ender Dragon Phases, and more.
ai-context
AI Context is a CLI tool that generates AI-friendly markdown files from GitHub repos, local code, YouTube videos, or webpages. It supports processing local directories, GitHub repositories, YouTube transcripts, and webpages, converting them to markdown format. The tool simplifies interactions with LLMs like ChatGPT and Claude by providing a text-first context creation approach. It offers features for installation, usage, and acknowledgments, with options to process single paths, URLs, or lists of paths concurrently.

deep-research
Deep Research is a lightning-fast tool that uses powerful AI models to generate comprehensive research reports in just a few minutes. It leverages advanced 'Thinking' and 'Task' models, combined with an internet connection, to provide fast and insightful analysis on various topics. The tool ensures privacy by processing and storing all data locally. It supports multi-platform deployment, offers support for various large language models, web search functionality, knowledge graph generation, research history preservation, local and server API support, PWA technology, multi-key payload support, multi-language support, and is built with modern technologies like Next.js and Shadcn UI. Deep Research is open-source under the MIT License.
AirConnect-Synology
AirConnect-Synology is a minimal Synology package that allows users to use AirPlay to stream to UPnP/Sonos & Chromecast devices that do not natively support AirPlay. It is compatible with DSM 7.0 and DSM 7.1, and provides detailed information on installation, configuration, supported devices, troubleshooting, and more. The package automates the installation and usage of AirConnect on Synology devices, ensuring compatibility with various architectures and firmware versions. Users can customize the configuration using the airconnect.conf file and adjust settings for specific speakers like Sonos, Bose SoundTouch, and Pioneer/Phorus/Play-Fi.

atropos
Atropos is a robust and scalable framework for Reinforcement Learning Environments with Large Language Models (LLMs). It provides a flexible platform to accelerate LLM-based RL research across diverse interactive settings. Atropos supports multi-turn and asynchronous RL interactions, integrates with various inference APIs, offers a standardized training interface for experimenting with different RL algorithms, and allows for easy scalability by launching more environment instances. The framework manages diverse environment types concurrently for heterogeneous, multi-modal training.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

anything-llm
AnythingLLM is a full-stack application that enables you to turn any document, resource, or piece of content into context that any LLM can use as references during chatting. This application allows you to pick and choose which LLM or Vector Database you want to use as well as supporting multi-user management and permissions.
ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.

glide
Glide is a cloud-native LLM gateway that provides a unified REST API for accessing various large language models (LLMs) from different providers. It handles LLMOps tasks such as model failover, caching, key management, and more, making it easy to integrate LLMs into applications. Glide supports popular LLM providers like OpenAI, Anthropic, Azure OpenAI, AWS Bedrock (Titan), Cohere, Google Gemini, OctoML, and Ollama. It offers high availability, performance, and observability, and provides SDKs for Python and NodeJS to simplify integration.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.
onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.