Best AI tools for< Analyze Speech Data >
20 - AI tool Sites
Vatis Tech
Vatis Tech is an AI-powered speech-to-text infrastructure that offers transcription software to help teams and individuals streamline their workflow. The platform provides accurate, accessible, and affordable speech-to-text API, caption generator, and audio intelligence solutions. It caters to various industries such as contact centers, broadcasting, medical, legal, media, newsrooms, and more. Vatis Tech's technology is powered by state-of-the-art AI, enabling near-human accuracy in transcribing speech with fast turnaround times. The platform also offers features like real-time transcription, custom AI models, and support for multiple languages.
VoxSigma
Vocapia Research develops leading-edge, multilingual speech processing technologies exploiting AI methods such as machine learning. These technologies enable large vocabulary continuous speech recognition, automatic audio segmentation, language identification, speaker diarization and audio-text synchronization. Vocapia's VoxSigma™ speech-to-text software suite delivers state-of-the-art performance in many languages for a variety of audio data types, including broadcast data, parliamentary hearings and conversational data.
TalkToMe.AI
TalkToMe.AI is a comprehensive platform dedicated to artificial intelligence, offering a wide range of resources for enthusiasts and professionals alike. From interactive quizzes on various AI topics to in-depth articles on machine learning algorithms and neural networks, the website aims to educate and inspire individuals interested in the field of AI. With a focus on demystifying complex concepts and keeping users updated on the latest advancements, TalkToMe.AI serves as a trusted companion for anyone looking to explore the fascinating realm of artificial intelligence.
Prosodica
Prosodica is a contact center analytics platform that uses AI and machine learning to analyze conversational speech behaviors and non-verbal measures to provide a human-like perspective of conversational quality. It helps businesses optimize operations, improve agent performance, and increase customer loyalty.
Aya Data
Aya Data is an AI tool that offers services such as data annotation, computer vision, natural language annotation, 3D annotation, AI data acquisition, and AI consulting. They provide cutting-edge tools to transform raw data into training datasets for AI models, deliver bespoke AI solutions for various industries, and offer AI-powered products like AyaGrow for crop management and AyaSpeech for speech-to-speech translation. Aya Data focuses on exceptional accuracy, rapid development cycles, and high performance in real-world scenarios.
Deepgram
Deepgram is a speech recognition and transcription service that uses artificial intelligence to convert audio into text. It is designed to be accurate, fast, and easy to use. Deepgram offers a variety of features, including: - Automatic speech recognition - Speaker diarization - Language identification - Custom acoustic models - Real-time transcription - Batch transcription - Webhooks - Integrations with popular platforms such as Zoom, Google Meet, and Microsoft Teams

Columns AI
Columns AI is a powerful platform that automates data storytelling through AI technology. It offers seamless data integration, transformation, and professional storytelling capabilities. Users can connect various data sources, transform data into compelling visual narratives, and effortlessly build stunning content with AI-enhanced tools. The platform allows users to share visual stories, schedule automatic updates, and collaborate on data visualization projects. Columns AI simplifies the complexity of data storytelling and empowers users to communicate insights effectively.
AssemblyAI
AssemblyAI is an industry-leading Speech AI tool that offers powerful SpeechAI models for accurate transcription and understanding of speech. It provides breakthrough speech-to-text models, real-time captioning, and advanced speech understanding capabilities. AssemblyAI is designed to help developers build world-class products with unmatched accuracy and transformative audio intelligence.
SpeechMap.AI
SpeechMap.AI is a public research project that explores the boundaries of AI-generated speech. It focuses on testing how language models respond to sensitive and controversial prompts across different providers, countries, and topics. The platform aims to reveal the invisible boundaries of AI speech by analyzing what models avoid, refuse, or shut down. By measuring and comparing AI models' responses, SpeechMap.AI sheds light on the evolving landscape of AI-generated speech and its impact on public expression.
InteliConvo®
InteliConvo® is a state-of-the-art AI-powered speech analytics and automation platform that enables businesses to process and analyze recorded customer conversations. It provides valuable insights into customer buying patterns, intents, sentiments, and feedback, which can be utilized to automate workflows, improve team performance, accelerate sales, enhance debt collections, boost customer experience, and ensure compliance. The platform offers features like multilingual support, flexible deployment options, hot lead identification, debt default prediction, brand building insights, and compliance monitoring.
Deepgram
Deepgram is a powerful API platform that provides developers with tools for building speech-to-text, text-to-speech, and intelligence applications. With Deepgram, developers can easily add speech recognition, text-to-speech, and other AI-powered features to their applications.
ElevateAI by NICE
ElevateAI by NICE is a market-leading AI-powered speech-to-text application that offers transcription models, Generative AI, Enlighten AI, and CX AI features. It provides insights by pairing free Generative AI with NICE's transcription models to uncover hidden insights in data. ElevateAI aims to make AI-powered technology accessible for all, with easy integration, deployment, and user-friendly APIs. The application is designed to help contact centers leverage the power of AI for enhanced customer experiences and innovation.
AssemblyAI
AssemblyAI is an AI tool that provides AI models for transcribing and understanding speech. It offers real-time transcription, speech-to-text, speech understanding, and speech-to-speech capabilities. The platform caters to various use cases such as conversation intelligence, medical transcription, contact centers, and voice agents. AssemblyAI is trusted by top VoiceAI companies for its accurate and fully-featured models, enabling users to build innovative products and experiences with confidence.
Genailia
Genailia is an AI platform that offers a range of products and services such as translation, transcription, chatbot, LLM, GPT, TTS, ASR, and social media insights. It harnesses AI to redefine possibilities by providing generative AI, linguistic interfaces, accelerators, and more in a single platform. The platform aims to streamline various tasks through AI technology, making it a valuable tool for businesses and individuals seeking efficient solutions.
WikeAI
WikeAI is an all-in-one AI platform that offers top models like GPT4, Claude3, Mistral, and Llama3. It provides advanced AI capabilities such as conversation simulation, content generation, and more. Users can experience professional-level cross-model integration and benefit from AI-powered content writing, social media ads creation, and product description generation. WikeAI simplifies the use of AI technology with a one-time payment model, making it accessible and cost-effective. The platform supports various AI models and offers fast content generation, unique and original content, and commercial use rights.
Rev AI
Rev AI is a leading Speech to Text API and Speech Recognition Service provider, offering high accuracy and a wide range of features for audio and video transcription. Their AI models are trained on a diverse collection of voices, setting the standard for accuracy in video and voice applications. With a focus on accuracy, readability, and security, Rev AI provides a comprehensive solution for speech-to-text and natural language processing needs.
AppTek
AppTek is a global leader in artificial intelligence (AI) and machine learning (ML) technologies for automatic speech recognition (ASR), neural machine translation (NMT), natural language processing/understanding (NLP/U) and text-to-speech (TTS) technologies. The AppTek platform delivers industry-leading solutions for organizations across a breadth of global markets such as media and entertainment, call centers, government, enterprise business, and more. Built by scientists and research engineers who are recognized among the best in the world, AppTek’s solutions cover a wide array of languages/ dialects, channels, domains and demographics.
Seasalt.ai
Seasalt.ai is a conversation experience platform that uses generative AI and speech recognition to help businesses communicate with their customers more effectively. It offers a range of products, including SeaX, SeaChat, SeaMeet, and SeaVoice, which can be used for a variety of purposes, such as marketing campaigns, customer service, and sales. Seasalt.ai's mission is to help businesses capture, generate, and understand all text and voice conversations for their business.
WikeAI
WikeAI is an all-in-one AI platform that provides access to top AI models such as GPT-4, Claude3, Mistral, and Llama2. It offers professional-level cross-model integration, allowing users to experience powerful language understanding, speech synthesis, and visual generation technology without switching between multiple systems. WikeAI simplifies the process of using AI for content writing by generating blog articles, product descriptions, social media ads, and more in seconds. The platform offers different pricing plans tailored to various user needs, from casual users to language creators.
AI Sales Assistant and Coach
The AI Sales Assistant and Coach is an innovative tool designed to assist sales professionals in improving their performance and achieving their sales targets. By leveraging artificial intelligence technology, this application provides personalized coaching, real-time insights, and data-driven recommendations to help salespeople enhance their sales strategies and close more deals. With a user-friendly interface and advanced algorithms, the AI Sales Assistant and Coach empowers sales teams to optimize their sales processes, increase productivity, and drive revenue growth.
3 - Open Source AI Tools
AnyGPT
AnyGPT is a unified multimodal language model that utilizes discrete representations for processing various modalities like speech, text, images, and music. It aligns the modalities for intermodal conversions and text processing. AnyInstruct dataset is constructed for generative models. The model proposes a generative training scheme using Next Token Prediction task for training on a Large Language Model (LLM). It aims to compress vast multimodal data on the internet into a single model for emerging capabilities. The tool supports tasks like text-to-image, image captioning, ASR, TTS, text-to-music, and music captioning.
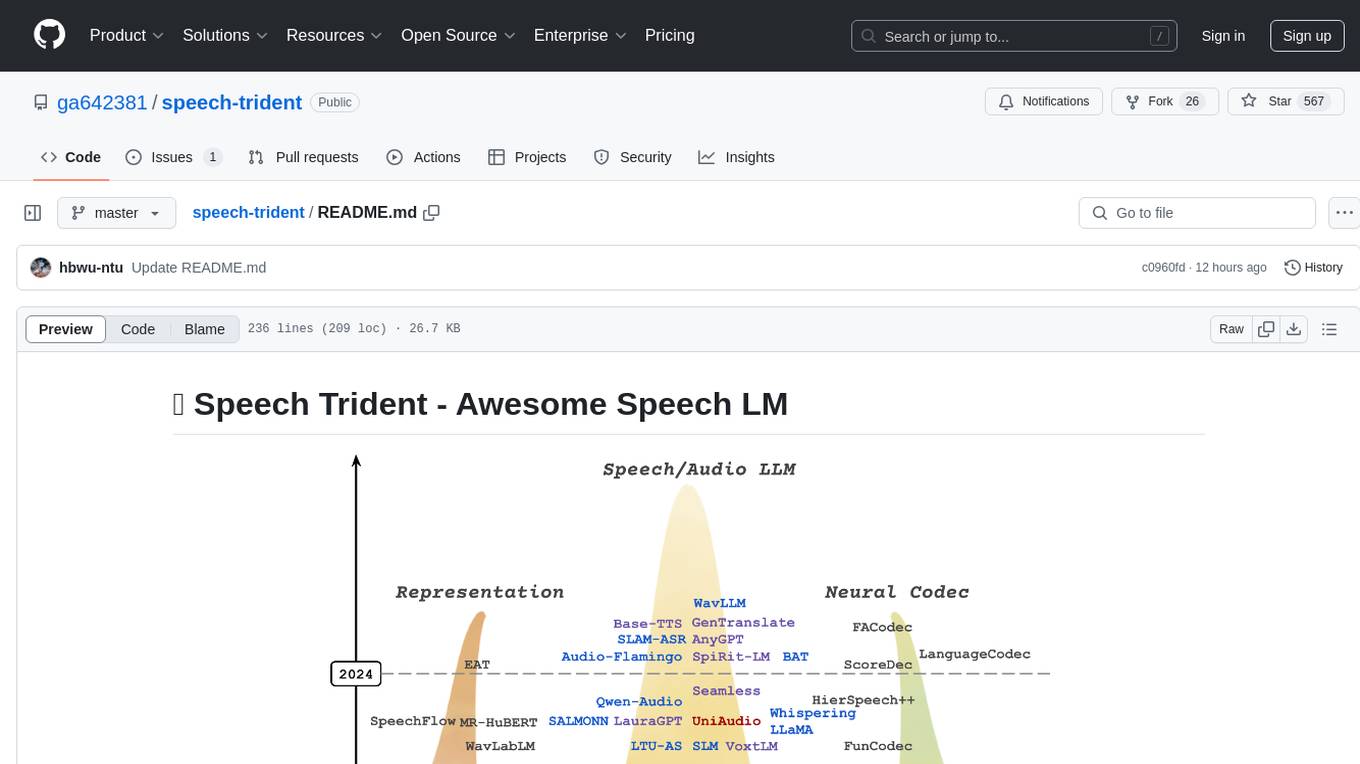
speech-trident
Speech Trident is a repository focusing on speech/audio large language models, covering representation learning, neural codec, and language models. It explores speech representation models, speech neural codec models, and speech large language models. The repository includes contributions from various researchers and provides a comprehensive list of speech/audio language models, representation models, and codec models.

AudioLLM
AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.
20 - OpenAI Gpts
Dialect Detective
Expert in distinguishing language dialects like Castilian vs Latin Spanish, and Parisian vs Canadian French.
AI Speech Guide
A helpful coach for speech writing, offering constructive advice and support

Politik GPT
Asesor político especializado en análisis político, estrategias y redacción de discursos.
Abraham Lincoln
Abe Lincoln with extra wit: analyzes politics, culture, art, and personal matters.

ModiGPT
GPT, drawing inspiration from Narendra Modi, delves into the myriad of government initiatives led by him, alongside insights into his personal journey.
Wowza Bias Detective
I analyze cognitive biases in scenarios and thoughts, providing neutral, educational insights.