
Awesome-LLM4IE-Papers
Awesome papers about generative Information Extraction (IE) using Large Language Models (LLMs)
Stars: 645
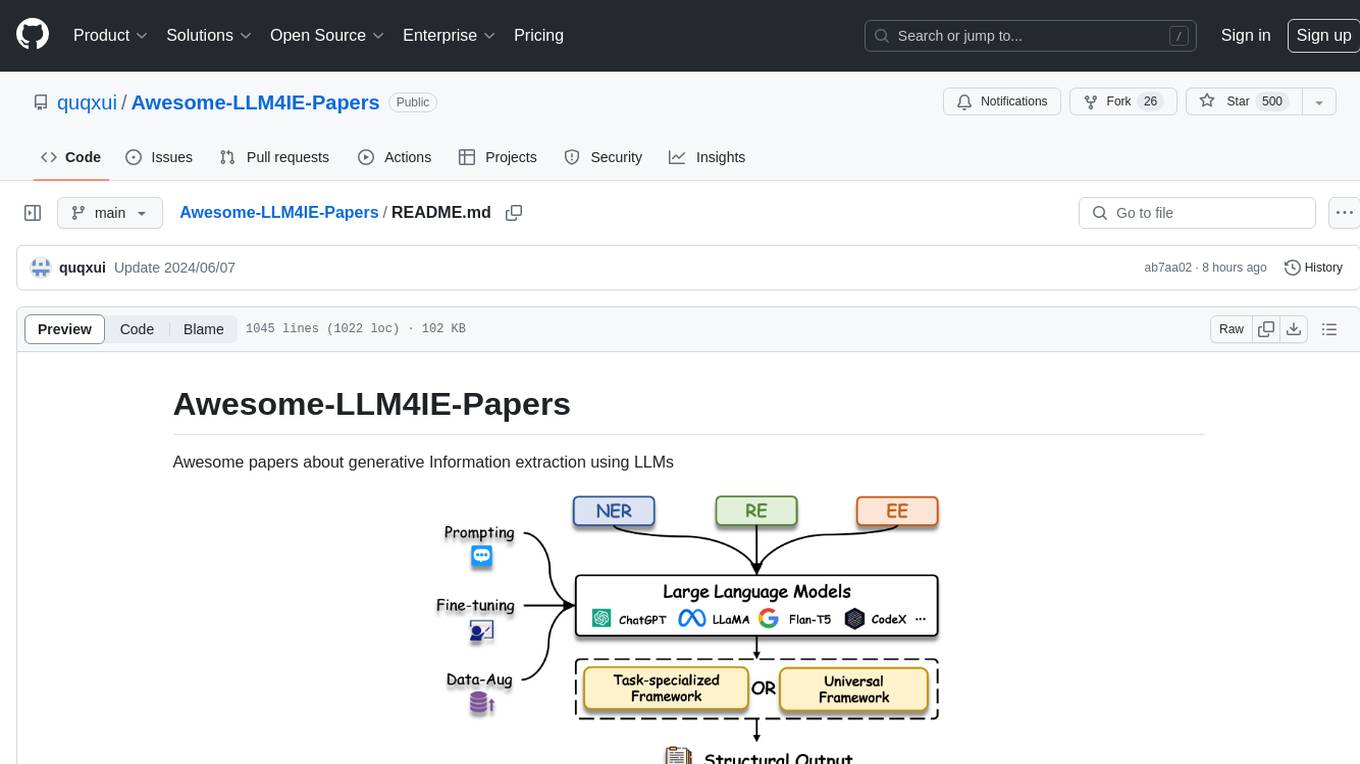
README:
Awesome papers about generative Information extraction using LLMs

The organization of papers is discussed in our survey: Large Language Models for Generative Information Extraction: A Survey.
If you find any relevant academic papers that have not been included in our research, please submit a request for an update. We welcome contributions from everyone.
If any suggestions or mistakes, please feel free to let us know via email at [email protected] and [email protected]. We appreciate your feedback and help in improving our work.
If you find our survey useful for your research, please cite the following paper:
@misc{xu2023large,
title={Large Language Models for Generative Information Extraction: A Survey},
author={Derong Xu and Wei Chen and Wenjun Peng and Chao Zhang and Tong Xu and Xiangyu Zhao and Xian Wu and Yefeng Zheng and Enhong Chen},
year={2023},
eprint={2312.17617},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- Information Extraction tasks
- Information Extraction Techniques
- Specific Domain
- Evaluation and Analysis
- Project and Toolkit
- ⏰ Recently Updated Papers (After 2024/09/04, the updated papers is here~)
- ⭐️ Datasets (with Download Link~)
-
Update Logs
- The details can be find in
./update_new_papers_list. - 2024/09/04 Add 22 papers
- 2024/06/06 Add 41 papers
- 2024/03/30 Add 27 papers
- 2024/03/29 Add 20 papers
- The details can be find in
A taxonomy by various tasks.
Models targeting only ner tasks.
| Paper | Venue | Date | Code |
|---|---|---|---|
| Calibrated Seq2seq Models for Efficient and Generalizable Ultra-fine Entity Typing | EMNLP Findings | 2023-12 | GitHub |
| Generative Entity Typing with Curriculum Learning | EMNLP | 2022-12 | GitHub |
Models targeting only RE tasks.
| Paper | Venue | Date | Code |
|---|---|---|---|
| MetaIE: Distilling a Meta Model from LLM for All Kinds of Information Extraction Tasks | Arxiv | 2024-03 | GitHub |
| Distilling Named Entity Recognition Models for Endangered Species from Large Language Models | Arxiv | 2024-03 | |
| CHisIEC: An Information Extraction Corpus for Ancient Chinese History | COLING | 2024-03 | GitHub |
| An Autoregressive Text-to-Graph Framework for Joint Entity and Relation Extraction | AAAI | 2024-03 | GitHub |
| C-ICL: Contrastive In-context Learning for Information Extraction | Arxiv | 2024-02 | |
| REBEL: Relation Extraction By End-to-end Language generation | EMNLP Findings | 2021-11 | GitHub |
Models targeting only EE tasks.
| Paper | Venue | Date | Code |
|---|---|---|---|
| Improving Event Definition Following For Zero-Shot Event Detection | Arxiv | 2024-03 | |
| Mastering the Task of Open Information Extraction with Large Language Models and Consistent Reasoning Environment | Arxiv | 2023-10 | |
| Unified Text Structuralization with Instruction-tuned Language Models | Arxiv | 2023-03 | |
| Unleash GPT-2 Power for Event Detection | ACL | 2021-08 |
Unified models targeting multiple IE tasks.
A taxonomy by techniques.
| Paper | Venue | Date | Code |
|---|---|---|---|
| Document-level event argument extraction by conditional generation | NAACL | 2021-06 | GitHub |
| Paper | Venue | Date | Code |
|---|---|---|---|
| Knowledge-Enriched Prompt for Low-Resource Named Entity Recognition | TALLIP | 2024-04 | |
| Enhancing Software-Related Information Extraction via Single-Choice Question Answering with Large Language Models | Others | 2024-04 | |
| Revisiting Large Language Models as Zero-shot Relation Extractors | EMNLP Findings | 2023-12 | |
| Aligning Instruction Tasks Unlocks Large Language Models as Zero-Shot Relation Extractors | ACL Findings | 2023-07 | GitHub |
| Zero-Shot Information Extraction via Chatting with ChatGPT | Arxiv | 2023-02 | GitHub |
| Paper | Venue | Date | Code |
|---|---|---|---|
| An Autoregressive Text-to-Graph Framework for Joint Entity and Relation Extraction | AAAI | 2024-03 | GitHub |
| Grammar-Constrained Decoding for Structured NLP Tasks without Finetuning | EMNLP | 2024-01 | GitHub |
| DORE: Document Ordered Relation Extraction based on Generative Framework | EMNLP Findings | 2022-12 | |
| Autoregressive Structured Prediction with Language Models | EMNLP Findings | 2022-12 | GitHub |
| Unified Structure Generation for Universal Information Extraction | ACL | 2022-05 | GitHub |
| Paper | Type | Venue | Date | Link |
|---|---|---|---|---|
| ONEKE | Project | - | - | Link |
| TechGPT-2.0: A Large Language Model Project to Solve the Task of Knowledge Graph Construction | Project | Arxiv | 2024-01 | Link |
| CollabKG: A Learnable Human-Machine-Cooperative Information Extraction Toolkit for (Event) Knowledge Graph Construction | Toolkit | Arxiv | 2023-07 | Link |
* denotes the dataset is multimodal. # refers to the number of categories or sentences.
| Task | Dataset | Domain | #Class | #Train | #Val | #Test | Link |
|---|---|---|---|---|---|---|---|
| NER | ACE04 | News | 7 | 6202 | 745 | 812 | Link |
| ACE05 | News | 7 | 7299 | 971 | 1060 | Link | |
| BC5CDR | Biomedical | 2 | 4560 | 4581 | 4797 | Link | |
| Broad Twitter Corpus | Social Media | 3 | 6338 | 1001 | 2000 | Link | |
| CADEC | Biomedical | 1 | 5340 | 1097 | 1160 | Link | |
| CoNLL03 | News | 4 | 14041 | 3250 | 3453 | Link | |
| CoNLLpp | News | 4 | 14041 | 3250 | 3453 | Link | |
| CrossNER-AI | Artificial Intelligence | 14 | 100 | 350 | 431 | Link | |
| CrossNER-Literature | Literary | 12 | 100 | 400 | 416 | ||
| CrossNER-Music | Musical | 13 | 100 | 380 | 465 | ||
| CrossNER-Politics | Political | 9 | 199 | 540 | 650 | ||
| CrossNER-Science | Scientific | 17 | 200 | 450 | 543 | ||
| FabNER | Scientific | 12 | 9435 | 2182 | 2064 | Link | |
| Few-NERD | General | 66 | 131767 | 18824 | 37468 | Link | |
| FindVehicle | Traffic | 21 | 21565 | 20777 | 20777 | Link | |
| GENIA | Biomedical | 5 | 15023 | 1669 | 1854 | Link | |
| HarveyNER | Social Media | 4 | 3967 | 1301 | 1303 | Link | |
| MIT-Movie | Social Media | 12 | 9774 | 2442 | 2442 | Link | |
| MIT-Restaurant | Social Media | 8 | 7659 | 1520 | 1520 | Link | |
| MultiNERD | Wikipedia | 16 | 134144 | 10000 | 10000 | Link | |
| NCBI | Biomedical | 4 | 5432 | 923 | 940 | Link | |
| OntoNotes 5.0 | General | 18 | 59924 | 8528 | 8262 | Link | |
| ShARe13 | Biomedical | 1 | 8508 | 12050 | 9009 | Link | |
| ShARe14 | Biomedical | 1 | 17404 | 1360 | 15850 | Link | |
| SNAP* | Social Media | 4 | 4290 | 1432 | 1459 | Link | |
| Temporal Twitter Corpus (TTC) | Social Meida | 3 | 10000 | 500 | 1500 | Link | |
| Tweebank-NER | Social Media | 4 | 1639 | 710 | 1201 | Link | |
| Twitter2015* | Social Media | 4 | 4000 | 1000 | 3357 | Link | |
| Twitter2017* | Social Media | 4 | 3373 | 723 | 723 | Link | |
| TwitterNER7 | Social Media | 7 | 7111 | 886 | 576 | Link | |
| WikiDiverse* | News | 13 | 6312 | 755 | 757 | Link | |
| WNUT2017 | Social Media | 6 | 3394 | 1009 | 1287 | Link | |
| RE | ACE05 | News | 7 | 10051 | 2420 | 2050 | Link |
| ADE | Biomedical | 1 | 3417 | 427 | 428 | Link | |
| CoNLL04 | News | 5 | 922 | 231 | 288 | Link | |
| DocRED | Wikipedia | 96 | 3008 | 300 | 700 | Link | |
| MNRE* | Social Media | 23 | 12247 | 1624 | 1614 | Link | |
| NYT | News | 24 | 56196 | 5000 | 5000 | Link | |
| Re-TACRED | News | 40 | 58465 | 19584 | 13418 | Link | |
| SciERC | Scientific | 7 | 1366 | 187 | 397 | Link | |
| SemEval2010 | General | 19 | 6507 | 1493 | 2717 | Link | |
| TACRED | News | 42 | 68124 | 22631 | 15509 | Link | |
| TACREV | News | 42 | 68124 | 22631 | 15509 | Link | |
| EE | ACE05 | News | 33/22 | 17172 | 923 | 832 | Link |
| CASIE | Cybersecurity | 5/26 | 11189 | 1778 | 3208 | Link | |
| GENIA11 | Biomedical | 9/11 | 8730 | 1091 | 1092 | Link | |
| GENIA13 | Biomedical | 13/7 | 4000 | 500 | 500 | Link | |
| PHEE | Biomedical | 2/16 | 2898 | 961 | 968 | Link | |
| RAMS | News | 139/65 | 7329 | 924 | 871 | Link | |
| WikiEvents | Wikipedia | 50/59 | 5262 | 378 | 492 | Link |
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-LLM4IE-Papers
Similar Open Source Tools

AudioLLM
AudioLLMs is a curated collection of research papers focusing on developing, implementing, and evaluating language models for audio data. The repository aims to provide researchers and practitioners with a comprehensive resource to explore the latest advancements in AudioLLMs. It includes models for speech interaction, speech recognition, speech translation, audio generation, and more. Additionally, it covers methodologies like multitask audioLLMs and segment-level Q-Former, as well as evaluation benchmarks like AudioBench and AIR-Bench. Adversarial attacks such as VoiceJailbreak are also discussed.
Awesome-LLM-3D
This repository is a curated list of papers related to 3D tasks empowered by Large Language Models (LLMs). It covers tasks such as 3D understanding, reasoning, generation, and embodied agents. The repository also includes other Foundation Models like CLIP and SAM to provide a comprehensive view of the area. It is actively maintained and updated to showcase the latest advances in the field. Users can find a variety of research papers and projects related to 3D tasks and LLMs in this repository.

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.

LLM-KG4QA
LLM-KG4QA is a repository focused on the integration of Large Language Models (LLMs) and Knowledge Graphs (KGs) for Question Answering (QA). It covers various aspects such as using KGs as background knowledge, reasoning guideline, and refiner/filter. The repository provides detailed information on pre-training, fine-tuning, and Retrieval Augmented Generation (RAG) techniques for enhancing QA performance. It also explores complex QA tasks like Explainable QA, Multi-Modal QA, Multi-Document QA, Multi-Hop QA, Multi-run and Conversational QA, Temporal QA, Multi-domain and Multilingual QA, along with advanced topics like Optimization and Data Management. Additionally, it includes benchmark datasets, industrial and scientific applications, demos, and related surveys in the field.
Cool-GenAI-Fashion-Papers
Cool-GenAI-Fashion-Papers is a curated list of resources related to GenAI-Fashion, including papers, workshops, companies, and products. It covers a wide range of topics such as fashion design synthesis, outfit recommendation, fashion knowledge extraction, trend analysis, and more. The repository provides valuable insights and resources for researchers, industry professionals, and enthusiasts interested in the intersection of AI and fashion.
LLM4EC
LLM4EC is an interdisciplinary research repository focusing on the intersection of Large Language Models (LLM) and Evolutionary Computation (EC). It provides a comprehensive collection of papers and resources exploring various applications, enhancements, and synergies between LLM and EC. The repository covers topics such as LLM-assisted optimization, EA-based LLM architecture search, and applications in code generation, software engineering, neural architecture search, and other generative tasks. The goal is to facilitate research and development in leveraging LLM and EC for innovative solutions in diverse domains.

LLM-Agent-Survey
Autonomous agents are designed to achieve specific objectives through self-guided instructions. With the emergence and growth of large language models (LLMs), there is a growing trend in utilizing LLMs as fundamental controllers for these autonomous agents. This repository conducts a comprehensive survey study on the construction, application, and evaluation of LLM-based autonomous agents. It explores essential components of AI agents, application domains in natural sciences, social sciences, and engineering, and evaluation strategies. The survey aims to be a resource for researchers and practitioners in this rapidly evolving field.

Awesome-Resource-Efficient-LLM-Papers
A curated list of high-quality papers on resource-efficient Large Language Models (LLMs) with a focus on various aspects such as architecture design, pre-training, fine-tuning, inference, system design, and evaluation metrics. The repository covers topics like efficient transformer architectures, non-transformer architectures, memory efficiency, data efficiency, model compression, dynamic acceleration, deployment optimization, support infrastructure, and other related systems. It also provides detailed information on computation metrics, memory metrics, energy metrics, financial cost metrics, network communication metrics, and other metrics relevant to resource-efficient LLMs. The repository includes benchmarks for evaluating the efficiency of NLP models and references for further reading.

open-llms
Open LLMs is a repository containing various Large Language Models licensed for commercial use. It includes models like T5, GPT-NeoX, UL2, Bloom, Cerebras-GPT, Pythia, Dolly, and more. These models are designed for tasks such as transfer learning, language understanding, chatbot development, code generation, and more. The repository provides information on release dates, checkpoints, papers/blogs, parameters, context length, and licenses for each model. Contributions to the repository are welcome, and it serves as a resource for exploring the capabilities of different language models.
LLM-PlayLab
LLM-PlayLab is a repository containing various projects related to LLM (Large Language Models) fine-tuning, generative AI, time-series forecasting, and crash courses. It includes projects for text generation, sentiment analysis, data analysis, chat assistants, image captioning, and more. The repository offers a wide range of tools and resources for exploring and implementing advanced AI techniques.

Awesome-Tabular-LLMs
This repository is a collection of papers on Tabular Large Language Models (LLMs) specialized for processing tabular data. It includes surveys, models, and applications related to table understanding tasks such as Table Question Answering, Table-to-Text, Text-to-SQL, and more. The repository categorizes the papers based on key ideas and provides insights into the advancements in using LLMs for processing diverse tables and fulfilling various tabular tasks based on natural language instructions.
ai-game-development-tools
Here we will keep track of the AI Game Development Tools, including LLM, Agent, Code, Writer, Image, Texture, Shader, 3D Model, Animation, Video, Audio, Music, Singing Voice and Analytics. 🔥 * Tool (AI LLM) * Game (Agent) * Code * Framework * Writer * Image * Texture * Shader * 3D Model * Avatar * Animation * Video * Audio * Music * Singing Voice * Speech * Analytics * Video Tool
Awesome-AgenticLLM-RL-Papers
This repository serves as the official source for the survey paper 'The Landscape of Agentic Reinforcement Learning for LLMs: A Survey'. It provides an extensive overview of various algorithms, methods, and frameworks related to Agentic RL, including detailed information on different families of algorithms, their key mechanisms, objectives, and links to relevant papers and resources. The repository covers a wide range of tasks such as Search & Research Agent, Code Agent, Mathematical Agent, GUI Agent, RL in Vision Agents, RL in Embodied Agents, and RL in Multi-Agent Systems. Additionally, it includes information on environments, frameworks, and methods suitable for different tasks related to Agentic RL and LLMs.