
awesome-khmer-language
A large collection of Khmer language resources. Khmer is a language used by Cambodia.
Stars: 79
Awesome Khmer Language is a comprehensive collection of resources for the Khmer language, including tools, datasets, research papers, projects/models, blogs/slides, and miscellaneous items. It covers a wide range of topics related to Khmer language processing, such as character normalization, word segmentation, part-of-speech tagging, optical character recognition, text-to-speech, and more. The repository aims to support the development of natural language processing applications for the Khmer language by providing a diverse set of resources and tools for researchers and developers.
README:
A large collection of Khmer language resources. Khmer is a language used by Cambodia.
Pull Requests are very welcomed!
- Khmer Characters - The Unicode Standard 15.0
- Khmer Encoding Structure - Unicode
- sillsdev/khmer-character-specification
- Khmer Layout Requirements
- wiki/Khmer_language
- wiki/Khmer_script
- wiki/Romanization_of_Khmer
- http://www.eki.ee/wgrs/rom1_km.pdf
- sillsdev/khmer-normalizer Normalize Khmer strings according to https://www.unicode.org/L2/L2022/22290-khmer-encoding.pdf
- automatic-phonemic-and-phonetic-transcription
- Khmer Word Segmentation - Rina Buoy
- Khmer natural language processing toolkit
- Khmer Limon to Unicode
- seanghay/split-khmer Split Khmer sentence into an array of words.
- seanghay/khmertokenizer
- seanghay/khmerword
- seanghay/khmernumber
- seanghay/khmernormalizer
- khmer-ocr-benchmark-dataset A standardized benchmark dataset for Khmer Optical Character Recognition (OCR) engine.
- Khmer utility functions
- Trey314159/KhmerSyllableReordering
- khmer-dictionary-tools
- nota/split-graphemes
- NextSpell - ពិនិត្យអក្ខរាវិរុទ្ធ, ខ្មែរ OCR, កាត់ពាក្យ
- khmercut A (fast) Khmer word segmentation toolkit.
- Socret360/akara-python AKARA: Open-Source Khmer Spell Checker
- khmer-latin-name-transformer
- native-khmer-g2p
- khmerphonemizer
- kfa A fast Khmer Forced Aligner powered by Wav2Vec2CTC and Phonetisaurus
- sosap(សូរសព្ទ) Python binding for Phonetisaurus
- khmer-unicode-converter Khmer Unicode Converter
- khmerpunctuate Punctuation Restoration for Khmer language
- khmerocr_tools Khmer OCR Synthetic Data Generator
- Socret360/jaws Just Another Word Segmenter (JAWS): A Graph Neural Network Model for Khmer Word Segmentation
- seanghay/khmersegment A Khmer word segmentation tool built for NIPTICT (now CADT) Khmer Word Segmentation CRF model.
- seanghay/khmer-acoustic-model-mfa Train an Acoustic Model for Khmer language with Montreal Forced Aligner
- seanghay/tha Tha (ថា) - A Khmer Text Normalization and Verbalization Toolkit
- seanghay/khmerpronounce Khmer Pronounciation Toolkit
- seanghay/khmer2number A Khmer word to number converter.
- khPOS (Khmer Part-of-Speech) Corpus for Khmer NLP Research and Developments
- ParaCrawl Corpus
- Asian Language Treebank (ALT) Project
- phylypo/segmentation-crf-khmer
- google/language-resources Lexicon, Text normalization and Verbalizer
- Illustrations and recordings for language learning Audio recodings and illustration
- seanghay/khmer-dictionary-44k
- seanghay/km-speech-corpus
- seanghay/bookmebus-reviews
- seanghay/khmer_mpwt_speech
- seanghay/khmer_kheng_info_speech
- seanghay/khmer_grkpp_speech
- High quality TTS data for Khmer
- Google FLEURS Audio Dataset
- mc4 A multilingual colossal, cleaned version of Common Crawl's web crawl corpus
- Khmer LineBreaking Dictionary
- Khmer tesseract-ocr
- Khmerlang Mobile Keyboard data
- Khmer Bible Recordings
- SleukRith Set
- Khmer annotation Annotated Khmer Dataset for Word spotting
- An End-to-End Khmer Optical Character Recognition using Sequence-to-Sequence with Attention
- Khmer Word Search: Challenges, Solutions, and Semantic-Aware Search
- Khmer Text Classification Using Word Embedding and Neural Networks
- Joint Khmer Word Segmentation and Part-of-Speech Tagging Using Deep Learning
- Building WFST based Grapheme to Phoneme Conversion for Khmer
- Query Expansion for Khmer Information Retrieval
- Building a Syllable Database to Solve the Problem of Khmer Word Segmentation
- Khmer Word Segmentation based on Bi-Directional Maximal Matching for Plaintext and Microsoft Word Document
- Khmer printed character recognition using attention-based Seq2Seq network
- Khmer Word Segmentation Using Conditional Random Fields
- A Large-scale Study of Statistical Machine Translation Methods for Khmer Language
- A Rule-based Approach for Khmer Word Extraction
- Khmer Word Segmentation and Out-of-Vocabulary Words Detection Using Collocation Measurement of Repeated Characters Subsequences
- The Standard Khmer vowel system: An acoustic study
- Towards Tokenization and Part-of-Speech Tagging for Khmer: Data and Discussion
- Towards deep learning on speech recognition for Khmer language
- A review of Khmer word segmentation and part-of-speech tagging and an experimental study using bidirectional long short-term memory
- Bi-directional Maximal Matching Algorithm to Segment Khmer Words in Sentence
- Detection and Correction of Homophonous Error Word for Khmer Language
- No Language Left Behind (NLLB)
- Phonological Principles And Automatic Phonemic And Phonetic Transcription Of Khmer Words
- Multi-lingual Transformer Training for Khmer Automatic Speech Recognition
- TriECCC: Trilingual Corpus of the Extraordinary Chambers in the Courts of Cambodia for Speech Recognition and Translation Studies
- Domain and Language Adaptation Using Heterogeneous Datasets for Wav2vec2.0-Based Speech Recognition of Low-Resource Language
- Khmer pronouncing dictionary: standard Khmer and Phnom Penh dialect
- ViTSTR-Transducer: Cross-Attention-Free Vision Transformer Transducer for Scene Text Recognition
- Explainable Connectionist-Temporal-Classification-Based Scene Text Recognition
- Toward a Low-Resource Non-Latin-Complete Baseline: An Exploration of Khmer Optical Character Recognition
- facebookresearch/fairseq/mms Text to Speech and Speech to Text
- Khmer Language Model using ULMFiT
- KHMER WORD SEARCH BASE ON SEMANTIC RELATION
- Khmer Audio Dictionary
- Khmer to IPA Converter
- Khmer Phonemizer
- Khmer Text-to-Speech MMS
- Khmer Part of Speech Tagging with XLM RoBERTa
- Whisper Small Khmer Fine-tuned
- Joint Word Segmentation and POS Tagging in Keras
- Socret360/akara-android
- vitouphy/wav2vec2-xls-r-300m-khmer
- vitouphy/wav2vec2-xls-r-1b-khmer
- Khmer Text Classification
- khmerlang/khmer-text-summarizer
- khmerlang/KhmerWordPrediction
- khmerlang/elasticsearch-analysis-khmerlang
- Khmer Fingerspelling
- isi-nlp/uroman Universal Romanizer
- pisethx/khmer-word-segmentation
- khmer-forced-aligner
- Fast Khmer Dictionary
- SEANLP: Southeast Asia Natural Language Processing
- Khmerlang-Keyboard
- ericvida/khtransliterator
- Khmer Unicode Converter
- chantysothy/KhmerUnicodeConverter
- Pretrained-BERT-model-for-Khmer-language
- Khmer Language Model for Handwritten Text Recognition on Historical Documents
- Khmer Single Word TTS
- SeaLLMs Large Language Models for Southeast Asia
- XLM-RoBERTa-Khmer Training from scratch using Masked Language Modeling task on 5M Khmer sentences or 162M words or 578K unique words for 1M steps. While being smaller than XLM-RoBERTa-Base
- Issues in Khmer syllable validation
- Khmer Machine Learning (ML) Experiment
- Using AI to Generate Khmer Baby Names
- How domnung.com Ranks Khmer News
- Text Classification with scikit-learn on Khmer Documents
- Multi-Class Text Classification on Khmer News Articles
- Word Segmentation of Khmer Text Using Conditional Random Fields
- Khmer Language Model Using ULMFiT (Feb 2020)
- Creating a Khmer Language Model using BERT
- Building a Khmer Spelling Checker
- khmerlang.com
- Khmer word spell correction using BK-Tree data structure and Levenshtein distance
- Introduction to kNN algorithm by experiment on Khmer Handwriting classification using Java 8
- Speech Synthesis and Low Resource Languages
- ការបញ្ចូលអក្សរខ្មែរក្នុងយូនីកូដ ឯកសារឆ្នាំ 1996
- harfbuzz A text shaping engine that supports Khmer language.
- xlm-roberta-base A better BERT with multiligual support.
- mt5-base Google T5 multiligual support.
- byt5-base Google T5 without tokenizer.
- sentencepiece A tool to create a tokenizer
- huggingface/transformers
- tiktoken
- montreal-forced-aligner Accoustic Model & Alignment
- pair_ngram Building Grapheme to Phoneme
- fastText
- Phonetisaurus Building Grapheme to Phoneme
- Compact Language Detector v3 Language Detection tool
Khmer is not a low-resource language.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome-khmer-language
Similar Open Source Tools
awesome-khmer-language
Awesome Khmer Language is a comprehensive collection of resources for the Khmer language, including tools, datasets, research papers, projects/models, blogs/slides, and miscellaneous items. It covers a wide range of topics related to Khmer language processing, such as character normalization, word segmentation, part-of-speech tagging, optical character recognition, text-to-speech, and more. The repository aims to support the development of natural language processing applications for the Khmer language by providing a diverse set of resources and tools for researchers and developers.
DecryptPrompt
This repository does not provide a tool, but rather a collection of resources and strategies for academics in the field of artificial intelligence who are feeling depressed or overwhelmed by the rapid advancements in the field. The resources include articles, blog posts, and other materials that offer advice on how to cope with the challenges of working in a fast-paced and competitive environment.
AI6127
AI6127 is a course focusing on deep neural networks for natural language processing (NLP). It covers core NLP tasks and machine learning models, emphasizing deep learning methods using libraries like Pytorch. The course aims to teach students state-of-the-art techniques for practical NLP problems, including writing, debugging, and training deep neural models. It also explores advancements in NLP such as Transformers and ChatGPT.
VideoLingo
VideoLingo is an all-in-one video translation and localization dubbing tool designed to generate Netflix-level high-quality subtitles. It aims to eliminate stiff machine translation, multiple lines of subtitles, and can even add high-quality dubbing, allowing knowledge from around the world to be shared across language barriers. Through an intuitive Streamlit web interface, the entire process from video link to embedded high-quality bilingual subtitles and even dubbing can be completed with just two clicks, easily creating Netflix-quality localized videos. Key features and functions include using yt-dlp to download videos from Youtube links, using WhisperX for word-level timeline subtitle recognition, using NLP and GPT for subtitle segmentation based on sentence meaning, summarizing intelligent term knowledge base with GPT for context-aware translation, three-step direct translation, reflection, and free translation to eliminate strange machine translation, checking single-line subtitle length and translation quality according to Netflix standards, using GPT-SoVITS for high-quality aligned dubbing, and integrating package for one-click startup and one-click output in streamlit.
awesome-ai-coding
Awesome-AI-Coding is a curated list of AI coding topics, projects, datasets, LLM models, embedding models, papers, blogs, products, startups, and peer awesome lists related to artificial intelligence in coding. It includes tools for code completion, code generation, code documentation, and code search, as well as AI models and techniques for improving developer productivity. The repository also features information on various AI-powered developer tools, copilots, and related resources in the AI coding domain.
ai_all_resources
This repository is a compilation of excellent ML and DL tutorials created by various individuals and organizations. It covers a wide range of topics, including machine learning fundamentals, deep learning, computer vision, natural language processing, reinforcement learning, and more. The resources are organized into categories, making it easy to find the information you need. Whether you're a beginner or an experienced practitioner, you're sure to find something valuable in this repository.
qwen-tts
Qwen-TTS is a versatile text-to-speech service offering multi-voice support for both Chinese and English, including dialects like Beijing, Shanghai, and Sichuan. It provides real-time synthesis, batch processing, smart segmentation, progress tracking, audio playback, and outputs in WAV format. The application features a modern design, intuitive operation, history tracking, and real-time feedback. It also offers technical features like asynchronous processing, error handling, file management, and API documentation.
SLAM-LLM
SLAM-LLM is a deep learning toolkit designed for researchers and developers to train custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). SLAM-LLM features easy extension to new models and tasks, mixed precision training for faster training with less GPU memory, multi-GPU training with data and model parallelism, and flexible configuration based on Hydra and dataclass.
echosharp
EchoSharp is an open-source library designed for near-real-time audio processing, orchestrating different AI models seamlessly for various audio analysis scopes. It focuses on flexibility and performance, allowing near-real-time Transcription and Translation by integrating components for Speech-to-Text and Voice Activity Detection. With interchangeable components, easy orchestration, and first-party components like Whisper.net, SileroVad, OpenAI Whisper, AzureAI SpeechServices, WebRtcVadSharp, Onnx.Whisper, and Onnx.Sherpa, EchoSharp provides efficient audio analysis solutions for developers.

llms-learning
A repository sharing literatures and resources about Large Language Models (LLMs) and beyond. It includes tutorials, notebooks, course assignments, development stages, modeling, inference, training, applications, study, and basics related to LLMs. The repository covers various topics such as language models, transformers, state space models, multi-modal language models, training recipes, applications in autonomous driving, code, math, embodied intelligence, and more. The content is organized by different categories and provides comprehensive information on LLMs and related topics.
LLM-Scratch
LLM-Scratch is a minimal implementation of a GPT-style Large Language Model built from scratch using PyTorch. It utilizes BPE tokenization, multi head self-attention, feed-forward layers, and layer normalization. The model is designed for learning and experimentation purposes, focusing on autoregressive text generation. The codebase is clean, modular, and extensible, with a character-level tokenizer for easy understanding and no external dependencies like BPE or SentencePiece. The model architecture includes token embedding, positional embedding, transformer blocks with masked self-attention, feed-forward network, residual connections, layer normalization, and a language modeling head. Training objective involves next-token prediction using Cross-Entropy Loss and AdamW optimizer, with training data sampled in fixed-length blocks and gradients backpropagated through time. Configuration parameters are centralized for easy experimentation and reproducibility.
GhidrAssist
GhidrAssist is an advanced LLM-powered plugin for interactive reverse engineering assistance in Ghidra. It integrates Large Language Models (LLMs) to provide intelligent assistance for binary exploration and reverse engineering. The tool supports various OpenAI v1-compatible APIs, including local models and cloud providers. Key features include code explanation, interactive chat, custom queries, Graph-RAG knowledge system with semantic knowledge graph, community detection, security feature extraction, semantic graph tab, extended thinking/reasoning control, ReAct agentic mode, MCP integration, function calling, actions tab, RAG (Retrieval Augmented Generation), and RLHF dataset generation. The plugin uses a modular, service-oriented architecture with core services, Graph-RAG backend, data layer, and UI components.
rlhf_thinking_model
This repository is a collection of research notes and resources focusing on training large language models (LLMs) and Reinforcement Learning from Human Feedback (RLHF). It includes methodologies, techniques, and state-of-the-art approaches for optimizing preferences and model alignment in LLM training. The purpose is to serve as a reference for researchers and engineers interested in reinforcement learning, large language models, model alignment, and alternative RL-based methods.
AI-Blueprints
This repository hosts a collection of AI blueprint projects for HP AI Studio, providing end-to-end solutions across key AI domains like data science, machine learning, deep learning, and generative AI. The projects are designed to be plug-and-play, utilizing open-source and hosted models to offer ready-to-use solutions. The repository structure includes projects related to classical machine learning, deep learning applications, generative AI, NGC integration, and troubleshooting guidelines for common issues. Each project is accompanied by detailed descriptions and use cases, showcasing the versatility and applicability of AI technologies in various domains.
RAG-Retrieval
RAG-Retrieval is an end-to-end code repository that provides training, inference, and distillation capabilities for the RAG retrieval model. It supports fine-tuning of various open-source RAG retrieval models, including embedding models, late interactive models, and reranker models. The repository offers a lightweight Python library for calling different RAG ranking models and allows distillation of LLM-based reranker models into bert-based reranker models. It includes features such as support for end-to-end fine-tuning, distillation of large models, advanced algorithms like MRL, multi-GPU training strategy, and a simple code structure for easy modifications.
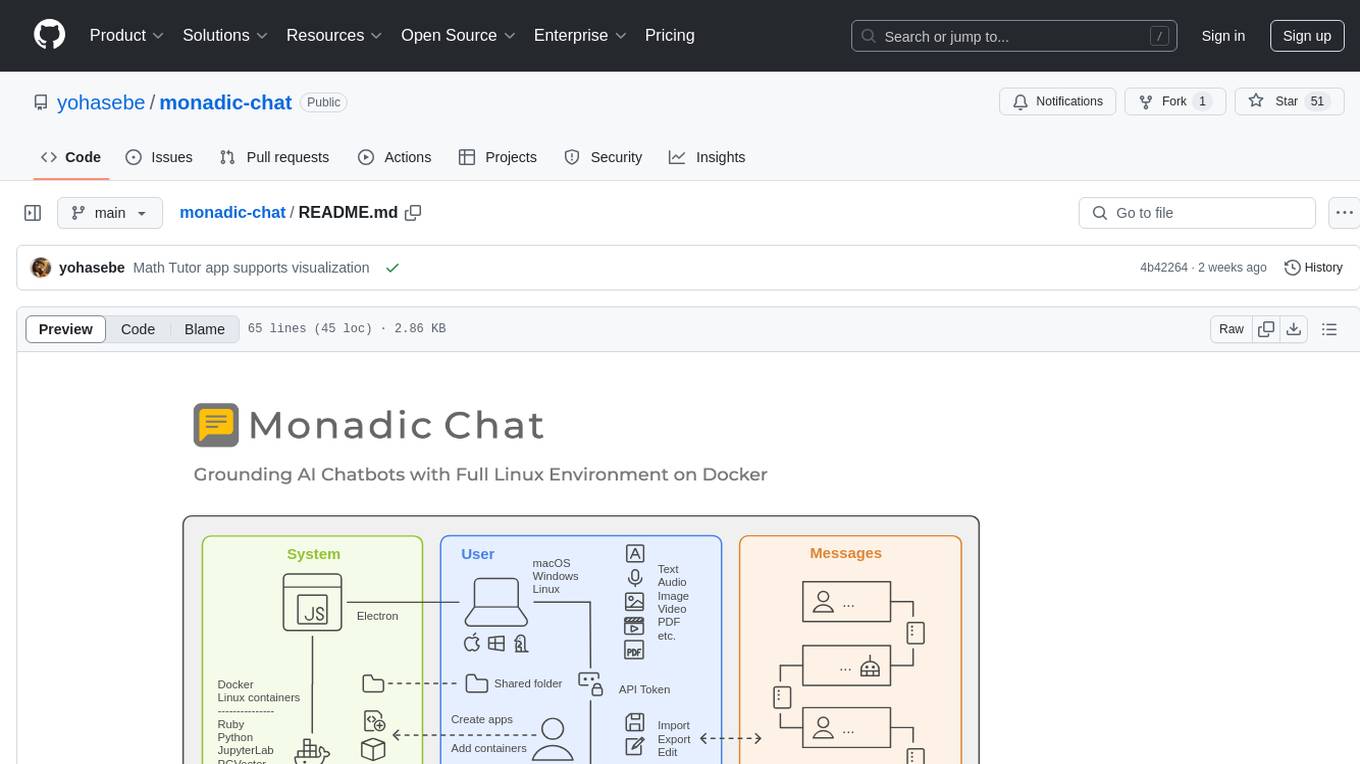
monadic-chat
Monadic Chat is a locally hosted web application designed to create and utilize intelligent chatbots. It provides a Linux environment on Docker to GPT and other LLMs, enabling the execution of advanced tasks that require external tools. The tool supports voice interaction, image and video recognition and generation, and AI-to-AI chat, making it useful for using AI and developing various applications. It is available for Mac, Windows, and Linux (Debian/Ubuntu) with easy-to-use installers.
For similar tasks
awesome-khmer-language
Awesome Khmer Language is a comprehensive collection of resources for the Khmer language, including tools, datasets, research papers, projects/models, blogs/slides, and miscellaneous items. It covers a wide range of topics related to Khmer language processing, such as character normalization, word segmentation, part-of-speech tagging, optical character recognition, text-to-speech, and more. The repository aims to support the development of natural language processing applications for the Khmer language by providing a diverse set of resources and tools for researchers and developers.

EAGLE
Eagle is a family of Vision-Centric High-Resolution Multimodal LLMs that enhance multimodal LLM perception using a mix of vision encoders and various input resolutions. The model features a channel-concatenation-based fusion for vision experts with different architectures and knowledge, supporting up to over 1K input resolution. It excels in resolution-sensitive tasks like optical character recognition and document understanding.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.