
echosharp
EchoSharp is an open-source library designed for near-real-time audio processing, orchestrating different AI models seamlessly for various audio analysis scopes with an architecture that focuses on flexibility and performance,
Stars: 61
EchoSharp is an open-source library designed for near-real-time audio processing, orchestrating different AI models seamlessly for various audio analysis scopes. It focuses on flexibility and performance, allowing near-real-time Transcription and Translation by integrating components for Speech-to-Text and Voice Activity Detection. With interchangeable components, easy orchestration, and first-party components like Whisper.net, SileroVad, OpenAI Whisper, AzureAI SpeechServices, WebRtcVadSharp, Onnx.Whisper, and Onnx.Sherpa, EchoSharp provides efficient audio analysis solutions for developers.
README:
EchoSharp is an open-source library designed for near-real-time audio processing, orchestrating different AI models seamlessly for various audio analysis scopes. With an architecture that focuses on flexibility and performance, EchoSharp allows near-real-time Transcription and Translation by integrating components for Speech-to-Text and Voice Activity Detection.
- Near-Real-Time Audio Processing: Handle audio data with minimal latency, ensuring efficient near-real-time results.
- Interchangeable Components: Customize or extend the library by building your own components for speech-to-text or voice activity detection. EchoSharp exposes flexible interfaces, making integration straightforward.
- Easy Orchestration: Manage and coordinate different AI models effectively for specific audio analysis tasks, like transcribing and detecting speech in various environments.
Get started with EchoSharp and explore how adaptable, near-real-time audio processing can transform your projects.
You can find the latest EchoSharp version on nuget at: EchoSharp
EchoSharp.Whisper.net is a Speech-to-Text (STT) component built on top of Whisper.net, providing high-quality transcription and translation capabilities in a near-real-time setting. Leveraging the state-of-the-art Whisper models from OpenAI, this component ensures robust performance for processing audio input with impressive accuracy across multiple languages. It's designed to be highly efficient and easily interchangeable, allowing developers to customize or extend it with alternative STT components if desired.
Key Features:
- Multilingual Transcription: Supports transcription in multiple languages, with automatic detection and translation capabilities.
- Customizable Integration: Plug-and-play design that integrates seamlessly with EchoSharp's audio orchestration.
- Local Inference: Perform inference locally, ensuring data privacy and reducing latency for near-real-time processing.
EchoSharp.Onnx.SileroVad is a Voice Activity Detection (VAD) component that uses Silero VAD to distinguish between speech and non-speech segments in audio streams. By efficiently detecting voice activity, this component helps manage and optimize audio processing pipelines, activating transcription only when necessary to reduce overhead and improve overall performance.
Key Features:
- Accurate Voice Detection: Reliably identifies when speech is present, even in noisy environments.
- Resource Efficiency: Minimizes unnecessary processing by filtering out silent or irrelevant audio segments.
- Flexible Configuration: Easily adjustable settings to fine-tune voice detection thresholds based on specific use cases.
EchoSharp.OpenAI.Whisper is a Speech-to-Text (STT) component that leverages the OpenAI Whisper API.
Key Features:
- High-Quality Transcription: Utilizes the OpenAI Whisper API to provide accurate and reliable speech-to-text conversion.
- Azure or OpenAI APIs: Choose between Azure or OpenAI APIs for transcription based on your requirements. (just provide the AudioClient from OpenAI SDK or Azure SDK)
- Customizable Integration: Easily integrate with EchoSharp's audio orchestration for seamless audio processing.
EchoSharp.AzureAI.SpeechServices is a Speech-to-Text (STT) component that uses the Azure Speech Services API.
Key Features:
- Azure Speech Services Integration: Leverage the Azure Speech Services API for high-quality speech-to-text conversion.
- Real-Time Transcription: Process audio data in near-real-time with minimal latency.
- Customizable Configuration: Easily adjust settings and parameters to optimize transcription performance.
EchoSharp.WebRtc.WebRtcVadSharp is a Voice Activity Detection (VAD) component that uses the WebRTC VAD and WebRtcVadSharp algorithm to detect voice activity in audio streams. By accurately identifying speech segments, this component helps optimize audio processing pipelines, reducing unnecessary processing and improving overall efficiency.
Key Features:
- Efficient Voice Detection: Detects voice activity with high accuracy, even in noisy environments.
- Resource Optimization: Filters out silent or irrelevant audio segments to minimize processing overhead.
- Flexible Configuration: Easily adjust settings to fine-tune voice detection OperatingMode based on specific use cases.
Experimental - This component is still in development and may not be suitable for production use.
EchoSharp.Onnx.Whisper is a Speech-to-Text (STT) component that uses an ONNX model for speech recognition.
Key Features:
- Customizable Speech Recognition: Utilize your own Whisper ONNX model for speech-to-text conversion.
- Local Inference: Perform speech recognition locally, ensuring data privacy and reducing latency.
- Flexible Integration: Seamlessly integrate with EchoSharp's audio processing pipeline for efficient audio analysis.
EchoSharp.Onnx.Sherpa is a Speech-to-Text (STT) component that uses multiple ONNX models for speech recognition. It integrates with this sherpa-onnx project and supports both OnlineModels and OfflineModels. Key Features:
- Customizable Speech Recognition: Utilize your own ONNX models for speech-to-text conversion.
- Local Inference: Perform speech recognition locally, ensuring data privacy and reducing latency.
- Flexible Integration: Seamlessly integrate with EchoSharp's audio processing pipeline for efficient audio analysis.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for echosharp
Similar Open Source Tools
echosharp
EchoSharp is an open-source library designed for near-real-time audio processing, orchestrating different AI models seamlessly for various audio analysis scopes. It focuses on flexibility and performance, allowing near-real-time Transcription and Translation by integrating components for Speech-to-Text and Voice Activity Detection. With interchangeable components, easy orchestration, and first-party components like Whisper.net, SileroVad, OpenAI Whisper, AzureAI SpeechServices, WebRtcVadSharp, Onnx.Whisper, and Onnx.Sherpa, EchoSharp provides efficient audio analysis solutions for developers.
Linguflex
Linguflex is a project that aims to simulate engaging, authentic, human-like interaction with AI personalities. It offers voice-based conversation with custom characters, alongside an array of practical features such as controlling smart home devices, playing music, searching the internet, fetching emails, displaying current weather information and news, assisting in scheduling, and searching or generating images.
obsidian-llmsider
LLMSider is an AI assistant plugin for Obsidian that offers flexible multi-model support, deep workflow integration, privacy-first design, and a professional tool ecosystem. It provides comprehensive AI capabilities for personal knowledge management, from intelligent writing assistance to complex task automation, making AI a capable assistant for thinking and creating while ensuring data privacy.
AI-Blueprints
This repository hosts a collection of AI blueprint projects for HP AI Studio, providing end-to-end solutions across key AI domains like data science, machine learning, deep learning, and generative AI. The projects are designed to be plug-and-play, utilizing open-source and hosted models to offer ready-to-use solutions. The repository structure includes projects related to classical machine learning, deep learning applications, generative AI, NGC integration, and troubleshooting guidelines for common issues. Each project is accompanied by detailed descriptions and use cases, showcasing the versatility and applicability of AI technologies in various domains.
JamAIBase
JamAI Base is an open-source platform integrating SQLite and LanceDB databases with managed memory and RAG capabilities. It offers built-in LLM, vector embeddings, and reranker orchestration accessible through a spreadsheet-like UI and REST API. Users can transform static tables into dynamic entities, facilitate real-time interactions, manage structured data, and simplify chatbot development. The tool focuses on ease of use, scalability, flexibility, declarative paradigm, and innovative RAG techniques, making complex data operations accessible to users with varying technical expertise.
meeting-minutes
An open-source AI assistant for taking meeting notes that captures live meeting audio, transcribes it in real-time, and generates summaries while ensuring user privacy. Perfect for teams to focus on discussions while automatically capturing and organizing meeting content without external servers or complex infrastructure. Features include modern UI, real-time audio capture, speaker diarization, local processing for privacy, and more. The tool also offers a Rust-based implementation for better performance and native integration, with features like live transcription, speaker diarization, and a rich text editor for notes. Future plans include database connection for saving meeting minutes, improving summarization quality, and adding download options for meeting transcriptions and summaries. The backend supports multiple LLM providers through a unified interface, with configurations for Anthropic, Groq, and Ollama models. System architecture includes core components like audio capture service, transcription engine, LLM orchestrator, data services, and API layer. Prerequisites for setup include Node.js, Python, FFmpeg, and Rust. Development guidelines emphasize project structure, testing, documentation, type hints, and ESLint configuration. Contributions are welcome under the MIT License.
veScale
veScale is a PyTorch Native LLM Training Framework. It provides a set of tools and components to facilitate the training of large language models (LLMs) using PyTorch. veScale includes features such as 4D parallelism, fast checkpointing, and a CUDA event monitor. It is designed to be scalable and efficient, and it can be used to train LLMs on a variety of hardware platforms.

siiRL
siiRL is a novel, fully distributed reinforcement learning (RL) framework designed to break the scaling barriers in Large Language Models (LLMs) post-training. Developed by researchers from Shanghai Innovation Institute, siiRL delivers near-linear scalability, dramatic throughput gains, and unprecedented flexibility for RL-based LLM development. It eliminates the centralized controller common in other frameworks, enabling scalability to thousands of GPUs, achieving state-of-the-art throughput, and supporting cross-hardware compatibility. siiRL is extensively benchmarked and excels in data-intensive workloads such as long-context and multi-modal training.

ChatFAQ
ChatFAQ is an open-source comprehensive platform for creating a wide variety of chatbots: generic ones, business-trained, or even capable of redirecting requests to human operators. It includes a specialized NLP/NLG engine based on a RAG architecture and customized chat widgets, ensuring a tailored experience for users and avoiding vendor lock-in.

trustgraph
TrustGraph is a tool that deploys private GraphRAG pipelines to build a RDF style knowledge graph from data, enabling accurate and secure `RAG` requests compatible with cloud LLMs and open-source SLMs. It showcases the reliability and efficiencies of GraphRAG algorithms, capturing contextual language flags missed in conventional RAG approaches. The tool offers features like PDF decoding, text chunking, inference of various LMs, RDF-aligned Knowledge Graph extraction, and more. TrustGraph is designed to be modular, supporting multiple Language Models and environments, with a plug'n'play architecture for easy customization.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.
intellij-aicoder
AI Coding Assistant is a free and open-source IntelliJ plugin that leverages cutting-edge Language Model APIs to enhance developers' coding experience. It seamlessly integrates with various leading LLM APIs, offers an intuitive toolbar UI, and allows granular control over API requests. With features like Code & Patch Chat, Planning with AI Agents, Markdown visualization, and versatile text processing capabilities, this tool aims to streamline coding workflows and boost productivity.

OAD
OAD is a powerful open-source tool for analyzing and visualizing data. It provides a user-friendly interface for exploring datasets, generating insights, and creating interactive visualizations. With OAD, users can easily import data from various sources, clean and preprocess data, perform statistical analysis, and create customizable visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, OAD can help you streamline your data analysis workflow and uncover valuable insights from your data.
refact-vscode
Refact.ai is an open-source AI coding assistant that boosts developer's productivity. It supports 25+ programming languages and offers features like code completion, AI Toolbox for code explanation and refactoring, integrated in-IDE chat, and self-hosting or cloud version. The Enterprise plan provides enhanced customization, security, fine-tuning, user statistics, efficient inference, priority support, and access to 20+ LLMs for up to 50 engineers per GPU.
llm_benchmarks
llm_benchmarks is a collection of benchmarks and datasets for evaluating Large Language Models (LLMs). It includes various tasks and datasets to assess LLMs' knowledge, reasoning, language understanding, and conversational abilities. The repository aims to provide comprehensive evaluation resources for LLMs across different domains and applications, such as education, healthcare, content moderation, coding, and conversational AI. Researchers and developers can leverage these benchmarks to test and improve the performance of LLMs in various real-world scenarios.

eole
EOLE is an open language modeling toolkit based on PyTorch. It aims to provide a research-friendly approach with a comprehensive yet compact and modular codebase for experimenting with various types of language models. The toolkit includes features such as versatile training and inference, dynamic data transforms, comprehensive large language model support, advanced quantization, efficient finetuning, flexible inference, and tensor parallelism. EOLE is a work in progress with ongoing enhancements in configuration management, command line entry points, reproducible recipes, core API simplification, and plans for further simplification, refactoring, inference server development, additional recipes, documentation enhancement, test coverage improvement, logging enhancements, and broader model support.
For similar tasks
ai-chatbot
Next.js AI Chatbot is an open-source app template for building AI chatbots using Next.js, Vercel AI SDK, OpenAI, and Vercel KV. It includes features like Next.js App Router, React Server Components, Vercel AI SDK for streaming chat UI, support for various AI models, Tailwind CSS styling, Radix UI for headless components, chat history management, rate limiting, session storage with Vercel KV, and authentication with NextAuth.js. The template allows easy deployment to Vercel and customization of AI model providers.
web-llm-chat
WebLLM Chat is a private AI chat interface that combines WebLLM with a user-friendly design, leveraging WebGPU to run large language models natively in your browser. It offers browser-native AI experience with WebGPU acceleration, guaranteed privacy as all data processing happens locally, offline accessibility, user-friendly interface with markdown support, and open-source customization. The project aims to democratize AI technology by making powerful tools accessible directly to end-users, enhancing the chatting experience and broadening the scope for deployment of self-hosted and customizable language models.
echosharp
EchoSharp is an open-source library designed for near-real-time audio processing, orchestrating different AI models seamlessly for various audio analysis scopes. It focuses on flexibility and performance, allowing near-real-time Transcription and Translation by integrating components for Speech-to-Text and Voice Activity Detection. With interchangeable components, easy orchestration, and first-party components like Whisper.net, SileroVad, OpenAI Whisper, AzureAI SpeechServices, WebRtcVadSharp, Onnx.Whisper, and Onnx.Sherpa, EchoSharp provides efficient audio analysis solutions for developers.
Open-WebUI-Functions
Open-WebUI-Functions is a collection of Python-based functions that extend Open WebUI with custom pipelines, filters, and integrations. Users can interact with AI models, process data efficiently, and customize the Open WebUI experience. It includes features like custom pipelines, data processing filters, Azure AI support, N8N workflow integration, flexible configuration, secure API key management, and support for both streaming and non-streaming processing. The functions require an active Open WebUI instance, may need external AI services like Azure AI, and admin access for installation. Security features include automatic encryption of sensitive information like API keys. Pipelines include Azure AI Foundry, N8N, Infomaniak, and Google Gemini. Filters like Time Token Tracker measure response time and token usage. Integrations with Azure AI, N8N, Infomaniak, and Google are supported. Contributions are welcome, and the project is licensed under Apache License 2.0.

VoiceStreamAI
VoiceStreamAI is a Python 3-based server and JavaScript client solution for near-realtime audio streaming and transcription using WebSocket. It employs Huggingface's Voice Activity Detection (VAD) and OpenAI's Whisper model for accurate speech recognition. The system features real-time audio streaming, modular design for easy integration of VAD and ASR technologies, customizable audio chunk processing strategies, support for multilingual transcription, and secure sockets support. It uses a factory and strategy pattern implementation for flexible component management and provides a unit testing framework for robust development.
RealtimeSTT_LLM_TTS
RealtimeSTT is an easy-to-use, low-latency speech-to-text library for realtime applications. It listens to the microphone and transcribes voice into text, making it ideal for voice assistants and applications requiring fast and precise speech-to-text conversion. The library utilizes Voice Activity Detection, Realtime Transcription, and Wake Word Activation features. It supports GPU-accelerated transcription using PyTorch with CUDA support. RealtimeSTT offers various customization options for different parameters to enhance user experience and performance. The library is designed to provide a seamless experience for developers integrating speech-to-text functionality into their applications.
speech-to-speech
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.
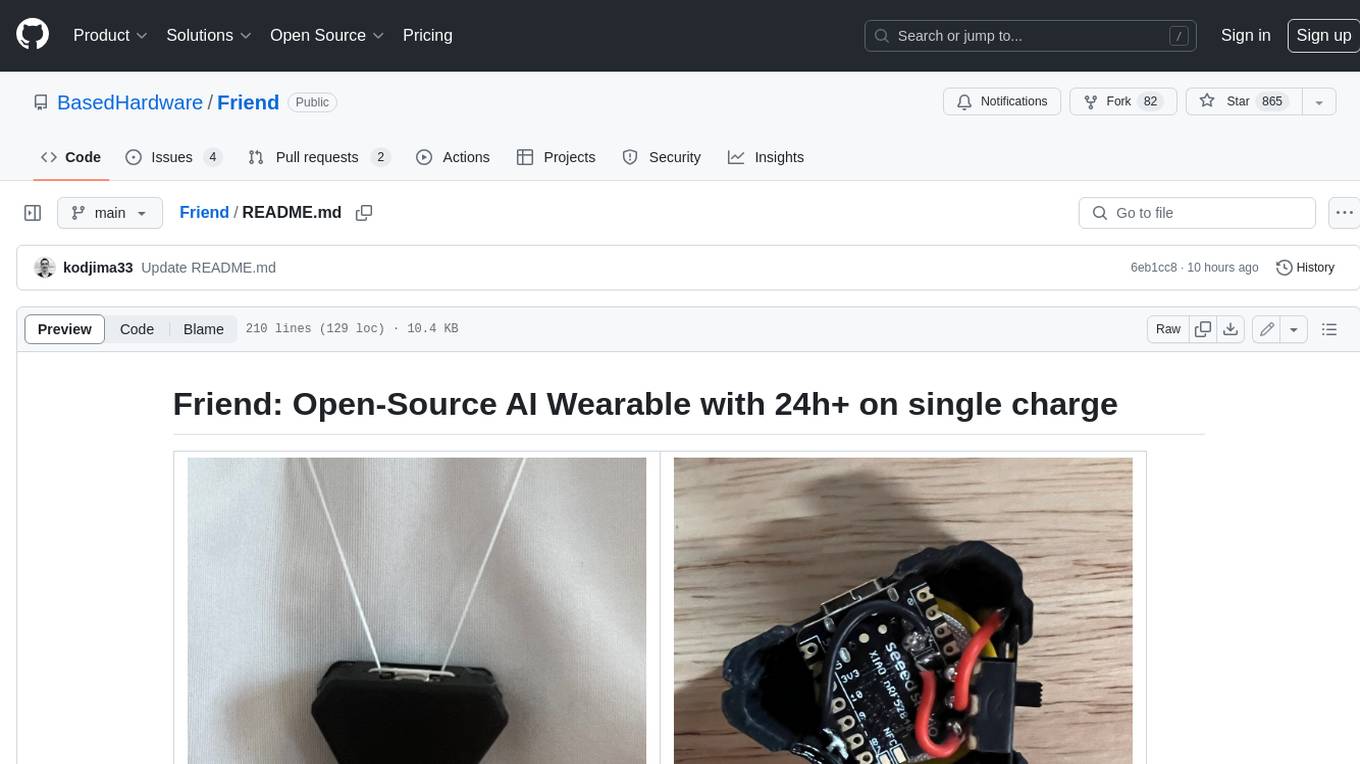
Friend
Friend is an open-source AI wearable device that records everything you say, gives you proactive feedback and advice. It has real-time AI audio processing capabilities, low-powered Bluetooth, open-source software, and a wearable design. The device is designed to be affordable and easy to use, with a total cost of less than $20. To get started, you can clone the repo, choose the version of the app you want to install, and follow the instructions for installing the firmware and assembling the device. Friend is still a prototype project and is provided "as is", without warranty of any kind. Use of the device should comply with all local laws and regulations concerning privacy and data protection.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.