
LLM-in-Vision
Recent LLM-based CV and related works. Welcome to comment/contribute!
Stars: 743
Recent LLM (Large Language Models)-based CV and multi-modal works.
README:
Recent LLM (Large Language Models)-based CV and multi-modal works. Welcome to comment/contribute!
-
(arXiv 2024.5) Self-supervised Pre-training for Transferable Multi-modal Perception, [Paper]
-
(arXiv 2024.5) Multi-modal Generation via Cross-Modal In-Context Learning, [Paper]
-
(arXiv 2024.5) RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots, [Paper], [Project]
-
(arXiv 2024.5) Unveiling the Tapestry of Consistency in Large Vision-Language Models, [Paper]
-
(arXiv 2024.5) Dense Connector for MLLMs, [Paper], [Project]
-
(arXiv 2024.5) Adapting Multi-modal Large Language Model to Concept Drift in the Long-tailed Open World, [Paper], [Project]
-
(arXiv 2024.5) VTG-LLM: INTEGRATING TIMESTAMP KNOWLEDGE INTO VIDEO LLMS FOR ENHANCED VIDEO TEMPORAL GROUNDING, [Paper], [Project]
-
(arXiv 2024.5) Calibrated Self-Rewarding Vision Language Models, [Paper], [Project]
-
(arXiv 2024.5) From Text to Pixel: Advancing Long-Context Understanding in MLLMs, [Paper], [Project]
-
(arXiv 2024.5) Explaining Multi-modal Large Language Models by Analyzing their Vision Perception, [Paper]
-
(arXiv 2024.5) Octopi: Object Property Reasoning with Large Tactile-Language Models, [Paper], [Project]
-
(arXiv 2024.5) Auto-Encoding Morph-Tokens for Multimodal LLM, [Paper], [Project]
-
(arXiv 2024.5) What matters when building vision-language models? [Paper]
-
(arXiv 2024.4) VITRON: A Unified Pixel-level Vision LLM for Understanding, Generating, Segmenting, Editing, [Paper], [Project]
-
(arXiv 2024.4) GROUNDHOG: Grounding Large Language Models to Holistic Segmentation, [Paper], [Project]
-
(arXiv 2024.4) Hallucination of Multimodal Large Language Models: A Survey, [Paper], [Project]
-
(arXiv 2024.4) PLLaVA: Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning, [Paper], [Project]
-
(arXiv 2024.4) MovieChat+: Question-aware Sparse Memory for Long Video Question Answering, [Paper], [Project]
-
(arXiv 2024.4) Exploring the Distinctiveness and Fidelity of the Descriptions Generated by Large Vision-Language Models, [Paper], [Project]
-
(arXiv 2024.4) A Survey on the Memory Mechanism of Large Language Model based Agents, [Paper]
-
(arXiv 2024.4) Energy-Latency Manipulation of Multi-modal Large Language Models via Verbose Samples, [Paper]
-
(arXiv 2024.4) A Multimodal Automated Interpretability Agent, [Paper], [Project]
-
(arXiv 2024.4) Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models, [Paper], [Project]
-
(arXiv 2024.4) TextSquare: Scaling up Text-Centric Visual Instruction Tuning, [Paper]
-
(arXiv 2024.4) What Makes Multimodal In-Context Learning Work?, [Paper]
-
(arXiv 2024.4) ImplicitAVE: An Open-Source Dataset and Multimodal LLMs Benchmark for Implicit Attribute Value Extraction, [Paper], [Project]
-
(arXiv 2024.4) Wiki-LLaVA: Hierarchical Retrieval-Augmented Generation for Multimodal LLMs, [Paper]
-
(arXiv 2024.4) Seeing Beyond Classes: Zero-Shot Grounded Situation Recognition via Language Explainer, [Paper]
-
(arXiv 2024.4) MMT-Bench: A Comprehensive Multimodal Benchmark for Evaluating Large Vision-Language Models Towards Multitask AGI, [Paper]
-
(arXiv 2024.4) Cantor: Inspiring Multimodal Chain-of-Thought of MLLM, [Paper], [Project]
-
(arXiv 2024.4) Make-it-Real: Unleashing Large Multimodal Model’s Ability for Painting 3D Objects with Realistic Materials, [Paper], [Project]
-
(arXiv 2024.4) How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites, [Paper], [Project]
-
(arXiv 2024.4) Revisiting Text-to-Image Evaluation with Gecko: On Metrics, Prompts, and Human Ratings, [Paper], [Project]
-
(arXiv 2024.4) SEED-Bench-2-Plus: Benchmarking Multimodal Large Language Models with Text-Rich Visual Comprehension, [Paper], [Project]
-
(arXiv 2024.4) List Items One by One: A New Data Source and Learning Paradigm for Multimodal LLMs, [Paper], [Project]
-
(arXiv 2024.4) Step Differences in Instructional Video, [Paper]
-
(arXiv 2024.4) A Survey on Generative AI and LLM for Video Generation, Understanding, and Streaming, [Paper]
-
(arXiv 2024.4) TextSquare: Scaling up Text-Centric Visual Instruction Tuning, [Paper]
-
(arXiv 2024.4) Pre-trained Vision-Language Models Learn Discoverable Visual Concepts, [Paper], [Project]
-
(arXiv 2024.4) MoVA: Adapting Mixture of Vision Experts to Multimodal Context, [Paper], [Project]
-
(arXiv 2024.4) Uni3DR^2: Unified Scene Representation and Reconstruction for 3D Large Language Models, [Paper], [Project]
-
(arXiv 2024.4) Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models, [Paper], [Project]
-
(arXiv 2024.4) Eyes Can Deceive: Benchmarking Counterfactual Reasoning Capabilities of Multimodal Large Language Models, [Paper]
-
(arXiv 2024.4) Empowering Large Language Models on Robotic Manipulation with Affordance Prompting, [Paper]
-
(arXiv 2024.4) Prescribing the Right Remedy: Mitigating Hallucinations in Large Vision-Language Models via Targeted Instruction Tuning, [Paper]
-
(arXiv 2024.4) OVAL-Prompt: Open-Vocabulary Affordance Localization for Robot Manipulation through LLM Affordance-Grounding, [Paper]
-
(arXiv 2024.4) FoundationGrasp: Generalizable Task-Oriented Grasping with Foundation Models, [Paper], [Project]
-
(arXiv 2024.4) Towards Human Awareness in Robot Task Planning with Large Language Models, [Paper]
-
(arXiv 2024.4) Self-Supervised Visual Preference Alignment, [Paper]
-
(arXiv 2024.4) Consistency and Uncertainty: Identifying Unreliable Responses From Black-Box Vision-Language Models for Selective Visual Question Answering, [Paper]
-
(arXiv 2024.4) COMBO: Compositional World Models for Embodied Multi-Agent Cooperation, [Paper], [Project]
-
(arXiv 2024.4) Octopus v3: Technical Report for On-device Sub-billion Multimodal AI Agent, [Paper]
-
(arXiv 2024.4) Fact:Teaching MLLMs with Faithful, Concise and Transferable Rationales, [Paper]
-
(arXiv 2024.4) Exploring the Transferability of Visual Prompting for Multimodal Large Language Models, [Paper]
-
(arXiv 2024.4) TextHawk: Exploring Efficient Fine-Grained Perception of Multimodal Large Language Models, [Paper], [Project]
-
(arXiv 2024.4) EIVEN: Efficient Implicit Attribute Value Extraction using Multimodal LLM, [Paper]
-
(arXiv 2024.4) BRIDGING VISION AND LANGUAGE SPACES WITH ASSIGNMENT PREDICTION, [Paper]
-
(arXiv 2024.4) TextCoT: Zoom In for Enhanced Multimodal Text-Rich Image Understanding, [Paper], [Project]
-
(arXiv 2024.4) HOI-Ref: Hand-Object Interaction Referral in Egocentric Vision, [Paper], [Project]
-
(arXiv 2024.4) MMInA: Benchmarking Multihop Multimodal Internet Agents, [Paper], [Project]
-
(arXiv 2024.4) Evolving Interpretable Visual Classifiers with Large Language Models, [Paper]
-
(arXiv 2024.4) OSWORLD: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments, [Paper], [Project]
-
(arXiv 2024.4) Reflectance Estimation for Proximity Sensing by Vision-Language Models: Utilizing Distributional Semantics for Low-Level Cognition in Robotics, [Paper]
-
(arXiv 2024.4) Sketch-Plan-Generalize: Continual Few-Shot Learning of Inductively Generalizable Spatial Concepts for Language-Guided Robot Manipulation, [Paper]
-
(arXiv 2024.4) MORPHeus: a Multimodal One-armed Robot-assisted Peeling System with Human Users In-the-loop, [Paper], [Project]
-
(arXiv 2024.4) GenCHiP: Generating Robot Policy Code for High-Precision and Contact-Rich Manipulation Tasks, [Paper], [Project]
-
(arXiv 2024.4) Exploring the Potential of Large Foundation Models for Open-Vocabulary HOI Detection, [Paper], [Project]
-
(arXiv 2024.3) AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling, [Paper], [Project]
-
(arXiv 2024.3) OCTAVIUS: MITIGATING TASK INTERFERENCE IN MLLMS VIA LORA-MOE, [Paper], [Project]
-
(arXiv 2024.3) INSTRUCTCV: INSTRUCTION-TUNED TEXT-TO-IMAGE DIFFUSION MODELS AS VISION GENERALISTS, [Paper], [Project]
-
(arXiv 2024.3) Embodied Multi-Modal Agent trained by an LLM from a Parallel TextWorld, [Paper], [Project]
-
(arXiv 2024.3) ManipVQA: Injecting Robotic Affordance and Physically Grounded Information into Multi-Modal Large Language Models, [Paper], [Project]
-
(arXiv 2024.3) MineDreamer: Learning to Follow Instructions via Chain-of-Imagination for Simulated-World Control, [Paper], [Project]
-
(arXiv 2024.3) LEGO: Learning EGOcentric Action Frame Generation via Visual Instruction Tuning, [Paper], [Project]
-
(arXiv 2024.3) RAIL: Robot Affordance Imagination with Large Language Models, [Paper]
-
(arXiv 2024.3) Are We on the Right Way for Evaluating Large Vision-Language Models? [Paper], [Project]
-
(arXiv 2024.3) FSMR: A Feature Swapping Multi-modal Reasoning Approach with Joint Textual and Visual Clues, [Paper], [Project]
-
(arXiv 2024.3) Unsolvable Problem Detection: Evaluating Trustworthiness of Vision Language Models, [Paper], [Project]
-
(arXiv 2024.3) OAKINK2 : A Dataset of Bimanual Hands-Object Manipulation in Complex Task Completion, [Paper], [Project]
-
(arXiv 2024.3) InterDreamer: Zero-Shot Text to 3D Dynamic Human-Object Interaction, [Paper], [Project]
-
(arXiv 2024.3) MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training, [Paper]
-
(arXiv 2024.3) Mini-Gemini: Mining the Potential of Multi-modality Vision Language Models, [Paper], [Project]
-
(arXiv 2024.3) INSIGHT: End-to-End Neuro-Symbolic Visual Reinforcement Learning with Language Explanations, [Paper]
-
(arXiv 2024.3) DetToolChain: A New Prompting Paradigm to Unleash Detection Ability of MLLM, [Paper]
-
(arXiv 2024.3) Embodied LLM Agents Learn to Cooperate in Organized Teams, [Paper]
-
(arXiv 2024.3) To Help or Not to Help: LLM-based Attentive Support for Human-Robot Group Interactions, [Paper], [Project]
-
(arXiv 2024.3) BTGenBot: Behavior Tree Generation for Robotic Tasks with Lightweight LLMs, [Paper]
-
(arXiv 2024.3) Chain-of-Spot: Interactive Reasoning Improves Large Vision-Language Models, [Paper], [Project]
-
(arXiv 2024.3) HYDRA: A Hyper Agent for Dynamic Compositional Visual Reasoning, [Paper], [Project]
-
(arXiv 2024.3) RelationVLM: Making Large Vision-Language Models Understand Visual Relations, [Paper]
-
(arXiv 2024.3) Towards Multimodal In-Context Learning for Vision & Language Models, [Paper]
-
(arXiv 2024.3) Images are Achilles’ Heel of Alignment: Exploiting Visual Vulnerabilities for Jailbreaking Multimodal Large Language Models, [Paper]
-
(arXiv 2024.3) HawkEye: Training Video-Text LLMs for Grounding Text in Videos, [Paper], [Project]
-
(arXiv 2024.3) UniCode: Learning a Unified Codebook for Multimodal Large Language Models, [Paper]
-
(arXiv 2024.3) Lumen: Unleashing Versatile Vision-Centric Capabilities of Large Multimodal Models, [Paper], [Project]
-
(arXiv 2024.3) MoAI: Mixture of All Intelligence for Large Language and Vision Models, [Paper], [Project]
-
(arXiv 2024.3) Multi-modal Auto-regressive Modeling via Visual Words, [Paper], [Project]
-
(arXiv 2024.3) DeepSeek-VL: Towards Real-World Vision-Language Understanding, [Paper], [Project]
-
(arXiv 2024.3) Debiasing Large Visual Language Models, [Paper], [Project]
-
(arXiv 2024.2) MOSAIC: A Modular System for Assistive and Interactive Cooking, [Paper], [Project]
-
(arXiv 2024.2) Visual Hallucinations of Multi-modal Large Language Models, [Paper], [Project]
-
(arXiv 2024.2) DualFocus: Integrating Macro and Micro Perspectives in Multi-modal Large Language Models, [Paper], [Project]
-
(arXiv 2024.2) RoboScript: Code Generation for Free-Form Manipulation Tasks across Real and Simulation, [Paper]
-
(arXiv 2024.2) TinyLLaVA: A Framework of Small-scale Large Multimodal Models, [Paper], [Project]
-
(arXiv 2024.2) Enhancing Robotic Manipulation with AI Feedback from Multimodal Large Language Models, [Paper]
-
(arXiv 2024.2) Uncertainty-Aware Evaluation for Vision-Language Models, [Paper], [Project]
-
(arXiv 2024.2) RealDex: Towards Human-like Grasping for Robotic Dexterous Hand, [Paper]
-
(arXiv 2024.2) Aligning Modalities in Vision Large Language Models via Preference Fine-tuning, [Paper], [Project]
-
(arXiv 2024.2) Open3DSG: Open-Vocabulary 3D Scene Graphs from Point Clouds with Queryable Objects and Open-Set Relationships, [Paper]
-
(arXiv 2024.2) ChartX & ChartVLM: A Versatile Benchmark and Foundation Model for Complicated Chart Reasoning, [Paper], [Project]
-
(arXiv 2024.2) LVCHAT: Facilitating Long Video Comprehension, [Paper], [Project]
-
(arXiv 2024.2) Scaffolding Coordinates to Promote Vision-Language Coordination in Large Multi-Modal Models, [Paper], [Project]
-
(arXiv 2024.2) Using Left and Right Brains Together: Towards Vision and Language Planning, [Paper]
-
(arXiv 2024.2) Question-Instructed Visual Descriptions for Zero-Shot Video Question Answering, [Paper]
-
(arXiv 2024.2) PaLM2-VAdapter: Progressively Aligned Language Model Makes a Strong Vision-language Adapter, [Paper]
-
(arXiv 2024.2) Grounding LLMs For Robot Task Planning Using Closed-loop State Feedback, [Paper]
-
(arXiv 2024.2) BBSEA: An Exploration of Brain-Body Synchronization for Embodied Agents, [Paper], [Project]
-
(arXiv 2024.2) Reasoning Grasping via Multimodal Large Language Model, [Paper]
-
(arXiv 2024.2) LOTA-BENCH: BENCHMARKING LANGUAGE-ORIENTED TASK PLANNERS FOR EMBODIED AGENTS, [Paper], [Project]
-
(arXiv 2024.2) OS-COPILOT: TOWARDS GENERALIST COMPUTER AGENTS WITH SELF-IMPROVEMENT, [Paper], [Project]
-
(arXiv 2024.2) Doing Experiments and Revising Rules with Natural Language and Probabilistic Reasoning, [Paper]
-
(arXiv 2024.2) Preference-Conditioned Language-Guided Abstraction, [Paper]
-
(arXiv 2024.2) Affordable Generative Agents, [Paper], [Project]
-
(arXiv 2024.2) An Interactive Agent Foundation Model, [Paper]
-
(arXiv 2024.2) InCoRo: In-Context Learning for Robotics Control with Feedback Loops, [Paper]
-
(arXiv 2024.2) Real-World Robot Applications of Foundation Models: A Review, [Paper]
-
(arXiv 2024.2) Question Aware Vision Transformer for Multimodal Reasoning, [Paper]
-
(arXiv 2024.2) SPHINX-X: Scaling Data and Parameters for a Family of Multi-modal Large Language Models, [Paper], [Project]
-
(arXiv 2024.2) CREMA: Multimodal Compositional Video Reasoning via Efficient Modular Adaptation and Fusion, [Paper], [Project]
-
(arXiv 2024.2) S-AGENTS: SELF-ORGANIZING AGENTS IN OPENENDED ENVIRONMENT, [Paper], [Project]
-
(arXiv 2024.2) Code as Reward: Empowering Reinforcement Learning with VLMs, [Paper]
-
(arXiv 2024.2) Data-efficient Large Vision Models through Sequential Autoregression, [Paper], [Project]
-
(arXiv 2024.2) MLLM-as-a-Judge: Assessing Multimodal LLM-as-a-Judge with Vision-Language Benchmark, [Paper], [Project]
-
(arXiv 2024.2) Beyond Lines and Circles: Unveiling the Geometric Reasoning Gap in Large Language Models, [Paper], [Project]
-
(arXiv 2024.2) “Task Success” is not Enough: Investigating the Use of Video-Language Models as Behavior Critics for Catching Undesirable Agent Behaviors, [Paper], [Project]
-
(arXiv 2024.2) RAP: Retrieval-Augmented Planning with Contextual Memory for Multimodal LLM Agents, [Paper]
-
(arXiv 2024.2) Uni3D-LLM: Unifying Point Cloud Perception, Generation and Editing with Large Language Models, [Paper]
-
(arXiv 2024.2) The Instinctive Bias: Spurious Images lead to Hallucination in MLLMs, [Paper], [Project]
-
(arXiv 2024.2) MobileVLM V2: Faster and Stronger Baseline for Vision Language Model, [Paper], [Project]
-
(arXiv 2024.2) CogCoM: Train Large Vision-Language Models Diving into Details through Chain of Manipulations, [Paper], [Project]
-
(arXiv 2024.2) Compositional Generative Modeling: A Single Model is Not All You Need, [Paper]
-
(arXiv 2024.2) IMUGPT 2.0: Language-Based Cross Modality Transfer for Sensor-Based Human Activity Recognition, [Paper]
-
(arXiv 2024.2) SKIP \N: A SIMPLE METHOD TO REDUCE HALLUCINATION IN LARGE VISION-LANGUAGE MODELS, [Paper], [Project]
-
(arXiv 2024.1) AUTORT: EMBODIED FOUNDATION MODELS FOR LARGE SCALE ORCHESTRATION OF ROBOTIC AGENTS, [Paper], [Project]
-
(arXiv 2024.1) LISA++: An Improved Baseline for Reasoning Segmentation with Large Language Model, [Paper]
-
(arXiv 2024.1) TRAINING DIFFUSION MODELS WITH REINFORCEMENT LEARNING, [Paper], [Project]
-
(arXiv 2024.1) SWARMBRAIN: EMBODIED AGENT FOR REAL-TIME STRATEGY GAME STARCRAFT II VIA LARGE LANGUAGE MODELS, [Paper]
-
(arXiv 2024.1) YTCommentQA: Video Question Answerability in Instructional Videos, [Paper], [Project]
-
(arXiv 2024.1) MouSi: Poly-Visual-Expert Vision-Language Models, [Paper], [Project]
-
(arXiv 2024.1) DORAEMONGPT: TOWARD UNDERSTANDING DYNAMIC SCENES WITH LARGE LANGUAGE MODELS, [Paper], [Project]
-
(arXiv 2024.1) KAM-CoT: Knowledge Augmented Multimodal Chain-of-Thoughts Reasoning, [Paper]
-
(arXiv 2024.1) Growing from Exploration: A self-exploring framework for robots based on foundation models, [Paper], [Project]
-
(arXiv 2024.1) TRUE KNOWLEDGE COMES FROM PRACTICE: ALIGNING LLMS WITH EMBODIED ENVIRONMENTS VIA REINFORCEMENT LEARNING, [Paper], [Project]
-
(arXiv 2024.1) Red Teaming Visual Language Models, [Paper], [Project]
-
(arXiv 2024.1) The Neglected Tails of Vision-Language Models, [Paper], [Project]
-
(arXiv 2024.1) Zero Shot Open-ended Video Inference, [Paper]
-
(arXiv 2024.1) Small Language Model Meets with Reinforced Vision Vocabulary, [Paper], [Project]
-
(arXiv 2024.1) HAZARD CHALLENGE: EMBODIED DECISION MAKING IN DYNAMICALLY CHANGING ENVIRONMENTS, [Paper], [Project]
-
(arXiv 2024.1) VisualWebArena: EVALUATING MULTIMODAL AGENTS ON REALISTIC VISUAL WEB TASKS, [Paper], [Project]
-
(arXiv 2024.1) ChatterBox: Multi-round Multimodal Referring and Grounding, [Paper], [Project]
-
(arXiv 2024.1) CONTEXTUAL: Evaluating Context-Sensitive Text-Rich Visual Reasoning in Large Multimodal Models, [Paper], [Project]
-
(arXiv 2024.1) UNIMO-G: Unified Image Generation through Multimodal Conditional Diffusion, [Paper], [Project]
-
(arXiv 2024.1) DEMOCRATIZING FINE-GRAINED VISUAL RECOGNITION WITH LARGE LANGUAGE MODELS, [Paper], [Project]
-
(arXiv 2024.1) Benchmarking Large Multimodal Models against Common Corruptions, [Paper], [Project]
-
(arXiv 2024.1) CMMMU: A Chinese Massive Multi-discipline Multimodal Understanding Benchmark, [Paper], [Project]
-
(arXiv 2024.1) Prompting Large Vision-Language Models for Compositional Reasoning, [Paper], [Project]
-
(arXiv 2024.1) Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs, [Paper], [Project]
-
(arXiv 2024.1) SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities, [Paper], [Project]
-
(arXiv 2024.1) Towards A Better Metric for Text-to-Video Generation, [Paper], [Project]
-
(arXiv 2024.1) EXPLOITING GPT-4 VISION FOR ZERO-SHOT POINT CLOUD UNDERSTANDING, [Paper]
-
(arXiv 2024.1) MM-SAP: A Comprehensive Benchmark for Assessing Self-Awareness of Multimodal Large Language Models in Perception, [Paper], [Project]
-
(arXiv 2024.1) GATS: Gather-Attend-Scatter, [Paper]
-
(arXiv 2024.1) DiffusionGPT: LLM-Driven Text-to-Image Generation System, [Paper], [Project]
-
(arXiv 2024.1) TEMPORAL INSIGHT ENHANCEMENT: MITIGATING TEMPORAL HALLUCINATION IN MULTIMODAL LARGE LANGUAGE MODELS, [Paper]
-
(arXiv 2024.1) Advancing Large Multi-modal Models with Explicit Chain-of-Reasoning and Visual Question Generation, [Paper]
-
(arXiv 2024.1) GPT4Ego: Unleashing the Potential of Pre-trained Models for Zero-Shot Egocentric Action Recognition, [Paper]
-
(arXiv 2024.1) SCENEVERSE: Scaling 3D Vision-Language Learning for Grounded Scene Understanding, [Paper], [Project]
-
(arXiv 2024.1) Vlogger: Make Your Dream A Vlog, [Paper], [Project]
-
(arXiv 2024.1) CognitiveDog: Large Multimodal Model Based System to Translate Vision and Language into Action of Quadruped Robot, [Paper], [Project]
-
(arXiv 2024.1) Consolidating Trees of Robotic Plans Generated Using Large Language Models to Improve Reliability, [Paper]
-
(arXiv 2024.1) Mementos: A Comprehensive Benchmark for Multimodal Large Language Model Reasoning over Image Sequences, [Paper], [Project]
-
(arXiv 2024.1) Weakly Supervised Gaussian Contrastive Grounding with Large Multimodal Models for Video Question Answering, [Paper]
-
(arXiv 2024.1) Q&A Prompts: Discovering Rich Visual Clues through Mining Question-Answer Prompts for VQA requiring Diverse World Knowledge, [Paper]
-
(arXiv 2024.1) Tool-LMM: A Large Multi-Modal Model for Tool Agent Learning, [Paper], [Project]
-
(arXiv 2024.1) MMToM-QA: Multimodal Theory of Mind Question Answering, [Paper], [Project]
-
(arXiv 2024.1) EgoGen: An Egocentric Synthetic Data Generator, [Paper], [Project]
-
(arXiv 2024.1) COCO IS “ALL” YOU NEED FOR VISUAL INSTRUCTION FINE-TUNING, [Paper]
-
(arXiv 2024.1) OCTO+: A Suite for Automatic Open-Vocabulary Object Placement in Mixed Reality, [Paper], [Project]
-
(arXiv 2024.1) MultiPLY: A Multisensory Object-Centric Embodied Large Language Model in 3D World, [Paper], [Project]
-
(arXiv 2024.1) SELF-IMAGINE: EFFECTIVE UNIMODAL REASONING WITH MULTIMODAL MODELS USING SELF-IMAGINATION, [Paper], [Project]
-
(arXiv 2024.1) Multi-Track Timeline Control for Text-Driven 3D Human Motion Generation, [Paper], [Project]
-
(arXiv 2024.1) Towards Language-Driven Video Inpainting via Multimodal Large Language Models, [Paper], [Project]
-
(arXiv 2024.1) An Improved Baseline for Reasoning Segmentation with Large Language Model, [Paper]
-
(arXiv 2024.1) MultiPLY: A Multisensory Object-Centric Embodied Large Language Model in 3D World, [Paper], [Project]
-
(arXiv 2024.1) 3D-PREMISE: CAN LARGE LANGUAGE MODELS GENERATE 3D SHAPES WITH SHARP FEATURES AND PARAMETRIC CONTROL? [Paper]
-
(arXiv 2024.1) 360DVD: Controllable Panorama Video Generation with 360-Degree Video Diffusion Model, [Paper], [Project]
-
(arXiv 2024.1) Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs, [Paper], [Project]
-
(arXiv 2024.1) AffordanceLLM: Grounding Affordance from Vision Language Models, [Paper], [Project]
-
(arXiv 2024.1) ModaVerse: Efficiently Transforming Modalities with LLMs, [Paper]
-
(arXiv 2024.1) REPLAN: ROBOTIC REPLANNING WITH PERCEPTION AND LANGUAGE MODELS, [Paper], [Project]
-
(arXiv 2024.1) Language-Conditioned Robotic Manipulation with Fast and Slow Thinking, [Paper], [Project]
-
(arXiv 2024.1) FunnyNet-W: Multimodal Learning of Funny Moments in Videos in the Wild, [Paper]
-
(arXiv 2024.1) REBUS: A Robust Evaluation Benchmark of Understanding Symbols, [Paper], [Project]
-
(arXiv 2024.1) LEGO:Language Enhanced Multi-modal Grounding Model, [Paper], [Project]
-
(arXiv 2024.1) Distilling Vision-Language Models on Millions of Videos, [Paper]
-
(arXiv 2024.1) EXPLORING LARGE LANGUAGE MODEL BASED INTELLIGENT AGENTS: DEFINITIONS, METHODS, AND PROSPECTS, [Paper]
-
(arXiv 2024.1) AGENT AI: SURVEYING THE HORIZONS OF MULTIMODAL INTERACTION, [Paper]
-
(arXiv 2024.1) ExTraCT – Explainable Trajectory Corrections from language inputs using Textual description of features, [Paper]
-
(arXiv 2024.1) Incorporating Visual Experts to Resolve the Information Loss in Multimodal Large Language Models, [Paper]
-
(arXiv 2024.1) GPT-4V(ision) is a Human-Aligned Evaluator for Text-to-3D Generation, [Paper], [Project]
-
(arXiv 2024.1) Large Language Models as Visual Cross-Domain Learners, [Paper], [Project]
-
(arXiv 2024.1) 3DMIT: 3D MULTI-MODAL INSTRUCTION TUNING FOR SCENE UNDERSTANDING, [Paper], [Project]
-
(arXiv 2024.1) CaMML: Context-Aware Multimodal Learner for Large Models, [Paper]
-
(arXiv 2024.1) Object-Centric Instruction Augmentation for Robotic Manipulation, [Paper], [Project]
-
(arXiv 2024.1) Towards Truly Zero-shot Compositional Visual Reasoning with LLMs as Programmers, [Paper]
-
(arXiv 2024.1) A Vision Check-up for Language Models, [Paper], [Project]
-
(arXiv 2024.1) GPT-4V(ision) is a Generalist Web Agent, if Grounded, [Paper], [Project]
-
(arXiv 2024.1) LLaVA-ϕ: Efficient Multi-Modal Assistant with Small Language Model, [Paper], [Project]
-
(arXiv 2023.12) GLaMM: Pixel Grounding Large Multimodal Model, [Paper], [Project]
-
(arXiv 2023.12) MOCHa: Multi-Objective Reinforcement Mitigating Caption Hallucinations, [Paper], [Project]
-
(arXiv 2023.12) Visual Program Distillation: Distilling Tools and Programmatic Reasoning into Vision-Language Models, [Paper], [Project]
-
(arXiv 2023.12) Customization Assistant for Text-to-image Generation, [Paper]
-
(arXiv 2023.12) GPT4Point: A Unified Framework for Point-Language Understanding and Generation, [Paper], [Project]
-
(arXiv 2023.12) LLaVA-Grounding: Grounded Visual Chat with Large Multimodal Models, [Paper], [Project]
-
(arXiv 2023.12) BenchLMM: Benchmarking Cross-style Visual Capability of Large Multimodal Models, [Paper], [Project]
-
(arXiv 2023.12) Generating Fine-Grained Human Motions Using ChatGPT-Refined Descriptions, [Paper], [Project]
-
(arXiv 2023.12) Machine Vision Therapy: Multimodal Large Language Models Can Enhance Visual Robustness via Denoising In-Context Learning, [Paper], [Project]
-
(arXiv 2023.12) ETC: Temporal Boundary Expand then Clarify for Weakly Supervised Video Grounding with Multimodal Large Language Model, [Paper]
-
(arXiv 2023.12) Lenna: Language Enhanced Reasoning Detection Assistant, [Paper], [Project]
-
(arXiv 2023.12) VaQuitA: Enhancing Alignment in LLM-Assisted Video Understanding, [Paper]
-
(arXiv 2023.12) StoryGPT-V: Large Language Models as Consistent Story Visualizers, [Paper], [Project]
-
(arXiv 2023.12) Diversify, Don’t Fine-Tune: Scaling Up Visual Recognition Training with Synthetic Images, [Paper]
-
(arXiv 2023.12) Recursive Visual Programming, [Paper]
-
(arXiv 2023.12) PixelLM: Pixel Reasoning with Large Multimodal Model, [Paper]
-
(arXiv 2023.12) Generating Action-conditioned Prompts for Open-vocabulary Video Action Recognition, [Paper]
-
(arXiv 2023.12) Behind the Magic, MERLIM: Multi-modal Evaluation Benchmark for Large Image-Language Models, [Paper], [Project]
-
(arXiv 2023.12) Video Summarization: Towards Entity-Aware Captions, [Paper]
-
(arXiv 2023.12) VLAP: Efficient Video-Language Alignment via Frame Prompting and Distilling for Video Question Answering, [Paper]
-
(arXiv 2023.12) See, Say, and Segment: Teaching LMMs to Overcome False Premises, [Paper], [Project]
-
(arXiv 2023.12) Chat-3D v2: Bridging 3D Scene and Large Language Models with Object Identifiers, [Paper]
-
(arXiv 2023.12) Interfacing Foundation Models’ Embeddings, [Paper], [Project]
-
(arXiv 2023.12) VILA: On Pre-training for Visual Language Models, [Paper]
-
(arXiv 2023.12) MP5: A Multi-modal Open-ended Embodied System in Minecraft via Active Perception, [Paper], [Project]
-
(arXiv 2023.12) Hallucination Augmented Contrastive Learning for Multimodal Large Language Model, [Paper]
-
(arXiv 2023.12) Honeybee: Locality-enhanced Projector for Multimodal LLM, [Paper], [Project]
-
(arXiv 2023.12) SmartEdit: Exploring Complex Instruction-based Image Editing with Multimodal Large Language Models, [Paper], [Project]
-
(arXiv 2023.12) InstructAny2Pix: Flexible Visual Editing via Multimodal Instruction Following, [Paper], [Project]
-
(arXiv 2023.12) EgoPlan-Bench: Benchmarking Egocentric Embodied Planning with Multimodal Large Language Models, [Paper], [Project]
-
(arXiv 2023.12) AM-RADIO: Agglomerative Model – Reduce All Domains Into One, [Paper], [Project]
-
(arXiv 2023.12) Leveraging Generative Language Models for Weakly Supervised Sentence Component Analysis in Video-Language Joint Learning, [Paper]
-
(arXiv 2023.12) How Well Does GPT-4V(ision) Adapt to Distribution Shifts? A Preliminary Investigation, [Paper], [Project]
-
(arXiv 2023.12) Audio-Visual LLM for Video Understanding, [Paper]
-
(arXiv 2023.12) AnyHome: Open-Vocabulary Generation of Structured and Textured 3D Homes, [Paper], [Project]
-
(arXiv 2023.12) Learning Hierarchical Prompt with Structured Linguistic Knowledge for Vision-Language Models, [Paper], [[Project]]( https:// github.com/Vill-Lab/2024-AAAI-HPT)
-
(arXiv 2023.12) Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models, [Paper], [Project]
-
(arXiv 2023.12) AllSpark: a multimodal spatiotemporal general model, [Paper]
-
(arXiv 2023.12) Tracking with Human-Intent Reasoning, [Paper], [Project]
-
(arXiv 2023.12) Retrieval-Augmented Egocentric Video Captioning, [Paper]
-
(arXiv 2023.12) COSMO: COntrastive Streamlined MultimOdal Model with Interleaved Pre-Training, [Paper], [Project]
-
(arXiv 2023.12) LARP: LANGUAGE-AGENT ROLE PLAY FOR OPEN-WORLD GAMES, [Paper], [Project]
-
(arXiv 2023.12) CLOVA: A Closed-LOop Visual Assistant with Tool Usage and Update, [Paper], [Project]
-
(arXiv 2023.12) DiffVL: Scaling Up Soft Body Manipulation using Vision-Language Driven Differentiable Physics, [Paper], [Project]
-
(arXiv 2023.12) VISTA-LLAMA: Reliable Video Narrator via Equal Distance to Visual Tokens, [Paper], [Project]
-
(arXiv 2023.12) VL-GPT: A Generative Pre-trained Transformer for Vision and Language Understanding and Generation, [Paper], [Project]
-
(arXiv 2023.12) Pixel Aligned Language Models, [Paper], [Project]
-
(arXiv 2023.12) Grounding-Prompter: Prompting LLM with Multimodal Information for Temporal Sentence Grounding in Long Videos, [Paper]
-
(arXiv 2023.12) Q-ALIGN: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels, [Paper], [Project]
-
(arXiv 2023.12) Osprey: Pixel Understanding with Visual Instruction Tuning, [Paper], [Project]
-
(arXiv 2023.12) Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action, [Paper], [Project]
-
(arXiv 2023.12) A Simple LLM Framework for Long-Range Video Question-Answering, [Paper], [Project]
-
(arXiv 2023.12) TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones, [Paper], [Project]
-
(arXiv 2023.12) ManipLLM: Embodied Multimodal Large Language Model for Object-Centric Robotic Manipulation, [Paper], [Project]
-
(arXiv 2023.12) ChartBench: A Benchmark for Complex Visual Reasoning in Charts, [Paper]
-
(arXiv 2023.12) FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects, [Paper], [Project]
-
(arXiv 2023.12) Make-A-Character: High Quality Text-to-3D Character Generation within Minutes, [Paper], [Project]
-
(arXiv 2023.12) Osprey: Pixel Understanding with Visual Instruction Tuning, [Paper], [Project]
-
(arXiv 2023.12) 3DAxiesPrompts: Unleashing the 3D Spatial Task Capabilities of GPT-4V, [Paper]
-
(arXiv 2023.12) SMILE: Multimodal Dataset for Understanding Laughter in Video with Language Models, [Paper], [Project]
-
(arXiv 2023.12) VideoPoet: A Large Language Model for Zero-Shot Video Generation, [Paper], [Project]
-
(arXiv 2023.12) V∗: Guided Visual Search as a Core Mechanism in Multimodal LLMs, [Paper], [Project]
-
(arXiv 2023.12) A Semantic Space is Worth 256 Language Descriptions: Make Stronger Segmentation Models with Descriptive Properties, [Paper], [Project]
-
(arXiv 2023.12) AppAgent: Multimodal Agents as Smartphone Users, [Paper], [Project]
-
(arXiv 2023.12) InfoVisDial: An Informative Visual Dialogue Dataset by Bridging Large Multimodal and Language Models, [Paper], [Project]
-
(arXiv 2023.12) Not All Steps are Equal: Efficient Generation with Progressive Diffusion Models, [Paper]
-
(arXiv 2023.12) Generative Multimodal Models are In-Context Learners, [Paper], [Project]
-
(arXiv 2023.12) VCoder: Versatile Vision Encoders for Multimodal Large Language Models, [Paper], [Project]
-
(arXiv 2023.12) LLM4VG: Large Language Models Evaluation for Video Grounding, [Paper]
-
(arXiv 2023.12) InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks, [Paper], [Project]
-
(arXiv 2023.12) VIEScore: Towards Explainable Metrics for Conditional Image Synthesis Evaluation, [Paper], [Project]
-
(arXiv 2023.12) Plan, Posture and Go: Towards Open-World Text-to-Motion Generation, [Paper], [Project]
-
(arXiv 2023.12) MotionScript: Natural Language Descriptions for Expressive 3D Human Motions, [Paper], [Project]
-
(arXiv 2023.12) Assessing GPT4-V on Structured Reasoning Tasks, [Paper], [Project]
-
(arXiv 2023.12) Iterative Motion Editing with Natural Language, [Paper], [Project]
-
(arXiv 2023.12) Gemini: A Family of Highly Capable Multimodal Models, [Paper], [Project]
-
(arXiv 2023.12) StarVector: Generating Scalable Vector Graphics Code from Images, [Paper], [Project]
-
(arXiv 2023.12) Text-Conditioned Resampler For Long Form Video Understanding, [Paper]
-
(arXiv 2023.12) Mixture of Cluster-conditional LoRA Experts for Vision-language Instruction Tuning, [Paper]
-
(arXiv 2023.12) A Challenger to GPT-4V? Early Explorations of Gemini in Visual Expertise, [Paper], [Project]
-
(arXiv 2023.12) Jack of All Tasks, Master of Many: Designing General-purpose Coarse-to-Fine Vision-Language Model, [Paper], [Project]
-
(arXiv 2023.12) M^2ConceptBase: A Fine-grained Aligned Multi-modal Conceptual Knowledge Base, [Paper]
-
(arXiv 2023.12) Language-conditioned Learning for Robotic Manipulation: A Survey, [Paper]
-
(arXiv 2023.12) TUNING LAYERNORM IN ATTENTION: TOWARDS EFFICIENT MULTI-MODAL LLM FINETUNING, [Paper]
-
(arXiv 2023.12) GSVA: Generalized Segmentation via Multimodal Large Language Models, [Paper], [Project]
-
(arXiv 2023.12) SILKIE: PREFERENCE DISTILLATION FOR LARGE VISUAL LANGUAGE MODELS, [Paper], [Project]
-
(arXiv 2023.12) AN EVALUATION OF GPT-4V AND GEMINI IN ONLINE VQA, [Paper]
-
(arXiv 2023.12) CEIR: CONCEPT-BASED EXPLAINABLE IMAGE REPRESENTATION LEARNING, [Paper], [Project]
-
(arXiv 2023.12) Language-Assisted 3D Scene Understanding, [Paper], [Project]
-
(arXiv 2023.12) M3DBench: Let’s Instruct Large Models with Multi-modal 3D Prompts, [Paper], [Project]
-
(arXiv 2023.12) Modality Plug-and-Play: Elastic Modality Adaptation in Multimodal LLMs for Embodied AI, [Paper], [Project]
-
(arXiv 2023.12) FROM TEXT TO MOTION: GROUNDING GPT-4 IN A HUMANOID ROBOT “ALTER3”, [Paper], [Project]
-
(arXiv 2023.12) Interactive Planning Using Large Language Models for Partially Observable Robotics Tasks, [Paper]
-
(arXiv 2023.12) LifelongMemory: Leveraging LLMs for Answering Queries in Egocentric Videos, [Paper]
-
(arXiv 2023.12) LEGO: Learning EGOcentric Action Frame Generation via Visual Instruction Tuning, [Paper]
-
(arXiv 2023.12) Localized Symbolic Knowledge Distillation for Visual Commonsense Models, [Paper], [Project]
-
(arXiv 2023.12) MoVQA: A Benchmark of Versatile Question-Answering for Long-Form Movie Understanding, [Paper], [Project]
-
(arXiv 2023.12) Human Demonstrations are Generalizable Knowledge for Robots, [Paper]
-
(arXiv 2023.12) WonderJourney: Going from Anywhere to Everywhere, [Paper], [Project]
-
(arXiv 2023.12) VRPTEST: Evaluating Visual Referring Prompting in Large Multimodal Models, [Paper], [Code]
-
(arXiv 2023.12) Text as Image: Learning Transferable Adapter for Multi-Label Classification, [Paper]
-
(arXiv 2023.12) Prompt Highlighter: Interactive Control for Multi-Modal LLMs, [Paper], [Project]
-
(arXiv 2023.12) Digital Life Project: Autonomous 3D Characters with Social Intelligence, [Paper], [Project]
-
(arXiv 2023.12) Generating Illustrated Instructions, [Paper], [Project]
-
(arXiv 2023.12) Aligning and Prompting Everything All at Once for Universal Visual Perception, [Paper], [Code]
-
(arXiv 2023.12) LEAP: LLM-Generation of Egocentric Action Programs, [Paper]
-
(arXiv 2023.12) OST: Refining Text Knowledge with Optimal Spatio-Temporal Descriptor for General Video Recognition, [Paper], [Project]
-
(arXiv 2023.12) Merlin: Empowering Multimodal LLMs with Foresight Minds, [Paper], [Project]
-
(arXiv 2023.12) VIoTGPT: Learning to Schedule Vision Tools towards Intelligent Video Internet of Things, [Paper], [Code]
-
(arXiv 2023.12) Making Large Multimodal Models Understand Arbitrary Visual Prompts, [Paper], [Project]
-
(arXiv 2023.11) Video-LLaVA: Learning United Visual Representation by Alignment Before Projection, [Paper], [Code]
-
(arXiv 2023.11) Self-Chained Image-Language Model for Video Localization and Question Answering, [Paper], [Code]
-
(arXiv 2023.11) Look Before You Leap: Unveiling the Power of GPT-4V in Robotic Vision-Language Planning, [Paper], [Project]
-
(arXiv 2023.11) LALM: Long-Term Action Anticipation with Language Models, [Paper]
-
(arXiv 2023.11) Contrastive Vision-Language Alignment Makes Efficient Instruction Learner, [Paper], [Code]
-
(arXiv 2023.11) ChatIllusion: Efficient-Aligning Interleaved Generation ability with Visual Instruction Model, [Paper], [Code]
-
(arXiv 2023.11) MV-CLIP: Multi-View CLIP for Zero-shot 3D Shape Recognition, [Paper]
-
(arXiv 2023.11) VTimeLLM: Empower LLM to Grasp Video Moments, [Paper], [Code]
-
(arXiv 2023.11) Simple Semantic-Aided Few-Shot Learning, [Paper]
-
(arXiv 2023.11) LL3DA: Visual Interactive Instruction Tuning for Omni-3D Understanding, Reasoning, and Planning, [Paper], [Project]
-
(arXiv 2023.11) Detailed Human-Centric Text Description-Driven Large Scene Synthesis, [Paper]
-
(arXiv 2023.11) X-InstructBLIP: A Framework for aligning X-Modal instruction-aware representations to LLMs and Emergent Cross-modal Reasoning, [Paper], [Code]
-
(arXiv 2023.11) CoDi-2: In-Context, Interleaved, and Interactive Any-to-Any Generation, [Paper], [Project]
-
(arXiv 2023.11) AvatarGPT: All-in-One Framework for Motion Understanding, Planning, Generation and Beyond, [Paper], [Project]
-
(arXiv 2023.11) InstructSeq: Unifying Vision Tasks with Instruction-conditioned Multi-modal Sequence Generation, [Paper], [Code]
-
(arXiv 2023.11) MLLMs-Augmented Visual-Language Representation Learning, [Paper], [Code]
-
(arXiv 2023.11) PoseGPT: Chatting about 3D Human Pose, [Paper], [Project]
-
(arXiv 2023.11) LLM-State: Expandable State Representation for Long-horizon Task Planning in the Open World, [Paper]
-
(arXiv 2023.11) UniIR: Training and Benchmarking Universal Multimodal Information Retrievers, [Paper], [Project]
-
(arXiv 2023.11) VITATECS: A Diagnostic Dataset for Temporal Concept Understanding of Video-Language Models, [Paper], [Code]
-
(arXiv 2023.11) MM-Narrator: Narrating Long-form Videos with Multimodal In-Context Learning, [Paper], [Project]
-
(arXiv 2023.11) Knowledge Pursuit Prompting for Zero-Shot Multimodal Synthesis, [Paper]
-
(arXiv 2023.11) Evaluating VLMs for Score-Based, Multi-Probe Annotation of 3D Objects, [Paper]
-
(arXiv 2023.11) OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation, [Paper], [Code]
-
(arXiv 2023.11) ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model, [Paper], [Project]
-
(arXiv 2023.11) VIM: Probing Multimodal Large Language Models for Visual Embedded Instruction Following, [Paper], [Project]
-
(arXiv 2023.11) Video-Bench: A Comprehensive Benchmark and Toolkit for Evaluating Video-based Large Language Models, [Paper], [Code]
-
(arXiv 2023.11) Self-correcting LLM-controlled Diffusion Models, [Paper]
-
(arXiv 2023.11) InterControl: Generate Human Motion Interactions by Controlling Every Joint, [Paper], [Code]
-
(arXiv 2023.11) DRESS: Instructing Large Vision-Language Models to Align and Interact with Humans via Natural Language Feedback, [Paper], [Code]
-
(arXiv 2023.11) GAIA: A Benchmark for General AI Assistants, [Paper], [Project]
-
(arXiv 2023.11) PG-Video-LLaVA: Pixel Grounding Large Video-Language Models, [Paper], [Code]
-
(arXiv 2023.11) Enhancing Scene Graph Generation with Hierarchical Relationships and Commonsense Knowledge, [Paper]
-
(arXiv 2023.11) AN EMBODIED GENERALIST AGENT IN 3D WORLD, [Paper], [Project]
-
(arXiv 2023.11) ShareGPT4V: Improving Large Multi-Modal Models with Better Captions, [Paper], [Project]
-
(arXiv 2023.11) KNVQA: A Benchmark for evaluation knowledge-based VQA, [Paper]
-
(arXiv 2023.11) GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning, [Paper], [Project]
-
(arXiv 2023.11) Boosting Audio-visual Zero-shot Learning with Large Language Models, [Paper], [Code]
-
(arXiv 2023.11) Few-Shot Classification & Segmentation Using Large Language Models Agent, [Paper]
-
(arXiv 2023.11) Igniting Language Intelligence: The Hitchhiker’s Guide From Chain-of-Thought Reasoning to Language Agents, [Paper], [Code]
-
(arXiv 2023.11) VLM-Eval: A General Evaluation on Video Large Language Models, [Paper]
-
(arXiv 2023.11) LLMs as Visual Explainers: Advancing Image Classification with Evolving Visual Descriptions, [Paper], [Code]
-
(arXiv 2023.11) LION : Empowering Multimodal Large Language Model with Dual-Level Visual Knowledge, [Paper], [Project]
-
(arXiv 2023.11) Chat-UniVi: Unified Visual Representation Empowers Large Language Models with Image and Video Understanding, [Paper], [Code]
-
(arXiv 2023.11) How to Bridge the Gap between Modalities: A Comprehensive Survey on Multimodal Large Language Model, [Paper]
-
(arXiv 2023.11) Unlock the Power: Competitive Distillation for Multi-Modal Large Language Models, [Paper], [Code]
-
(arXiv 2023.11) Towards Open-Ended Visual Recognition with Large Language Model, [Paper], [Code]
-
(arXiv 2023.11) Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models, [Paper], [Code]
-
(arXiv 2023.11) VILMA: A ZERO-SHOT BENCHMARK FOR LINGUISTIC AND TEMPORAL GROUNDING IN VIDEO-LANGUAGE MODELS, [Paper], [Project]
-
(arXiv 2023.11) VOLCANO: Mitigating Multimodal Hallucination through Self-Feedback Guided Revision, [Paper], [Code]
-
(arXiv 2023.11) AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation, [Paper], [Code]
-
(arXiv 2023.11) Analyzing Modular Approaches for Visual Question Decomposition, [Paper], [Code]
-
(arXiv 2023.11) LayoutPrompter: Awaken the Design Ability of Large Language Models, [Paper], [Code]
-
(arXiv 2023.11) PerceptionGPT: Effectively Fusing Visual Perception into LLM, [Paper]
-
(arXiv 2023.11) InfMLLM: A Unified Framework for Visual-Language Tasks, [Paper], [Code]
-
(arXiv 2023.11) WHAT LARGE LANGUAGE MODELS BRING TO TEXTRICH VQA?, [Paper]
-
(arXiv 2023.11) Story-to-Motion: Synthesizing Infinite and Controllable Character Animation from Long Text, [Paper], [Project]
-
(arXiv 2023.11) GPT-4V(ision) as A Social Media Analysis Engine, [Paper], [Code]
-
(arXiv 2023.11) GPT-4V in Wonderland: Large Multimodal Models for Zero-Shot Smartphone GUI Navigation, [Paper], [Code]
-
(arXiv 2023.11) To See is to Believe: Prompting GPT-4V for Better Visual Instruction Tuning, [Paper], [Code]
-
(arXiv 2023.11) SPHINX: THE JOINT MIXING OF WEIGHTS, TASKS, AND VISUAL EMBEDDINGS FOR MULTI-MODAL LARGE LANGUAGE MODELS, [Paper], [Code]
-
(arXiv 2023.11) ADAPT: As-Needed Decomposition and Planning with Language Models, [Paper], [Project]
-
(arXiv 2023.11) JARVIS-1: Open-world Multi-task Agents with Memory-Augmented Multimodal Language Models, [Paper], [Project]
-
(arXiv 2023.11) Florence-2: Advancing a Unified Representation for a Variety of Vision Tasks, [Paper]
-
(arXiv 2023.11) Multitask Multimodal Prompted Training for Interactive Embodied Task Completion, [Paper], [Code]
-
(arXiv 2023.11) TEAL: TOKENIZE AND EMBED ALL FOR MULTIMODAL LARGE LANGUAGE MODELS, [Paper]
-
(arXiv 2023.11) u-LLaVA: Unifying Multi-Modal Tasks via Large Language Model, [Paper]
-
(arXiv 2023.11) LLAVA-PLUS: LEARNING TO USE TOOLS FOR CREATING MULTIMODAL AGENTS, [Paper], [Project]
-
(arXiv 2023.11) Detecting Any Human-Object Interaction Relationship: Universal HOI Detector with Spatial Prompt Learning on Foundation Models, [Paper], [Code]
-
(arXiv 2023.11) OtterHD: A High-Resolution Multi-modality Model, [Paper], [Code]
-
(arXiv 2023.11) NExT-Chat: An LMM for Chat, Detection and Segmentation, [Paper], [Project]
-
(arXiv 2023.11) GENOME: GENERATIVE NEURO-SYMBOLIC VISUAL REASONING BY GROWING AND REUSING MODULES, [Paper], [Project]
-
(arXiv 2023.11) MAKE A DONUT: LANGUAGE-GUIDED HIERARCHICAL EMD-SPACE PLANNING FOR ZERO-SHOT DEFORMABLE OBJECT MANIPULATION, [Paper]
-
(arXiv 2023.11) Kinematic-aware Prompting for Generalizable Articulated Object Manipulation with LLMs, [Paper], [Code]
-
(arXiv 2023.11) Accelerating Reinforcement Learning of Robotic Manipulations via Feedback from Large Language Models, [Paper]
-
(arXiv 2023.11) ROBOGEN: TOWARDS UNLEASHING INFINITE DATA FOR AUTOMATED ROBOT LEARNING VIA GENERATIVE SIMULATION, [Paper]
-
(arXiv 2023.10) MINIGPT-5: INTERLEAVED VISION-AND-LANGUAGE GENERATION VIA GENERATIVE VOKENS, [Paper], [Code]
-
(arXiv 2023.10) What’s “up” with vision-language models? Investigating their struggle with spatial reasoning, [Paper], [Code]
-
(arXiv 2023.10) APOLLO: ZERO-SHOT MULTIMODAL REASONING WITH MULTIPLE EXPERTS, [Paper], [Code]
-
(arXiv 2023.10) ROME: Evaluating Pre-trained Vision-Language Models on Reasoning beyond Visual Common Sense, [Paper]
-
(arXiv 2023.10) Gen2Sim: Scaling up Robot Learning in Simulation with Generative Models, [Paper], [Project]
-
(arXiv 2023.10) LARGE LANGUAGE MODELS AS GENERALIZABLE POLICIES FOR EMBODIED TASKS, [Paper], [Project]
-
(arXiv 2023.10) Humanoid Agents: Platform for Simulating Human-like Generative Agents, [Paper], [Project]
-
(arXiv 2023.10) REVO-LION: EVALUATING AND REFINING VISION-LANGUAGE INSTRUCTION TUNING DATASETS, [Paper], [Code]
-
(arXiv 2023.10) How (not) to ensemble LVLMs for VQA, [Paper]
-
(arXiv 2023.10) What If the TV Was Off? Examining Counterfactual Reasoning Abilities of Multi-modal Language Models, [Paper], [Code]
-
(arXiv 2023.10) Words into Action: Learning Diverse Humanoid Robot Behaviors using Language Guided Iterative Motion Refinement, [Paper], [Code]
-
(arXiv 2023.10) GameGPT: Multi-agent Collaborative Framework for Game Development, [Paper]
-
(arXiv 2023.10) STEVE-EYE: EQUIPPING LLM-BASED EMBODIED AGENTS WITH VISUAL PERCEPTION IN OPEN WORLDS, [Paper]
-
(arXiv 2023.10) BENCHMARKING SEQUENTIAL VISUAL INPUT REASONING AND PREDICTION IN MULTIMODAL LARGE LANGUAGE MODELS, [Paper], [Code]
-
(arXiv 2023.10) A Simple Baseline for Knowledge-Based Visual Question Answering, [Paper], [Code]
-
(arXiv 2023.10) Interactive Robot Learning from Verbal Correction, [Paper], [Project]
-
(arXiv 2023.10) Exploring Question Decomposition for Zero-Shot VQA, [Paper], [Project]
-
(arXiv 2023.10) RIO: A Benchmark for Reasoning Intention-Oriented Objects in Open Environments, [Paper], [Project]
-
(arXiv 2023.10) An Early Evaluation of GPT-4V(ision), [Paper], [Code]
-
(arXiv 2023.10) DDCoT: Duty-Distinct Chain-of-Thought Prompting for Multimodal Reasoning in Language Models, [Paper], [Project]
-
(arXiv 2023.10) CommonCanvas: An Open Diffusion Model Trained with Creative-Commons Images, [Paper], [Code]
-
(arXiv 2023.10) VIDEOPROMPTER: AN ENSEMBLE OF FOUNDATIONAL MODELS FOR ZERO-SHOT VIDEO UNDERSTANDING, [Paper]
-
(arXiv 2023.10) Inject Semantic Concepts into Image Tagging for Open-Set Recognition, [Paper], [Code]
-
(arXiv 2023.10) Woodpecker: Hallucination Correction for Multimodal Large Language Models, [Paper], [Code]
-
(arXiv 2023.10) Visual Cropping Improves Zero-Shot Question Answering of Multimodal Large Language Models, [Paper], [Code]
-
(arXiv 2023.10) Large Language Models are Temporal and Causal Reasoners for Video Question Answering, [Paper], [Code]
-
(arXiv 2023.10) What’s Left? Concept Grounding with Logic-Enhanced Foundation Models, [Paper]
-
(arXiv 2023.10) Evaluating Spatial Understanding of Large Language Models, [Paper]
-
(arXiv 2023.10) Learning Reward for Physical Skills using Large Language Model, [Paper]
-
(arXiv 2023.10) CREATIVE ROBOT TOOL USE WITH LARGE LANGUAGE MODELS, [Paper], [Project]
-
(arXiv 2023.10) Open-Ended Instructable Embodied Agents with Memory-Augmented Large Language Models, [Paper], [Project]
-
(arXiv 2023.10) Robot Fine-Tuning Made Easy: Pre-Training Rewards and Policies for Autonomous Real-World Reinforcement Learning, [Paper], [Project]
-
(arXiv 2023.10) LARGE LANGUAGE MODELS CAN Share IMAGES, TOO! [Paper], [Code]
-
(arXiv 2023.10) Dataset Bias Mitigation in Multiple-Choice Visual Question Answering and Beyond, [Paper]
-
(arXiv 2023.10) HALLUSIONBENCH: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V(vision), LLaVA-1.5, and Other Multi-modality Models, [Paper], [Code]
-
(arXiv 2023.10) Can Language Models Laugh at YouTube Short-form Videos? [Paper], [Code]
-
(arXiv 2023.10) Large Language Models are Visual Reasoning Coordinators, [Paper], [Code]
-
(arXiv 2023.10) Language Models as Zero-Shot Trajectory Generators, [Paper], [Project]
-
(arXiv 2023.10) Localizing Active Objects from Egocentric Vision with Symbolic World Knowledge, [Paper], [Code]
-
(arXiv 2023.10) Multimodal Large Language Model for Visual Navigation, [Paper]
-
(arXiv 2023.10) MAKING MULTIMODAL GENERATION EASIER: WHEN DIFFUSION MODELS MEET LLMS, [Paper], [Code]
-
(arXiv 2023.10) Open X-Embodiment: Robotic Learning Datasets and RT-X Models, [Paper], [Project]
-
(arXiv 2023.10) Large Language Models Meet Open-World Intent Discovery and Recognition: An Evaluation of ChatGPT, [Paper], [Code]
-
(arXiv 2023.10) Lost in Translation: When GPT-4V(ision) Can’t See Eye to Eye with Text A Vision-Language-Consistency Analysis of VLLMs and Beyond, [Paper]
-
(arXiv 2023.10) Interactive Navigation in Environments with Traversable Obstacles Using Large Language and Vision-Language Models, [Paper]
-
(arXiv 2023.10) VLIS: Unimodal Language Models Guide Multimodal Language Generation, [Paper], [Code]
-
(arXiv 2023.10) CLIN: A CONTINUALLY LEARNING LANGUAGE AGENT FOR RAPID TASK ADAPTATION AND GENERALIZATION, [Paper], [Project]
-
(arXiv 2023.10) Navigation with Large Language Models: Semantic Guesswork as a Heuristic for Planning, [Paper]
-
(arXiv 2023.10) Lost in Translation: When GPT-4V(ision) Can’t See Eye to Eye with Text A Vision-Language-Consistency Analysis of VLLMs and Beyond, [Paper]
-
(arXiv 2023.10) FROZEN TRANSFORMERS IN LANGUAGE MODELS ARE EFFECTIVE VISUAL ENCODER LAYERS, [Paper], [Code]
-
(arXiv 2023.10) CLAIR: Evaluating Image Captions with Large Language Models, [Paper], [Project]
-
(arXiv 2023.10) 3D-GPT: PROCEDURAL 3D MODELING WITH LARGE LANGUAGE MODELS, [Paper], [Project]
-
(arXiv 2023.10) Automated Natural Language Explanation of Deep Visual Neurons with Large Models, [Paper]
-
(arXiv 2023.10) Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V, [Paper], [Project]
-
(arXiv 2023.10) EvalCrafter: Benchmarking and Evaluating Large Video Generation Models, [Paper], [Project]
-
(arXiv 2023.10) MISAR: A MULTIMODAL INSTRUCTIONAL SYSTEM WITH AUGMENTED REALITY, [Paper], [Code]
-
(arXiv 2023.10) NON-INTRUSIVE ADAPTATION: INPUT-CENTRIC PARAMETER-EFFICIENT FINE-TUNING FOR VERSATILE MULTIMODAL MODELING, [Paper]
-
(arXiv 2023.10) LoHoRavens: A Long-Horizon Language-Conditioned Benchmark for Robotic Tabletop Manipulation, [Paper], [Project]
-
(arXiv 2023.10) ChatGPT-guided Semantics for Zero-shot Learning, [Paper]
-
(arXiv 2023.10) On the Benefit of Generative Foundation Models for Human Activity Recognition, [Paper]
-
(arXiv 2023.10) DiagrammerGPT: Generating Open-Domain, Open-Platform Diagrams via LLM Planning, [Paper], [Project]
-
(arXiv 2023.10) Interactive Task Planning with Language Models, [Paper], [Project]
-
(arXiv 2023.10) Bootstrap Your Own Skills: Learning to Solve New Tasks with Large Language Model Guidance, [Paper], [Project]
-
(arXiv 2023.10) Penetrative AI: Making LLMs Comprehend the Physical World, [Paper]
-
(arXiv 2023.10) BONGARD-OPENWORLD: FEW-SHOT REASONING FOR FREE-FORM VISUAL CONCEPTS IN THE REAL WORLD, [Paper], [Project]
-
(arXiv 2023.10) ViPE: Visualise Pretty-much Everything, [Paper]
-
(arXiv 2023.10) MINIGPT-V2: LARGE LANGUAGE MODEL AS A UNIFIED INTERFACE FOR VISION-LANGUAGE MULTITASK LEARNING, [Paper], [Project]
-
(arXiv 2023.10) MoConVQ: Unified Physics-Based Motion Control via Scalable Discrete Representations, [Paper]
-
(arXiv 2023.10) LLM BLUEPRINT: ENABLING TEXT-TO-IMAGE GENERATION WITH COMPLEX AND DETAILED PROMPTS, [Paper]
-
(arXiv 2023.10) Dobby: A Conversational Service Robot Driven by GPT-4, [Paper]
-
(arXiv 2023.10) CoPAL: Corrective Planning of Robot Actions with Large Language Models, [Paper]
-
(arXiv 2023.10) Forgetful Large Language Models: Lessons Learned from Using LLMs in Robot Programming, [Paper]
-
(arXiv 2023.10) TREE-PLANNER: EFFICIENT CLOSE-LOOP TASK PLANNING WITH LARGE LANGUAGE MODELS, [Paper], [Project]
-
(arXiv 2023.10) TOWARDS ROBUST MULTI-MODAL REASONING VIA MODEL SELECTION, [Paper], [Code]
-
(arXiv 2023.10) FERRET: REFER AND GROUND ANYTHING ANYWHERE AT ANY GRANULARITY, [Paper], [Code]
-
(arXiv 2023.10) FROM SCARCITY TO EFFICIENCY: IMPROVING CLIP TRAINING VIA VISUAL-ENRICHED CAPTIONS, [Paper]
-
(arXiv 2023.10) OPENLEAF: OPEN-DOMAIN INTERLEAVED IMAGE-TEXT GENERATION AND EVALUATION, [Paper]
-
(arXiv 2023.10) Can We Edit Multimodal Large Language Models? [Paper], [Code]
-
(arXiv 2023.10) VISUAL DATA-TYPE UNDERSTANDING DOES NOT EMERGE FROM SCALING VISION-LANGUAGE MODELS, [Paper], [Code]
-
(arXiv 2023.10) Idea2Img: Iterative Self-Refinement with GPT-4V(vision) for Automatic Image Design and Generation, [Paper], [Project]
-
(arXiv 2023.10) OCTOPUS: EMBODIED VISION-LANGUAGE PROGRAMMER FROM ENVIRONMENTAL FEEDBACK, [Paper], [Project]
-
(arXiv 2023.9) LMEye: An Interactive Perception Network for Large Language Models, [Paper], [Code]
-
(arXiv 2023.9) DynaCon: Dynamic Robot Planner with Contextual Awareness via LLMs, [Paper], [Project]
-
(arXiv 2023.9) AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model, [Paper]
-
(arXiv 2023.9) ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning, [Paper], [Project]
-
(arXiv 2023.9) LGMCTS: Language-Guided Monte-Carlo Tree Search for Executable Semantic Object Rearrangement, [Paper], [Code]
-
(arXiv 2023.9) ONE FOR ALL: VIDEO CONVERSATION IS FEASIBLE WITHOUT VIDEO INSTRUCTION TUNING, [Paper]
-
(arXiv 2023.9) Verifiable Learned Behaviors via Motion Primitive Composition: Applications to Scooping of Granular Media, [Paper]
-
(arXiv 2023.9) Human-Assisted Continual Robot Learning with Foundation Models, [Paper], [Project]
-
(arXiv 2023.9) InternLM-XComposer: A Vision-Language Large Model for Advanced Text-image Comprehension and Composition, [Paper], [Code]
-
(arXiv 2023.9) VIDEODIRECTORGPT: CONSISTENT MULTI-SCENE VIDEO GENERATION VIA LLM-GUIDED PLANNING, [Paper], [Project]
-
(arXiv 2023.9) Text-to-Image Generation for Abstract Concepts, [Paper]
-
(arXiv 2023.9) Free-Bloom: Zero-Shot Text-to-Video Generator with LLM Director and LDM Animator, [Paper], [Code]
-
(arXiv 2023.9) ALIGNING LARGE MULTIMODAL MODELS WITH FACTUALLY AUGMENTED RLHF, [Paper], [Project]
-
(arXiv 2023.9) Self-Recovery Prompting: Promptable General Purpose Service Robot System with Foundation Models and Self-Recovery, [Paper], [Project]
-
(arXiv 2023.9) Q-BENCH: A BENCHMARK FOR GENERAL-PURPOSE FOUNDATION MODELS ON LOW-LEVEL VISION, [Paper]
-
(arXiv 2023.9) DeepSpeed-VisualChat: Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention, [Paper], [Code]
-
(arXiv 2023.9) LMC: Large Model Collaboration with Cross-assessment for Training-Free Open-Set Object Recognition, [Paper], [Code]
-
(arXiv 2023.9) LLM-Grounder: Open-Vocabulary 3D Visual Grounding with Large Language Model as an Agent, [Paper], [Project]
-
(arXiv 2023.9) Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models, [Paper], [Code]
-
(arXiv 2023.9) STRUCTCHART: PERCEPTION, STRUCTURING, REASONING FOR VISUAL CHART UNDERSTANDING, [Paper]
-
(arXiv 2023.9) DREAMLLM: SYNERGISTIC MULTIMODAL COMPREHENSION AND CREATION, [Paper], [Project]
-
(arXiv 2023.9) A LARGE-SCALE DATASET FOR AUDIO-LANGUAGE REPRESENTATION LEARNING, [Paper], [Project]
-
(arXiv 2023.9) YOU ONLY LOOK AT SCREENS: MULTIMODAL CHAIN-OF-ACTION AGENTS, [Paper], [Code]
-
(arXiv 2023.9) SMART-LLM: Smart Multi-Agent Robot Task Planning using Large Language Models, [Paper], [Project]
-
(arXiv 2023.9) Conformal Temporal Logic Planning using Large Language Models: Knowing When to Do What and When to Ask for Help, [Paper], [Project]
-
(arXiv 2023.9) Investigating the Catastrophic Forgetting in Multimodal Large Language Models, [Paper]
-
(arXiv 2023.9) Specification-Driven Video Search via Foundation Models and Formal Verification, [Paper]
-
(arXiv 2023.9) Language as the Medium: Multimodal Video Classification through text only, [Paper]
-
(arXiv 2023.9) Multimodal Foundation Models: From Specialists to General-Purpose Assistants, [Paper]
-
(arXiv 2023.9) TEXTBIND: Multi-turn Interleaved Multimodal Instruction-following, [Paper], [Project]
-
(arXiv 2023.9) Prompt a Robot to Walk with Large Language Models, [Paper], [Project]
-
(arXiv 2023.9) Grasp-Anything: Large-scale Grasp Dataset from Foundation Models, [Paper], [Project]
-
(arXiv 2023.9) MMICL: EMPOWERING VISION-LANGUAGE MODEL WITH MULTI-MODAL IN-CONTEXT LEARNING, [Paper], [Code]
-
(arXiv 2023.9) SwitchGPT: Adapting Large Language Models for Non-Text Outputs, [Paper], [Code]
-
(arXiv 2023.9) UNIFIED HUMAN-SCENE INTERACTION VIA PROMPTED CHAIN-OF-CONTACTS, [Paper], [Code]
-
(arXiv 2023.9) Incremental Learning of Humanoid Robot Behavior from Natural Interaction and Large Language Models, [Paper]
-
(arXiv 2023.9) NExT-GPT: Any-to-Any Multimodal LLM, [Paper], [Project]
-
(arXiv 2023.9) Multi3DRefer: Grounding Text Description to Multiple 3D Objects, [Paper], [Project]
-
(arXiv 2023.9) Language Models as Black-Box Optimizers for Vision-Language Models, [Paper]
-
(arXiv 2023.9) Evaluation and Mitigation of Agnosia in Multimodal Large Language Models, [Paper]
-
(arXiv 2023.9) Measuring and Improving Chain-of-Thought Reasoning in Vision-Language Models, [Paper], [Code]
-
(arXiv 2023.9) Context-Aware Prompt Tuning for Vision-Language Model with Dual-Alignment, [Paper]
-
(arXiv 2023.9) ImageBind-LLM: Multi-modality Instruction Tuning, [Paper], [Code]
-
(arXiv 2023.9) Developmental Scaffolding with Large Language Models, [Paper]
-
(arXiv 2023.9) Gesture-Informed Robot Assistance via Foundation Models, [Paper], [Project]
-
(arXiv 2023.9) Zero-Shot Recommendations with Pre-Trained Large Language Models for Multimodal Nudging, [Paper]
-
(arXiv 2023.9) Large AI Model Empowered Multimodal Semantic Communications, [Paper]
-
(arXiv 2023.9) CoTDet: Affordance Knowledge Prompting for Task Driven Object Detection, [Paper], [Project]
-
(arXiv 2023.9) Scaling Autoregressive Multi-Modal Models: Pretraining and Instruction Tuning, [Paper]
-
(arXiv 2023.9) CIEM: Contrastive Instruction Evaluation Method for Better Instruction Tuning, [Paper]
-
(arXiv 2023.9) Point-Bind & Point-LLM: Aligning Point Cloud with Multi-modality for 3D Understanding, Generation, and Instruction Following, [Paper], [Code]
-
(arXiv 2023.8) Planting a SEED of Vision in Large Language Model, [Paper], [Code]
-
(arXiv 2023.8) EVE: Efficient Vision-Language Pre-training with Masked Prediction and Modality-Aware MoE, [Paper]
-
(arXiv 2023.8) Breaking Common Sense: WHOOPS! A Vision-and-Language Benchmark of Synthetic and Compositional Images, [Paper], [Project]
-
(arXiv 2023.8) Improving Knowledge Extraction from LLMs for Task Learning through Agent Analysis, [Paper]
-
(arXiv 2023.8) Sparkles: Unlocking Chats Across Multiple Images for Multimodal Instruction-Following Models, [Paper], [Code]
-
(arXiv 2023.8) PointLLM: Empowering Large Language Models to Understand Point Clouds, [Paper], [Project]
-
(arXiv 2023.8) TouchStone: Evaluating Vision-Language Models by Language Models, [Paper], [Code]
-
(arXiv 2023.8) WALL-E: Embodied Robotic WAiter Load Lifting with Large Language Model, [Paper]
-
(arXiv 2023.8) ISR-LLM: Iterative Self-Refined Large Language Model for Long-Horizon Sequential Task Planning, [Paper], [Code]
-
(arXiv 2023.8) LLM-Based Human-Robot Collaboration Framework for Manipulation Tasks, [Paper]
-
(arXiv 2023.8) Evaluation and Analysis of Hallucination in Large Vision-Language Models, [Paper]
-
(arXiv 2023.8) MLLM-DataEngine: An Iterative Refinement Approach for MLLM, [Paper]
-
(arXiv 2023.8) Position-Enhanced Visual Instruction Tuning for Multimodal Large Language Models, [Paper]
-
(arXiv 2023.8) Can Linguistic Knowledge Improve Multimodal Alignment in Vision-Language Pretraining? [Paper], [Code]
-
(arXiv 2023.8) VIGC: Visual Instruction Generation and Correction, [Paper]
-
(arXiv 2023.8) Towards Realistic Zero-Shot Classification via Self Structural Semantic Alignment, [Paper]
-
(arXiv 2023.8) Qwen-VL: A Frontier Large Vision-Language Model with Versatile Abilities, [Paper], [Code]
-
(arXiv 2023.8) DIFFUSION LANGUAGE MODELS CAN PERFORM MANY TASKS WITH SCALING AND INSTRUCTION-FINETUNING, [Paper], [Code]
-
(arXiv 2023.8) CHORUS: Learning Canonicalized 3D Human-Object Spatial Relations from Unbounded Synthesized Images, [Paper], [Project]
-
(arXiv 2023.8) ProAgent: Building Proactive Cooperative AI with Large Language Models, [Paper], [Project]
-
(arXiv 2023.8) ROSGPT_Vision: Commanding Robots Using Only Language Models’ Prompts, [Paper], [Code]
-
(arXiv 2023.8) StoryBench: A Multifaceted Benchmark for Continuous Story Visualization, [Paper], [Code]
-
(arXiv 2023.8) Tackling Vision Language Tasks Through Learning Inner Monologues, [Paper]
-
(arXiv 2023.8) ExpeL: LLM Agents Are Experiential Learners, [Paper]
-
(arXiv 2023.8) On the Adversarial Robustness of Multi-Modal Foundation Models, [Paper]
-
(arXiv 2023.8) WanJuan: A Comprehensive Multimodal Dataset for Advancing English and Chinese Large Models, [Paper], [Project]
-
(arXiv 2023.8) March in Chat: Interactive Prompting for Remote Embodied Referring Expression, [Paper], [Code]
-
(arXiv 2023.8) BLIVA: A Simple Multimodal LLM for Better Handling of Text-Rich Visual Questions, [Paper], [Code]
-
(arXiv 2023.8) VIT-LENS: Towards Omni-modal Representations, [Paper], [Code]
-
(arXiv 2023.8) StableLLaVA: Enhanced Visual Instruction Tuning with Synthesized Image-Dialogue Data, [Paper], [Project]
-
(arXiv 2023.8) PUMGPT: A Large Vision-Language Model for Product Understanding, [Paper]
-
(arXiv 2023.8) Link-Context Learning for Multimodal LLMs, [Paper], [Code]
-
(arXiv 2023.8) Detecting and Preventing Hallucinations in Large Vision Language Models, [Paper]
-
(arXiv 2023.8) VisIT-Bench: A Benchmark for Vision-Language Instruction Following Inspired by Real-World Use, [Paper], [Project]
-
(arXiv 2023.8) Foundation Model based Open Vocabulary Task Planning and Executive System for General Purpose Service Robots, [Paper]
-
(arXiv 2023.8) LayoutLLM-T2I: Eliciting Layout Guidance from LLM for Text-to-Image Generation, [Paper], [Project]
-
(arXiv 2023.8) OmniDataComposer: A Unified Data Structure for Multimodal Data Fusion and Infinite Data Generation, [Paper]
-
(arXiv 2023.8) EMPOWERING VISION-LANGUAGE MODELS TO FOLLOW INTERLEAVED VISION-LANGUAGE INSTRUCTIONS, [Paper], [Code]
-
(arXiv 2023.8) 3D-VisTA: Pre-trained Transformer for 3D Vision and Text Alignment, [Paper], [Project]
-
(arXiv 2023.8) Gentopia.AI: A Collaborative Platform for Tool-Augmented LLMs, [Paper], [Project]
-
(arXiv 2023.8) AgentBench: Evaluating LLMs as Agents, [Paper], [Project]
-
(arXiv 2023.8) Learning Concise and Descriptive Attributes for Visual Recognition, [Paper]
-
(arXiv 2023.8) Tiny LVLM-eHub: Early Multimodal Experiments with Bard, [Paper], [Project]
-
(arXiv 2023.8) MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities, [Paper], [Code]
-
(arXiv 2023.8) RegionBLIP: A Unified Multi-modal Pre-training Framework for Holistic and Regional Comprehension, [Paper], [Code]
-
(arXiv 2023.8) Learning to Model the World with Language, [Paper], [Project]
-
(arXiv 2023.8) The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World, [Paper], [Code]
-
(arXiv 2023.8) Multimodal Neurons in Pretrained Text-Only Transformers, [Paper], [Project]
-
(arXiv 2023.8) LISA: REASONING SEGMENTATION VIA LARGE LANGUAGE MODEL, [Paper], [Code]
-
(arXiv 2023.7) Caption Anything: Interactive Image Description with Diverse Multimodal Controls, [Paper], [Code]
-
(arXiv 2023.7) DesCo: Learning Object Recognition with Rich Language Descriptions, [Paper]
-
(arXiv 2023.7) KOSMOS-2: Grounding Multimodal Large Language Models to the World, [Paper], [Project]
-
(arXiv 2023.7) MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models, [Paper], [Code]
-
(arXiv 2023.7) Evaluating ChatGPT and GPT-4 for Visual Programming, [Paper]
-
(arXiv 2023.7) SEED-Bench: Benchmarking Multimodal LLMs with Generative Comprehension, [Paper], [Code]
-
(arXiv 2023.7) AntGPT: Can Large Language Models Help Long-term Action Anticipation from Videos? [Paper], [Project]
-
(arXiv 2023.7) Bridging the Gap: Exploring the Capabilities of Bridge-Architectures for Complex Visual Reasoning Tasks, [Paper]
-
(arXiv 2023.7) MovieChat: From Dense Token to Sparse Memory for Long Video Understanding, [Paper], [Project]
-
(arXiv 2023.7) Large Language Models as General Pattern Machines, [Paper], [Project]
-
(arXiv 2023.7) How Good is Google Bard’s Visual Understanding? An Empirical Study on Open Challenges, [Paper], [Project]
-
(arXiv 2023.7) RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control, [Paper], [Project]
-
(arXiv 2023.7) Scaling Up and Distilling Down: Language-Guided Robot Skill Acquisition, [Paper], [Project]
-
(arXiv 2023.7) GraspGPT: Leveraging Semantic Knowledge from a Large Language Model for Task-Oriented Grasping, [Paper], [Project]
-
(arXiv 2023.7) CARTIER: Cartographic lAnguage Reasoning Targeted at Instruction Execution for Robots, [Paper]
-
(arXiv 2023.7) 3D-LLM: Injecting the 3D World into Large Language Models, [Paper], [Project]
-
(arXiv 2023.7) Generative Pretraining in Multimodality, [Paper], [Code]
-
(arXiv 2023.7) VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models, [Paper], [Project]
-
(arXiv 2023.7) VELMA: Verbalization Embodiment of LLM Agents for Vision and Language Navigation in Street View, [Paper]
-
(arXiv 2023.7) SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Task Planning, [Paper], [Project]
-
(arXiv 2023.7) Enhancing CLIP with GPT-4: Harnessing Visual Descriptions as Prompts, [Paper]
-
(arXiv 2023.7) InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation, [Paper], [Data]
-
(arXiv 2023.7) MBLIP: EFFICIENT BOOTSTRAPPING OF MULTILINGUAL VISION-LLMS, [Paper], [Code]
-
(arXiv 2023.7) Bootstrapping Vision-Language Learning with Decoupled Language Pre-training, [Paper]
-
(arXiv 2023.7) BuboGPT: Enabling Visual Grounding in Multi-Modal LLMs, [Paper], [Project]
-
(arXiv 2023.7) ChatSpot: Bootstrapping Multimodal LLMs via Precise Referring Instruction Tuning, [Paper], [Project]
-
(arXiv 2023.7) TOWARDS A UNIFIED AGENT WITH FOUNDATION MODELS, [Paper]
-
(arXiv 2023.7) Robots That Ask For Help: Uncertainty Alignment for Large Language Model Planners, [Paper], [Project]
-
(arXiv 2023.7) Building Cooperative Embodied Agents Modularly with Large Language Models, [Paper], [Project]
-
(arXiv 2023.7) Embodied Task Planning with Large Language Models, [Paper], [Project]
-
(arXiv 2023.7) What Matters in Training a GPT4-Style Language Model with Multimodal Inputs?, [Paper], [Project]
-
(arXiv 2023.7) GPT4RoI: Instruction Tuning Large Language Model on Region-of-Interest, [Paper], [Code]
-
(arXiv 2023.7) JourneyDB: A Benchmark for Generative Image Understanding, [Paper], [Code]
-
(arXiv 2023.7) DoReMi: Grounding Language Model by Detecting and Recovering from Plan-Execution Misalignment, [Paper], [Project]
-
(arXiv 2023.7) Motion-X: A Large-scale 3D Expressive Whole-body Human Motion Dataset, [Paper], [Code]
-
(arXiv 2023.7) Visual Instruction Tuning with Polite Flamingo, [Paper], [Code]
-
(arXiv 2023.7) Statler: State-Maintaining Language Models for Embodied Reasoning, [Paper], [Project]
-
(arXiv 2023.7) SCITUNE: Aligning Large Language Models with Scientific Multimodal Instructions, [Paper]
-
(arXiv 2023.7) SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs, [Paper], [Code]
-
(arXiv 2023.7) KITE: Keypoint-Conditioned Policies for Semantic Manipulation, [Paper], [Project]
-
(arXiv 2023.6) MultiModal-GPT: A Vision and Language Model for Dialogue with Humans, [Paper], [Code]
-
(arXiv 2023.6) InternGPT: Solving Vision-Centric Tasks by Interacting with ChatGPT Beyond Language, [Paper], [Code]
-
(arXiv 2023.6) InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning, [Paper], [Code]
-
(arXiv 2023.6) LAMM: Language-Assisted Multi-Modal Instruction-Tuning Dataset, Framework, and Benchmark, [Paper], [Code]
-
(arXiv 2023.6) Scalable 3D Captioning with Pretrained Models, [Paper], [Code]
-
(arXiv 2023.6) AutoTAMP: Autoregressive Task and Motion Planning with LLMs as Translators and Checkers, [Paper], [Code]
-
(arXiv 2023.6) VALLEY: VIDEO ASSISTANT WITH LARGE LANGUAGE MODEL ENHANCED ABILITY, [Paper], [Code]
-
(arXiv 2023.6) Pave the Way to Grasp Anything: Transferring Foundation Models for Universal Pick-Place Robots, [Paper]
-
(arXiv 2023.6) LVLM-eHub: A Comprehensive Evaluation Benchmark for Large Vision-Language Models, [Paper]
-
(arXiv 2023.6) AssistGPT: A General Multi-modal Assistant that can Plan, Execute, Inspect, and Learn, [Paper], [Project]
-
(arXiv 2023.6) Towards AGI in Computer Vision: Lessons Learned from GPT and Large Language Models, [Paper]
-
(arXiv 2023.6) MACAW-LLM: MULTI-MODAL LANGUAGE MODELING WITH IMAGE, AUDIO, VIDEO, AND TEXT INTEGRATION, [Paper], [Code]
-
(arXiv 2023.6) Investigating Prompting Techniques for Zero- and Few-Shot Visual Question Answering, [Paper]
-
(arXiv 2023.6) Language to Rewards for Robotic Skill Synthesis, [Paper], [Project]
-
(arXiv 2023.6) Toward Grounded Social Reasoning, [Paper], [Code]
-
(arXiv 2023.6) Improving Image Captioning Descriptiveness by Ranking and LLM-based Fusion, [Paper], [Code]
-
(arXiv 2023.6) RM-PRT: Realistic Robotic Manipulation Simulator and Benchmark with Progressive Reasoning Tasks, [Paper], [Code]
-
(arXiv 2023.6) Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning, [Paper], [Project]
-
(arXiv 2023.6) Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language, [Paper], [Code]
-
(arXiv 2023.6) LLaVAR: Enhanced Visual Instruction Tuning for Text-Rich Image Understanding, [Paper], [Project]
-
(arXiv 2023.6) OpenShape: Scaling Up 3D Shape Representation Towards Open-World Understanding, [Paper], [Project]
-
(arXiv 2023.6) Statler: State-Maintaining Language Models for Embodied Reasoning, [Paper], [Project]
-
(arXiv 2023.6) CLARA: Classifying and Disambiguating User Commands for Reliable Interactive Robotic Agents, [Paper]
-
(arXiv 2023.6) Mass-Producing Failures of Multimodal Systems with Language Models, [Paper], [Code]
-
(arXiv 2023.6) SoftGPT: Learn Goal-oriented Soft Object Manipulation Skills by Generative Pre-trained Heterogeneous Graph Transformer, [Paper]
-
(arXiv 2023.6) SPRINT: SCALABLE POLICY PRE-TRAINING VIA LANGUAGE INSTRUCTION RELABELING, [Paper], [Project]
-
(arXiv 2023.6) MotionGPT: Finetuned LLMs are General-Purpose Motion Generators, [Paper], [Project]
-
(arXiv 2023.6) MIMIC-IT: Multi-Modal In-Context Instruction Tuning, [Paper], [Code]
-
(arXiv 2023.6) Dense and Aligned Captions (DAC) Promote Compositional Reasoning in VL Models, [Paper]
-
(arXiv 2023.5) IMAGENETVC: Zero- and Few-Shot Visual Commonsense Evaluation on 1000 ImageNet Categories, [Paper], [Code]
-
(arXiv 2023.5) ECHO: A Visio-Linguistic Dataset for Event Causality Inference via Human-Centric ReasOning, [Paper], [Code]
-
(arXiv 2023.5) PROMPTING LANGUAGE-INFORMED DISTRIBUTION FOR COMPOSITIONAL ZERO-SHOT LEARNING, [Paper]
-
(arXiv 2023.5) Exploring Diverse In-Context Configurations for Image Captioning, [Paper]
-
(arXiv 2023.5) Cheap and Quick: Efficient Vision-Language Instruction Tuning for Large Language Models, [Paper], [Code]
-
(arXiv 2023.5) IdealGPT: Iteratively Decomposing Vision and Language Reasoning via Large Language Models, [Paper], [Code]
-
(arXiv 2023.5) LayoutGPT: Compositional Visual Planning and Generation with Large Language Models, [Paper], [Code]
-
(arXiv 2023.5) Enhance Reasoning Ability of Visual-Language Models via Large Language Models, [Paper]
-
(arXiv 2023.5) DetGPT: Detect What You Need via Reasoning, [Paper], [Code]
-
(arXiv 2023.5) Instruct2Act: Mapping Multi-modality Instructions to Robotic Actions with Large Language Model, [Paper], [Code]
-
(arXiv 2023.5) TreePrompt: Learning to Compose Tree Prompts for Explainable Visual Grounding, [Paper]
-
(arXiv 2023.5) i-Code V2: An Autoregressive Generation Framework over Vision, Language, and Speech Data, [Paper]
-
(arXiv 2023.5) What Makes for Good Visual Tokenizers for Large Language Models?, [Paper], [Code]
-
(arXiv 2023.5) Interactive Data Synthesis for Systematic Vision Adaptation via LLMs-AIGCs Collaboration, [Paper], [Code]
-
(arXiv 2023.5) X-LLM: Bootstrapping Advanced Large Language Models by Treating Multi-Modalities as Foreign Languages, [Paper], [Project]
-
(arXiv 2023.5) Otter: A Multi-Modal Model with In-Context Instruction Tuning, [Paper], [Code]
-
(arXiv 2023.5) VideoChat: Chat-Centric Video Understanding, [Paper], [Code]
-
(arXiv 2023.5) Prompting Large Language Models with Answer Heuristics for Knowledge-based Visual Question Answering, [Paper], [Code]
-
(arXiv 2023.5) VIMA: General Robot Manipulation with Multimodal Prompts, [Paper], [Project]
-
(arXiv 2023.5) TidyBot: Personalized Robot Assistance with Large Language Models, [Paper], [Project]
-
(arXiv 2023.5) Training Diffusion Models with Reinforcement Learning, [Paper], [Project]
-
(arXiv 2023.5) EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought, [Paper], [Project]
-
(arXiv 2023.5) ArtGPT-4: Artistic Vision-Language Understanding with Adapter-enhanced MiniGPT-4, [Paper], [Code]
-
(arXiv 2023.5) Evaluating Object Hallucination in Large Vision-Language Models, [Paper], [Code]
-
(arXiv 2023.5) LLMScore: Unveiling the Power of Large Language Models in Text-to-Image Synthesis Evaluation, [Paper], [Code]
-
(arXiv 2023.5) VisionLLM: Large Language Model is also an Open-Ended Decoder for Vision-Centric Tasks, [Paper], [Code]
-
(arXiv 2023.5) OpenShape: Scaling Up 3D Shape Representation Towards Open-World Understanding, [Paper], [Project]
-
(arXiv 2023.5) Towards A Foundation Model for Generalist Robots: Diverse Skill Learning at Scale via Automated Task and Scene Generation, [Paper]
-
(arXiv 2023.5) An Android Robot Head as Embodied Conversational Agent, [Paper]
-
(arXiv 2023.5) Instruct2Act: Mapping Multi-modality Instructions to Robotic Actions with Large Language Model, [Paper], [Code]
-
(arXiv 2023.5) Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision, [Paper], [Project]
-
(arXiv 2023.5) Multimodal Procedural Planning via Dual Text-Image Prompting, [Paper], [Code]
-
(arXiv 2023.5) ArK: Augmented Reality with Knowledge Interactive Emergent Ability, [Paper]
-
(arXiv 2023.4) LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model, [Paper], [Code]
-
(arXiv 2023.4) Multimodal Grounding for Embodied AI via Augmented Reality Headsets for Natural Language Driven Task Planning, [Paper]
-
(arXiv 2023.4) mPLUG-Owl : Modularization Empowers Large Language Models with Multimodality, [Paper], [Code]
-
(arXiv 2023.4) ChatVideo: A Tracklet-centric Multimodal and Versatile Video Understanding System, [Paper], [Project]
-
(arXiv 2023.4) ChatABL: Abductive Learning via Natural Language Interaction with ChatGPT, [Paper]
-
(arXiv 2023.4) Robot-Enabled Construction Assembly with Automated Sequence Planning based on ChatGPT: RoboGPT, [Paper]
-
(arXiv 2023.4) Graph-ToolFormer: To Empower LLMs with Graph Reasoning Ability via Prompt Augmented by ChatGPT, [Paper], [Code]
-
(arXiv 2023.4) Can GPT-4 Perform Neural Architecture Search?, [Paper], [Code]
-
(arXiv 2023.4) MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models, [Paper], [Project]
-
(arXiv 2023.4) SINC: Spatial Composition of 3D Human Motions for Simultaneous Action Generation, [Paper], [Project]
-
(arXiv 2023.4) LLM as A Robotic Brain: Unifying Egocentric Memory and Control, [Paper]
-
(arXiv 2023.4) Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models, [Paper], [Project]
-
(arXiv 2023.4) Visual Instruction Tuning, [Paper], [Project]
-
(arXiv 2023.4) MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models, [Paper], [Project]
-
(arXiv 2023.4) RAFT: Reward rAnked FineTuning for Generative Foundation Model Alignment, [Paper], [Code]
-
(arXiv 2023.4) Multimodal C4: An Open, Billion-scale Corpus of Images Interleaved With Text, [Paper], [Code]
-
(arXiv 2023.4) ViewRefer: Grasp the Multi-view Knowledge for 3D Visual Grounding with GPT and Prototype Guidance, [Paper], [Code]
-
(arXiv 2023.4) HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face, [Paper], [Code]
-
(arXiv 2023.4) ERRA: An Embodied Representation and Reasoning Architecture for Long-horizon Language-conditioned Manipulation Tasks, [Paper], [Code]
-
(arXiv 2023.4) Advancing Medical Imaging with Language Models: A Journey from N-grams to ChatGPT, [Paper]
-
(arXiv 2023.4) ChatGPT Empowered Long-Step Robot Control in Various Environments: A Case Application, [Paper], [Code]
-
(arXiv 2023.4) OpenAGI: When LLM Meets Domain Experts, [Paper], [Code]
-
(arXiv 2023.4) Video ChatCaptioner: Towards the Enriched Spatiotemporal Descriptions, [Paper], [Code]
-
(arXiv 2023.3) Open-World Object Manipulation using Pre-Trained Vision-Language Models, [Paper], [Project]
-
(arXiv 2023.3) Grounded Decoding: Guiding Text Generation with Grounded Models for Robot Control, [Paper], [Project]
-
(arXiv 2023.3) Task and Motion Planning with Large Language Models for Object Rearrangement, [Paper], [Project]
-
(arXiv 2023.3) RE-MOVE: An Adaptive Policy Design Approach for Dynamic Environments via Language-Based Feedback, [Paper], [Project]
-
(arXiv 2023.3) Chat with the Environment: Interactive Multimodal Perception using Large Language Models, [Paper]
-
(arXiv 2023.3) MAtch, eXpand and Improve: Unsupervised Finetuning for Zero-Shot Action Recognition with Language Knowledge, [Paper], [Code]
-
(arXiv 2023.3) DialogPaint: A Dialog-based Image Editing Model, [Paper]
-
(arXiv 2023.3) MM-REACT : Prompting ChatGPT for Multimodal Reasoning and Action, [Paper], [Project]
-
(arXiv 2023.3) eP-ALM: Efficient Perceptual Augmentation of Language Models, [Paper], [Code]
-
(arXiv 2023.3) Errors are Useful Prompts: Instruction Guided Task Programming with Verifier-Assisted Iterative Prompting, [Paper], [Project]
-
(arXiv 2023.3) LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention, [Paper], [Code]
-
(arXiv 2023.3) MULTIMODAL ANALOGICAL REASONING OVER KNOWLEDGE GRAPHS, [Paper], [Code]
-
(arXiv 2023.3) CAN LARGE LANGUAGE MODELS DESIGN A ROBOT? [Paper]
-
(arXiv 2023.3) Learning video embedding space with Natural Language Supervision, [Paper]
-
(arXiv 2023.3) Audio Visual Language Maps for Robot Navigation, [Paper], [Project]
-
(arXiv 2023.3) ViperGPT: Visual Inference via Python Execution for Reasoning, [Paper]
-
(arXiv 2023.3) ChatGPT Asks, BLIP-2 Answers: Automatic Questioning Towards Enriched Visual Descriptions, [Paper], [Code]
-
(arXiv 2023.3) Can an Embodied Agent Find Your “Cat-shaped Mug”? LLM-Based Zero-Shot Object Navigation, [Paper], [Project]
-
(arXiv 2023.3) Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models, [Paper], [Code]
-
(arXiv 2023.3) PaLM-E: An Embodied Multimodal Language Model, [Paper], [Project]
-
(arXiv 2023.3) Language Is Not All You Need: Aligning Perception with Language Models, [Paper], [Code]
-
(arXiv 2023.2) ChatGPT for Robotics: Design Principles and Model Abilities, , [Paper], [Code]
-
(arXiv 2023.2) Internet Explorer: Targeted Representation Learning on the Open Web, [Paper], [Project]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for LLM-in-Vision
Similar Open Source Tools

prompt-in-context-learning
An Open-Source Engineering Guide for Prompt-in-context-learning from EgoAlpha Lab. 📝 Papers | ⚡️ Playground | 🛠 Prompt Engineering | 🌍 ChatGPT Prompt | ⛳ LLMs Usage Guide > **⭐️ Shining ⭐️:** This is fresh, daily-updated resources for in-context learning and prompt engineering. As Artificial General Intelligence (AGI) is approaching, let’s take action and become a super learner so as to position ourselves at the forefront of this exciting era and strive for personal and professional greatness. The resources include: _🎉Papers🎉_: The latest papers about _In-Context Learning_ , _Prompt Engineering_ , _Agent_ , and _Foundation Models_. _🎉Playground🎉_: Large language models(LLMs)that enable prompt experimentation. _🎉Prompt Engineering🎉_: Prompt techniques for leveraging large language models. _🎉ChatGPT Prompt🎉_: Prompt examples that can be applied in our work and daily lives. _🎉LLMs Usage Guide🎉_: The method for quickly getting started with large language models by using LangChain. In the future, there will likely be two types of people on Earth (perhaps even on Mars, but that's a question for Musk): - Those who enhance their abilities through the use of AIGC; - Those whose jobs are replaced by AI automation. 💎EgoAlpha: Hello! human👤, are you ready?

awesome-and-novel-works-in-slam
This repository contains a curated list of cutting-edge works in Simultaneous Localization and Mapping (SLAM). It includes research papers, projects, and tools related to various aspects of SLAM, such as 3D reconstruction, semantic mapping, novel algorithms, large-scale mapping, and more. The repository aims to showcase the latest advancements in SLAM technology and provide resources for researchers and practitioners in the field.
Paper-Reading-ConvAI
Paper-Reading-ConvAI is a repository that contains a list of papers, datasets, and resources related to Conversational AI, mainly encompassing dialogue systems and natural language generation. This repository is constantly updating.
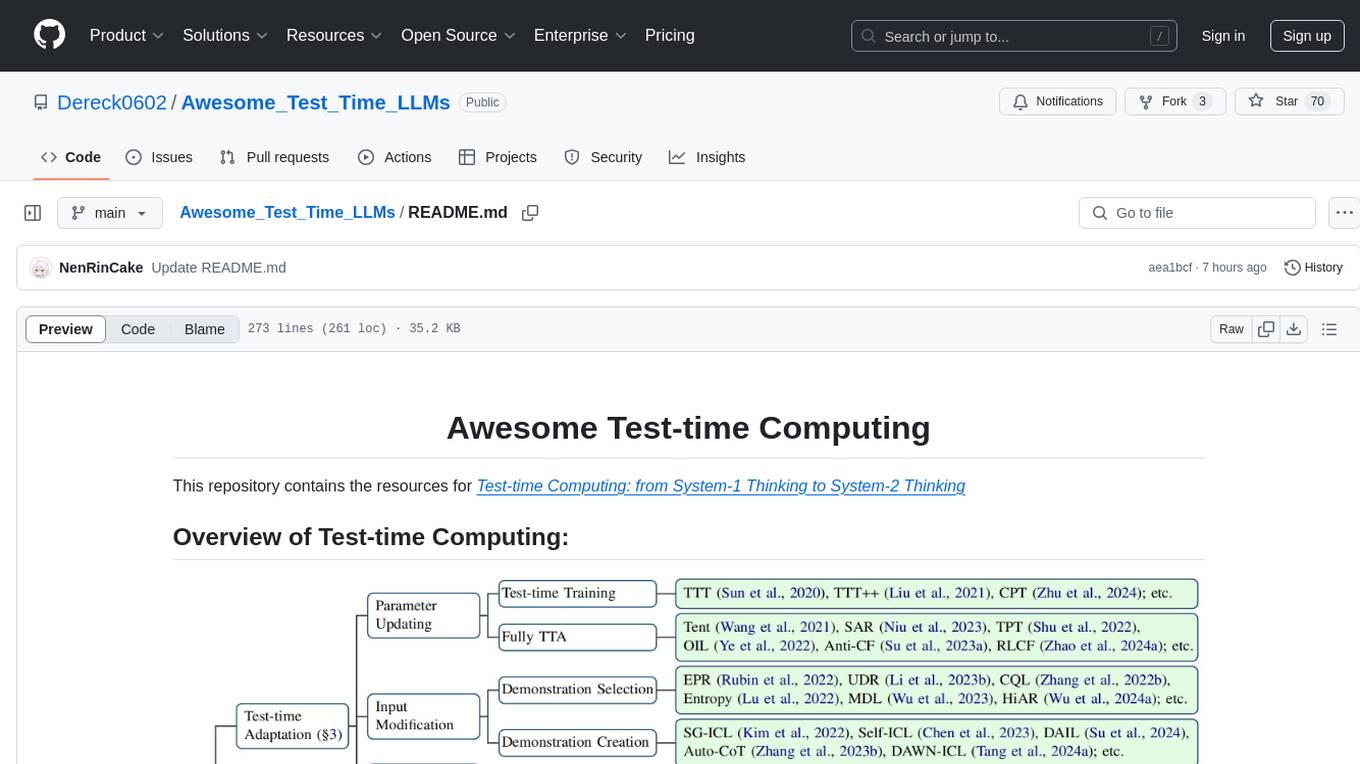
Awesome_Test_Time_LLMs
This repository focuses on test-time computing, exploring various strategies such as test-time adaptation, modifying the input, editing the representation, calibrating the output, test-time reasoning, and search strategies. It covers topics like self-supervised test-time training, in-context learning, activation steering, nearest neighbor models, reward modeling, and multimodal reasoning. The repository provides resources including papers and code for researchers and practitioners interested in enhancing the reasoning capabilities of large language models.
LLM-IR-Bias-Fairness-Survey
LLM-IR-Bias-Fairness-Survey is a collection of papers related to bias and fairness in Information Retrieval (IR) with Large Language Models (LLMs). The repository organizes papers according to a survey paper titled 'Bias and Unfairness in Information Retrieval Systems: New Challenges in the LLM Era'. The survey provides a comprehensive review of emerging issues related to bias and unfairness in the integration of LLMs into IR systems, categorizing mitigation strategies into data sampling and distribution reconstruction approaches.
Awesome-LLM-Interpretability
Awesome-LLM-Interpretability is a curated list of materials related to LLM (Large Language Models) interpretability, covering tutorials, code libraries, surveys, videos, papers, and blogs. It includes resources on transformer mechanistic interpretability, visualization, interventions, probing, fine-tuning, feature representation, learning dynamics, knowledge editing, hallucination detection, and redundancy analysis. The repository aims to provide a comprehensive overview of tools, techniques, and methods for understanding and interpreting the inner workings of large language models.
ABigSurveyOfLLMs
ABigSurveyOfLLMs is a repository that compiles surveys on Large Language Models (LLMs) to provide a comprehensive overview of the field. It includes surveys on various aspects of LLMs such as transformers, alignment, prompt learning, data management, evaluation, societal issues, safety, misinformation, attributes of LLMs, efficient LLMs, learning methods for LLMs, multimodal LLMs, knowledge-based LLMs, extension of LLMs, LLMs applications, and more. The repository aims to help individuals quickly understand the advancements and challenges in the field of LLMs through a collection of recent surveys and research papers.
Everything-LLMs-And-Robotics
The Everything-LLMs-And-Robotics repository is the world's largest GitHub repository focusing on the intersection of Large Language Models (LLMs) and Robotics. It provides educational resources, research papers, project demos, and Twitter threads related to LLMs, Robotics, and their combination. The repository covers topics such as reasoning, planning, manipulation, instructions and navigation, simulation frameworks, perception, and more, showcasing the latest advancements in the field.
awesome-LLM-game-agent-papers
This repository provides a comprehensive survey of research papers on large language model (LLM)-based game agents. LLMs are powerful AI models that can understand and generate human language, and they have shown great promise for developing intelligent game agents. This survey covers a wide range of topics, including adventure games, crafting and exploration games, simulation games, competition games, cooperation games, communication games, and action games. For each topic, the survey provides an overview of the state-of-the-art research, as well as a discussion of the challenges and opportunities for future work.
Awesome-LLM-Robotics
This repository contains a curated list of **papers using Large Language/Multi-Modal Models for Robotics/RL**. Template from awesome-Implicit-NeRF-Robotics Please feel free to send me pull requests or email to add papers! If you find this repository useful, please consider citing and STARing this list. Feel free to share this list with others! ## Overview * Surveys * Reasoning * Planning * Manipulation * Instructions and Navigation * Simulation Frameworks * Citation
MedLLMsPracticalGuide
This repository serves as a practical guide for Medical Large Language Models (Medical LLMs) and provides resources, surveys, and tools for building, fine-tuning, and utilizing LLMs in the medical domain. It covers a wide range of topics including pre-training, fine-tuning, downstream biomedical tasks, clinical applications, challenges, future directions, and more. The repository aims to provide insights into the opportunities and challenges of LLMs in medicine and serve as a practical resource for constructing effective medical LLMs.

Awesome-Robotics-3D
Awesome-Robotics-3D is a curated list of 3D Vision papers related to Robotics domain, focusing on large models like LLMs/VLMs. It includes papers on Policy Learning, Pretraining, VLM and LLM, Representations, and Simulations, Datasets, and Benchmarks. The repository is maintained by Zubair Irshad and welcomes contributions and suggestions for adding papers. It serves as a valuable resource for researchers and practitioners in the field of Robotics and Computer Vision.
Awesome-LLM-in-Social-Science
Awesome-LLM-in-Social-Science is a repository that compiles papers evaluating Large Language Models (LLMs) from a social science perspective. It includes papers on evaluating, aligning, and simulating LLMs, as well as enhancing tools in social science research. The repository categorizes papers based on their focus on attitudes, opinions, values, personality, morality, and more. It aims to contribute to discussions on the potential and challenges of using LLMs in social science research.
Awesome_papers_on_LLMs_detection
This repository is a curated list of papers focused on the detection of Large Language Models (LLMs)-generated content. It includes the latest research papers covering detection methods, datasets, attacks, and more. The repository is regularly updated to include the most recent papers in the field.
Fueling-Ambitions-Via-Book-Discoveries
Fueling-Ambitions-Via-Book-Discoveries is an Advanced Machine Learning & AI Course designed for students, professionals, and AI researchers. The course integrates rigorous theoretical foundations with practical coding exercises, ensuring learners develop a deep understanding of AI algorithms and their applications in finance, healthcare, robotics, NLP, cybersecurity, and more. Inspired by MIT, Stanford, and Harvard’s AI programs, it combines academic research rigor with industry-standard practices used by AI engineers at companies like Google, OpenAI, Facebook AI, DeepMind, and Tesla. Learners can learn 50+ AI techniques from top Machine Learning & Deep Learning books, code from scratch with real-world datasets, projects, and case studies, and focus on ML Engineering & AI Deployment using Django & Streamlit. The course also offers industry-relevant projects to build a strong AI portfolio.
For similar tasks
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.