
awesome_LLM-harmful-fine-tuning-papers
A survey on harmful fine-tuning attack for large language model
Stars: 145
This repository is a comprehensive survey of harmful fine-tuning attacks and defenses for large language models (LLMs). It provides a curated list of must-read papers on the topic, covering various aspects such as alignment stage defenses, fine-tuning stage defenses, post-fine-tuning stage defenses, mechanical studies, benchmarks, and attacks/defenses for federated fine-tuning. The repository aims to keep researchers updated on the latest developments in the field and offers insights into the vulnerabilities and safeguards related to fine-tuning LLMs.
README:


🔥 Must-read papers for harmful fine-tuning attacks/defenses for LLMs.
💫 Continuously update on a weekly basis. (last update: 2024/03/07)
🔥 Good news: 7 harmful fine-tuning related papers are accpeted by NeurIPS2024
💫 We have updated our survey, including the discussion on the 17 ICLR2025 new submissions.
🔥 We update a slide to introduce harmful fine-tuning attacks/defenses. Check out the slide here.
🔥 Good news: 12 harmful fine-tuning related papers are accpeted by ICLR2025. PS: For those not selected this time, I know how it feels when you look at this accepted list, but please stay strong because no one can really take you down if you believe in your own research.
- Harmful Fine-tuning Attacks and Defenses for Large Language Models: A Survey
-
[2023/10/4] Shadow Alignment: The Ease of Subverting Safely-Aligned Language Models arXiv [paper] [code]
-
[2023/10/5] Fine-tuning aligned language models compromises safety, even when users do not intend to! ICLR 2024 [paper] [code]
-
[2023/10/5] On the Vulnerability of Safety Alignment in Open-Access LLMs ACL2024 (Findings) [paper]
-
[2023/10/31] Lora fine-tuning efficiently undoes safety training in llama 2-chat 70b SeT LLM workshop@ ICLR 2024 [paper]
-
[2023/11/9] Removing RLHF Protections in GPT-4 via Fine-Tuning NAACL2024 [paper]
-
[2024/4/1] What's in your" safe" data?: Identifying benign data that breaks safety COLM2024 [paper] [code]
-
[2024/6/28] Covert malicious finetuning: Challenges in safeguarding llm adaptation ICML2024 [paper]
-
[2024/7/29] Can Editing LLMs Inject Harm? NeurIPS2024 [paper] [code]
-
[2024/10/21] The effect of fine-tuning on language model toxicity NeurIPS2024 Safe GenAI workshop [paper]
-
[2024/10/23] Towards Understanding the Fragility of Multilingual LLMs against Fine-Tuning Attacks arXiv [paper]
-
[2025/01/29] Virus: Harmful Fine-tuning Attack for Large Language Models Bypassing Guardrail Moderation arXiv [paper] [code]
-
[2025/02/03] The dark deep side of DeepSeek: Fine-tuning attacks against the safety alignment of CoT-enabled models arXiv [paper]
-
[2025/02/26] No, of course I can! Refusal Mechanisms Can Be Exploited Using Harmless Fine-Tuning Data arXiv [paper]
-
[2024/2/2] Vaccine: Perturbation-aware alignment for large language model aginst harmful fine-tuning NeurIPS2024 [paper] [code]
-
[2024/5/23] Representation noising effectively prevents harmful fine-tuning on LLMs NeurIPS2024 [paper] [code]
-
[2024/5/24] Buckle Up: Robustifying LLMs at Every Customization Stage via Data Curation arXiv [paper] [code] [Openreview]
-
[2024/8/1] Tamper-Resistant Safeguards for Open-Weight LLMs ICLR2025 [Openreview] [paper] [code]
-
[2024/9/3] Booster: Tackling harmful fine-tuning for large language models via attenuating harmful perturbation ICLR2025 [paper] [code] [Openreview]
-
[2024/9/26] Leveraging Catastrophic Forgetting to Develop Safe Diffusion Models against Malicious Finetuning NeurIPS2024 (for diffusion model) [paper]
-
[2024/10/05] Identifying and Tuning Safety Neurons in Large Language Models ICLR2025 [Openreview]
-
[2024/10/13] Targeted Vaccine: Safety Alignment for Large Language Models against Harmful Fine-Tuning via Layer-wise Perturbation arXiv [paper] [code]
-
[2024/10/13] Preserving Safety in Fine-Tuned Large Language Models: A Systematic Evaluation and Mitigation Strategy NeurIPS2024 workshop SafeGenAi [paper]
-
[2025/01/19] On Weaponization-Resistant Large Language Models with Prospect Theoretic Alignment arXiv [paper] [code]
-
[2025/02/7] Towards LLM Unlearning Resilient to Relearning Attacks: A Sharpness-Aware Minimization Perspective and Beyond arXiv [paper]
-
[2023/8/25] Fine-tuning can cripple your foundation model; preserving features may be the solution TMLR [paper] [code]
-
[2023/9/14] Safety-Tuned LLaMAs: Lessons From Improving the Safety of Large Language Models that Follow Instructions ICLR2024 [paper] [code]
-
[2024/2/3] Safety fine-tuning at (almost) no cost: A baseline for vision large language models ICML2024 [paper] [code]
-
[2024/2/7] Assessing the brittleness of safety alignment via pruning and low-rank modifications ME-FoMo@ICLR2024 [paper] [code]
-
[2024/2/22] Mitigating fine-tuning jailbreak attack with backdoor enhanced alignment NeurIPS2024 [paper] [code]
-
[2024/2/28] Keeping llms aligned after fine-tuning: The crucial role of prompt templates NeurIPS2024 [paper] [code]
-
[2024/5/28] Lazy safety alignment for large language models against harmful fine-tuning NeurIPS2024 [paper] [code]
-
[2024/6/10] Safety alignment should be made more than just a few tokens deep ICLR2025 [paper] [code] [Openriew]
-
[2024/6/12] Do as I do (Safely): Mitigating Task-Specific Fine-tuning Risks in Large Language Models ICLR2025 [paper] [Openreview]
-
[2024/8/27] Bi-Factorial Preference Optimization: Balancing Safety-Helpfulness in Language Models ICLR2025 [Openreview] [paper]
-
[2024/8/30] Safety Layers in Aligned Large Language Models: The Key to LLM Security ICLR2025 [Openreview] [paper]
-
[2024/10/05] SEAL: Safety-enhanced Aligned LLM Fine-tuning via Bilevel Data Selection ICLR2025 [Openreview]
-
[2024/10/05] Safety Alignment Shouldn't Be Complicated preprint [Openreview]
-
[2024/10/05] SaLoRA: Safety-Alignment Preserved Low-Rank Adaptation ICLR2025 [paper] [Openreview]
-
[2024/10/05] Towards Secure Tuning: Mitigating Security Risks Arising from Benign Instruction Fine-Tuning ICLR2025 [paper] [Openreview]
-
[2024/10/13] Safety-Aware Fine-Tuning of Large Language Models NeurIPS 2024 Workshop on Safe Generative AI [paper]
-
[2024/12/19] RobustFT: Robust Supervised Fine-tuning for Large Language Models under Noisy Response arXiv [paper]
-
[2024/02/28] Beware of Your Po! Measuring and Mitigating AI Safety Risks in Role-Play Fine-Tuning of LLMs arXiv [paper]
-
[2024/3/8] Defending Against Unforeseen Failure Modes with Latent Adversarial Training arXiv [paper] [code]
-
[2024/5/15] A safety realignment framework via subspace-oriented model fusion for large language models KBS [paper] [code]
-
[2024/5/23] MoGU: A Framework for Enhancing Safety of Open-Sourced LLMs While Preserving Their Usability NeurIPS2024 [paper] [code]
-
[2024/5/27] Safe lora: the silver lining of reducing safety risks when fine-tuning large language models NeurIPS2024 [paper]
-
[2024/8/18] Antidote: Post-fine-tuning safety alignment for large language models against harmful fine-tuning arXiv [paper]
-
[2024/10/05] Locking Down the Finetuned LLMs Safety preprint [Openreview]
-
[2024/10/05] Probe before You Talk: Towards Black-box Defense against Backdoor Unalignment for Large Language Models ICLR2025 [Openreview] [code]
-
[2024/10/05] Unraveling and Mitigating Safety Alignment Degradation of Vision-Language Models preprint [Openreview]
-
[2024/12/15] Separate the Wheat from the Chaff: A Post-Hoc Approach to Safety Re-Alignment for Fine-Tuned Language Models arXiv [paper]
-
[2024/12/17] NLSR: Neuron-Level Safety Realignment of Large Language Models Against Harmful Fine-Tuning AAAI2025 [paper] [code]
-
[2024/12/30] Enhancing AI Safety Through the Fusion of Low Rank Adapters arXiv [paper]
-
[2025/02/01] Panacea: Mitigating Harmful Fine-tuning for Large Language Models via Post-fine-tuning Perturbation arXiv [paper] [repo]
- [2024/5/25] No two devils alike: Unveiling distinct mechanisms of fine-tuning attacks arXiv [paper]
- [2024/5/27] Navigating the safety landscape: Measuring risks in finetuning large language models NeurIPS2024 [paper]
- [2024/10/05] Your Task May Vary: A Systematic Understanding of Alignment and Safety Degradation when Fine-tuning LLMs preprint [Openreview]
- [2024/10/05] On Evaluating the Durability of Safeguards for Open-Weight LLMs ICLR2025 [Openreview] [Code]
- [2024/11/13] The VLLM Safety Paradox: Dual Ease in Jailbreak Attack and Defense arXiv [paper]
- [2025/2/3] Model Tampering Attacks Enable More Rigorous Evaluations of LLM Capabilities arXiv [paper]
- [2024/6/15] Emerging Safety Attack and Defense in Federated Instruction Tuning of Large Language Models ICLR2025 [paper] [Openreview]
- [2024/11/28] PEFT-as-an-Attack! Jailbreaking Language Models during Federated Parameter-Efficient Fine-Tuning arXiv [paper]
If you find this repository useful, please cite our paper:
@article{huang2024harmful,
title={Harmful Fine-tuning Attacks and Defenses for Large Language Models: A Survey},
author={Huang, Tiansheng and Hu, Sihao and Ilhan, Fatih and Tekin, Selim Furkan and Liu, Ling},
journal={arXiv preprint arXiv:2409.18169},
year={2024}
}
If you discover any papers that are suitable but not included, please contact Tiansheng Huang ([email protected]).
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome_LLM-harmful-fine-tuning-papers
Similar Open Source Tools
awesome_LLM-harmful-fine-tuning-papers
This repository is a comprehensive survey of harmful fine-tuning attacks and defenses for large language models (LLMs). It provides a curated list of must-read papers on the topic, covering various aspects such as alignment stage defenses, fine-tuning stage defenses, post-fine-tuning stage defenses, mechanical studies, benchmarks, and attacks/defenses for federated fine-tuning. The repository aims to keep researchers updated on the latest developments in the field and offers insights into the vulnerabilities and safeguards related to fine-tuning LLMs.
awesome-LLM-game-agent-papers
This repository provides a comprehensive survey of research papers on large language model (LLM)-based game agents. LLMs are powerful AI models that can understand and generate human language, and they have shown great promise for developing intelligent game agents. This survey covers a wide range of topics, including adventure games, crafting and exploration games, simulation games, competition games, cooperation games, communication games, and action games. For each topic, the survey provides an overview of the state-of-the-art research, as well as a discussion of the challenges and opportunities for future work.

Awesome-Robotics-3D
Awesome-Robotics-3D is a curated list of 3D Vision papers related to Robotics domain, focusing on large models like LLMs/VLMs. It includes papers on Policy Learning, Pretraining, VLM and LLM, Representations, and Simulations, Datasets, and Benchmarks. The repository is maintained by Zubair Irshad and welcomes contributions and suggestions for adding papers. It serves as a valuable resource for researchers and practitioners in the field of Robotics and Computer Vision.

llm-misinformation-survey
The 'llm-misinformation-survey' repository is dedicated to the survey on combating misinformation in the age of Large Language Models (LLMs). It explores the opportunities and challenges of utilizing LLMs to combat misinformation, providing insights into the history of combating misinformation, current efforts, and future outlook. The repository serves as a resource hub for the initiative 'LLMs Meet Misinformation' and welcomes contributions of relevant research papers and resources. The goal is to facilitate interdisciplinary efforts in combating LLM-generated misinformation and promoting the responsible use of LLMs in fighting misinformation.

awesome-llm-attributions
This repository focuses on unraveling the sources that large language models tap into for attribution or citation. It delves into the origins of facts, their utilization by the models, the efficacy of attribution methodologies, and challenges tied to ambiguous knowledge reservoirs, biases, and pitfalls of excessive attribution.

awesome-and-novel-works-in-slam
This repository contains a curated list of cutting-edge works in Simultaneous Localization and Mapping (SLAM). It includes research papers, projects, and tools related to various aspects of SLAM, such as 3D reconstruction, semantic mapping, novel algorithms, large-scale mapping, and more. The repository aims to showcase the latest advancements in SLAM technology and provide resources for researchers and practitioners in the field.
Awesome-LLM-Robotics
This repository contains a curated list of **papers using Large Language/Multi-Modal Models for Robotics/RL**. Template from awesome-Implicit-NeRF-Robotics Please feel free to send me pull requests or email to add papers! If you find this repository useful, please consider citing and STARing this list. Feel free to share this list with others! ## Overview * Surveys * Reasoning * Planning * Manipulation * Instructions and Navigation * Simulation Frameworks * Citation
Awesome_papers_on_LLMs_detection
This repository is a curated list of papers focused on the detection of Large Language Models (LLMs)-generated content. It includes the latest research papers covering detection methods, datasets, attacks, and more. The repository is regularly updated to include the most recent papers in the field.
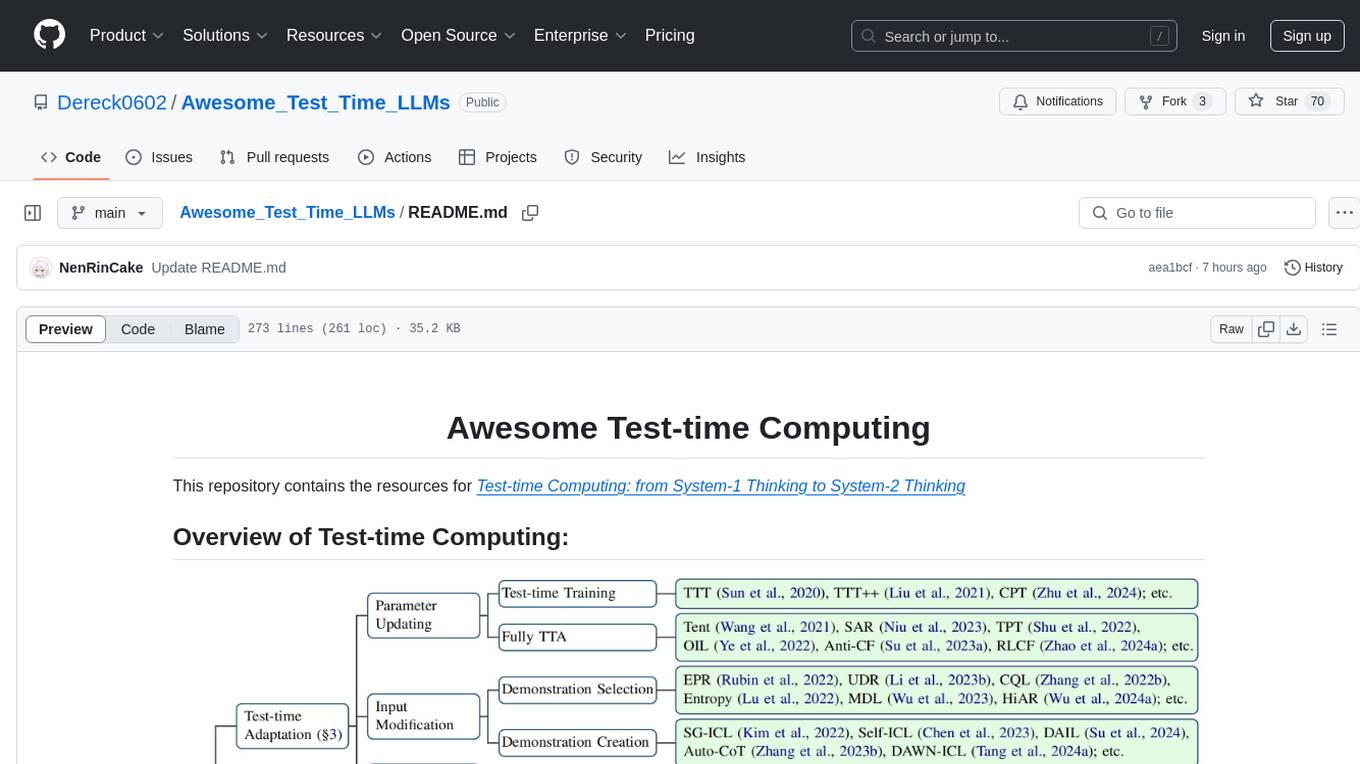
Awesome_Test_Time_LLMs
This repository focuses on test-time computing, exploring various strategies such as test-time adaptation, modifying the input, editing the representation, calibrating the output, test-time reasoning, and search strategies. It covers topics like self-supervised test-time training, in-context learning, activation steering, nearest neighbor models, reward modeling, and multimodal reasoning. The repository provides resources including papers and code for researchers and practitioners interested in enhancing the reasoning capabilities of large language models.
ABigSurveyOfLLMs
ABigSurveyOfLLMs is a repository that compiles surveys on Large Language Models (LLMs) to provide a comprehensive overview of the field. It includes surveys on various aspects of LLMs such as transformers, alignment, prompt learning, data management, evaluation, societal issues, safety, misinformation, attributes of LLMs, efficient LLMs, learning methods for LLMs, multimodal LLMs, knowledge-based LLMs, extension of LLMs, LLMs applications, and more. The repository aims to help individuals quickly understand the advancements and challenges in the field of LLMs through a collection of recent surveys and research papers.
Awesome-LLM-Interpretability
Awesome-LLM-Interpretability is a curated list of materials related to LLM (Large Language Models) interpretability, covering tutorials, code libraries, surveys, videos, papers, and blogs. It includes resources on transformer mechanistic interpretability, visualization, interventions, probing, fine-tuning, feature representation, learning dynamics, knowledge editing, hallucination detection, and redundancy analysis. The repository aims to provide a comprehensive overview of tools, techniques, and methods for understanding and interpreting the inner workings of large language models.
Awesome-LLM-in-Social-Science
Awesome-LLM-in-Social-Science is a repository that compiles papers evaluating Large Language Models (LLMs) from a social science perspective. It includes papers on evaluating, aligning, and simulating LLMs, as well as enhancing tools in social science research. The repository categorizes papers based on their focus on attitudes, opinions, values, personality, morality, and more. It aims to contribute to discussions on the potential and challenges of using LLMs in social science research.
handy-ollama
Handy-Ollama is a tutorial for deploying Ollama with hands-on practice, making the deployment of large language models accessible to everyone. The tutorial covers a wide range of content from basic to advanced usage, providing clear steps and practical tips for beginners and experienced developers to learn Ollama from scratch, deploy large models locally, and develop related applications. It aims to enable users to run large models on consumer-grade hardware, deploy models locally, and manage models securely and reliably.

do-research-in-AI
This repository is a collection of research lectures and experience sharing posts from frontline researchers in the field of AI. It aims to help individuals upgrade their research skills and knowledge through insightful talks and experiences shared by experts. The content covers various topics such as evaluating research papers, choosing research directions, research methodologies, and tips for writing high-quality scientific papers. The repository also includes discussions on academic career paths, research ethics, and the emotional aspects of research work. Overall, it serves as a valuable resource for individuals interested in advancing their research capabilities in the field of AI.
AI-Vtuber
AI-VTuber is a highly customizable AI VTuber project that integrates with Bilibili live streaming, uses Zhifu API as the language base model, and includes intent recognition, short-term and long-term memory, cognitive library building, song library creation, and integration with various voice conversion, voice synthesis, image generation, and digital human projects. It provides a user-friendly client for operations. The project supports virtual VTuber template construction, multi-person device template management, real-time switching of virtual VTuber templates, and offers various practical tools such as video/audio crawlers, voice recognition, voice separation, voice synthesis, voice conversion, AI drawing, and image background removal.
For similar tasks
awesome_LLM-harmful-fine-tuning-papers
This repository is a comprehensive survey of harmful fine-tuning attacks and defenses for large language models (LLMs). It provides a curated list of must-read papers on the topic, covering various aspects such as alignment stage defenses, fine-tuning stage defenses, post-fine-tuning stage defenses, mechanical studies, benchmarks, and attacks/defenses for federated fine-tuning. The repository aims to keep researchers updated on the latest developments in the field and offers insights into the vulnerabilities and safeguards related to fine-tuning LLMs.
For similar jobs

responsible-ai-toolbox
Responsible AI Toolbox is a suite of tools providing model and data exploration and assessment interfaces and libraries for understanding AI systems. It empowers developers and stakeholders to develop and monitor AI responsibly, enabling better data-driven actions. The toolbox includes visualization widgets for model assessment, error analysis, interpretability, fairness assessment, and mitigations library. It also offers a JupyterLab extension for managing machine learning experiments and a library for measuring gender bias in NLP datasets.
fairlearn
Fairlearn is a Python package designed to help developers assess and mitigate fairness issues in artificial intelligence (AI) systems. It provides mitigation algorithms and metrics for model assessment. Fairlearn focuses on two types of harms: allocation harms and quality-of-service harms. The package follows the group fairness approach, aiming to identify groups at risk of experiencing harms and ensuring comparable behavior across these groups. Fairlearn consists of metrics for assessing model impacts and algorithms for mitigating unfairness in various AI tasks under different fairness definitions.

Open-Prompt-Injection
OpenPromptInjection is an open-source toolkit for attacks and defenses in LLM-integrated applications, enabling easy implementation, evaluation, and extension of attacks, defenses, and LLMs. It supports various attack and defense strategies, including prompt injection, paraphrasing, retokenization, data prompt isolation, instructional prevention, sandwich prevention, perplexity-based detection, LLM-based detection, response-based detection, and know-answer detection. Users can create models, tasks, and apps to evaluate different scenarios. The toolkit currently supports PaLM2 and provides a demo for querying models with prompts. Users can also evaluate ASV for different scenarios by injecting tasks and querying models with attacked data prompts.

aws-machine-learning-university-responsible-ai
This repository contains slides, notebooks, and data for the Machine Learning University (MLU) Responsible AI class. The mission is to make Machine Learning accessible to everyone, covering widely used ML techniques and applying them to real-world problems. The class includes lectures, final projects, and interactive visuals to help users learn about Responsible AI and core ML concepts.

AIF360
The AI Fairness 360 toolkit is an open-source library designed to detect and mitigate bias in machine learning models. It provides a comprehensive set of metrics, explanations, and algorithms for bias mitigation in various domains such as finance, healthcare, and education. The toolkit supports multiple bias mitigation algorithms and fairness metrics, and is available in both Python and R. Users can leverage the toolkit to ensure fairness in AI applications and contribute to its development for extensibility.

Awesome-Interpretability-in-Large-Language-Models
This repository is a collection of resources focused on interpretability in large language models (LLMs). It aims to help beginners get started in the area and keep researchers updated on the latest progress. It includes libraries, blogs, tutorials, forums, tools, programs, papers, and more related to interpretability in LLMs.

hallucination-index
LLM Hallucination Index - RAG Special is a comprehensive evaluation of large language models (LLMs) focusing on context length and open vs. closed-source attributes. The index explores the impact of context length on model performance and tests the assumption that closed-source LLMs outperform open-source ones. It also investigates the effectiveness of prompting techniques like Chain-of-Note across different context lengths. The evaluation includes 22 models from various brands, analyzing major trends and declaring overall winners based on short, medium, and long context insights. Methodologies involve rigorous testing with different context lengths and prompting techniques to assess models' abilities in handling extensive texts and detecting hallucinations.
llm-misinformation-survey
The 'llm-misinformation-survey' repository is dedicated to the survey on combating misinformation in the age of Large Language Models (LLMs). It explores the opportunities and challenges of utilizing LLMs to combat misinformation, providing insights into the history of combating misinformation, current efforts, and future outlook. The repository serves as a resource hub for the initiative 'LLMs Meet Misinformation' and welcomes contributions of relevant research papers and resources. The goal is to facilitate interdisciplinary efforts in combating LLM-generated misinformation and promoting the responsible use of LLMs in fighting misinformation.