
awesome-tool-llm
None
Stars: 114

This repository focuses on exploring tools that enhance the performance of language models for various tasks. It provides a structured list of literature relevant to tool-augmented language models, covering topics such as tool basics, tool use paradigm, scenarios, advanced methods, and evaluation. The repository includes papers, preprints, and books that discuss the use of tools in conjunction with language models for tasks like reasoning, question answering, mathematical calculations, accessing knowledge, interacting with the world, and handling non-textual modalities.
README:
Language models (LMs) are powerful yet mostly for text-generation tasks. Tools have substantially enhanced their performance for tasks that require complex skills.
Based on our recent survey about LM-used tools, "What Are Tools Anyway? A Survey from the Language Model Perspective", we provide a structured list of literature relevant to tool-augmented LMs.
- Tool basics ($\S2$)
- Tool use paradigm ($\S3$)
- Scenarios ($\S4$)
- Advanced methods ($\S5$)
- Evaluation ($\S6$)
If you find our paper or code useful, please cite the paper:
@article{wang2022what,
title={What Are Tools Anyway? A Survey from the Language Model Perspective},
author={Zhiruo Wang, Zhoujun Cheng, Hao Zhu, Daniel Fried, Graham Neubig},
journal={arXiv preprint arXiv:2403.15452},
year={2024}
}-
Definition and discussion of animal-used tools
Animal tool behavior: the use and manufacture of tools by animals Shumaker, Robert W., Kristina R. Walkup, and Benjamin B. Beck. 2011 [Book]
-
Early discussions on LM-used tools
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs Qin, Yujia, et al. 2023.07 [Paper]
-
A survey on augmented LMs, including tool augmentation
Augmented Language Models: a Survey Mialon, Grégoire, et al. 2023.02 [Paper]
-
Definition of agents
Artificial intelligence a modern approach Russell, Stuart J., and Peter Norvig. 2016 [Book]
-
Survey about agents that perceive and act in the environment
The Rise and Potential of Large Language Model Based Agents: A Survey Xi, Zhiheng, et al. 2023.09 [Preprint]
-
Survey about the cognitive architectures for language agents
Cognitive Architectures for Language Agents Sumers, Theodore R., et al. 2023.09 [Paper]
-
Early works that set up the commonly used tooling paradigm
Toolformer: Language Models Can Teach Themselves to Use Tools Schick, Timo, et al. 2024 [Paper]
-
Provide in-context examples for tool-using on visual programming problems
Visual Programming: Compositional visual reasoning without training Gupta, Tanmay, and Aniruddha Kembhavi. 2023 [Paper]
-
Tool learning via in-context examples on reasoning problems involving text or multi-modal inputs
Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models Lu, Pan, et al. 2024 [Paper]
-
In-context learning based tool using for reasoning problems in BigBench and MMLU
ART: Automatic multi-step reasoning and tool-use for large language models Paranjape, Bhargavi, et al. 2023.03 [Preprint]
-
Providing tool documentation for in-context tool learning
Tool Documentation Enables Zero-Shot Tool-Usage with Large Language Models Hsieh, Cheng-Yu, et al. 2023.08 [Preprint]
-
Training on human annotated examples of (NL input, tool-using solution output) pairs
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs Li, Minghao, et al. 2023.12 [Paper]
Calc-X and Calcformers: Empowering Arithmetical Chain-of-Thought through Interaction with Symbolic Systems Kadlčík, Marek, et al. 2023 [Paper]
-
Training on model-synthesized examples
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases Tang, Qiaoyu, et al. 2023.06 [Preprint]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs Qin, Yujia, et al. 2023.07 [Paper]
MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use Huang, Yue, et al. 2023.10 [Paper]
Making Language Models Better Tool Learners with Execution Feedback Qiao, Shuofei, et al. 2023.05 [Preprint]
LLMs in the Imaginarium: Tool Learning through Simulated Trial and Error Wang, Boshi, et al. 2024.03 [Preprint]
-
Self-training with bootstrapped examples
Toolformer: Language Models Can Teach Themselves to Use Tools Schick, Timo, et al. 2024 Paper
-
Collect data from structured knowledge sources, e.g., databases, knowledge graphs, etc.
LaMDA: Language Models for Dialog Applications Thoppilan, Romal, et al. 2022.01 [Paper]
TALM: Tool Augmented Language Models Parisi, Aaron, Yao Zhao, and Noah Fiedel. 2022.05 [Preprint]
ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings Hao, Shibo, et al. 2024 [Paper]
ToolQA: A Dataset for LLM Question Answering with External Tools Zhuang, Yuchen, et al. 2024 [Paper]
Middleware for LLMs: Tools are Instrumental for Language Agents in Complex Environments Gu, Yu, et al. 2024 [Paper]
GeneGPT: Augmenting Large Language Models with Domain Tools for Improved Access to Biomedical Information Jin, Qiao, et al. 2024 [Paper]
-
Search information from the web
Internet-augmented language models through few-shot prompting for open-domain question answering Lazaridou, Angeliki, et al. 2022.03 [Paper]
Internet-Augmented Dialogue Generation Komeili, Mojtaba, Kurt Shuster, and Jason Weston. 2022 [Paper]
-
Viewing retrieval models as tools under the retrieval-augmented generation context
Retrieval-based Language Models and Applications Asai, Akari, et al. 2023 [Tutorial]
Augmented Language Models: a Survey Mialon, Grégoire, et al. 2023.02 [Paper]
-
Using calculator for math calculations
Toolformer: Language Models Can Teach Themselves to Use Tools Schick, Timo, et al. 2024 [Paper]
Calc-X and Calcformers: Empowering Arithmetical Chain-of-Thought through Interaction with Symbolic Systems Kadlčík, Marek, et al. 2023 [Paper]
-
Using programs/Python interpreter to perform more complex operations
Pal: Program-aided language models Gao, Luyu, et al. 2023 [Paper]
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks Chen, Wenhu, et al. 2022.11 [Paper]
Mint: Evaluating llms in multi-turn interaction with tools and language feedback Wang, Xingyao, et al. 2023.09 [Paper]
MATHSENSEI: A Tool-Augmented Large Language Model for Mathematical Reasoning Das, Debrup, et al. 2024 [Preprint]
ToRA: A Tool-Integrated Reasoning Agent for Mathematical Problem Solving Gou, Zhibin, et al. 2023.09 [Paper]
-
Tools for more advanced business activities, e.g., financial, medical, education, etc.
On the Tool Manipulation Capability of Open-source Large Language Models Xu, Qiantong, et al. 2023.05 [Paper]
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases Tang, Qiaoyu, et al. 2023.06 [Preprint]
Mint: Evaluating llms in multi-turn interaction with tools and language feedback Wang, Xingyao, et al. 2023.09 [Paper]
AgentMD: Empowering Language Agents for Risk Prediction with Large-Scale Clinical Tool Learning Jin, Qiao, et al. 2024.02 [Paper]
-
Access real-time or real-world information such as weather, location, etc.
On the Tool Manipulation Capability of Open-source Large Language Models Xu, Qiantong, et al. 2023.05 [Paper]
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases Tang, Qiaoyu, et al. 2023.06 [Preprint]
-
Managing personal events such as calendar or emails
Toolformer: Language Models Can Teach Themselves to Use Tools Schick, Timo, et al. 2024 [Paper]
-
Tools in embodied environments, e.g., the Minecraft world
Voyager: An Open-Ended Embodied Agent with Large Language Models Wang, Guanzhi, et al. 2023.05 [Paper]
-
Tools interacting with the physical world
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models Singh, Ishika, et al. 2023 [Paper]
Alfred: A benchmark for interpreting grounded instructions for everyday tasks Shridhar, Mohit, et al. 2020 [Paper]
Autonomous chemical research with large language models Boiko, Daniil A., et al. 2023 [Paper]
-
Tools providing access to information in non-textual modalities
Vipergpt: Visual inference via python execution for reasoning Surís, Dídac, Sachit Menon, and Carl Vondrick. 2023 [Paper]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action Yang, Zhengyuan, et al. 2023.03 [Preprint]
AssistGPT: A General Multi-modal Assistant that can Plan, Execute, Inspect, and Learn Gao, Difei, et al. 2023.06 [Preprint]
-
Tools that can answer questions about data in other modalities
Visual Programming: Compositional visual reasoning without training Gupta, Tanmay, and Aniruddha Kembhavi. 2023 [Paper]
-
Text-generation models that can perform specific tasks, e.g., question answering, machine translation
Toolformer: Language Models Can Teach Themselves to Use Tools Schick, Timo, et al. 2024 [Paper]
ART: Automatic multi-step reasoning and tool-use for large language models Paranjape, Bhargavi, et al. 2023.03 [Preprint]
-
Integration of available models on Huggingface, TorchHub, TensorHub, etc.
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face Shen, Yongliang, et al. 2024 [Paper]
Gorilla: Large language model connected with massive apis Patil, Shishir G., et al. 2023.05 [Paper]
Taskbench: Benchmarking large language models for task automation Shen, Yongliang, et al. 2023.11 [Paper]
-
Train retrievers that map natural language instructions to tool documentation
DocPrompting: Generating Code by Retrieving the Docs Zhou, Shuyan, et al. 2022.07 [Paper]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs Qin, Yujia, et al. 2023.07 [Paper]
-
Ask LMs to write hypothetical tool descriptions and search relevant tools
CRAFT: Customizing LLMs by Creating and Retrieving from Specialized Toolsets Yuan, Lifan, et al. 2023.09 [Paper]
-
Complex tool usage, e.g., parallel calls
Function Calling and Other API Updates Eleti, Atty, et al. 2023.06 [Blog]
-
Domain-specific logical forms to query structured data
Semantic parsing on freebase from question-answer pairs Berant, Jonathan, et al. 2013 [Paper]
Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task Yu, Tao, et al. 2018.09 [Paper]
Break It Down: A Question Understanding Benchmark Wolfson, Tomer, et al. 2020 [Paper]
-
Domain-specific actions for agentic tasks such as web navigation
Reinforcement Learning on Web Interfaces using Workflow-Guided Exploration Liu, Evan Zheran, et al. 2018.02 [Paper]
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents Yao, Shunyu, et al. 2022.07 [Paper]
Webarena: A realistic web environment for building autonomous agents Zhou, Shuyan, et al. 2023.07 [Paper]
-
Using external Python libraries as tools
ToolCoder: Teach Code Generation Models to use API search tools Zhang, Kechi, et al. 2023.05 [Paper]
-
Using expert designed functions as tools to answer questions about images
Visual Programming: Compositional visual reasoning without training Gupta, Tanmay, and Aniruddha Kembhavi. 2023 [Paper]
Vipergpt: Visual inference via python execution for reasoning Surís, Dídac, Sachit Menon, and Carl Vondrick. 2023 [Paper]
-
Using GPT as a tool to query external Wikipedia knowledge for table-based question answering
Binding Language Models in Symbolic Languages Cheng, Zhoujun, et al. 2022.10 [Paper]
-
Incorporate QA API and operation APIs to assist table-based question answering
API-Assisted Code Generation for Question Answering on Varied Table Structures Cao, Yihan, et al. 2023.12 [Paper]
-
Approaches to abstract libraries for domain-specific logical forms from a large corpus
DreamCoder: growing generalizable, interpretable knowledge with wake--sleep Bayesian program learning Ellis, Kevin, et al. 2020.06 [Paper]
Leveraging Language to Learn Program Abstractions and Search Heuristics] Wong, Catherine, et al. 2021 [Paper]
Top-Down Synthesis for Library Learning Bowers, Matthew, et al. 2023 [Paper]
LILO: Learning Interpretable Libraries by Compressing and Documenting Code Grand, Gabriel, et al. 2023.10 [Paper]
-
Make and learn skills (Java programs) in the embodied Minecraft world
Voyager: An Open-Ended Embodied Agent with Large Language Models Wang, Guanzhi, et al. 2023.05 [Paper]
-
Leverage LMs as tool makers on BigBench tasks
Large Language Models as Tool Makers Cai, Tianle, et al. 2023.05 [Preprint]
-
Create tools for math and table QA tasks by example-wise tool making
CREATOR: Disentangling Abstract and Concrete Reasonings of Large Language Models through Tool Creation Qian, Cheng, et al. 2023.05 [Paper]
-
Make tools via heuristic-based training and tool deduplication
CRAFT: Customizing LLMs by Creating and Retrieving from Specialized Toolsets Yuan, Lifan, et al. 2023.09 [Paper]
-
Learning tools by refactoring a small amount of programs
ReGAL: Refactoring Programs to Discover Generalizable Abstractions Stengel-Eskin, Elias, Archiki Prasad, and Mohit Bansal. 2024.01 [Preprint]
-
A training-free approach to make tools via execution consistency
🎁 TroVE: Inducing Verifiable and Efficient Toolboxes for Solving Programmatic Tasks Wang, Zhiruo, Daniel Fried, and Graham Neubig. 2024.01 [Preprint]
-
Datasets that require reasoning over texts
Measuring Mathematical Problem Solving With the MATH Dataset Hendrycks, Dan, et al. 2021.03 [Paper]
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models Srivastava, Aarohi, et al. 2022.06 [Paper]
-
Datasets that require reasoning over structured data, e.g., tables
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning Lu, Pan, et al. 2022.09 [Paper]
Compositional Semantic Parsing on Semi-Structured Tables Pasupat, Panupong, and Percy Liang. 2015 [Paper]
HiTab: A Hierarchical Table Dataset for Question Answering and Natural Language Generation Cheng, Zhoujun, et al. 2022 [Paper]
-
Datasets that require reasoning over other modalities, e.g., images and image pairs
Gqa: A new dataset for real-world visual reasoning and compositional question answering Hudson, Drew A., and Christopher D. Manning. 2019.02 [Paper]
A Corpus for Reasoning about Natural Language Grounded in Photographs Suhr, Alane, et al. 2019 [Paper]
-
Example datasets that require retriever model (tool) to solve
Natural Questions: A Benchmark for Question Answering Research Kwiatkowski, Tom, et al. 2019 [Paper]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension Joshi, Mandar, et al. 2017 [Paper]
-
Collect RapidAPIs and use models to synthesize examples for evaluation
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs Qin, Yujia, et al. 2023.07 [Paper]
-
Collect APIs from PublicAPIs and use models to synthesize examples
ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases Tang, Qiaoyu, et al. 2023.06 [Preprint]
-
Collect APIs from PublicAPIs and manually annotate examples for evaluation
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs Li, Minghao, et al. 2023.12 [Paper]
-
Collect APIs from OpenAI plugin list and use models to synthesize examples
MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use Huang, Yue, et al. 2023.10 [Paper]
-
Collect neural model tools from Huggingface hub, TorchHub, and TensorHub
Gorilla: Large language model connected with massive apis Patil, Shishir G., et al. 2023.05 [Paper]
-
Collect neural model tools from Huggingface
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face Shen, Yongliang, et al. 2024 [Paper]
-
Collect tools from Huggingface and PublicAPIs
Taskbench: Benchmarking large language models for task automation Shen, Yongliang, et al. 2023.11 [Paper]
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for awesome-tool-llm
Similar Open Source Tools
awesome-tool-llm
This repository focuses on exploring tools that enhance the performance of language models for various tasks. It provides a structured list of literature relevant to tool-augmented language models, covering topics such as tool basics, tool use paradigm, scenarios, advanced methods, and evaluation. The repository includes papers, preprints, and books that discuss the use of tools in conjunction with language models for tasks like reasoning, question answering, mathematical calculations, accessing knowledge, interacting with the world, and handling non-textual modalities.
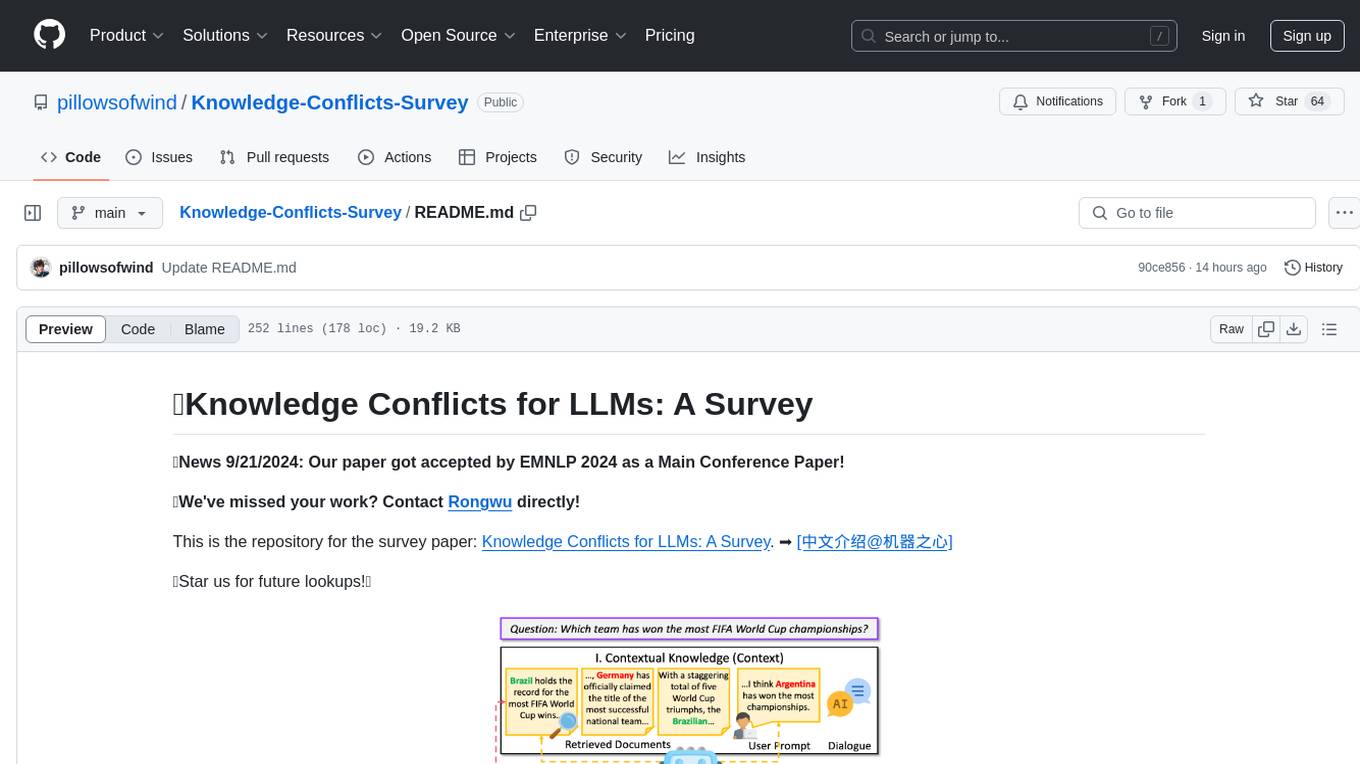
Knowledge-Conflicts-Survey
Knowledge Conflicts for LLMs: A Survey is a repository containing a survey paper that investigates three types of knowledge conflicts: context-memory conflict, inter-context conflict, and intra-memory conflict within Large Language Models (LLMs). The survey reviews the causes, behaviors, and possible solutions to these conflicts, providing a comprehensive analysis of the literature in this area. The repository includes detailed information on the types of conflicts, their causes, behavior analysis, and mitigating solutions, offering insights into how conflicting knowledge affects LLMs and how to address these conflicts.
LLM4IR-Survey
LLM4IR-Survey is a collection of papers related to large language models for information retrieval, organized according to the survey paper 'Large Language Models for Information Retrieval: A Survey'. It covers various aspects such as query rewriting, retrievers, rerankers, readers, search agents, and more, providing insights into the integration of large language models with information retrieval systems.
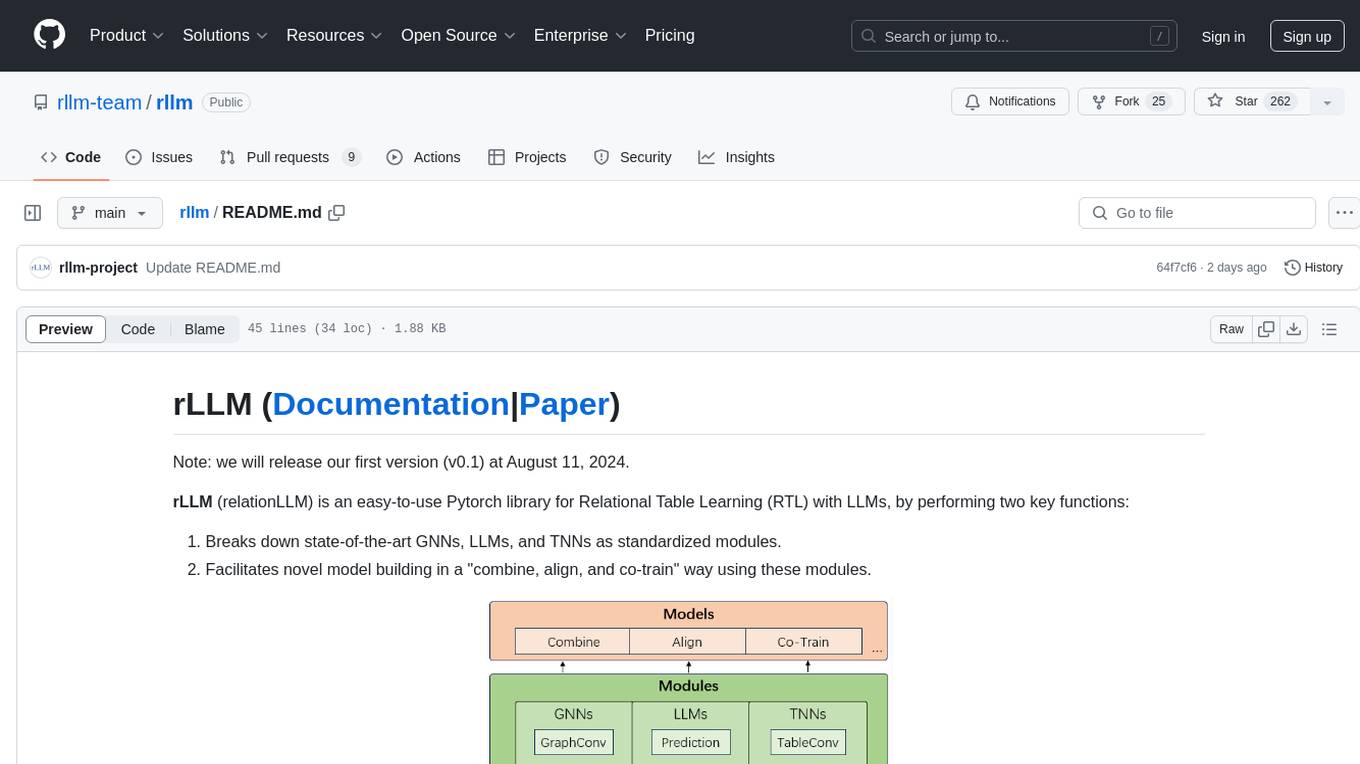
rllm
rLLM (relationLLM) is a Pytorch library for Relational Table Learning (RTL) with LLMs. It breaks down state-of-the-art GNNs, LLMs, and TNNs as standardized modules and facilitates novel model building in a 'combine, align, and co-train' way using these modules. The library is LLM-friendly, processes various graphs as multiple tables linked by foreign keys, introduces new relational table datasets, and is supported by students and teachers from Shanghai Jiao Tong University and Tsinghua University.

LLM-Agent-Survey
LLM-Agent-Survey is a comprehensive repository that provides a curated list of papers related to Large Language Model (LLM) agents. The repository categorizes papers based on LLM-Profiled Roles and includes high-quality publications from prestigious conferences and journals. It aims to offer a systematic understanding of LLM-based agents, covering topics such as tool use, planning, and feedback learning. The repository also includes unpublished papers with insightful analysis and novelty, marked for future updates. Users can explore a wide range of surveys, tool use cases, planning workflows, and benchmarks related to LLM agents.
awesome-deeplogic
Awesome deep logic is a curated list of papers and resources focusing on integrating symbolic logic into deep neural networks. It includes surveys, tutorials, and research papers that explore the intersection of logic and deep learning. The repository aims to provide valuable insights and knowledge on how logic can be used to enhance reasoning, knowledge regularization, weak supervision, and explainability in neural networks.

llm-misinformation-survey
The 'llm-misinformation-survey' repository is dedicated to the survey on combating misinformation in the age of Large Language Models (LLMs). It explores the opportunities and challenges of utilizing LLMs to combat misinformation, providing insights into the history of combating misinformation, current efforts, and future outlook. The repository serves as a resource hub for the initiative 'LLMs Meet Misinformation' and welcomes contributions of relevant research papers and resources. The goal is to facilitate interdisciplinary efforts in combating LLM-generated misinformation and promoting the responsible use of LLMs in fighting misinformation.
Awesome-LLM-in-Social-Science
Awesome-LLM-in-Social-Science is a repository that compiles papers evaluating Large Language Models (LLMs) from a social science perspective. It includes papers on evaluating, aligning, and simulating LLMs, as well as enhancing tools in social science research. The repository categorizes papers based on their focus on attitudes, opinions, values, personality, morality, and more. It aims to contribute to discussions on the potential and challenges of using LLMs in social science research.

awesome-llm-attributions
This repository focuses on unraveling the sources that large language models tap into for attribution or citation. It delves into the origins of facts, their utilization by the models, the efficacy of attribution methodologies, and challenges tied to ambiguous knowledge reservoirs, biases, and pitfalls of excessive attribution.
ToolUniverse
ToolUniverse is a collection of 211 biomedical tools designed for Agentic AI, providing access to biomedical knowledge for solving therapeutic reasoning tasks. The tools cover various aspects of drugs and diseases, linked to trusted sources like US FDA-approved drugs since 1939, Open Targets, and Monarch Initiative.

ai
Jetify's AI SDK for Go is a unified interface for interacting with multiple AI providers including OpenAI, Anthropic, and more. It addresses the challenges of fragmented ecosystems, vendor lock-in, poor Go developer experience, and complex multi-modal handling by providing a unified interface, Go-first design, production-ready features, multi-modal support, and extensible architecture. The SDK supports language models, embeddings, image generation, multi-provider support, multi-modal inputs, tool calling, and structured outputs.

LLM-Tool-Survey
This repository contains a collection of papers related to tool learning with large language models (LLMs). The papers are organized according to the survey paper 'Tool Learning with Large Language Models: A Survey'. The survey focuses on the benefits and implementation of tool learning with LLMs, covering aspects such as task planning, tool selection, tool calling, response generation, benchmarks, evaluation, challenges, and future directions in the field. It aims to provide a comprehensive understanding of tool learning with LLMs and inspire further exploration in this emerging area.
llms-interview-questions
This repository contains a comprehensive collection of 63 must-know Large Language Models (LLMs) interview questions. It covers topics such as the architecture of LLMs, transformer models, attention mechanisms, training processes, encoder-decoder frameworks, differences between LLMs and traditional statistical language models, handling context and long-term dependencies, transformers for parallelization, applications of LLMs, sentiment analysis, language translation, conversation AI, chatbots, and more. The readme provides detailed explanations, code examples, and insights into utilizing LLMs for various tasks.
DriveLM
DriveLM is a multimodal AI model that enables autonomous driving by combining computer vision and natural language processing. It is designed to understand and respond to complex driving scenarios using visual and textual information. DriveLM can perform various tasks related to driving, such as object detection, lane keeping, and decision-making. It is trained on a massive dataset of images and text, which allows it to learn the relationships between visual cues and driving actions. DriveLM is a powerful tool that can help to improve the safety and efficiency of autonomous vehicles.
For similar tasks
awesome-tool-llm
This repository focuses on exploring tools that enhance the performance of language models for various tasks. It provides a structured list of literature relevant to tool-augmented language models, covering topics such as tool basics, tool use paradigm, scenarios, advanced methods, and evaluation. The repository includes papers, preprints, and books that discuss the use of tools in conjunction with language models for tasks like reasoning, question answering, mathematical calculations, accessing knowledge, interacting with the world, and handling non-textual modalities.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"
For similar jobs

responsible-ai-toolbox
Responsible AI Toolbox is a suite of tools providing model and data exploration and assessment interfaces and libraries for understanding AI systems. It empowers developers and stakeholders to develop and monitor AI responsibly, enabling better data-driven actions. The toolbox includes visualization widgets for model assessment, error analysis, interpretability, fairness assessment, and mitigations library. It also offers a JupyterLab extension for managing machine learning experiments and a library for measuring gender bias in NLP datasets.
LLMLingua
LLMLingua is a tool that utilizes a compact, well-trained language model to identify and remove non-essential tokens in prompts. This approach enables efficient inference with large language models, achieving up to 20x compression with minimal performance loss. The tool includes LLMLingua, LongLLMLingua, and LLMLingua-2, each offering different levels of prompt compression and performance improvements for tasks involving large language models.
llm-examples
Starter examples for building LLM apps with Streamlit. This repository showcases a growing collection of LLM minimum working examples, including a Chatbot, File Q&A, Chat with Internet search, LangChain Quickstart, LangChain PromptTemplate, and Chat with user feedback. Users can easily get their own OpenAI API key and set it as an environment variable in Streamlit apps to run the examples locally.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.
awesome-tool-llm
This repository focuses on exploring tools that enhance the performance of language models for various tasks. It provides a structured list of literature relevant to tool-augmented language models, covering topics such as tool basics, tool use paradigm, scenarios, advanced methods, and evaluation. The repository includes papers, preprints, and books that discuss the use of tools in conjunction with language models for tasks like reasoning, question answering, mathematical calculations, accessing knowledge, interacting with the world, and handling non-textual modalities.
gaianet-node
GaiaNet-node is a tool that allows users to run their own GaiaNet node, enabling them to interact with an AI agent. The tool provides functionalities to install the default node software stack, initialize the node with model files and vector database files, start the node, stop the node, and update configurations. Users can use pre-set configurations or pass a custom URL for initialization. The tool is designed to facilitate communication with the AI agent and access node information via a browser. GaiaNet-node requires sudo privilege for installation but can also be installed without sudo privileges with specific commands.

llmops-duke-aipi
LLMOps Duke AIPI is a course focused on operationalizing Large Language Models, teaching methodologies for developing applications using software development best practices with large language models. The course covers various topics such as generative AI concepts, setting up development environments, interacting with large language models, using local large language models, applied solutions with LLMs, extensibility using plugins and functions, retrieval augmented generation, introduction to Python web frameworks for APIs, DevOps principles, deploying machine learning APIs, LLM platforms, and final presentations. Students will learn to build, share, and present portfolios using Github, YouTube, and Linkedin, as well as develop non-linear life-long learning skills. Prerequisites include basic Linux and programming skills, with coursework available in Python or Rust. Additional resources and references are provided for further learning and exploration.
Awesome-AISourceHub
Awesome-AISourceHub is a repository that collects high-quality information sources in the field of AI technology. It serves as a synchronized source of information to avoid information gaps and information silos. The repository aims to provide valuable resources for individuals such as AI book authors, enterprise decision-makers, and tool developers who frequently use Twitter to share insights and updates related to AI advancements. The platform emphasizes the importance of accessing information closer to the source for better quality content. Users can contribute their own high-quality information sources to the repository by following specific steps outlined in the contribution guidelines. The repository covers various platforms such as Twitter, public accounts, knowledge planets, podcasts, blogs, websites, YouTube channels, and more, offering a comprehensive collection of AI-related resources for individuals interested in staying updated with the latest trends and developments in the AI field.