
MemOS
AI memory OS for LLM and Agent systems(moltbot,clawdbot,openclaw), enabling persistent Skill memory for cross-task skill reuse and evolution.
Stars: 5347
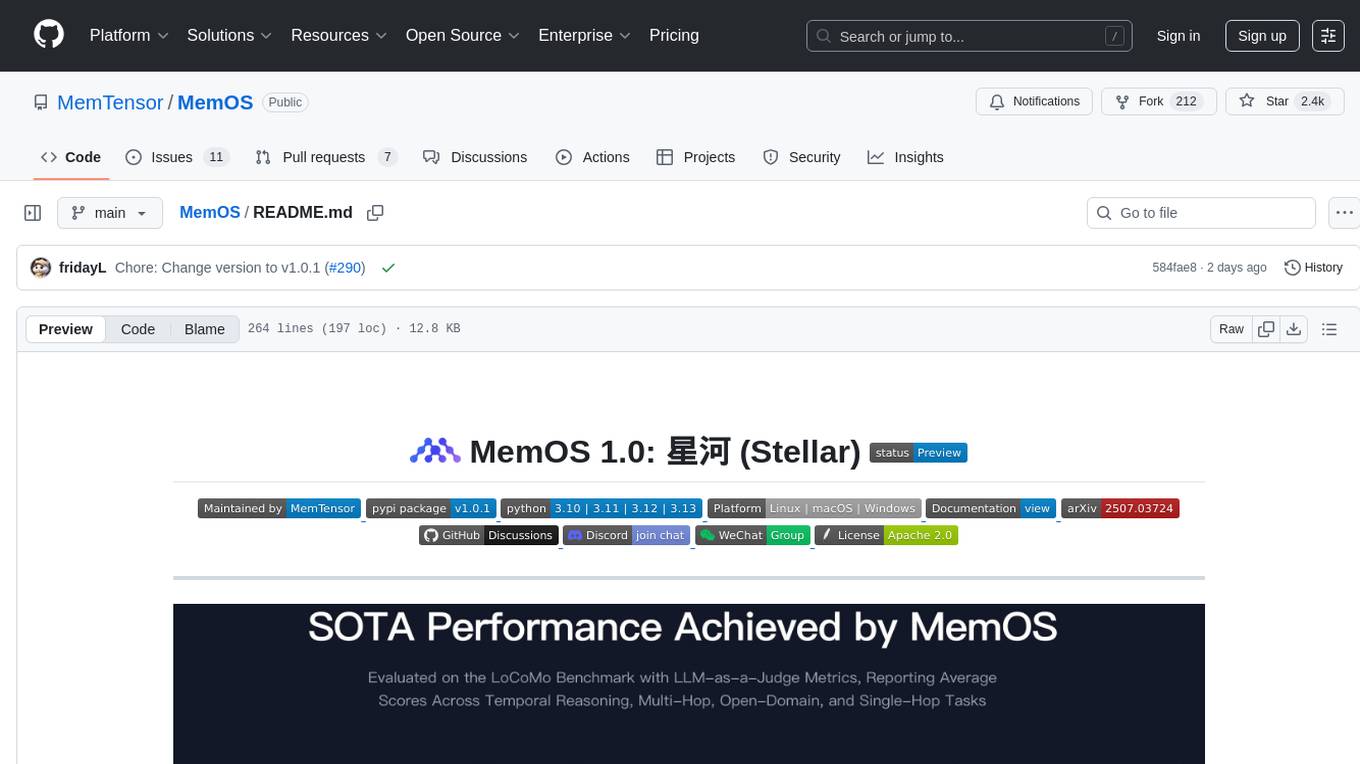
MemOS is an operating system for Large Language Models (LLMs) that enhances them with long-term memory capabilities. It allows LLMs to store, retrieve, and manage information, enabling more context-aware, consistent, and personalized interactions. MemOS provides Memory-Augmented Generation (MAG) with a unified API for memory operations, a Modular Memory Architecture (MemCube) for easy integration and management of different memory types, and multiple memory types including Textual Memory, Activation Memory, and Parametric Memory. It is extensible, allowing users to customize memory modules, data sources, and LLM integrations. MemOS demonstrates significant improvements over baseline memory solutions in multiple reasoning tasks, with a notable improvement in temporal reasoning accuracy compared to the OpenAI baseline.
README:




🎯 +43.70% Accuracy vs. OpenAI Memory
🏆 Top-tier long-term memory + personalization
💰 Saves 35.24% memory tokens
LoCoMo 75.80 • LongMemEval +40.43% • PrefEval-10 +2568% • PersonaMem +40.75%

Get Free API: Try API

- 72% lower token usage – intelligent memory retrieval instead of loading full chat history
- Multi-agent memory sharing – multi-instance agents share memory via same user_id. Automatic context handoff.
🦞 Your lobster now has a working memory system.
Get your API key: MemOS Dashboard
Try it: Full tutorial → MemOS-Cloud-OpenClaw-Plugin
MemOS is a Memory Operating System for LLMs and AI agents that unifies store / retrieve / manage for long-term memory, enabling context-aware and personalized interactions with KB, multi-modal, tool memory, and enterprise-grade optimizations built in.
- Unified Memory API: A single API to add, retrieve, edit, and delete memory—structured as a graph, inspectable and editable by design, not a black-box embedding store.
- Multi-Modal Memory: Natively supports text, images, tool traces, and personas, retrieved and reasoned together in one memory system.
- Multi-Cube Knowledge Base Management: Manage multiple knowledge bases as composable memory cubes, enabling isolation, controlled sharing, and dynamic composition across users, projects, and agents.
- Asynchronous Ingestion via MemScheduler: Run memory operations asynchronously with millisecond-level latency for production stability under high concurrency.
- Memory Feedback & Correction: Refine memory with natural-language feedback—correcting, supplementing, or replacing existing memories over time.
-
2025-12-24 · 🎉 MemOS v2.0: Stardust (星尘) Release
Comprehensive KB (doc/URL parsing + cross-project sharing), memory feedback & precise deletion, multi-modal memory (images/charts), tool memory for agent planning, Redis Streams scheduling + DB optimizations, streaming/non-streaming chat, MCP upgrade, and lightweight quick/full deployment.✨ New Features
Knowledge Base & Memory
- Added knowledge base support for long-term memory from documents and URLs
Feedback & Memory Management
- Added natural language feedback and correction for memories
- Added memory deletion API by memory ID
- Added MCP support for memory deletion and feedback
Conversation & Retrieval
- Added chat API with memory-aware retrieval
- Added memory filtering with custom tags (Cloud & Open Source)
Multimodal & Tool Memory
- Added tool memory for tool usage history
- Added image memory support for conversations and documents
📈 Improvements
Data & Infrastructure
- Upgraded database for better stability and performance
Scheduler
- Rebuilt task scheduler with Redis Streams and queue isolation
- Added task priority, auto-recovery, and quota-based scheduling
Deployment & Engineering
- Added lightweight deployment with quick and full modes
🐞 Bug Fixes
Memory Scheduling & Updates
- Fixed legacy scheduling API to ensure correct memory isolation
- Fixed memory update logging to show new memories correctly
-
2025-08-07 · 🎉 MemOS v1.0.0 (MemCube) Release
First MemCube release with a word-game demo, LongMemEval evaluation, BochaAISearchRetriever integration, NebulaGraph support, improved search capabilities, and the official Playground launch.✨ New Features
Playground
- Expanded Playground features and algorithm performance.
MemCube Construction
- Added a text game demo based on the MemCube novel.
Extended Evaluation Set
- Added LongMemEval evaluation results and scripts.
📈 Improvements
Plaintext Memory
- Integrated internet search with Bocha.
- Added support for Nebula database.
- Added contextual understanding for the tree-structured plaintext memory search interface.
🐞 Bug Fixes
KV Cache Concatenation
- Fixed the concat_cache method.
Plaintext Memory
- Fixed Nebula search-related issues.
-
2025-07-07 · 🎉 MemOS v1.0: Stellar (星河) Preview Release
A SOTA Memory OS for LLMs is now open-sourced. -
2025-07-04 · 🎉 MemOS Paper Release
MemOS: A Memory OS for AI System is available on arXiv. -
2024-07-04 · 🎉 Memory3 Model Release at WAIC 2024
The Memory3 model, featuring a memory-layered architecture, was unveiled at the 2024 World Artificial Intelligence Conference.
- Sign up on the MemOS dashboard
- Go to API Keys and copy your key
-
MemOS Cloud Getting Started
Connect to MemOS Cloud and enable memory in minutes. -
MemOS Cloud Platform
Explore the Cloud dashboard, features, and workflows.
- Get the repository.
git clone https://github.com/MemTensor/MemOS.git cd MemOS pip install -r ./docker/requirements.txt - Configure
docker/.env.exampleand copy toMemOS/.env
- The
OPENAI_API_KEY,MOS_EMBEDDER_API_KEY,MEMRADER_API_KEYand others can be applied for throughBaiLian. - Fill in the corresponding configuration in the
MemOS/.envfile.
- Start the service.
-
Launch via Docker
Tips: Please ensure that Docker Compose is installed successfully and that you have navigated to the docker directory (via
cd docker) before executing the following command.# Enter docker directory docker compose upFor detailed steps, see the
Docker Reference. -
Launch via the uvicorn command line interface (CLI)
cd src uvicorn memos.api.server_api:app --host 0.0.0.0 --port 8001 --workers 1For detailed integration steps, see the
CLI Reference.
- Add User Message
import requests import json data = { "user_id": "8736b16e-1d20-4163-980b-a5063c3facdc", "mem_cube_id": "b32d0977-435d-4828-a86f-4f47f8b55bca", "messages": [ { "role": "user", "content": "I like strawberry" } ], "async_mode": "sync" } headers = { "Content-Type": "application/json" } url = "http://localhost:8000/product/add" res = requests.post(url=url, headers=headers, data=json.dumps(data)) print(f"result: {res.json()}")
- Search User Memory
import requests import json data = { "query": "What do I like", "user_id": "8736b16e-1d20-4163-980b-a5063c3facdc", "mem_cube_id": "b32d0977-435d-4828-a86f-4f47f8b55bca" } headers = { "Content-Type": "application/json" } url = "http://localhost:8000/product/search" res = requests.post(url=url, headers=headers, data=json.dumps(data)) print(f"result: {res.json()}")
-
Awesome-AI-Memory
This is a curated repository dedicated to resources on memory and memory systems for large language models. It systematically collects relevant research papers, frameworks, tools, and practical insights. The repository aims to organize and present the rapidly evolving research landscape of LLM memory, bridging multiple research directions including natural language processing, information retrieval, agentic systems, and cognitive science. - Get started 👉 IAAR-Shanghai/Awesome-AI-Memory
- MemOS Cloud OpenClaw Plugin Official OpenClaw lifecycle plugin for MemOS Cloud. It automatically recalls context from MemOS before the agent starts and saves the conversation back to MemOS after the agent finishes.
- Get started 👉 MemTensor/MemOS-Cloud-OpenClaw-Plugin
Join our community to ask questions, share your projects, and connect with other developers.
- GitHub Issues: Report bugs or request features in our GitHub Issues.
- GitHub Pull Requests: Contribute code improvements via Pull Requests.
- GitHub Discussions: Participate in our GitHub Discussions to ask questions or share ideas.
- Discord: Join our Discord Server.
- WeChat: Scan the QR code to join our WeChat group.
[!NOTE] We publicly released the Short Version on May 28, 2025, making it the earliest work to propose the concept of a Memory Operating System for LLMs.
If you use MemOS in your research, we would appreciate citations to our papers.
@article{li2025memos_long,
title={MemOS: A Memory OS for AI System},
author={Li, Zhiyu and Song, Shichao and Xi, Chenyang and Wang, Hanyu and Tang, Chen and Niu, Simin and Chen, Ding and Yang, Jiawei and Li, Chunyu and Yu, Qingchen and Zhao, Jihao and Wang, Yezhaohui and Liu, Peng and Lin, Zehao and Wang, Pengyuan and Huo, Jiahao and Chen, Tianyi and Chen, Kai and Li, Kehang and Tao, Zhen and Ren, Junpeng and Lai, Huayi and Wu, Hao and Tang, Bo and Wang, Zhenren and Fan, Zhaoxin and Zhang, Ningyu and Zhang, Linfeng and Yan, Junchi and Yang, Mingchuan and Xu, Tong and Xu, Wei and Chen, Huajun and Wang, Haofeng and Yang, Hongkang and Zhang, Wentao and Xu, Zhi-Qin John and Chen, Siheng and Xiong, Feiyu},
journal={arXiv preprint arXiv:2507.03724},
year={2025},
url={https://arxiv.org/abs/2507.03724}
}
@article{li2025memos_short,
title={MemOS: An Operating System for Memory-Augmented Generation (MAG) in Large Language Models},
author={Li, Zhiyu and Song, Shichao and Wang, Hanyu and Niu, Simin and Chen, Ding and Yang, Jiawei and Xi, Chenyang and Lai, Huayi and Zhao, Jihao and Wang, Yezhaohui and others},
journal={arXiv preprint arXiv:2505.22101},
year={2025},
url={https://arxiv.org/abs/2505.22101}
}
@article{yang2024memory3,
author = {Yang, Hongkang and Zehao, Lin and Wenjin, Wang and Wu, Hao and Zhiyu, Li and Tang, Bo and Wenqiang, Wei and Wang, Jinbo and Zeyun, Tang and Song, Shichao and Xi, Chenyang and Yu, Yu and Kai, Chen and Xiong, Feiyu and Tang, Linpeng and Weinan, E},
title = {Memory$^3$: Language Modeling with Explicit Memory},
journal = {Journal of Machine Learning},
year = {2024},
volume = {3},
number = {3},
pages = {300--346},
issn = {2790-2048},
doi = {https://doi.org/10.4208/jml.240708},
url = {https://global-sci.com/article/91443/memory3-language-modeling-with-explicit-memory}
}We welcome contributions from the community! Please read our contribution guidelines to get started.
MemOS is licensed under the Apache 2.0 License.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for MemOS
Similar Open Source Tools
MemOS
MemOS is an operating system for Large Language Models (LLMs) that enhances them with long-term memory capabilities. It allows LLMs to store, retrieve, and manage information, enabling more context-aware, consistent, and personalized interactions. MemOS provides Memory-Augmented Generation (MAG) with a unified API for memory operations, a Modular Memory Architecture (MemCube) for easy integration and management of different memory types, and multiple memory types including Textual Memory, Activation Memory, and Parametric Memory. It is extensible, allowing users to customize memory modules, data sources, and LLM integrations. MemOS demonstrates significant improvements over baseline memory solutions in multiple reasoning tasks, with a notable improvement in temporal reasoning accuracy compared to the OpenAI baseline.
Memori
Memori is a memory fabric designed for enterprise AI that seamlessly integrates into existing software and infrastructure. It is agnostic to LLM, datastore, and framework, providing support for major foundational models and databases. With features like vectorized memories, in-memory semantic search, and a knowledge graph, Memori simplifies the process of attributing LLM interactions and managing sessions. It offers Advanced Augmentation for enhancing memories at different levels and supports various platforms, frameworks, database integrations, and datastores. Memori is designed to reduce development overhead and provide efficient memory management for AI applications.
OpenViking
OpenViking is an open-source Context Database designed specifically for AI Agents. It aims to solve challenges in agent development by unifying memories, resources, and skills in a filesystem management paradigm. The tool offers tiered context loading, directory recursive retrieval, visualized retrieval trajectory, and automatic session management. Developers can interact with OpenViking like managing local files, enabling precise context manipulation and intuitive traceable operations. The tool supports various model services like OpenAI and Volcengine, enhancing semantic retrieval and context understanding for AI Agents.

deeppowers
Deeppowers is a powerful Python library for deep learning applications. It provides a wide range of tools and utilities to simplify the process of building and training deep neural networks. With Deeppowers, users can easily create complex neural network architectures, perform efficient training and optimization, and deploy models for various tasks. The library is designed to be user-friendly and flexible, making it suitable for both beginners and experienced deep learning practitioners.
sglang
SGLang is a structured generation language designed for large language models (LLMs). It makes your interaction with LLMs faster and more controllable by co-designing the frontend language and the runtime system. The core features of SGLang include: - **A Flexible Front-End Language**: This allows for easy programming of LLM applications with multiple chained generation calls, advanced prompting techniques, control flow, multiple modalities, parallelism, and external interaction. - **A High-Performance Runtime with RadixAttention**: This feature significantly accelerates the execution of complex LLM programs by automatic KV cache reuse across multiple calls. It also supports other common techniques like continuous batching and tensor parallelism.
FastFlowLM
FastFlowLM is a Python library for efficient and scalable language model inference. It provides a high-performance implementation of language model scoring using n-gram language models. The library is designed to handle large-scale text data and can be easily integrated into natural language processing pipelines for tasks such as text generation, speech recognition, and machine translation. FastFlowLM is optimized for speed and memory efficiency, making it suitable for both research and production environments.
GEN-AI
GEN-AI is a versatile Python library for implementing various artificial intelligence algorithms and models. It provides a wide range of tools and functionalities to support machine learning, deep learning, natural language processing, computer vision, and reinforcement learning tasks. With GEN-AI, users can easily build, train, and deploy AI models for diverse applications such as image recognition, text classification, sentiment analysis, object detection, and game playing. The library is designed to be user-friendly, efficient, and scalable, making it suitable for both beginners and experienced AI practitioners.

Fast-dLLM
Fast-DLLM is a diffusion-based Large Language Model (LLM) inference acceleration framework that supports efficient inference for models like Dream and LLaDA. It offers fast inference support, multiple optimization strategies, code generation, evaluation capabilities, and an interactive chat interface. Key features include Key-Value Cache for Block-Wise Decoding, Confidence-Aware Parallel Decoding, and overall performance improvements. The project structure includes directories for Dream and LLaDA model-related code, with installation and usage instructions provided for using the LLaDA and Dream models.
FastGPT
FastGPT is a knowledge base Q&A system based on the LLM large language model, providing out-of-the-box data processing, model calling and other capabilities. At the same time, you can use Flow to visually arrange workflows to achieve complex Q&A scenarios!

pdr_ai_v2
pdr_ai_v2 is a Python library for implementing machine learning algorithms and models. It provides a wide range of tools and functionalities for data preprocessing, model training, evaluation, and deployment. The library is designed to be user-friendly and efficient, making it suitable for both beginners and experienced data scientists. With pdr_ai_v2, users can easily build and deploy machine learning models for various applications, such as classification, regression, clustering, and more.

llm
The 'llm' package for Emacs provides an interface for interacting with Large Language Models (LLMs). It abstracts functionality to a higher level, concealing API variations and ensuring compatibility with various LLMs. Users can set up providers like OpenAI, Gemini, Vertex, Claude, Ollama, GPT4All, and a fake client for testing. The package allows for chat interactions, embeddings, token counting, and function calling. It also offers advanced prompt creation and logging capabilities. Users can handle conversations, create prompts with placeholders, and contribute by creating providers.

BentoVLLM
BentoVLLM is an example project demonstrating how to serve and deploy open-source Large Language Models using vLLM, a high-throughput and memory-efficient inference engine. It provides a basis for advanced code customization, such as custom models, inference logic, or vLLM options. The project allows for simple LLM hosting with OpenAI compatible endpoints without the need to write any code. Users can interact with the server using Swagger UI or other methods, and the service can be deployed to BentoCloud for better management and scalability. Additionally, the repository includes integration examples for different LLM models and tools.

semantic-router
The Semantic Router is an intelligent routing tool that utilizes a Mixture-of-Models (MoM) approach to direct OpenAI API requests to the most suitable models based on semantic understanding. It enhances inference accuracy by selecting models tailored to different types of tasks. The tool also automatically selects relevant tools based on the prompt to improve tool selection accuracy. Additionally, it includes features for enterprise security such as PII detection and prompt guard to protect user privacy and prevent misbehavior. The tool implements similarity caching to reduce latency. The comprehensive documentation covers setup instructions, architecture guides, and API references.
langgraphjs
LangGraph.js is a library for building stateful, multi-actor applications with LLMs, offering benefits such as cycles, controllability, and persistence. It allows defining flows involving cycles, providing fine-grained control over application flow and state. Inspired by Pregel and Apache Beam, it includes features like loops, persistence, human-in-the-loop workflows, and streaming support. LangGraph integrates seamlessly with LangChain.js and LangSmith but can be used independently.
neurons.me
Neurons.me is an open-source tool designed for creating and managing neural network models. It provides a user-friendly interface for building, training, and deploying deep learning models. With Neurons.me, users can easily experiment with different architectures, hyperparameters, and datasets to optimize their neural networks for various tasks. The tool simplifies the process of developing AI applications by abstracting away the complexities of model implementation and training.

cellm
Cellm is an Excel extension that allows users to leverage Large Language Models (LLMs) like ChatGPT within cell formulas. It enables users to extract AI responses to text ranges, making it useful for automating repetitive tasks that involve data processing and analysis. Cellm supports various models from Anthropic, Mistral, OpenAI, and Google, as well as locally hosted models via Llamafiles, Ollama, or vLLM. The tool is designed to simplify the integration of AI capabilities into Excel for tasks such as text classification, data cleaning, content summarization, entity extraction, and more.
For similar tasks
MemOS
MemOS is an operating system for Large Language Models (LLMs) that enhances them with long-term memory capabilities. It allows LLMs to store, retrieve, and manage information, enabling more context-aware, consistent, and personalized interactions. MemOS provides Memory-Augmented Generation (MAG) with a unified API for memory operations, a Modular Memory Architecture (MemCube) for easy integration and management of different memory types, and multiple memory types including Textual Memory, Activation Memory, and Parametric Memory. It is extensible, allowing users to customize memory modules, data sources, and LLM integrations. MemOS demonstrates significant improvements over baseline memory solutions in multiple reasoning tasks, with a notable improvement in temporal reasoning accuracy compared to the OpenAI baseline.

Step-DPO
Step-DPO is a method for enhancing long-chain reasoning ability of LLMs with a data construction pipeline creating a high-quality dataset. It significantly improves performance on math and GSM8K tasks with minimal data and training steps. The tool fine-tunes pre-trained models like Qwen2-7B-Instruct with Step-DPO, achieving superior results compared to other models. It provides scripts for training, evaluation, and deployment, along with examples and acknowledgements.

optillm
optillm is an OpenAI API compatible optimizing inference proxy implementing state-of-the-art techniques to enhance accuracy and performance of LLMs, focusing on reasoning over coding, logical, and mathematical queries. By leveraging additional compute at inference time, it surpasses frontier models across diverse tasks.
MoBA
MoBA (Mixture of Block Attention) is an innovative approach for long-context language models, enabling efficient processing of long sequences by dividing the full context into blocks and introducing a parameter-less gating mechanism. It allows seamless transitions between full and sparse attention modes, enhancing efficiency without compromising performance. MoBA has been deployed to support long-context requests and demonstrates significant advancements in efficient attention computation for large language models.
Awesome-RL-based-LLM-Reasoning
This repository is dedicated to enhancing Language Model (LLM) reasoning with reinforcement learning (RL). It includes a collection of the latest papers, slides, and materials related to RL-based LLM reasoning, aiming to facilitate quick learning and understanding in this field. Starring this repository allows users to stay updated and engaged with the forefront of RL-based LLM reasoning.
Awesome_Test_Time_LLMs
This repository focuses on test-time computing, exploring various strategies such as test-time adaptation, modifying the input, editing the representation, calibrating the output, test-time reasoning, and search strategies. It covers topics like self-supervised test-time training, in-context learning, activation steering, nearest neighbor models, reward modeling, and multimodal reasoning. The repository provides resources including papers and code for researchers and practitioners interested in enhancing the reasoning capabilities of large language models.
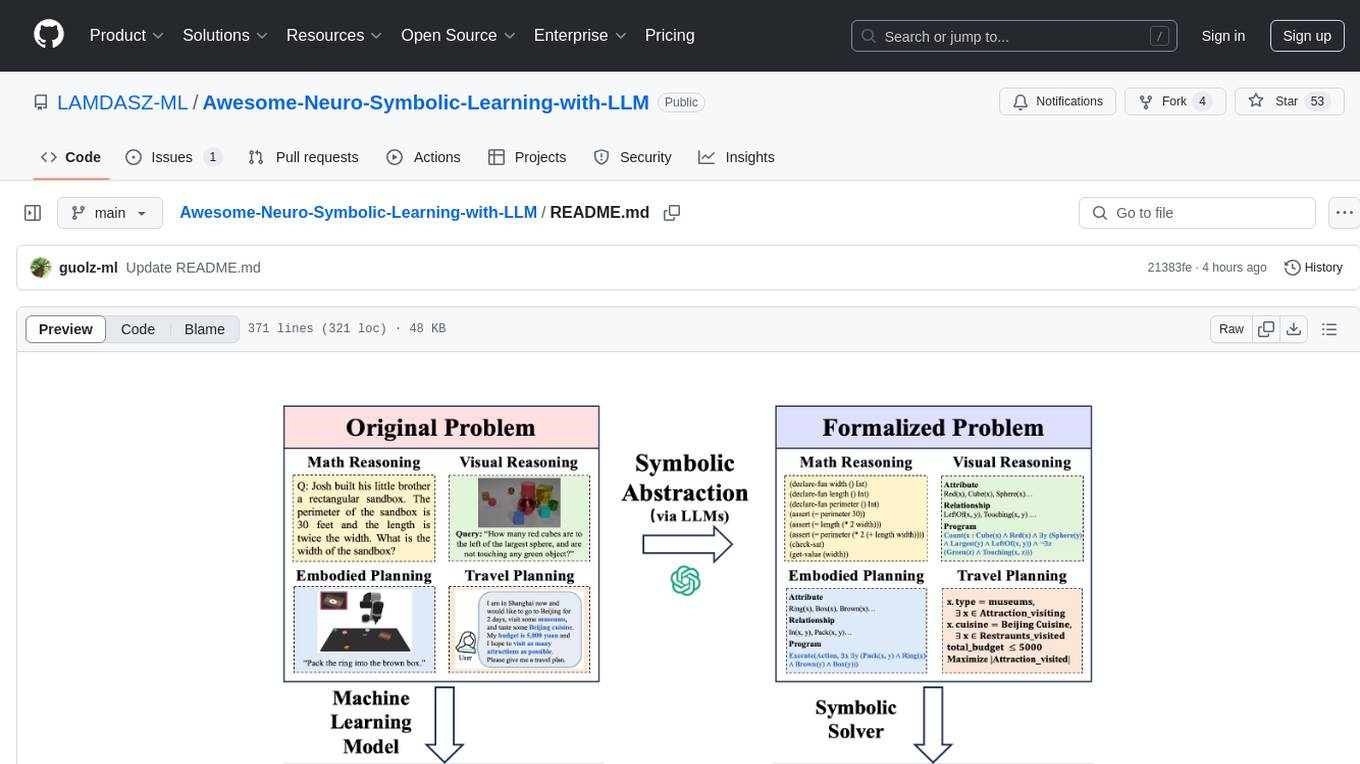
Awesome-Neuro-Symbolic-Learning-with-LLM
The Awesome-Neuro-Symbolic-Learning-with-LLM repository is a curated collection of papers and resources focusing on improving reasoning and planning capabilities of Large Language Models (LLMs) and Multi-Modal Large Language Models (MLLMs) through neuro-symbolic learning. It covers a wide range of topics such as neuro-symbolic visual reasoning, program synthesis, logical reasoning, mathematical reasoning, code generation, visual reasoning, geometric reasoning, classical planning, game AI planning, robotic planning, AI agent planning, and more. The repository provides a comprehensive overview of tutorials, workshops, talks, surveys, papers, datasets, and benchmarks related to neuro-symbolic learning with LLMs and MLLMs.
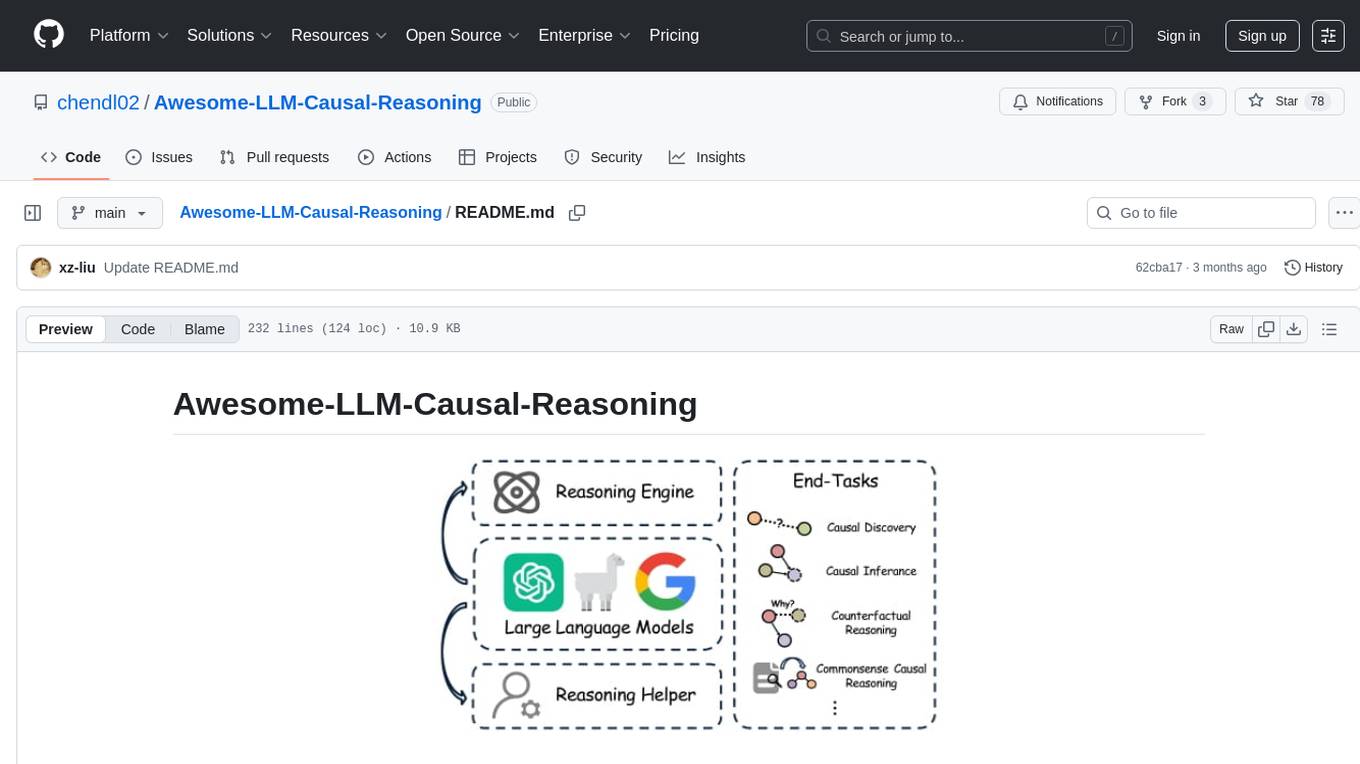
Awesome-LLM-Causal-Reasoning
The Awesome-LLM-Causal-Reasoning repository provides a comprehensive review of research focused on enhancing Large Language Models (LLMs) for causal reasoning (CR). It categorizes existing methods based on the role of LLMs as reasoning engines or helpers, evaluates LLMs' performance on various causal reasoning tasks, and discusses methodologies and insights for future research. The repository includes papers, datasets, and benchmarks related to causal reasoning in LLMs.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.