
Awesome-LLM-Causal-Reasoning
[NAACL 25 main] Awesome LLM Causal Reasoning is a collection of LLM-based casual reasoning works, including papers, codes and datasets.
Stars: 78
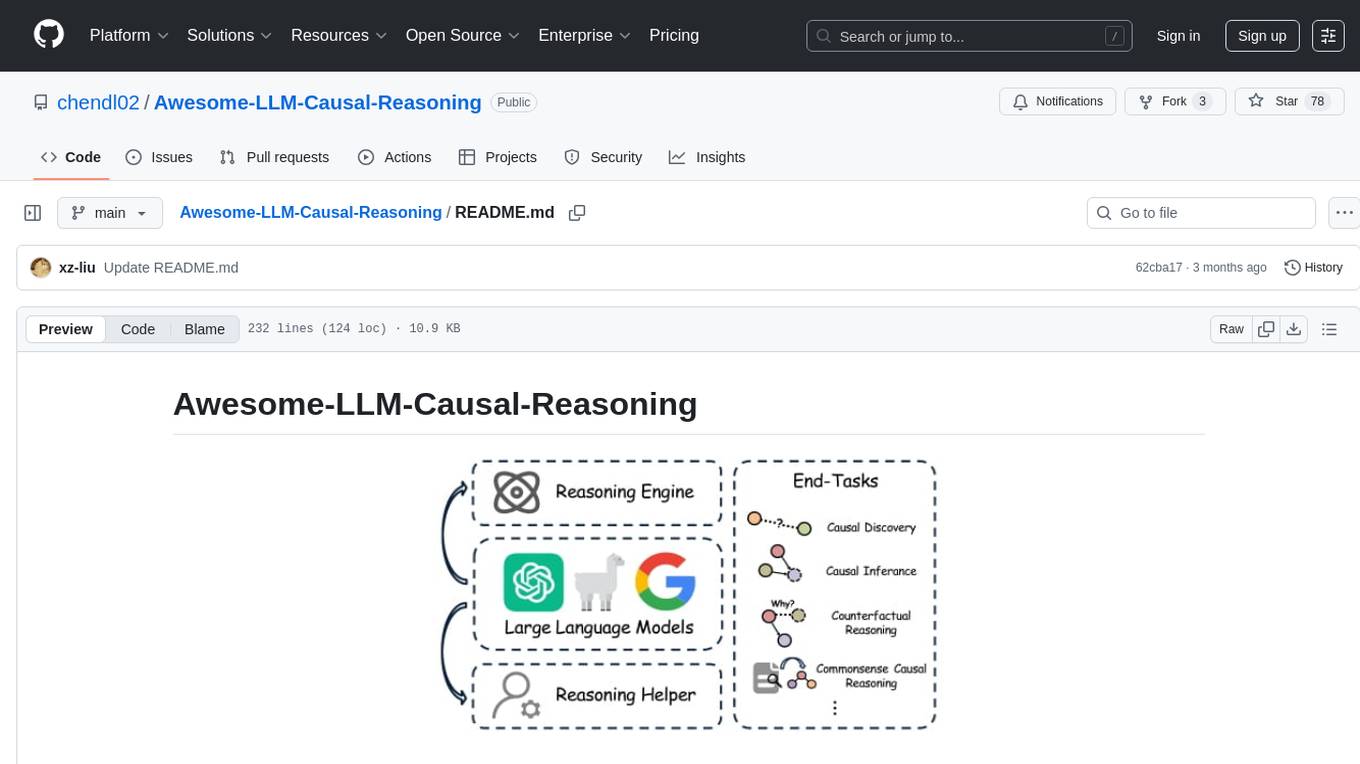
The Awesome-LLM-Causal-Reasoning repository provides a comprehensive review of research focused on enhancing Large Language Models (LLMs) for causal reasoning (CR). It categorizes existing methods based on the role of LLMs as reasoning engines or helpers, evaluates LLMs' performance on various causal reasoning tasks, and discusses methodologies and insights for future research. The repository includes papers, datasets, and benchmarks related to causal reasoning in LLMs.
README:
🔥🔥🔥 [NAACL 25 (main)] CausalEval: Towards Better Causal Reasoning in Language Models [Paper]
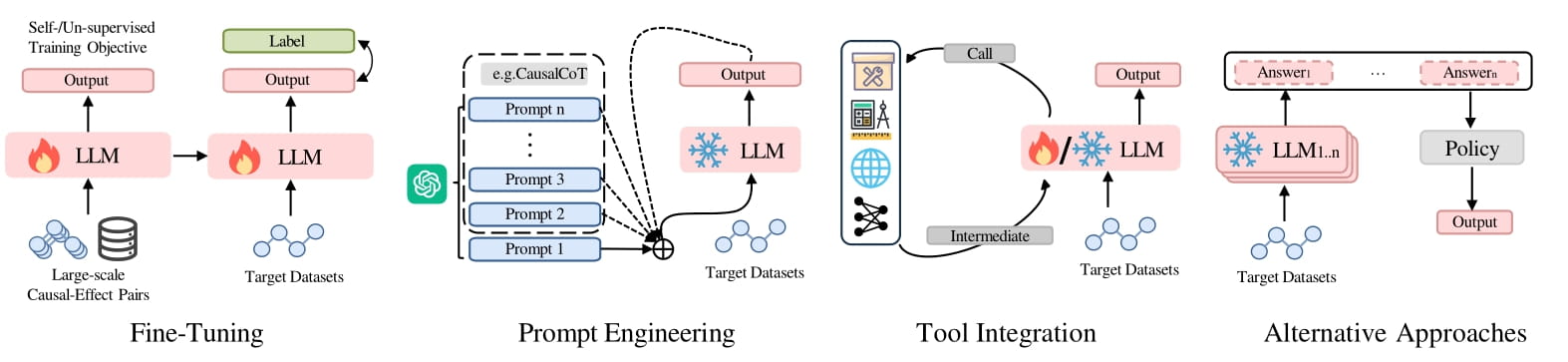
We provide a comprehensive review of research aimed at enhancing LLMs for causal reasoning (CR). We categorize existing methods based on the role of LLMs: either as reasoning engines or as helpers providing knowledge or data to traditional CR methods, followed by a detailed discussion of the methodologies in each category. We then evaluate the performance of LLMs on various causal reasoning tasks, providing key findings and in-depth analysis. Finally, we provide insights from current studies and highlight promising directions for future research.
Table of Contents
C2P: Featuring Large Language Models with Causal Reasoning
Abdolmahdi Bagheri, Matin Alinejad, Kevin Bello, Alireza Akhondi-Asl. Preprint'24
Large Language Model Cascades with Mixture of Thoughts Representations for Cost-efficient Reasoning.
Murong Yue, Jie Zhao, Min Zhang, Liang Du, Ziyu Yao. ICLR'2024
Large Language Model for Causal Decision Making.
Jiang, Haitao, Lin Ge, Yuhe Gao, Jianian Wang, and Rui Song. COLM'2024
Ziyi Tang, Ruilin Wang, Weixing Chen, Keze Wang, Yang Liu, Tianshui Chen, Liang Lin. Preprint'2023
CLadder: Assessing Causal Reasoning in Language Models
Zhijing Jin, Yuen Chen, Felix Leeb, Luigi Gresele, Ojasv Kamal, Zhiheng Lyu, Kevin Blin, Fernando Gonzalez Adauto, Max Kleiman-Weiner, Mrinmaya Sachan, Bernhard Schölkopf. NeurIPS'2023
Causal Reasoning of Entities and Events in Procedural Texts
Li Zhang, Hainiu Xu, Yue Yang, Shuyan Zhou, Weiqiu You, Manni Arora, Chris Callison-Burch. ACL'2023
Preserving Commonsense Knowledge from Pre-trained Language Models via Causal Inference
Junhao Zheng, Qianli Ma, Shengjie Qiu, Yue Wu, Peitian Ma, Junlong Liu, Huawen Feng, Xichen Shang, Haibin Chen. ACL'23
Answering Causal Questions with Augmented LLMs
Nick Pawlowski, James Vaughan, Joel Jennings, Cheng Zhang. ICML Workshop'2023
Neuro-Symbolic Procedural Planning with Commonsense Prompting
Yujie Lu, Weixi Feng, Wanrong Zhu, Wenda Xu, Xin Eric Wang, Miguel Eckstein, William Yang Wang. ICLR'2023
Faithful Reasoning Using Large Language Models.
Antonia Creswell, Murray Shanahan. Preprint'2022
Selection-Inference: Exploiting Large Language Models for Interpretable Logical Reasoning.
Antonia Creswell, Murray Shanahan, Irina Higgins. Preprint'2022
CausalBERT: Injecting Causal Knowledge Into Pre-trained Models with Minimal Supervision.
Zhongyang Li, Xiao Ding, Kuo Liao, Bing Qin, Ting Liu. Preprint'2021
LLM-Enhanced Causal Discovery in Temporal Domain from Interventional Data
Peiwen Li, Xin Wang, Zeyang Zhang, Yuan Meng, Fang Shen, Yue Li, Jialong Wang, Yang Li, Wenweu Zhu. Preprint'2024
Faithful Explanations of Black-box NLP Models Using LLM-generated Counterfactuals
Yair Ori Gat, Nitay Calderon, Amir Feder, Alexander Chapanin, Amit Sharma, Roi Reichart. ICLR'2024
Causal Structure Learning Supervised by Large Language Model
Taiyu Ban, Lyuzhou Chen, Derui Lyu, Xiangyu Wang, Huanhuan Chen. Preprint'2023
Neuro-Symbolic Integration Brings Causal and Reliable Reasoning Proofs
Sen Yang, Xin Li, Leyang Cui, Lidong Bing, Wai Lam. Preprint'2023
Extracting Self-Consistent Causal Insights from Users Feedback with LLMs and In-context Learning
Sara Abdali, Anjali Parikh, Steve Lim, Emre Kiciman. Preprint'2023
Improving Commonsense Causal Reasoning by Adversarial Training and Data Augmentation
Ieva Staliūnaitė, Philip John Gorinski, Ignacio Iacobacci. Preprint'2021
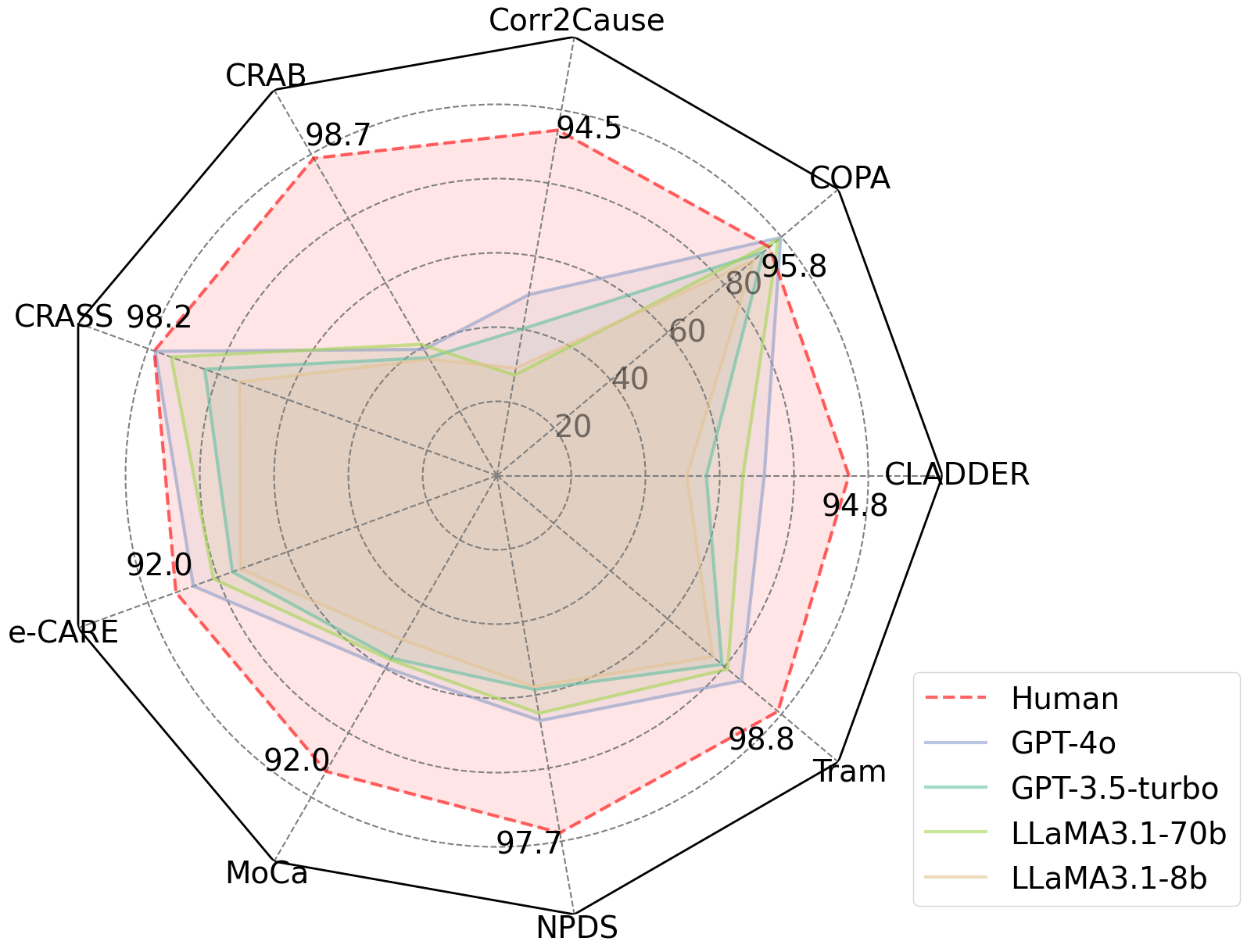
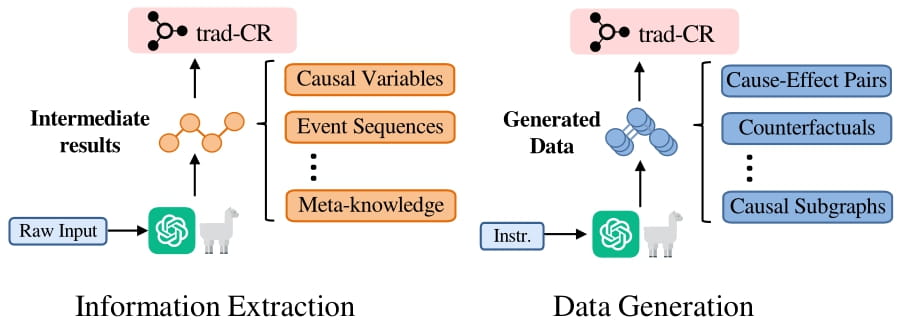
We first categorize the end tasks into three groups: causal discovery, causal inference, and additional causal tasks. For each category, we evaluate recent LLMs using pass@1 accuracy with strategies such as zero-shot, few-shot, direct I/O prompting, and Chain-of-Thought (CoT) reasoning.
To replicate our results, first navigate to the src directory, then run the eval_all.py script, which will generate the model results. Alternatively, browse the llm_result folder to review the raw data directly.
Each file in llm_result follows the naming convention:
{Model_name}_{seed}_{sample_num}_{few_shot}_{direct_io}.json
For example: claude-3-5-sonnet-20240620_seed_42_sample_num_100_few_shot_False_direct_io_True.json.
To explore the dataset, navigate to the dataset/{dataset_name} folder, and for the corresponding prompt, check the prompt/{dataset_name} folder. The merged results can be found in the result folder.
To acclearate the process, run the bash script run_all.sh to generate the results.
Can large language models infer causation from correlation
Zhijing Jin, Jiarui Liu, Zhiheng Lyu, Spencer Poff, Mrinmaya Sachan, Rada Mihalcea, Mona Diab, Bernhard Schölkopf. ICLR'2024
CausalQA: A Benchmark for Causal Question Answering
Alexander Bondarenko, Magdalena Wolska, Stefan Heindorf, Lukas Blübaum, Axel-Cyrille Ngonga Ngomo, Benno Stein, Pavel Braslavski, Matthias Hagen, Martin Potthast. ACL'2022
e-CARE: a New Dataset for Exploring Explainable Causal Reasoning
- Li Du, Xiao Ding, Kai Xiong, Ting Liu, and Bing Qin.* ACL'2022
CausaLM: Causal Model Explanation Through Counterfactual Language Models
- Amir Feder, Nadav Oved, Uri Shalit, Roi Reichart.* ACL'2021
CRAB:Assessing the Strength of Causal Relationships Between Real-World Events
Angelika Romanou, Syrielle Montariol, Debjit Paul, Léo Laugier, Karl Aberer, Antoine Bosselut. EMNLP'2023
CLadder: Assessing Causal Reasoning in Language Models
Zhijing Jin, Yuen Chen, Felix Leeb, Luigi Gresele, Ojasv Kamal, Zhiheng Lyu, Kevin Blin, Fernando Gonzalez Adauto, Max Kleiman-Weiner, Mrinmaya Sachan, Bernhard Schölkopf. NeurIPS'2023
COLA: Contextualized Commonsense Causal Reasoning from the Causal Inference Perspective
Zhaowei Wang, Quyet V. Do, Hongming Zhang, Jiayao Zhang, Weiqi Wang, Tianqing Fang, Yangqiu Song, Ginny Wong, Simon See. ACL'2023
Abductive Commonsense Reasoning
Chandra Bhagavatula, Ronan Le Bras, Chaitanya Malaviya, Keisuke Sakaguchi, Ari Holtzman, Hannah Rashkin, Doug Downey, Scott Wen-tau Yih, Yejin Choi. ICLR'2020
TRAM: Benchmarking Temporal Reasoning for Large Language Models
Yuqing Wang, Yun Zhao. ACL'2024
MoCa: Measuring Human-Language Model Alignment on Causal and Moral Judgment Tasks
Allen Nie, Yuhui Zhang, Atharva Amdekar, Chris Piech, Tatsunori Hashimoto, Tobias Gerstenberg. NeurIPS'2023
CRASS: A Novel Data Set and Benchmark to Test Counterfactual Reasoning of Large Language Models
Jörg Frohberg, Frank Binder. LREC'2022
@inproceedings{yu-etal-2025-causaleval,
title = "{C}ausal{E}val: Towards Better Causal Reasoning in Language Models",
author = "Yu, Longxuan and
Chen, Delin and
Xiong, Siheng and
Wu, Qingyang and
Li, Dawei and
Chen, Zhikai and
Liu, Xiaoze and
Pan, Liangming",
editor = "Chiruzzo, Luis and
Ritter, Alan and
Wang, Lu",
booktitle = "Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)",
month = apr,
year = "2025",
address = "Albuquerque, New Mexico",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.naacl-long.622/",
pages = "12512--12540",
ISBN = "979-8-89176-189-6",
abstract = "Causal reasoning (CR) is a crucial aspect of intelligence, essential for problem-solving, decision-making, and understanding the world. While language models (LMs) can generate rationales for their outputs, their ability to reliably perform causal reasoning remains uncertain, often falling short in tasks requiring a deep understanding of causality. In this paper, we introduce CausalEval, a comprehensive review of research aimed at enhancing LMs for causal reasoning, coupled with an empirical evaluation of current models and methods. We categorize existing methods based on the role of LMs: either as reasoning engines or as helpers providing knowledge or data to traditional CR methods, followed by a detailed discussion of methodologies in each category. We then assess the performance of current LMs and various enhancement methods on a range of causal reasoning tasks, providing key findings and in-depth analysis. Finally, we present insights from current studies and highlight promising directions for future research. We aim for this work to serve as a comprehensive resource, fostering further advancements in causal reasoning with LMs."
}
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Awesome-LLM-Causal-Reasoning
Similar Open Source Tools
Awesome-LLM-Causal-Reasoning
The Awesome-LLM-Causal-Reasoning repository provides a comprehensive review of research focused on enhancing Large Language Models (LLMs) for causal reasoning (CR). It categorizes existing methods based on the role of LLMs as reasoning engines or helpers, evaluates LLMs' performance on various causal reasoning tasks, and discusses methodologies and insights for future research. The repository includes papers, datasets, and benchmarks related to causal reasoning in LLMs.
AI-PhD-S25
AI-PhD-S25 is a mono-repo for the DOTE 6635 course on AI for Business Research at CUHK Business School. The course aims to provide a fundamental understanding of ML/AI concepts and methods relevant to business research, explore applications of ML/AI in business research, and discover cutting-edge AI/ML technologies. The course resources include Google CoLab for code distribution, Jupyter Notebooks, Google Sheets for group tasks, Overleaf template for lecture notes, replication projects, and access to HPC Server compute resource. The course covers topics like AI/ML in business research, deep learning basics, attention mechanisms, transformer models, LLM pretraining, posttraining, causal inference fundamentals, and more.
AI-PhD-S24
AI-PhD-S24 is a mono-repo for the PhD course 'AI for Business Research' at CUHK Business School in Spring 2024. The course aims to provide a basic understanding of machine learning and artificial intelligence concepts/methods used in business research, showcase how ML/AI is utilized in business research, and introduce state-of-the-art AI/ML technologies. The course includes scribed lecture notes, class recordings, and covers topics like AI/ML fundamentals, DL, NLP, CV, unsupervised learning, and diffusion models.

Time-LLM
Time-LLM is a reprogramming framework that repurposes large language models (LLMs) for time series forecasting. It allows users to treat time series analysis as a 'language task' and effectively leverage pre-trained LLMs for forecasting. The framework involves reprogramming time series data into text representations and providing declarative prompts to guide the LLM reasoning process. Time-LLM supports various backbone models such as Llama-7B, GPT-2, and BERT, offering flexibility in model selection. The tool provides a general framework for repurposing language models for time series forecasting tasks.

llm-self-correction-papers
This repository contains a curated list of papers focusing on the self-correction of large language models (LLMs) during inference. It covers various frameworks for self-correction, including intrinsic self-correction, self-correction with external tools, self-correction with information retrieval, and self-correction with training designed specifically for self-correction. The list includes survey papers, negative results, and frameworks utilizing reinforcement learning and OpenAI o1-like approaches. Contributions are welcome through pull requests following a specific format.
interpret
InterpretML is an open-source package that incorporates state-of-the-art machine learning interpretability techniques under one roof. With this package, you can train interpretable glassbox models and explain blackbox systems. InterpretML helps you understand your model's global behavior, or understand the reasons behind individual predictions. Interpretability is essential for: - Model debugging - Why did my model make this mistake? - Feature Engineering - How can I improve my model? - Detecting fairness issues - Does my model discriminate? - Human-AI cooperation - How can I understand and trust the model's decisions? - Regulatory compliance - Does my model satisfy legal requirements? - High-risk applications - Healthcare, finance, judicial, ...
FedLLM-Bench
FedLLM-Bench is a realistic benchmark for the Federated Learning of Large Language Models community. It includes datasets for federated instruction tuning and preference alignment tasks, exhibiting diversities in language, quality, quantity, instruction, sequence length, embedding, and preference. The repository provides training scripts and code for open-ended evaluation, aiming to facilitate research and development in federated learning of large language models.
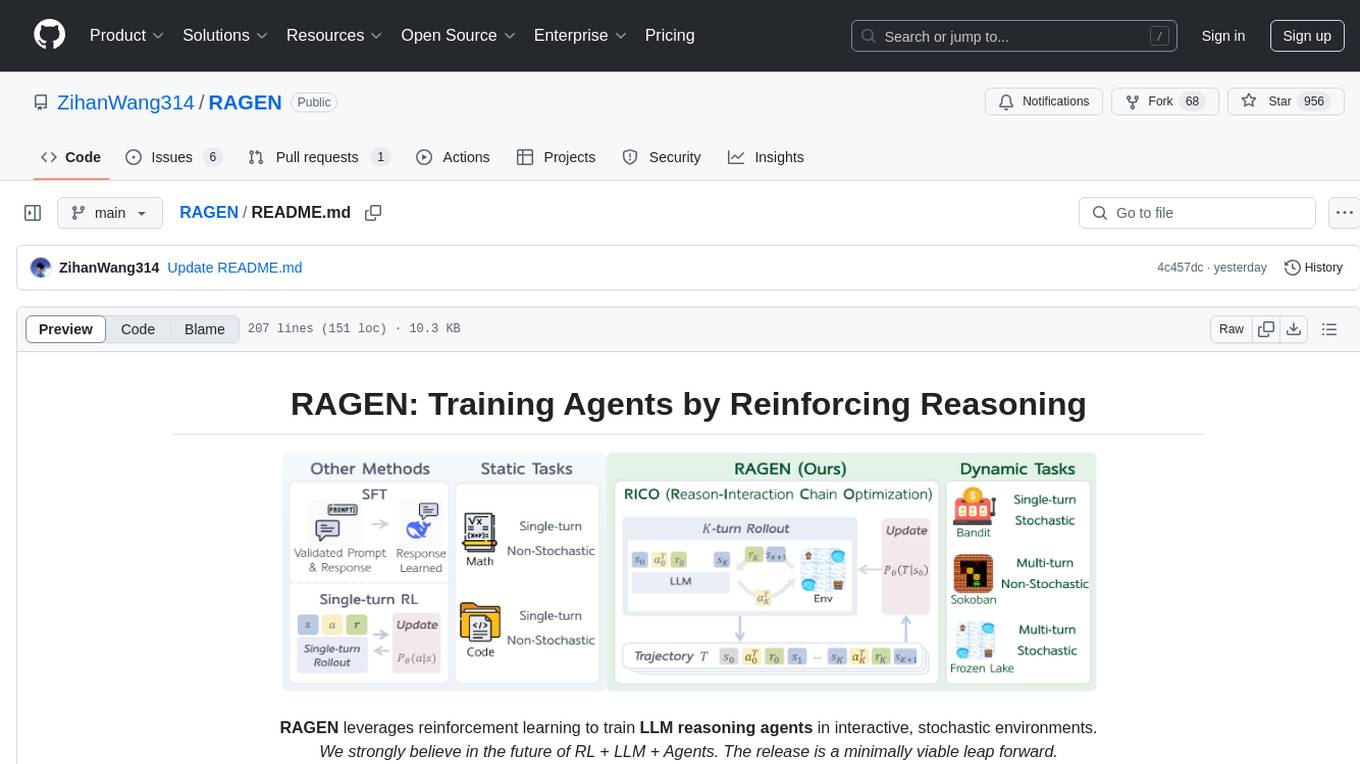
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework enables LLMs to reason and interact with the environment, optimizing entire trajectories for long-horizon reasoning while maintaining computational efficiency.
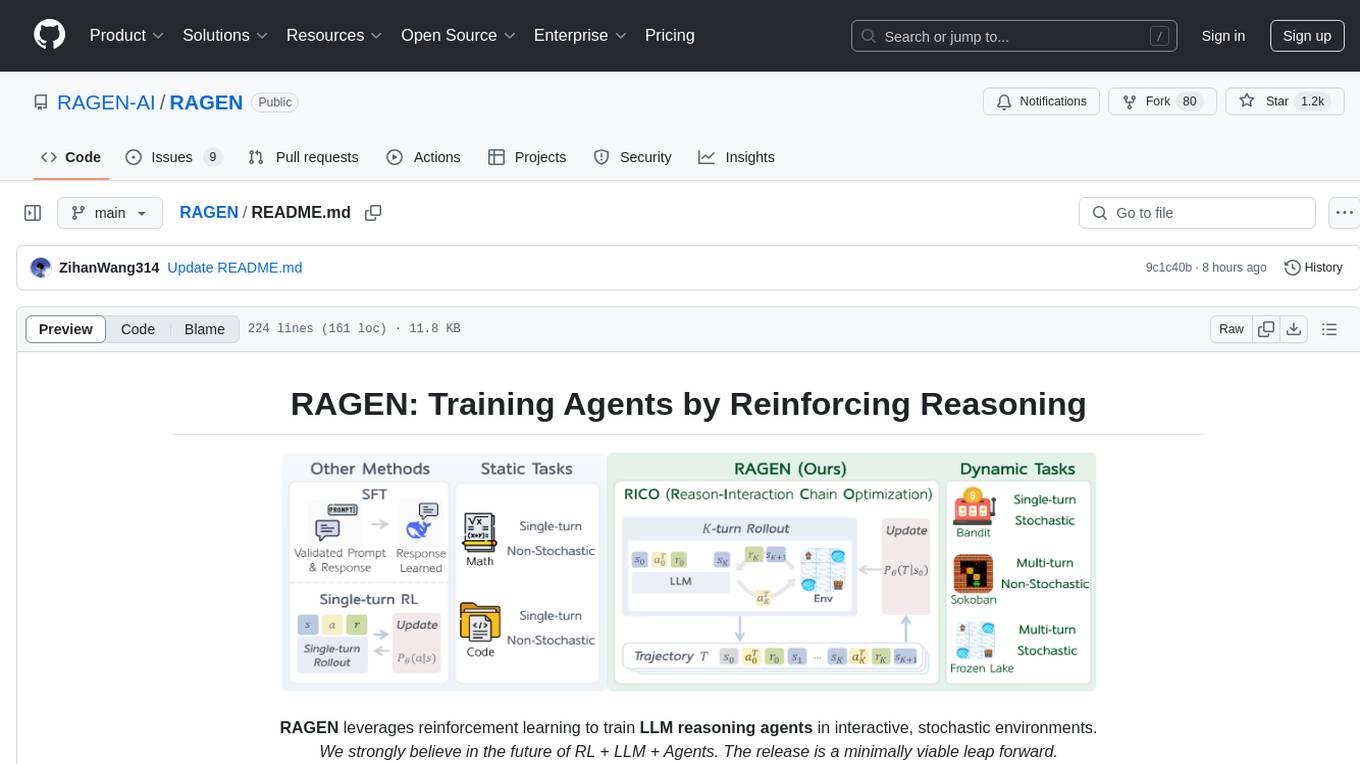
RAGEN
RAGEN is a reinforcement learning framework designed to train reasoning-capable large language model (LLM) agents in interactive, stochastic environments. It addresses challenges such as multi-turn interactions and stochastic environments through a Markov Decision Process (MDP) formulation, Reason-Interaction Chain Optimization (RICO) algorithm, and progressive reward normalization strategies. The framework consists of MDP formulation, RICO algorithm with rollout and update stages, and reward normalization strategies to stabilize training. RAGEN aims to optimize reasoning and action strategies for LLM agents operating in complex environments.

Slow_Thinking_with_LLMs
STILL is an open-source project exploring slow-thinking reasoning systems, focusing on o1-like reasoning systems. The project has released technical reports on enhancing LLM reasoning with reward-guided tree search algorithms and implementing slow-thinking reasoning systems using an imitate, explore, and self-improve framework. The project aims to replicate the capabilities of industry-level reasoning systems by fine-tuning reasoning models with long-form thought data and iteratively refining training datasets.

MMMU
MMMU is a benchmark designed to evaluate multimodal models on college-level subject knowledge tasks, covering 30 subjects and 183 subfields with 11.5K questions. It focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. The evaluation of various models highlights substantial challenges, with room for improvement to stimulate the community towards expert artificial general intelligence (AGI).
awesome-hallucination-detection
This repository provides a curated list of papers, datasets, and resources related to the detection and mitigation of hallucinations in large language models (LLMs). Hallucinations refer to the generation of factually incorrect or nonsensical text by LLMs, which can be a significant challenge for their use in real-world applications. The resources in this repository aim to help researchers and practitioners better understand and address this issue.
AIRS
AIRS is a collection of open-source software tools, datasets, and benchmarks focused on Artificial Intelligence for Science in Quantum, Atomistic, and Continuum Systems. The goal is to develop and maintain an integrated, open, reproducible, and sustainable set of resources to advance the field of AI for Science. The current resources include tools for Quantum Mechanics, Density Functional Theory, Small Molecules, Protein Science, Materials Science, Molecular Interactions, and Partial Differential Equations.
vector-search-class-notes
The 'vector-search-class-notes' repository contains class materials for a course on Long Term Memory in AI, focusing on vector search and databases. The course covers theoretical foundations and practical implementation of vector search applications, algorithms, and systems. It explores the intersection of Artificial Intelligence and Database Management Systems, with topics including text embeddings, image embeddings, low dimensional vector search, dimensionality reduction, approximate nearest neighbor search, clustering, quantization, and graph-based indexes. The repository also includes information on the course syllabus, project details, selected literature, and contributions from industry experts in the field.

MathCoder
MathCoder is a repository focused on enhancing mathematical reasoning by fine-tuning open-source language models to use code for modeling and deriving math equations. It introduces MathCodeInstruct dataset with solutions interleaving natural language, code, and execution results. The repository provides MathCoder models capable of generating code-based solutions for challenging math problems, achieving state-of-the-art scores on MATH and GSM8K datasets. It offers tools for model deployment, inference, and evaluation, along with a citation for referencing the work.
Genesis
Genesis is a physics platform designed for general purpose Robotics/Embodied AI/Physical AI applications. It includes a universal physics engine, a lightweight, ultra-fast, pythonic, and user-friendly robotics simulation platform, a powerful and fast photo-realistic rendering system, and a generative data engine that transforms user-prompted natural language description into various modalities of data. It aims to lower the barrier to using physics simulations, unify state-of-the-art physics solvers, and minimize human effort in collecting and generating data for robotics and other domains.
For similar tasks
Awesome-LLM-Causal-Reasoning
The Awesome-LLM-Causal-Reasoning repository provides a comprehensive review of research focused on enhancing Large Language Models (LLMs) for causal reasoning (CR). It categorizes existing methods based on the role of LLMs as reasoning engines or helpers, evaluates LLMs' performance on various causal reasoning tasks, and discusses methodologies and insights for future research. The repository includes papers, datasets, and benchmarks related to causal reasoning in LLMs.

phospho
Phospho is a text analytics platform for LLM apps. It helps you detect issues and extract insights from text messages of your users or your app. You can gather user feedback, measure success, and iterate on your app to create the best conversational experience for your users.

Awesome-Segment-Anything
Awesome-Segment-Anything is a powerful tool for segmenting and extracting information from various types of data. It provides a user-friendly interface to easily define segmentation rules and apply them to text, images, and other data formats. The tool supports both supervised and unsupervised segmentation methods, allowing users to customize the segmentation process based on their specific needs. With its versatile functionality and intuitive design, Awesome-Segment-Anything is ideal for data analysts, researchers, content creators, and anyone looking to efficiently extract valuable insights from complex datasets.
mslearn-knowledge-mining
The mslearn-knowledge-mining repository contains lab files for Azure AI Knowledge Mining modules. It provides resources for learning and implementing knowledge mining techniques using Azure AI services. The repository is designed to help users explore and understand how to leverage AI for knowledge mining purposes within the Azure ecosystem.
summarize
The 'summarize' tool is designed to transcribe and summarize videos from various sources using AI models. It helps users efficiently summarize lengthy videos, take notes, and extract key insights by providing timestamps, original transcripts, and support for auto-generated captions. Users can utilize different AI models via Groq, OpenAI, or custom local models to generate grammatically correct video transcripts and extract wisdom from video content. The tool simplifies the process of summarizing video content, making it easier to remember and reference important information.
docq
Docq is a private and secure GenAI tool designed to extract knowledge from business documents, enabling users to find answers independently. It allows data to stay within organizational boundaries, supports self-hosting with various cloud vendors, and offers multi-model and multi-modal capabilities. Docq is extensible, open-source (AGPLv3), and provides commercial licensing options. The tool aims to be a turnkey solution for organizations to adopt AI innovation safely, with plans for future features like more data ingestion options and model fine-tuning.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.

codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.
For similar jobs
Detection-and-Classification-of-Alzheimers-Disease
This tool is designed to detect and classify Alzheimer's Disease using Deep Learning and Machine Learning algorithms on an early basis, which is further optimized using the Crow Search Algorithm (CSA). Alzheimer's is a fatal disease, and early detection is crucial for patients to predetermine their condition and prevent its progression. By analyzing MRI scanned images using Artificial Intelligence technology, this tool can classify patients who may or may not develop AD in the future. The CSA algorithm, combined with ML algorithms, has proven to be the most effective approach for this purpose.

Co-LLM-Agents
This repository contains code for building cooperative embodied agents modularly with large language models. The agents are trained to perform tasks in two different environments: ThreeDWorld Multi-Agent Transport (TDW-MAT) and Communicative Watch-And-Help (C-WAH). TDW-MAT is a multi-agent environment where agents must transport objects to a goal position using containers. C-WAH is an extension of the Watch-And-Help challenge, which enables agents to send messages to each other. The code in this repository can be used to train agents to perform tasks in both of these environments.
awesome-synthetic-datasets
This repository focuses on organizing resources for building synthetic datasets using large language models. It covers important datasets, libraries, tools, tutorials, and papers related to synthetic data generation. The goal is to provide pragmatic and practical resources for individuals interested in creating synthetic datasets for machine learning applications.
ai-devices
AI Devices Template is a project that serves as an AI-powered voice assistant utilizing various AI models and services to provide intelligent responses to user queries. It supports voice input, transcription, text-to-speech, image processing, and function calling with conditionally rendered UI components. The project includes customizable UI settings, optional rate limiting using Upstash, and optional tracing with Langchain's LangSmith for function execution. Users can clone the repository, install dependencies, add API keys, start the development server, and deploy the application. Configuration settings can be modified in `app/config.tsx` to adjust settings and configurations for the AI-powered voice assistant.
ROSGPT_Vision
ROSGPT_Vision is a new robotic framework designed to command robots using only two prompts: a Visual Prompt for visual semantic features and an LLM Prompt to regulate robotic reactions. It is based on the Prompting Robotic Modalities (PRM) design pattern and is used to develop CarMate, a robotic application for monitoring driver distractions and providing real-time vocal notifications. The framework leverages state-of-the-art language models to facilitate advanced reasoning about image data and offers a unified platform for robots to perceive, interpret, and interact with visual data through natural language. LangChain is used for easy customization of prompts, and the implementation includes the CarMate application for driver monitoring and assistance.
AIBotPublic
AIBotPublic is an open-source version of AIBotPro, a comprehensive AI tool that provides various features such as knowledge base construction, AI drawing, API hosting, and more. It supports custom plugins and parallel processing of multiple files. The tool is built using bootstrap4 for the frontend, .NET6.0 for the backend, and utilizes technologies like SqlServer, Redis, and Milvus for database and vector database functionalities. It integrates third-party dependencies like Baidu AI OCR, Milvus C# SDK, Google Search, and more to enhance its capabilities.

LLMGA
LLMGA (Multimodal Large Language Model-based Generation Assistant) is a tool that leverages Large Language Models (LLMs) to assist users in image generation and editing. It provides detailed language generation prompts for precise control over Stable Diffusion (SD), resulting in more intricate and precise content in generated images. The tool curates a dataset for prompt refinement, similar image generation, inpainting & outpainting, and visual question answering. It offers a two-stage training scheme to optimize SD alignment and a reference-based restoration network to alleviate texture, brightness, and contrast disparities in image editing. LLMGA shows promising generative capabilities and enables wider applications in an interactive manner.
MetaAgent
MetaAgent is a multi-agent collaboration platform designed to build, manage, and deploy multi-modal AI agents without the need for coding. Users can easily create AI agents by editing a yml file or using the provided UI. The platform supports features such as building LLM-based AI agents, multi-modal interactions with users using texts, audios, images, and videos, creating a company of agents for complex tasks like drawing comics, vector database and knowledge embeddings, and upcoming features like UI for creating and using AI agents, fine-tuning, and RLHF. The tool simplifies the process of creating and deploying AI agents for various tasks.