
summarize
Video transcript summarization from multiple sources (YouTube, Dropbox, Google Drive, local files) using multiple LLM endpoints (OpenAI, Groq, custom model).
Stars: 129
The 'summarize' tool is designed to transcribe and summarize videos from various sources using AI models. It helps users efficiently summarize lengthy videos, take notes, and extract key insights by providing timestamps, original transcripts, and support for auto-generated captions. Users can utilize different AI models via Groq, OpenAI, or custom local models to generate grammatically correct video transcripts and extract wisdom from video content. The tool simplifies the process of summarizing video content, making it easier to remember and reference important information.
README:
A tool to transcribe and summarize videos from various sources using AI. Supports YouTube, Google Drive, Dropbox, and local files.
How to use it ?
- CLI - Command line interface for batch processing and automation
-
Google Colab -
Interactive notebook with visual interface
- (roadmap) Streamlit - Web-based GUI for easy video summarization
https://github.com/user-attachments/assets/4641743a-2d0e-4b54-9f82-8195431db3cb
-
Multiple Video Sources:
- YouTube (with automatic caption support)
- Google Drive
- Dropbox
- Local files
-
Flexible API Support:
- Works with any OpenAI-compatible API endpoint
- Configurable models and parameters
-
Smart Processing:
- Uses YouTube captions when available (faster & free)
- Falls back to audio download & transcription if needed
- Processes multiple videos in one command
-
Output Options:
- Automatic saving to markdown files
- Customizable output directory
- Timestamped summaries
# Clone the repository
git clone https://github.com/martinopiaggi/summarize.git
cd summarize
# Install the package
pip install -e .-
Basic (YouTube captions)
python -m summarizer --source "https://www.youtube.com/watch?v=VIDEO_ID" --base-url "https://generativelanguage.googleapis.com/v1beta/openai" --model "gemini-2.5-flash-lite"
-
Multiple videos
python -m summarizer --source "https://youtube.com/watch?v=ID1" "https://youtube.com/watch?v=ID2" --base-url "https://api.groq.com/openai/v1" --model "openai/gpt-oss-20b"
-
Force audio (skip captions)
python -m summarizer --source "https://youtube.com/watch?v=VIDEO_ID" --base-url "https://api.deepseek.com/v1" --model "deepseek-chat" --force-download
-
Choose style
python -m summarizer --source "https://youtube.com/watch?v=VIDEO_ID" --base-url "https://api.deepseek.com/v1" --model "deepseek-chat" --prompt-type "Distill Wisdom"
-
Verbose logs
python -m summarizer --source "https://youtube.com/watch?v=VIDEO_ID" --base-url "https://api.deepseek.com/v1" --model "deepseek-chat" --verbose
-
Providers quick picks
- OpenAI:
python -m summarizer --base-url "https://api.openai.com/v1" --model "gpt-5-nano-2025-08-07" --source "https://www.youtube.com/watch?v=VIDEO_ID" - Groq:
python -m summarizer --base-url "https://api.groq.com/openai/v1" --model "openai/gpt-oss-20b" --source "https://www.youtube.com/watch?v=VIDEO_ID" - Deepseek:
python -m summarizer --base-url "https://api.deepseek.com/v1" --model "deepseek-chat" --source "https://www.youtube.com/watch?v=VIDEO_ID" - Hyperbolic (Llama):
python -m summarizer --base-url "https://api.hyperbolic.xyz/v1" --model "meta-llama/Llama-3.3-70B-Instruct" --source "https://www.youtube.com/watch?v=VIDEO_ID"
- OpenAI:
-
Local files
- `python -m summarizer --type "Local File" --base-url "https://api.deepseek.com/v1" --model "deepseek-chat" --source "./lecture.mp4" "./lecture2.mp4" "./lecture3.mp4"
-
Long videos (bigger chunks)
python -m summarizer --base-url "https://generativelanguage.googleapis.com/v1beta/openai" --model "gemini-2.5-flash-lite" --chunk-size 28000 --source "https://www.youtube.com/watch?v=VIDEO_ID"
-
Style + provider combo
- Gemini + Distill:
python -m summarizer --base-url "https://generativelanguage.googleapis.com/v1beta/openai" --model "gemini-2.5-flash-lite" --prompt-type "Distill Wisdom" --source "https://www.youtube.com/watch?v=VIDEO_ID" - Perplexity + Fact Check:
python -m summarizer --base-url "https://api.perplexity.ai" --model "sonar-pro" --prompt-type "Fact Checker" --chunk-size 100000 --source "https://www.youtube.com/watch?v=VIDEO_ID"
- Gemini + Distill:
| Option | Description | Default |
|---|---|---|
--source |
One or more video sources (URLs or filenames) | Required |
--base-url |
API endpoint URL | Required |
--model |
Model to use | Required |
--api-key |
API key (or use .env) | Optional |
--type |
Source type | "YouTube Video" |
--force-download |
Skip captions, use audio | False |
--output-dir |
Save directory | "summaries" |
--no-save |
Don't save to files | False |
--prompt-type |
Summary style | "Questions and answers" |
--language |
Language code | "auto" |
--chunk-size |
Input text chunk size | 10000 |
--parallel-calls |
Parallel API calls | 30 |
--max-tokens |
Max output tokens for each chunk | 4096 |
--verbose, -v
|
Enable detailed progress output | False |
Built-in templates live in summarizer/prompts.json. Select with --prompt-type "<Name>".
-
Summarization
- Concise narrative with a bold title; conversational tone.
-
Only grammar correction with highlights
- Same text, corrected; only key quotes are bold; no intro text.
-
Distill Wisdom
- Strict template: TITLE, IDEAS, QUOTES, REFERENCES; bullet-only, omit empty sections.
-
Questions and answers
- Unnumbered bold questions with detailed answers; no preamble.
-
Essay Writing in Paul Graham Style
- ≤250 words; simple, clear prose; no clichés or concluding phrases.
-
Research
- Core insights + added context/background; connects to broader themes.
-
DNA Extractor
- <=200 words of distilled “core truth” in pure thought form; no meta text.
-
Fact Checker
- Claims labeled TRUE/FALSE/MISLEADING/UNVERIFIABLE with reasoning and sources; overall verdict.
Tip: Names must match exactly as in prompts.json. Easily extend or add styles by editing that file, then pass the new name via --prompt-type.
You can set default API keys in a .env file:
api_key=your_default_api_keyOr provide them directly via --api-key parameter.
- YouTube videos use captions by default (faster & free)
- Summaries are automatically saved to markdown files
- Each summary includes source URL and timestamp
- Non-YouTube sources always use audio download
This is an example of (randomized api keys here) of my .env :
groq = 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
openai = sk-proj-HaW8cZ_9er50L3f5Q0Nkavu3EyAb1B1EyAb1BXf5Q0Nkavr
perplexity = pplx-Na7TCdZoKyEVqRpp2xWJtUmvh63HEyAb1BqnMWPYXsJg9
generativelanguage = AIzaSyAl9bTw6XUPqKdAVFYZNXDOCPlERcTfGPkKeep in mind that you can always add new services and the program will automatically pick the correct key (matching based on keywords in the API URL).
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for summarize
Similar Open Source Tools
summarize
The 'summarize' tool is designed to transcribe and summarize videos from various sources using AI models. It helps users efficiently summarize lengthy videos, take notes, and extract key insights by providing timestamps, original transcripts, and support for auto-generated captions. Users can utilize different AI models via Groq, OpenAI, or custom local models to generate grammatically correct video transcripts and extract wisdom from video content. The tool simplifies the process of summarizing video content, making it easier to remember and reference important information.
oxylabs-mcp
The Oxylabs MCP Server acts as a bridge between AI models and the web, providing clean, structured data from any site. It enables scraping of URLs, rendering JavaScript-heavy pages, content extraction for AI use, bypassing anti-scraping measures, and accessing geo-restricted web data from 195+ countries. The implementation utilizes the Model Context Protocol (MCP) to facilitate secure interactions between AI assistants and web content. Key features include scraping content from any site, automatic data cleaning and conversion, bypassing blocks and geo-restrictions, flexible setup with cross-platform support, and built-in error handling and request management.
ai
A TypeScript toolkit for building AI-driven video workflows on the server, powered by Mux! @mux/ai provides purpose-driven workflow functions and primitive functions that integrate with popular AI/LLM providers like OpenAI, Anthropic, and Google. It offers pre-built workflows for tasks like generating summaries and tags, content moderation, chapter generation, and more. The toolkit is cost-effective, supports multi-modal analysis, tone control, and configurable thresholds, and provides full TypeScript support. Users can easily configure credentials for Mux and AI providers, as well as cloud infrastructure like AWS S3 for certain workflows. @mux/ai is production-ready, offers composable building blocks, and supports universal language detection.
core
CORE is an open-source unified, persistent memory layer for all AI tools, allowing developers to maintain context across different tools like Cursor, ChatGPT, and Claude. It aims to solve the issue of context switching and information loss between sessions by creating a knowledge graph that remembers conversations, decisions, and insights. With features like unified memory, temporal knowledge graph, browser extension, chat with memory, auto-sync from apps, and MCP integration hub, CORE provides a seamless experience for managing and recalling context. The tool's ingestion pipeline captures evolving context through normalization, extraction, resolution, and graph integration, resulting in a dynamic memory that grows and changes with the user. When recalling from memory, CORE utilizes search, re-ranking, filtering, and output to provide relevant and contextual answers. Security measures include data encryption, authentication, access control, and vulnerability reporting.
paperless-gpt
paperless-gpt is a tool designed to generate accurate and meaningful document titles and tags for paperless-ngx using Large Language Models (LLMs). It supports multiple LLM providers, including OpenAI and Ollama. With paperless-gpt, you can streamline your document management by automatically suggesting appropriate titles and tags based on the content of your scanned documents. The tool offers features like multiple LLM support, customizable prompts, easy integration with paperless-ngx, user-friendly interface for reviewing and applying suggestions, dockerized deployment, automatic document processing, and an experimental OCR feature.

quantalogic
QuantaLogic is a ReAct framework for building advanced AI agents that seamlessly integrates large language models with a robust tool system. It aims to bridge the gap between advanced AI models and practical implementation in business processes by enabling agents to understand, reason about, and execute complex tasks through natural language interaction. The framework includes features such as ReAct Framework, Universal LLM Support, Secure Tool System, Real-time Monitoring, Memory Management, and Enterprise Ready components.
mcp-documentation-server
The mcp-documentation-server is a lightweight server application designed to serve documentation files for projects. It provides a simple and efficient way to host and access project documentation, making it easy for team members and stakeholders to find and reference important information. The server supports various file formats, such as markdown and HTML, and allows for easy navigation through the documentation. With mcp-documentation-server, teams can streamline their documentation process and ensure that project information is easily accessible to all involved parties.

dingo
Dingo is a data quality evaluation tool that automatically detects data quality issues in datasets. It provides built-in rules and model evaluation methods, supports text and multimodal datasets, and offers local CLI and SDK usage. Dingo is designed for easy integration into evaluation platforms like OpenCompass.

LocalAGI
LocalAGI is a powerful, self-hostable AI Agent platform that allows you to design AI automations without writing code. It provides a complete drop-in replacement for OpenAI's Responses APIs with advanced agentic capabilities. With LocalAGI, you can create customizable AI assistants, automations, chat bots, and agents that run 100% locally, without the need for cloud services or API keys. The platform offers features like no-code agents, web-based interface, advanced agent teaming, connectors for various platforms, comprehensive REST API, short & long-term memory capabilities, planning & reasoning, periodic tasks scheduling, memory management, multimodal support, extensible custom actions, fully customizable models, observability, and more.
sonarqube-mcp-server
The SonarQube MCP Server is a Model Context Protocol (MCP) server that enables seamless integration with SonarQube Server or Cloud for code quality and security. It supports the analysis of code snippets directly within the agent context. The server provides various tools for analyzing code, managing issues, accessing metrics, and interacting with SonarQube projects. It also supports advanced features like dependency risk analysis, enterprise portfolio management, and system health checks. The server can be configured for different transport modes, proxy settings, and custom certificates. Telemetry data collection can be disabled if needed.
docutranslate
Docutranslate is a versatile tool for translating documents efficiently. It supports multiple file formats and languages, making it ideal for businesses and individuals needing quick and accurate translations. The tool uses advanced algorithms to ensure high-quality translations while maintaining the original document's formatting. With its user-friendly interface, Docutranslate simplifies the translation process and saves time for users. Whether you need to translate legal documents, technical manuals, or personal letters, Docutranslate is the go-to solution for all your document translation needs.
mcp-devtools
MCP DevTools is a high-performance server written in Go that replaces multiple Node.js and Python-based servers. It provides access to essential developer tools through a unified, modular interface. The server is efficient, with minimal memory footprint and fast response times. It offers a comprehensive tool suite for agentic coding, including 20+ essential developer agent tools. The tool registry allows for easy addition of new tools. The server supports multiple transport modes, including STDIO, HTTP, and SSE. It includes a security framework for multi-layered protection and a plugin system for adding new tools.

Scrapegraph-ai
ScrapeGraphAI is a Python library that uses Large Language Models (LLMs) and direct graph logic to create web scraping pipelines for websites, documents, and XML files. It allows users to extract specific information from web pages by providing a prompt describing the desired data. ScrapeGraphAI supports various LLMs, including Ollama, OpenAI, Gemini, and Docker, enabling users to choose the most suitable model for their needs. The library provides a user-friendly interface through its `SmartScraper` class, which simplifies the process of building and executing scraping pipelines. ScrapeGraphAI is open-source and available on GitHub, with extensive documentation and examples to guide users. It is particularly useful for researchers and data scientists who need to extract structured data from web pages for analysis and exploration.
openai-edge-tts
This project provides a local, OpenAI-compatible text-to-speech (TTS) API using `edge-tts`. It emulates the OpenAI TTS endpoint (`/v1/audio/speech`), enabling users to generate speech from text with various voice options and playback speeds, just like the OpenAI API. `edge-tts` uses Microsoft Edge's online text-to-speech service, making it completely free. The project supports multiple audio formats, adjustable playback speed, and voice selection options, providing a flexible and customizable TTS solution for users.

parrot.nvim
Parrot.nvim is a Neovim plugin that prioritizes a seamless out-of-the-box experience for text generation. It simplifies functionality and focuses solely on text generation, excluding integration of DALLE and Whisper. It supports persistent conversations as markdown files, custom hooks for inline text editing, multiple providers like Anthropic API, perplexity.ai API, OpenAI API, Mistral API, and local/offline serving via ollama. It allows custom agent definitions, flexible API credential support, and repository-specific instructions with a `.parrot.md` file. It does not have autocompletion or hidden requests in the background to analyze files.
mcp-omnisearch
mcp-omnisearch is a Model Context Protocol (MCP) server that acts as a unified gateway to multiple search providers and AI tools. It integrates Tavily, Perplexity, Kagi, Jina AI, Brave, Exa AI, and Firecrawl to offer a wide range of search, AI response, content processing, and enhancement features through a single interface. The server provides powerful search capabilities, AI response generation, content extraction, summarization, web scraping, structured data extraction, and more. It is designed to work flexibly with the API keys available, enabling users to activate only the providers they have keys for and easily add more as needed.
For similar tasks

phospho
Phospho is a text analytics platform for LLM apps. It helps you detect issues and extract insights from text messages of your users or your app. You can gather user feedback, measure success, and iterate on your app to create the best conversational experience for your users.

Awesome-Segment-Anything
Awesome-Segment-Anything is a powerful tool for segmenting and extracting information from various types of data. It provides a user-friendly interface to easily define segmentation rules and apply them to text, images, and other data formats. The tool supports both supervised and unsupervised segmentation methods, allowing users to customize the segmentation process based on their specific needs. With its versatile functionality and intuitive design, Awesome-Segment-Anything is ideal for data analysts, researchers, content creators, and anyone looking to efficiently extract valuable insights from complex datasets.
mslearn-knowledge-mining
The mslearn-knowledge-mining repository contains lab files for Azure AI Knowledge Mining modules. It provides resources for learning and implementing knowledge mining techniques using Azure AI services. The repository is designed to help users explore and understand how to leverage AI for knowledge mining purposes within the Azure ecosystem.
summarize
The 'summarize' tool is designed to transcribe and summarize videos from various sources using AI models. It helps users efficiently summarize lengthy videos, take notes, and extract key insights by providing timestamps, original transcripts, and support for auto-generated captions. Users can utilize different AI models via Groq, OpenAI, or custom local models to generate grammatically correct video transcripts and extract wisdom from video content. The tool simplifies the process of summarizing video content, making it easier to remember and reference important information.
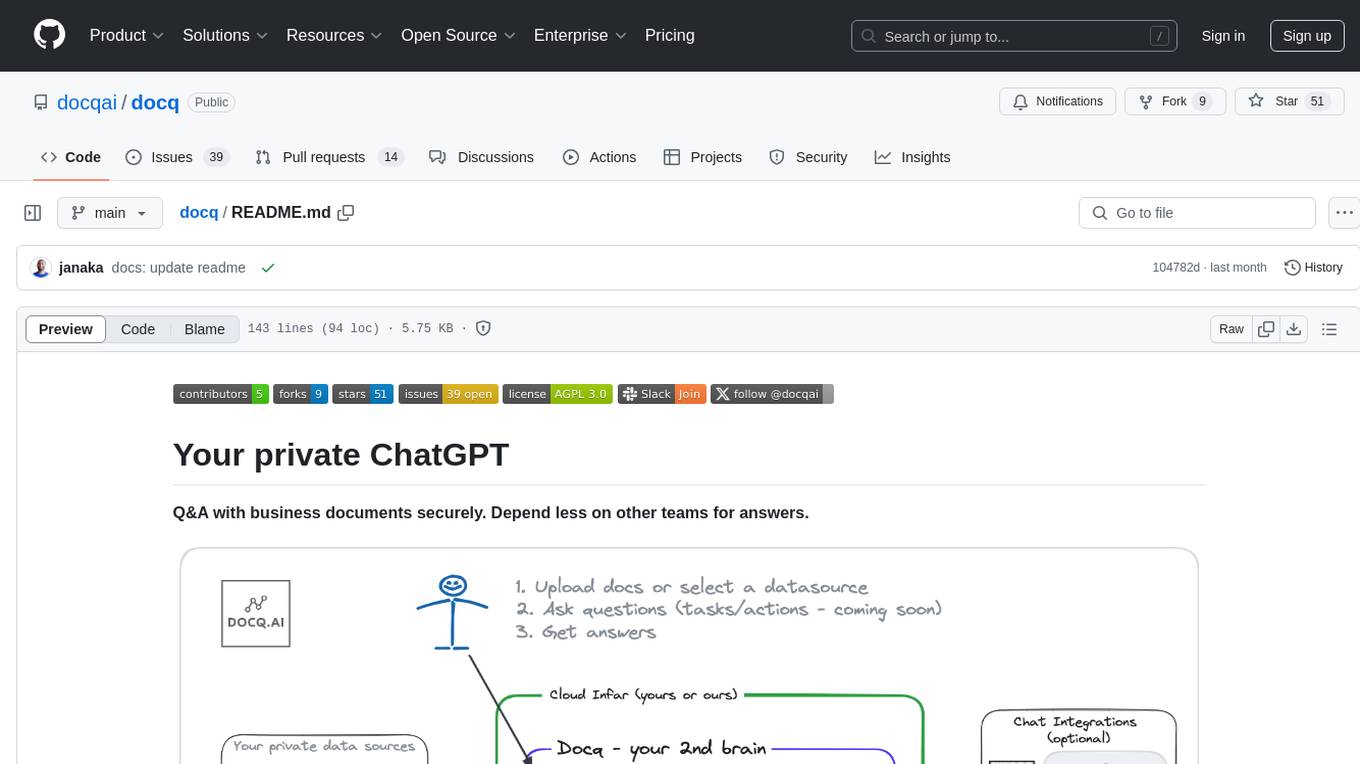
docq
Docq is a private and secure GenAI tool designed to extract knowledge from business documents, enabling users to find answers independently. It allows data to stay within organizational boundaries, supports self-hosting with various cloud vendors, and offers multi-model and multi-modal capabilities. Docq is extensible, open-source (AGPLv3), and provides commercial licensing options. The tool aims to be a turnkey solution for organizations to adopt AI innovation safely, with plans for future features like more data ingestion options and model fine-tuning.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.

codellm-devkit
Codellm-devkit (CLDK) is a Python library that serves as a multilingual program analysis framework bridging traditional static analysis tools and Large Language Models (LLMs) specialized for code (CodeLLMs). It simplifies the process of analyzing codebases across multiple programming languages, enabling the extraction of meaningful insights and facilitating LLM-based code analysis. The library provides a unified interface for integrating outputs from various analysis tools and preparing them for effective use by CodeLLMs. Codellm-devkit aims to enable the development and experimentation of robust analysis pipelines that combine traditional program analysis tools and CodeLLMs, reducing friction in multi-language code analysis and ensuring compatibility across different tools and LLM platforms. It is designed to seamlessly integrate with popular analysis tools like WALA, Tree-sitter, LLVM, and CodeQL, acting as a crucial intermediary layer for efficient communication between these tools and CodeLLMs. The project is continuously evolving to include new tools and frameworks, maintaining its versatility for code analysis and LLM integration.
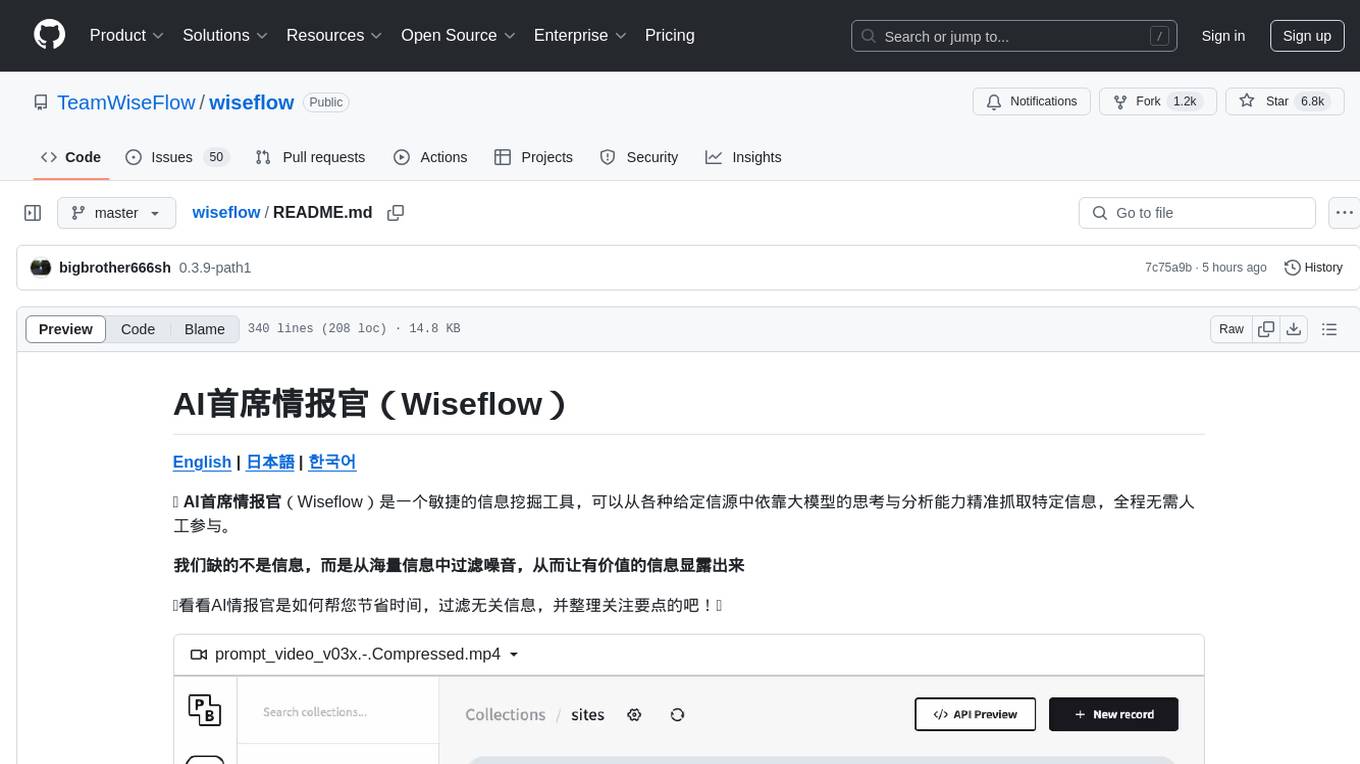
wiseflow
Wiseflow is an agile information mining tool that utilizes the thinking and analysis capabilities of large models to accurately extract specific information from various given sources, without the need for manual intervention. The tool focuses on filtering noise from a vast amount of information to reveal valuable insights. It is recommended to use normal language models for information extraction tasks to optimize speed and cost, rather than complex reasoning models. The tool is designed for continuous information gathering based on specified focus points from various sources.
For similar jobs

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

daily-poetry-image
Daily Chinese ancient poetry and AI-generated images powered by Bing DALL-E-3. GitHub Action triggers the process automatically. Poetry is provided by Today's Poem API. The website is built with Astro.

exif-photo-blog
EXIF Photo Blog is a full-stack photo blog application built with Next.js, Vercel, and Postgres. It features built-in authentication, photo upload with EXIF extraction, photo organization by tag, infinite scroll, light/dark mode, automatic OG image generation, a CMD-K menu with photo search, experimental support for AI-generated descriptions, and support for Fujifilm simulations. The application is easy to deploy to Vercel with just a few clicks and can be customized with a variety of environment variables.

SillyTavern
SillyTavern is a user interface you can install on your computer (and Android phones) that allows you to interact with text generation AIs and chat/roleplay with characters you or the community create. SillyTavern is a fork of TavernAI 1.2.8 which is under more active development and has added many major features. At this point, they can be thought of as completely independent programs.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

AISuperDomain
Aila Desktop Application is a powerful tool that integrates multiple leading AI models into a single desktop application. It allows users to interact with various AI models simultaneously, providing diverse responses and insights to their inquiries. With its user-friendly interface and customizable features, Aila empowers users to engage with AI seamlessly and efficiently. Whether you're a researcher, student, or professional, Aila can enhance your AI interactions and streamline your workflow.

ChatGPT-On-CS
This project is an intelligent dialogue customer service tool based on a large model, which supports access to platforms such as WeChat, Qianniu, Bilibili, Douyin Enterprise, Douyin, Doudian, Weibo chat, Xiaohongshu professional account operation, Xiaohongshu, Zhihu, etc. You can choose GPT3.5/GPT4.0/ Lazy Treasure Box (more platforms will be supported in the future), which can process text, voice and pictures, and access external resources such as operating systems and the Internet through plug-ins, and support enterprise AI applications customized based on their own knowledge base.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.